分布式系统架构-----异地多活架构
背景
最近公司在搞异地多活,特来写篇文章来学习和回顾一下。
异地多活看字面意思 :不通的地方部署服务。前段时间发生的B站挂掉的事情,网上众说纷纭,有的说是有机房着火了,导致服务宕机。那对于这种突发的情况,我们应该如何应对呢?包括说有些地方地震了导致机房宕机等等。
这些自然灾害我们是不可避免的所以我们得从架构层面解决这种突发问题。
异地多活架构
1. 什么是异地多活架构?
- 异地:不同的地理位置,多活:不同的地理位置的服务都能独立提供服务。
- 异地多活的目的也就是容灾,容灾的话我们也可以理解为某个地方服务出现了灾难性故障,而服务仍然能正常提供服务。
2. 异地多活的问题
- 代价高,机器数量成倍增长
- 运维成本也高,因为部署在不同的城市(国家等等),所以系统运维的人力还有资源都是极高的。
- 系统复杂变高,本来只需要考虑的写一个数据集群的数据现在需要考虑写进两个集群,包括业务上的一些数据一致性问题,也随之变高。
- 系统性能,因为异地多活会部署在不同的城市,所以距离就会带来延迟(距离越远,耗时越久)。
3. 常用的几种多活方案
同城异区
-
同城异区指的是将业务部署在同一个城市不同区的多个机房。例如,在广州部署两个机房,一个机房在南沙,一个在荔湾,然后将两个机房用专用的高速网络连接在一起。
-
但是像这种出现广州地震那么这种情况这种架构仍然解决不了问题的,但是我们结合故障的发生的概率和架构的复杂度之间取一个平衡的话,那对于这种架构来是最优的。
-
距离上会有大几十千米的距离加上告诉网络,那我们大概就可以将这两个集群当作一个机房了。不用做过多的业务和性能方面的优化等等
跨城异地
-
跨城异地指的是业务部署在不同城市的多个机房,而且距离最好要远一些。例如,将业务部署在北京和广州两个机房,而不是将业务部署在广州和深圳的两个机房。
-
为何跨城异地要强调距离要远呢?前面我在介绍同城异区的架构时提到同城异区不能解决新奥尔良水灾这种问题,而两个城市离得太近又无法应对如美加大停电这种问题,跨城异地其实就是为了解决这两类问题的,因此需要在距离上比较远,才能有效应对这类极端灾难事件。这么讲来,我更愿意称这种方式是夸省异地
-
也就是说跨省解决的问题是:自然灾害和地区政策大停电。
跨国异地
-
跨国异地指的是业务部署在不同国家的多个机房。相比跨城异地,跨国异地的距离就更远了,因此数据同步的延时会更长,正常情况下可能就有几秒钟了。这种程度的延迟已经无法满足异地多活标准的第一条:“正常情况下,用户无论访问哪一个地点的业务系统,都能够得到正确的业务服务”。例如,假设有一个微博类网站,分别在中国的上海和美国的纽约都建了机房,用户 A 在上海机房发表了一篇微博,此时如果他的一个关注者 B 用户访问到美国的机房,很可能无法看到用户 A 刚刚发表的微博。虽然跨城异地也会有此类同步延时问题,但正常情况下几十毫秒的延时对用户来说基本无感知的;而延时达到几秒钟就感觉比较明显了。
-
也就是说跨国针对的业务场景是,不同地区就近请求对应的机房,机房之间的数据通过数据同步进行同步。(这也是base理论中的最终一一致么)。像我们现在比较流行的夸奖电商的那些服务,岂不是都是这种跨国异地机构呢?
应用
在背景也讲了我们公司也做了异地多活,多活的方式数据跨城异区。一个集群部署在广州南沙,一个部署在广东佛山。
由于我们的服务系统复杂度不高,主要就是读,所以在架构复杂度上也是不高的,还是比较容易搞的。
我们服务的流量高峰QPS大概在在十万级别,性能得在200ms内,一般都是10ms内返回。
大概服务的物理架构图如下:
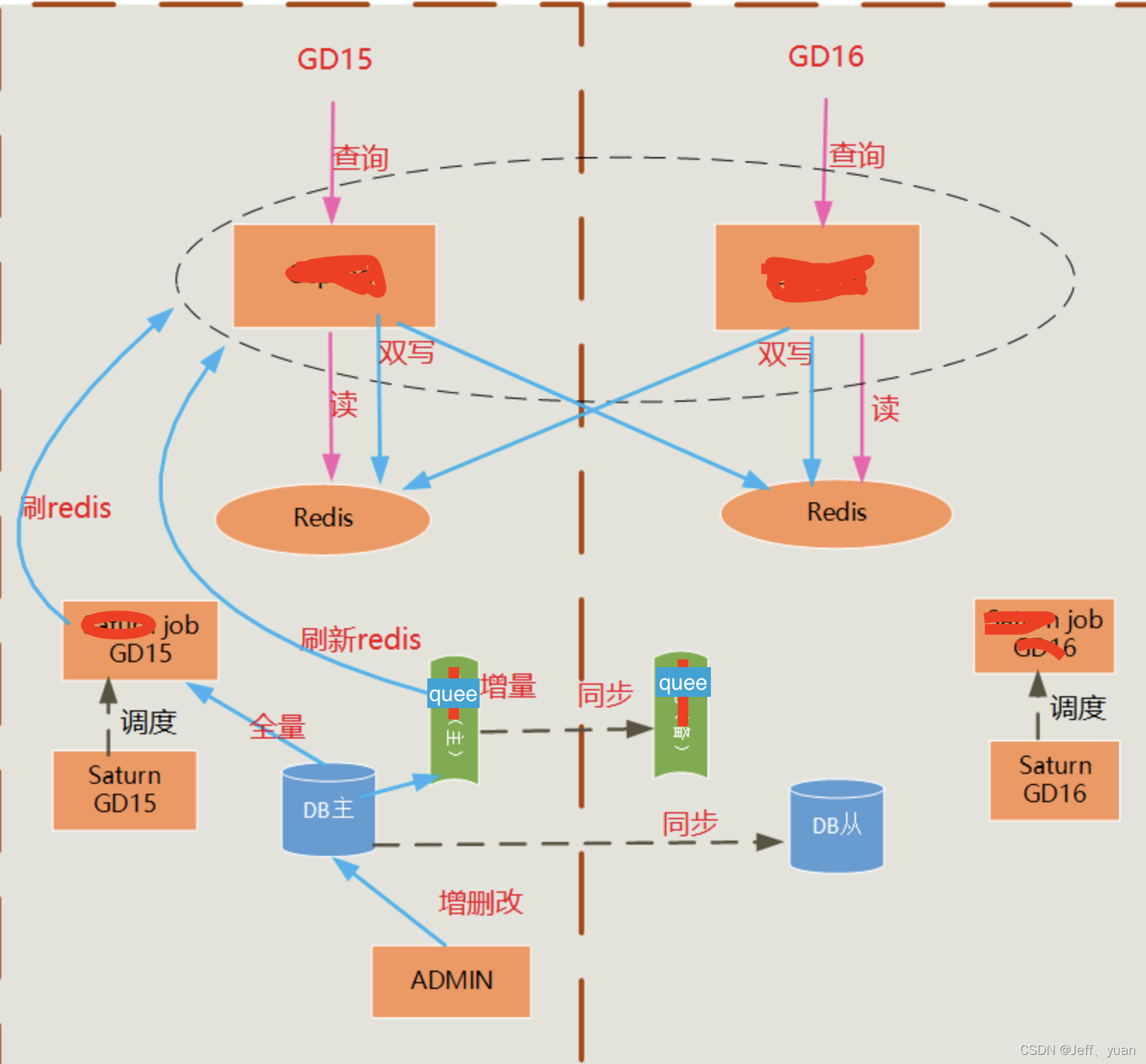
从上面架构图可知:
- mysql 采用主从机制
- redis 使用两个集群,通过双写实时同步
- quee采用的主备用
- job 和 服务就是两个异地集群
遇到的问题
-
服务数据一致性问题
刚启动服务数据一致问题:
-
因为服务都是读缓存的,又因为redis 缓存并不会回源。(听蹩脚的设计)所以在新搭建好的新集群需要去同步redis里的数据。
-
redis的数据来源主要为两个:saturn 主动刷入,和队列的主动同步,由于在刚开始设计的时候有考虑到redis宕机的问题,所以一旦宕机立码启动数据同步,但是这会导致分钟级别的不可用。但是由于业务逻辑存在兜底逻辑所以对于用户的伤害也不是很大。
-
异地集群搭建好后,通过job将所有的数据刷进新起的集群。
-
同步完成后验证也是一个难点,又因为我们有一个语法验收的工具可以对比机器之前的计算出的结果。所以就使用这个工具进行验收。对比gd15集群和gd16集群的数据对比。
-
-
启动好后数据一致性问题:
- 因为还有就是数据库mysql的数据是实时在变化的所有这个时候redis的数据和mysql的数据就会有可能不一致,通过架构图可知。我们是通过双写redis达到的,虽然redis也有自己的同步机制,但是出于性能考虑采用业务层中间件实现双写。
- 也就是说15集群写redsi的数据也同时会写入16集群,16集群的数据也会写入15集群。从而达到实时一致。
-
延时问题
- 整个服务搭建好后总共耗时多了2-4ms
- 对于我们服务来讲还是可以接受的。
参考
https://time.geekbang.org/column/article/9787
https://zhuanlan.zhihu.com/p/32009822