һ.Ԫ��(Tuples and Case Classes )
��java��˵Tuples��flink�Դ���һ����, ����scala��˵flinkû���ṩ����Tuples����, ��Ϊscala�����Դ���һ�������� case class.
��Ҫ˵˵java���Tuples, Java API �ṩ��Tuple1��ߵ�Tuple25. Ԫ���ÿ���ֶζ����������� Flink ����, 1 25������ֵ���˼�Dz����ĸ���.
Tuple1 t1;
Tuple2<String,String> t2;
Tuple3<String,Integer,Long> t3;
����Tuple�е�����flink�ṩ�˱�ݵķ���,����:tuple.getField(int position)���ֶ������� 0 ��ʼ, ����tuple.f��ʽ, f���������,Ҳ�Ǵ�0��ʼ.
���� Tuple3<String, String,Integer> t3=new Tuple3<String,
String,Integer>(��������, ����,20)
���Ҫ�����������������ַ���:
- t3.f2
- t3.getField(2)
case class WordCount(word: String, count: Int)
val input = env.fromElements(
WordCount("hello", 1),
WordCount("world", 2)) // Case Class Data Set
2.java��
DataStream<Tuple2<String, Integer>> wordCounts = env.fromElements(
new Tuple2<String, Integer>("hello", 1),
new Tuple2<String, Integer>("world", 2));
wordCounts.map(new MapFunction<Tuple2<String, Integer>, Integer>() {
@Override
public Integer map(Tuple2<String, Integer> value) throws Exception {
return value.f1;
}
});
����������java��Tuple,Tuple��һ��ʵ����java���л��ӿڵ�һ������ӿ�,Tuple2 Tupe3 ��Tuple25��ʵ����Tuple�ӿڵľ������
Tuple�ӿ�ʵ����java�����л��ӿ�,public abstract class Tuple implements java.io.Serializable
������Tuple2��Դ��:
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// --------------------------------------------------------------
// THIS IS A GENERATED SOURCE FILE. DO NOT EDIT!
// GENERATED FROM org.apache.flink.api.java.tuple.TupleGenerator.
// --------------------------------------------------------------
package org.apache.flink.api.java.tuple;
import org.apache.flink.annotation.Public;
import org.apache.flink.util.StringUtils;
/**
* A tuple with 2 fields. Tuples are strongly typed; each field may be of a separate type. The
* fields of the tuple can be accessed directly as public fields (f0, f1, ...) or via their position
* through the {@link #getField(int)} method. The tuple field positions start at zero.
*
* <p>Tuples are mutable types, meaning that their fields can be re-assigned. This allows functions
* that work with Tuples to reuse objects in order to reduce pressure on the garbage collector.
*
* <p>Warning: If you subclass Tuple2, then be sure to either
*
* <ul>
* <li>not add any new fields, or
* <li>make it a POJO, and always declare the element type of your DataStreams/DataSets to your
* descendant type. (That is, if you have a "class Foo extends Tuple2", then don't use
* instances of Foo in a DataStream<Tuple2> / DataSet<Tuple2>, but declare it as
* DataStream<Foo> / DataSet<Foo>.)
* </ul>
*
* @see Tuple
* @param <T0> The type of field 0
* @param <T1> The type of field 1
*/
@Public
public class Tuple2<T0, T1> extends Tuple {
private static final long serialVersionUID = 1L;
/** Field 0 of the tuple. */
public T0 f0;
/** Field 1 of the tuple. */
public T1 f1;
/** Creates a new tuple where all fields are null. */
public Tuple2() {}
/**
* Creates a new tuple and assigns the given values to the tuple's fields.
*
* @param f0 The value for field 0
* @param f1 The value for field 1
*/
public Tuple2(T0 f0, T1 f1) {
this.f0 = f0;
this.f1 = f1;
}
@Override
public int getArity() {
return 2;
}
@Override
@SuppressWarnings("unchecked")
public <T> T getField(int pos) {
switch (pos) {
case 0:
return (T) this.f0;
case 1:
return (T) this.f1;
default:
throw new IndexOutOfBoundsException(String.valueOf(pos));
}
}
@Override
@SuppressWarnings("unchecked")
public <T> void setField(T value, int pos) {
switch (pos) {
case 0:
this.f0 = (T0) value;
break;
case 1:
this.f1 = (T1) value;
break;
default:
throw new IndexOutOfBoundsException(String.valueOf(pos));
}
}
/**
* Sets new values to all fields of the tuple.
*
* @param f0 The value for field 0
* @param f1 The value for field 1
*/
public void setFields(T0 f0, T1 f1) {
this.f0 = f0;
this.f1 = f1;
}
/**
* Returns a shallow copy of the tuple with swapped values.
*
* @return shallow copy of the tuple with swapped values
*/
public Tuple2<T1, T0> swap() {
return new Tuple2<T1, T0>(f1, f0);
}
// -------------------------------------------------------------------------------------------------
// standard utilities
// -------------------------------------------------------------------------------------------------
/**
* Creates a string representation of the tuple in the form (f0, f1), where the individual
* fields are the value returned by calling {@link Object#toString} on that field.
*
* @return The string representation of the tuple.
*/
@Override
public String toString() {
return "("
+ StringUtils.arrayAwareToString(this.f0)
+ ","
+ StringUtils.arrayAwareToString(this.f1)
+ ")";
}
/**
* Deep equality for tuples by calling equals() on the tuple members.
*
* @param o the object checked for equality
* @return true if this is equal to o.
*/
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Tuple2)) {
return false;
}
@SuppressWarnings("rawtypes")
Tuple2 tuple = (Tuple2) o;
if (f0 != null ? !f0.equals(tuple.f0) : tuple.f0 != null) {
return false;
}
if (f1 != null ? !f1.equals(tuple.f1) : tuple.f1 != null) {
return false;
}
return true;
}
@Override
public int hashCode() {
int result = f0 != null ? f0.hashCode() : 0;
result = 31 * result + (f1 != null ? f1.hashCode() : 0);
return result;
}
/**
* Shallow tuple copy.
*
* @return A new Tuple with the same fields as this.
*/
@Override
@SuppressWarnings("unchecked")
public Tuple2<T0, T1> copy() {
return new Tuple2<>(this.f0, this.f1);
}
/**
* Creates a new tuple and assigns the given values to the tuple's fields. This is more
* convenient than using the constructor, because the compiler can infer the generic type
* arguments implicitly. For example: {@code Tuple3.of(n, x, s)} instead of {@code new
* Tuple3<Integer, Double, String>(n, x, s)}
*/
public static <T0, T1> Tuple2<T0, T1> of(T0 f0, T1 f1) {
return new Tuple2<>(f0, f1);
}
}
����flink���Tuple�����л�,�ײ㻹���õ�java�����л�,��û�������������л����.
��.java����scala ��ѭ�����淶����(POJOs )
��ͨ��������Ҫ��:
- ������public ��
- ������һ������������Ĭ�Ϲ��캯��
- �ֶα���Ҳ�ǹ�����,�����ṩget/set����
- �ֶε����ͱ��뱻ע������л���֧��
���������Ӵ���:
public class WordWithCount {
public String word;
public int count;
public WordWithCount() {}
public WordWithCount(String word, int count) {
this.word = word;
this.count = count;
}
}
DataStream<WordWithCount> wordCounts = env.fromElements(
new WordWithCount("hello", 1),
new WordWithCount("world", 2));
wordCounts.keyBy(value -> value.word);
������scala
class WordWithCount(var word: String, var count: Int) {
//���������
def this() {
this(null, -1)
}
}
val input = env.fromElements(
//����������ֱ�ӵ��õ���������,����scala��������ο��ҵ���������
new WordWithCount("hello", 1),
new WordWithCount("world", 2)) // Case Class Data Set
input.keyBy(_.word)
������˵˵����ԭ��:�������Լ��������ͨ��,flink���Ȼ��������������ļ��,������Ե�һ������Ƿ���public ���ε���C>Modifier.isPublic([��].getModifiers()), �������֮���ַ���������������,��ô�ͻ�Ե�ǰ�����PojoSerializer ���л������з�װ,�����Ǽ̳й�ϵ:
public final class PojoSerializer extends TypeSerializer {��}
public abstract class TypeSerializer implements Serializable{��}
���Կ�������õ����л�����java�����л�. TypeSerializer��һ������ӿ�,���������е����л������TypeSerializer��һ��ʵ�ְ���PojoSerializer,������һЩʵ����TypeSerializer����.
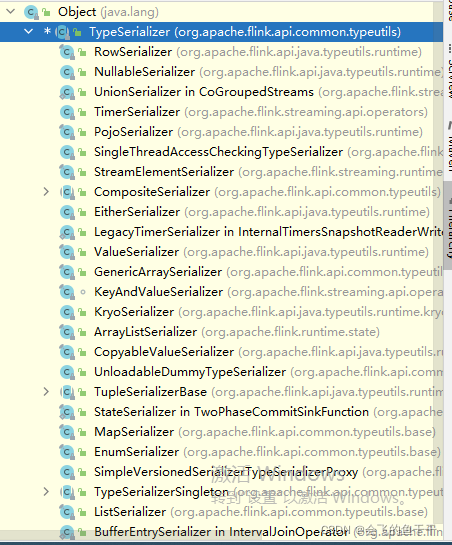
�����ⲻ����������������,��ôflinkĬ�ϵ����л�������ͼ�е�:KryoSerializer ,������л��������õ� Kryo���.��KryoSerializer ����������ע��:
A type serializer that serializes its type using the Kryo serialization framework (https://github.com/EsotericSoftware/kryo).
This serializer is intended as a fallback serializer for the cases that are not covered by the basic types, tuples, and POJOs.
Type parameters:
�C The type to be serialized.
public class KryoSerializer extends TypeSerializer {������ʡ��}
��.ԭʼ����(Primitive Types )
flink֧������scala/java ������ԭʼ����:Integer String Double
��.ͨ����(General Class Types)
java/scala �����ض�����˵�Ĺ淶,��ôscala�Ὣ���ఴ��ͳһ�����л����������л�,������л������õ����л������Kryo
��.flink���õ�Values����
����Ҫʵ��org.apache.flink.types.Value �ӿڵ� read ��write����. ��ͨ����(General Class Types) ���Values�ӿ����л���ʽ���Ӹ�Ч.
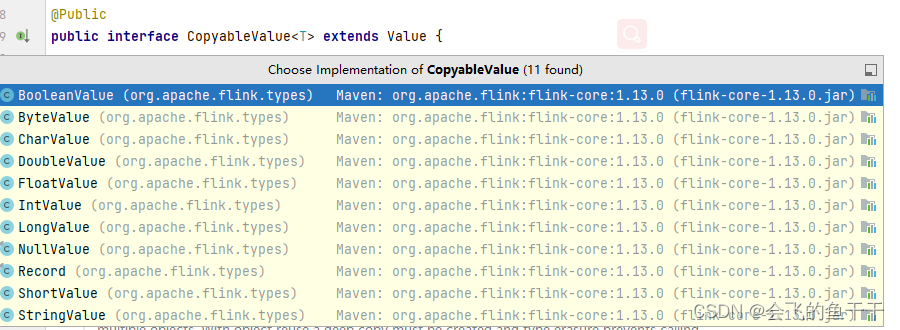
Flink�ṩ��Ԥ�����Value����,����������������Ӧ��(ByteValue, ShortValue, IntValue, LongValue, FloatValue, DoubleValue, StringValue, CharValue, BooleanValue)����ЩValue���ͳ䵱�����������͵Ŀɱ����:���ǵ�ֵ���Ը���,�Ӷ���������Ա���ö���,���������ռ�����ѹ����
��ͼչʾ��Ԥ��������ͺͽӿ�Value�Ĺ�ϵ:
��.Hadoop Writables
������ʹ��ʵ��org.apache.hadoop.Writable�ӿڵ����͡�write()�ͷ����ж�������л���readFields()���������л���
��.��������
������ʹ����������,���� Scala ��Either��Option��Try. Java API ���Լ����Զ���ʵ��Either���� Scala ����Either,����ʾ���ֿ������͵�ֵ,����ҡ� Either������Ҫ������ֲ�ͬ���ͼ�¼�Ĵ�������������dz����á�
����java�������Ͳ��������⡯
Java �������ڱ�������˺ܶ��������Ϣ������ Java�г�Ϊ���Ͳ���������ζ��������ʱ,�����ʵ������֪���䷺�����͡�����,�� JVM ��DataStream�͵�ʵ��DataStream��������ͬ��
Flink ��������ִ��ʱ(���ó���� main ����ʱ)��Ҫ������Ϣ��Flink Java API ��ͼ�Ը��ַ�ʽ�ع���������������Ϣ,��������ʽ�洢�����ݼ���������С�������ͨ����������DataStream.getType()���÷�������һ�� ��ʵ��TypeInformation,���� Flink �ڲ���ʾ���͵ķ�ʽ��
�����ƶ����������,��ijЩ�������Ҫ����Ա����������ϡ���,���� ExecutionEnvironment.fromCollection(),�����������д����������͵IJ�����
������MapFunction<I, O>�����ķ��ͺ���������Ҫ�����������Ϣ��
����������
- ע��������:�������ǩ��ֻ����������,����ִ�й�����ʵ����ʹ���˳����͵�������,��ô�� Flink
�˽���Щ�����Ϳ��ܻ���������ܡ�Ϊ��,��.registerType(clazz)Ϊÿ�������͵���StreamExecutionEnvironmentor
ExecutionEnvironment�� - ע���Զ������л���: Flink ���˵�Kryo���������Լ����������������͡������������Ͷ��� Kryo(���Ҳ��
Flink)�촦��������,���� Google Guava
����������Ĭ����������������������������Ϊ�������������ע���������л�������仰��˵�и���������ͼȲ���IntegerҲ����String,����������Զ�������ͱ���MyInt��ʱ���ǿ������MyIntע��һ���Զ�������л���.���á�.getConfig().addDefaultKryoSerializer(clazz,
serializer)-��������ṩ������ Kryo
���л������й�ʹ���Զ������л�����ĸ�����ϸ��Ϣ,��������������л��������˹�����ʵ������,һ����˵����ֻ���Զ������,���ٻ��Զ�������. - ����������ʾ:��ʱ,���� Flink ���ƶϳ���������,���û����봫��������ʾ����ͨ��ֻ�� Java API
���DZ���ġ�������ʾ���ָ���ϸ����������һ�㡣 - �ֶ�����TypeInformation:�����ijЩ API ���ÿ����DZ�Ҫ��,��Ϊ Java �ķ������Ͳ���,Flink
���ƶ��������͡��й���ϸ��Ϣ,��������� TypeInformation �� TypeSerializer ��
����TypeInfomation
flinkʵ�����Լ�������ϵͳ,���������ͼ��.�Լ���ƽ������schem ,TypeInfomation�����������͵Ļ���,TypeInfomation�����˵�ǰ���͵�������ʲô,�Լ������л����õ�ʲô,��ͼ����ʵ�ִ˽ӿڵĻ���: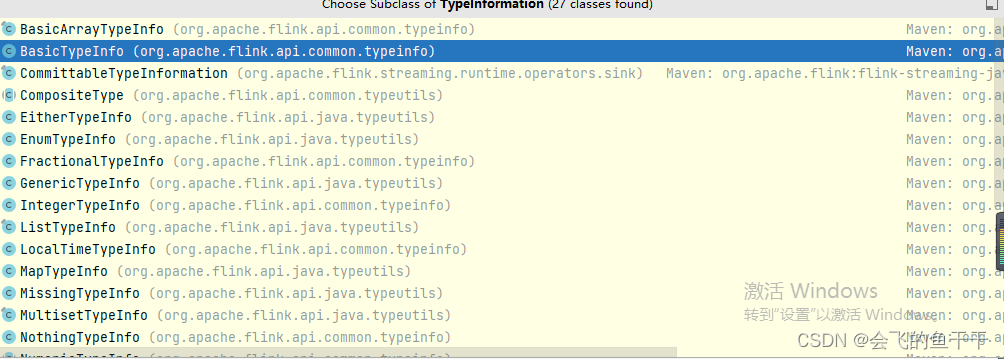
��������һ��BasicTypeInfo:
BasicTypeInfo for primitive types (int, long, double, byte, ��), String, Date, Void, BigInteger, and BigDecimal.(BasicTypeInfo ��java�������͵ķ�װ��,���� int long double byte)
public static final BasicTypeInfo<Boolean> BOOLEAN_TYPE_INFO =
new BasicTypeInfo<>(
Boolean.class,
new Class<?>[] {},
BooleanSerializer.INSTANCE,
BooleanComparator.class);
ע�����:BooleanSerializer ������л�����ʵ����ʵ����TypeSerializer.
����˵��: TypeSerializer��һ������ӿ�,���������е����л������TypeSerializer��һ��ʵ��.