主库添加以下配置(根据注释和实际情况删减,没必要的可以去掉):
# 开启日志
general_log = 1
general_log_file = mysql.log
# 主从复制配置
server-id = 1
# binlog日志格式,mysql默认采用statement,建议使用mixed
# STATEMENT模式(SBR)
# 每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
# ROW模式(RBR)
# 不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
# MIXED模式(MBR)
# 以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
binlog_format= MIXED
# binlog日志文件
log-bin=mysql-bin
# binlog过期清理时间
expire_logs_days=7
# binlog每个日志文件大小
max_binlog_size= 100m
# binlog缓存大小
binlog_cache_size= 4m
# 最大binlog缓存大小
max_binlog_cache_size= 512m
重启主库:
service mysqld restart
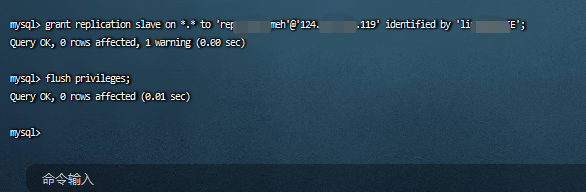
在主库上创建账号并授权给slave库:
grant replication slave on *.* to '[设置从库读取主库日志的账号]'@'[从库IP]' identified by '[设置你的密码]';
flush privileges;
去从库服务器上验证账号是否可用( 只能在从库上验证,因为创建账号时制定了IP,这个账号只能使用指定IP的从库服务器访问)
mysql -h124.***.***.158 -u[设置从库读取主库日志的账号] -p[设置你的密码]

使用从库服务器测试没问题。
下一步查看主库状态:
show master status\G;

从库配置(根据注释和实际情况删减,没必要的可以去掉):
# 开启日志
general_log = 1
general_log_file = mysql.log
# 注意:两个机器的server-id不能一样
server-id = 2
# 后跟路径表示开启中继日志,使用相对路径时表示在于数据目录在同一目录下,则默认位置在数据文件的目录(datadir)
relay-log=relay-log-bin
# 定义relay_log的位置和名称;一般和relay-log在同一目录
relay-log-index=slave-relay-bin.index
# 从节点跳过所有错误的日志
slave-skip-errors=all
# 1:innodb_file_per_table参数后innodb可以把每个表的数据单独保存
# 0:所有的innodb表的数据都是保存在innodb系统表空间中的在drop table ,truncate table后表空间文件并不会进行收缩,也就是说
# 表空间文件所占的磁盘空间并不会因为drop table , truncate table 而释放。
innodb_file_per_table=1
# 解析主机名的相关配置
skip_name_resolve=1
# 设置只读
read_only= 1
# A>B>C实现三级主从同步时使用bin-log只会记录直接在slave库上执行的SQL语句,
# 由replication机制的SQL线程读取relay-log而执行的SQL语句并不会记录到bin-log,log-slave-updates可以配置把这部分也记录下来
log-slave-updates=true
# 日志的名字叫mysql-bin
log-bin= mysql-bin
# binlog过期清理时间
expire_logs_days=7
# binlog每个日志文件大小
max_binlog_size= 100m
# binlog缓存大小
binlog_cache_size= 4m
# 最大binlog缓存大小
max_binlog_cache_size= 512m
重启从库:
service mysql restart
配置主从复制复制关系(在从库上执行):
change master to master_host='[主库IP]',master_user='[主库上创建的复制账号]',master_password='[账号对应密码]', master_log_file='mysql-bin.000002',master_log_pos=969;
start slave;

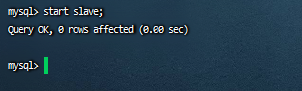
启动主从复制:
start slave;
查看主从状态:
show slave status\G;

最终测试,使用Navicat同时连接两个库:

在主库上新建个数据库:

刷新从库,瞬间就有了。