官网下载软件:
Ubuntu : https://releases.ubuntu.com/
jdk : https://www.oracle.com/java/technologies/downloads/
Hadoop : https://archive.apache.org/dist/hadoop/common/hadoop-3.3.2/
下载后上传到服务器,解压
一
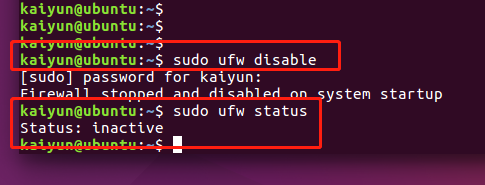
1. 关闭防火墙
sudo ufw disable
查看防火墙状态,状态为“不活动”,说明防火墙已经关闭
sudo ufw status
2. ssh 安装
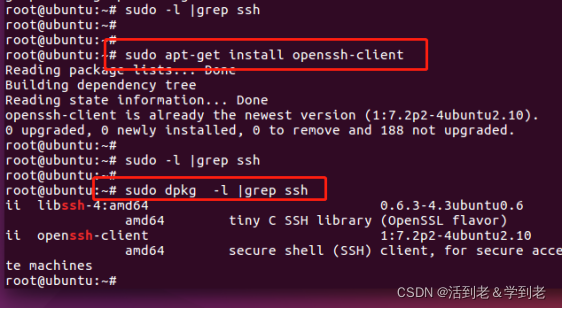
(1)安装SSH客户端软件
检查是否已安装
sudo dpkg -l | grep ssh
安装:
sudo apt-get install openssh-client`在这里插入代码片`
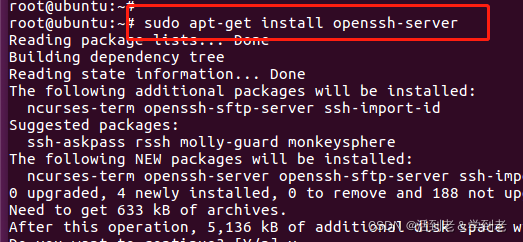
(2)安装SSH服务端软件
sudo apt-get install openssh-server
重启:
sudo /etc/init.d/ssh restart

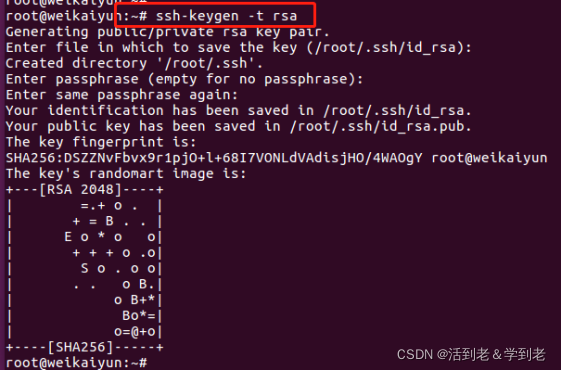
(3)免密登录设置
生成密钥对 , 一路回车
ssh-keygen -t rsa
查看
ls ~/.ssh

追加公钥
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600 .ssh/authorized_keys

查看
ls ~/.ssh

免密登录验证
~/.ssh$ ssh node1
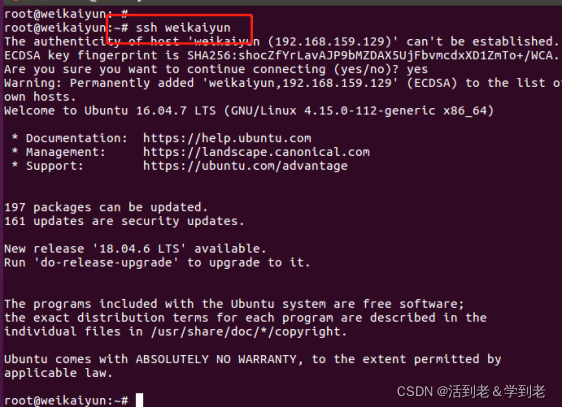
退出
exit
3. JDK
-
解压,更名,建立软连接

-
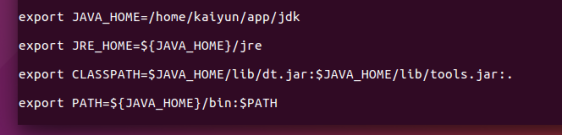
配置JDK环境变量
vim ~/.bashrc
追加
export JAVA_HOME=~/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=${JAVA_HOME}/bin:$PATH
使配置生效
source ~/.bashrc
验证
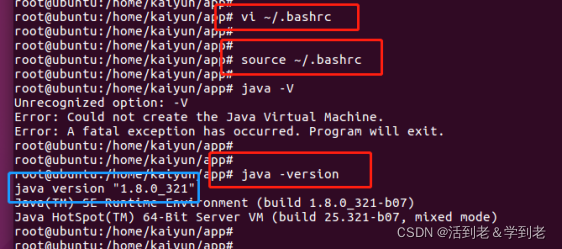
四. Hadoop
1. 更改主机名
查看主机名
hostname

更改主机名
sudo vim /etc/hostname

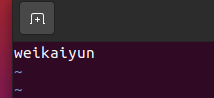
重启

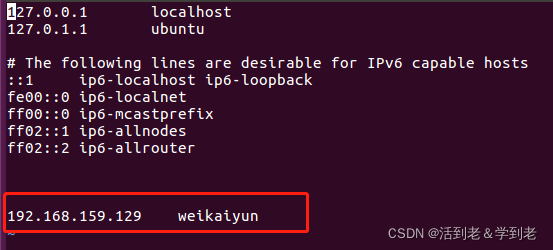
(2)映射IP地址及主机名
sudo vim /etc/hosts
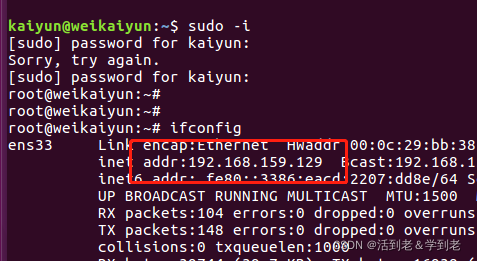

追加
192.168.30.128 node1
(3)设置Hadoop配置文件
解压,改名称
设置环境变量
vi ~/.bashrc
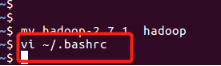
追加
export HADOOP_HOME=~/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
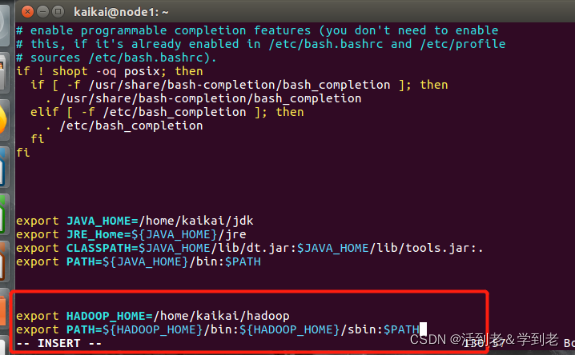
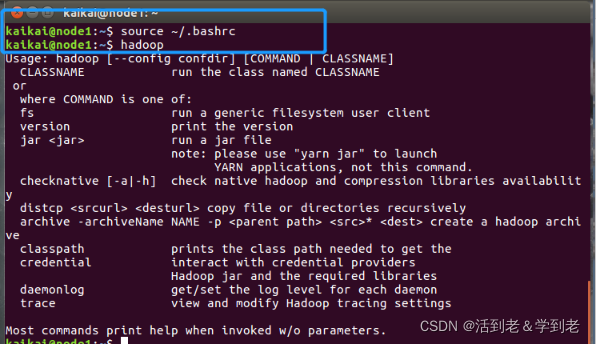
使配置生效
输入 hadoop 验证
source ~/.bashrc
2. 配置 hadoop 相关 文件
在 hadoop 的 etc/hadoop 下
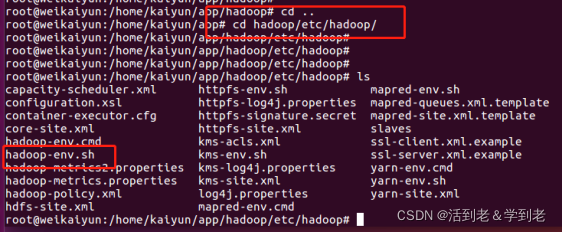
(1) hadoop-env.sh
cd ~/hadoop/etc/hadoop
vi hadoop-env.sh

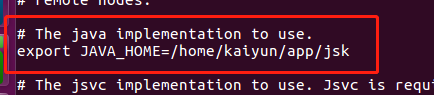
找到export JAVA_HOME一行,把行首的#去掉,并按实际修改JAVA_HOME的值。
# The java implementation to use.
export JAVA_HOME=/home/hadoop/jdk
(2) .core-site.xml
vi core-site.xml

<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
<!-- 以上ip地址或主机名要按实际情况修改 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
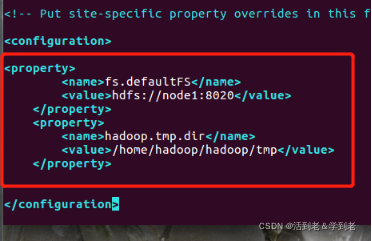
PS : /home/hadoop/hadoop/tmp 这个目录是不存在的,要自己创建一个,如果后面jps验证后出不来,就试试加权限
(3) 配置hdfs-site.xml
vi hdfs-site.xml

<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
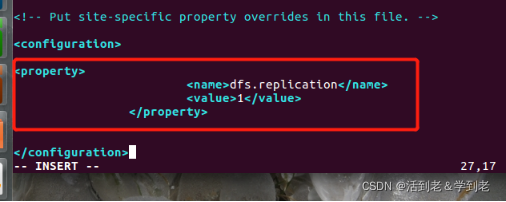
dfs.replication的默认值是3,因为伪分布式只有一个节点,所以值设置为1
(4) 配置mapred-site.xml
复制mapred-site.xml.template,生成mapred-site.xml
cp mapred-site.xml.template mapred-site.xml

打开mapred-site.xml
vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
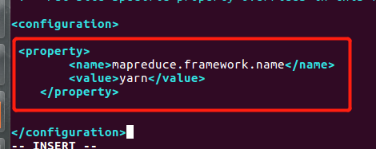
mapreduce.framework.name默认值为local,设置为yarn,让MapReduce程序运行在YARN框架上
(5) 配置yarn-site.xml
vi yarn-site.xml

<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<!-- 以上主机名或IP地址按实际情况修改 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
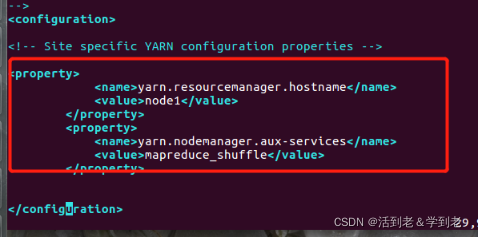
PS:
通过以上设置,我们完成了Hadoop伪分布式模式的配置。其实Hadoop可以配置的属性还有很多,没有配置的属性就用默认值,默认属性配置存放在core-default.xml、hdfs-default.xml、mapred-default.xml和yarn-default.xml文件中。可以到官网查询对应文档或通过命令 locate <查找的文件名> 来查找文件所在路径,再通过cat命令查看其内容
ps: 用locate 之前先更新
locate core-default.xml
/home/hadoop/soft/hadoop-2.7.3/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.xml
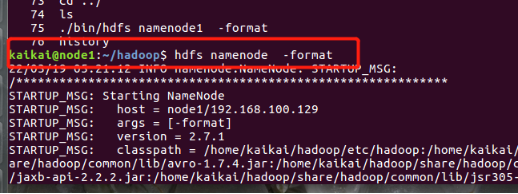
(6) 格式化HDFS
hdfs namenode -format
sudo chmod 777 hadoop
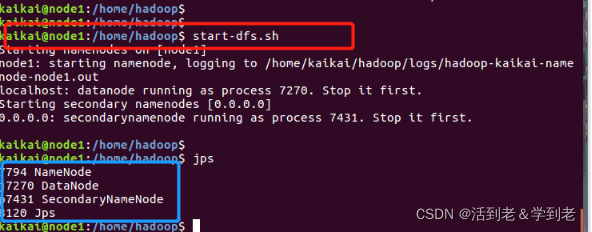
(7) 启动Hadoop
启动HDFS
start-dfs.sh
用jps命令验证
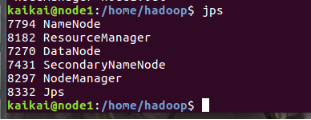
启动YARN
start-yarn.sh
用jps命令验证多了两个
或者
start-all.sh
五 通过Web访问Hadoop
- HDFS Web界面
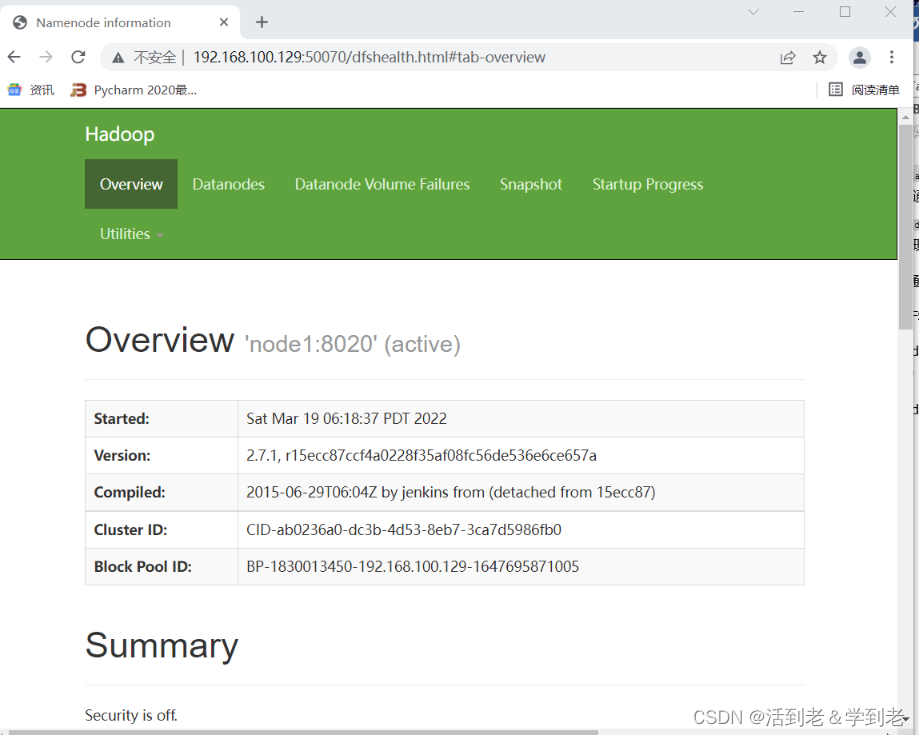
(1)在Windows浏览器中,输入网址http://192.168.100.129:50070,可以查看NameNode和DataNode的信息
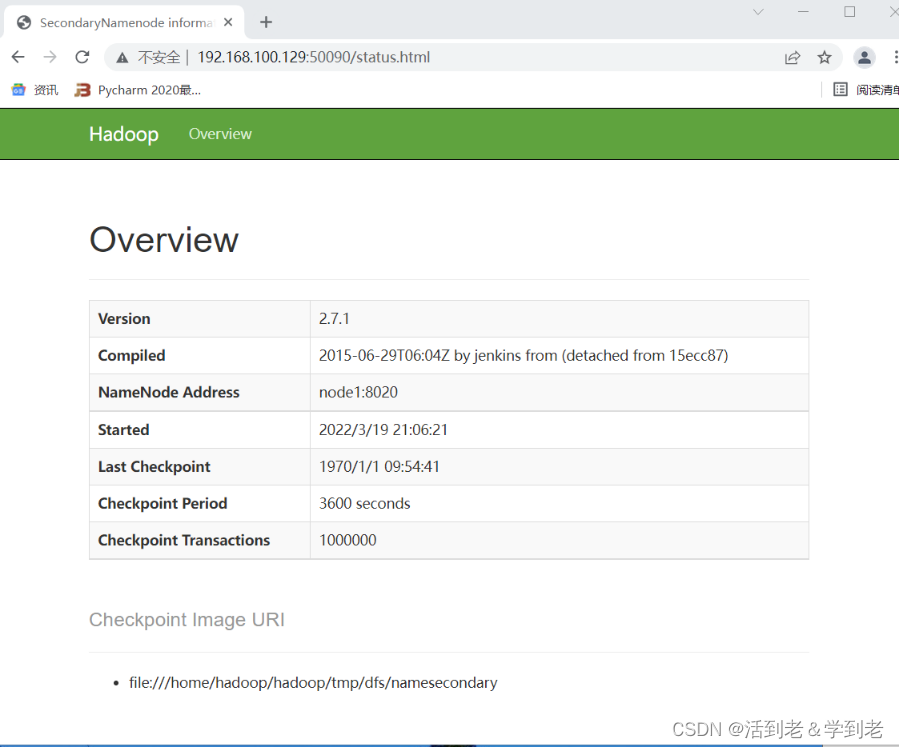
(2)在Windows浏览器中,输入网址http://192.168.100.129:50090,可以查看SecondaryNameNode的信息
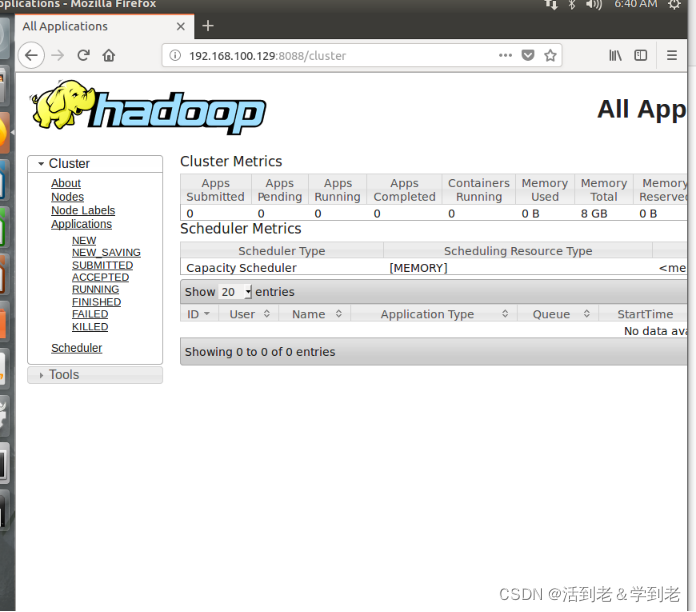
- YARN Web界面
在Ubuntu操作系统的浏览器中,输入网址http://192.168.100.129:8088,可以查看集群所有应用程序的信息
六 测试Hadoop
通过一个MapReduce程序测试Hadoop,统计HDFS中/input/data.txt文件内单词出现的次数
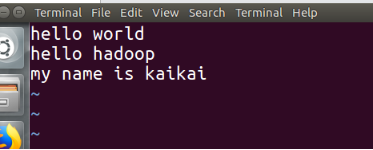
1.创建一个文本文件data.txt
cd ~
vi data.txt
Hello World
Hello Hadoop
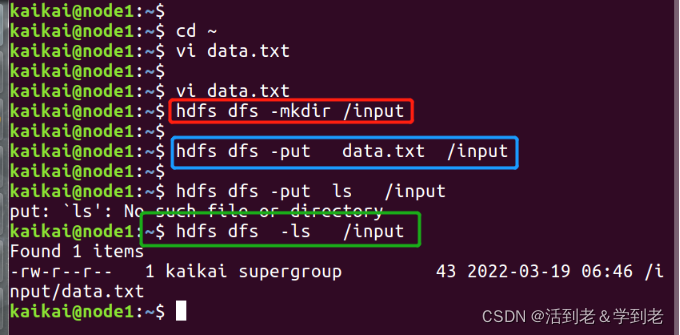
- 在HDFS创建input文件夹
hdfs dfs -mkdir /input
将data.txt上传到HDFS
hdfs dfs -put data.txt /input
查看是否上传成功
hdfs dfs -ls /input
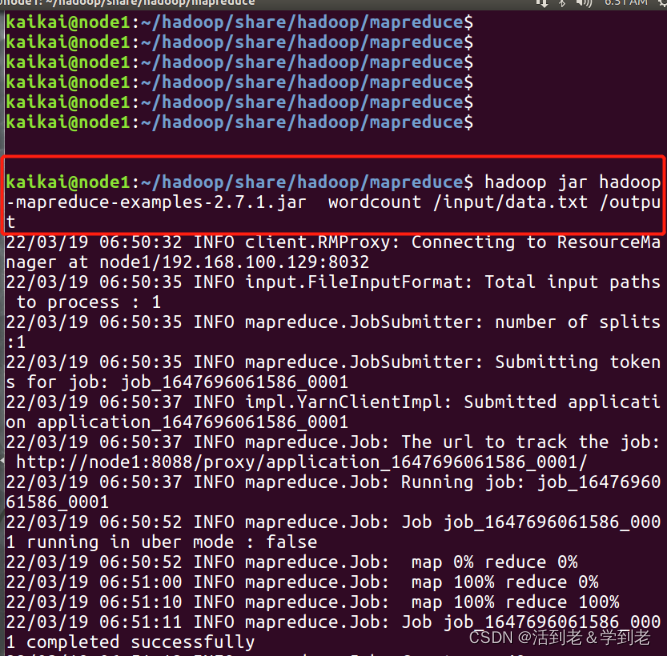
(5) 运行MapReduce WordCount例子
cd ~/hadoop/share/hadoop/mapreduce
注意 jar 版本
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output
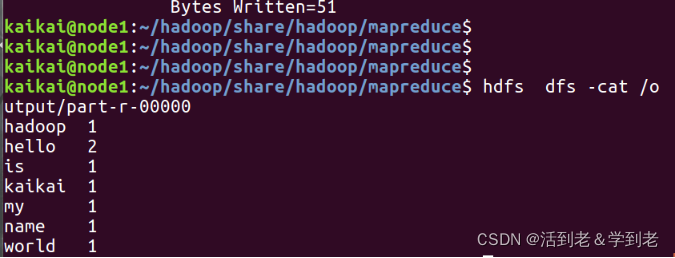
(6) 查看结果
hdfs dfs -cat /output/part-r-00000
(7) 停止Hadoop进程
stop-dfs.sh
stop-yarn.sh
或者
stop-all.sh
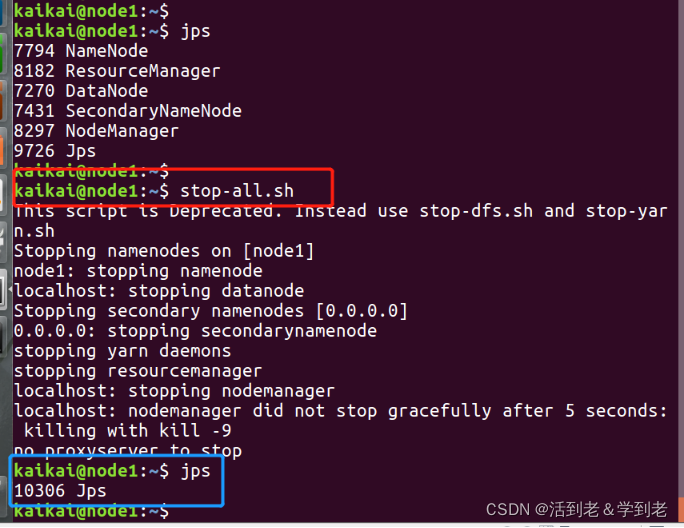
至此,Hadoop伪分布式模式搭建完成
PS: 由于是后期整理的笔记,IP与主机名,目录路径可能存在偏差,读者需多注意一下