Redis 官方网站刊登的Redis分布式锁 Distributed locks with Redis
A Distributed Lock Pattern With Redis
为什么基于故障转移的实施还不够
redis主从无法真正实现Redlock
官方认为:
使用 Redis 锁定资源的最简单方法是在实例中创建密钥。密钥通常是使用 Redis 过期功能在有限的时间内创建的,因此最终它会被释放(无死锁)。当客户端需要释放资源时,它会删除密钥
当单点故障时,因为redis复制是异步的,这样做无法实现互斥的安全属性
模型:
- 客户端 A 获取主控中的锁
- 主服务器在对密钥的写入传输到副本之前崩溃
- 副本被提升为主
- 客户端 B 获得对同一个资源 A 已经持有锁的锁。违反安全规定!

可以看出clientB也获得了与clientA一样的锁
redis单实例中实现分布式锁的正确方式
# 在密钥不存在时设置密钥 my_random_value
# NX 表示if not exist 就设置并返回True,否则不设置并返回False
# PX保证表示过期时间用毫秒级 过期时间30000毫秒
# 值 my_random_value必须是所有client和所有锁请求发生期间唯一的
SET resource_name my_random_value NX PX 30000
释放锁的逻辑是:
-- 仅当密钥存在并且存储在密钥中的值正是我期望的值(对应本身client的字符串)时才删除密钥
-- 删除原因:保证服务器资源的高利用效率,不用等到锁自动过期才删除
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
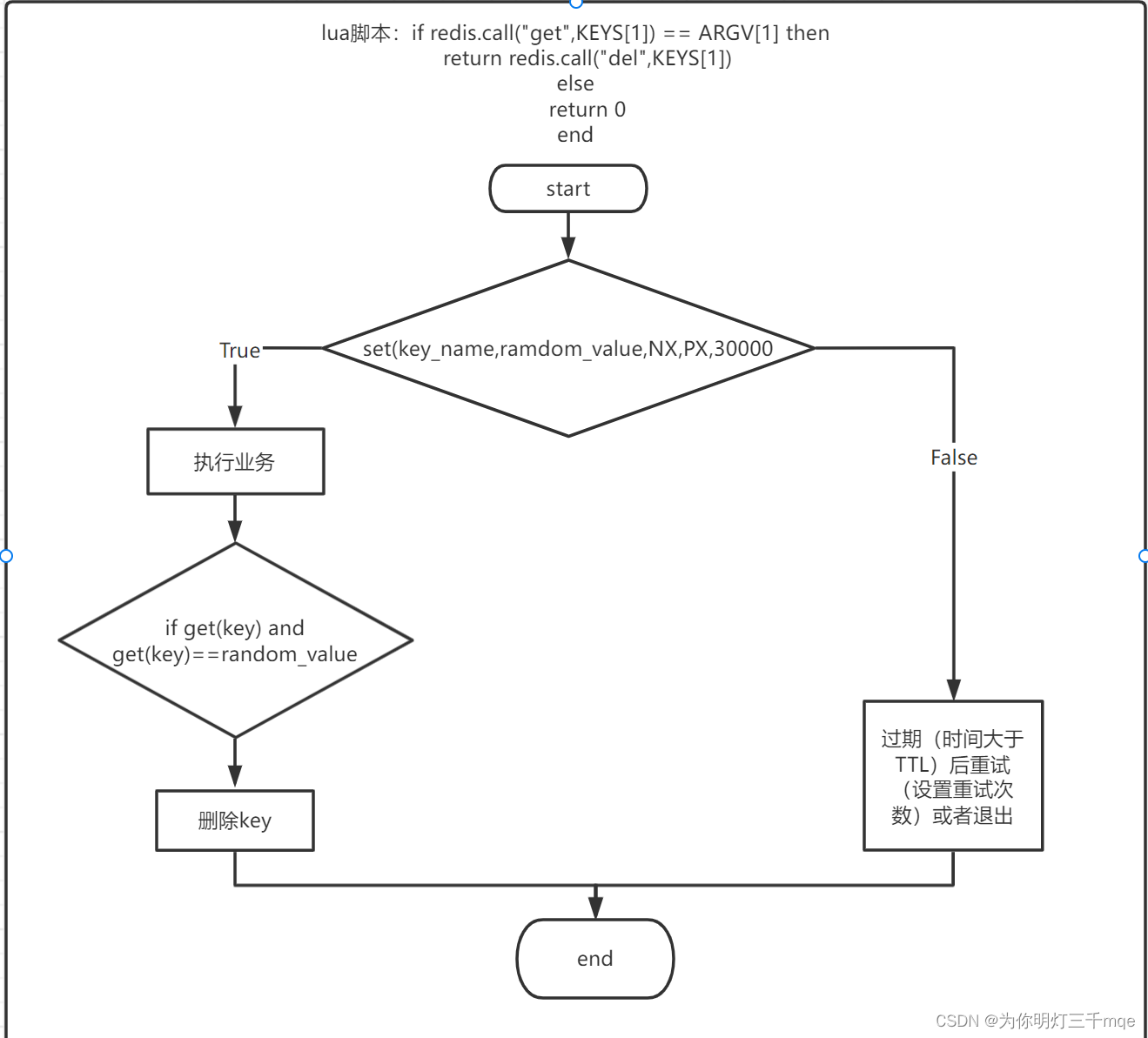
保证不会出现clientA调用锁后,遭遇阻塞,锁过期被删除(其他client获取),当clientA删除锁时误删其他client获取的锁
解决方法:使用一些随机字符串,每个锁都用一个随机字符串“签名”,只有对应的签名才能删除对应的锁
RedLock算法
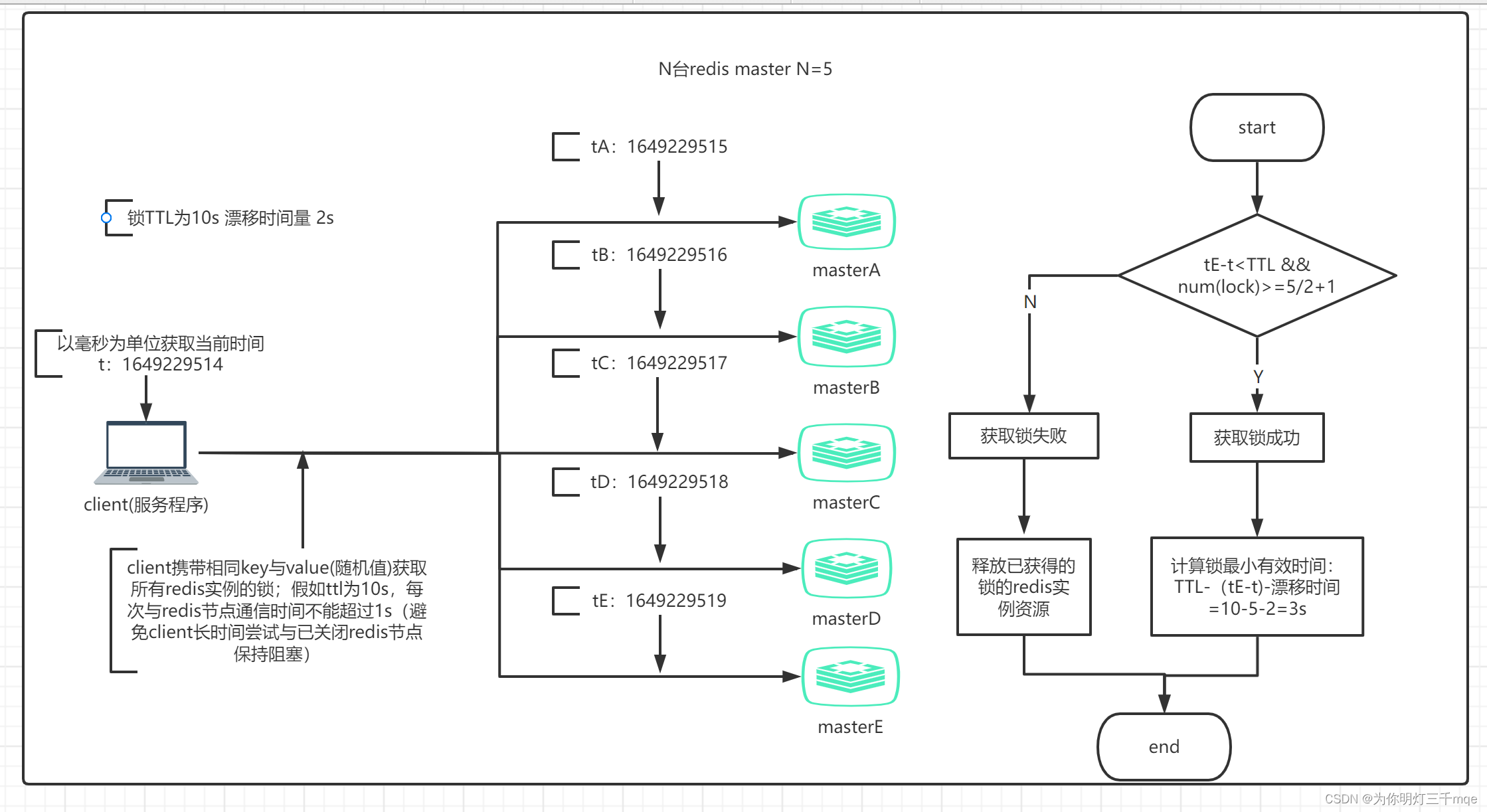
- 它以毫秒为单位获取当前时间
- 它尝试顺序获取所有 N 个实例中的锁,在所有实例中使用相同的键名和随机值。在步骤 2 中,当在每个实例中设置锁时,客户端使用一个与锁自动释放总时间相比较小的超时来获取它。例如,如果自动释放时间为 10 秒,则超时可能在 ~ 5-50 毫秒范围内。这可以防止客户端在尝试与已关闭的 Redis 节点通信时长时间保持阻塞:如果一个实例不可用,我们应该尽快尝试与下一个实例通信
- 客户端通过从当前时间中减去步骤 1 中获得的时间戳来计算获取锁所用的时间。当且仅当客户端能够在大多数实例中获取锁(至少 3 个) ,且获取锁的总时间小于锁的有效时间,则认为锁已被获取
- 如果获得了锁,则其有效时间被认为是初始有效时间减去经过的时间,如步骤 3 中计算的那样
- 如果客户端由于某种原因未能获得锁(它无法锁定 N/2+1 个实例或有效时间为负数),它将尝试解锁所有实例(即使是它认为没有的实例)能够锁定)
RedLock算法是否是异步算法?
可以看成是同步算法;因为即使进程间(多个电脑间)没有同步时钟,但是每个进程时间流速大致相同;仅当时钟漂移相对于TTL较小时,可以忽略,所以可以看成同步算法;
RedLock失败重试
当client未获取锁时,在随机时间后重试获取锁;并且最好在同一时刻并发的把set命令发送给所有redis实例;而且对于已经获取锁的client在完成任务后要及时释放锁,这是为了节省时间
RedLock释放锁
由于释放锁时会判断这个锁的Random_value是不是自己设置的,如果是才删除;所以在释放锁时非常简单,只要向所有实例都发出释放锁的命令,不用考虑能否成功释放锁;
RedLock算法安全论据
- 先假设client获取所有实例,所有实例包含相同的key和过期时间(TTL) ,但每个实例set命令时间不同导致不能同时过期,第一个set命令之前是T1,最后一个set命令后为T2,则此client有效获取锁的最小时间为TTL-(T2-T1)-时钟漂移
- 对于以N/2+ 1(也就是一半以 上)的方式判断获取锁成功,是因为如果小于一半判断为成功的话,有可能出现多个client都成功获取锁的情况, 从而使锁失效
- 一个client锁定大多数事例耗费的时间大于或接近锁的过期时间(最小有效时间未负或趋近于0),就认为锁无效,并且解锁这个redis实例(不执行业务) ;只要在TTL时间内成功获取一半以上的锁便是有效锁;否则无效
系统活性论据
- 锁的自动释放(密钥过期):最终密钥可以再次被锁定
- 客户端在获取锁失败(不到一半以上),或任务完成后 能够自动释放锁,不用等到其自动过期
- 客户端需要重试锁时,它等待的时间比获取大多数锁所需的时间要长(第一次失败到第二次重试时间间隔),以便在资源争用期间不太可能出现脑裂情况,限制重试次数