编者按:本文详细介绍 Milvus 2.0 如何对查询节点的数据进行管理,以及如何提供查询能力。
快速回顾 Milvus 进行数据插入与持久化相关的流程与机制
Milvus 架构快速回顾
数据插入流程
数据组织机制
如何将数据加载进查询节点 query node
数据加载流程详解
数据管理与维护
Milvus 上实现实时查询的相关操作和流程
快速回顾 Milvus 进行数据插入与持久化相关的流程与机制
Milvus 架构快速回顾
如下图所示,Milvus 向量数据库的整体架构可以分为 coordinator service、worker node、 message ?storage 和 object storage 这几大部分。
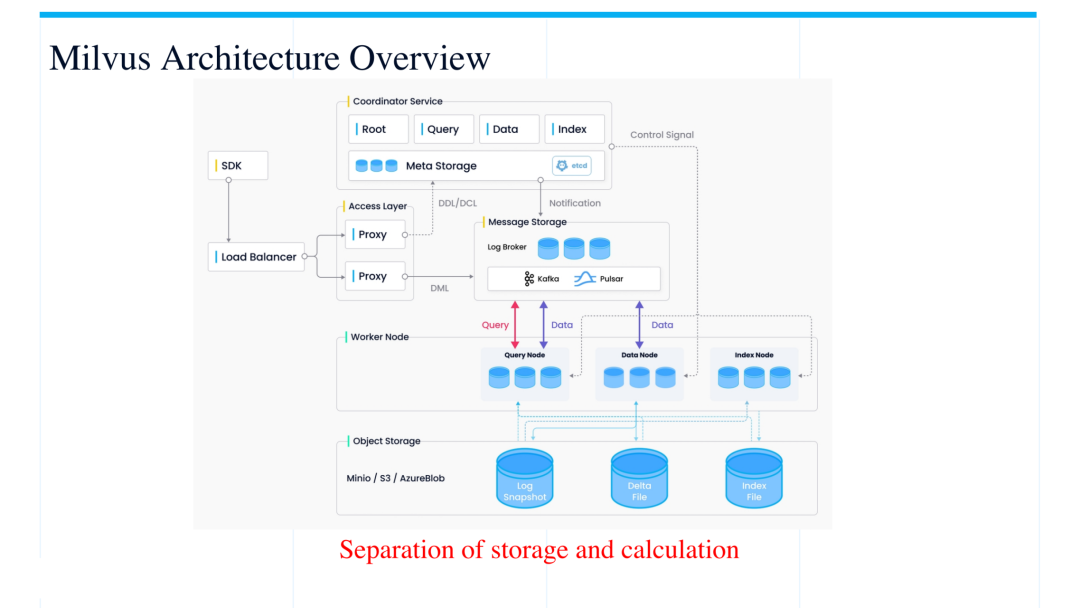
Coordinator services 承担的主要工作是协调各个 worker node 的工作,其中的各个模块与 worker node 是一一对应的关系,并协调管理各个 node 之间的工作。如架构图中所示,query coordinator 对应并协调 query node,data coordinator 对应并协调 data node,index coordinator 对应并协调 index node。Data node 负责数据的持久化存储,基本上是一个 I/O 密集型的工作负载,负责把数据从 log broker 中写到最终的 object storage 当中。而 index node 负责实现向量索引的构建,最后由 query node 来承担整个 Milvus 的查询工作,这两类 node 是数据计算密集型的节点, 除此之外,系统架构中还有两个比较重要的部分:message storage 和 object storage。Message storage 相当于一个 WAL 的东西,当数据插入到这个地方之后,系统会保障数据不会有丢失。其中的 log broker 会默认将数据存放 7 天,这期间即使下面的 worker node 出现了部分宕机的情况,系统也可以从 log broker 中恢复一些数据及状态。Object storage 负责实现数据持久化存储,log broker 里面的数据最终都会持久化到 object storage 里面,以进行数据的长期保存。
总体来说这个架构相当于一个存储与计算分离的一个系统, data ?这边负责数据存储,然后 query 这边负责查询计算。
数据插入流程
![]()
第一步:Insert message 从 SDK 发到 proxy 之后,proxy 把这个 insert ?message 插到相应的 log broker 中,插入到 log broker 中的每条消息都有唯一的主键和一个时间戳;
第二步:插入到 log broker 之后,数据会被 data node 消费;
第三步:Data node 会把数据写入进持久化存储当中,最终数据在持久化存储中是基于 segment 的粒度来组织的,也就是说这个消息除了中主键和时间戳,还会被额外赋予一个 ?segment ID,以标识出这条数据最终会属于哪个 segment。Data note 在收到这些信息之后,会把相应的信息写入相应的 segment 中,并最终写入到持久化存储中去。
第四、五步:在数据被持久化之后,如果说基于这些数据直接做查询的话,查询速度会比较慢,因此一般情况下会考虑去构建一些索引去以加速查询速度。这时 index node 就会把信息从持久化存储里拉出来并构建索引,而构建的索引文件又会被回写进持久化存储中(S3 或 Minio 等等)。有时我们会需要构建多个索引,以从中选挑选出其中查询速度最快的一个,这样的操作也可以在 index node 中实现。
Log broker 和 object storage 也是 Milvus 架构中保障数据可靠性很重要的两部分,在系统设计中这两部分也可以分别选择一些第三方组件,来保障不同情况下的可靠性。
![]()
一种常见的情况,是在查询的同时也进行数据插入,这时一部分数据处在 log broker 中,而一部分数据处于 object storage 里面。我们把这两部数据分别做了定义,在 object storage 里面的数据为 批数据,而在 log broker 里面的是流数据。显而易见,在做实时查询的场景下,如果想遍历所有已经插入的数据,则必须要在流数据和批数据里同时做查询,才能返回正确的实时查询数据。
数据组织机制
接下来看一下数据存储的相关机制,数据分两部分存储。一部分是在 object storage;一部分是在 log broker。
首先看一下在 log broker 里面,数据的组织形式是怎样的呢?
可以看参考下图,数据可分成这几部分:唯一的 collection ID、唯一的 partiton ID、唯一 的 segment ID。
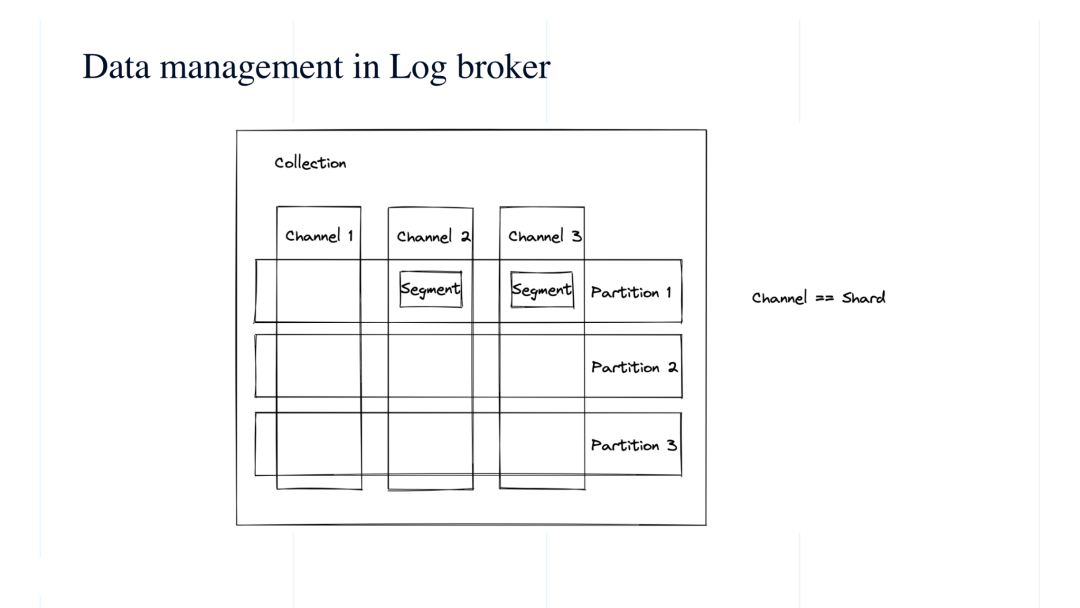
每个 collection 在系统里面都会分配指定数量的 channel,可以理解成是类似 Kafka 中的 topic, 或类似传统数据库里面的 shard 的概念。
在图示中,假如我们对 collection 分配了三个 channel,假设我们要插入 100 条数据,那么这 100 条数据会平均的分到这三个 channel 中,然后在三个 channel 里面,数据又是以 segment 为粒度进行拆分。目前每个 segment 的容量是有上限的,系统默认最大到 512M。在持续的数据插入过程中,会优先持续往一个 segment 中写入,但如果容量超过 512M,系统会新分配一个 segment ID 继续数据插入。所以在真实的场景中,每个 channel 里面都会包含很多个 segment。总结来说,数据在 log broker 中,可以拆分成,collection、partition 和 segment,最终我们存储在系统里面,实际上是很多个小的 segment。
接下来,我们再看一下在 object storage 中的数据组织方式。与 log broker 一样,data node 在收到 insert message 之后,也是按照 segment 进行组织的。当一个 segment 达到 512M 的默认上限时,或者用户直接强制停止对这个 segment 插入数据,这时 segment 会被持久化存储进 object storage当中。在持久化存储中,每个 segment 中的存储格式是一个一个更小的 log snapshot ,而且是分成多列的。具体的这个列数是和待插入的 collection 的 schema 有关。如果 collection 的 schema 有 4 列,数据插入 segment 中也会有 4 列。所以,最终在 object storage 中,数据存储的形式是很多个 log snapshot。
![]()
如何将数据加载进查询节点 query node
数据加载流程详解
在明确了数据的组织方式后,接下来我们看看数据进行查询加载的具体流程。
在 query node 中,把 log?broker?中的流数据称为 streaming,把 object storage 中的批数据称为 historical。流数据和批量数据的加载流程如下:
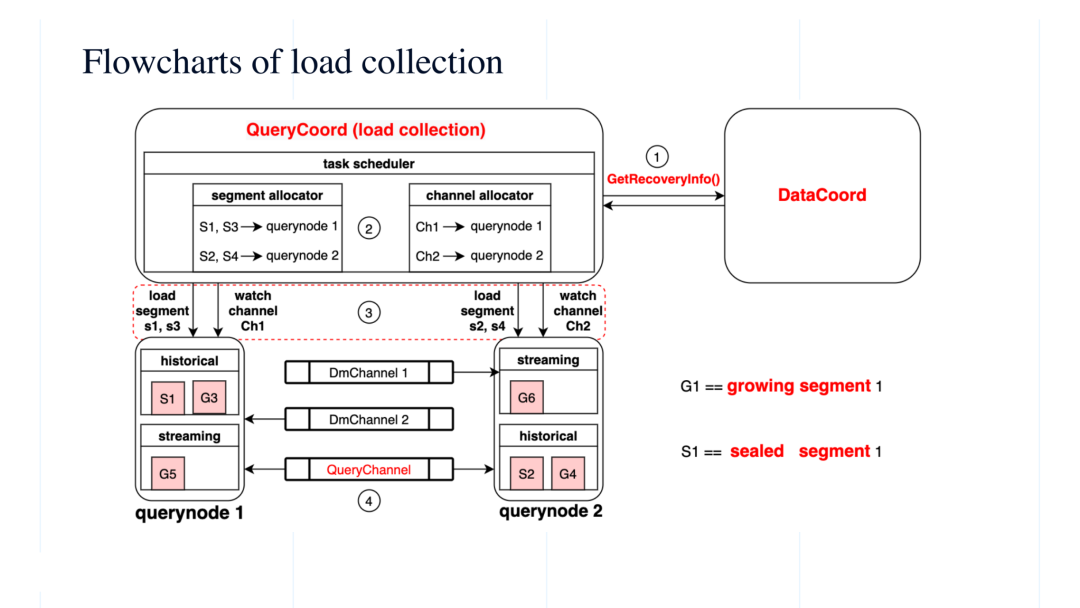
首先,query coord 会询问 data coord。Data coord 因为一直在负责持续的插入数据,它可以反馈给 query coord 两种信息:一种是已经持久化存储了哪些 segment,另一种是这些已经持久化的 segment 所对应 checkpoint 信息,根据 checkpoint 可以知道从 log broker 中获得这些 segment 所消费到的最后位置。
接着,在收到这两部分信息后,query coord 会输出一定的分配策略。这些策略也分成两部分:按照 segment 进行分配(如图示 segment allocator),或按照 channel 进行分配(如图示 channel allocator)。
Segment allocator 会把持久化存储- 也就是批数据- 中的不同的 segment 分配给不同的 query node 进行处理,如图将 S1、S3 分配给 query node 1,将S2、S4分配给 query node 2。Channel allocator 会把 log broker 中不同的 channel 分配给不通的 query node 进行监听,如图 query node 1 监听 Ch 1, query node 2 监听 Ch 2。
这些分配策略下发到各个 query node 之后,query node 就会按照策略进行相应的 load 和 watch 操作。如图示 query node 1 中,historical (批数据)部分会将分配给它的 S1、S3 数据从持久化存储中加载进来,而 streaming 部分会订阅 log broker 中的 Ch1,将这部分流数据接入。
因为 Ch1 可以持续不断的插入数据(流数据), 而由这部分接入 query node 中的数据我们定义为 growing segment,因为会持续不断的增长,是增量数据,如图示的 G5。相对应的,histroical 中的 segment 定义 sealed segment,是静态的存量数据。
数据管理与维护
对于 sealed segment 的的管理,系统的设计主要考虑负载均衡和宕机的情况。
![]()
如图示,假如 query node 4 ?上面有很多这个 sealed segment ,但是其他节点比较少,在这种情况下 query node 4 的查询可能是整个查询里面的一个瓶颈。所以这时,系统就要考虑说把这些 sealed segment 负载均衡到到其他节点上去。
另一种情况,如果某一个节点突然挂掉了,这个时候它上面的负载也能够快速的迁移到其他正常节点上,以保证查询到的结果是正确的。
对增量数据来讲,刚才提到说 query node 监听相应的 dmchannel 之后,这些增量数据都就会进入到 query node 里。但具体是怎么进入的呢?这里我们用到了一个 flow graph 模型,一种状态驱动的模型,整个 flow graph 包括 input node, filter node, insert node 和 service time 四部分。首先,input node 负责从流里面收到 Insert 消息,然后 filter node 对消息进行过滤。为什么需要过滤呢?因为用户可能仅需要加载 collection 下的某一个 partition 数据。过滤完之后,insert node 把这些数据插到底层的 growing segment 中,在这以后 server time node 负责更新查询的服务时间。
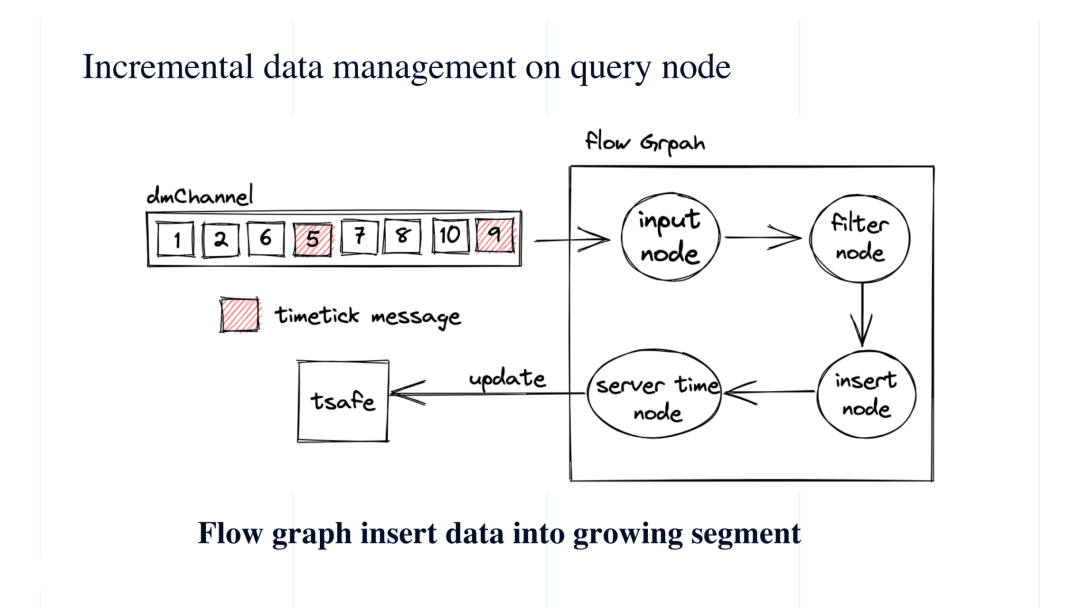
最开始我们回顾数据 insert 流程时提到,每一条 insert message 中都有分配了一个时间戳。
大家可以参看图示左侧的例子,假如说数据从左到右只依次插入,那么第一条消息插入的时间戳是 1,第二条消息插入的时间戳是 2,第三条消息操作时间戳是 6,第四条这里为什么标红呢?这是系统插入的 timetick message,它代表的不是 insert message。Timticker 表示 timestamp 小于这个 timetick 的插入数据都已经在 log broker 中了。换句话说,在这个 timetick 5 之后出现的 insert message ?它们所对应的时间戳不会小于 5,可以看到后面的几条时间戳分别是 7、8、9、10,时间戳都是大于 5 的,也就是说时间戳小于 5 的 insert message 消息肯定都会出现在左侧。换句话说,当 query node 收到 timetick = 5 的消息时,可以确定说时间戳在 5 之前的所有消息都已经进入到 qurey node 中,从而来确认查询的正确。那么这里的server time node 就是在从 insert node 接收到 timetiker 后,比如图示的 5 或 9,会更新一个 tsafe, 相当于一个表示安全的时间戳,只要 tsafe 到了 5,那么 5 之前的数据都是可以查的。
有了这些铺垫,下面开始讲如何真正的做 query 的这部分。
Milvus 上是实现实时查询的相关操作和流程
首先讲一下查询请求(query message)是如何定义的。
Query message 同样由 proxy 插入到 log broker, 在之后 query node 会通过监听 log broker 中的 query channel, 来获取到 query message。
Query message 具体长什么样呢?
![]()
-
Message ID,对这个查询系统分配的一个全局分配的 ID;
-
Collection ID:query 请求对应的 collection ID,假如说 query 是制定在 collection 中查询,那么它要指定对应的 collection ID。当然在 SDK 那边,其实这个地方指定的是 collection name, 在系统内会对 name 和 ID 做一对一的映射。
-
execPlan:执行数,对应 SDK 那边的操作,相当于在 SDK 做查询的时候指定了表达式,也就是一个 PR 。对于向量查询来讲,主要是做属性过滤的,假如说某一个属性大于 10 或者是等于 10 做一些使用过滤。
-
Service timestamp:上文提到的 tsafe 更新之后,service timestamp 也会相应更新,用来说明现在服务的时间到哪个点了,在此之前插入的数据都可以进行查询。
-
Travel timestamp:如果需要对对某一个时间段之前的数据进行查询,可以通过 (services timestamp - travle timestamp)来标定新的时间戳和数据范围;
-
Guarantee timestmap:如果需要对某一个时间段之后的在进行数据查询,只有当 services timestam 大于等于 guarantee timestamp 这个条件满足时,查询工作才会开始。
现在看一下具体的查询操作流程:
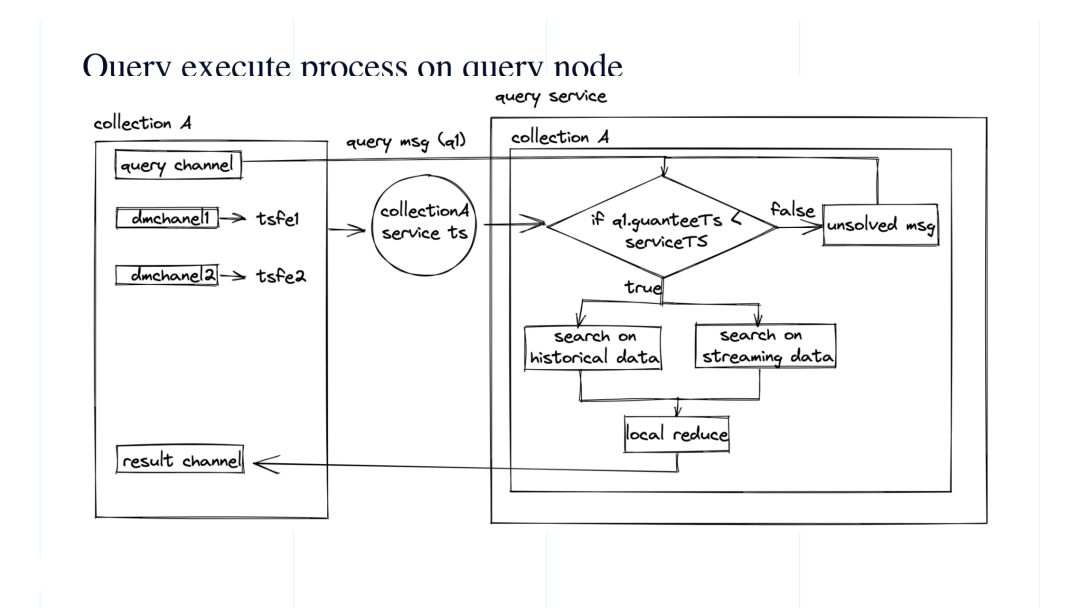
收到 query message 之后,系统会先去做一个判断,如果 service time 大于 query message 中的 guarantee timestamp,那么就会执行这个查询。查询分成两个同时并行的部分, 一部分是持久化存储的 historical data,另一部分是 log broker 中的 streaming data。最后会做一个 local reduce 。之前也讲过 historical 和 streaming 中间因为种种原因是可能会出现一些数据的重复的,那么这里最后就需要先做一个 reduce。
以上是比较顺利的流程。而如果说在第一步判断时间戳是,可服务时间还没能推进到 guarantee timestamp,那么这个查询会放进 unsolved meessage, 一直等待,直到满足条件可以进行查询。
最终结果会被推送到 result channel,由 proxy 来接受。当然 proxy 会从很多 query node 上面接受结果,也会在做一轮 global reduce。到此整个查询流程完毕。
但这里还有一个问题,就是 proxy 在向 SDK 返回最终结果之前,如何去确定已经收到了全部的查询结果。为此我们做了一个策略:在返回的 result message 中,也会记录下,哪些 sealed segments被查询过 (searched sealed segments),以及哪些 dmChannel 被查询过(dmchannels searched), 以及在 querynode 上有哪些 segment (global sealed segments)。如果所有 query node 的 search result 里 searched sealed segments 的并集大于 global sealed segments,而且这个 collection 的所有 dmchannel 对应的增量数据都被查询过,就认为所有的查询结果都收到了,proxy 就可以进行 reduce 操作,并将结果最终返回给 SDK。
完整版视频讲解请戳:https://www.bilibili.com/video/BV1cg411F7wd?spm_id_from=333.337.search-card.all.click
如果你在使用的过程中,对 Milvus 有任何改进或建议,欢迎在 GitHub 或者各种官方渠道和我们保持联系~
Zilliz?以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz?构建了?Milvus?向量数据库,以加快下一代数据平台的发展。Milvus?数据库是?LF?AI?&?Data?基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。

