在传统的mysql 主从复制架构:
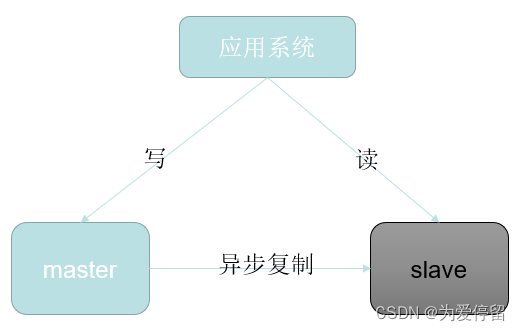
其mysql master对slave节点时异步复制,有可能会导致客户端读到的数据是脏数据,则如何要求mysql集群中各节点保持严格的数据一致呢?用PXC集群来搭建mysql集群:
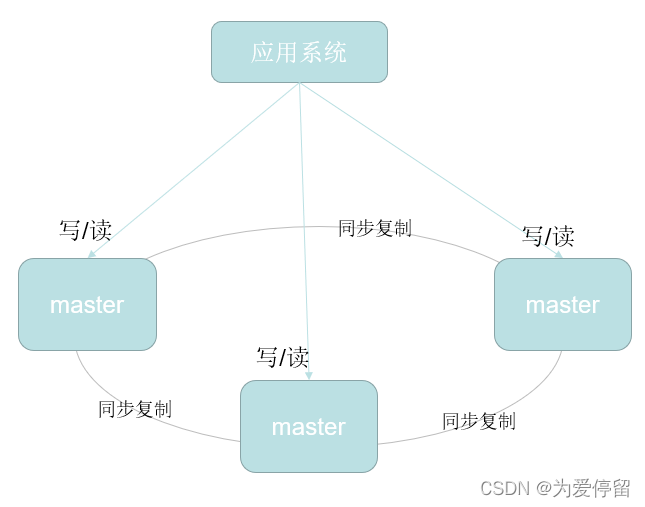
可见,pxc mysql集群,是多主结构,每个节点可读可写,且数据都保持一致?
mycat进行分库分表
mycat 表分为:逻辑表,e-r表,分片表,全局表,非分片表
?如:schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<table name="config" primaryKey="id" type="global" dataNode="dn1,dn2" />
<table name="user" primaryKey="id" dataNode="dn1,dn2" rule="mod-long" autoIncrement="true" fetchStoreNodeByJdbc="true">
<childTable name="course_user" primaryKey="id" joinKey="user_id" parentKey="id"> </childTable>
</table>
<table name="order" primaryKey="id" autoIncrement="true" fetchStoreNodeByJdbc="true" dataNode="dn3" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="my_test" />
<dataNode name="dn2" dataHost="localhost2" database="my_test" />
<dataNode name="dn3" dataHost="localhost3" database="my_test" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W1" url="jdbc:mysql://192.168.211.128:3306" user="root" password="root">
<readHost host="W1R1" url="jdbc:mysql://192.168.211.128:3307" user="root" password="root" />
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W2" url="jdbc:mysql://192.168.211.128:3316" user="root" password="root">
<readHost host="W2R2" url="jdbc:mysql://192.168.211.128:3317" user="root" password="root" />
</writeHost>
</dataHost>
<dataHost name="localhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="W3" url="jdbc:mysql://192.168.211.128:13306" user="root" password="root">
<readHost host="W3R1" url="jdbc:mysql://192.168.211.128:13307" user="root" password="root" />
<readHost host="W3R2" url="jdbc:mysql://192.168.211.128:13308" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>config表是全局表
order表是非分片表
course_user是 user 的e-r表
user和course_user都是分片表
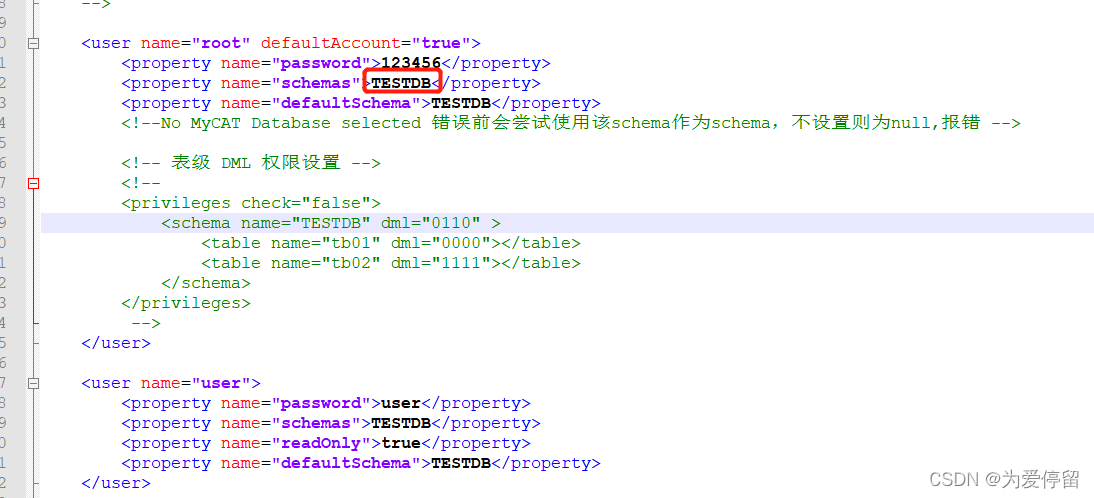
看server.xml,root用户下配置的逻辑库是TESTDB,逻辑库可以看到全量数据
?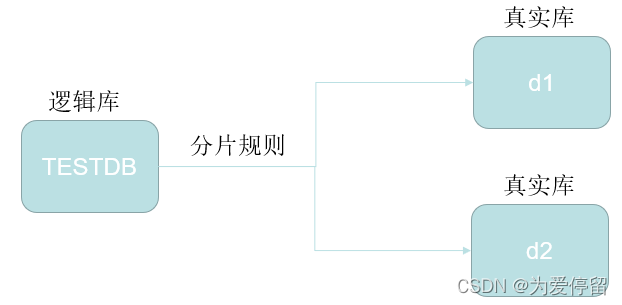
注意:在逻辑库中创建表一定要在schema.xml中配置的表,否则创建不了?
?如果需要单库分表的话,则分库的分片规则,要根据非主键id去分库,分表的分片规则可以根据主键去进行分片,分片规则都可以在rule.xml配置
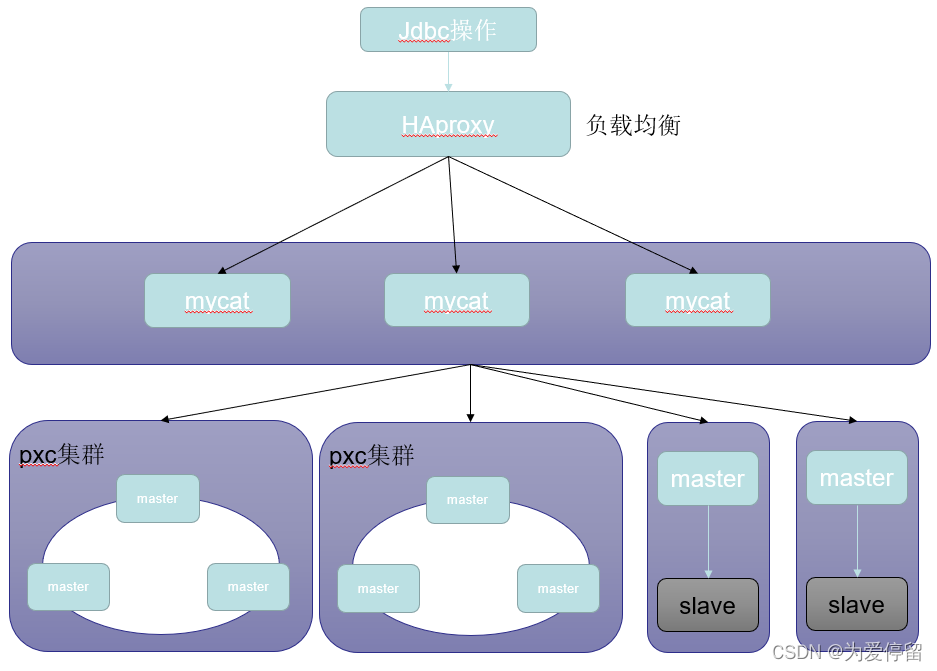
?高一致性集群方案设计
HAProxy可以承载千万级并发,当然在一定的硬件条件下: