ʱ��ʹ���
һ��ʱ������
1. Flink �е�ʱ������
??����һ̨��������,��ʱ�䡱��Ȼ����ָϵͳʱ�䡣������֪��,Flink ��һ���ֲ�ʽ����ϵͳ���ֲ�ʽ�ܹ������ص�,���ǽڵ�˴˶���������Ӱ��,������˸��ߵ����������ݴ���;���������б�,��������Ҳ��Դ�ڴˡ�
??�ڷֲ�ʽϵͳ��,�ڵ㡰����Ϊ����,��û��ͳһʱ�ӵ�,���ݺͿ�����Ϣ��ͨ��������д��䡣����������һ�������Ǵ��ھۺ�,����ϣ����ÿ��Сʱ�������ռ���������ͳ�ƴ����������ڲ��еĴ���������,�������ڽڵ㲻ͬ,ϵͳʱ��Ҳ���в���;������ϣ��ͳ�� 8 ��
~9 �������ʱ,�Բ���������˵��ʵ�����ǡ�ͬʱ����,�ռ���������Ҳ������
??�Ǽ�Ȼһ����Ⱥ���� JobManager ��Ϊ������,�Dz�������ͳһ������ TaskManager ����ͬ��ʱ���źž�������?��Ҳ�Dz��еġ���Ϊ���紫������ӳ�,�������ӳ��Dz�ȷ����,���� JobManager ������ͬ���ź���ͬʱ�������нڵ�;��Ҫӵ��һ��ȫ��ͳһ��ʱ��,�ڷֲ�ʽϵͳ�����������ġ�
??��һ���鷳��������,����ʽ�����Ĺ�����,�������ڲ�ͬ�Ľڵ�䲻ͣ������,��ͬ��Ҳ�������紫����ӳ١�����һ��,��������������Ҫ��ڵ㴫������ʱ,���Ƕ��ڡ�ʱ�䡱 ������Ҳ��������ͬ������,���������� 8 �� 59 �� 59 �뷢��һ������,������Ҫ�����ڼ���ʱ�Ѿ��� 9 ���� 1 ����,���������ݵ��ò��ñ��յ� 8 ��~9 ��Ĵ�����?
??����,������ϣ�������ݰ���ʱ�䴰���������ռ�����ʱ,��ʱ�䡱������˭Ϊ���ͷdz���Ҫ�ˡ�
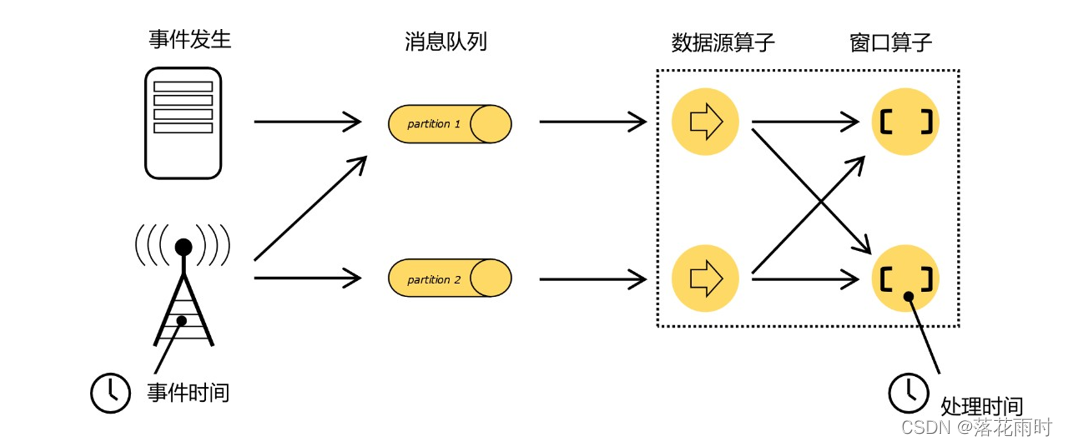
??������������һ����ʽ���ݴ����Ĺ��̡���ͼ��ʾ,���¼�����֮��,���ɵ����ݱ��ռ�����,���Ƚ���ֲ�ʽ��Ϣ����,Ȼ�� Flink ϵͳ�е� Source ���Ӷ�ȡ����,���������ε�ת������(��������)����,�����ɴ������ӽ��м��㴦����
??������,�����������dz���Ҫ��ʱ���:һ�������ݲ�����ʱ��,���ǰ����������¼�ʱ�䡱(Event Time);��һ��������������������ʱ��,����������ʱ�䡱(Processing Time)������������Ĵ��ڲ���,������������ʱ����Ϊ������,������ν�ġ�ʱ�����塱(Notions of Time)�����ڷֲ�ʽϵͳ�����紫����ӳٺ�ʱ��Ư��,����ʱ������¼�������ʱ��������ͺ�
1.1 ����ʱ��(Processing Time)
??����ʱ��ĸ���dz���,����ִָ�д��������Ļ�����ϵͳʱ�䡣
??�������������Ϊ������,��ô���������ĸ����ھͺ�������:ֻ��������������������ʱ,��ǰ��ϵͳʱ�䡣����֮ǰ�ٵ�����,���� 8 �� 59 �� 59 �����,�����ڼ���ʱ��ʱ
���� 9 ���� 1 ��,��ô�������ݾ����� 9 �㡪10 ��Ĵ���;������ݴ���dz���,9 ��֮ǰ�͵��˴�������,��ô�������� 8 �㡪9 ��Ĵ����ˡ�ÿ�����еĴ���������,��ֻ�����Լ���ϵͳʱ�ӻ��ִ��ڡ��������������� 8 �� 10 ���������г���,��ô������һֱ�� 9 ����ǰ��������������,�����ڵ�һ������;9 ��֮��10 ��֮ǰ���������ݾͽ����ڵڶ������ڡ�
??���ַ����dz��ֱ�,����Ҫ�����ڵ�֮�����Э��ͬ��,Ҳ����Ҫ�������������е�λ��,����˵���ǡ��ҵĵ������ҵġ������Դ���ʱ�������ʱ�����塣
1.2 �¼�ʱ��(Event Time)
??�¼�ʱ��,��ָÿ���¼��ڶ�Ӧ���豸�Ϸ�����ʱ��,Ҳ�����������ɵ�ʱ�䡣
����һ������,���ʱ����Ȼ��ȷ����,������������Ϊһ������Ƕ�뵽�����С�����ʵ�����������ݼ�¼�ġ�ʱ�����(Timestamp)��
??���¼�ʱ��������,���Ƕ���ʱ��ĺ���,�Ͳ����κλ�����ϵͳʱ����,�������������ݱ���������ȷ�,���൱����������ʱ���Լ�������û��ʱ�ӵ�,����ֻ����һ�����ݾ���һ�¡����ڼ����ˡ�;�����ݱ���Ҳû�б�,ֻ��һ���Դ��ġ�����ʱ�䡱,��������ͻ������ʱ����ȷ���Լ���ʱ�ӡ�������������������ԴԴ���ϲ�����,һ����˵,�Ȳ���������Ҳ���ȱ�����,���Ե�����ͣ�ؽӵ�����ʱ,���ǵ�ʱ���Ҳ�������Dz���������,�Ϳ��Դ���ʱ����ƽ���
??��Ȼ���ǻᷢ��,�����и�ǰ��,���ǡ��Ȳ����������ȱ�������,��Ҫ�����ǿ��Ա�֤���ݵ����˳�������ڷֲ�ʽϵͳ�����紫���ӳٵIJ�ȷ����,ʵ��Ӧ��������Ҫ��Ե�����������������ġ������������,�Ͳ��ܼذ������Դ���ʱ�������ʱ����,����Ҫ������ı�־����ʾ�¼�ʱ���չ,�� Flink �а��������¼�ʱ��ġ�ˮλ�ߡ�(Watermarks)������ˮλ�ߵĸ�����÷�,���ǻ��Ժ���ܡ�
1.3 ����ʱ������ĶԱ�
??ʵ��Ӧ����,���ݲ�����ʱ��ʹ�����ʱ���������ȫ��ͬ�ġ��ܳ�ʱ���ռ�����������, ��������ֻҪһ˲��;Ҳ�п�����������������������,��ʱ����˴������ݴ�������, ��������ѹ��(back pressure)��
??ͨ����˵,����ʱ�������Ǽ���Ч�ʵĺ�����,���¼�ʱ�����������ǵ�ҵ������������Ը���ʱ������ʹ���¼�ʱ��;��������ʱ��Ҳ����һ���Ǵ������ڴ���ʱ�����,����û���κθ��ӿ���,����һ����ֱ�Ӵ���,������ַ�ʽ���������ǵ��������ӳٽ������, Ч�ʴﵽ��ߡ�
��������ǰ���ᵽ��,�ڷֲ�ʽ������,����ʱ����ʵ�Dz�ȷ����,������������ʱ�Ӳ�ͳһ;�������������ӳ�,�������ݵ���������������ʱ���п�����,���ڴ��ڲ����Ϳ����ռ�������ȷ��������,���ݴ�����˳��Ҳ�ᱻ���ҡ���ͻ�Ӱ�쵽����������ȷ�ԡ����Դ���ʱ������,һ�����ڶ�ʵʱ��Ҫ�ߡ����Լ���ȷ��Ҫ��̫�ߵij�����
??�����¼�ʱ��������,ˮλ�߳�Ϊ��ʱ��,����ͳһ����ʱ��Ľ��ȡ���ͱ�֤�������ܿ��Խ����ݻ��ֵ���ȷ�Ĵ�����,���� 8 �� 59 �� 59 �����������,�������紫����ӳ��Ƕ���,����Զ���� 8 ��~9 ��Ĵ���,������֡�������֪�����ݻ������������,Ҫ���ô�����ȷ���ռ�����������,�ͱ������Щ���ҵ����ݶ�����,�����Ҫһ���ĵȴ�ʱ�䡣���������Ͽ�,�¼�ʱ����������һ���ӳ�Ϊ����,�����˴����������ȷ�ԡ����������ӳ�һ��ֻ�к��뼶,���Լ�ʹ���¼�ʱ������,ͬ��������ɵ��ӳ�ʵʱ������������
??����,�����¼�ʱ��ʹ���ʱ��,Flink ����һ��������ʱ�䡱(Ingestion Time)�ĸ���,����ָ���ݽ��� Flink ��������ʱ��,Ҳ���� Source ���Ӷ������ݵ�ʱ�䡣����ʱ���൱�����¼�ʱ��ʹ���ʱ���һ���к�,���ǰ� Source ����Ĵ���ʱ��,���������ݵIJ���ʱ�����ӵ����������һ��,ˮλ��(watermark)Ҳ�ͻ������ʱ��ֱ������,����Ҫ����ָ���ˡ�����ʱ��������Ա�֤�ȽϺõ���ȷ��,ͬʱ�ֲ�������̫����ӳ١����ľ�����Ϊ���¼�ʱ��dz���,���Ե���������¼�ʱ����������
�� Flink ��,���ڴ���ʱ��Ƚϼ�,���ڰ汾Ĭ�ϵ�ʱ�������Ǵ���ʱ��;�����ǵ��¼�ʱ����ʵ��Ӧ���и�Ϊ�㷺,�� 1.12 �汾��ʼ,Flink �Ѿ����¼�ʱ����Ϊ��Ĭ�ϵ�ʱ�����塣
����ˮλ��(Watermark)
1. ʲô��ˮλ��
??���¼�ʱ��������,���Dz�����ϵͳʱ��,���ǻ��������Դ���ʱ���ȥ������һ��ʱ��, ������ʾ��ǰʱ��Ľ�չ������ÿ��������������һ���Լ�����ʱ��,����ǰ���ǿ����ݵ�ʱ����������ġ�
??���ڷֲ�ʽϵͳ��,����������ʽ�ֻ���һЩ���⡣��Ϊ���ݱ����ڴ���ת���Ĺ����л�仯,����������ھۺ������IJ���,��ʵ��Ҫ��һ�����ݲŻ����һ�����,��ô���ε����ݾͻ����,ʱ����ȵĿ��ƾͲ�����ϸ�ˡ�����,��������������ʱ,һ��ֻ�ܴ����һ��������(���㲥��),���������IJ����������ʱ�Ӿ����ƽ��ˡ�����һ��ʱ���Ϊ 9���������ݵ���,��ǰ�����ʱ�Ӿ��Ѿ��� 9 ����;�����굱ǰ����Ҫ���͵�����,�������������һ�����ڼ���,���ж�Ϊ 3,��ô���յ�������ݵ�������,ʱ��Ҳ���չ�� 9 ��,9 ������Ĵ��ھͿ��Թرս��м�����;����������������������ʱ��û�б仯,���ܽ��д��ڼ��㡣
??��������Ӧ�ð�ʱ��Ҳ�����ݵ���ʽ���ݳ�ȥ,������������ǰʱ��Ľ�չ;�������ʱ�ӵĴ��ݲ�����Ϊ���ھۺ�֮��������ͣ�͡�һ�ּ��뷨��,���������м���һ��ʱ�ӱ��,��¼��ǰ���¼�ʱ��;�����ǿ���ֱ�ӹ㲥������,�����������յ�������,�Ϳ��Ը����Լ���ʱ���ˡ�����������ˮ������������־�ļǺ�,�� Flink ��,�������������¼�ʱ��(Event Time)��չ�ı��,�ͱ�������ˮλ�ߡ�(Watermark)��
??����ʵ����,ˮλ�߿��Կ���һ����������ݼ�¼,���Dz��뵽�������е�һ����ǵ�, ��Ҫ���ݾ���һ��ʱ���,����ָʾ��ǰ���¼�ʱ�䡣�����������е�λ��,��Ӧ������ij�����ݵ���֮��;�����Ϳ��Դ������������ȡʱ���,��Ϊ��ǰˮλ�ߵ�ʱ����ˡ�

??��ͼ��ʾ,ÿ���¼�����������,��������һ��ʱ���,����ֱ����һ��������ʾ������û��ָ����λ,��������Ϊ����ߺ���(�������,���潲��ͳһ��Ϊ����)����������2 ������ݵ���֮��,��ǰ���¼�ʱ����� 2 ��;�ں������һ��ʱ���ҲΪ 2 ���ˮλ��,
??��������һ������������������ 5 ����������ݵ���֮��,ͬ���ں������һ��ˮλ��,ʱ���ҲΪ 5,��ǰ��ʱ�Ӿ��ƽ����� 5 �롣����,������������ж�����������������,����ֻҪ��ˮλ�߹㲥��ȥ,�Ϳ���֪ͨ��������������ǰ��ʱ������ˡ�
??ˮλ�߾������������������,���������е�һ����,��������һ������,�ڲ�ͬ����֮�䴫�䡣�⿴�����dz���;���������Ǿͽ�һ��̽��һЩ���ӵ�״����
1.1 �������е�ˮλ��
??������״̬��,����Ӧ�ð����������ɵ��Ⱥ�˳���źöӽ�������;Ҳ����˵,���Ǵ����Ĺ��̻ᱣ��ԭ�ȵ�˳��,����������ԭ�������Ļ����Ǵ�ÿ����������ȡʱ���,�Ϳ��Ա�֤���Ǵ�С����������,�Ӷ������ˮλ��Ҳ����������¼�ʱ�Ӳ�����ǰ�ƽ���
??ʵ��Ӧ����,�����ǰ�������dz���,���ܻ��кܶ����ݵ�ʱ�������ͬ��,��ʱÿ��һ�����ݾ���ȡʱ���������ˮλ�߾����˴��������ù������Ҽ�ʹʱ�����ͬ,ͬʱӿ��������ʱ����dz�С(���缸����),�����Դ�������ҲûʲôӰ�졣����Ϊ�����Ч��,һ���ÿ��һ��ʱ������һ��ˮλ��,���ˮλ�ߵ�ʱ���,���ǵ�ǰ�������ݵ�ʱ���,��ͼ��ʾ��������ʱ��ˮλ��,��ʵ�����������е�һ�������Գ��ֵ�ʱ���ǡ�

??������Ҫע�����,ˮλ�߲���ġ����ڡ�,����Ҳ��һ��ʱ�����ڵ�ǰ�¼�ʱ��������,���������趨��ÿ�� 100ms ����һ��ˮλ��,�Ǿ���Ҫ���¼�ʱ���ƽ� 100ms ���ܲ���;�����¼�ʱ�ӱ����Ľ�չ,�������ǿ�ˮλ������ʾ�ġ�������Ҫ����һ��ˮλ��,��ǰ������ˮλ��Ҫ��ǰ�ƽ� 100ms,�����������ѭ�������Զ���ˮλ�ߵ�����������,����ʱ����ָ����ʱ��(ϵͳʱ��),�������¼�ʱ�䡣
1.2 �������е�ˮλ��
??�������Ĵ����dz���,������ˮλ��Ҳ��û����̫������á����������ֻ����������״̬�¡�����֪���ڷֲ�ʽϵͳ��,�����ڽڵ�䴫��,����Ϊ���紫���ӳٵIJ�ȷ����, ����˳�����ı�,�������ν�ġ��������ݡ���
??������˵�ġ�����(out-of-order),��ָ���ݵ��Ⱥ�˳��һ��,��Ҫ���ǻ������ݵIJ���ʱ����Եġ���ͼ��ʾ,һ�� 7 ��ʱ����������,����ʱ����ȻҪ�� 9 ���������;���Ǿ������ݻ���ʹ���֮��,��������������յ��� 9 �������,֮�� 7 ������ݲ������١���ʱ�������ϣ������ˮλ��,��ָʾ��ǰ���¼�ʱ���չ,�ָ���ô����?

��ֱ�۵��뷨��Ȼ�Ǹ�֮ǰһ��,���ǻ��ǿ�����������,ÿ��һ�����ݾ���ȡ����ʱ���������һ��??ˮλ�ߡ��������ڵ��������������,�����п����µ�ʱ�����֮ǰ�Ļ�С,���ֱ�ӽ����ʱ���ˮλ���ٲ���,���ǵġ�ʱ�ӡ��ͻ����ˡ���ˮλ�߾ʹ�����ʱ��,ʱ�ⲻ�ܵ���,����ˮλ�ߵ�ʱ���Ҳ���ܼ�С��
??���˼·Ҳ�ܼ�:���Dz����µ�ˮλ��ʱ,Ҫ���ж�һ��ʱ����Ƿ��֮ǰ�Ĵ�,����Ͳ��������µ�ˮλ��,��ͼ��ʾ��Ҳ����˵,ֻ�����ݵ�ʱ����ȵ�ǰʱ�Ӵ�,�����ƶ�ʱ��ǰ��,��ʱ�Ų���ˮλ�ߡ�

??������ǵ���������ͬʱ�����Ĵ���Ч��,����ͬ������������������ˮλ�ߡ���ʱֻ��Ҫ����һ��֮ǰ���������е����ʱ���,��Ҫ����ˮλ��ʱ,��ֱ��������Ϊʱ��������µ�ˮλ��,��ͼ��ʾ��

??���������ܿ��Զ����һ���¼�ʱ��,ȴҲ�����һ���dz��������:��������ȷ�������ٵ��������ݡ��������������,�� 9 ����������ݵ���֮��,���Ǿ�ֱ�ӽ�ʱ���ƽ�����9 ��;�����һ�����ڽ���ʱ����� 9 ��(����,Ҫͳ�� 0~9 �����������),��ô��ʱ���ھ�Ӧ�ùرա����ռ������������ݼ����������ˡ�����ʵ��,���������������,��������ʱ���Ϊ 7 �롢8 ��������� 9 �������֮��ŵ���,����ǡ��ٵ����ݡ�(late data)�����DZ���ҲӦ������ 0~9 ���������,����ʱ�����Ѿ��ر�,������Щ���ݾͱ���©��,��ᵼ��ͳ�ƽ������ȷ��
??Ϊ���ô����ܹ���ȷ�ռ����ٵ�������,����Ҳ���Ե��� 2 ��;Ҳ����
�õ�ǰ�������ݵ����ʱ�����ȥ 2 ��,����Ҫ�����ˮλ�ߵ�ʱ���,��ͼ 6-10 ��ʾ����
���Ļ�,9 ������ݵ���֮��,�¼�ʱ�Ӳ���ֱ���ƽ��� 9 ��,���ǽ�չ���� 7 ��;����ȵ�
11 ������ݵ���֮��,�¼�ʱ�ӲŻ��չ�� 9 ��,��ʱ�ٵ�����Ҳ�����ռ���,0~9 ��Ĵ��ھͿ�����ȷ�������ˡ�

??�����ϸ�۲�ͻῴ��,���֡��� 2 �롱�IJ�����ʵ�����ܴ������е��������ݡ�����
22 ������ݵ���֮��,�����ˮλ��ʱ���Ϊ 20,Ҳ���ǵ�ǰʱ���Ѿ��ƽ����� 20 ��;����
10~20 ��Ĵ���,��ʱ�ùر��ˡ�����֮���ֻ��� 17 ��ijٵ����ݵ���,������Ӧ������10~20�봰��,����ȴ����©�����ˡ����ָ���ô����?
??��Ȼ���ڵ� 2 �뻹�ǵȲ��� 17 ������ijٵ�����,����Ȼ���ǿ������Ŷ�ȼ���,Ҳ���ǰ�ʱ�ӵ��ø���һЩ�����յ�Ŀ��,����Ҫ�ô����ܹ������гٵ����ݶ��ս���,�õ���ȷ�ļ���������Ӧ��ˮλ����,��ʵ����Ҫ��֤,��ǰʱ���Ѿ���չ�������ʱ���,����֮�������гٵ��������ˡ�
������һ��ʾ��,���ǿ���ʹ�������Եķ�ʽ������ȷ��ˮλ�ߡ�

??��ͼ��ʾ,��һ��ˮλ��ʱ���Ϊ 7,����ʾ��ǰ�¼�ʱ���� 7 ��,7 ��֮ǰ�����ݶ��Ѿ�����,֮����Ҳ��������;ͬ��,�ڶ�����������ˮλ��ʱ����ֱ�Ϊ 12 �� 20,��ʾ11 �롢20 ��֮ǰ�����ݶ��Ѿ�����,����ж�Ӧ�Ĵ��ھͿ���ֱ�ӹر���,ͳ�ƵĽ��һ������ȷ�ġ���������ˮλ�������������ɵ�,���Բ����λ�ò�һ������ʱ����������ݺ��档
??������Ҫע�����,����һ���������ռ�������,������֮ǰ�����Ѿ���������ݡ���Ϊ���������ĸ�����,�������ݱ�����ʱ���������,һ������ֻ���ռ���������������Щ���ݡ�Ҳ����˵,��ͼ�о���ˮλ�� W(20)֮ǰ��ʱ���Ϊ 22 �����ݵ���,10~20 ��Ĵ�����Ҳ�����ռ��������,���м�����Ȼ���Եõ���ȷ�Ľ�������ڴ��ڵ�ԭ��,���ǻ��ں������չ�����⡣
1.3 ˮλ�ߵ�����
??�������ǿ���֪��,ˮλ�߾ʹ����˵�ǰ���¼�ʱ��ʱ��,���ҿ��������ݵ�ʱ��������ϼ�һЩ�ӳ�����֤��������,��һ���������������ȷ�����dz���Ҫ��
���ǿ����ܽ�һ��ˮλ�ߵ�����:
- ˮλ���Dz��뵽�������е�һ�����,������Ϊ��һ�����������
- ˮλ����Ҫ��������һ��ʱ���,������ʾ��ǰ�¼�ʱ��Ľ�չ
- ˮλ���ǻ������ݵ�ʱ������ɵ�
- ˮλ�ߵ�ʱ������뵥������,��ȷ��������¼�ʱ��ʱ��һֱ��ǰ�ƽ�
- ˮλ�߿���ͨ�������ӳ�,����֤��ȷ������������
- һ��ˮλ�� Watermark(t),��ʾ�ڵ�ǰ�����¼�ʱ���Ѿ��ﵽ��ʱ��� t, ����� t ֮ǰ���������ݶ�������,֮�����в������ʱ��� t�� �� t ������
??ˮλ���� Flink �������б�֤�����ȷ�Եĺ��Ļ���,�������������һ�����,��ɶ��������ݵ���ȷ�����������ⲿ������,���ǻ��Ժ��һ��չ�����⡣
2. �������ˮλ��
2.1 ����ˮλ�ߵ�����ԭ��
??Flink �е�ˮλ��,��ʵ���������жԵ��ӳٺͽ����ȷ�Ե�һ��Ȩ�����,���Ұѿ��Ƶ�Ȩ�������˳���Ա,���ǿ����ڴ����ж���ˮλ�ߵ����ɲ��ԡ�
2.2 ˮλ�����ɲ���(Watermark Strategies)
??�� Flink �� DataStream API �� , �� һ �� �� �� �� �� �� �� ˮ λ �� �� ����:.assignTimestampsAndWatermarks(),����Ҫ����Ϊ���е����ݷ���ʱ���,������ˮλ����ָʾ�¼�ʱ��:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(WatermarkStrategy<T> watermarkStrategy)
����ʹ��ʱ,ֱ����DataStream ���ø÷�������,����ͨ�� transform ������ȫһ����
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(<watermark strategy>);
??����������ɻ�:����˵�������Ѿ���ʱ�������,Ϊʲô���ﻹҪ�����䡱��?������Ϊԭʼ��ʱ���ֻ��д����־���ݵ�һ���ֶ�,�������ȡ��������ȷ�������������, Flink ����֪����������������ʱ��ġ���Ȼ,��Щʱ������Դ�������ṩ��ʱ�����Ϣ, �����ȡKafka ʱ,���ǾͿ��Դ� Kafka ������ֱ�ӻ�ȡʱ���,������Ҫ������ȡ�ֶη����ˡ�
??.assignTimestampsAndWatermarks()������Ҫ����һ�� WatermarkStrategy��Ϊ����,����� �� ν �� ��** ˮ λ �� �� �� �� ��** �� �� WatermarkStrategy �� �� �� �� һ �� �� ʱ�����������TimestampAssigner ��һ����ˮλ����������WatermarkGenerator��
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>,WatermarkGeneratorSupplier<T>{
@Override TimestampAssigner<T>
createTimestampAssigner(TimestampAssignerSupplier.Context context);
@Override WatermarkGenerator<T>
createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
TimestampAssigner:��Ҫ�������������Ԫ�ص�ij���ֶ�����ȡʱ���,�������Ԫ�ء�ʱ����ķ���������ˮλ�ߵĻ�����WatermarkGenerator: ��Ҫ�����ռȶ��ķ�ʽ, ����ʱ�������ˮλ�ߡ���WatermarkGenerator �ӿ���,��Ҫ������������:onEvent()�� onPeriodicEmit()��onEvent:ÿ���¼�(����)����������õķ���,���IJ����е�ǰ�¼���ʱ���, �Լ���������ˮλ�ߵ�һ�� WatermarkOutput,���Ի����¼������ֲ���onPeriodicEmit:�����Ե����ķ���,������ WatermarkOutput ����ˮλ�ߡ�����ʱ��Ϊ����ʱ��,���Ե��û������õ�.setAutoWatermarkInterval()����������,Ĭ��Ϊ200ms��
2.3 Flink ����ˮλ��������
??WatermarkStrategy����ӿ���һ������ˮλ�߲��Եij���,�����ǿ�������ʵ���Լ�������;����������Щ����,�����Ҫ�Լ�ʵ��Ӧ�û��DZȽ��鷳�ġ����� Flink ��ֿ��ǵ������ǵ�ʹ��,�ṩ�����õ�ˮλ��������(WatermarkGenerator),�������伴�ü��˱��,����ҲΪ�����Զ���ˮλ�߲����ṩ��ģ�塣
??����������������ͨ������ WatermarkStrategy �ľ�̬�������������������Ƕ�������������ˮλ�ߵ�,�ֱ��Ӧ�Ŵ������������������ij�����
(1) ������
??����������,��Ҫ�ص����ʱ�����������(Monotonously Increasing Timestamps),������Զ������ֳٵ����ݵ����⡣��������������ˮλ�ߵ���ij���, ֱ�ӵ���WatermarkStrategy.forMonotonousTimestamps()�����Ϳ���ʵ�֡�����˵,����ֱ���õ�ǰ����ʱ�����Ϊˮλ�߾Ϳ����ˡ�
stream.assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>(){
@Override
public long extractTimestamp(Event element, long recordTimestamp){
return element.timestamp;
}
})
);
??������������ǵ���.withTimestampAssigner()����,�������е� timestamp �ֶ���ȡ����, ��Ϊʱ������������Ԫ��;Ȼ�������õ�������ˮλ������������������ɲ��ԡ�����,��ȡ��������ʱ���,�������Ǵ���������¼�ʱ�䡣
&mesp;?������Ҫע�����,ʱ�����ˮλ�ߵĵ�λ,���붼��������
(2) ������
??��������������Ҫ�ȴ��ٵ����ݵ���,���Ա�������һ���̶������ӳ�ʱ��( Fixed Amount of Lateness)����ʱ����ˮλ�ߵ�ʱ���,���ǵ�ǰ������������ʱ�����ȥ�ӳٵĽ��,�൱�ڰѱ�����,��ǰʱ�ӻ��ͺ������ݵ����ʱ��������� WatermarkStrategy. forBoundedOutOfOrderness()�����Ϳ���ʵ�֡����������Ҫ����һ�� maxOutOfOrderness ����,��ʾ���������̶ȡ�,����ʾ����������������ʱ���������ֵ;���������ȷ������̶�,��ô���ö�Ӧʱ�䳤�ȵ��ӳ�,�Ϳ��Եȵ����е����������ˡ�
// ������Դ��Ϊsocket�ı���,��ת����Event����
env.socketTextStream("localhost", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
})
// ����ˮλ�ߵ���
.assignTimestampsAndWatermarks(
// �������������ˮλ��,�ӳ�ʱ������Ϊ5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// ��ȡʱ�������
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
)
??���������,����ͬ����ȡ�� timestamp �ֶ���Ϊʱ���,������ 5 ����ӳ�ʱ�䴴����
������������ˮλ����������
??��ʵ��,��������ˮλ�������������Ϻ���������һ����,�൱���ӳ���Ϊ 0 ��������ˮλ��������,������ȫ��ͬ:
WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(0))
??������Ҫע�����,�����������ɵ�ˮλ��������ʱ���,��ʵ�� ��ǰ���ʱ��� �C �ӳ�ʱ�� �C 1,����ĵ�λ�Ǻ��롣ΪʲôҪ�� 1 ������?���ǿ��Ի���һ��ˮλ�ߵ��ص�:ʱ���Ϊ t ��ˮλ��,��ʾʱ�����t ������ȫ������,���������ˡ��������������,Ҳ�����ӳ�ʱ��Ϊ 0 �����,��ôʱ���Ϊ 7 ������ݵ���ʱ,֮����ʵ�ǻ��п��ܼ����� 7 ������ݵ�;�������ɵ�ˮλ�߲��� 7 ��,���� 6 �� 999 ����,7 ������ݻ����Լ���������һ�������BoundedOutOfOrdernessWatermarks ��Դ�������Եؿ���:
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
2.4 �Զ���ˮλ�߲���
??һ����˵,Flink ���õ�ˮλ���������Ϳ�������Ӧ�������ˡ�������ʱ���ǵ�ҵ�������ܷdz�����,��ʱ��ˮλ�����ɵ���Ҳ�и��ߵ�Ҫ��,���Ǿͱ����Զ���ʵ��ˮλ�߲���WatermarkStrategy �ˡ�
??�� WatermarkStrategy ��,ʱ��������� TimestampAssigner ���Ǵ�ͬС���,ָ���ֶ���ȡʱ����Ϳ�����;����ͬ���ԵĹؼ������� WatermarkGenerator��ʵ�֡�����˵��,Flink �����ֲ�ͬ������ˮλ�ߵķ�ʽ:һ������������(Periodic),��һ�����ϵ�ʽ��(Punctuated)�����ǵ� WatermarkGenerator �ӿ��е�����������?����onEvent()�� onPeriodicEmit(),ǰ������ÿ���¼�����ʱ����,�������ɿ�������Ե����������Ե��õķ����з���ˮλ��,��Ȼ��������������ˮλ��;�����¼������ķ����з���ˮλ��,��Ȼ���Ƕϵ�ʽ�����ˡ����ַ�ʽ�IJ�ͬ�ͼ���������������������ʵ���ϡ�
(1)������ˮλ��������(Periodic Generator)
??������������һ����ͨ�� onEvent()�۲��ж�������¼�,���� onPeriodicEmit()���ˮλ�ߡ�
������һ���Զ�������������ˮλ�ߵĴ���:
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// �Զ���ˮλ�ߵIJ���
public class CustomWatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.addSource(new ClickSource())
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp; // ���߳�������Դ���ʱ�������һ���ֶ�
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // �ӳ�ʱ��
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // �۲쵽�����ʱ���
@Override
public void onEvent(Event event, long eventTimestamp, WatermarkOutput output) {
// ÿ��һ�����ݾ͵���һ��
maxTs = Math.max(event.timestamp, maxTs); // �������ʱ���
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// ����ˮλ��,Ĭ��200ms����һ��
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
}
??������ onPeriodicEmit()����� output.emitWatermark(),�Ϳ��Է���ˮλ����;���������ϵͳ��������Եص���,Ĭ��200msһ�Ρ�����ˮλ�ߵ�ʱ�����������ǰ�������ݵ����ʱ�����(�����ʵ������������������,Ҳ�Ǽ�ȥ�ӳ�ʱ���ټ� 1),������ʲôʱ�������������ء�
(2)�ϵ�ʽˮλ��������(Punctuated Generator)
??�ϵ�ʽ�������ͣ�ؼ�� onEvent()�е��¼�,�����ִ���ˮλ����Ϣ�������¼�ʱ, ����������ˮλ�ߡ�һ����˵,�ϵ�ʽ����������ͨ�� onPeriodicEmit()����ˮλ�ߡ�
�Զ���Ķϵ�ʽˮλ����������������:
public class CustomPunctuatedGenerator implements WatermarkGenerator<Event> {
@Override
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// ֻ���������ض��� itemId ʱ,�ŷ���ˮλ��
if (r.user.equals("Mary")) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// ����Ҫ���κ�����,��Ϊ������ onEvent �����з�����ˮλ��
}
}
??������onEvent()���жϵ�ǰ�¼��� user �ֶ�,ֻ��������Mary����������ֵʱ,�ŵ���output.emitWatermark()����ˮλ�ߡ������������ȫ�����¼���������,����ˮλ�ߵ�����һ����ij�����ݵ���֮��
2.5 ���Զ�������Դ�з���ˮλ��
??����Ҳ�������Զ��������Դ�г�ȡ�¼�ʱ��,Ȼ����ˮλ�ߡ�����Ҫע�����,���Զ�������Դ�з�����ˮλ���Ժ�,�Ͳ������ڳ�����ʹ�� assignTimestampsAndWatermarks���� �� �� �� ˮ λ �� �� �� ���Զ�������Դ������ˮλ�ߺ��ڳ�����ʹ��assignTimestampsAndWatermarks ��������ˮλ�߶���ֻ��ȡ��һ��ʾ����������:
import com.atguigu.chapter05.Event;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import java.util.Calendar;
import java.util.Random;
public class EmitWatermarkInSourceFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSourceWithWatermark()).print();
env.execute();
}
// ����������Դ�е�����
public static class ClickSourceWithWatermark implements SourceFunction<Event> {
private boolean running = true;
@Override
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random();
String[] userArr = {"Mary", "Bob", "Alice"};
String[] urlArr = {"./home", "./cart", "./prod?id=1"};
while (running) {
long currTs = Calendar.getInstance().getTimeInMillis(); // ����ʱ���
String username = userArr[random.nextInt(userArr.length)];
String url = urlArr[random.nextInt(urlArr.length)];
Event event = new Event(username, url, currTs);
// ʹ��collectWithTimestamp���������ݷ��ͳ�ȥ,��ָ�������е�ʱ������ֶ�
sourceContext.collectWithTimestamp(event, event.timestamp);
// ����ˮλ��
sourceContext.emitWatermark(new Watermark(event.timestamp - 1L));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
}
??���Զ���ˮλ��������ˮλ����� assignTimestampsAndWatermarks �����������,��������IJ��������Եġ��������Ե�ˮλ��,�Լ�ˮλ�ߵĴ�СҲ��ȫ�������Զ��塣���Էdz��ʺ�������д Flink �IJ��Գ���,���� Flink �ĸ��ָ��������ԡ�
3. ˮλ�ߵĴ���
??����֪��ˮλ�����������в����һ�����,������ʾ�¼�ʱ��Ľ�չ,������������һ��������䴫�ݡ����ֻ��ֱͨʽ(forward)�Ĵ���,�Ǻܼ�,���ݺ�ˮλ�߶��ǰ��ձ�����˳�����δ��ݡ����δ�����;һ��ˮλ�ߵ�������������, ��ô�������ͻὫ���ڲ���ʱ����Ϊ���ˮλ�ߵ�ʱ�����
??������,�������ʱ�ӡ���ʵ��Ȼ�Ǹ���Ϊ����,��û��ͳһ��ʱ�ӡ�ʵ��Ӧ�������������ζ��ж������������,Ϊ��ͳһ�ƽ��¼�ʱ��Ľ�չ,����Ҫ��������������ˮλ�ߡ�ʱ�Ӹı�֮��,Ҫ�ѵ�ǰ��ˮλ���ٴη���,�㲥�����е���������������,��������Ͳ���Ҫ����ԭʼ�����е�ʱ���(����ת��������,���ݿ����Ѿ��ı���),Ҳ����֪����ǰ�¼�ʱ���ˡ�
??���ǻ�������һ������,�Ǿ����ڡ��ط�����(redistributing)�Ĵ���ģʽ��,һ�������п��ܻ��յ����Բ�ͬ������������������ݡ�����ͬ������������ʱ�Ӳ���ͬ��,����ͬһʱ�̷������������ˮλ�߿��ܲ�����ͬ����ʱ���������ָ���˭����?
??���Ҫ�ص�ˮλ�߶���ı�����:����ʾ���ǡ���ǰʱ��֮ǰ������,���Ѿ������ˡ�������һ�ֱ�֤,������������ֻҪ��ӵ����ˮλ��,�ʹ���֮���Ҳ����ٸ��㷢�����������,����Է�����ͳ�Ƽ����������©���ݡ����������һ�������յ����������β�������IJ�ͬ��ˮλ��,˵�����θ��������������п�����,���ȸ�����ͬ����������������������������ˮλ��,һ���� 5 ��,һ���� 7 ��;�������һ�����������Ѿ������� 5 ��֮ǰ����������,���ڶ����������������� 7 �롣����ʱ�Լ���ʱ����ôȷ����?��ȻҲҪ�ԡ���֮ǰ������ȫ�����롱Ϊ������������Խϴ��ˮλ�� 7 ����Ϊ��ǰʱ��,�Ǿͱ�ʾ��7 ��ǰ�����ݶ��Ѿ������ꡱ,����Ȼ������ʵ������һ�����η����Ŵ����� 5 ��,5~7 ������ݻ��ͣ�ط���;���������С��ˮλ�� 5 ����Ϊ��ǰʱ�ӾͲ��������������,��Ϊȷʵ�������η������Ѿ�������,�����ٷ� 5 ��ǰ�������ˡ����������뵽��ľͰԭ����:���е����β����������Χ��ľͰ��һ���ľ��,��������̵���һ��,����������Ͱ�е�ˮλ��

??���ǿ�����һ�����������,��ˮλ��������䴫�ݵĹ�����������һ�顣��ͼ 6-12 ��ʾ,��ǰ���������,���ĸ�����������,���Ի���յ������ĸ�������ˮλ��;����������������������,���Ի���������������ˮλ�ߡ������������:
(1) ���β�������������ͬ��ˮλ��,��ǰ�����Ϊÿһ����������һ��������ˮλ�ߡ�
(Partition Watermark),����һ������ʱ��;����ǰ�����Լ���ʱ��,�������з���ʱ������С���Ǹ���
(2) ����һ���µ�ˮλ��(��һ������ 4)�����δ���ʱ,��ǰ��������ȸ��¶�Ӧ�ķ���ʱ��;Ȼ���ٴ��ж����з���ʱ���е���Сֵ,�����֮ǰ��,˵���¼�ʱ�����˽�չ,��ǰ�����ʱ��Ҳ�Ϳ��Ը����ˡ�����Ҫע��,���º������ʱ��,����һ�����������Ǹ�����ˮλ��,��������ı���ǵ�һ������ʱ��,����С�ķ���ʱ���ǵ��������� 3,���ǵ�ǰ����ʱ�Ӿ��ƽ����� 3����ʱ���н�չʱ,��ǰ����ͻὫ�Լ���ʱ����ˮλ�ߵ���ʽ,�㲥����������������
(3) �ٴ��յ��µ�ˮλ��(�ڶ������� 7)��,ִ��ͬ���Ĵ������̡����Ƚ��ڶ�������ʱ�Ӹ���Ϊ 7,Ȼ��Ƚ����з���ʱ��;������Сֵû�б仯,��ô��ǰ�����ʱ��Ҳ����,Ҳ��������������ˮλ�ߡ�
(4) ͬ������,����һ���յ��µ�ˮλ��(���������� 6)֮��,����������ʱ�Ӹ���Ϊ6,ͬʱ���з���ʱ����Сֵ����˵�һ������ 4,���Ե�ǰ�����ʱ���ƽ��� 4,������ʱ���Ϊ 4 ��ˮλ��,�㲥�����θ�����������
??ˮλ��������������֮��Ĵ���,�dz�����ر����˷ֲ�ʽϵͳ��û��ͳһʱ�ӵ�����, ÿ�������ԡ�������֮ǰ�������ݡ�Ϊ����ȷ���Լ���ʱ��,�Ϳ��Ա�֤���ڴ����Ľ��������ȷ�ġ������ж������ϲ�֮����д����ij���,ˮλ�ߴ��ݵĹ��������Ƶġ����� Flink �еĶ���ת��,���ǻ��ں����½��н��ܡ�
��������
1. ���ڵĸ���
??Flink ��һ����ʽ��������,��Ҫ������������������,����ԴԴ���ϡ�����������Ҫ���ӷ����Ч�ش�������,һ�ַ�ʽ���ǽ����������и�����ġ����ݿ顱���д���,�������ν�ġ����ڡ�(Window)��
??�� Flink ��, ���ھ����������������ĺ��ġ����Ǻ����װѴ��������һ���̶�λ�õġ���,����ԴԴ���ϵ�������,��ij��ʱ��㴰�ڸùر���,��ֹͣ�ռ����ݡ��������㲢������������,���Ƕ���һ��ʱ�䴰��,ÿ 10 ��ͳ��һ������,��ô���൱�ڰѴ��ڷ�������,�� 0 �뿪ʼ�ռ�����;�� 10 ��ʱ,������ǰ��������������,���һ�����,Ȼ����մ��ڼ����ռ�����;�� 20 ��ʱ,�ٶԴ������������ݽ��м��㴦��,������;�������ơ�

??����ע��Ϊ����ȷ���ݻ��ֵ���һ������,���崰�ڶ��ǰ�����ʼʱ�䡢����������ʱ����,����ѧ���ű�ʾ����һ������ҿ�������,���� 0~10 ��Ĵ��ڿ��Ա�ʾΪ[0, 10),���ﵥλΪ�롣
??�� Flink ��,������ʵ������һ������,�����������ݱ���ס�˾�ֻ�ܽ���һ�����ڡ����֮��,����Ӧ�ðѴ��������һ����Ͱ��,��ͼ��ʾ���� Flink ��,���ڿ������и������С�Ķ�����洢Ͱ��(bucket);ÿ�����ݶ���ַ�����Ӧ��Ͱ��,�����ﴰ�ڽ���ʱ��ʱ,�Ͷ�ÿ��Ͱ���ռ������ݽ��м��㴦����

??Flink �д��ڲ����Ǿ�̬���õ�,���Ƕ�̬��������������������������䷶Χ�����ݴﵽʱ,�Ŵ�����Ӧ�Ĵ��ڡ�����,����������Ϊ���ﴰ�ڽ���ʱ��ʱ, ���ھʹ������㲢�ر�,��ʵ�ϡ��������㡱�͡����ڹرա�������ΪҲ���Էֿ�,�ⲿ���������ǻ��ں���������
2. ���ڵķ���
2.1 �����������ͷ���
??���ڱ����ǽ�ȡ�н����ݵ�һ�ַ�ʽ,���Դ���һ���dz���Ҫ����Ϣ��ʵ���ǡ�������ȡ���ݡ������仰˵,������ʲô������ʼ�ͽ������ݵĽ�ȡ,���ǰ����������ڵġ��������͡���
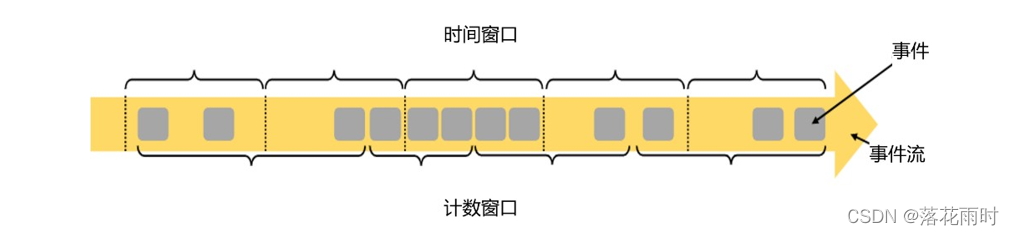
??�����������뵽�ľ��ǰ���ʱ���ȥ��ȡ����,���ִ��ھͽ�����ʱ�䴰����( Time Window)������ʵ��Ӧ�������,֮ǰ���ٵ�����Ҳ����ʱ�䴰�ڡ�������ʱ������֮��,������ʵҲ��������������,Ҳ����˵���չ̶��ĸ���,����ȡһ�����ݼ�,���ִ��ڽ���������������(Count Window),��ͼ��ʾ��
(1)ʱ�䴰��(Time Window)
??ʱ�䴰����ʱ��������崰�ڵĿ�ʼ(start)�ͽ���(end),���Խ�ȡ���ľ���ijһʱ��ε����ݡ��������ʱ��ʱ,���ڲ����ռ�����,��������������,�������ڹر����١����Կ���˵����˼·���ǡ����㷢������
??�ý���ʱ���ȥ��ʼʱ��,�õ����ʱ��ij���,���Ǵ��ڵĴ�С(window size)�������ʱ������Dz�ͬ������,�������ǿ��Զ��崦��ʱ�䴰�ں��¼�ʱ�䴰�ڡ�
??Flink ����һ��ר�ŵ�������ʾʱ�䴰��,���ƾͽ��� TimeWindow�������ֻ������˽������:start �� end,��ʾ���ڵĿ�ʼ�ͽ�����ʱ���,��λΪ���롣
private final long start;
private final long end;
??���ǿ��Ե��ù��е�getStart()�� getEnd()����ֱ�ӻ�ȡ������ʱ���������,TimeWindow���ṩ��һ�� maxTimestamp()����,������ȡ�������ܹ��������ݵ����ʱ�����
public long maxTimestamp() {
return end - 1;
}
??������,�����е�����,���������ʱ�������end - 1,��Ҳ�ʹ��������Ƕ���Ĵ���ʱ�䷶Χ��������ҿ�������[start,end)��
??Ϊʲô���Ѵ������䶨������ұա������Ͻ���ʱ����?����maxTimestamp �� end һ��,���Ϳ���ʡȥһ�������Ķ�����?
??����Ҫ��Ϊ�˷����жϴ���ʲôʱ��رա������¼�ʱ������,���ڵĹر���Ҫˮλ���ƽ������ڵĽ���ʱ��;������֪��,ˮλ�� Watermark(t)�����ĺ����ǡ�ʱ���С�ڵ��� t �����ݶ��ѵ���,���������ˡ���Ϊ�˼���,�����Ȳ��������������õ��ӳ�ʱ�䡣��ô���µ�һ��ʱ���Ϊ t ������ʱ,��ǰˮλ�ߵ�ʱ���ƽ����� t �C 1(���ǵ�������������ˮλ�ߵļ�һ������?)�����Ե�ʱ���Ϊ end �����ݵ���ʱ,ˮλ���ƽ�����end - 1;������ǰѴ��ڶ���Ϊ������ end,��ô��ǰ��ˮλ�߸պþ��� maxTimestamp,��ʾ�����ܹ����������ݶ��Ѿ�����,���ǾͿ���ֱ�ӹرմ����ˡ��������������Ķ���,���ǾͲ���Ҫ��ȥ�����Ƿ��˵ġ���һ����,ֱ�ӿ���ʱ���Ϊ end ������,�رն�Ӧ�Ĵ��ڡ����Ϊ������������ˮλ���ӳ�ʱ�� delay,Ҳֻ��Ҫ�ȵ�ʱ���Ϊ end + delay ������,�Ϳ��Թش��ˡ�
(2)��������(Count Window)
??�������ڻ���Ԫ�صĸ�������ȡ����,����̶��ĸ���ʱ�ʹ������㲢�رմ��ڡ����൱����λ���ޡ��������ͷ�����,�Ƿ���ʱ���ء�ÿ�����ڽ�ȡ���ݵĸ���,���Ǵ��ڵĴ�С��
??�����������ʱ�䴰�ھ��Ӽ�,����ֻ��ָ�����ڴ�С,�Ϳ������ݷ��䵽��Ӧ�Ĵ������ˡ��� Flink �ڲ�Ҳ��û�ж�Ӧ��������ʾ��������,�ײ���ͨ����ȫ�ִ��ڡ�(Global Window)��ʵ�ֵġ�����ȫ�ִ���,�����Ժ⡣
2.2 ���մ��ڷ������ݵĹ������
??ʱ�䴰�ںͼ�������,ֻ�ǶԴ��ڵ�һ�����»���;�ھ���Ӧ��ʱ,����Ҫ������Ӿ�ϸ�Ĺ���,����������Ӧ�û��ֵ��ĸ�������ȥ����ͬ�ķ������ݵķ�ʽ,�Ϳ����в�ͬ�Ĺ���Ӧ�á�
??���ݷ������ݵĹ���,���ڵľ���ʵ�ֿ��Է�Ϊ 4 ��:��������(Tumbling Window)����������(Sliding Window)���Ự����(Session Window),�Լ�ȫ�ִ���(Global Window)��������������������ܡ�
(1)��������(Tumbling Windows)
??���������й̶��Ĵ�С,��һ�ֶ����ݽ��С�������Ƭ���Ļ��ַ�ʽ������֮��û���ص�, Ҳ�����м��,�ǡ���β��ӡ���״̬��������ǰѶ�����ڵĴ���,����һ�����ڵ��˶�, �Ǿͺ������ڲ�ͣ����ǰ��������һ����������Ĵ�����ʽ,����֮ǰ���ٵ����Ӷ��ǹ������ڡ�Ҳ������Ϊ���������ǡ����νӡ�,����ÿ�����ݶ��ᱻ���䵽һ������,����ֻ������һ�����ڡ�
??�������ڿ��Ի���ʱ�䶨��,Ҳ���Ի������ݸ�������;��Ҫ�IJ���ֻ��һ��,���Ǵ��ڵĴ�С(window size)���������ǿ��Զ���һ������Ϊ 1 Сʱ�Ĺ���ʱ�䴰��,��ôÿ��Сʱ�ͻ����һ��ͳ��;���߶���һ������Ϊ 10 �Ĺ�����������,�ͻ�ÿ 10 ��������һ��ͳ�ơ�
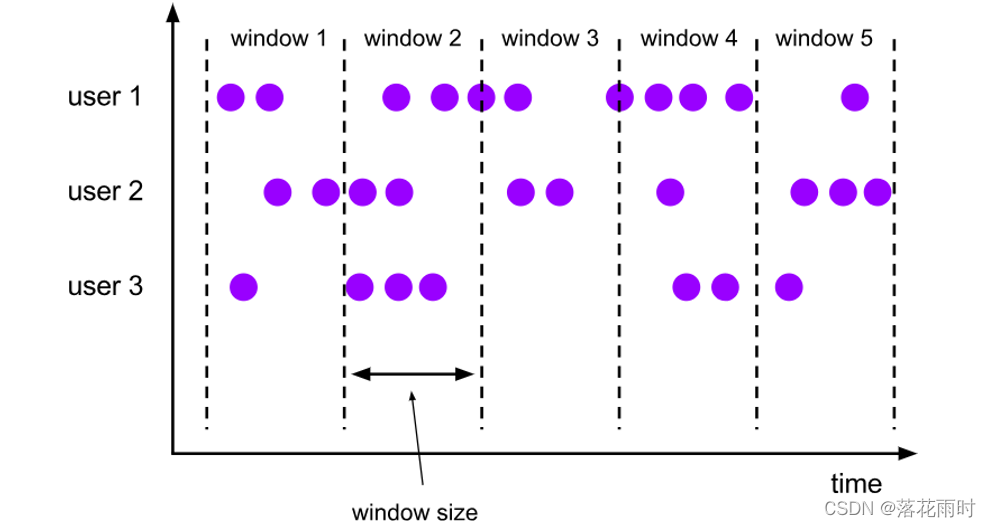
??��ͼ��ʾ,СԲ���ʾ���е�����,���Ƕ����ݰ��� userId ���˷��������̶��˴��ڴ�С֮��,���з����Ĵ��ڻ��ֶ���һ�µ�;����û���ص�,ÿ������ֻ����һ�����ڡ�
??��������Ӧ�÷dz��㷺,�����Զ�ÿ��ʱ������ۺ�ͳ��,�ܶ�BI ����ָ�궼����������ʵ�֡�
(2)��������(Sliding Windows)
??�������������,�������ڵĴ�СҲ�ǹ̶��ġ���������,����֮�䲢������β��ӵ�, ���ǿ��ԡ�������һ����λ�á��������һ�����ڵ��˶�,��ô��������ǰС����������һ����
??��Ȼ����ǰ����,��ôÿһ������Զ,��Ҳ�ǿ��Կ��Ƶġ����Զ��廬�����ڵIJ���������:��ȥ���ڴ�С(window size)֮��,����һ��������������(window slide),����ʵ�ʹ����˴��ڼ����Ƶ�ʡ������ľ���������¸����ڿ�ʼ��ʱ����,�����ڴ�С�ǹ̶���,����Ҳ�����������ڽ���ʱ��ļ��;�����ڽ���ʱ�䴥������������,��ô���������ʹ����˼���Ƶ�ʡ�����,���Ƕ���һ������Ϊ 1 Сʱ����������Ϊ 5 ���ӵĻ�������,��ô�ͻ�ͳ�� 1 Сʱ�ڵ�����,ÿ 5 ����ͳ��һ�Ρ�ͬ��,�������ڿ��Ի���ʱ�䶨��,Ҳ���Ի������ݸ������塣

??���ǿ��Կ���,����������С�ڴ��ڴ�Сʱ,�������ھͻ������ص�,��ʱ����Ҳ���ܻᱻͬʱ���䵽��������С�������ĸ���,���ɴ��ڴ�С�ͻ��������ı�ֵ(size/slide)����������ͼ��ʾ,���������պ��Ǵ��ڴ�С��һ��,��ôÿ�����ݶ��ᱻ���䵽 2 ��������������Ƕ���Ĵ��ڳ���Ϊ 1 Сʱ����������Ϊ 30 ����,��ô���� 8 �� 55 �ֵ�����,Ӧ��ͬʱ����[8 ��, 9 ��)��[8 ���, 9 ���)��������;������ 8 �� 10 �ֵ�����,��ͬʱ����[8��, 9 ��)��[7 ���, 8 ���)�������ڡ�
??����,����������ʵ�ǹ̶���С���ڵĸ������һ����ʽ;���仰˵,��������Ҳ���Կ�����һ������Ļ������ڡ������ڴ�С���ڻ�������(size = slide)����Ȼ,����Ҳ���Զ��廬���������ڴ��ڴ�С,�����Ļ��ͻ���ִ��ڲ��ص��������м�������;��ʱ��Щ���ݲ������κ�һ������,�ͻ������©ͳ�ơ�����һ�������,���ǻ��û�������С�ڴ��ڴ�С, ����������Ϊ�������Ĺ�ϵ��
??��һЩ������,������Ҫͳ�����һ��ʱ���ڵ�ָ��,����������Ƶ��Ҫ���ֺܸ�,����Ҫ��ʵʱ����,�����Ʊ�۸�� 24 Сʱ�ǵ���ͳ��,������һ��ʱ������Ϊ�����쳣��������ʱ�����������ɾ��Ǻܺõ�ʵ�ַ�ʽ��
(3)�Ự����(Session Windows)
??�Ự���ڹ���˼��,�ǻ��ڡ��Ự��(session)���������ݽ��з���ġ�����ĻỰ���� Web Ӧ���� session �ĸ���,����������ʾ���˵�ͨѶ����,���ǽ��ûỰ��ʱʧЧ�Ļ������������ڡ�����˵,������������֮��Ϳ���һ���Ự����,�����������������½������, ��ô��һֱ���ֻỰ;���һ��ʱ��һֱû�յ�����,�Ǿ���Ϊ�Ự��ʱʧЧ,�����Զ��رա���ͺ������Ǵ�绰һ��,���ʱ��ʱ����˵��ʲô,��˵����û����;������������εij�Ĭ,���춼û��˵,����Ȼ�Ϳ��Թҵ绰�ˡ�
??�뻬�����ں������ڲ�ͬ,�Ự����ֻ�ܻ���ʱ��������,��û�С��Ự�������ڡ��ĸ����ܺ�����,���Ự����ֹ�ı�־���ǡ���һ��ʱ��û����������,���������ʱ����ijɸ���,�ͳ��ˡ�����������û����������,����ȫ������ì�ܵ�˵����
??��ͬ���ǻ�������жϱ�,�⡰һ��ʱ�䡱�����Ƕ��پͺ���Ҫ��,������ȷָ�������ڻỰ���ڶ���,����Ҫ�IJ����������ʱ��ij���(size),����ʾ�Ự�ij�ʱʱ��,Ҳ���������Ự����֮�����С���롣��������������ݵ�����ʱ����(Gap)С��ָ���Ĵ�С(size),��˵�����ڱ��ֻỰ,���Ǿ�����ͬһ������;��� gap ���� size,��ô���������ݾ�Ӧ�������µĻỰ����,��ǰһ�����ھ�Ӧ�ùر��ˡ��ھ���ʵ����,���ǿ������þ�̬�̶��Ĵ�С(size),Ҳ����ͨ��һ���Զ������ȡ��(gap extractor)��̬��ȡ��С��� gap ��ֵ��
??���ǵ��¼�ʱ�������µ�������,�����ֻ���һЩ�鷳�������������ݵ�ʱ���� gap ����ָ���� size,������Ϊ�������������Ự����,ǰһ�����ھر�;������������������,���ܻ��гٵ�����,����ʱ����պ�����֮ǰ����������֮��ġ�����һ��,֮ǰ�����жϵļ���оͲ��ǡ�һֱû�����ݡ�,����С��ļ���п��ܻ�� size ��ҪС����������������ݱ���Ӧ������ͬһ���Ự���ڡ�
??������ Flink �ײ�,�ԻỰ���ڵĴ�����Ƚ�����:ÿ��һ���µ�����,���ᴴ��һ���µĻỰ����;Ȼ���ж����д���֮��ľ���,���С�ڸ����� size,�Ͷ����ǽ��кϲ�(merge) ��������Window ������,�ԻỰ���ڻ��е����Ĵ�������

(4)ȫ�ִ���(Global Windows)
??����һ��Ƚ�ͨ�õĴ���,���ǡ�ȫ�ִ��ڡ������ִ���ȫ����Ч,�����ͬ key ���������ݶ����䵽ͬһ��������;˵ֱ��һ��,��û�ִ���һ������������������ֹ��,�������ִ���Ҳû�н�����ʱ��,Ĭ���Dz�������������ġ����ϣ�����ܶ����ݽ��м��㴦��, ����Ҫ�Զ��塰��������(Trigger)��

3. ����API ����
3.1 ��������(Keyed)�ͷǰ�������(Non-Keyed)
??�ڶ��崰�ڲ���֮ǰ,������Ҫȷ��,�����ǻ��ڰ�������(Keyed)�������� KeyedStream������,����ֱ����û�а��������� DataStream �Ͽ�����Ҳ����˵,�ڵ��ô�������֮ǰ, �Ƿ��� keyBy ������
(1)������������(Keyed Windows)
??������������keyBy ������,�������ᰴ��key ����Ϊ��������(logical streams),����� KeyedStream������ KeyedStream ���д��ڲ���ʱ, ���ڼ�����ڶ��������������ͬʱִ�С���ͬ key �����ݻᱻ���͵�ͬһ������������,�����ڲ��������ÿ�� key ���е����Ĵ��������Կ�����Ϊ,ÿ�� key �϶�������һ�鴰��,���Զ����ؽ���ͳ�Ƽ��㡣
??�ڴ���ʵ����,������Ҫ�ȶ� DataStream ����.keyBy()���а�������, Ȼ���ٵ���.window()���崰�ڡ�
stream.keyBy(...)
.window(...)
(2)�ǰ�������(Non-Keyed Windows)
??���û�н��� keyBy,��ôԭʼ�� DataStream �Ͳ���ֳɶ�����������ʱ������ֻ����һ������(task)��ִ��,���൱�ڲ��жȱ���� 1��������ʵ��Ӧ����һ�㲻�Ƽ�ʹ�����ַ�ʽ��
??�ڴ�����,ֱ�ӻ��� DataStream ����.windowAll()���崰�ڡ�
������Ҫע�����,���ڷǰ��������Ĵ��ڲ���,�ֶ��������ӵIJ��ж�Ҳ����Ч��,
windowAll��������һ���Dz��еIJ�����
3.2 �����д��� API �ĵ���
??����ǰ�õĻ���,���������ǾͿ��������ڴ�����ʵ��һ�����ڲ����ˡ�����˵,���ڲ�����Ҫ����������:���ڷ�����(Window Assigners)�����ں���(Window Functions)��
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
??����.window()������Ҫ����һ�����ڷ�����,��ָ���˴��ڵ�����;�������.aggregate()��������һ�����ں�����Ϊ����,���������崰�ھ���Ĵ����������ڷ������и�����ʽ, �����ں����ĵ��÷���Ҳ��ֻ.aggregate()һ��,���ǽ���������ϸչ�����⡣
??����,��ʵ��Ӧ����,һ�㶼��Ҫ����ִ������,�ǰ������������õ�,��������֮��������������Ϊ��;�����Ҫʵ�ַǰ�����������,ֻҪǰ�治�� keyBy,�������.window()ʱֱ�ӻ���.windowAll()�Ϳ����ˡ�
4. ���ڷ�����(Window Assigners)
??���崰�ڷ�����(Window Assigners)�ǹ����������ӵĵ�һ��,�������þ��Ƕ�������Ӧ�ñ������䡱���ĸ����ڡ����ڷ������ݵĹ���,��ʵ�Ͷ�Ӧ�Ų�ͬ�Ĵ������͡����Կ���˵,���ڷ�������ʵ������ָ�����ڵ����͡�
??���ڷ�������ͨ�õĶ��巽ʽ,���ǵ���.window() ���������������Ҫ����һ��WindowAssigner��Ϊ����,���� WindowedStream������Ƿǰ�����������,��ôֱ�ӵ���.windowAll()����,ͬ������һ��WindowAssigner,���ص��� AllWindowedStream��
??���ڰ����������Ϳ��Էֳ�ʱ�䴰�ںͼ�������,�����վ���ķ������,���й������ڡ��������ڡ��Ự���ڡ�ȫ�ִ������֡���ȥ��Ҫ�Զ����ȫ�ִ�����,�������õ����� Flink �ж����������õķ�����ʵ��,���ǿ��Է���ص���ʵ�ָ�������
4.1 ʱ�䴰��
??ʱ�䴰������õĴ�������,�ֿ���ϸ��Ϊ�����������ͻỰ���֡�
??�ڽ���İ汾��,����ֱ�ӵ���.timeWindow()������ʱ�䴰��;���ַ�ʽ�dz����,��ʹ���¼�ʱ������ʱ��Ҫ��������,����Ա������Ϊ���������������н������������1.12�汾֮��,���ַ�ʽ�Ѿ���������,����������ʽ����ֱ�ӵ���.window(),�����洫���Ӧʱ�������µĴ��ڷ�����������һ��,���Dz���Ҫר�Ŷ���ʱ������,Ĭ�Ͼ����¼�ʱ��;������ô���ʱ��,��ô�����ﴫ�봦��ʱ��Ĵ��ڷ������Ϳ����ˡ����������г���ÿ������Ĵ���ʵ�֡�
(1)��������ʱ�䴰��
??���ڷ���������TumblingProcessingTimeWindows �ṩ,��Ҫ�������ľ�̬����.of()��
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
??����.of()������Ҫ����һ�� Time ���͵IJ��� size,��ʾ�������ڵĴ�С,�������ﴴ����һ������Ϊ 5 ��Ĺ������ڡ�
??����,.of()����һ�����ط���,���Դ������� Time ���͵IJ���:size �� offset����һ��������Ȼ���Ǵ��ڴ�С,�ڶ����������ʾ������ʼ���ƫ������������Ҫ����һЩ����:��������֮ǰ�Ķ���,����������ʵֻ��һ�� size �Dz���Ψһȷ���ġ��������Ƕ��� 1 ��Ĺ�������,��ÿ��� 0 �㿪ʼ��ʱ�ǿ��Ե�,ͳ�Ƶľ���һ����Ȼ�յ���������;�������ÿ����賿 2 �㿪ʼ��ʱ��ʵҲ��ȫû����,ֻ����ͳ�Ƶ����ݱ����ÿ�� 2 �㵽�ڶ��� 2 �㡣�����ʼ���ѡȡ,��ʵ�Դ��ڱ���������û��Ӱ��;��Ϊ�˷���Ӧ��,Ĭ�ϵ���ʼ��ʱ����Ǵ��ڴ�С����������Ҳ����˵,������Ƕ��� 1 ��Ĵ���,Ĭ�Ͼʹ� 0 �㿪ʼ;������� 1 Сʱ�Ĵ���,Ĭ�Ͼʹ����㿪ʼ����������Ƿ�Ҫ�������Ĭ��ֵ��ʼ,�ǾͿ���ͨ������ƫ����offset ��������
??������ܺ���ûʲô��,��ҪŪ��ƫ�������Ǹ��Լ��ұ�Ť��?����ʵ����ʵ����;�ġ�����֪��,��ͬ���ҷֲ��ڲ�ͬ��ʱ������ʱ�����ʵ����1970 �� 1 �� 1 �� 0 ʱ 0 �� 0 �� 0 ���뿪ʼ�����һ��������,�����ʱ������ UTC ʱ��,Ҳ���� 0 ʱ��(��ʱ��)Ϊ���ġ��������ڵ�ʱ���Ƕ�����,Ҳ���� UTC+8,�� UTC �� 8 Сʱ��ʱ����Ƕ��� 1 ���������ʱ,�����Ĭ�ϵ���ʼ��,��ô�õ�������ʱ��ÿ�� 0�㿪������,��ʱ�DZ���ʱ������ 8 �㡣�������õ�����ʱ��ÿ�� 0 �㿪���Ĺ���������?ֻҪ����-8 Сʱ��ƫ�����Ϳ�����:
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
(2)��������ʱ�䴰��
���ڷ��������� SlidingProcessingTimeWindows �ṩ,ͬ����Ҫ�������ľ�̬����.of()��
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
??����.of()������Ҫ�������� Time ���͵IJ���:size �� slide,ǰ�߱�ʾ�������ڵĴ�С, ���߱�ʾ�������ڵĻ����������������ﴴ����һ������Ϊ 10 �롢��������Ϊ 5 ��Ļ������ڡ�
??��������ͬ�������ӵ���������,����ָ��������ʼ���ƫ����,�÷������������ȫһ�¡�
(3)����ʱ��Ự����
??���ڷ��������� ProcessingTimeSessionWindows �ṩ,��Ҫ�������ľ�̬����.withGap()����.withDynamicGap()��
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
??����.withGap()������Ҫ����һ�� Time ���͵IJ��� size,��ʾ�Ự�ij�ʱʱ��,Ҳ������С��� session gap���������ﴴ���˾�̬�Ự��ʱʱ��Ϊ 10 ��ĻỰ���ڡ�
.window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) {
// ��ȡ session gap ֵ����, ��λ����
return element.f0.length() * 1000;
}
}))
??����.withDynamicGap()������Ҫ����һ�� SessionWindowTimeGapExtractor ��Ϊ����,�������� session gap �Ķ�̬��ȡ����������,������ȡ������Ԫ�صĵ�һ���ֶ�,�����ij��ȳ��� 1000 ��Ϊ�Ự��ʱ�ļ����
(4)�����¼�ʱ�䴰��
���ڷ���������TumblingEventTimeWindows �ṩ,�÷�����������¼�������ȫһ�¡�
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
����.of()����Ҳ���Դ���ڶ������� offset,�������ô�����ʼ���ƫ������
(5)�����¼�ʱ�䴰��
���ڷ���������SlidingEventTimeWindows�ṩ,�÷��뻬�������¼�������ȫһ�¡�
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
(6)�¼�ʱ��Ự����
���ڷ���������EventTimeSessionWindows �ṩ,�÷��봦���¼��Ự������ȫһ�¡�
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
4.2 ��������
??�������ڸ���dz���,�����ײ��ǻ���ȫ�ִ���(Global Window)ʵ�ֵġ�Flink Ϊ�����ṩ�˷dz�����Ľӿ�:ֱ�ӵ���.countWindow()���������ݷ������IJ�ͬ,�ֿ��Է�Ϊ�����������ںͻ���������������,�������Ǿ��������ǵľ���ʵ�֡�
(1)������������
������������ֻ��Ҫ����һ�������͵IJ��� size,��ʾ���ڵĴ�С��
stream.keyBy(...)
.countWindow(10)
??���Ƕ�����һ������Ϊ 10 �Ĺ�����������,��������Ԫ�������ﵽ 10 ��ʱ��,�ͻᴥ������ִ�в��رմ��ڡ�
(2)������������
�����������������,������Ҫ��.countWindow()����ʱ������������:size �� slide,ǰ�߱�ʾ���ڴ�С,���߱�ʾ����������
stream.keyBy(...)
.countWindow(10,3)
���Ƕ�����һ������Ϊ 10����������Ϊ 3 �Ļ����������ڡ�ÿ������ͳ�� 10 ������,ÿ�� 3 �����ݾ�ͳ�����һ�ν����
4.3 ȫ�ִ���
??ȫ�ִ����Ǽ������ڵĵײ�ʵ��,һ������Ҫ�Զ��崰��ʱʹ�á����Ķ���ͬ����ֱ�ӵ���.window(),��������GlobalWindows ���ṩ��
stream.keyBy(...)
.window(GlobalWindows.create());
��Ҫע��ʹ��ȫ�ִ���,�������ж��崥��������ʵ�ִ��ڼ���,�������κ����á�
5. ���ں���(Window Functions)
??�����˴��ڷ�����,����ֻ��֪�������������ĸ�����,���Խ������ռ�������;�����ռ���������Ҫ��ʲô,��ʵ����ȫû��ͷ���������ڴ��ڷ�����֮��,�����ٽ���һ�����崰����ν��м���IJ���,�������ν�ġ����ں�����(window functions)��
??�����ڷ���������֮��,���ݿ��Է��䵽��Ӧ�Ĵ�����,������������ת���õ�������������WindowedStream��������Ͳ����� DataStream,���Բ�����ֱ�ӽ�������ת��,�������һ�����ô��ں���,���ռ��������ݽ��д�������֮��,���������ٴεõ� DataStream��

??���ں���������Ҫ�Դ������ռ����������ļ������,���ݴ����ķ�ʽ���Է�Ϊ����:�����ۺϺ�����ȫ���ں�����
5.1 �����ۺϺ���(incremental aggregation functions)
??���ڽ������ռ�����,������Ĵ���������Ȼ���ǽ��оۺϡ����ڶ����������з�,���Կ����õ���һ���н����ݼ���������ǵȵ��������ݶ��ռ���,�ڴ��ڵ��˽���ʱ��Ҫ��������һ˲����ȥ���оۺ�,��Ȼ�Ͳ�����Ч�ˡ������൱�����������������˼·����ʵʱ��������
??Ϊ�����ʵʱ��,���ǿ����ٴν���������˼·������:���� DataStream �ļۺ�һ��,ÿ��һ�����ݾ��������м���,�м�ֻҪ����һ���ľۺ�״̬�Ϳ�����;����ֻ�����ڲ�����������,����Ҫ�ȵ����ڽ���ʱ�䡣�ȵ����ڵ��˽���ʱ����Ҫ�����������ʱ��,����ֻ��Ҫ�ó�֮ǰ�ۺϵ�״ֱ̬�����,�����ɾʹ������˳������е�Ч�ʺ�ʵʱ�ԡ�
??���͵������ۺϺ���������:ReduceFunction ��AggregateFunction��
(1)��Լ����(ReduceFunction)
??������ľۺϷ�ʽ���ǹ�Լ(reduce)�������ڻ���ת���ľۺ������н��ܹ� reduce ���÷�,���ڵĹ�Լ�ۺ�Ҳ�dz�����,���ǽ��������ռ����������������й�Լ�������ǽ���������ʱ,����Ҫ����һ��״̬;ÿ��һ���µ�����,�ͺ�֮ǰ�ľۺ�״̬����Լ,������ʵ��������ʽ�ľۺϡ�
??���ں�����Ҳ�ṩ�� ReduceFunction:ֻҪ���� WindowedStream ����.reduce()����,Ȼ���� ReduceFunction ��Ϊ����,�Ϳ���ָ���Թ�Լ����Ԫ�صķ�ʽȥ�Դ��������ݽ��оۺ��ˡ������ ReduceFunction ��ʵ��ۺ�ʱ�õ��� ReduceFunction ��ͬһ��������ӿ�, ����ʹ�÷�ʽҲ����ȫһ���ġ�
??���ǻ���һ��,ReduceFunction ����Ҫ��дһ�� reduce ����,�������������������������Ԫ��,����Լ��������������������,��������������ͱ��뱣��һ�¡�Ҳ����˵,�м�ۺϵ�״̬������Ľ��,�������������������һ���ġ�
������ʹ��ReduceFunction ���������ۺϵĴ���ʾ����
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class WindowReduceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// ���Զ�������Դ��ȡ����,����ȡʱ���������ˮλ��
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})); stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
// ������ת���ɶ�Ԫ��,�������
return Tuple2.of(value.user, 1L);
}
})
.keyBy(r -> r.f0)
// ���ù����¼�ʱ�䴰��
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
// �����ۼӹ���,���ڱպ�ʱ,�����η����ۼӽ��
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
.print();
env.execute();
}
}
���н����ʽ����:
(Alice,2)
(Mary,2)
...
??���������Ƕ�ÿ���û�����Ϊ���ݽ����˿���ͳ�ơ��� word count ������,���Ƚ�����ת����(user, count)�Ķ�Ԫ����ʽ(����Ϊ Tuple2<String, Long>),ÿ�����ݶ�Ӧ�ij�ʼ countֵ���� 1;Ȼ�����û� id ����,�ڴ���ʱ���¿���������,ͳ��ÿ 5 ���ڵ��û���Ϊ���������ڴ��ڵļ���,������ ReduceFunction �� count ֵ���������ۺ�:�����лὫ��ǰ���� count ֵ�����һ����Լ״̬,ÿ��һ������,�ͻ�����ڲ��� reduce ����,���������е� count ֵ���ӵ�״̬��,���õ��µ�״̬�����������ȵ��� 5 �봰�ڵĽ���ʱ��,�Ͱѹ�Լ�õ�״ֱ̬�������
??������Ҫע��,���Ǿ������ھۺ�ת�����������,����������Ȼ�Ƕ�Ԫ�� Tuple2<String, Long>��
(2)�ۺϺ���(AggregateFunction)
??ReduceFunction ���Խ���������Լ�ۺϵ�����,��������ӿ���һ������,���Ǿۺ�״̬�����͡������������Ͷ������������������һ���������ʹ���DZ����ھۺ�ǰ,�Ƚ�����ת��(map)��Ԥ�ڽ������;������Щ�����,����Ҫ��״̬���н�һ���������ܵõ�������,��ʱ���ǵ����Ϳ��ܲ�ͬ,ʹ�� ReduceFunction �ͻ�dz��鷳��
??����,�������ϣ������һ�����ݵ�ƽ��ֵ,Ӧ���������ۺ���?������,��ʱ������Ҫ��������״̬��:���ݵ��ܺ�(sum),�Լ����ݵĸ���(count),�����������������ߵ���(sum/count)������� ReduceFunction,��ô����Ӧ���Ȱ�����ת���ɶ�Ԫ��(sum, count)����ʽ,Ȼ����й�Լ�ۺ�,����ٽ�Ԫ�������Ԫ�����ת���õ�����ƽ��ֵ������Ӧ��ֻ��һ������,������ȴ��Ҫmap-reduce-map ��������,����Ȼ������Ч��
??������Ȼ�����뵽,���ȡ������һ�µ�����,���������ݡ��м�״̬���������������Ͷ����Բ�ͬ,���Ϳ���һ��ֱ�Ӹ㶨����?
??Flink �� Window API �е� aggregate ���ṩ�������IJ�����ֱ�ӻ��� WindowedStream ����.aggregate() ����, �Ϳ��Զ���������Ĵ��ھۺϲ��������������Ҫ����һ��AggregateFunction ��ʵ������Ϊ������AggregateFunction ��Դ���еĶ�������:
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable{
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
??AggregateFunction ���Կ����� ReduceFunction ��ͨ�ð汾,��������������:��������
(IN)���ۼ�������(ACC)���������(OUT)���������� IN ������������Ԫ�ص���������;�ۼ������� ACC �������ǽ��оۺϵ��м�״̬����;��������͵�Ȼ�������ռ������������ˡ�
�ӿ������ĸ�����:
createAccumulator():����һ���ۼ���,�����Ϊ�ۺϴ�����һ����ʼ״̬,ÿ���ۺ�����ֻ�����һ�Ρ�add():�������Ԫ�����ӵ��ۼ����С�����ǻ��ھۺ�״̬,�����������ݽ��н�һ���ۺϵĹ��̡�����������������:��ǰ�µ������� value,�͵�ǰ���ۼ���accumulator;����һ���µ��ۼ���ֵ,Ҳ���ǶԾۺ�״̬���и��¡�ÿ�����ݵ���֮��������������getResult():���ۼ�������ȡ�ۺϵ���������Ҳ����˵,���ǿ��Զ�����״̬, Ȼ���ٻ�����Щ�ۺϵ�״̬�����һ������������������֮ǰ�����ᵽ�ļ���ƽ��ֵ,�Ϳ��� sum �� count ��Ϊ״̬�����ۼ���,���ڵ����������ʱ����õ����ս�����������ֻ�ڴ���Ҫ������ʱ���á�merge():�ϲ������ۼ���,�����ϲ����״̬��Ϊһ���ۼ������ء��������ֻ����Ҫ�ϲ����ڵij����²Żᱻ����;����ĺϲ�����(Merging Window)�ij������ǻỰ����(Session Windows)��
??���Կ��Կ���,**AggregateFunction �Ĺ���ԭ����:**���ȵ��� createAccumulator()Ϊ�����ʼ��һ��״̬(�ۼ���);����ÿ��һ�����ݾ͵���һ�� add()����,�����ݽ��оۺ�,�õ��Ľ��������״̬��;�ȵ��˴�����Ҫ���ʱ,�ٵ��� getResult()�����õ���������������, �� ReduceFunction ��ͬ,AggregateFunction Ҳ������ʽ�ľۺ�;���������롢�м�״̬����������Ϳ��Բ�ͬ,ʹ��Ӧ�ø������㡣
??��������һ���������ӡ�����֪��,�ڵ�����վ��,PV(ҳ�������)�� UV(�����ÿ���)�Ƿdz���Ҫ����������ָ�ꡣһ����˵,PV ͳ�Ƶ������еĵ����;�����û� id ����ȥ��֮��,�õ��ľ��� UV��������ʱ���ǻ��� PV/UV �����ֵ,����ʾ���˾��ظ���������,Ҳ����ƽ��ÿ���û�����ʶ��ٴ�ҳ��,����һ���̶��ϴ������û���ճ�ȡ�
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class UrlViewCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// ��Ҫ����url����,����������ͳ��
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// ͬʱ���������ۺϺ�����ȫ���ں���
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
env.execute();
}
// �Զ��������ۺϺ���,��һ�����ݾͼ�һ
public static class UrlViewCountAgg implements AggregateFunction<Event, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
// �Զ��崰�ڴ�������,ֻ��Ҫ��װ������Ϣ
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
// ��ϴ�����Ϣ,��װ�������
Long start = context.window().getStart();
Long end = context.window().getEnd();
// ��������ֻ��һ��Ԫ��,���������ۺϺ����ļ�����
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
}
??���������Ǵ������¼�ʱ�们������,ͳ�� 10 ���ӵġ��˾� PV��,ÿ 2 ��ͳ��һ�Ρ����ھۺϵ�״̬����Ҫ����������,��˴��ھۺ�ʱʹ���˸������� AggregateFunction��Ϊ��ͳ�� UV,������һ�� HashSet �������г��ֹ����û� id,ʵ���Զ�ȥ��;�� PV ��ͳ��������һ��������,ÿ��һ�����ݼ�һ�Ϳ����ˡ����������״̬,����Ϊ����һ�� HashSet ��һ�� count ֵ�Ķ�Ԫ��(Tuple2<HashSet, Long>),ÿ��һ������,�ͽ� user ����HashSet,ͬʱ count �� 1������� count ���� PV,�� HashSet ��Ԫ�صĸ���(size)���� UV;�������մ��ڵ�������,�������ǵı�ֵ��
����û���漰�Ự����,���� merge()�������Բ����κβ�����
??����,Flink ҲΪ���ڵľۺ��ṩ��һϵ��Ԥ����ļۺϷ���, ����ֱ�ӻ���WindowedStream ���á���Ҫ����.sum()/max()/maxBy()/min()/minBy(),�� KeyedStream �ļۺϷdz����ơ����ǵĵײ�,��ʵ����ͨ��AggregateFunction ��ʵ�ֵġ�
??ͨ�� ReduceFunction �� AggregateFunction ���ǿ��Է���,�����ۺϺ�����ʵ����������������˼·�������н����ݼ�,�����DZ���һ���ۺ�״̬,�����ݵ���ʱ��ͣ�ظ���״̬������� Flink ��ν�ġ���״̬����������,ͨ�����ַ�ʽ���Լ������߳������е�Ч��,������ʵ��Ӧ������Ϊ������
5.2 ȫ���ں���(full window functions)
??���ڲ����е���һ�������ȫ���ں������������ۺϺ�����ͬ,ȫ���ں�����Ҫ���ռ������е�����,�����ڲ���������,�ȵ�����Ҫ��������ʱ����ȡ�����ݽ��м��㡣
??������,����ǵ��͵�������˼·�ˡ�����������,��һ��������������ʽ�����������̡����������������ǵ�Ч��:��Ϊ����ȫ���ļ�������ѹ����Ҫ����������һ˲��,����֮ǰ�ռ����ݵ�����������ȴ�������¡���ͺñ�ƽʱ���ù�,������֮ǰͨ�������,�϶�����ѹ������ճ������ϡ�
??��Ϊʲô����Ҫ��ȫ���ں�����?������Ϊ��Щ������,����Ҫ���ļ���������ȫ�������ݲ���Ч,��ʱ�������ۺϾ�ûʲô������;����,����Ľ���п���Ҫ�����������е�һЩ��Ϣ(���細�ڵ���ʼʱ��),���������ۺϺ����������ġ�����,���ǻ���Ҫ�и��ḻ�Ĵ��ڼ��㷽ʽ,��Ϳ�����ȫ���ں�����ʵ�֡�
??�� Flink ��,ȫ���ں���Ҳ������:WindowFunction��ProcessWindowFunction��
(1)���ں���(WindowFunction)
??WindowFunction �����Ͼ��ǡ����ں�����,����ʵ���ϰ汾��ͨ�ô��ں����ӿڡ����ǿ��Ի���WindowedStream ����.apply()����,����һ�� WindowFunction ��ʵ���ࡣ
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
??������п��Ի�ȡ�����������������ݵĿɵ�������( Iterable),�������õ�����(Window)��������Ϣ��WindowFunction �ӿ���Դ����ʵ������:
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable {
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
}
??�����ڵ������ʱ����Ҫ��������ʱ,�ͻ��������� apply ���������ǿ��Դ� input ������ȡ�������ռ�������,��� key �� window ��Ϣ,ͨ���ռ���(Collector)������������ Collector ���÷�,�� FlatMapFunction ����ͬ��
??��������Ҳ������,WindowFunction ���ṩ����������Ϣ����,Ҳû�и����Ĺ��ܡ���ʵ��,�������ÿ��Ա� ProcessWindowFunction ȫ����,����֮����ܻ������á�һ����ʵ��Ӧ��,ֱ��ʹ�� ProcessWindowFunction �Ϳ����ˡ�
(2)�������ں���(ProcessWindowFunction)
??ProcessWindowFunction ��Window API ����ײ��ͨ�ô��ں����ӿڡ�֮����˵������ײ㡱,����Ϊ���˿����õ������е���������֮��,ProcessWindowFunction �����Ի�ȡ��һ���������Ķ���(Context)����������Ķ���dz�ǿ��,�����ܹ���ȡ������Ϣ,�����Է��ʵ�ǰ��ʱ���״̬��Ϣ�������ʱ��Ͱ����˴���ʱ��(processing time)���¼�ʱ��ˮλ��(event time watermark)�����ʹ�� ProcessWindowFunction ���������ܸ��ӷḻ����ʵ��, ProcessWindowFunction �� Flink �ײ�API������������(process function)�е�һԱ,���ڴ����������ǻ��ں����½�չ�����⡣
??��Ȼ ��Щ�ô������������ܺ���ԴΪ���۵ġ� ��Ϊһ��ȫ���ں��� ,ProcessWindowFunction ͬ����Ҫ���������ݻ����������ȵ����ڴ�������ʱ��ʹ�á�����ʵ����һ����ǿ���WindowFunction��
??����ʹ�ø� WindowFunction �dz�����,���ǿ��Ի��� WindowedStream ����.process()����,����һ�� ProcessWindowFunction ��ʵ���ࡣ������һ��������վͳ��ÿСʱ UV ������:
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
public class UvCountByWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// ������ȫ������ͬһ����,������ͳ��UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
// �Զ��崰�ڴ�������
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow>{
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
HashSet<String> userSet = new HashSet<>();
// ������������,�ŵ�Set��ȥ��
for (Event event: elements){
userSet.add(event.user);
}
// ��ϴ�����Ϣ,��װ�������
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect("����: " + new Timestamp(start) + " ~ " + new Timestamp(end)
+ " �Ķ����ÿ�������:" + userSet.size());
}
}
}
5.3 �����ۺϺ�ȫ���ں����Ľ��ʹ��
??�����ۺϺ���������������Ч����һ���������,��һ��������͡�������������
�����ϵ���,ȫ���ں���ֻ�ǰ������ռ���������,��û�д���;���˴���Ҫ�رա���������ʱ��,�ٱ��������������ε���,�õ����ս������������Dz��������ۺϵķ�ʽ,��ôֻ��Ҫ����һ����ǰ�͵�״̬,ÿ�����ݵ���ʱ�ͻ���һ�μӷ�,����״̬;����Ҫ��������ʱ��,ֻҪ����ǰ״ֱ̬���ó����Ϳ����ˡ������ۺ��൱�ڰѼ���������̯�����˴����ռ����ݵĹ�����,��Ȼ�ͻ��ȫ���ھۺϸ��Ӹ�Ч���������ʵʱ��
??��ȫ���ں��������������ṩ�˸������Ϣ,������Ϊ�Ǹ��ӡ�ͨ�á��Ĵ��ڲ�������ֻ�����ռ����ݡ��ṩ�����������Ϣ,�����е�ԭ���϶�����,����������ʲô������ȫ�������ⷢ�ӡ����ʹ�ô��ڼ���������,���ܸ���ǿ��
??������ʵ��Ӧ����,��������ϣ����������ߵ��ŵ�,�����ǽ����һ��ʹ�á�Flink ��Window API ������ʵ�����������÷���
??����֮ǰ�ڵ��� WindowedStream ��.reduce()��.aggregate()����ʱ,ֻ�Ǽ�ֱ�Ӵ�����һ�� ReduceFunction �� AggregateFunction ���������ۺϡ�����֮��,��ʵ�����Դ���ڶ�������:һ��ȫ���ں���,������WindowFunction ���� ProcessWindowFunction��
??�������õĴ���������:���ڵ�һ������(�����ۺϺ���)��������������,ÿ��һ�����ݾ���һ�ξۺ�;�ȵ�������Ҫ��������ʱ,����õڶ�������(ȫ���ں���)�Ĵ���������������Ҫע�����,�����ȫ���ں����Ͳ��ٻ�������������,����ֱ�ӽ������ۺϺ����Ľ������������Iterable ���͵����롣һ�������,��ʱ�Ŀɵ��������о�ֻ��һ��Ԫ���ˡ�
??�������Ǿ�һ�������ʵ����˵��������վ�ĸ���ͳ��ָ����,һ������Ҫ��ͳ��ָ��������ŵ�����;��Ҫ�õ����ŵ� url,ǰ���ǵõ�ÿ�����ӵġ����Ŷȡ���һ�������,������url �������(�����)��ʾ���Ŷȡ���������ͳ�� 10 ���ӵ� url �����,ÿ 5 ���Ӹ���һ��; ����Ϊ�˸���������չʾ,��Ӧ�ðѴ��ڵ���ʼ����ʱ��һ����������ǿ��Զ��廬������, ����������ۺϺ�����ȫ���ں������õ�ͳ�ƽ����
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class UrlViewCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// ��Ҫ����url����,����������ͳ��
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// ͬʱ���������ۺϺ�����ȫ���ں���
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
env.execute();
}
// �Զ��������ۺϺ���,��һ�����ݾͼ�һ
public static class UrlViewCountAgg implements AggregateFunction<Event, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
// �Զ��崰�ڴ�������,ֻ��Ҫ��װ������Ϣ
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
// ��ϴ�����Ϣ,��װ�������
Long start = context.window().getStart();
Long end = context.window().getEnd();
// ��������ֻ��һ��Ԫ��,���������ۺϺ����ļ�����
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
}
??��������һ�� AggregateFunction ��ʵ�������ۺ�,ÿ��һ�����ݾͼ�����һ;�õ��Ľ������ ProcessWindowFunction,��ϴ�����Ϣ��װ��������Ҫ�� UrlViewCount,�������ͳ�ƽ����
ע:ProcessWindowFunction �Ǵ��������е�һ��,�������ǻ���ϸ���⡣����ֻ�������������ۺϺ���������������һ�㴰����Ϣ��
??���ڴ��������廹�������ۺ�,������ȫ���ں����ֿ��Ի�ȡ���������Ϣ��װ���,�����Ľ�ϼ�������ִ��ں���������,�ڱ�֤�������ܺ�ʵʱ�Ե�ͬʱ֧���˸��ӷḻ��Ӧ�ó�����
6. ����ˮλ�ߺʹ��ڵ�ʹ��
??֮ǰ����,��ˮλ�ߵ��ﴰ�ڽ���ʱ��ʱ,���ھͻ�պϲ��ٽ��ճٵ�������,��Ϊ����ˮλ�ߵĶ���,����С�ڵ���ˮλ�ߵ����ݶ��Ѿ�����,������Ȼ Flink ����Ϊ�����е����ݶ�������(���ܿ��ܴ��ڳٵ�����,Ҳ����ʱ���С�ڵ�ǰˮλ�ߵ�����)�����ǿ�����֮ǰ����ˮλ�ߴ���WatermarkTest �Ļ�����,���Ӵ���Ӧ����һ�²���:
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// ������Դ��Ϊsocket�ı���,��ת����Event����
env.socketTextStream("localhost", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
})
// ����ˮλ�ߵ���
.assignTimestampsAndWatermarks(
// �������������ˮλ��,�ӳ�ʱ������Ϊ5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// ��ȡʱ�������
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
)
// ����user����,����ͳ��
.keyBy(data -> data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new WatermarkTestResult())
.print();
env.execute();
}
// �Զ��崦�����ں���,�����ǰ��ˮλ�ߺʹ�����Ϣ
public static class WatermarkTestResult extends ProcessWindowFunction<Event, String, String, TimeWindow>{
@Override
public void process(String s, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long currentWatermark = context.currentWatermark();
Long count = elements.spliterator().getExactSizeIfKnown();
out.collect("����" + start + " ~ " + end + "�й���" + count + "��Ԫ��,���ڱպϼ���ʱ,ˮλ�ߴ���:" + currentWatermark);
}
}
}
??�����������õ�����ӳ�ʱ���� 5 ��,���Ե��������ն����� nc ����,Ҳ���� nc �Clk 7777
Ȼ��������������ʱ:
Alice, ./home, 1000
Alice, ./cart, 2000
Alice, ./prod?id=100, 10000
Alice, ./prod?id=200, 8000
Alice, ./prod?id=300, 15000
���ǻῴ�����½��:
���� 0 ~ 10000 �й��� 3 ��Ԫ��,���ڱպϼ���ʱ,ˮλ�ߴ���:9999
??���Ǿͻᷢ��,���������[Alice, ./prod?id=300, 15000]ʱ,���л������Ե�(Ĭ�� 200 ����)����һ��ʱ���Ϊ 15000L �C 5 * 1000L �C 1L = 9999 �����ˮλ��,�Ѿ������˴���[0,10000)�Ľ���ʱ��,���Իᴥ�����ڵıպϼ��㡣������������һ��[Alice, ./prod?id=200, 9000]ʱ,���������κν��;��Ϊ����һ���ٵ�����,�������ڵĴ����Ѿ���������Ȼ��������(����Ĭ�ϱ�����),�������ٽ��뵽������,��ȻҲ�������¼������ˡ������еijٵ�����Ĭ�ϻᱻ����,��ᵼ�¼���������ȷ��Flink �ṩ����Ч�����ٵ����ݵ��ֶ�,���潲��
7. ���� API
����һ���������Ӷ���,���ڷ������ʹ��ں����DZز����ٵġ�����֮��,Flink ���ṩ������һЩ��ѡ��API,�����ǿ��Ը������ؿ��ƴ�����Ϊ��
��ϸ�ɿ��ο�����,�˴�������ϸ����
7.1 ������(Trigger)
??��������Ҫ���������ƴ���ʲôʱ�����㡣��ν�ġ��������㡱,�����Ͼ���ִ�д��ں���,���Կ�����Ϊ�Ǽ���õ����������Ĺ��̡�
??����WindowedStream ����.trigger()����,�Ϳ��Դ���һ���Զ���Ĵ��ڴ�����(Trigger)��
7.2 �Ƴ���(Evictor)
�Ƴ�����Ҫ���������Ƴ�ijЩ���ݵ��������� WindowedStream ����.evictor()����,�Ϳ��Դ���һ���Զ�����Ƴ���(Evictor)��Evictor ��һ���ӿ�,��ͬ�Ĵ������Ͷ��и���Ԥʵ�ֵ��Ƴ�����
7.3 �����ӳ�(Allowed Lateness)
??Ϊ�˽���ٵ����ݵ�����,Flink �ṩ��һ������Ľӿ�,����Ϊ������������һ��������������ӳ١�(Allowed Lateness)��Ҳ����˵,���ǿ����趨�����ӳ�һ��ʱ��,�����ʱ����,���ڲ�������,����������������Ȼ���Խ��봰���в��������㡣ֱ��ˮλ���ƽ����� ���ڽ���ʱ�� + �ӳ�ʱ��,�����������ڵ��������,��ʽ�رմ��ڡ�
??����WindowedStream ����.allowedLateness()����,����һ�� Time ���͵��ӳ�ʱ��,�Ϳ��Ա�ʾ�������ʱ���ڵ��ӳ����ݡ�
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))
7.4 ���ٵ������ݷ���������(��Ҫ)
??������Ȼ���뵽,��ʹ�������ô��ڵ��ӳ�ʱ��,�չ黹������,���������ݻ��ǻᱻ������������붪���κ�һ������,�ָ���ô����?
??Flink ���ṩ������һ�ַ�ʽ�����ٵ����ݡ����ǿ��Խ�δ���봰�ڵijٵ�����,���롰���������(side output)��������Ĵ�������ν�IJ������,�൱������������һ������֧��,������е���������Щ�����˸��ϵij������ñ����������ݡ�
??���� WindowedStream ����.sideOutputLateData() ����,�Ϳ���ʵ��������ܡ�������Ҫ����һ���������ǩ��(OutputTag),������Ƿ�֧�ijٵ�����������Ϊ����ľ������е�ԭʼ����,����OutputTag ����������������������ͬ��
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
??���ٵ����ݷ���������֮��,��Ӧ�ÿ��Խ�����ȡ���������ڴ��ڴ������֮���DataStream,����.getSideOutput()����,�����Ӧ�������ǩ,�Ϳ��Ի�ȡ���ٵ��������ڵ����ˡ�
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
??����ע��,getSideOutput()�� SingleOutputStreamOperator �ķ���,��ȡ���IJ��������������Ӧ�ú� OutputTag ָ��������һ��,�봰�ھۺ�֮�����е��������Ϳ��Բ�ͬ��
8. ���ڵ���������
??��Ϥ�˴��� API ��ʹ��,�����ٻ�ͷ����һ�´��ڱ�������������,��Ҳ�ǶԴ������в�����һ���ܽᡣ
1. ���ڵĴ���
���ڵ����ͺͻ�����Ϣ�ɴ��ڷ�����(window assigners)ָ��,�����ڲ���Ԥ�ȴ�����, ������������������������һ��Ӧ������������ڵ�����Ԫ�ص���ʱ,�ͻᴴ����Ӧ�Ĵ��ڡ�
2. ���ڼ���Ĵ���
���˴��ڷ�����,ÿ�����ڻ������Լ��Ĵ��ں���(window functions)�ʹ�����(trigger)�����ں������Է�Ϊ�����ۺϺ�����ȫ���ں���,��Ҫ�����˴����м������;������������ָ�����ô��ں�����������
���ڲ�ͬ�Ĵ�������,�������������Ҳ�ͬ������,һ�������¼�ʱ�䴰��,Ӧ����ˮλ�ߵ��ﴰ�ڽ���ʱ���ʱ������,���ڡ����㷢����;��һ����������,���ڴ�����Ԫ�������ﵽ�����Сʱ��������,���ڡ������ͷ����������� Flink Ԥ����Ĵ������Ͷ��ж�Ӧ���õĴ�������
�����¼�ʱ�䴰�ڶ���,��ȥ�������ʱ��ġ����㷢����,������һ�����Ρ������������������ӳ�,��ô���ˮλ�߳����˴��ڽ���ʱ�䡢����û�е����趨������ӳ�ʱ��,���ڼ��ڵ���ijٵ�����Ҳ�ᴥ�����ڼ��㡣��������û��ʱ���ϰ���������˳�,��ʱ��Ҫ�ٴ�ͣ��������,���µ���������ͳ�ƽ�����
3. ���ڵ�����
һ�������,��ʱ��ﵽ�˽�����,�ͻ�ֱ�Ӵ����������������������״̬���ٴ��ڡ���ʱ���ڵ����ٿ�����Ϊ�ʹ���������ͬһʱ�̡�������Ҫע��, Flink ��ֻ��ʱ�䴰��
(TimeWindow)�����ٻ���;���ڼ�������(CountWindow)�ǻ���ȫ�ִ���(GlobalWindw) ʵ�ֵ�,��ȫ�ִ��ڲ������״̬,���ԾͲ��ᱻ���١�
������ij�����,���ڵ����ٺʹ��������������ͬ���¼�ʱ��������,��������������ӳ�,��ô��ˮλ�ߵ��ﴰ�ڽ���ʱ��ʱ,��Ȼ�������ٴ���;������������ȫɾ����ʱ���, �Ǵ��ڵĽ���ʱ������û�ָ���������ӳ�ʱ�䡣

??Window API ���Ȱ���ʱ�������ֳ����ࡣkeyBy ֮��� KeyedStream,���Ե���.window()��������������������(Keyed Windows);��������� keyBy,DataStream Ҳ����ֱ�ӵ���.windowAll()�����ǰ����������ڡ�֮��ķ������þ���ȫһ���ˡ�
??������������ͨ��.window()/.windowAll()�������崰�ڷ�����,�õ� WindowedStream; Ȼ �� ͨ �� �� �� ת �� �� �� ( reduce/aggregate/apply/process ) �� �� �� �� �� ��(ReduceFunction/AggregateFunction/ProcessWindowFunction),���崰�ڵľ�����㴦����, ת��֮�����µõ�DataStream�������߱ز�����,�Ǵ�������(WindowOperator)����Ҫ����ɲ��֡�
??����,��������֮��,�����Ի��� WindowedStream ����.trigger()�Զ��崥����������.evictor()�����Ƴ���������.allowedLateness()ָ�������ӳ�ʱ�䡢����.sideOutputLateData() ���ٵ�����д��������,��Щ���ǿ�ѡ��API,һ�㲻��Ҫʵ�֡�����������˲������, ���Ի��ڴ��ھۺ�֮���DataStream ����.getSideOutput()��ȡ���������
�ġ��ٵ����ݵĴ���
��������:����ˮλ���ӳ�ʱ�䡢�������ڴ����ٵ����ݡ����ٵ����ݷ��봰�ڲ������
��ϸ�ɿ��ο�����
�����
Word��:https://download.csdn.net/download/mengxianglong123/85035166
PDF��:https://download.csdn.net/download/mengxianglong123/85035172
��Ҫ�Ŀ���˽����,���