зюНќЪ§ОнКўЗЧГЃЕФЛ№,ЕЋЪЧвЛЕЉУЛХЊКУ,ОЭЛсБфГЩЁАЪ§ОнегдѓЁБЁЃШчКЮБмУтЁАЪ§ОнКўЁББфГЩЁАЪ§ОнегдѓЁБФи?зюКУЕФАьЗЈОЭЪЧжЮРэЯШааЁЃ
БОЮФЕФФкШнжївЊАќРЈЫФВПЗж:
1ЁЂЪ§ОнКўБГОАИХЪі,НщЩмЬкбЖЪ§ОнКўЕФећЬхМмЙЙ;
2ЁЂЪ§ОнКўЭГвЛдЊЪ§ОнФЃПщЕФЯъЯИМмЙЙЪЕЯж;
3ЁЂНщЩмЬкбЖдЦЩЯдЊЪ§ОнЖрзтЛЇЕФЩшМЦФЃЪН;
4ЁЂНщЩмЭГвЛдЊЪ§ОнЕФСНДѓКЫаФФмСІ:дкЯпЪ§ОнФПТМКЭРыЯпЪ§ОнжЮРэЕФЙІФмЁЃ
01
ЪВУДЪЧЪ§ОнКў
ЫцзХSnowflakeЙЋЫОЙЩМлИпИшУЭНјКЭИїДѓдЦГЇЩЬЕФЭЦЙу,Ъ§ОнКўвбГЩЮЊНќ2ЁЂ3ФъРДДѓЪ§ОнСьгђЕФаТЙѓжЎвЛ,ЖјЪВУДЪЧЪ§ОнКў,Ъ§ОнКўгыЪ§ОнВжПтжЎМфЕФОКељКЭШкКЯ,ИїМвдЦГЇЩЬКЭЪ§ОнЦНЬЈЖМгаздМКЕФНтЖСЁЃ
ДгЖЈвхРДПД,Ъ§ОнВжПтЪЧ1990ФъгЩЪ§ВжжЎИИBill InmonЬсГі,ЪЧУцЯђжїЬтЕФЁЂМЏГЩЕФЁЂЯрЖдЮШЖЈЕФЁЂЗДгГРњЪЗЕФЪ§ОнМЏКЯ,ЮЊЩЯВуЬсЙЉЙмРэОіВп;ЖјЪ§ОнКўИХФюзюдчЪЧ2010ФъгЩPentaho CTO James DixonЬсГі,ЪЧДцДЂИїРрздШЛИёЪНЪ§ОнЕФЯЕЭГ,ЬсЙЉЪ§ОнETLВйзїЁЃ
вдЮвЕФРэНт,Ъ§ОнВжПтКЭЪ§ОнКўПЩЗжБ№ПДзїЪЧЗжЖјжЮжЎКЭЮоЮЊЖјжЮЁЃ
-
Ъ§ОнВжПт:ОпгаБъзМЕФЪ§ОнФЃаЭКЭЪ§ОнЗжВу,АќРЈODSВйзїЪ§ОнВу,CDMЭЈгУЪ§ОнФЃаЭВу,ADSЪ§ОнгІгУВу,ЖјУПВугжПЩвдНјааЯИЗж;Ъ§ОнВжПтНіжЇГжНсЙЙЛЏЪ§Он,дкаДШыЪ§ОнЮФМўЪБ,БиаыЬсЧАЖЈвхКУЪ§ОнЕФSchemaНсЙЙ;Ъ§ОнВжПтЕФећЬхЪ§ОнжЪСПНЯИп,ЕЋЫцжЎЖјРДЕФЙЙНЈГЩБОНЯДѓЧвНіжЇГжЬиЖЈМЦЫув§ЧцЁЃ
-
Ъ§ОнКў:ЮоашЬсЧАЩшМЦКУЪ§ОнФЃаЭКЭЪ§ОнЗжВу,жЇГжНсЙЙЛЏКЭАыНсЙЙЛЏЪ§Он,дкЪ§ОнЖСШЁВйзїЪБ,ВХашвЊШЗЖЈГіЪ§ОнЕФSchemaНсЙЙ;ЯрБШгкЪ§ОнВжПт,Ъ§ОнКўЕФећЬхЪ§ОнжЪСПНЯЕЭ,ЕЋЦфЙЙНЈГЩБОНЯаЁ,ЧвжЇГжЖрбљЛЏЕФМЦЫув§ЧцНјааЪ§ОнЗжЮіЁЃ

вдЬкбЖЪ§ОнКўМЦЫуDLCЮЊР§,Ъ§ОнКўЕФећЬхгХЪЦПЩвдЗжЮЊ:ИпаЇадЁЂЕЭГЩБОЁЂвзРЉеЙЁЃ
-
ИпЪБаЇ:ПЩЛљгкБэИёЪН,ЪЙгУIcebergЬсЙЉааМЖЪ§ОнВйзї,ПЩНЋДЋЭГЕФДѓЪ§ОнЪ§ВжЪБбгДгаЁЪБМЖБ№НЕЕЭЕНЗжжгМЖБ№;ПЩЛљгкДцДЂЛКДц,ЪЙгУAlluxioЬсЙЉБОЕиЕФЗжВуДцДЂ,МгЫйМЦЫуЁЃ
-
ЕЭГЩБО:ЯрБШгкДЋЭГЕФHDFS,ЬкбЖдЦЩЯЖдЯѓДцДЂCOSЕФМЦЗбИќМгЕЭСЎ,гУЛЇжЛашЮЊЪЕМЪДцДЂЕФЪ§ОнТђЕЅ,ЬьШЛЪЪКЯдЦдЩњГЁОАЁЃЬсЙЉЪ§ОнКўServerlessМЦЫуФмСІ,ПЩЛљгкдЦЩЯEKSЖдМЦЫузЪдДНјааЖЏЬЌРЉЫѕШн,ШУгУЛЇЮоашЙКТђећЬзEMRМЏШКОЭФмЪЕЯжКЃСПЕФЪ§ОнЗжЮіЁЃ
-
взРЉеЙ:ЪЙгУДцЫуЗжРыМмЙЙ,ПЩНтёюМЦЫузЪдДКЭДцДЂзЪдДЕФРЉЫѕШн;ПЩРЉеЙжЇГжЖрбљЛЏЕФМЦЫув§Чц,ФПЧАвбжЇГжPrestoКЭSparkНјааМЦЫуЗжЮіЁЃ
Ъ§ОнКўдкСщЛюадЕФгХЪЦЯТ,вВашвЊИќКУЕФЙмРэФмСІ,АќРЈЪ§ОнНЈФЃФмСІКЭЪ§ОнжЮРэФмСІ,ЖјИїГЇЩЬвВЗзЗзЬсГіКўВжвЛЬхЕФИХФю,НЋЪ§ОнКўКЭЪ§ОнВжПтНјааећКЯ,ИќКУЕФИљОнЪЕМЪашЧѓбАевСНепЕФЦНКтЁЃ
02
ЬкбЖЪ§ОнКўКЭЬкбЖЭГвЛдЊЪ§ОнжЮРэПђМм
ЬкбЖЪ§ОнКўЕФећЬхМмЙЙШчЯТЭМЫљЪО,ПЩвдМђЕЅРэНтЮЊ3+2МмЙЙ,гЩЪ§ОнКўЕФШ§ДѓЛљБОзщГЩвЊЫиКЭСНДѓЙиСЊФЃПщЙЙГЩЁЃ
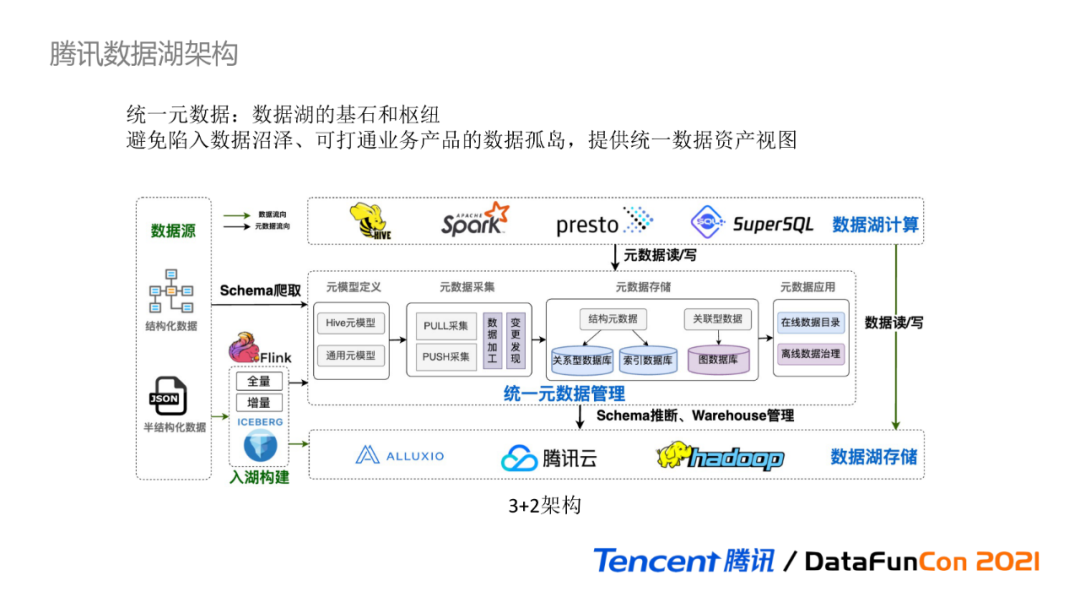
ЪзЯШРДПДЪ§ОнКўЕФШ§ДѓЛљБОзщГЩвЊЫи:
**Ъ§ОнКўДцДЂ:**ЬсЙЉКЃСПвьЙЙЪ§ОнЕФДцДЂФмСІ,ОпБИЕЭГЩБОЁЂИпПЩгУЁЂПЩЕЏадЩьЫѕЁЃDLCЛљгкЬкбЖдЦЖдЯѓДцДЂCOSзїЮЊжївЊЪ§ОнКўДцДЂ,ДюХфAlluxioНјааЪ§ОнБрХХКЭЗжВуЛКДц,ЭЌЪБвВжЇГждЦЩЯEMR HDFSРЉеЙДцДЂ;
**Ъ§ОнКўМЦЫу:**вдServerlessЮоЗўЮёЕФаЮЪНЬсЙЉИпаЇУєНнЕФМЦЫуЗжЮіЁЃDLCжЇГжЛљгкPrestoЪЕЯжМДЯЏЗжЮі,ЛљгкSparkЪЕЯжЪ§ОнETLХњДІРэЁЂЛљгкЬкбЖSuperSQLЪЕЯжСЊАюПчдДЗжЮі;
**ЭГвЛдЊЪ§Он:**ЬсЙЉдЦЩЯЭГвЛЕФдкЯпЪ§ОнФПТМКЭРыЯпЪ§ОнжЮРэФмСІ,жївЊгаЫФИіВПЗжЙЙГЩ:
-
дЊФЃаЭЖЈвх:ЪЧЖддЊЪ§ОнЕФГщЯѓУшЪі,ЖЈвхСЫHiveдЊФЃаЭКЭЭЈгУдЊФЃаЭ;
-
дЊЪ§ОнВЩМЏ:жЇГжЛљгкPULLЖЈЪБРШЁКЭPUSHжїЖЏЩЯБЈЕФСНжжЗНЪНВЩМЏдЊЪ§Он,ВЂЖддЪМдЊЪ§ОнНјааМгЙЄДІРэ;
-
дЊЪ§ОнДцДЂ:ИљОнВЛЭЌдЊЪ§ОнЕФЪ§ОнНсЙЙКЭгУЭО,бЁдёДцЗХдкВЛЭЌРраЭЕФЪ§ОнПтжа,ФПЧАЪЙгУСЫЙиЯЕаЭЪ§ОнПтЁЂЫїв§Ъ§ОнПтЁЂЭМЪ§ОнПт;
-
дЊЪ§ОнгІгУ:ЗжЮЊдкЯпЪ§ОнФПТМКЭРыЯпЪ§ОнжЮРэСНРрЙІФмФЃПщ,дкЯпЪ§ОнФПТМПЩЮЊЪ§ОнКўЕФМЦЫув§ЧцЬсЙЉSchemaЙмРэЙІФм,ЖјРыЯпЪ§ОнжЮРэПЩЮЊЪ§ОнКўЬсЙЉзЪВњЙмРэФмСІЁЃ
СНДѓЙиСЊФЃПщАќРЈ:
-
вьЙЙЪ§ОндД:ЮЊЪ§ОнКўЬсЙЉЩњВњзЪСЯРДдД,жЇГжНсЙЙЛЏЪ§Он,ШчЬкбЖдЦЩЯEMR HIve,CDBЁЂCDWЕШЪ§ОнПтРДдД,ЭЌЪБвВжЇГжАыНсЙЙЛЏЪ§Он,ШчJsonЮФБОЁЂLogШежОЕШ;
-
ШыКўЙЙНЈ:ЮЊЪ§ОнКўЬсЙЉБуНнЕФЪ§ОнШыКўМЏГЩФмСІ,ЛљгкIcebergБэИёЪНКЭFlink,ПЩЪЕЯжШЋСПКЭдіСПЕФЪ§ОнЕМШыМЏГЩЙІФмЁЃ
дкећИіМмЙЙЭМжа,гЩКкЩЋМ§ЭЗЕФдЊЪ§ОнСїЯђПЩвдПДГі,ЭГвЛдЊЪ§ОнЪЧећИіЪ§ОнКўЕФЛљЪЏКЭЪрХІ,ЗЂЛгзХГаЩЯЦєЯТЕФЙиСЊзїгУ,ГаЩЯЖдНгЪ§ОнКўМЦЫув§Чц,ЦєЯТЖдНгЪ§ОнКўДцДЂ,ПЩЭЈЙ§дЊЪ§ОнВЩМЏДгвьЙЙЪ§ОндДНјааSchemaЪ§ОнНсЙЙХРШЁЁЃ
ЖјЪ§ОнЕФSchemaаХЯЂгжПЩвдЮЊШыКўЙЙНЈЬсЙЉЛљБОЕФдЊЪ§ОнзЪСЯЁЃдЊЪ§ОнжаЕФSchemaЙмРэКЭЪ§ОнжЮРэ,ЬсЩ§КЭБЃжЄСЫЪ§ОнКўЕФЪ§ОнжЪСП,БмУтЯнШыЪ§Онегдѓ,ЭЌЪБЭГвЛдЊЪ§ОнПЩвдећКЯВЛЭЌЕФвЕЮёГЁОАЬсЙЉЭГвЛЕФЪ§ОнЙмРэЪгЭМ,ДђЭЈИївЕЮёЕФЪ§ОнЙТЕКЁЃ
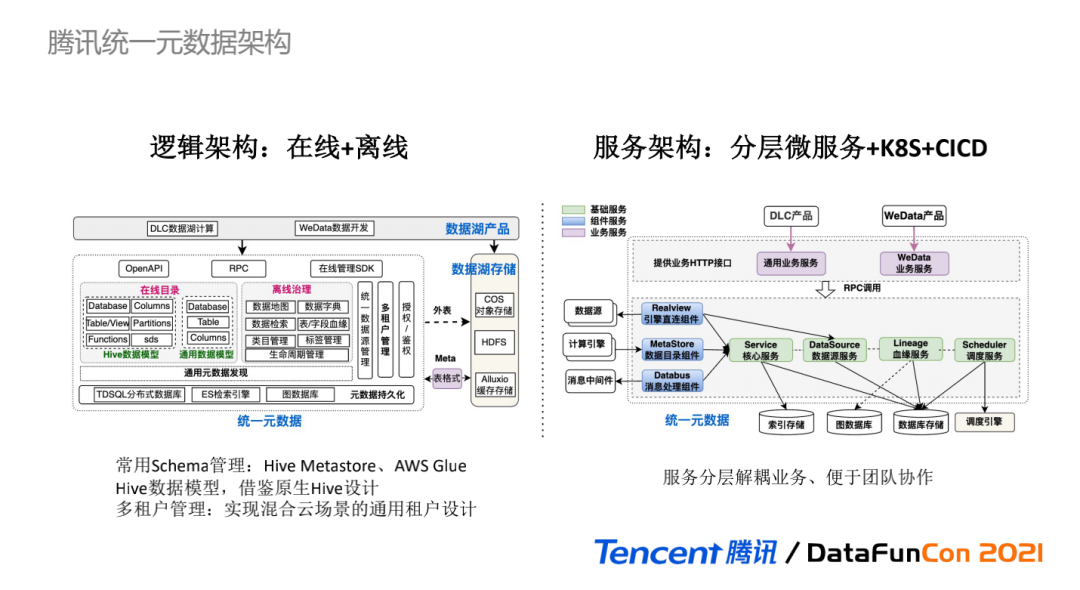
ЯТУцРДПДЬкбЖЭГвЛдЊЪ§ОнЕФФЃПщЯъЯИМмЙЙ,ЦфжаЯЕЭГТпММмЙЙШчЭМЫљЪО,гаСНДѓКЫаФЙІФм:дкЯпЪ§ОнФПТМКЭРыЯпЪ§ОнжЮРэЁЃ
**дкЯпФПТМ:**ЬсЙЉдЊЪ§ОнSchemaЙмРэФмСІ,ПЩРрБШHive MetastoreЛђAWS Glue зщМў,ЖдНгМЦЫув§ЧцЬсЙЉдЊЪ§ОнаХЯЂЁЃИљОнОпЬхЕФЪЙгУГЁОАКЭЗўЮёЖЈЮЛ,ЮвУЧЗХЦњСЫИќОпСщЛюадЕЋгжИќИДдгЕФдЊдЊФЃаЭЙмРэ,ЖЈвхСЫСНРр:HiveЪ§ОнФЃаЭКЭЭЈгУЪ§ОнФЃаЭЁЃ
HiveЪ§ОнФЃаЭВЮПМдЩњHiveЕФЪ§ОнНсЙЙЩшМЦ,ЭЈЙ§ЖЈвхDBЁЂБэЁЂUDF FunctionЁЂзжЖЮЁЂЗжЧјЁЂДцДЂУшЪі,ЪЙЕУдкЯпФПТМЙІФмОЁПЩФмгыSQL-on-HadoopЕФМЦЫув§ЧцЮоЗьЖдНг;ЖјЭЈгУФЃаЭЭЈЙ§ЖЈвхDBЁЂБэЁЂзжЖЮ,ПЩЪЪХфЛљБОЕФЪ§ОнжЮРэФмСІЁЃ
**РыЯпжЮРэ:**ЬсЙЉЗсИЛЕФдЊЪ§ОнЙмРэгІгУ,АќРЈЪ§ОнЕиЭМЁЂЪ§ОнзжЕфЁЂЪ§ОнМьЫїЁЂБэ/зжЖЮМЖБ№бЊдЕЁЂРрФПЙмРэЁЂБъЧЉЙмРэЁЂЩњУќжмЦкЙмРэЕШЙІФмЁЃГ§дкЯпКЭРыЯпКЫаФЙІФмЭт,ЖрзтЛЇЙмРэЪЕЯжЛьКЯдЦГЁОАЕФЭЈгУзтЛЇЩшМЦ,ЪЙЕУЭГвЛдЊЪ§ОнПЩЪЪХфВЛЭЌГЁОАЁЃ
ЯЕЭГЗўЮёМмЙЙШчгвЭМЫљЪО,ЛљгкЗжВуЮЂЗўЮёЁЂk8sШнЦїЛЏЁЂCICDГжајМЏГЩКЭВПЪ№ЪЕЯждЦдЩњЕФЗўЮёМмЙЙ,ЭГвЛдЊЪ§ОнЕФЗўЮёЗжЮЊШ§Ву:
-
ЛљДЁЗўЮё:гыЪ§ОнПтДцДЂЖдНг,ЬсЙЉЛљДЁЕФдЊЪ§ОнЙмРэФмСІ,АќРЈКЫаФЗўЮёЁЂЪ§ОндДЗўЮёЁЂбЊдЕЗўЮёЁЂЕїЖШЗўЮё;
-
зщМўЗўЮё:вдЗўЮёНјГЬЕФаЮЪНЬсЙЉзщМўЛЏЙІФм,НіЕїгУЛљДЁЗўЮёЬсЙЉЕФНгПк,ВЛгыЪ§ОнПтжБНгЖдНг,АќРЈв§ЧцжБСЌзщМўЁЂЪ§ОнФПТМзщМўЁЂЯћЯЂДІРэзщМў;
-
вЕЮёЗўЮё:ЬсЙЉHTTPНгПкгыОпЬхЕФвЕЮёВњЦЗНЛЛЅ,ИљОнУПИівЕЮёЕФЖРЬиад,ПЩЗжБ№ЬсЙЉВЛЭЌЕФвЕЮёЗўЮёЁЃ
етбљЕФЗжВуЩшМЦ,БЃжЄЛљДЁЗўЮёКЭзщМўЗўЮёЕФЭЈгУад,ОЁПЩФмгыИіадЛЏвЕЮёГЁОАНтёюЁЃЭЌЪБдкЭХЖгПЊЗЂЪЕМљжа,вВБугкВЛЭЌЭХЖгазї,вЕЮёЭХЖгПЩПьЫйЕФВЮгыЕНОпЬхЕФвЕЮёПЊЗЂжаЁЃ
03
зтЛЇЩшМЦ:НщЩмЬкбЖдЦЩЯЕФдЊЪ§ОнзтЛЇ
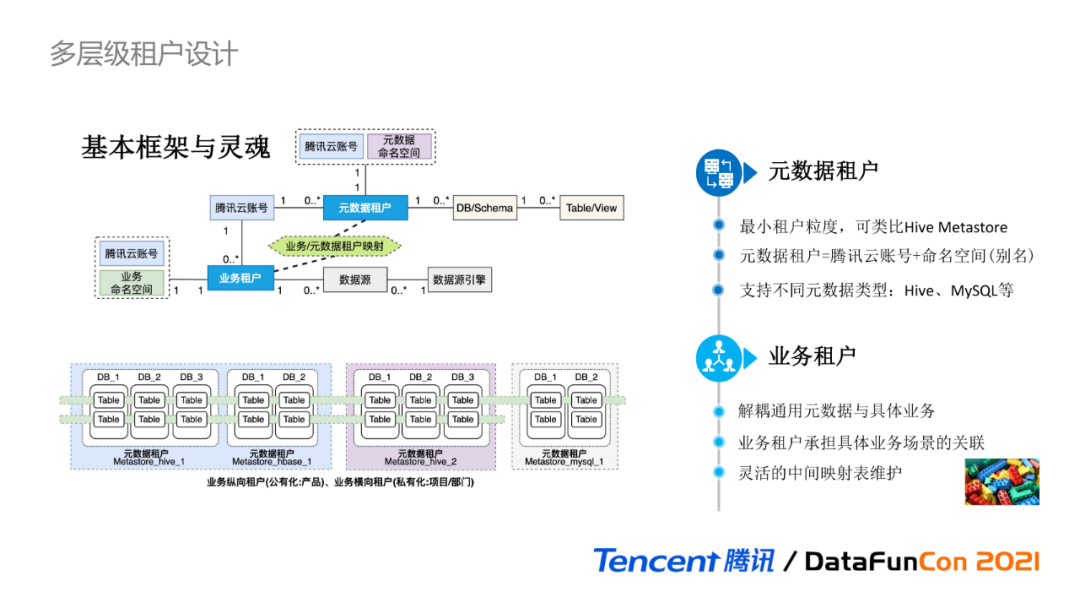
дЊЪ§ОнжаЖрВуМЖЕФзтЛЇЩшМЦЪЧећИіЯЕЭГЕФЛљБОПђМмгыСщЛъ,ЫљгаЕФЪЕЯжТпМЖМЛсвдДЫЮЊЛљДЁНјааЕўМгЁЃЫфШЛетИіСьгђФЃаЭПДЦ№РДБШНЯЦгЫиКЭМђЕЅ,ЕЋдкЩшМЦжЎГѕ,ЮвУЧЭХЖгФкВПЬжТлСЫТљОУВХзюжеШЗЖЈЕФЁЃ
ГщЯѓГідЊЪ§ОнзтЛЇКЭвЕЮёзтЛЇСНИіВуМЖЮЌЖШЕФзтЛЇМЖБ№,РДМмЙЙдЊЪ§ОнЕФЛљБОФмСІКЭТњзуВЛЭЌЕФвЕЮёашЧѓ,ШчСЊАюЖрCatalogЙмРэ,ЖрвЕЮёЕФдЊЪ§ОнДђЭЈЁЃ
дЊЪ§ОнзтЛЇЪЧЯЕЭГжаЕФзюаЁзтЛЇСЃЖШ,ПЩКИЧЭъБИЕФдЊЪ§ОнSchemaаХЯЂ,ВЛЭЌдЊЪ§ОнзтЛЇЪЧЯрЛЅЖРСЂИєРыЕФЁЃвЛИідЊЪ§ОнзтЛЇПЩРрБШЮЊвЛИіHive Metastore,дЊЪ§ОнзтЛЇгыЪ§ОнПтDBЪЧвЛЖдЖрЕФЙиЯЕЁЃвЛИіЬкбЖдЦеЫКХЯТЖдгІЖрИідЊЪ§ОнзтЛЇ,ПЩвдЪЪХфЖрCatalogЙмРэГЁОАЁЃ
ЮЊБугкМЦЫув§ЧцКЭЭтВПЗўЮёЕФНгПкЕїгУ,ЭЌИіЬкбЖдЦеЫКХЯТ,ПЩЖЈвхВЛжиУћЕФдЊЪ§ОнУќУћПеМфзїЮЊБ№УћРДЪЙгУ,гыдЊЪ§ОнзтЛЇвЛвЛЖдгІЁЃдЊЪ§ОнзтЛЇЪЧГщЯѓТпМИХФю,ПЩжЇГжВЛЭЌЕФдЊЪ§ОнРраЭ,ШчHiveЁЂMySQLЕШЁЃ
вЕЮёзтЛЇЕФЩшМЦГѕждЪЧЮЊСЫНтёюЭЈгУдЊЪ§ОнгыОпЬхвЕЮёЕФЧПЙиСЊЙиЯЕ,ЪЙЕУЕзВудЊЪ§ОнзтЛЇгыОпЬхЕФвЕЮёЪЧЮоЙиЕФ,гЩвЕЮёзтЛЇГаЕЃОпЬхвЕЮёГЁОАЕФЙиСЊгыЮЌЛЄЁЃЪ§ОндДвЛАугЩвЕЮёЪЙгУЗНЬсЙЉЕФ,вђДЫЩшМЦЮЊгывЕЮёзтЛЇЯрЙи,вЛИівЕЮёзтЛЇПЩЖдгІЖрИіЪ§ОндДЁЃ
ашвЊЬиБ№ЙизЂЕФЪЧ:дЊЪ§ОнзтЛЇгывЕЮёзтЛЇБОЩэУЛгажБНгЧвУїШЗЕФЙиСЊЙиЯЕ,ЫќУЧЕФЙиЯЕгЩжаМфгГЩфБэЮЌЛЄ,ИУгГЩфЙиЯЕЪЧСщЛюЕФ,гЩОпЬхЕФвЕЮёТпМОіЖЈЕФ,ВЛЭЌвЕЮёГЁОАЪЙгУЕФжаМфгГЩфБэВЛЭЌ,аТдівЛжжаТвЕЮёРраЭ,НіашРЉеЙжаМфгГЩфЙиЯЕБэЁЃ
вЕЮёзтЛЇгыдЊЪ§ОнзтЛЇЕФгГЩфЙиЯЕ,ПЩвдЗжЮЊСНРрЕФЛЎЗж:
-
знЯђЛЎЗж:ПЩгУгкЙЋгадЦГЁОА,ДгзнЯђЖддЊЪ§ОнзтЛЇНјааКЯВЂЛЎЗж,вЛИівЕЮёзтЛЇЖдгІвЛИідЦЩЯВњЦЗ,УПИіВњЦЗжЎМфдЊЪ§ОнЪЧТпМИєРыЕФ,ЖјДгЬкбЖдЦеЫКХетИіИќИпЮЌЖШ,гжПЩЖдЖрИівЕЮёВњЦЗНјааЙТЕКдЊЪ§ОнЕФДђЭЈ;
-
КсЯђЛЎЗж:ПЩгУгкЫНгадЦГЁОА,ДгКсЯђЖддЊЪ§ОнзтЛЇНјааЙВЯэМАВ№Зж,вЛИівЕЮёзтЛЇЖдгІвЛИіЙЋЫОВПУХ,ЫљгаВПУХЖМЙВЯэвЛИіЫНгаЛЏМЏШККЭдЊЪ§ОнзтЛЇ,ВПУХжЎМфЭЈЙ§DBЮЌЖШНјааИєРы,дђжаМфБэЮЌЛЄВПУХЁЂдЊЪ§ОнзтЛЇКЭDBУћГЦЕФЙиЯЕЁЃ
04
ЙІФмФЃПщ - дкЯпФПТМ
ЯТУцЮвУЧНјШыЭГвЛдЊЪ§ОнЕФЕквЛИіКЫаФЙІФмФЃПщ:дкЯпЪ§ОнФПТМЁЃдквЕНчЗНАИжа,Hive MetastoreЪЧHadoopЩњЬЌШІжаЪ§ОнФПТМЙмРэЕФЪТЪЕБъзМ,ЮЊSQL on HadoopЕФЗжЮіМЦЫув§ЧцЬсЙЉЭЈгУЕФSchemaЙмРэФмСІЁЃ
дкDLCЪ§ОнКўМЦЫуГЁОАжа,ЮЊБЃжЄМЦЫув§ЧцгыЭГвЛдЊЪ§ОнФмЙЛзюаЁГЩБОЕФЮоЗьЖдНг,ЮвУЧЪзЯШПМТЧЕФЪЧШчКЮНјааHive MetastoreЕФИФдьЪЕЯж,ЬсЙЉБЃГжвЛжТЕФMetastore RPCНгПк,ШУМЦЫув§ЧцЖдЕзВудЊЪ§ОнЕФЗўЮёаЮЬЌСуИажЊЁЃ
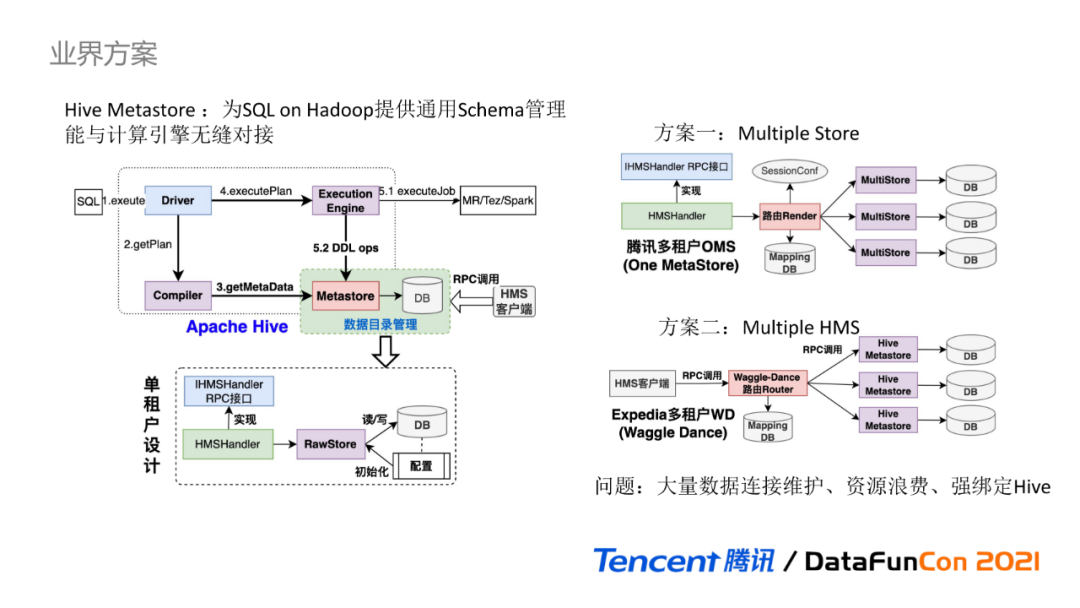
ЪзЯШРДДѓжТЛиЙЫHiveжДааЕФСїГЬ:гЩDriverДЅЗЂSQLНтЮі,CompilerБрвыЦїНјааБрвыНтЮіЛёШЁТпММЦЛЎЖдЯѓ,ЛсЛљгкHive Metastore RPCНгПкЛёШЁSchemaдЊЪ§ОнаХЯЂ,гУгкаЃбщКЭЗсИЛТпММЦЛЎЖдЯѓЁЃ
ТпММЦЛЎзЊЛЛЮЊПЩжДааЕФЮяРэМЦЛЎ,гЩExecution EngineжДаав§ЧцДЅЗЂжДаа,ЦфжаШєЩцМАдЊЪ§ОнБфИќВйзї,ЛсЕїгУHive Metastore RPCНгПкНјаадЊЪ§ОнБфИќ,ВЂзюжеНЋдЊЪ§ОнаХЯЂГжОУЛЏЕНRDBMSЁЃHive MetastoreЪЧЕфаЭЕФЕЅзтЛЇЩшМЦ,ВЛЭЌгУЛЇжЎМфSchemaЮоЗЈЭъШЋИєРы,ЮожЇГжДДНЈжиУћЪ§ОнПтЁЃ
Hive MetastoreЕФФкВПЩшМЦвЊЕуЪЧЛљгкHMSHandlerРрЭъШЋЪЕЯжIHMSHandlerРрЖЈвхЕФRPCНгПк,HMSHandlerЛљгкRawStoreРрДгХфжУжаМгдиГжОУВуЕФЪ§ОнПтСЌНгаХЯЂВЂГѕЪМЛЏ,зюжеЪ§ОндЊЪ§ОнЖСаДВйзїгЩRawStoreЛљгкJDOПђМмЪЕЯжЁЃ
ЮЊРЉеЙКЭжЇГжHive MetastoreЪЕЯжЖрзтЛЇЕФФмСІ,вЕНчгаВЛЭЌЕФЪЕЯжЗНАИ,жївЊЗжЮЊСНРрЁЃ
ЗНАИвЛ:вдЬкбЖЖрзтЛЇOMSЕФЪЕЯжЮЊР§,ЭЈЙ§ЧжШыаоИФHive MetatsoreЕФдДТы,дкHMSHandlerСЌНгRawStoreжЎМфаТдіТЗгЩЙмРэЦї,ДгRPCСЌНгЕФSessionХфжУЛёШЁСЌНгБъЪЖ,ИљОнБъЪЖ,ДггГЩфDBжаЛёШЁОпЬхЕФJDBCСЌНгаХЯЂВЂГѕЪМЛЏ,зюжегЩЖдгІЕФMultiStoreЭъГЩдЊЪ§ОнЖСаДВйзї,ЖрзтЛЇЪЕЯжПЩРэНтЮЊЖрИіСЌНгДцДЂMultiStoreЁЃ
ЗНАИЖў:вдExpediaЙЋЫОЕФWD(Waggle Dance)ЪЕЯжЮЊР§,дкHive MetastoreжЎЭтдіМгТЗгЩЙмРэЗўЮё,гУЛЇЕїгУТЗгЩЗўЮёЬсЙЉЕФRPCНгПк,ЭЈЙ§ХфжУДггГЩфDBжа,НЋRPCЧыЧѓТЗгЩзЊЗЂЕНеце§ЕФHive MetastoreЩЯ,ЖрзтЛЇЪЕЯжПЩРэНтЮЊЖрИіHive MetastoreЁЃЫфШЛЗНАИЖўЖддЩњHive MetastoreЧжШыадНЯаЁ,ЕЋвВдіЖрСЫвЛВуЧыЧѓСДТЗЁЃ
вдЩЯСНжжЗНАИЖМВЛЪЪгУгкЙЋгадЦЪ§ОнКўГЁОАЁЃЪзЯШ,СНжжЖрзтЛЇЗНАИЕзВуЖМЪЧЭЈЙ§АѓЖЈЖРСЂЕФЪ§ОнПтСЌНгЪЕЯж,вЛИізтЛЇМДЮЊвЛИіЖРСЂЕФЪ§ОнПтСЌНг,ашвЊНјааДѓСПЕФЪ§ОнПтСЌНгЙмРэ;ЦфДЮ,ЙЋгадЦГЁОАЛсДцдкКмЖрГЄЮВЪдгУгУЛЇ,ДѓСПЕФЗЧЛюдОгУЛЇЛсдьГЩЪ§ОнПтзЪдДЕФРЫЗб;зюКѓ,СНжжЗНАИЖМгыHive MetastoreЕФЪ§ОнФЃаЭКЭЪЕЯжТпМЧПАѓЖЈ,ЖдгкЪЕЯжЪ§ОнжЮРэЙІФм,ДцдкКмгВадЕФЯожЦЬѕМўЁЃ
ЮвУЧзюжебЁдёЕФЪЕЯжЗНАИЪЧжиаТЪЕЯжHive Metastore RPCНгПк,ДѓжТЕФЪЕЯжСїГЬШчЭМЫљЪО:аТдіздЖЈвхHandlerРрМЬГаIHMSHandler,ЭъШЋжиаТЪЕЯжThriftЮФМўRPCНгПкЁЃФкВПдіМгRPCШЯжЄМјШЈВйзї,ВЂзюжеЖдЭтЬсЙЉRPC ServerЗўЮёЁЃ
здЖЈвхHandlerжївЊИКд№ДІРэMetastoreТпМКЭЪ§ОнзЊЛЛВйзї,еце§ЕФдЊЪ§ОнГжОУЛЏЭЈЙ§ЗўЮёМфRPCЕїгУзюжегЩдЊЪ§ОнЛљДЁЗўЮёЭъГЩЁЃдкЯпФПТМГ§ЬсЙЉЭъШЋМцШнHive MetastoreЕФRPCНгПкЭт,ЛЙЬсЙЉСЫHTTPНгПкЙЉВЛЭЌЕФВњЦЗЪЙгУЁЃИУЪЕЯжЗНАИЫфШЛОпгаКмЧПЕФСщЛюад,ЕЋећЬхЪЕЯжКЭЮЌЛЄГЩБОЦЋИп,ВЂВЛЪЪКЯЫљгаГЁОАЁЃ
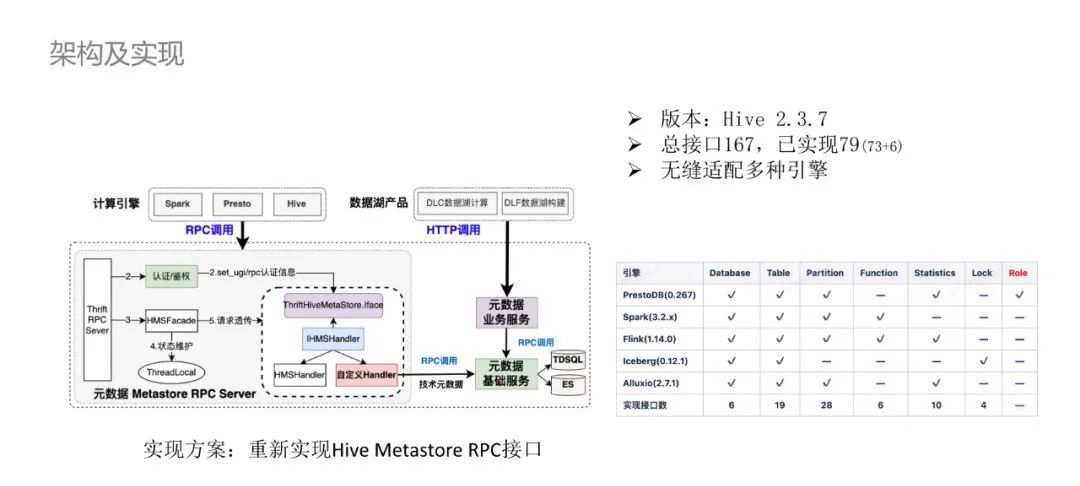
ФПЧАздбаЕФдЊЪ§ОнMetastoreЙЙНЈдкHive 2.3.7АцБОжЎЩЯ,RPCЮФМўЖЈвхЕФНгПкзмЪ§га167Иі,вбЪЕЯжНгПкЪ§79Иі,жївЊАќРЈСљРр:Ъ§ОнПтЁЂЪ§ОнБэЁЂЗжЧјЁЂздЖЈвхUDFЁЂЭГМЦдЊЪ§ОнЁЂЪТЮёЫј,вбОпБИЮоЗьЖдНгЖрв§ЧцЕФФмСІЁЃ
ЮвУЧвбЩЯЯпВЂЪЪХфЪЙгУЕФв§ЧцгаPrestoDBЁЂSparkЁЂFlinkЁЂIcebergЁЂAlluxioЁЃУПИів§ЧцЫљЪЙгУЕНЕФНгПкЗЖЮЇШчЩЯБэЫљЪО,РЖЩЋКсЯпДњБэИУв§ЧцВЛЛсЕїгУетРрRPCНгПкЁЃ
вђЮЊбЁдёЪЙгУЭъШЋжиаДЕФЗНАИ,ЮвУЧПЩвдЛљгкMetastoreНјааЩюЖШгХЛЏЁЃЖдгкЪ§ОнФЃаЭ,ЮвУЧдкHive MetastoreЕФдЩњФЃаЭжЎЩЯНјааЖўДЮГщЯѓКЭМђЛЏЁЃ
КЫаФФЃаЭгЩ12ИіМѕЩйЕН6Иі,жївЊЕФИФдьАќРЈ:
Ђй ШЅГ§PARAMSБэ:НЋKVЕФХфжУВЮЪ§ЙиСЊБэвдJsonзжЗћДЎЕФаЮЪНзїЮЊЪ§ОнФЃаЭЕФвЛИізжЖЮ;
Ђк ЭГвЛФЃаЭ:НЋЗжЧјзжЖЮгыЗЧЗжЧјзжЖЮЭГвЛГЩвЛИіЪ§ОнФЃаЭ;
Ђл МђЛЏSDS:МђЛЏДцДЂУшЪіSDSЯрЙиСЊЕФЪ§ОнФЃаЭ;
Ђм зтЛЇЮЌЛЄ:DBКЭTableжЎЩЯдіМгСЫдЊЪ§ОнзтЛЇЕФзжЖЮЮЌЛЄЁЃ
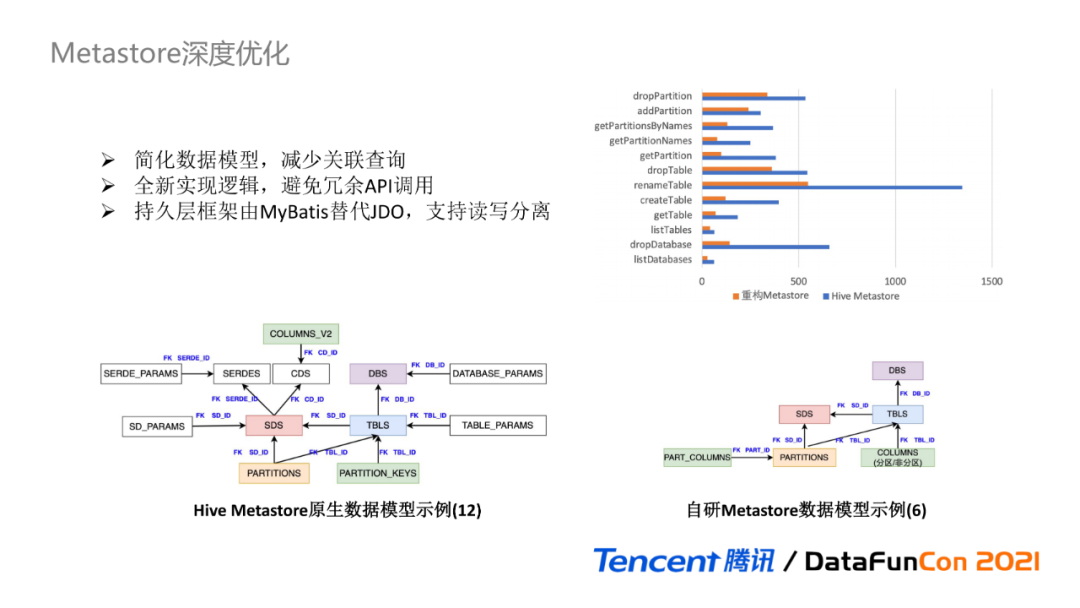
МђЛЏКѓЕФЪ§ОнФЃаЭ,ПЩвдМѕЩйДѓСПЕФЪ§ОнПтЙиСЊВщбЏ,ЖјШЋаТЕФЪЕЯжТпМ,ДгИљдДЩЯМѕЩйСЫШпгрAPIЕФЕїгУВЂНјаажДааТпМгХЛЏ;ГжОУВуПђМмгЩИќСщЛюЕФMybatisЬцДњJDO,жЇГжЛљгкЪ§ОнПтЕФЖСаДЗжРыЁЃ
ИУЭМеЙЪОСЫ100ДЮНгПкжиИДЕїгУЯТ,ПтЁЂБэЁЂЗжЧјЕФИїНгПкЕФКФЪБЖдБШ,ПЩвдПДГіжиЙЙКѓMetastoreЕФКФЪБдЖЕЭгкдЩњHive MetastoreКФЪБЁЃ

ЖдгкдкЯпЪ§ОнФПТМ,Г§СЫЬсЙЉSchemaЙмРэЭт,ЛЙЬсЙЉСЫЭЈгУЕФЭГМЦдЊЪ§Он,ЮЊCBOгХЛЏЦїжњСІЁЃЪзЯШМђвЊЛиЙЫЯТSQLЕФНтЮіжДааСїГЬ,SQLгяОфОЙ§ДЪЗЈ/гяЗЈКЭгявхНтЮіКѓ,ЛёЕУЦгЫиЕФТпМЫузгЪї,ОЙ§ВщбЏгХЛЏЦїЕФДњЪ§ТпМгХЛЏ,ЛёШЁЦфжазюЖЬжДааТЗОЖЕФТпМЫузгЪї,зюКѓТпМЫузгЪїзЊЛЛЮЊЮяРэЫузгЪїВЂЬсНЛжДаав§ЧцЁЃ
ВщбЏгХЛЏЦїЪЧSQLв§ЧцЕФжиЕуКЫаФФмСІ,ГЃМћЕФгХЛЏЦїгаЛљгкЙцдђЕФRBOгХЛЏЦїКЭЛљгкДњМлЕФCBOгХЛЏЦї,ЦфжаCBOгХЛЏЦїПЩЭЈЙ§ИажЊЪ§ОнРДЕїећжДааМЦЛЎ,дкДѓЪ§ОнСьгђИќЪмЛЖгЁЃ
CBOЕФвЊЫигЩЭГМЦаХЯЂКЭДњМлФЃаЭЙЙГЩ,ЮЊМгЫйМЦЫугХЛЏ,ЭГвЛдЊЪ§ОнЬсЙЉЖрв§ЧцЭЈгУЕФЭГМЦдЊЪ§ОнЙІФм,жЇГжБэЁЂЗжЧјЁЂзжЖЮМЖБ№ЕФЭГМЦдЊЪ§Он,ОпЬхИїМЖБ№ЕФЭГМЦаХЯЂШчЯТБэЫљЪОЁЃ
Жрв§ЧцЭЈгУЭГМЦдЊЪ§ОнЕФЪЕЯжСїГЬДѓжТШчЯТ:HiveЁЂSparkЁЂPrestoжЇГжANALYZEгяОф,ЭЈЙ§жДааANALYZEЗжВМЪНШЮЮё,МЦЫуГіЭГМЦдЊЪ§Он,МЦЫув§ЧцЕїгУдЊЪ§ОнMetastoreНгПкГжОУЛЏЭГМЦдЊЪ§ОнЁЃ
ЕЋДцдкЕФвЛИіЮЪЬт:ВЛЭЌЕФМЦЫув§ЧцЪЙгУЕФЭГМЦдЊЪ§ОнЖСаДНгПкПЩФмВЛЭЌЁЃдЊЪ§ОнMetastoreзїЮЊжазЊВу,ЛсИљОнМЦЫув§ЧцРраЭНјаазЊЛЛДІРэ,ЪЙЕУЭГМЦдЊЪ§ОнЖдгкВЛЭЌв§ЧцЖМЪЧЭЈгУадЁЃ
ШчPrestoМЦЫуГіЕФЭГМЦдЊЪ§Он,дкSparkжДааSQL,ПЩжБНгЛёШЁЖдгІЭГМЦаХЯЂНјааCBOгХЛЏ,ЖјЮоашдйДЮANALYZEМЦЫуЁЃ
05
ЙІФмФЃПщ - Ъ§ОнжЮРэ
[ЭтСДЭМЦЌзЊДцЪЇАм,дДеОПЩФмгаЗРЕССДЛњжЦ,НЈвщНЋЭМЦЌБЃДцЯТРДжБНгЩЯДЋ(img-mXIDMPC3-1649207876432)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]
зюКѓНјШыЭГвЛдЊЪ§ОнЕФЕкЖўИіКЫаФЙІФмФЃПщ:РыЯпЪ§ОнжЮРэЁЃеыЖддЊЪ§ОнжЮРэ,ИїРрПЊдДЗНАИдквЕНчВуГіВЛЧю,етРяСаОйСЫМИИівЕФкБШНЯСїааЕФдЊЪ§ОнЙмРэзщМў:
-
Apache Atlas:ЪЧЛљгкHadoopжЎЩЯЕФдЊЪ§ОнЙмРэПђМм,жївЊвдМЦЫув§ЧцHookЕФЗНЪН,РДЛёШЁдЊЪ§ОнаХЯЂ,ВЂЬсЙЉЛљБОЕФдЊЪ§ОнгІгУЙмРэ;
-
LinkedIn DataHub:ЪЧLinkedIn WarehowsЕФЧАЩэ,ЬсЙЉдЊЪ§ОнЫбЫїМАМЏГЩЙІФм;
-
Lyft Amundsen:зюНќБШНЯШШУХЕФдЊЪ§ОнЙмРэЯЕЭГжЎвЛ,гЩlyftПЊдДЕФЪ§ОнЗЂЯжЦНЬЈЁЃ
ЛљгквЕНчЗНАИЕїба,ПЩвдзмНсГівдЯТЙцТЩ:
-
ПЊдДЕФЪ§ОнжЮРэВњЦЗвВдкВЛЖЯЕќДњИќаТ:ДгЕЅЬхЗўЮёЕНЗжВуЗўЮё,ЕНвдЯћЯЂЧ§ЖЏЮЊжї,КмЖржїСїЕФдЊЪ§ОнЙмРэЯЕЭГ,ЛсВЩгУЯћЯЂжаМфМўРДНтёюЪ§ОнВЩМЏКЭЪ§ОнМгЙЄ,ЪЙЕУЯЕЭГИќОпЭЈгУадЁЃаТдіЕФвьЙЙЪ§ОндД,НіашАДееЙцЖЈЕФЯћЯЂИёЪНЗЂЫЭдЊЪ§ОнЕНЯћЯЂжаМфМў,дЊЪ§ОнОЭПЩвдБЛЯЕЭГНјааМгЙЄДІРэ;
-
ЭъећЕФЪ§ОнжЮРэЯЕЭГПЩвдЗжЮЊЫФИіЛљБОФЃПщ:дЊФЃаЭЖЈвхЁЂдЊЪ§ОнВЩМЏЁЂдЊЪ§ОнМгЙЄМАДцДЂЁЂдЊЪ§ОнгІгУ;
-
Ъ§ОнжЮРэЗўЮёГЃгУЕФЛљДЁзщМўга:ЙиЯЕаЭЪ§ОнПт,гУгкдЊЪ§ОнДцДЂ;Ыїв§Ъ§ОнПт,гУгкЪ§ОнМьЫїЕФ;ЭМЪ§ОнПт,гУгкЙиСЊЪ§ОнДцДЂ,ШчЪ§ОнбЊдЕЛђепдЊЪ§ОнЪЕЬх;ЯћЯЂжаМфМў,гУгкНтёюдЊЪ§ОнВйзї;ЕїЖШв§Чц,гУгкжДааВЩМЏШЮЮёЁЃ
вдAtlasЮЊР§,дЊФЃаЭЖЈвхдкCoreФЃПщType SystemжаЪЕЯж;дЊЪ§ОнВЩМЏдкIntegrationМЏГЩФЃПщНгЪедЊЪ§ОнHookЯћЯЂВЂЩњВњЕНЯћЯЂжаМфМў;дЊЪ§ОнМгЙЄМАДцДЂдкCoreФЃПщДІРэ,ЛљгкGraph EngineГжОУЛЏЁЃ
дЊЪ§ОнгІгУдкAppsФЃПщжаЪЙгУ;ЪЙгУKafkaзїЮЊЯћЯЂжаМфМў,ЪЙгУESЫїв§Ъ§ОнПтНјааЪ§ОнМьЫї;ЪЙгУJanusGraphЭМЪ§ОнПтНјаадЊЪ§ОнЪЕЬхДцДЂ,ЖјбЊдЕЯћЯЂвВзїЮЊЦфжавЛРрдЊЪ§ОнЪЕЬхЁЃ
ЯТБэеЙЪОСЫИїИіПЊдДЯЕЭГгыЬкбЖдЊЪ§ОнжЮРэЙІФмЕФЖдБШ,ЦфжаЬкбЖдЊЪ§ОнЕФЯюФПДњКХЮЊHybris,ПЩвдПДГіЬкбЖЭГвЛдЊЪ§ОнвбОпБИЗсИЛЕФЪ§ОнжЮРэФмСІЁЃ
Г§ЙІФмЕФЭъећадЖдБШЭт,АДееЮвУЧЕФвдЭљОбщ,ПЊдДЕФЪ§ОнжЮРэЯЕЭГдкЪЕМЪвЕЮёжаКмФбжБНгЕФЪЙгУЦ№РД,вђЮЊЪ§ОнжЮРэЪЧгывЕЮёСьгђКЭаЮЬЌУмЧаЯрЙи,жБНгЪЙгУОпгавЛЖЈГщЯѓадЧвЭЈгУЕФПЊдДЯЕЭГ,жЛФмЛёШЁБШНЯЛљДЁЕФЪ§ОнжЮРэФмСІ,КмФбЕУЕНвЕЮёЯрЙиЕФЪ§ОнМлжЕЁЃШєгывЕЮёНсКЯ,дђашвЊЖдПЊдДЯЕЭГНјааЩюЖШИФдьЕФЖўДЮПЊЗЂ,вђДЫдкЪ§ОнжЮРэВПЗжЮвУЧвВбЁдёЭъШЋздбаЁЃ
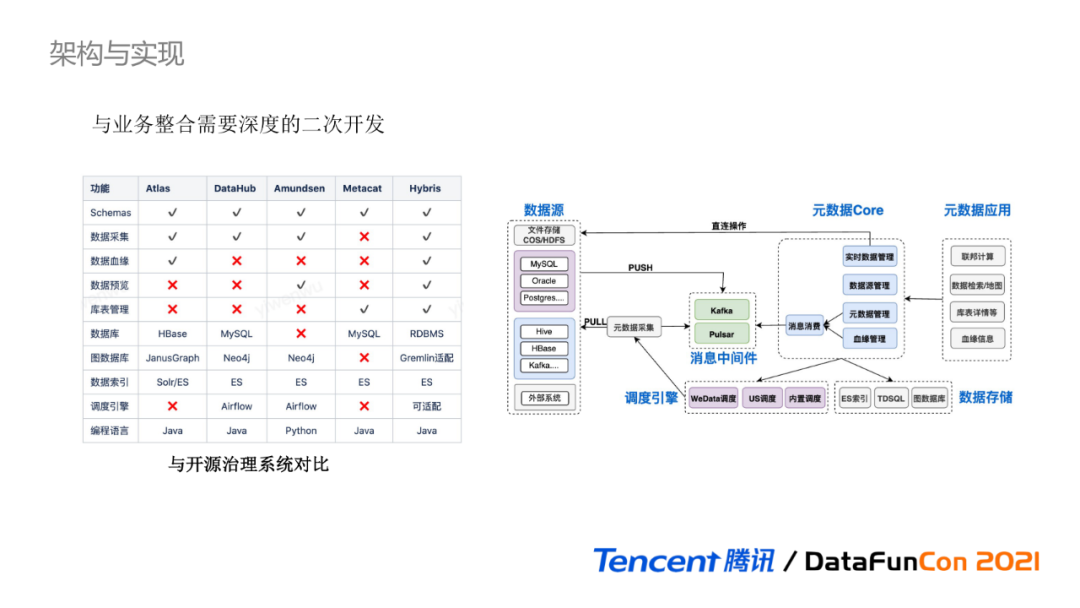
Ъ§ОнжЮРэЕФећЬхМмЙЙ:дкЙЋгадЦГЁОА,гЩЕїЖШв§ЧцДЅЗЂРыЯпВЩМЏЕїЖШШЮЮё,ЭЈЙ§PULLЖЈЪБРШЁЕФХРГцЗНЪНВЩМЏвьЙЙЪ§ОндДЕФдЊЪ§ОнаХЯЂ,ВЂНЋдЊЪ§ОнЗЂЫЭЕНЯћЯЂжаМфМўЁЃ
дЊЪ§ОнCoreжаЕФдЊЪ§ОнЙмРэКЭбЊдЕЙмРэЭЈЙ§ЯћЯЂЯћЗбЛёШЁЖдгІЕФдЊЪ§ОнНјааМгЙЄДІРэ,ВЂНЋдЊЪ§ОнГжОУЛЏЕНЪ§ОнПтЁЃ
Г§РыЯпВЩМЏЭт,вВЬсЙЉСЫжБНгЪ§ОндДв§ЧцЛёШЁЪЕЪБдЊЪ§ОнКЭНјааПтБэЙмРэЕФВйзїЁЃзюжегЩдЊЪ§ОнгІгУЙІФмЬсЙЉЖрбљЛЏЕФжЮРэЙІФмЁЃ