目录
2.重建库表时需要对应好,可能数据类型有所变化,但是其真正实现要一致。
其次,有人说,我可以使用 try-finally的方式关闭资源
在项目重构的时候,少不了数据迁移。所谓数据迁移,一般都是指从一个数据库迁移到另外一个数据库 ,而且这个数据库都变了。比如,从Oracle迁移到Maria(MySQL)上等。市面上有现成的数据迁移工具,如果公司允许使用这些工具的话,当然没问题,但是如果公司不允许使用,需要我们自己开发做数据迁移,那这个时候就需要我们自己开发代码来完成了。
一、注意事项
做数据迁移的时候需要注意的几点:
1.如何触发触发程序执行
数据迁移代码的执行最好是手动触发。什么意思呢?意思就是你通过一定的方式触发后台代码自动执行。可以实现的方式有:
1)curl方式,可以get和post请求;
2)接口方式,通过url请求调用;
3)shell脚本调用后台代码方式;
4)文件监听方式;
1)和2)比较简单,我们就不赘述了,3)就是通过shell脚本调用Java代码的方式触发后台程序,一般程序员都知道Java代码调用shell脚本,却有不少人不知道shell脚本调用后台代码的。这个其实也不复杂,可以自行百度。4)的话主要是监听一个文件目录,如果有新增文件,或者新增指定的文件,自动触发后台代码。其依赖的是commons-net包下的实现方案。这一种网上也有很多资料,大家可以自行百度,或者下面参考我的。
2.重建库表注意事项
重建库表需要对应好,可能数据类型有所变化,但是其真正实现要一致。比如在Oracle中存储字符串一般用的是varchar2,而在mysql或者Maria中用的则是varchar。再比如,日期时间等字段、索引、序列号、视图等,重建表之前要判断是否和原数据库的实现方案是一致的,不一致则要修改,需要注意这一点。
3.记录失败原因
?数据迁移时,如果迁移失败,需要记录失败原因,方便查找解决问题。
4.自动重试
因为数据迁移的时候,一次性大量数据做io操作,一不小心就容易出错。那么我们就需要在代码中进行自动重试,可以加一个循环即可,里面增加条件判断,失败则进行下一轮循环,成功则结束。
5.异常处理
不少人觉得异常处理不是很简单吗?作为一个有两三年开发经验的程序员都可以的。事实是,有些时候的异常处理是需要特别注意的。有些时候该抛异常,有些时候需要捕获打日志,或者捕获之后再抛出去,按照公司或项目的要求抛出指定的异常,而不是原生的异常。
关于异常这一点,首先你需要有一定的开发经验,其次你要对异常处理以及finally的处理有了解,或者准确说熟悉掌握这一点,这个其实不难,有两三年开发经验的人,只要去关注过这一块其实就是ok的。
二、数据初始化
注意事项说完了,我们开始进行数据初始化工作。
注意:本文讲的是将数据从Oracle中迁移到Maria中,Maria是mysql的另一个分支,和mysql基本没有什么区别――指的是在我们日常的SQL这一块。
首先,建表
你要建一张表,起名为数据迁移记录表。
CREATE TABLE `DATA_MIGRATION_RECORD` (
`ID` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',
`MIGRATE_TABLE_NAME` varchar(32) NOT NULL COMMENT '迁移表名称',
`STATUS` char(1) NOT NULL DEFAULT '0' COMMENT '迁移状态:0-未迁移,1-迁移中,2-成功,3-失败',
`RETRY_COUNT` int(11) DEFAULT NULL,
`FAILURE_REASON` varchar(128) DEFAULT NULL COMMENT '失败原因',
`CRT_TIME` timestamp NOT NULL DEFAULT current_timestamp() COMMENT '创建时间',
`UPD_TIME` timestamp NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp() COMMENT '更新时间',
PRIMARY KEY (`ID`) COMMENT '主键Id',
UNIQUE KEY `IDX_MIGRATE_TABLE` (`MIGRATE_TABLE_NAME`) COMMENT '迁移表名称索引'
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='数据迁移记录表'解释一下:
迁移表名称或者说表名:指的是Oracle中将要迁移的表名;
迁移状态:指的是迁移是我们需要记录该表迁移的状态;
重试次数(RETRY_COUNT):指的是我们代码自动进行重试的次数,一般情况下都是3-5次即可;
其他的就不需要解释了。
其次,数据做初始化
也就是说需要把将要迁移的表的信息插入这个迁移记录表中,除了表名,需要一一引入,其他都是一样的。id可以自增长,或则自定义都可以;表名就是将要迁移的表名,状态初始值为0-未迁移;重试次数初始值默认0;失败原因为空即可;创建时间和更新时间随系统即可。
2.1.如何做初始化呢?
这里我提供两种方案:
1.通过insert语句插入数据,其中表名修改成将要迁移的数据库中的表名即可
这种方案比较简单,没有难度,只是说需要一些手工操作,需要copy原数据库的表名,比较繁琐,需要认真自信;不过这数据迁移都要做uat测试的,保证了这一点上生产的时候就没有太大问题。可能有些人觉得,如果我表特别多怎么办,几十、几百张表,我一个一个的copy,多麻烦啊,有没有其他的自动方案呢?答案是有的。其实,如果只有几十张表,直接copy就可以了,然后通过insert语句操作也很简单省事。如果不想使用这个方案,那我们说一下自动的方案。
2.查询原库所有表,然后插入新库的迁移记录表中
比如,在Oracle追踪,我们可以查询到所有的表,但是这个所有的表指的是非系统表,也就是说是我们自己建的表。
-- 当前用户拥有的表
select table_name from user_tables;
-- 所有用户的表
select table_name from all_tables;
-- 包括系统表
select table_name from dba_tables;看了上面3个SQL,你可能说,那不就是用第二个SQL吗?正好满足,实际上不是的。
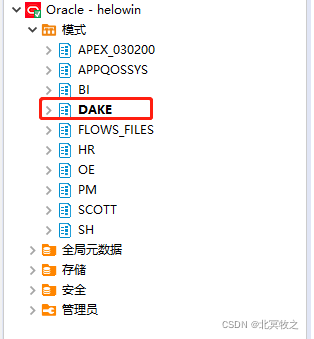
?上图中,除了DAKE这个模式是我自己新建的,其他的都是系统自带的,而DAKE下面只有一张表。

?如果你使用上面第二个SQL查询的话,可以查询出来2779条记录,第三个也是的。实际上这个是包含了root用户的所有模式在内的模式。说到模式,这个是Oracle特有的,mysql没有这个东西,你可以理解成库也可以,虽然不准确。
所以我们需要使用上面的第一个SQL,也就是:
-- 当前用户拥有的表
select table_name from user_tables;但是需要一个权限比较高的可以查看所有模式和表的用户,因为在数据库中我们可以通过用户名来限制访问哪些数据库或者说是模式。
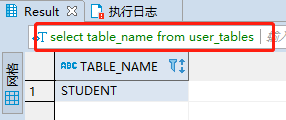
可以看到,我们执行该SQL之后,数据只有一条,就是STUDENT。
我们可以通过这个SQL,结合原生jdbc的方式通过代码插入到 数据迁移记录表(DATA_MIGRATION_RECORD)中。到了这里,后面的代码我们就不赘述了,自行百度,很简单。
注意:
1.查询出的数据,插入的时候,有多少数据,就要插入多少条才行,需要对应好。
2.怎么触发代码,参照我上面那个说的触发代码的方式,未尽之处,下文详解。
这一点做完之后,需要将要插入到的数据库和表准备好,也就是Maria或mysql中对应的表建好,不然怎么迁移呢?
三、数据迁移
准备工作好 了,我们开始做真正的迁移工作。
1.配置数据库连接
oracle.host=192.168.xxx.xxx
oracle.port=1521
#oracle.database=dake
oracle.service.name=helowin
oracle.driver=oracle.jdbc.driver.OracleDriver
oracle.jdbcUrl=jdbc:oracle:thin:@${oracle.host}:${oracle.port}:${oracle.service.name}
oracle.userName=dake
oracle.password=dake
maria.host=192.168.xxx.xxx
maria.port=3306
maria.database=study
maria.driver=org.mariadb.jdbc.Driver
maria.jdbcUrl=jdbc:mariadb://${maria.host}:${maria.port}/${maria.database}?useUnicode=true\
&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
maria.userName=dake
maria.password=1234562.DB工具类
package com.dake.util;
import com.dake.entity.MariaConfig;
import com.dake.entity.OracleConfig;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.*;
public class DBUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(DBUtils.class);
private static final int PAGE_SIZE = 5;
private static final OracleConfig ORACLE_CONFIG;
private static final MariaConfig MARIA_CONFIG;
static {
ORACLE_CONFIG = SpringContextUtil.getBean(OracleConfig.class);
MARIA_CONFIG = SpringContextUtil.getBean(MariaConfig.class);
}
/**
* 批量插入
*
* @param tableName 表名
*/
public static String insertWithBatch(String tableName) {
// 查询数据总量
String sql = "select count(0) from " + tableName;
PreparedStatement ps = null;
Connection conn = null;
ResultSet resultSet = null;
String reason = "";
try {
conn = getOracleConnection();
ps = conn.prepareStatement(sql);
resultSet = ps.executeQuery();
int rowCount = 0;
while (resultSet.next()) {
rowCount = resultSet.getInt("COUNT(0)");
}
LOGGER.info("---------【{}】表一共有【{}】条数据---------", tableName, rowCount);
int result = rowCount % PAGE_SIZE;
int pageCount = rowCount / PAGE_SIZE;
pageCount = result == 0 ? pageCount : pageCount + 1;
LOGGER.info("---------一共分【{}】页查询,每页【{}】条数据---------", pageCount, PAGE_SIZE);
for (int i = 0; i < pageCount; i++) {
LOGGER.info("---------第【{}】页数据迁移开始---------", i + 1);
String failureReason = insertWithBatch(tableName, i);
if (StringUtils.isNotBlank(failureReason)) {
return failureReason;
}
}
} catch (SQLException | ClassNotFoundException e) {
reason = "查询 Oracle 的" + tableName + "表数据总量失败";
LOGGER.error(reason, e);
} finally {
try {
close(resultSet, ps, conn);
} catch (SQLException e) {
reason = "查询 Oracle 的" + tableName + "表数据总量时,关闭 Oracle 数据库资源失败";
}
}
return reason;
}
/**
* 批量插入
*
* @param tableName 表名
* @param pageIndex 页码
*/
private static String insertWithBatch(String tableName, int pageIndex) {
int count;
long start;
Connection oracleConn = null;
PreparedStatement ps = null;
ResultSet oracleResultSet = null;
Connection mariaConn = null;
PreparedStatement mariaPs = null;
String failureReason = "";
try {
oracleConn = getOracleConnection();
String afterPagingSql = getSqlAfterPaging(tableName, pageIndex);
LOGGER.info("---------分页查询的SQL是:【{}】---------", afterPagingSql);
ps = oracleConn.prepareStatement(afterPagingSql);
oracleResultSet = ps.executeQuery();
int columnCount = oracleResultSet.getMetaData().getColumnCount();
// 因为分页查询语句中增加了 rownum 这一列,导致的结果就是,最外层的分页SQL查询出的字段数量比表中的全部字段多了一个 rownum 这个字段
// 所以在获取该表的所有列的数量时就要减一
columnCount -=1;
LOGGER.info("---------【{}】表一共有【{}】列数据---------", tableName, columnCount);
StringBuilder sb = new StringBuilder();
sb.append("insert into ").append(tableName).append(" values (");
for (int i = 0; i < columnCount; i++) {
sb.append("?").append(" ").append(",");
}
sb.deleteCharAt(sb.lastIndexOf(","));
sb.append(")");
LOGGER.info("---------批量插入的SQL是:【{}】---------", sb);
count = 0;
int num = 0;
start = System.currentTimeMillis();
mariaConn = getMariaConnection();
mariaPs = mariaConn.prepareStatement(sb.toString());
// 自动提交设置为false,我们进行手动提交
mariaConn.setAutoCommit(false);
while (oracleResultSet.next()) {
++count;
for (int i = 1; i <= columnCount; i++) {
mariaPs.setObject(i, oracleResultSet.getObject(i));
}
// 将预先语句存储起来,这里还没有向数据库插入
mariaPs.addBatch();
mariaPs.executeBatch();
LOGGER.info("---------第【" + ++num + "】次提交,耗时:"
+ (System.currentTimeMillis() - start) / 1000.0 + "s---------");
}
// 防止有数据未提交
mariaPs.executeBatch();
// 提交
mariaConn.commit();
LOGGER.info("---------完成【" + count + "】条数据迁移,总耗时:"
+ (System.currentTimeMillis() - start) / 1000.0 + "s---------");
} catch (SQLException | ClassNotFoundException e) {
failureReason = "批量插入数据失败";
LOGGER.error(failureReason, e);
} finally {
try {
close(oracleResultSet, ps, oracleConn);
} catch (SQLException e) {
failureReason = "批量插入数据时,关闭 Oracle 数据库资源失败";
LOGGER.error(failureReason, e);
}
try {
close(null, mariaPs, mariaConn);
} catch (SQLException e) {
failureReason = "批量插入数据时,关闭 Maria 数据库资源失败";
LOGGER.error(failureReason, e);
}
}
return failureReason;
}
public static Connection getMariaConnection() throws SQLException, ClassNotFoundException {
return DBUtils.getConnection(MARIA_CONFIG.getDriver(), MARIA_CONFIG.getJdbcUrl(), MARIA_CONFIG.getUserName(), MARIA_CONFIG.getPassword());
}
public static Connection getOracleConnection() throws SQLException, ClassNotFoundException {
return DBUtils.getConnection(ORACLE_CONFIG.getDriver(), ORACLE_CONFIG.getJdbcUrl(), ORACLE_CONFIG.getUserName(), ORACLE_CONFIG.getPassword());
}
public static Connection getConnection(String driver, String jdbcUrl, String userName, String password) throws ClassNotFoundException, SQLException {
// 加载驱动
Class.forName(driver);
// 创建连接
return DriverManager.getConnection(jdbcUrl, userName, password);
}
/**
* 获取分页后的SQL
*
* @param tableName 表名
* @param pageIndex 页码
*/
private static String getSqlAfterPaging(String tableName, int pageIndex) {
int startRow = pageIndex * PAGE_SIZE;
int endRow = (pageIndex + 1) * PAGE_SIZE;
return "select * from ("
+ "select t1.*, rownum num from ("
+ "select * from " + tableName + ") t1"
+ " where rownum <= " + endRow + ") t2"
+ " where t2.num > " + startRow;
}
/**
* 关闭数据库的资源.
* 关闭数据库的资源的顺序最好与使用的顺序相反
*
* @param rs 结果集
* @param ps 预编译语句
* @param conn 数据库连接
*/
public static void close(ResultSet rs, PreparedStatement ps, Connection conn) throws SQLException {
if (rs != null) {
rs.close();
}
if (ps != null) {
ps.close();
}
if (conn != null) {
conn.close();
}
}
/*
public static void close(ResultSet rs, PreparedStatement ps, Connection conn) {
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
throw new RuntimeException("---------关闭结果集失败:", e);
}
}
if (ps != null) {
try {
ps.close();
} catch (Exception e) {
throw new RuntimeException("---------关闭预编译失败:", e);
}
}
if (conn != null) {
try {
conn.close();
} catch (Exception e) {
throw new RuntimeException("---------关闭数据库连接失败:", e);
}
}
}
*/
}
3.数据迁移代码
package com.dake.util;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class DataMigrationUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(DataMigrationUtils.class);
/** 重试次数 */
private static final int RETRY_COUNT = 5;
/** 迁移中 */
private static final String STATUS_MIGRATING = "1";
/** 迁移失败 */
private static final String STATUS_FAILED = "3";
/**
* 循环迁移数据,增加重试机制
*/
public static void migrateWithCycle() {
for (int i = 1; i <= RETRY_COUNT; i++) {
try {
LOGGER.info("---------第【{}】次数据迁移开始---------", i);
boolean result = migrate();
if (result) {
LOGGER.info("---------第【{}】次数据迁移全部【成功】---------", i);
break;
} else {
LOGGER.error("---------第【{}】次数据迁移非全部【成功】---------", i);
}
} catch (Exception e) {
LOGGER.error(String.format("---------第【%s】次迁移数据失败:", i), e);
// 不能抛出异常。在应用启动后开始监听目标文件夹。由于监听器在独立的线程中执行,一旦异常发生将导致线程退出。
// 所以如果希望监听线程不中断,应在线程中捕获所有异常。
// throw new RuntimeException(String.format("---------第【%s】次迁移数据失败:", count), e);
}
}
}
/**
* 查询<strong>未迁移、迁移中、迁移失败</strong>的数据,并开始迁移数据。
*
* @return boolean
*/
private static boolean migrate() {
boolean result = true;
// 查询迁移状态为 未迁移和失败的,且重试次数小于5的 所有迁移表名
String sql = "select MIGRATE_TABLE_NAME, RETRY_COUNT, STATUS from DATA_MIGRATION_RECORD where (STATUS = '0' or STATUS = '1' or STATUS = '3') and RETRY_COUNT < 5";
Connection conn = null;
PreparedStatement ps = null;
ResultSet resultSet = null;
try {
conn = DBUtils.getMariaConnection();
ps = conn.prepareStatement(sql);
resultSet = ps.executeQuery();
while (resultSet.next()) {
String migrateTableName = resultSet.getString(1);
int retryCount = resultSet.getInt(2);
String status = resultSet.getString(3);
/*
* 迁移中或迁移失败,则清空该表然后重新迁移。
* 针对迁移中的数据,有两种情况:</br>
* 1.该表迁移成功,但是修改迁移状态失败;
* 2.该表迁移失败,修改迁移状态同样失败。
* 不管那种情况,在这里都做清空数据处理。之所以这么处理,是为了不在进行数据迁移和修改状态时增加事务。
* 因为数据的迁移是在循环中进行的,多层循环嵌套,再加上迁移数据量大的话,增加事务与回滚机制,会严重影响性能,耗费资源。
* 因此,为了解决这个问题,设置“迁移中”的状态,并且在每次迁移时对这种状态的数据做清空处理,则很好地解决了这个问题。
*/
if (STATUS_FAILED.equals(status) || STATUS_MIGRATING.equals(status)) {
LOGGER.info("---------【{}】表上次迁移失败,重新迁移需要清空上次插入的数据---------",
migrateTableName);
boolean success = deleteFailedData(migrateTableName);
if (success) {
LOGGER.info("---------【{}】表清空数据成功---------", migrateTableName);
} else {
LOGGER.error("---------【{}】表清空数据失败,可能需要人工干预---------", migrateTableName);
}
}
LOGGER.info("---------【{}】表迁移开始前先修改迁移状态为迁移中---------", migrateTableName);
boolean updStatus = updStatus(migrateTableName);
if (updStatus) {
LOGGER.info("---------【{}】表迁移开始前修改迁移状态为迁移中【成功】---------", migrateTableName);
LOGGER.info("---------【{}】表第【{}】次迁移开始---------", migrateTableName, (retryCount + 1));
boolean successful = migrateWithUpdate(migrateTableName, retryCount);
if (successful) {
LOGGER.info("---------【{}】表最终迁移【成功】---------", migrateTableName);
} else {
result = false;
LOGGER.error("---------【{}】表最终迁移【失败】---------", migrateTableName);
}
} else {
LOGGER.error("---------【{}】表迁移开始前修改迁移状态为迁移中【失败】---------", migrateTableName);
}
}
} catch (SQLException | ClassNotFoundException e) {
LOGGER.error("---------本次最终迁移失败:", e);
result = false;
} finally {
try {
DBUtils.close(resultSet, ps, conn);
} catch (SQLException e) {
LOGGER.error("---------查询未迁移和失败的数据时,关闭 Maria 数据库资源失败:", e);
result = false;
}
}
return result;
}
/**
* 迁移数据并记录迁移结果
*
* @param tableName 将要迁移的表名
* @param retryCount 重试次数
* @return boolean
*/
private static boolean migrateWithUpdate(String tableName, int retryCount) {
String failureReason = DBUtils.insertWithBatch(tableName);
if (StringUtils.isBlank(failureReason)) {
LOGGER.info("---------【" + tableName + "】表迁移成功---------");
return recordSuccessfulResults(tableName, retryCount);
} else {
LOGGER.error("---------【" + tableName + "】表迁移失败,失败原因是:" + failureReason);
recordFailedResults(tableName, retryCount, failureReason);
// 迁移失败,不管记录失败原因的操作成功与否,结果都是失败
return false;
}
}
/**
* 迁移数据成功,记录迁移结果。
* 如果数据迁移成功,但是记录失败原因失败,迁移状态如果不增加一个迁移中的状态,那么此时已经迁移成功的数据的状态依然是未迁移,
* 会导致数据再次插入,会有重复数据。</br>
* 如果不增加迁移中的状态,那么就可能需要考虑对插入的数据做回滚操作。如此一来,就需要对数据加事务,代价有点高,如果使用迁移中的状态,
* 就相对简单很多了。
*
* @param migrateTableName 将要迁移的表名
* @param retryCount 重试次数
*/
private static boolean recordSuccessfulResults(String migrateTableName, int retryCount) {
String successfulSql = "update DATA_MIGRATION_RECORD set STATUS = '2', RETRY_COUNT = " + (retryCount + 1) + ", "
+ "FAILURE_REASON = null" + " where MIGRATE_TABLE_NAME = '" + migrateTableName + "'";
// + "FAILURE_REASON = null" + " where MIGRATE_TABLE_NAME = " + migrateTableName;
LOGGER.info("---------【{}】表迁移成功,记录迁移结果开始---------", migrateTableName);
LOGGER.info("---------记录迁移结果的SQL为:【{}】---------", successfulSql);
boolean successful = executeUpdate(successfulSql);
if (successful) {
LOGGER.info("---------【{}】表迁移成功,记录迁移结果【成功】---------", migrateTableName);
} else {
LOGGER.error("---------【{}】表迁移成功,记录迁移结果【失败】---------", migrateTableName);
}
return successful;
}
/**
* 迁移数据失败,记录迁移结果
*
* @param migrateTableName 将要迁移的表名
* @param retryCount 重试次数
* @param failureReason 失败原因
*/
private static void recordFailedResults(String migrateTableName, int retryCount, String failureReason) {
String failedSql = "update DATA_MIGRATION_RECORD set status = '3', RETRY_COUNT = " + (retryCount + 1) + ", "
+ "FAILURE_REASON = " + failureReason + " where MIGRATE_TABLE_NAME = '" + migrateTableName + "'";
LOGGER.info("---------【{}】表迁移失败,记录迁移结果开始---------", migrateTableName);
boolean successful = executeUpdate(failedSql);
if (successful) {
LOGGER.info("---------【{}】表迁移失败,记录迁移结果【成功】---------", migrateTableName);
} else {
LOGGER.error("---------【{}】表迁移失败,记录迁移结果【失败】---------", migrateTableName);
}
}
/**
* 迁移开始之前,修改迁移状态为迁移中。
*
* @param tableName 将要迁移的表名
* @return boolean
*/
private static boolean updStatus(String tableName) {
return executeUpdate("update DATA_MIGRATION_RECORD set STATUS = '1' where MIGRATE_TABLE_NAME = '" + tableName + "'");
}
private static boolean deleteFailedData(String tableName){
// return executeUpdate("delete from " + tableName);
// 使用 truncate 命令需要drop权限,但是效率高。delete是DML语言,delete是DML语言
// truncate 命令截断表的数据不能回滚
return executeUpdate("truncate TABLE " + tableName);
}
/**
* 执行原生 JDBC 的更新操作
*
* @param sql SQL
*/
private static boolean executeUpdate(String sql) {
boolean result = true;
Connection mariaConn = null;
PreparedStatement ps = null;
try {
mariaConn = DBUtils.getMariaConnection();
ps = mariaConn.prepareStatement(sql);
ps.executeUpdate();
} catch (SQLException | ClassNotFoundException e) {
result = false;
LOGGER.error("---------记录迁移结果失败:", e);
} finally {
try {
DBUtils.close(null, ps, mariaConn);
} catch (SQLException e) {
result = false;
LOGGER.error("---------记录迁移结果时,关闭 Maria 数据库资源失败:", e);
}
}
return result;
}
}
4.触发代码自动执行
我测试的时候是在springboot的启动来中直接调用的,当然也可以通过手动触发的方式。下面我们就说说开头讲的通过文件监控触发代码自动执行的方式,这也是本文采用的方式。
首先,你要定义一个类,比如,FileListener,然后实现FileAlterationListenerAdaptor
package com.dake.listener;
import com.dake.util.DataMigrationUtils;
import org.apache.commons.io.filefilter.FileFilterUtils;
import org.apache.commons.io.filefilter.HiddenFileFilter;
import org.apache.commons.io.filefilter.IOFileFilter;
import org.apache.commons.io.monitor.FileAlterationListenerAdaptor;
import org.apache.commons.io.monitor.FileAlterationMonitor;
import org.apache.commons.io.monitor.FileAlterationObserver;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.io.File;
import java.util.concurrent.TimeUnit;
@Component
public class FileListener extends FileAlterationListenerAdaptor {
private static final Logger LOGGER = LoggerFactory.getLogger(FileListener.class);
String monitorDir = "src/main/resources/monitor/";
// @PostConstruct
public void init() throws Exception {
long interval = TimeUnit.SECONDS.toMillis(10);
IOFileFilter fileFilter = FileFilterUtils.and(FileFilterUtils.directoryFileFilter(), HiddenFileFilter.VISIBLE);
IOFileFilter filter = FileFilterUtils.and(FileFilterUtils.fileFileFilter(), FileFilterUtils.suffixFileFilter(".txt"));
IOFileFilter finalFileFilter = FileFilterUtils.or(fileFilter, filter);
// 使用过滤器创建观察者
FileAlterationObserver observer = new FileAlterationObserver(new File(monitorDir), finalFileFilter);
// 不使用过滤器创建观察者
// FileAlterationObserver observer = new FileAlterationObserver(new File(monitorDir));
observer.addListener(new FileListener());
new FileAlterationMonitor(interval, observer).start();
}
@Override
public void onStart(FileAlterationObserver observer) {
LOGGER.info("---------文件监听器启动---------");
super.onStart(observer);
}
@Override
public void onFileCreate(File file) {
LOGGER.info("---------文件创建:{}---------", file.getAbsolutePath());
// 执行业务操作,循环迁移数据
DataMigrationUtils.migrateWithCycle();
}
@Override
public void onFileChange(File file) {
LOGGER.info("---------文件修改:{}---------", file.getAbsolutePath());
}
@Override
public void onFileDelete(File file) {
LOGGER.info("---------文件删除:{}---------", file.getAbsolutePath());
}
@Override
public void onStop(FileAlterationObserver observer) {
LOGGER.info("---------文件监听器关闭---------");
super.onStop(observer);
}
}
5.定义自动执行runner类
通过这种方式,会自动监听 monitorDir 路径下面是否有新增文件,如果有的话就自动触发代码执行,触发的代码在? onFileCreate 方法中调用的。这里我们是通过? @PostConstruct 注解的方式来触发的,当然你也可以使用其他的方式。比如本文中就是实现? CommandLineRunner 接口的方式,定义一个runner类:
package com.dake.listener;
import org.apache.commons.io.monitor.FileAlterationMonitor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
public class FileListenerRunner implements CommandLineRunner {
private static final Logger LOGGER = LoggerFactory.getLogger(FileListenerRunner.class);
@Override
public void run(String... args) throws Exception {
FileAlterationMonitor monitor = FileListenerFactory.getMonitor();
try {
monitor.start();
} catch (Exception e) {
LOGGER.error("---------启动监视器失败---------");
}
}
}
6.定义监听工厂
package com.dake.listener;
import org.apache.commons.io.filefilter.FileFilterUtils;
import org.apache.commons.io.filefilter.HiddenFileFilter;
import org.apache.commons.io.filefilter.IOFileFilter;
import org.apache.commons.io.monitor.FileAlterationMonitor;
import org.apache.commons.io.monitor.FileAlterationObserver;
import java.io.File;
import java.util.concurrent.TimeUnit;
public class FileListenerFactory {
private static final String monitorDir = "src/main/resources/monitor/";
static long interval = TimeUnit.SECONDS.toMillis(10);
public static FileAlterationMonitor getMonitor() {
IOFileFilter fileFilter = FileFilterUtils.and(FileFilterUtils.directoryFileFilter(), HiddenFileFilter.VISIBLE);
IOFileFilter filter = FileFilterUtils.and(FileFilterUtils.fileFileFilter(), FileFilterUtils.suffixFileFilter(".txt"));
IOFileFilter finalFileFilter = FileFilterUtils.or(fileFilter, filter);
// 使用过滤器创建观察者
FileAlterationObserver observer = new FileAlterationObserver(new File(monitorDir), finalFileFilter);
// 不使用过滤器创建观察者
// FileAlterationObserver observer = new FileAlterationObserver(new File(monitorDir));
// 向监听者添加监听器,并注入业务服务
observer.addListener(new FileListener());
// 返回监听者
return new FileAlterationMonitor(interval, observer);
}
}
定义监听工厂的方式需要在工厂中指定监听的目录 monitorDir:
private static final String monitorDir = "src/main/resources/monitor/";
?至此迁移代码结束。
如果使用我上面的代码的话,我们会发现还缺少对应的类,比如,SpringContextUtil、MariaConfig、OracleConfig,代码如下:
package com.dake.util;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;
@Component
public class SpringContextUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext = null;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
if (SpringContextUtil.applicationContext == null) {
SpringContextUtil.applicationContext = applicationContext;
}
}
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
public static Object getBean(String name) {
return getApplicationContext().getBean(name);
}
public static <T> T getBean(Class<T> clazz) {
return getApplicationContext().getBean(clazz);
}
public static <T> T getBean(String name, Class<T> clazz) {
return getApplicationContext().getBean(name, clazz);
}
}
package com.dake.entity;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "maria")
public class MariaConfig {
private String driver;
private String jdbcUrl;
private String userName;
private String password;
}
package com.dake.entity;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "oracle")
public class OracleConfig {
private String driver;
private String jdbcUrl;
private String userName;
private String password;
}
至此,全部代码都在上面了。下面看一下我的项目结构,也好让大家清晰明了的看看:
四、异常处理?
下面我们在说说前文提到的异常处理问题。
为什么要回头说这一点呢?原因是,在这个业务逻辑中,单纯的抛出异常,然后交给最终调用者去处理的方式是行不通的,或者说是不合理的,为什么呢?
首先,关闭数据库资源问题
我们知道数据库的操作资源都是稀缺资源,打开连接关闭连接这些都是必须的,结束后我们需要关闭资源的,如果你抛出了异常,你就无法再那里关闭资源了。你可能谁说谁调用谁最终关闭,可是你如果看我上面的代码的会你会发现,调用者他也有他自己的资源需要关闭,到了调用者手里,就无法关闭资源了。本身数据迁移就是大量的数据操作,频繁的查询和插入,大量的IO操作本身就是需要特别注意的事情,如果资源不关闭的话,是不允许的,也会对项目后续的运行埋下隐患,可能会造成资源的浪费和内存的大量消耗,导致内存溢出等情况。
其次,有人说,我可以使用 try-finally的方式关闭资源
当然这种方式是可以的,只是说,一方面看起来代码不是很优雅,另一方面呢,我们在本文开头就说了需要记录失败原因的,方便查找问题,如果使用了这种方式,我们就无法记录失败的原因了。当然,你可以抛出异常之后交给最终调用者捕捉异常,然后将这个异常的堆栈信息记录的表中,这个也是可以的,但是完全没必要。因为这样的话,你记录的堆栈信息,套用了很多层次,真正出问题的时候看这些堆栈信息也不是很直观明了。倒不如像我这样,直接记录日志,记录错误原因,通过错误原因来查找问题,就很方便了。
第三,close方法的异常及其后续
我们看到,在我的那个close方法中,我都是抛出了异常,而下面我注释掉的是捕捉了异常的处理。为什么采用抛出异常的方式呢?因为数据迁移是很严谨的事情,不容半点错误,虽然关闭资源的时候出错的概率很小,但是如果出错了,程序不严谨可能导致意想不到的错误。如果我在这里抛出了异常,那么在调用者的手里,他就可以自行处理这种异常并记录错误原因。这还不是重点,重点是他可以通过这个错误来决定数据迁移工作是继续还是结束,还是进行下一轮的循环操作,也就是重试工作。
具体代码可以在gitee上面去查看:
?至此,我们的迁移工作结束了。
总结
1.注意事项;
2.自动触发代码的方案选择;
3.数据初始化方案选择;
4.数据迁移代码
5.异常处理说明。

