目录
6、数据仓库、datamarket、datahub、datalake、数据中台含义
学习hive --》官网
一、hive简介
hadoop 广义上:大数据生态圈,其中hive是使用SQL完成大数据统计分析的工具
狭义上:HDFS MR YARN
HDFS :hive的数据是存在HDFS上的(Distributed storge?分布式存储),元数据(Metadata)存储在对应的底层关系数据库。一般是Mysql
MR(计算引擎):hive的作业(sql)是通过hive的框架,翻译成MR作业
这里的引擎也可以是 Tez,Spark
不管底层使用什么引擎,对于用户来说是不感知的,同样的sql,只需要通过参数切换就可以实现。
YARN:hive的作业是提交到YARN上去运行的
hadoop开发可以是单机,但生产上一定是分布式
hive其实就是一个客户端,没有集群的概念,提交作业到集群的yarn上面去运行(没有感情的提交机器)
SQL--》 Hive --》MR --》YARN
生产环境上,哪台机器需要提交hive,就在哪台机器上配置hive,不同机器上的hive是相互独立的
总结:hive职责,将sql翻译成底层对应的执行引擎作业?
Distributed storge?分布式存储
HDFS ,AWS S3 ,各种云 OOS COS
这些系统,hive都可以对接,只需要有相应的jar包,本地的文件系统(File开头)也可以对接
Metadata 元数据
统一的元数据管理
元数据:描述数据的数据
源数据:来源系统的数据,HDFS数据,各个数据库的数据

?spark? ?impala? ?presto? 等等,统一可以使用Metadata
也就是说? hive里建的表? ? sparksql?也可以使用
二、hive比较关系型数据库
| hive | RDBMS(关系型数据库) | |
| 分布式 | 支持 | 支持 |
| 节点 | 支持 | 支持 |
| 成本? | 廉价 | 昂贵 |
| 数据量 | TB? PB | GB |
| 事务? ? | 支持 | 支持 |
| 延时性 | 高 | 低 |
| DML | 0.14之后支持(但是不建议用) | 支持? |
三、hive适用场景
批处理 / 离线处理
四、 hive的优缺点
优点:易上手,比MR使用起来简单多了
缺点:延时性高
五、一些问题
1、Hive的执行速度对比于Mysql谁快
没有对比性,具体问题具体分析
2、hive?sql? 和mysql?sql? 有什么关系
除了语法类似之外,没有任何关系
?六、hive安装
1、解压压缩包,并更名如下:

?2、?hive一些目录整理
| bin? | 可执行的文件 |
| conf? | 配置文件 |
| lib | hive相关的jar包 |
3、添加hive环形变量
在? /etc/profile?中添加

#HIVE_HOME
export HIVE_HOME=/home/peizk/app/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin?source? 一下? 使其生效
4、配置文件
[peizk@hadoop conf]$ vim hive-site.xml
内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>导入jar包到?hive? lib?下??

?
5、初始化元数据
(1)创建一个元数据库
mysql> create database metastore;
Query OK, 1 row affected (0.00 sec)
(2)初始化
[peizk@hadoop conf]$ schematool -initSchema -dbType mysql -verbose
hive启动一下,show? databases
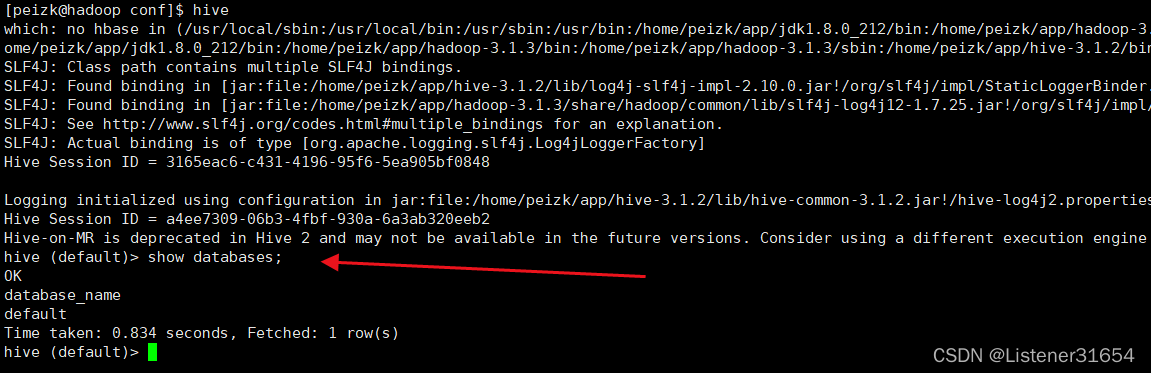
?出现? ok!
初始化成功
6、测试
创建一个表?插入一条数据
hive (default)> create table test0401(id bigint,name string);
OK
Time taken: 0.478 seconds
hive (default)> insert into test0401 values(1,'zhangsan');
Query ID = peizk_20220402153441_0c2729a1-961c-46ad-a03e-ef60c85e3af7
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2022-04-02 15:34:44,673 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local1960812315_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop:9000/user/hive/warehouse/test0401/.hive-staging_hive_2022-04-02_15-34-41_544_4957939646936871229-1/-ext-10000
Loading data to table default.test0401
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 166 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_col0 _col1
Time taken: 3.488 seconds
hive (default)> select * from test0401;
OK
test0401.id test0401.name
1 zhangsan
Time taken: 0.126 seconds, Fetched: 1 row(s)
hive (default)>
?查看hdfs? 有
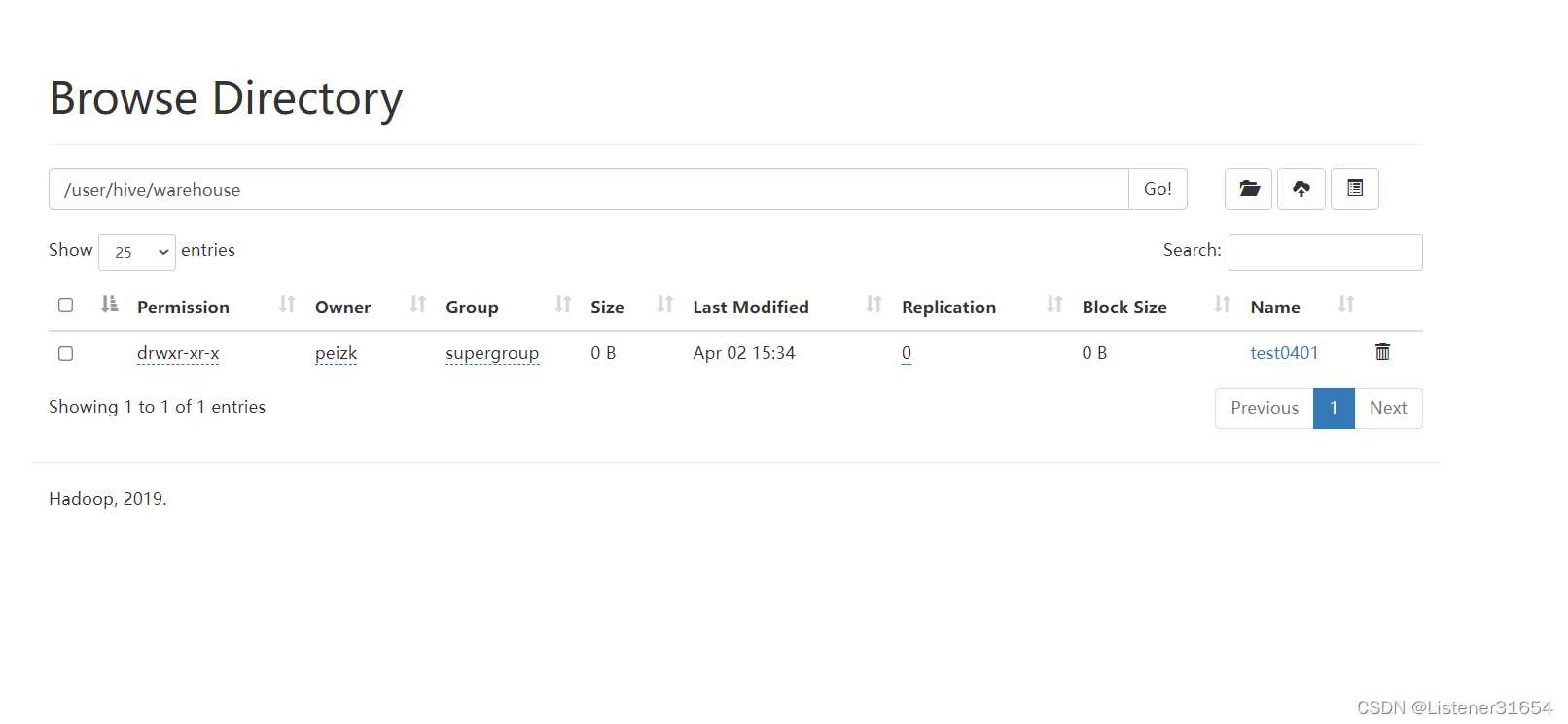
查看目录下文件内容
[root@hadoop ~]# hadoop fs -cat /user/hive/warehouse/test0401/*
2022-04-02 15:41:10,235 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1zhangsan
查看下mysql下metastore下? tbls? ?元数据
mysql> select * from TBLS;
+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED |
+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
| 1 | 1648884858 | 1 | 0 | peizk | USER | 0 | 1 | test0401 | MANAGED_TABLE | NULL | NULL | |
+--------+-------------+-------+------------------+-------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
1 row in set (0.00 sec)
mysql>
7、修改配置的其他办法
(1)hive? --hiveconf
hive? 启动,跟上需要修改的参数
例如不显示列名?
hive? --hiveconf? ? hive.cli.print.header =?false
(2)? set??
进入hive之后,可以通过?set?命令去配置?
set??hive.cli.print.header =?true;
总结:生效顺序
hive-site.xml? <??hive? --hiveconf? ? <? set?
七、作业
1、使用adb连接hive
开启hiveserver2
[peizk@hadoop hadoop]$ hive --service hiveserver2
##这是一个服务 在hive/bin目录下启动 可使用
sudo netstat -anp|grep 10000 查看是否启动成功
启动有点慢?在hadoop?家目录下? etc/hadoop? ? 更改core-site.xml? 新增如下内容
<property>
<name>hadoop.proxyuser.peizk.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.peizk.groups</name>
<value>*</value>
</property>
#################### 为了解决以下问题,添加上述内容
[root@hadoop ~]# beeline -u jdbc:hive2://hadoop:10000/default -n root
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/peizk/app/hive-3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/peizk/app/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://hadoop:10000/default
22/04/03 13:20:28 [main]: WARN jdbc.HiveConnection: Failed to connect to hadoop:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop:10000/default: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: peizk is not allowed to impersonate root (state=08S01,code=0)
Beeline version 3.1.2 by Apache Hive
?将hive家目录下的?jdbc? jar包?拿出? 在ADB中导入
如下:
?填写? 相应信息? ? 测试连接
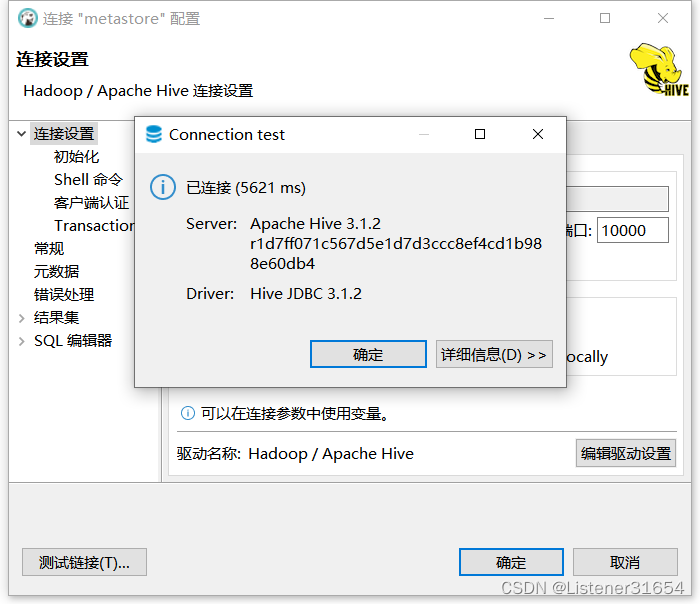
如下:?
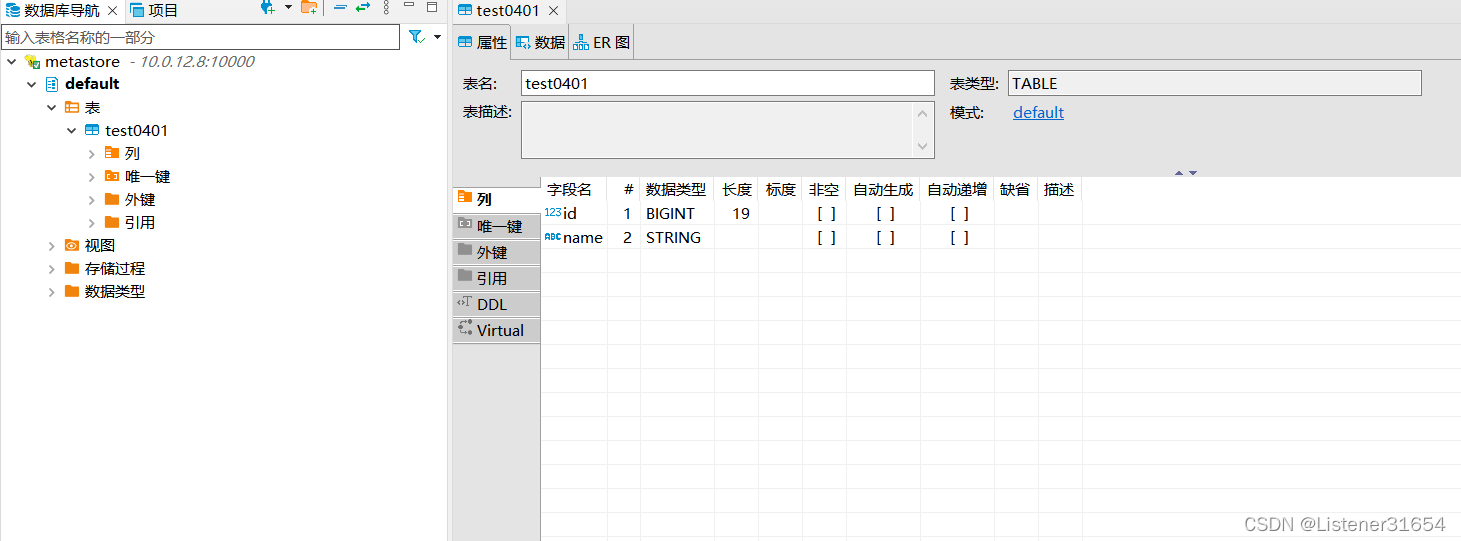
网页上也可看到
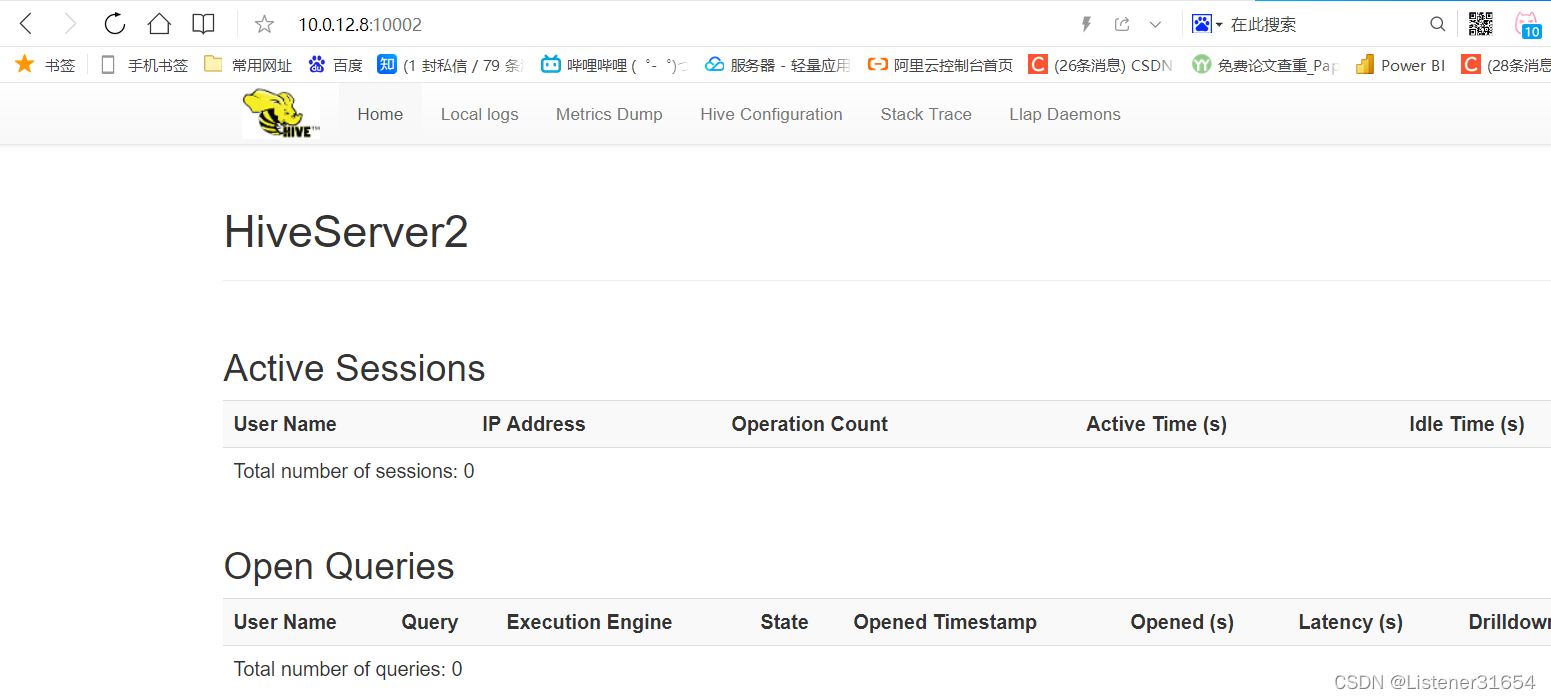
2、?MPP数据库的概念以及有哪些?
MPP数据库--大规模并行分析数据库。
MPP架构是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。有点类似于hadoop
并行处理的解释:
在数据库集群中,首先每个节点都有独立的磁盘存储系统和内存系统,其次业务数据根据数据库模型和应用特点划分到各个节点上,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
MPP的架构特性:
| 相对低的硬件成本 | 完全使用 x86?架构的 PC Server,不需要昂贵的 Unix 服务器和磁盘阵列 |
| 海量数据分布压缩存储 | 可处理 PB?级别以上的结构化数据,采用 hash分布、random 存储策略进行数据存储;同时采用先进的压缩算法,减少存储数据所需的空间,可以将所用空间减少 1~20 倍,并相应地提高 I/O 性能 |
| 数据加载高效性 | 基于策略的数据加载模式,集群整体加载速度可达2TB/h |
| 高扩展、高可靠 | 支持集群节点的扩容和缩容,支持全量、增量的备份/恢复 |
| 高可用、易维护 | 数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作 |
| 高并发 | 读写不互斥,支持数据的边加载边查询,单个节点并发能力大于 300?用户 |
| 行列混合存储 | 提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时 |
Hadoop?和 MPP 的一个区别:?
(1)在底层数据库上
MPP跑的是SQL,而Hadoop底层处理是MapReduce程序。
(2)
| 特征 | Hadoop | MPPDB | 传统数据库 |
| SQL支持 | 中 | 高 | 高 |
| 数据规模 | PB级别 | 准PB级别 | TB级别 |
| 计算性能 | 对非关系型操作效率高 | 对关系型操作效率高 | 对关系型操作效率中 |
| 数据结构 | 结构、半结构、非结构 | 结构 | 结构 |
总结:MPP适合多维度数据自助分析、数据集市等;Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
MPP产品? ?HPE Vertica? ?、MemSQL? ?、?Teradata? 、Google BigQuery
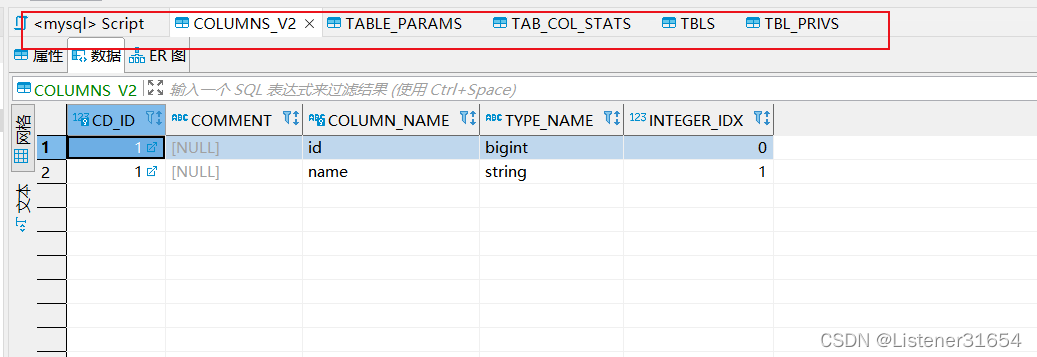
?3、在hive建表时,metastore哪些表会有改动?
4、Mysql的两种模式
InnoDB? 数据会存在ibdata 文件上 ,支持事务
MyISAM 数据存在独立的文件夹里,强调性能,不支持事务
5、cp? 与? mv??
一个是复制? 一个是剪切
6、数据仓库、datamarket、datahub、datalake、数据中台含义
数据仓库
数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。
面向主题:基于某个明确的主题,仅需要与该主题相关的数据
集成的:从不同的数据源采集数据到同一个数据源,此过程会有一些ETL操作。
随时间变化的:关键数据隐式或者显式的基于时间变化
相对稳定:数据仓库的数据一般是反应相当长一段时间内的数据内容
?
datamarket?数据集市
也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库。只面向某个特定的主题。为了解决灵活性和性能之间的矛盾,数据集市就是数据仓库体系结构中增加的一种小型的部门或工作组级别的数据仓库
datahub
DataHub是流式数据的处理平台,提供对流式数据的发布(Publish),订阅(Subscribe)和分发功能
在订阅-发布功能中,订阅者订阅自己感兴趣的数据,发布者发布到中间channel,发布-订阅彼此不知道对方的存在
datalake? 数据湖
数据湖是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。
数据中台
数据中台是一套可持续“让企业的数据用起来”的机制,一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建一套持续不断把数据变成资产并服务于业务的机制。