һ��ʲô������:
������mysql��һ�����ݽṹ,�������ݽṹ��֮Ϊ key,����˵��һ�����ݵ���֯��ʽ
���е�һ�������ݰ��������涨�Ľṹ��֯����һ�����νṹ,������B+����Χ��ѯ��ʵ�൱��n�ε�ֵ��ѯ
������:select name where id>3
��ֵ����:select name where id=2
����Ϊ��Ҫ������:
�Ż���ѯ�ٶ�,�������ݿ���˵��(select)д(insert,update,delete)��������ʮ:һ,���Բ���Ż����Եú���Ҫ
?
���������ȷ��������:
�������֪:
? ? 1����������֮��,������һ��ʱ��,�����������зdz���,��Ҫ������
? ? ? ? --����������һ�������ݿ���,����֮���Ҳ����(��������ǰ������),������ⶨλ���������Ͼ���Ҫ�ķѺܳ�ʱ��,�Ų�ɱ���
? ? ? ? ����취:����������֮����Ͽ�����Ա,��λ�����õIJ�ѯ�ֶ�,Ȼ��Ϊ���ֶδ�������? ? 2������Խ��Խ��
? ? ? ? --�����������ڼ��ٲ�ѯ��,�ή��д��Ч��
? ? ? ? --��ÿ��һ���������ǹ�����һ��������,�����ṹ��һЩ���ݴ���ibd�ļ���,���ļ�ռӲ�̿ռ�,Ҳ��ζ�ź�С��һ��update���ͻᵼ�ºܶ������������Ҫ�����仯,�Ӷ���Ӳ��IO����ȥ
?
�ġ�����֪ʶ
1�������ĸ���ԭ�����ǰ�Ӳ�̵�IO����������
2��Ϊһ�ű��е�һ���м�¼��������,����Ϊ���һҳҳ���ݴ���Ŀ¼,����Ŀ¼�ṹ��,�����Ժ�IJ�ѯ��Ӧ��ͨ��Ŀ¼ȥ��ѯ
3��һ�δ���IO������Ӱ��:
? ? �������:7200ת/m-> 120ת/s
? ? ���������������ݵ��ٶ���
? ? һ��IO���ӳ�ʱ��=ƽ��Ѱ��ʱ��(�����Ҫ5ms)+ ƽ���ӳ�ʱ��(ת��Ȧ��ʱ�� 4ms)=9ms
4�����̵�Ԥ��
? ? һҳ����һ�����̿�
? ? innodb�洢����һҳ16k,��һ��io��16k���ڴ���
? ? ���̵�Ԥ���ĸ���:�����������һ����ַ�����ݵ�ʱ��,�������ڵ�����Ҳ��ܿ챻���ʵ�
?
�塢��������
����ģ�͵ķ���:
? ? 1 B+������(��ֵ��ѯ�뷶Χ��ѯ����)
? ? 2 HASH����(��ֵ��ѯ��,��Χ��ѯ��)
? ? 3 FULL TEXT ȫ������(ֻ��������MYISAM����)
?
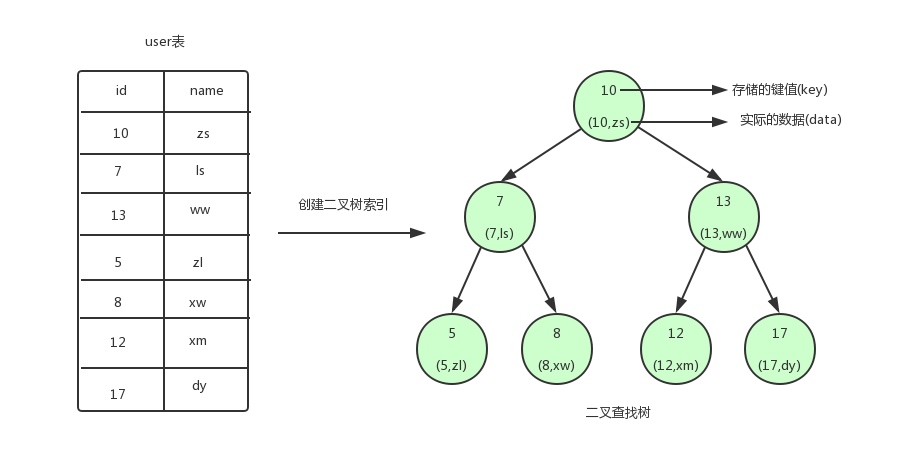
����������������������
? ? create index xx on user(id)
? ? 1 ��ȡ�����ֶε�ֵ����key,value���Ƕ�Ӧ�ı��м�¼
? ? �����������ֶ�������
? ? id name
? ? 10 ?21
? ? 7 ? 15
? ? 14 ?ww
? ? 5 ? xx? ? key:10-----��value:(10,21)
? ? ? ? 7 -----��value:(7,15)
? ? 2 ��key��Ϊ�����Ƚϴ�С,�������νṹ
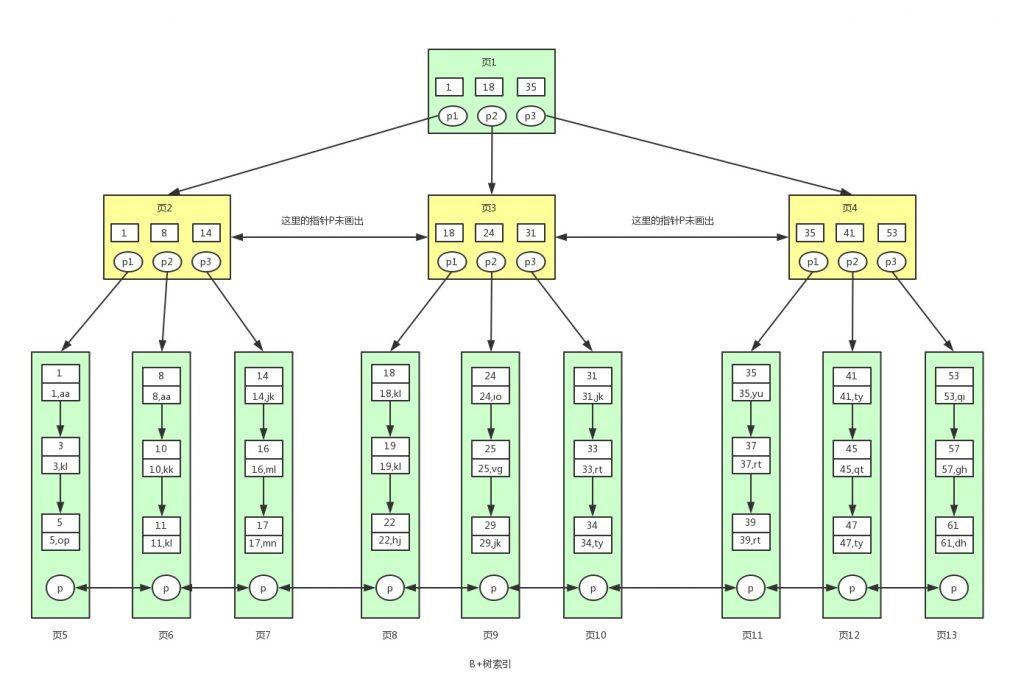
�ߡ�B+��
? ? �ݱ�:���������-��ƽ�������-��B��-��B+��
? ? 1 ������������ص�����κνڵ�����ӽڵ�ļ�ֵ��С�ڵ�ǰ�ڵ�ļ�ֵ,���ӽڵ�ļ�ֵ�����ڵ�ǰ�ڵ�ļ�ֵ��
? ? ���˵Ľڵ����dz�Ϊ���ڵ�,û���ӽڵ�Ľڵ����dz�֮ΪҶ�ڵ㡣
? ? ���������νṹ���ѯ���������ĸ߶��й�ϵ
? ? ȱ��:�����������һ������ʱ,���൱��ȫ��ɨ����
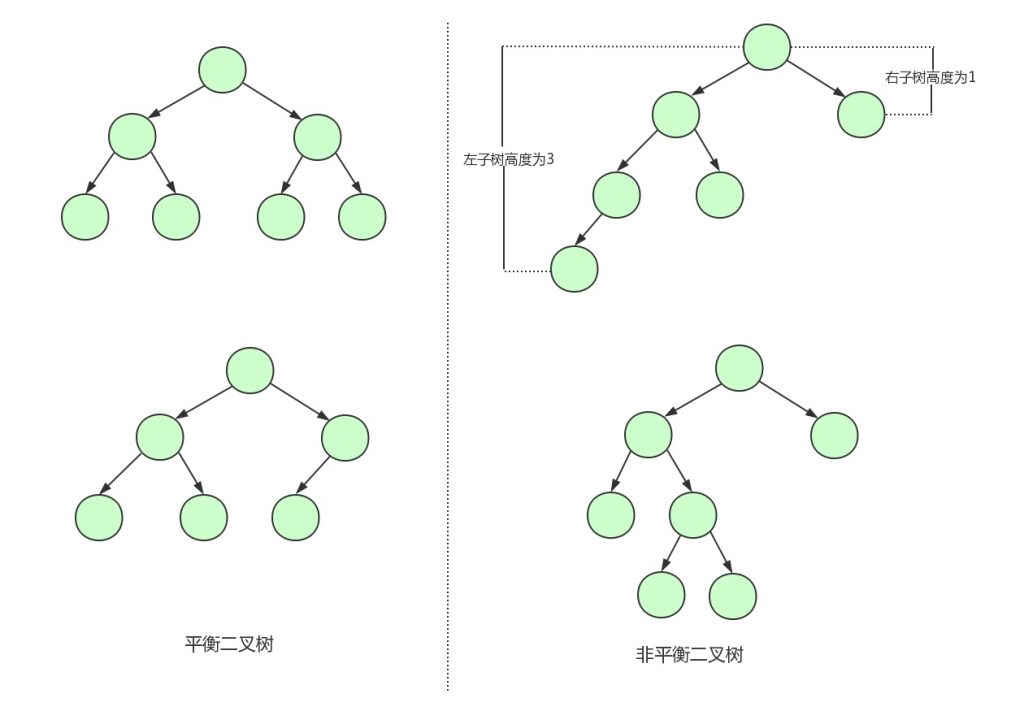
? ? ����취:������������ԭ����ʵ�Ƕ����������ò�ƽ����,Ҳ���Ǹ߶�̫����,�Ӷ����²���Ч�ʵIJ��ȶ��� Ϊ�˽���������,������Ҫ��֤���������һֱ����ƽ��,����Ҫ�õ�ƽ���������? ? 2 ƽ������� ƽ��������ֳ�AVL��,�����������������ԵĻ�����,Ҫ��ÿ���ڵ�����������ĸ߶Ȳ��ܳ���1
? ? ȱ��:ÿ���ڵ�ֻ����һ������
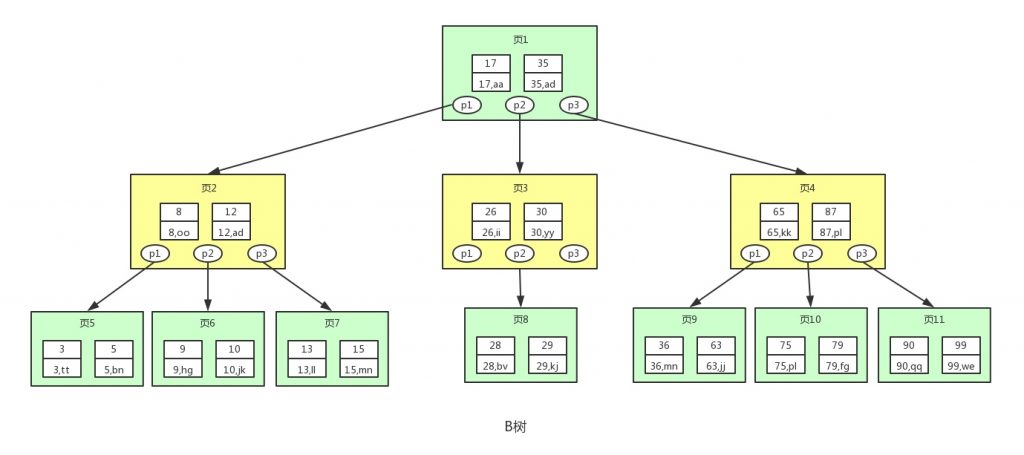
? ? ����취:��������ܹ���ƽ���������Ļ�����,�Ѹ���Ľڵ����һ�����̿���,��ôƽ��������ı�Ҳ�ͽ���ˡ�������һ�����ڵ���Դ洢�����ֵ�Ե�ƽ����,�����B����? ? 3 B�� B��(Balance Tree)��Ϊƽ��������˼,�ص�:һ�����̿�������ڵ�
? ? B�������ƽ�������,ÿ���ڵ�洢�˸���ļ�ֵ(key)������(data),����ÿ���ڵ�ӵ�и�����ӽڵ�,�ӽڵ�ĸ���һ���Ϊ��
? ? �����������,B���������ݶ�ȡ���̵Ĵ����������,���ݵIJ���Ч��Ҳ���ƽ��������ߺܶ�
? ? ps:���ڵ��dz�פ�ڴ��(���ڵ㲻��Ҫ��)
? ? ȱ��:B��ֻ�ó�����ֵ��ѯ,�����ڷ�Χ��ѯ(��Χ��ѯ�ı��ʾ���n�ε�ֵ��ѯ),����˵�������,B��Ҳ�ﲻ������? ? 4 B+�� B+���Ƕ�B���Ľ�һ���Ż�
? ? B+����B���ĶԱ�
? ? a B+����Ҷ�ӽڵ�non-leaf node���Dz��洢���ݵ�,���洢��,
? ? ��B���ķ�Ҷ�ӽڵ��в����洢��,Ҳ��洢���ݡ�B+��֮������ô������������:��һ���ڵ����һ��ҳ,�����ݿ���ҳ�Ĵ�С�ǹ̶���,innodb�洢����Ĭ��һҳΪ16KB,
? ? ������ҳ��С�̶���ǰ����,����һ��ҳ�з������Ľڵ�,��Ӧ�����Ľ���(�ڵ���ӽڵ���)�ͻ����,��ô���ĸ߶ȱ�Ȼ��������,���һ�����Dz������ݽ��д��̵�IO�����л��ٴμ���,���ݲ�ѯ��Ч��Ҳ����졣? ? b B+���Ľ����ǵ��ڼ���������
? ? ������ͼ,���ǵ�B+����ÿ���ڵ���Դ洢3����,3��B+������Դ洢3*3*3=9�����ݡ�
? ? ����������ǵ�B+��һ���ڵ���Դ洢1000����ֵ,��ô3��B+�����Դ洢1000��1000��1000=10�ڸ����ݡ���һ����ڵ��dz�פ�ڴ��,����һ�����Dz���10������,ֻ��Ҫ2�δ���IO,���nj�ը�����ơ�? ? c ��ΪB+���������������ݾ��洢��Ҷ�ӽڵ�leaf node,���������ǰ���˳�����еġ���ôB+��ʹ�÷�Χ����,�������,��������Լ�ȥ�ز��ұ���쳣����B����Ϊ���ݷ�ɢ�ڸ����ڵ�,Ҫʵ����һ���Ǻܲ����ġ�
����B+���и���ҳ֮��Ҳ��ͨ��˫���������ӵ�,Ҷ�ӽڵ��е�������ͨ�������������ӵġ���ʵ�����B������Ҳ���ԶԸ����ڵ������������ʵ��Щ��������֮ǰ������,����Ϊ��mysql��innodb�洢������,�������������洢�ġ�Ҳ����˵��ͼ�е�B+����������innodb��B+������������ʵ�ַ�ʽ,ȷ��˵Ӧ���Ǿۼ�������ps:��������ʱ,ibd�ļ����,����ѯЧ�������,����˵�������˷ѿռ任ʱ��
?
�ˡ�B+������
ibd�ļ��ڲ�ֻһ��B+��
��:
create index xx on user(id); ��idΪ��������һ��B+��
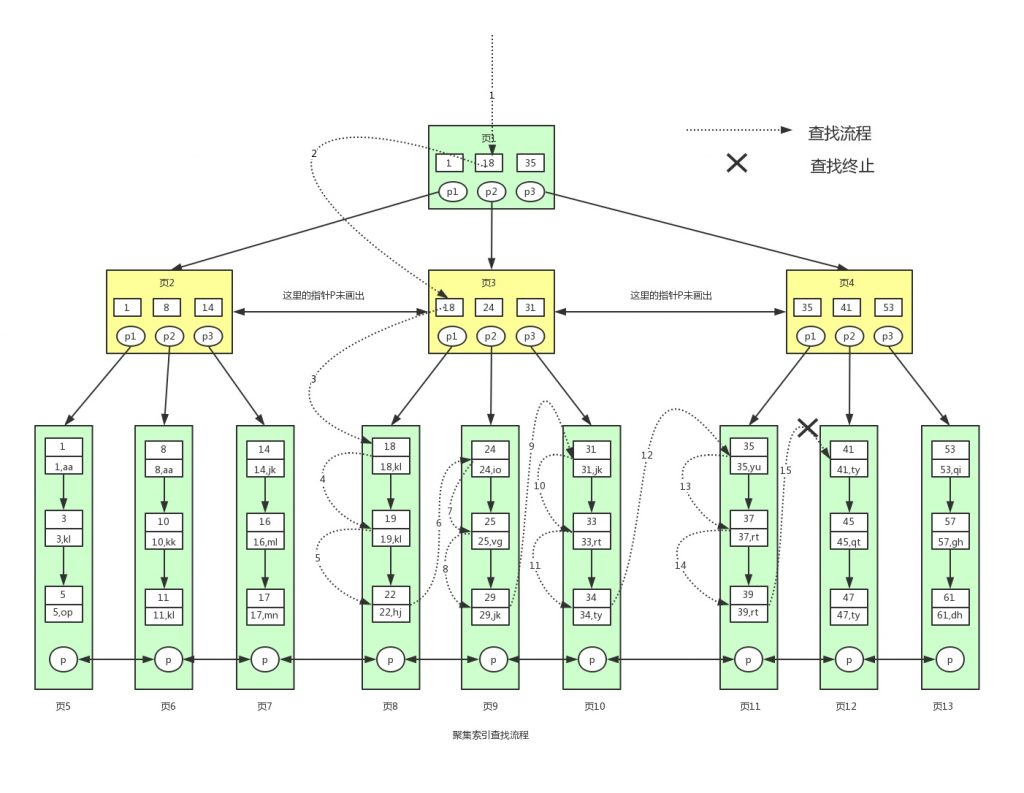
create index xx on user(name); ��nameΪ��������һ��B+����һ��:���ֽз�:�ۼ��������۴�����������������һ������
? ? ������Ϊkeyֵ������B+��,��B+����Ҷ�ӽڵ�ŵ�������ֵ�뱾�������ļ�¼,���е����ݶ��ۼ���Ҷ�ӽڵ���,���Գ�֮Ϊ�ۼ�����
? ? create index yy on user(id)
? ? select * from user where id='xx'���þۼ�������������
���濴�¾���IJ�������ͼ
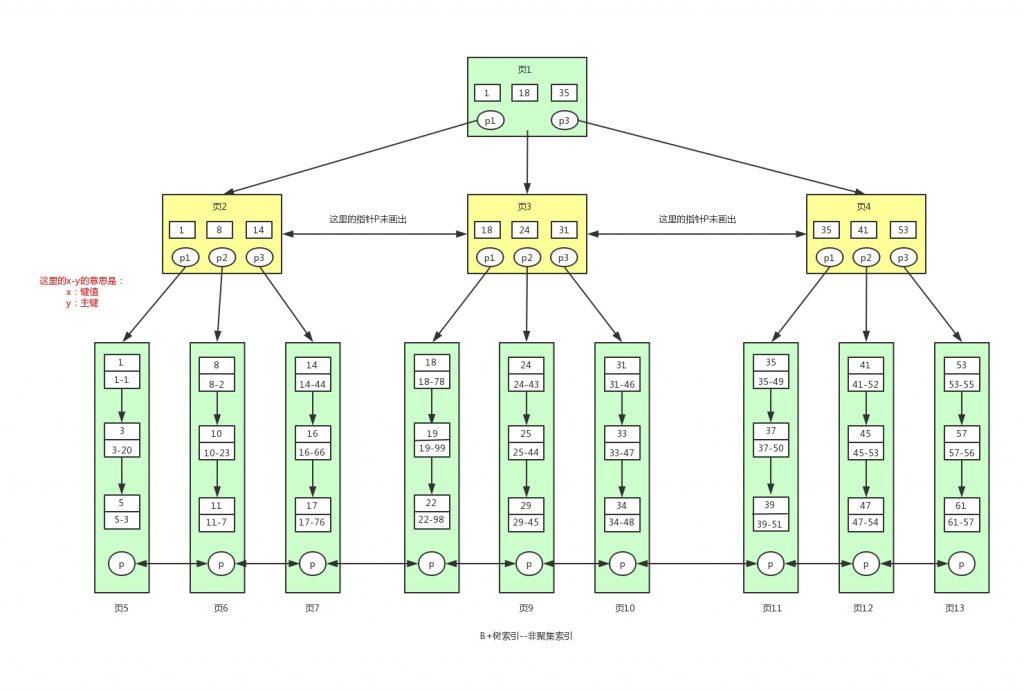
�ڶ���:���ֽз�:�Ǿۼ��������Ǿ۴�������������������������
? ? �Է�����ֵ����key������B+��,��B+����Ҷ�ӽڵ��ŵ���key�����Ӧ�������ֶ�ֵ
? ? create index yy on user(name)
? ? select * from user where name='xx'ps:1 innodb�洢����һ����һ������,��û��������,����ϵ����ҵ�һ����Ϊ����Ψһ���ֶε�����,��û���������ֶ�,�ᴴ��һ�������ֶ�Ϊkeyֵ����������
? ?2 һ��innodb�洢������б���Ҫ��ֻ����һ���ۼ�����,���ǿ����ж�������������÷Ǿۼ���������
���濴�¾���IJ�������ͼ:

�š��������������ر�����
����������:�����������Ļ�����,ֻ�ڱ���������Ҷ�ӽڵ���ҵ���������Ҫ������
? ? ����:��������-��id�ֶ�
? ? ? ? ?��������-��name�ֶ�? ? ? ? ?select name,id from user where name='egon'->id��name���ڸ�����������Ҷ�ӽڵ���
? ? ? ? ?selec * from user where id='2'->user�е��������ݶ�����idΪ����������B+����Ҷ�ӽڵ���
�ر�����:�������˸��������Ļ�����,�ڸ���������Ҷ�ӽڵ㲢û���ҵ���Ҫ������,��Ҫ�õ���Ӧ�������ֶ�ֵȥ�ۼ�������������һ��
? ? ����:��������-��id�ֶ�
? ? ? ? ?��������-��name�ֶ�? ? ? ? ?select name,age,gender from user where name='egon'->age��gender���ڸ���������Ҷ�ӽڵ�(name��name��Ӧ��idֵ)��
ʮ����������
�ۼ����� -primary key
�Ǿۼ����� -unique
? ? ? ? ?-indexcreate table t1(
? ? id int ,
? ? class_name varchar(20),
? ? name varchar(16),
? ? age int
)������������
alter table t1 add primary key t1(id)
ɾ�������ֶ�
alter table t1 drop primary key����Ψһ����
alter table t1 add unique key t1(class_name)
ɾ��Ψһ����
alter table t1 drop index t1������ͨ����
create index xx on t1(name)
ɾ����ͨ����
drop index xx on t1
?
ʮһ����������������ǰƥ��ԭ��
create index xx on t1(id,name) ��(id,name,age)����
�����������:
? ? id,name,age
? ? id,age
? ? id,name
? ? id
? ? �ҵIJ�ѯ�������漰����ֶ�ֵ,���������ֶ�ֵ�и�����,������ijһ���ֶ�ʱ(�������),���Խ���������