文章目录
1.函数
- 系统内置函数
- UDF函数
1.1 系统自定义函数
- 标量函数(Scalar Functions)
- 聚合函数(Aggregate Functions)
1.1.1 标量函数
所谓的“标量”,是指只有数值大小、没有方向的量;所以标量函数指的就是只对输入数据做转换操作、返回一个值的函数。这里的输入数据对应在表中,一般就是一行数据中 1 个或多个字段,因此这种操作有点像流处理转换算子中的 map。另外,对于一些没有输入参数、直
接可以得到唯一结果的函数,也属于标量函数。
比较函数(Comparison Functions)
(1)value1 = value2 判断两个值相等;
(2)value1 <> value2 判断两个值不相等
(3)value IS NOT NULL 判断 value 不为空
逻辑函数(Logical Functions)
(AND)、或(OR)、非(NOT), 判断语句(IS、IS NOT)进行真值判断
(1)boolean1 OR boolean2 布尔值 boolean1 与布尔值 boolean2 取逻辑或
(2)boolean IS FALSE 判断布尔值 boolean 是否为 false
(3)NOT boolean 布尔值 boolean 取逻辑非
算术函数(Arithmetic Functions)
(1)numeric1 + numeric2 两数相加
(2)POWER(numeric1, numeric2) 幂运算,取数 numeric1 的 numeric2 次方
(3)RAND() 返回(0.0, 1.0)区间内的一个 double 类型的伪随机数
字符串函数(String Functions)
(1)string1 || string2 两个字符串的连接
(2)UPPER(string) 将字符串 string 转为全部大写
(3)CHAR_LENGTH(string) 计算字符串 string 的长度
时间函数(Temporal Functions)
(1)DATE string 按格式"yyyy-MM-dd"解析字符串 string,返回类型为 SQL Date
(2)TIMESTAMP string 按格式"yyyy-MM-dd HH:mm:ss[.SSS]"解析,返回类型为 SQL timestamp
(3)CURRENT_TIME 返回本地时区的当前时间,类型为 SQL time(与 LOCALTIME等价)
(4)INTERVAL string range 返回一个时间间隔。string 表示数值;range 可以是 DAYMINUTE,DAT TO HOUR 等单位,也可以是 YEAR TO MONTH 这样的复合单位。如“2 年10 个月”可以写成:INTERVAL ‘2-10’ YEAR TO MONTH
1.1.2 聚合函数(Aggregate Functions)
- COUNT(*) 返回所有行的数量,统计个数
- SUM([ ALL | DISTINCT ] expression) 对某个字段进行求和操作。
- RANK() 返回当前值在一组值中的排名
- ROW_NUMBER() 对一组值排序后,返回当前值的行号。
其中,RANK()和 ROW_NUMBER()一般用在 OVER 窗口中
1.2 UDF 函数
用户自定义函数
- 标量函数(Scalar Functions):将输入的标量值转换成一个新的标量值;
- 表函数(Table Functions):将标量值转换成一个或多个新的行数据,也就是扩展成一个表;
- 聚合函数(Aggregate Functions):将多行数据里的标量值转换成一个新的标量值;
- 表聚合函数(Table Aggregate Functions):将多行数据里的标量值转换成一个或多个新的行数据。
标量函数: 1:1
表函数: 1:n
聚合函数: n:1
表聚合函数: n:n
1.2.1 标量函数
实现输出 user 的hashcode
需要实现ScalarFunction 抽象类, 并定于一个 eval() 的方法
public class Udf_ScalarFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment);
// DDL 中定义时间属性
String createDDL = "create table clickTable (" +
"`user` STRING, " +
"url STRING, " +
"ts BIGINT, " +
"et AS TO_TIMESTAMP( FROM_UNIXTIME(ts / 1000))," +
"WATERMARK FOR et AS et - INTERVAL '1' SECOND" +
") WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.txt'," +
" 'format' = 'csv')";
tableEnvironment.executeSql(createDDL);
// 注册自定义标量函数
tableEnvironment.createTemporarySystemFunction("myHash", MyHashFunction.class);
// 调用UDF进行查询
Table resultTable = tableEnvironment.sqlQuery("select user, myHash(user) from clickTable");
// 打印输出
tableEnvironment.toDataStream(resultTable).print();
environment.execute();
}
public static class MyHashFunction extends ScalarFunction{
public int eval(String str){
return str.hashCode();
}
}
}

1.2.2 表函数
类似地,要实现自定义的表函数,需要自定义类来继承抽象类 TableFunction,内部必须要实现的也是一个名为 eval 的求值方法。与标量函数不同的是,TableFunction 类本身是有一个泛型参数T 的,这就是表函数返回数据的类型;而 eval()方法没有返回类型,内部也没有 return语句,是通过调用 collect()方法来发送想要输出的行数据的。多么熟悉的感觉――回忆一下DataStream API 中的 FlatMapFunction 和 ProcessFunction,它们的 flatMap 和 processElement 方法也没有返回值,也是通过 out.collect()来向下游发送数据的。
通过表函数可以实现1:n 的功能
下面是表函数的一个具体示例。我们实现了一个分隔字符串的函数 SplitFunction,可以将
一个字符串转换成(字符串,长度)的二元组
public class Udf_TableFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment);
// DDL 中定义时间属性
String createDDL = "create table clickTable (" +
"`user` STRING, " +
"url STRING, " +
"ts BIGINT, " +
"et AS TO_TIMESTAMP( FROM_UNIXTIME(ts / 1000))," +
"WATERMARK FOR et AS et - INTERVAL '1' SECOND" +
") WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.txt'," +
" 'format' = 'csv')";
tableEnvironment.executeSql(createDDL);
tableEnvironment.createTemporarySystemFunction("mySplit", MySplit.class);
Table resultTable = tableEnvironment.sqlQuery("select user, url, word, length " +
"from clickTable, LATERAL TABLE (mySplit(url)) AS T(word, length)");
tableEnvironment.toDataStream(resultTable).print();
environment.execute();
}
// 表函数
public static class MySplit extends TableFunction<Tuple2<String, Integer>>{
public void eval(String str){
String[] strings = str.split("\\?");
for (String string : strings) {
collect(Tuple2.of(string, string.length()));
}
}
}
}

1.2.3 聚合函数
这是一个标准的“多对一”的转换。
聚合函数的概念我们之前已经接触过多次,如 SUM()、MAX()、MIN()、AVG()、COUNT()都是常见的系统内置聚合函数。而如果有些需求无法直接调用系统函数解决,我们就必须自定义聚合函数来实现功能了。
比如我们要从学生的分数表 ScoreTable 中计算每个学生的加权平均分。为了计算加权平均值,应该从输入的每行数据中提取两个值作为参数:要计算的分数值 score,以及它的权重weight。而在聚合过程中,累加器(accumulator)需要存储当前的加权总和 sum,以及目前数
据的个数 count。这可以用一个二元组来表示,也可以单独定义一个类 WeightedAvgAccum,里面包含 sum 和 count 两个属性,用它的对象实例来作为聚合的累加器。
public class Udf_AggregateFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment);
// DDL 中定义时间属性
String createDDL = "create table clickTable (" +
"`user` STRING, " +
"url STRING, " +
"ts BIGINT, " +
"et AS TO_TIMESTAMP( FROM_UNIXTIME(ts / 1000))," +
"WATERMARK FOR et AS et - INTERVAL '1' SECOND" +
") WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.txt'," +
" 'format' = 'csv')";
tableEnvironment.executeSql(createDDL);
tableEnvironment.createTemporarySystemFunction("weightAverage", WeightAverage.class);
Table table = tableEnvironment.sqlQuery("select user, weightAverage(ts, 1) as w_avg from clickTable group by user");
tableEnvironment.toChangelogStream(table).print();
environment.execute();
}
public static class WeightedAvgAccumulate{
public long sum = 0;
public int count = 0;
}
public static class WeightAverage extends AggregateFunction<Long, WeightedAvgAccumulate>{
// 累加计算的方法
@Override
public Long getValue(WeightedAvgAccumulate weightedAvgAccumulate) {
if (weightedAvgAccumulate.count == 0){
return null;
}else {
return weightedAvgAccumulate.sum / weightedAvgAccumulate.count;
}
}
// 累加器
@Override
public WeightedAvgAccumulate createAccumulator() {
return new WeightedAvgAccumulate();
}
// accumulate 累计函数
public void accumulate(WeightedAvgAccumulate avgAccumulate, Long l, Integer i){
avgAccumulate.sum += i * l;
avgAccumulate.count += i;
}
}
}
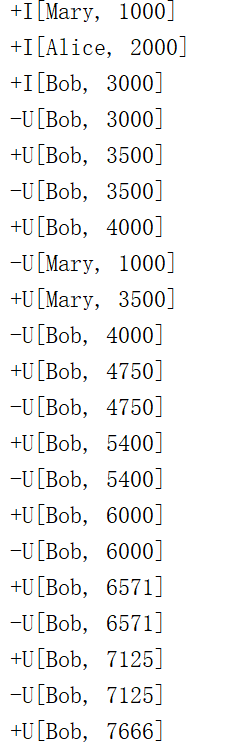
1.2.4 表聚合函数
是一个“多对多”的转换。自定义表聚合函数需要继承抽象类 TableAggregateFunction。
这就是最简单的 TOP-2 查询。
public class Udf_TableAggregateFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment);
// DDL 中定义时间属性
String createDDL = "create table clickTable (" +
"`user` STRING, " +
"url STRING, " +
"ts BIGINT, " +
"et AS TO_TIMESTAMP( FROM_UNIXTIME(ts / 1000))," +
"WATERMARK FOR et AS et - INTERVAL '1' SECOND" +
") WITH (" +
" 'connector' = 'filesystem'," +
" 'path' = 'input/clicks.txt'," +
" 'format' = 'csv')";
tableEnvironment.executeSql(createDDL);
tableEnvironment.createTemporarySystemFunction("Top2", Top2.class);
String subQuery = " SELECT user, COUNT(url) AS cnt, window_start, window_end" +
" FROM TABLE (" +
" TUMBLE(TABLE clickTable, DESCRIPTOR(et), INTERVAL '10' SECOND)" +
")" +
"GROUP BY user, window_start, window_end";
Table aggTable = tableEnvironment.sqlQuery(subQuery);
Table resultTable = aggTable.groupBy($("window_end"))
.flatAggregate(call("Top2", $("cnt")).as("value", "rank"))
.select($("window_end"), $("value"), $("rank"));
tableEnvironment.toChangelogStream(resultTable).print();
environment.execute();
}
// 单独定义一个累加器类型
public static class Top2Accumulator{
public Long max;
public Long secondMax;
}
public static class Top2 extends TableAggregateFunction<Tuple2<Long, Integer>, Top2Accumulator>{
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator accumulator = new Top2Accumulator();
accumulator.max = Long.MIN_VALUE;
accumulator.secondMax = Long.MIN_VALUE;
return accumulator;
}
// 定义一个累加器的方法
public void accumulate(Top2Accumulator accumulator, Long value){
if (value > accumulator.max){
accumulator.secondMax = accumulator.max;
accumulator.max = value;
}else if (value > accumulator.secondMax){
accumulator.secondMax = value;
}
}
// 输出结果
public void emitValue(Top2Accumulator accumulator, Collector<Tuple2<Long, Integer>> out){
if (accumulator.max != Long.MIN_VALUE){
out.collect(Tuple2.of(accumulator.max, 1));
}
if (accumulator.secondMax != Long.MAX_VALUE){
out.collect(Tuple2.of(accumulator.secondMax, 2));
}
}
}
}
2.SQL 客户端
- 首先启动本地集群
./bin/start-cluster.sh
- 启动 Flink SQL 客户端
./bin/sql-client.sh
- 设置运行模式
流模式
Flink SQL> SET 'execution.runtime-mode' = 'streaming';
执行结果模式
Flink SQL> SET 'sql-client.execution.result-mode' = 'table';
设置ttl
Flink SQL> SET 'table.exec.state.ttl' = '1000';
- 执行 SQL 查询
Flink SQL> CREATE TABLE EventTable(
> user STRING,
> url STRING,
> `timestamp` BIGINT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'events.csv',
> 'format' = 'csv'
> );
Flink SQL> CREATE TABLE ResultTable (
> user STRING,
> cnt BIGINT
> ) WITH (
> 'connector' = 'print'
> );
Flink SQL> INSERT INTO ResultTable SELECT user, COUNT(url) as cnt FROM EventTable
GROUP BY user;
在 SQL 客户端中,每定义一个 SQL 查询,就会把它作为一个 Flink 作业提交到集群上执行。所以通过这种方式,我们可以快速地对流处理程序进行开发测试。
3.连接外部系统
- Kafka
- 文件系统
- JDBC
- ES
- HBASE
- HIVE
3.1 Kafka
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
创建连接到 Kafka 的表
CREATE TABLE KafkaTable (
`user` STRING,
`url` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'events',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
这里定义了 Kafka 连接器对应的主题(topic),Kafka 服务器,消费者组 ID,消费者起始模式以及表格式。需要特别说明的是,在 KafkaTable 的字段中有一个 ts,它的声明中用到了METADATA FROM,这是表示一个“元数据列”(metadata column),它是由 Kafka 连接器的元数据“timestamp”生成的。这里的 timestamp 其实就是 Kafka 中数据自带的时间戳,我们把它直接作为元数据提取出来,转换成一个新的字段 ts。
3.2 文件系统
CREATE TABLE MyTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- 连接器类型
'path' = '...', -- 文件路径
'format' = '...' -- 文件格式
)
这里在 WITH 前使用了 PARTITIONED BY 对数据进行了分区操作。文件系统连接器支持对分区文件的访问。
3.3 JDBC
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
创建 JDBC 表的方法
CREATE TABLE MyTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users'
);
INSERT INTO MyTable
SELECT id, name, age, status FROM T;
3.4 Elasticsearch
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
连接ES 的表
CREATE TABLE MyTable (
user_id STRING,
user_name STRING
uv BIGINT,
pv BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'users'
);
3.5 HBASE
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-1.4_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
连接到HBASE 的表
CREATE TABLE MyTable (
rowkey INT,
family1 ROW<q1 INT>,
family2 ROW<q2 STRING, q3 BIGINT>,
family3 ROW<q4 DOUBLE, q5 BOOLEAN, q6 STRING>,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'mytable',
'zookeeper.quorum' = 'localhost:2181'
);
-- 假设表 T 的字段结构是 [rowkey, f1q1, f2q2, f2q3, f3q4, f3q5, f3q6]
INSERT INTO MyTable
SELECT rowkey, ROW(f1q1), ROW(f2q2, f2q3), ROW(f3q4, f3q5, f3q6) FROM T;
我们将另一张 T 中的数据提取出来,并用 ROW()函数来构造出对应的 column family,最终写入 HBase 中名为 mytable 的表。