互联网公司 A,以售卖在线广告来获得收入。这家公司想为广告主提供一个实时报表平台,为客户实时分析消费数据,作为广告主投放广告的决策基础。
互联网公司 B,计划开发运营一款 APP。这家公司想对 APP 用户进行行为分析,分析影响用户转换率、留存率的因素。
互联网公司 C,以电子商务为主营业务。这家公司想对订单数据进行分析、实时监测订单状态变更,以动态调整运营策略。
业务属性不同的 A / B / C 三家公司,都想对数据进行实时分析,对它们来说,什么样的系统能够满足需求呢?
首先,系统必须能够存储 PB 级的用户行为日志、广告、订单等数据,并对海量数据进行实时分析,为业务提供数据支撑。再者,A、B、C 公司提供的皆是在线分析服务,考虑到业务实际运行中的软硬件故障,系统必须能够容忍异常、保证服务 7×24 小时可用。
本文将讲述 StarRocks 管理海量数据、提供高可用服务等方面的工作和思考。
01 系统架构
面对海量数据,业界的通行做法是通过搭建分布式集群来进行数据管理。假设有 1PB 数据,考虑到市场主流机型的单机存储容量,集群规模差不多在 100 台节点左右。如此大规模的数据,如何均匀地分布到 100 台节点,如何对其进行并行计算,成为了架构上必须首要解决的两大难题。
StarRocks 采用 Shared-Nothing 架构,数据依照指定规则分布到各个节点。单个节点既有存储也有计算,二者的紧密耦合可以最大限度地实现本地计算,减少网络传输开销。跨节点的数据计算,例如分布式 Join,通过 MPP (Massively Parallel Processing) 框架完成。
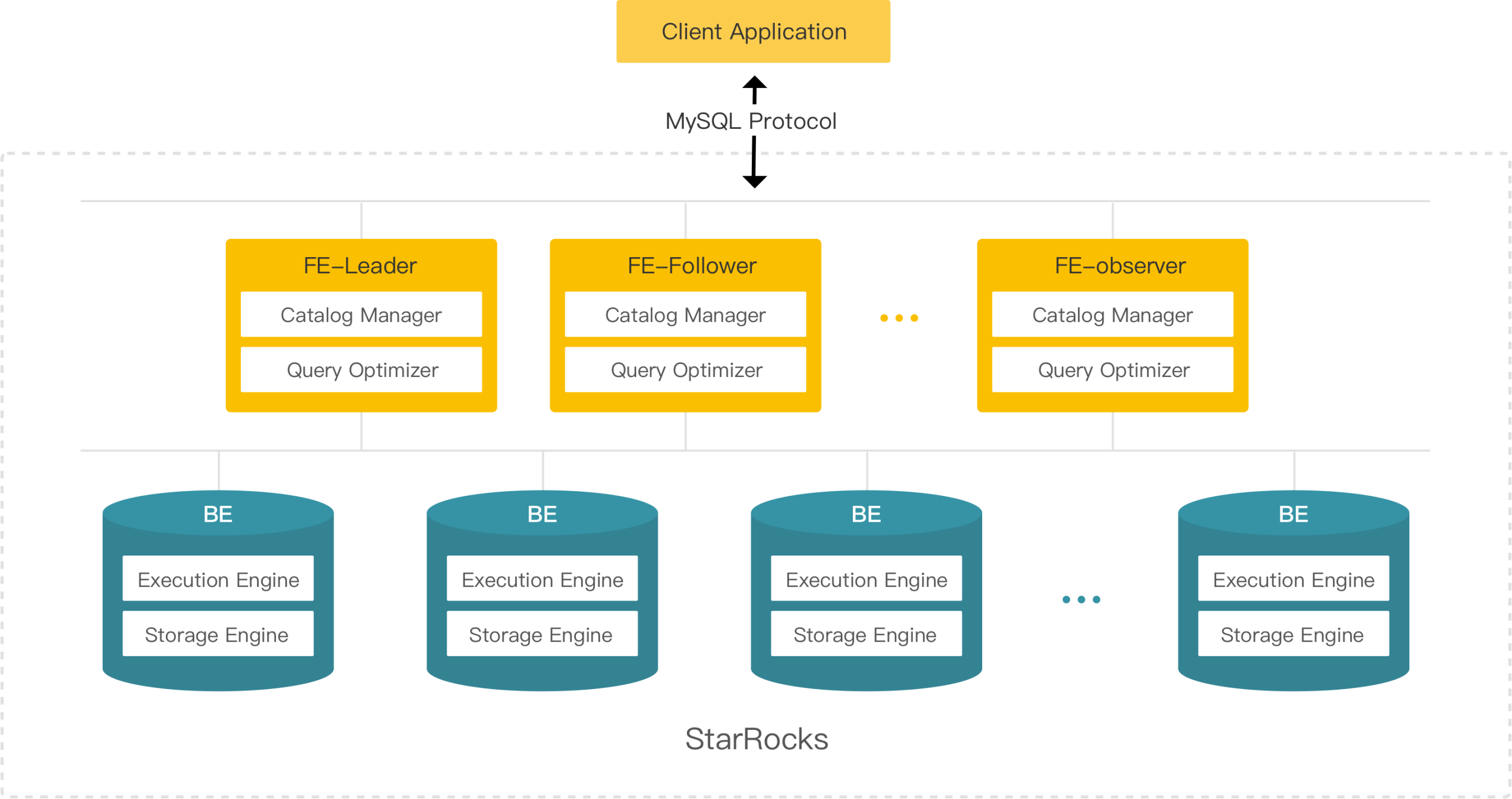
图 1 :StarRocks 整体架构
StarRocks 架构图如图 1 所示。FE 为元数据层,管理所有元数据;BE 为 数据存储层,也负责本地数据的计算。FE 对查询进行规划和分布式调度,并调度 BE 完成数据导入、Online Schema Change 等处理,提供高效的数据服务。
Table 和 Tablet
若要描述数据如何分布,必然牵扯到 StarRocks 的数据模型,即 StarRocks 提供什么接口来让用户定义数据。作为一款 OLAP 数据库,StarRocks 的数据模型服从关系模型。通过如图 2 所示的一个 SQL 语句,可以描述 StarRocks 对数据的定义。

图 2 :StarRocks Table Schema
图 2 中 bigdata 除定义数据类型之外,还定义了分区、分桶等数据分布的方式。bigdata 以季度为分区粒度,每个季度一个分区。分区内的数据,又再次进行 Hash 分桶,将其划分成 100 个 Tablets。Table -> Partition -> Tablet 三者之间的关系可以表示为图 3。

图 3 :Table / Partition / Tablet 三者之间的关系
Tablet 为数据管理的最小单元,无论多大数据规模的 Table 都可以拆解成一组 Tablets,统一进行管理。导入时,数据依据分区、分桶的定义,写到指定 Tablet;查询时,数据根据查询条件自动路由到相应 Tablet。
我们所展示的图 2 中,bigdata共有 400 个 Tablets。现假设有 100 台节点,StarRocks 会如何均匀地把这些 Tablets 存储到 BE 中呢?
FE 会均匀调度每台 BE 存储 4 个 Tablets。对于某个 BE 节点存储哪些 Tablets,没有静态绑定。FE 在保证数据可用性和可靠性的条件下,会动态调度 Tablets 数据到不同的 BE 上,以实现数据的更优分布。比如,当一个 BE 节点磁盘空间满,Tablet 就可能被移动到更空闲一些的 BE 节点。Tablets 数据迁移由 StarRocks 自动完成,无需人工干预,所有查询和导入正常在线运行而不受影响。
通过这种拆分 Tablet 的方式,业务方在扩缩容 BE 节点时,FE 将根据策略,在不同 BE 之间移动部分少量的 Tablets 即可自动快速实现数据均衡。而其他采用传统 MPP 数据库架构的系统,比如 ClickHouse,将全部表数据按照集群节点组成静态分布到各个节点上。在集群伸缩时,需要将全部数据进行重新 Sharding 和分布以实现较好的数据均衡。
整个过程需要移动所有的数据,而且写入服务需要暂停。整个过程往往需要手动操作,非常复杂,并且易出错。而 StarRocks 基于 Tablets 切分和迁移的自动伸缩机制具备非常好的线性扩展能力,整个过程完全自动执行,无需手动操作,无需停服。
MPP 计算引擎
解决完 Tablet 分布难题之后,紧接着要面对的是如何计算 Tablet 数据,获取业务指标数据。StarRocks 会利用 Tablet 数据的本地性,尽可能在靠近 Tablet 的地方完成更多算子的计算,减少网络数据传输。另外 StarRocks 采用 MPP 执行框架,多机并行执行查询。
于是,不论用户执行的是 Sort、GroupBy 还是 Join,StarRocks 都能最大限度地能够利用集群资源进行计算。相对于 ClickHouse 和 Druid 等采用的 Scatter-Gather 模式,StarRocks 的 MPP 架构可以有效避免单点瓶颈,更好利用集群整体的资源。
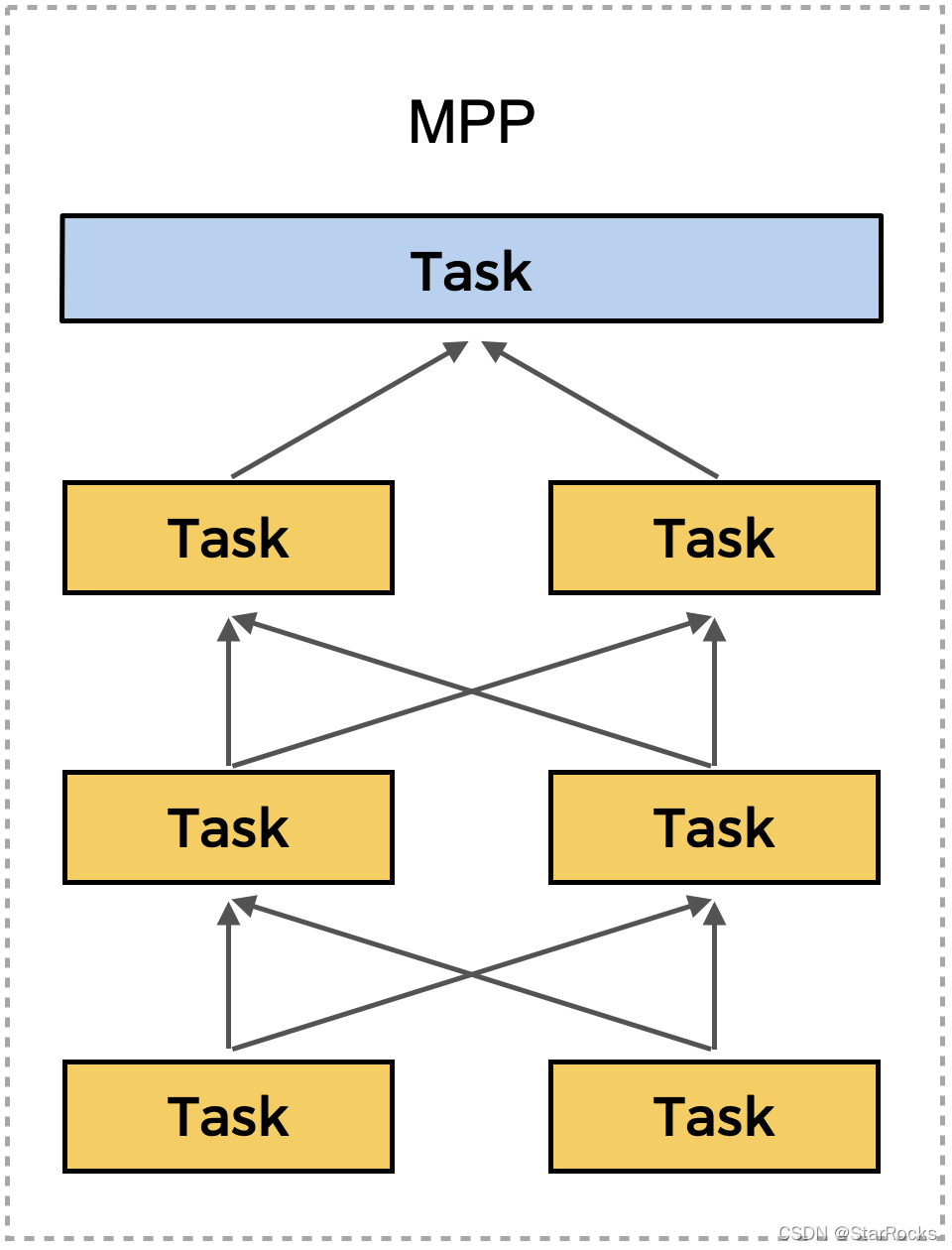
图 4 :StarRocks 的 MPP 执行框架
02 元数据和数据的高可用
StarRocks 元数据具体可分为三类:表 Schema,Tablet 的位置信息 ,节点状态。
作为集群的大脑,元数据每时每刻都可能被修改。频繁写入的过程中,为保证元数据的可用性,StarRocks 内嵌一个 BDB-JE 数据库进行元数据同步,此机制类似raft复制协议。每条写入日志会实时同步给多数派副本 (线上推荐三副本),多数副本写入成功才能返回给客户端成功信息。
与元数据一样,Tablet 也冗余多副本进行存储,默认三副本。单次导入的数据,同步发给三个副本,由它们各个写入自己的数据存储引擎中,当其中两个副本完成写入时,即可认为这批次导入完成。所有的导入任务统一由 FE 进行任务调度和事务协调,Tablet 的三个副本所在的 BE 之间无需运行类似 Raft 之类的复制协议。如果某个节点因为故障,没有写入最新数据,在节点恢复后,FE 将根据节点状态调度 Clone 任务给对应的 BE,BE将追平数据,从而保持三个副本一致。
FE 管理 Tablet 多个副本时,保证多个副本不落在相同节点上,从而防止单点故障导致数据丢失。FE 也可以根据策略动态在不同BE上创建和删除 Tablet 副本,实现 Tablet 数据在不同 BE 之间的自动数据均衡。整个过程之中,查询和导入不受影响。Tablet 各个副本在集群之中的分布如图 5 所示。
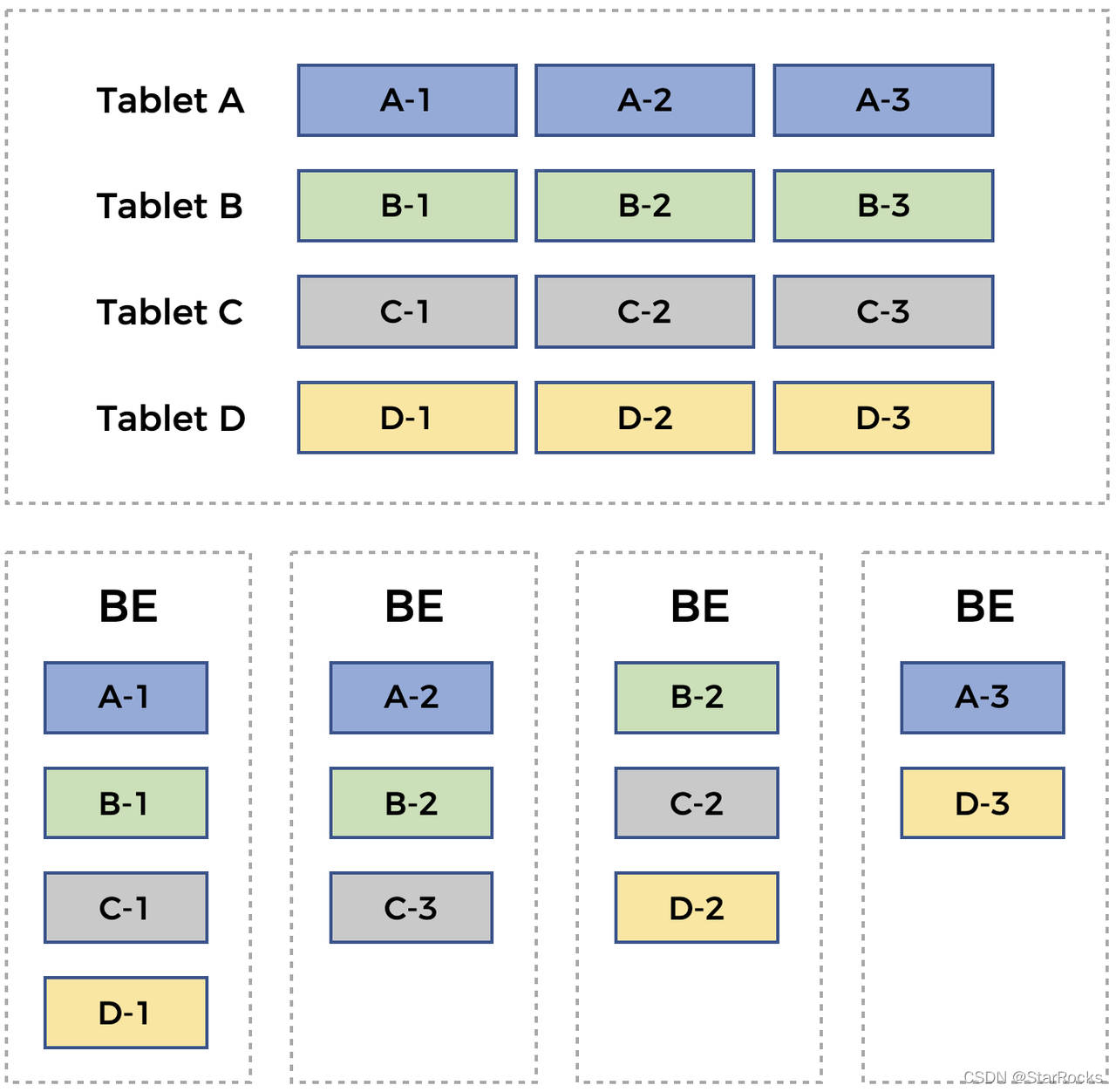
图 5 :Tablet 多副本在集群中的分布
03 数据导入
StarRocks 的实时导入主要面向分钟级别或者秒级别数据导入。以最常见的数据来源 Kafka 来说,StarRocks 原生支持订阅 Kafka、自动分批导入,每隔一定的间隔周期,提交一次导入。用户在使用过程中,只需在 StarRocks 中创建一个针对 Kafka 的例行导入任务即可。
之所以采用微批(MiniBatch)来进行实时导入,而不是单条单条实时导入,主要是考虑到 OLAP 系统导入请求的两个特性:
分钟级或者秒级导入可以满足大多业务对时效性的要求。
单条高频写入,需要系统设计非常复杂的存储机制来支持,而且系统吞吐能力会降低,也往往无法具备非常好的事务保障。StarRocks采用微批方式可以大大提升数据写入吞吐能力,并且对导入支持事务保证,这对减轻用户开发应用的成本非常关键。如果一个订单表在同步完 MySQL 数据之前能被查询到,查询结果很可能会对业务方造成困扰。
那么 StarRocks 如何保证实时导入事务?
StarRocks 使用经典的两阶段提交(Two-Phase Commit)方式,对单次导入进行处理。当导入事务完成时,StarRocks 为导入分配一个 Version,通过 MVCC(Mulit-version Concurrenyc Control)解决事务之间的冲突。
可以设想这样一种情形:某个查询带着 Version 100 进行数据扫描,整个执行过程超过一分钟;一分钟内,如果有新导入完成,其会被赋予Version 101、Version 102;通过Version,查询可以过滤掉 Version 100 和 Version 101 对应的文件,保证查询可以基于正确的数据快照进行计算。
04 Online Schema Change
业务运行过程中,Schema 变更不间断发生。这种变更,可能来自于分析维度变化,导致的加列、减列需求;也可能来自于构建索引、加速查询的需求。如果 Schema 变更中能不中断业务,可极大缓解 DBA 运维集群的压力。他们不用通知业务方暂时中止业务、等待变更结果,节省了协调各方面业务方的时间,也大大减少了手工运维工作和失误。
Online Schema Change将基于原有数据表(原表)生成一张新的数据表(新表)。整个过程分为三个阶段 t1、t2、t3。
t1: 收到 Schema Change 请求。此时,同时存在着正在运行的导入任务,需等待这部分导入任务完成,才能下发 Schema Change 任务。
t2: t1 之前的导入已经完成,直接下发 Schema Change 任务。至于 [t1, t2] 之间的导入任务,FE 会调度生成两份数据,一份给原表,一份给新表。
t3:BE 完成了Schema Change。FE 对原表和新表进行原子交换,Schema Change 完成。
整个过程中,原有schema的数据导入和查询能够正常运行,查询会基于原表进行。Schema Change 完成之后,查询会基于新表进行,业务方也可以导入新schema的数据。

图 6:Online Schema Change 流程
05 总结
本文着重介绍了 StarRocks 在大数据管理方面的工作,主要是从高可用、自助管理海量数据等角度进行了阐述。当然这只是 StarRocks 功能的冰山一角,高效列存数据组织、物化视图、数据合并(Compaction)、延迟物化(Late Materialization)等更多功能将在系列文章中进行介绍。
随着越来越广泛地应用到各大公司, StarRocks 正不断迭代,帮助用户创造更大价值。身处公有云时代,StarRocks 也在积极打造存储计算分离的 Cloud Native 新架构,相关成果敬请期待。
作者
李超勇 | StarRocks 核心研发
负责 StarRocks 的新型列式存储引擎、物化视图以及元数据管理等方面的研发工作。