Ŀ¼
һ�����Ӹ��Ƶĸ���:
һ��ʲô�����Ӹ���:

���Ӹ���,��ָ��һ̨Redis���ڵ������������,���Ƶ�������Redis�ӽڵ��������
���ڵ��Ϊ(master/leader),�ӽڵ��Ϊ(slave/follower);
1.���ݵĸ����ǵ����,ֻ�������ڵ㵽�ӽڵ���
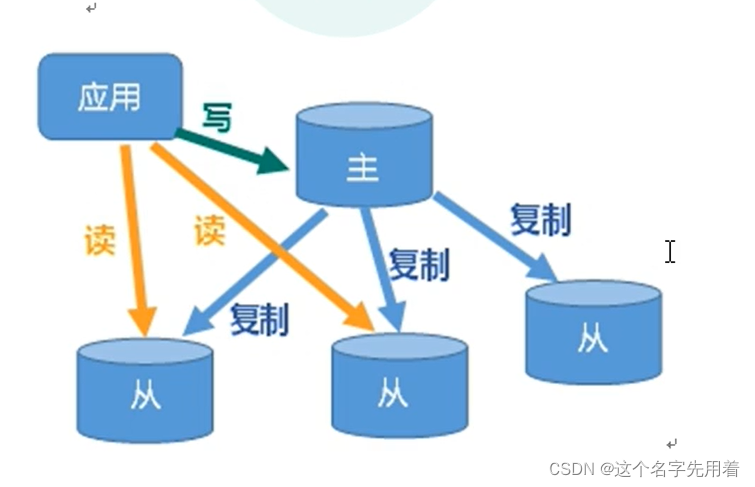
2.Master(���ڵ�)��дΪ��,Slave �ӽڵ��Զ�Ϊ����
3.Ĭ�������,ÿ̨Redis�������������ڵ�,����������Ϊ�ӽڵ�,��Ҫ�����������;
��һ�����ڵ�����ж���ӽڵ�(��û�дӽڵ�),��һ���ӽڵ�ֻ����һ�����ڵ㡣
�ܽ����:���Ӹ���:���ڵ㸺��д����,�ӽڵ㸺�������,���ڵ㶨�ڰ�����ͬ�����ӽڵ㱣֤���ݵ�һ���ԡ�
����Ϊʲôʹ��Redis���Ӹ���:
����ֻ��һ̨Redis����,����ǵ���ģʽ��
��һ�������ǵ�������崻�,���ݶ�ʧ,������ݺ���Ҫ,�ǻ���ɺܴ����ʧ��
�ڶ����������ڴ�����,һ̨���������ڴ��ǻ�ﵽ��ֵ��,һ̨������Ҳ����������������
�����������,������Ҫ����̨������,�������Ӹ��ơ������ݱ����ڶ�̨��������,���ұ�֤ÿ̨��������������ͬ���ġ���ʹ��һ̨������崻�,Ҳ��Ӱ���û���ʹ�á�redis���Լ���ʵ�ָ߿���,ͬʱʵ�����ݵ����౸����
����ʹ��Redis���Ӹ��Ƶ�����:
1,��������:���Ӹ���ʵ�������ݵ��ȱ���,��Ҳ�dz־û�ʵ�ֵ���һ�ַ�ʽ��
2,���ϻָ�:�����ڵ��������ʱ,�����ɴӽڵ��ṩ����,ʵ�ֿ��ٵĹ��ϻָ�;ʵ������һ�ַ�������ࡣ
3,��д����:master������Ҫ����д,slave������Ҫ���������ݡ�������߷������ĸ�������,���Ը�������ı仯,���Ӵӽڵ��������
4,���ؾ���:ͬʱ��϶�д����,�����ڵ��ṩд����,�ӽڵ��ṩ������,�ֵ��������ĸ��ء���д�ٶ���������,ͨ������ӽڵ�ֵ�������,�ܹ�������Redis����IJ��������ء�
5,�߿��õĻ�ʯ,���Ӹ������ڱ��ͼ�Ⱥģʽ�ܹ�ʵʩ�Ļ�����
�ġ����Ӹ��ƵIJ���:
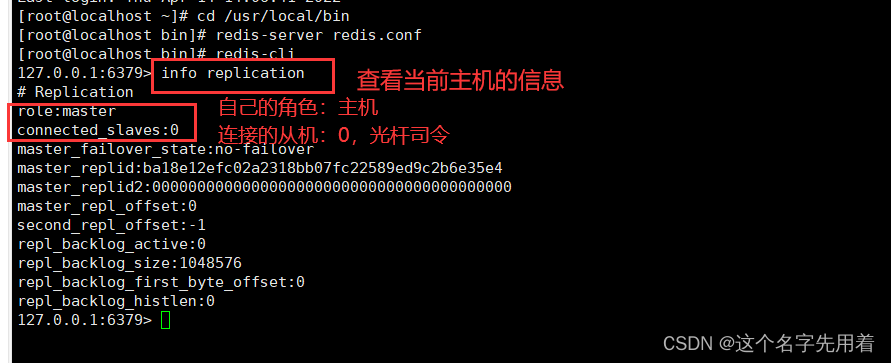
�Ȳ鿴��ǰ������������������Ϣ:
127.0.0.1:6379> info replication
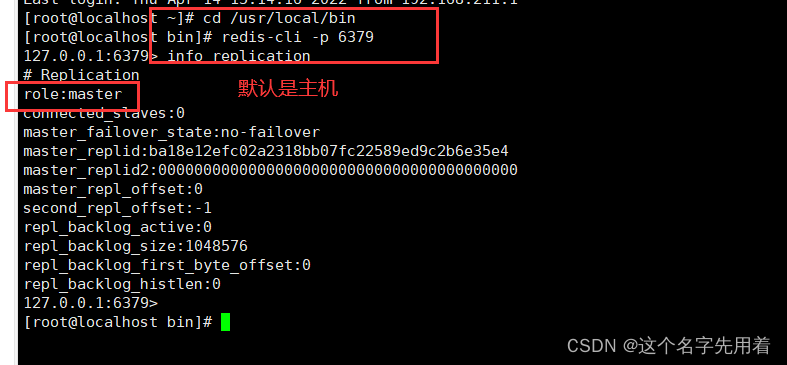
role��ɫ:master(����)
connected_slaves(�����ӵĴӻ�):0(û��)
master_failover_state (����_�����л�_״̬) :no-failover(û�й����л�)
���Ӹ��Ʋ���:
ʵ��������,�����ü���������linux�������������ӹ�ϵ,����������һ̨linux������ģ���̨redis����,��ʵ�����Ӹ���:

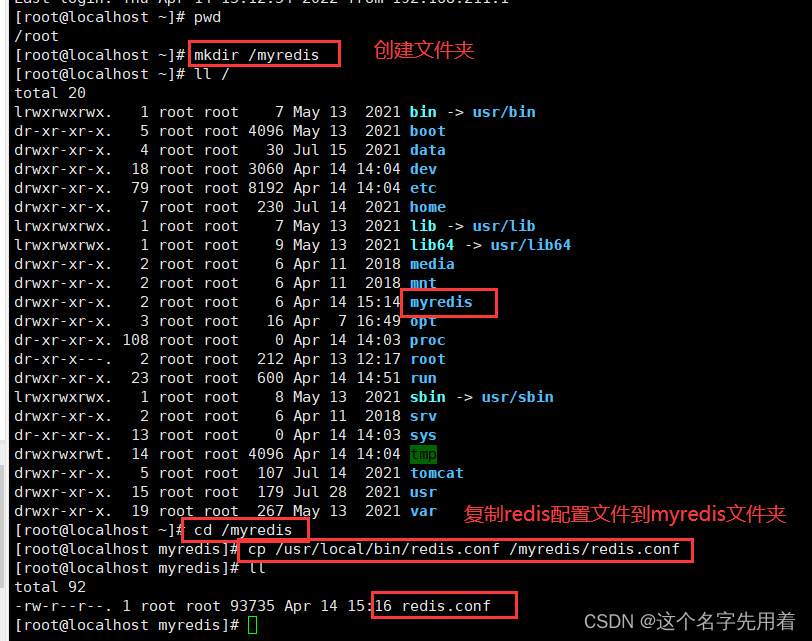
��һ��:����/myredis�ļ��С�
�ڶ���:����redis.conf�����ļ���myredis�ļ����С�
����:
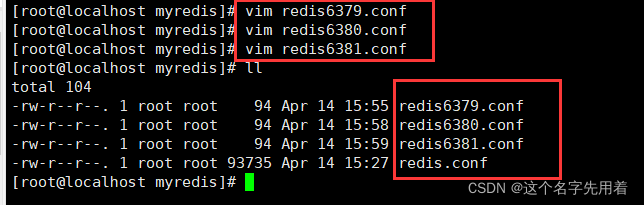
������:����һ������,���������µ������ļ�:redis6379.conf,redis6380.conf,redis6381.conf
ע��:����Ҳ���Էֱ���redis.conf��������,Ȼ�������Ϊredis6379.conf,redis6380.conf,redis6381.conf,Ȼ��ֱ������������ļ��������е㷱��,�ĵ����ݲ�����,������������½��ļ�,������ԭredis.conf�е�����,�������������ݼ���(�е���thymleaf�е�����)��
myredis�ļ������������ĸ��ļ�,һ��������redis.conf�������½��IJ�������conf�ļ�(redis6379.conf,redis6380.conf,redis6381.conf),�������������ļ��������ļ�������һЩ����;
�������:
�����ȱ༭Դredis.conf�����ļ�:
�ĵ�����Ϊ:�ر� aop:appendonly no����,��Ϊ����ͬ������ RDB �ļ����ϴ�����
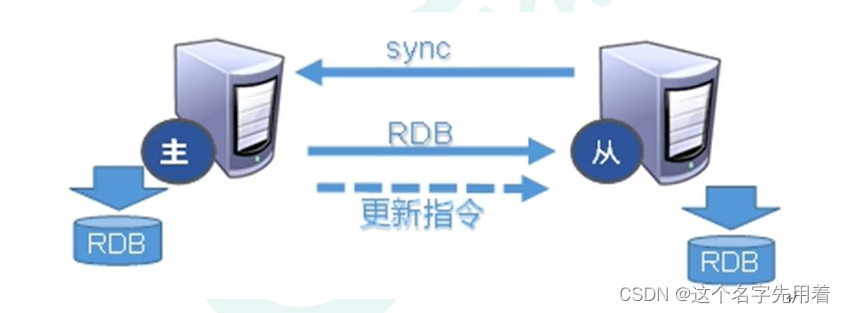
redis֧��master-slaveģʽ,һ�����,redis server��������������redis serverΪslave,�ӻ�ͬ�����������ݡ����ú�,��д����,���������д����,�ӻ�ֻ�����������������ѹ����redisʵ�ֵ������ջ�һ����,����ѡ��ǿһ���Ի�����һ����,ȡ����ҵ����
redis ����ͬ�������ַ�ʽ(������������):ȫͬ���Ͳ���ͬ����
���Ӹո����ӵ�ʱ��,����ȫͬ��;ȫͬ��������,���в���ͬ������Ȼ,�������Ҫ,slave ���κ�ʱ���Է���ȫͬ����redis ������,�������,���Ȼ᳢�Խ��в���ͬ��,�粻�ɹ�,Ҫ��ӻ�����ȫͬ��,������ BGSAVE����BGSAVE ������,���� RDB �ļ�;����ɹ�,�����ӻ����в���ͬ��,�������ѹ�ռ��е����ݡ�����˵,����ͬ������ RDB �ļ����ϴ�����;������С���ֵ�������,�Ͱ��ļ�¼������ÿ���ӻ���
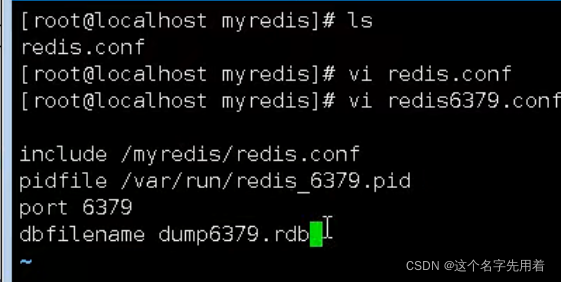
��Ȼ���½�redis6379.conf�ļ�,���༭:
vim redis6379.conf
���������:
include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
��ͬ��,�����½����������ӻ��������ļ�:
vim redis6380.conf
���������:
include /myredis/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
vim redis6381.conf
���������:
include /myredis/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb
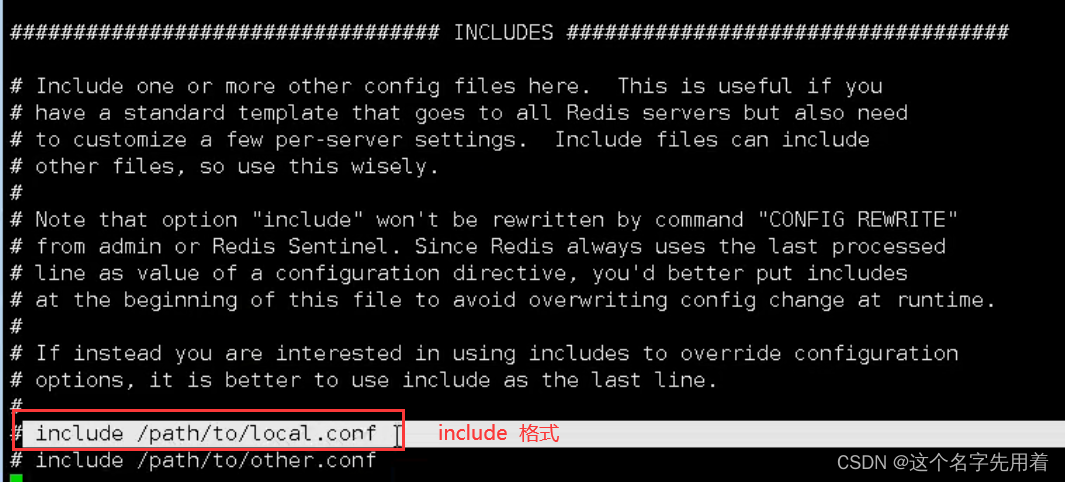
˵��:includ �������������ļ��Ĺ�������,�������������Լ�����:
������:
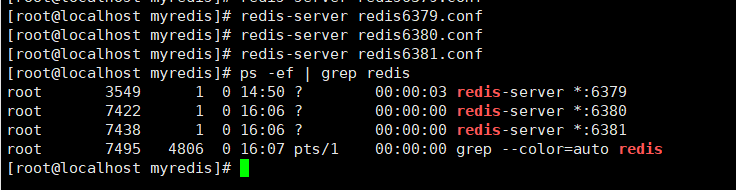
��������̨redis������,���鿴�Ƿ������ɹ�:
[root@localhost myredis]# redis-server redis6379.conf
[root@localhost myredis]# redis-server redis6380.conf
[root@localhost myredis]# redis-server redis6381.conf
ps -ef | grep redis
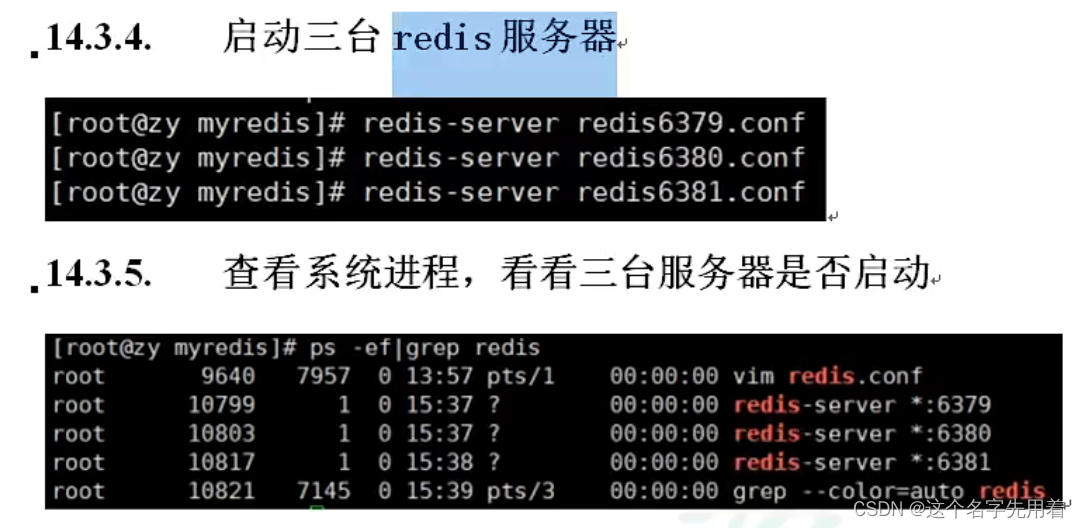
�ݲ鿴��̨�������������:
info replication
[root@localhost ~]# cd /usr/local/bin
[root@localhost bin]# redis-cli -p 6379
127.0.0.1:6379> info replication
�����ôӿⲻ�������� :
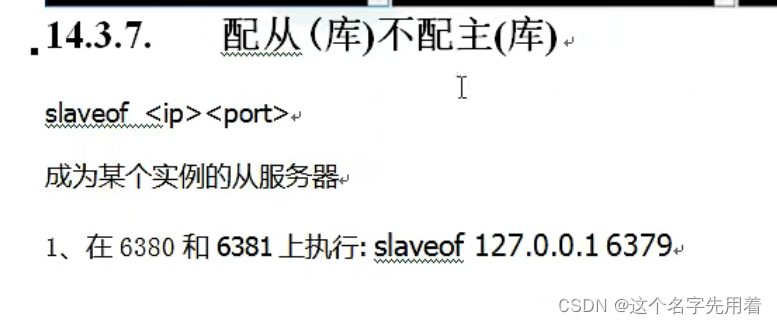
��6380�������óɴӻ�:
slaveof ����ip �����˿ں�
info replication
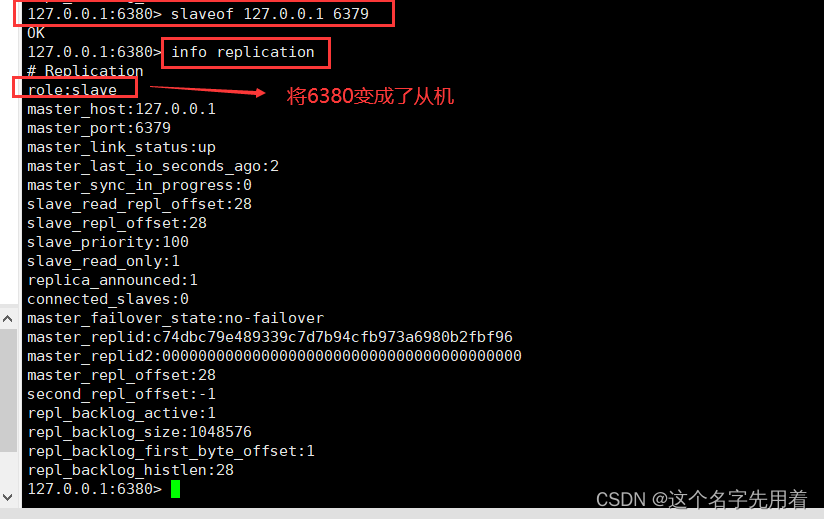
��6381�������óɴӻ�:
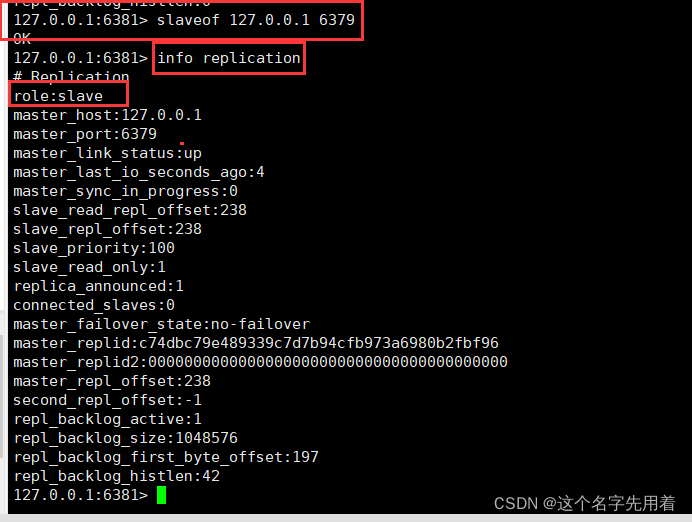
�������鿴:
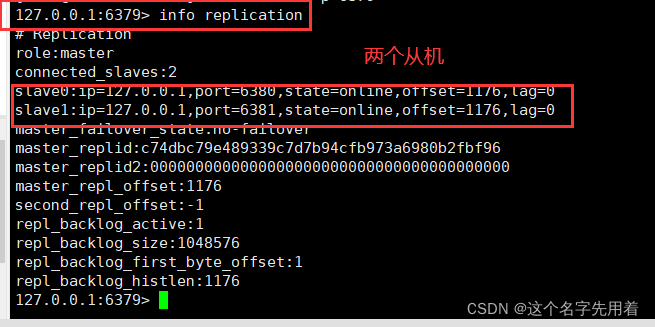
�߲������Ӹ��Ƶ�Ч��:
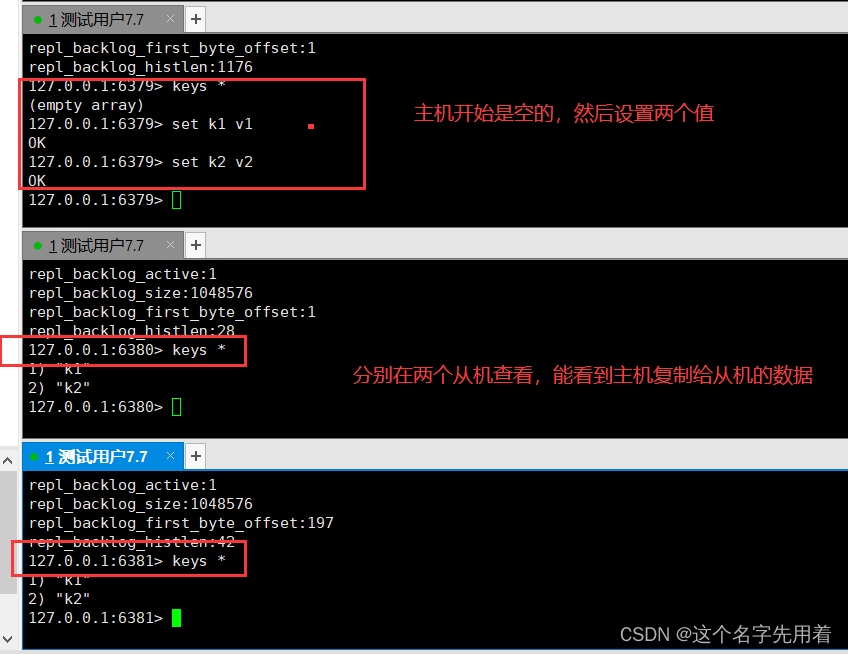
ע��:�ӻ�����ֻ�ܶ�����,�����ļ���ֻ�����ܱ�������:
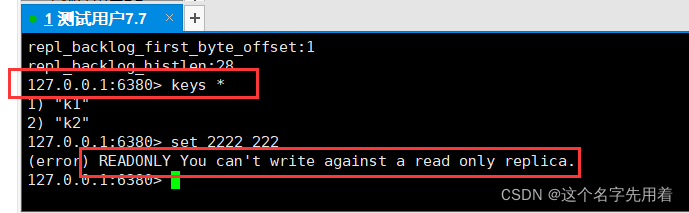
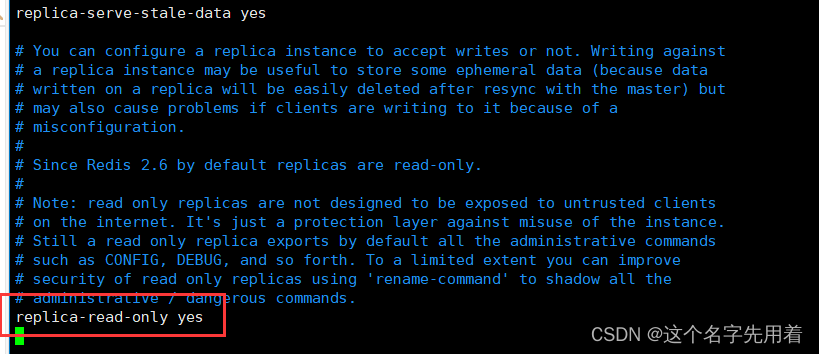

�ܽ�:
�������Ӹ��Ƶķ�ʽ������:
��ʽһ�����������ļ�:
�ӷ���������master�ڵ�
# ���ڵ�ip port �����Լ��ڵ�Ķ˿�
# replicaof <masterip> <masterport>
# ���ڵ����֤����(��ѡ)
# masterauth <master-password>
��ʽ����ʹ�������:
�ͻ���ʹ�ø�����slaveof ����ip �����˿ں�
info replication����ɲ鿴�ڵ���Ϣ
��������:
һ������:
һ�������ص�:
�ص�һ:�����ǰѵ�һ���ӷ����� �ҵ���,��ô�ڴӷ�����ͣ�������ʱ���,����������һЩд�IJ���,��������Ϊ�İѴӻ���������֮��,������д��������ͬ�����������Ĵӻ���,��Ȼ�ǿ��Ե�,��Ϊ��ӻ�һ��������,���������������ҵ�����д���ݵ���ӻ��С�
�ӻ���Ҫ���¼��뵽������:
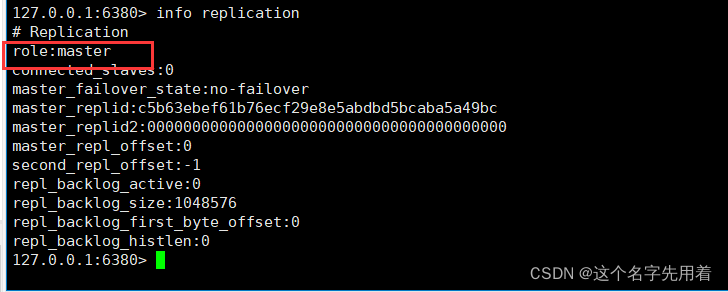
info replication �鿴���������Ĵӷ�������,���Ľ�ɫ�������������:
Ȼ����Ҫ���������ɴӻ�:slaveof 127.0.0.1 6379(���ַ�ʽ���DZȽ��鷳��)
�ص��:�����������ҵ���,�ӷ����������κ���,������ԭ������������λ��,���ҵ������������ٴ�������,�ֻص�������λ�á�

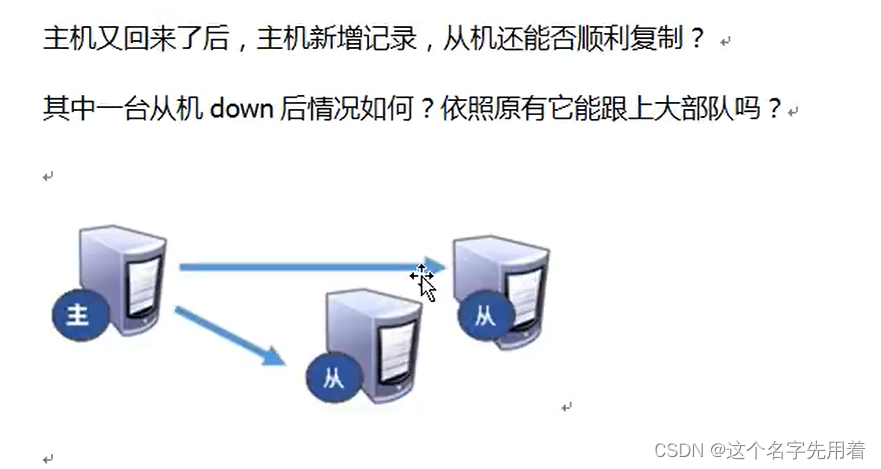
���Ӹ���ԭ��:
���Ӹ��Ƶ�������:
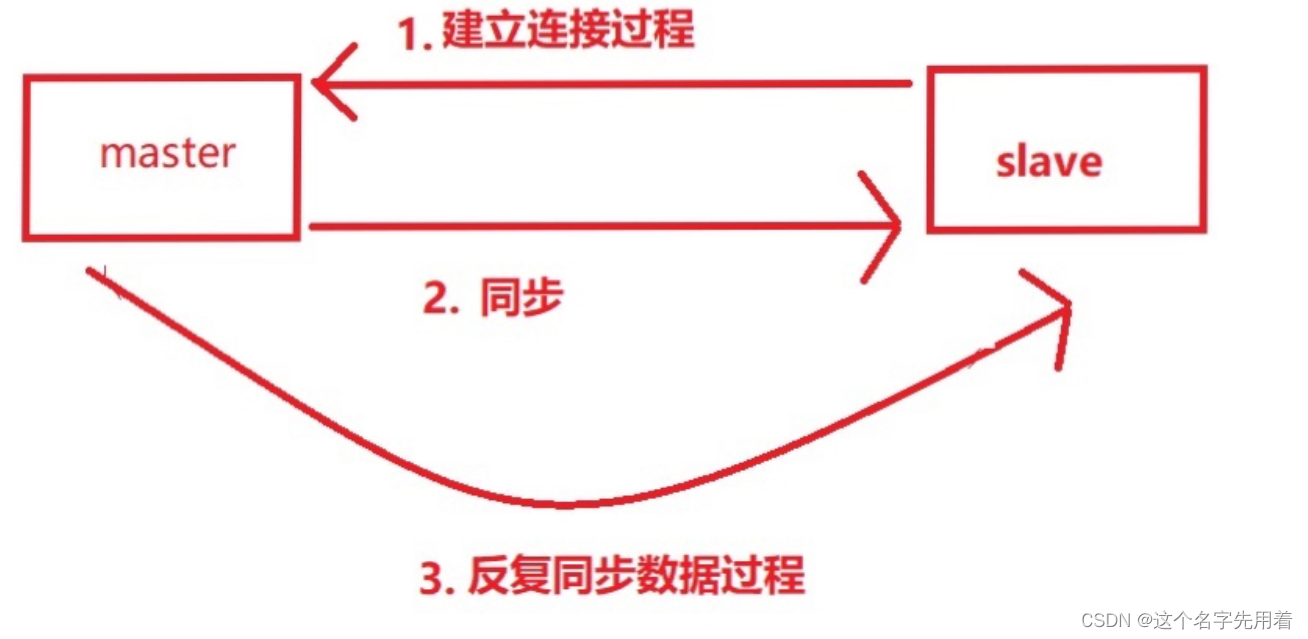
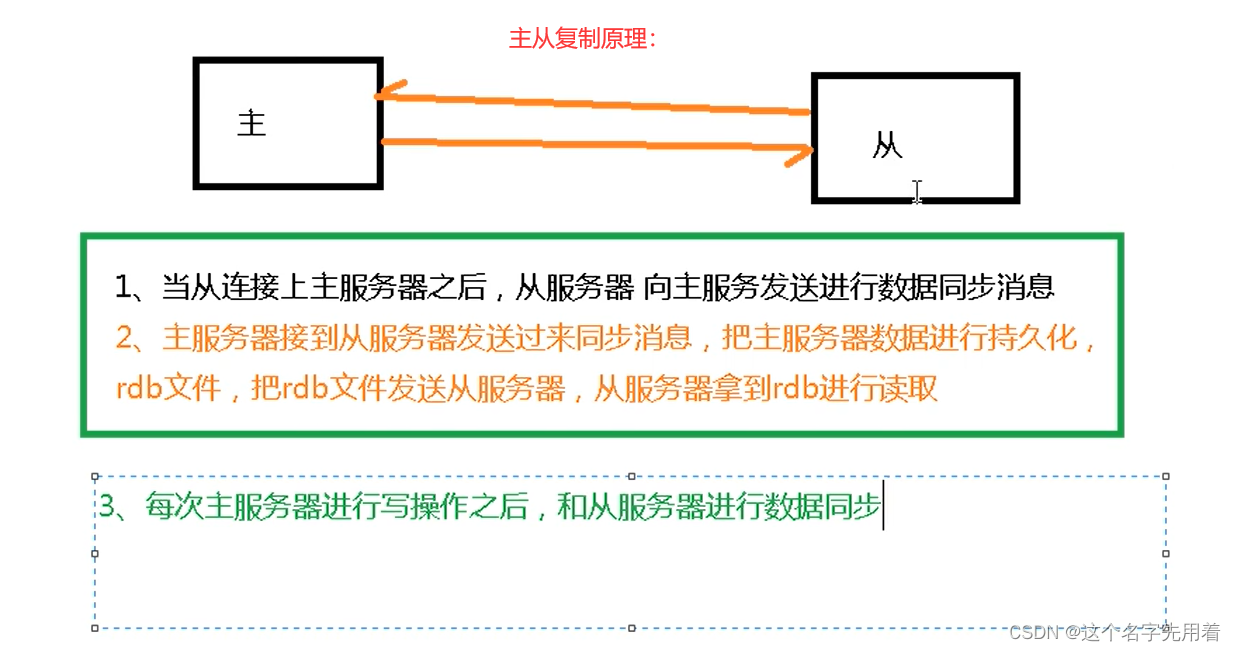
Redis���Ӹ��Ƶ������������������������Ρ�
- �������ӹ���:�����slave��master�������ӵĹ��̡�
- ����ͬ���Ĺ���:��maserͬ�����ݸ�slave�Ĺ��̡�
- ���������:�Ƿ���ͬ�����ݵĹ��̡�

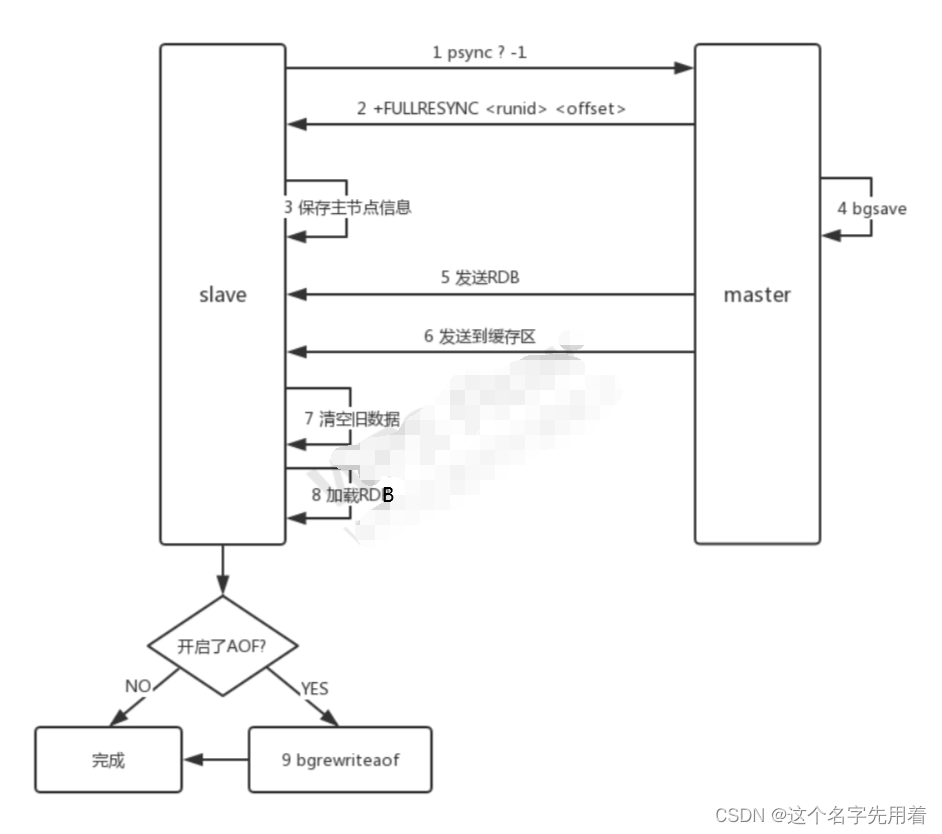
ȫ������:
ȫ�����������ӽڵ��һ�ν������Ӹ��ƹ�ϵʱ���뾭���Ľ�,������������:
-
�ӽڵ��ж���Ҫ����ȫ������,�����ڵ㴫������ psync ? -1 (���ڲ�֪�����ڵ�� runid �� offset,���Դ� -1)
-
���ڵ��յ�ȫ�����Ƶ�����,���� FULLRESYNC < runid > < offset > �������ڵ�� runid �� offset
-
�ӽڵ㱣�����ڵ�� runid �� offset ��Ϣ
-
���ڵ�ִ�� bgsave,�ں�̨���� RDB �ļ�,��ʹ��һ��������(��Ϊ���ƻ�����)��¼�����ڿ�ʼִ�е�����д����
-
���ڵ�� bgsave ִ����ɺ�,�� RDB �ļ������ӽڵ�
-
���ڵ�ִ�� send buffer ����,��ӽڵ�ͬ�����ɿ��չ����еĻ�������
-
�ӽڵ���վ����ݲ����� RDB �ļ�
-
����ӽڵ㿪���� AOF,��ᴥ�� bgrewriteaof ��ִ��,�Ӷ���֤ AOF �ļ����������ڵ������״̬
ͨ��ȫ�����ƵĹ��̿��Կ���,����������ʮ��������Դ��ʱ���:
���ڵ�ͨ�� bgsave ����ִ�� fork ���������ӽ��̽��� RDB �־û�,�ù����Ƿdz����� CPU���ڴ�ʹ��� I/O ��Դ
���ڵ�ͨ��������ӽڵ㴫�� RDB �ļ�,�ķ���������������������Դ��������������,��������������Ӧ���������ʱ�����Ӱ��
�ӽڵ���վ����ݲ������µ� RDB �ļ��Ĺ����������Ķ�����Ӧ������������,���ִ�� bgrewriteaof ����Ҳ��������������
��������:
���ӽڵ����ڸ������ڵ�ʱ���������쳣�������쳣,�ӽڵ���������ڵ㲹��ȱʧ����������,���ڵ�ֻ��Ҫ�����ƻ�ѹ�����������ݷ��͵��ӽڵ㼴�ɡ������ȫ������,�������Ƶijɱ�����С�ܶ�,����������:
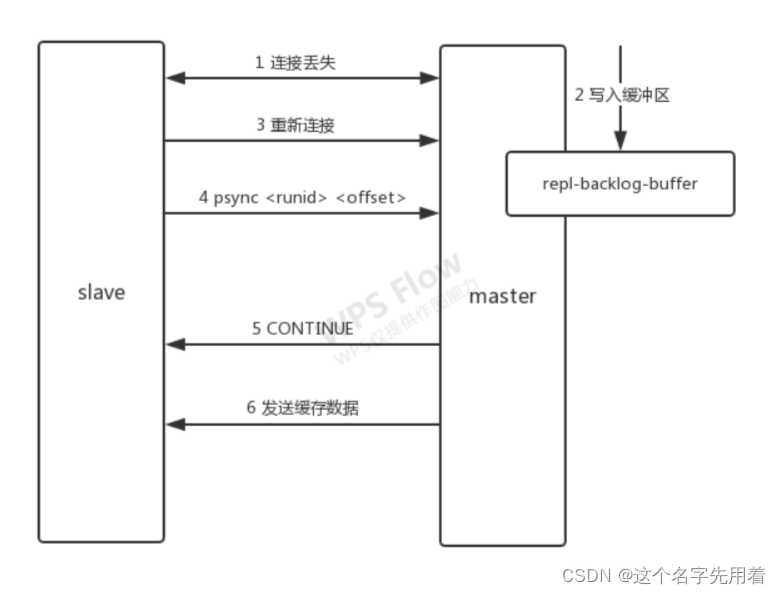
-
���緢������,���ڵ�ʹӽڵ�Ͽ�����
-
���ڵ�Ὣд����ݵ����ƻ�ѹ��������
-
�ӽڵ��ٴ����������ڵ�
-
�ӽڵ�ͨ������ psync < runid > < offset > �����ڵ��֪֮ǰ���ӵ� runid ���Լ���ƫ����
-
���ڵ����У�����ӽڵ㷵������ CONTINUE ��ʾ���Խ�����������
-
���ڵ㽫�����������ݷ��͵��ӽڵ�
���Ӹո����ӵ�ʱ��,����ȫ��ͬ��;ȫ��ͬ��������,��������ͬ������Ȼ,�������Ҫ,slave ���κ�ʱ���Է���ȫ��ͬ����redis ������,�������,���Ȼ᳢�Խ�������ͬ��,�粻�ɹ�,Ҫ��ӻ�����ȫ��ͬ����
н���ഫ:
���̾���:����6379 :ip127.0.0.1��>����6379 ����һ���ӻ�6380:ip127.0.0.1�C>Ȼ��
�ӻ�6380���Լ�Ҳ��һ���ӻ�8381 ,�൱�������˵����ഫ;
н���ഫ���ص��һ�����ͻ���һ��;
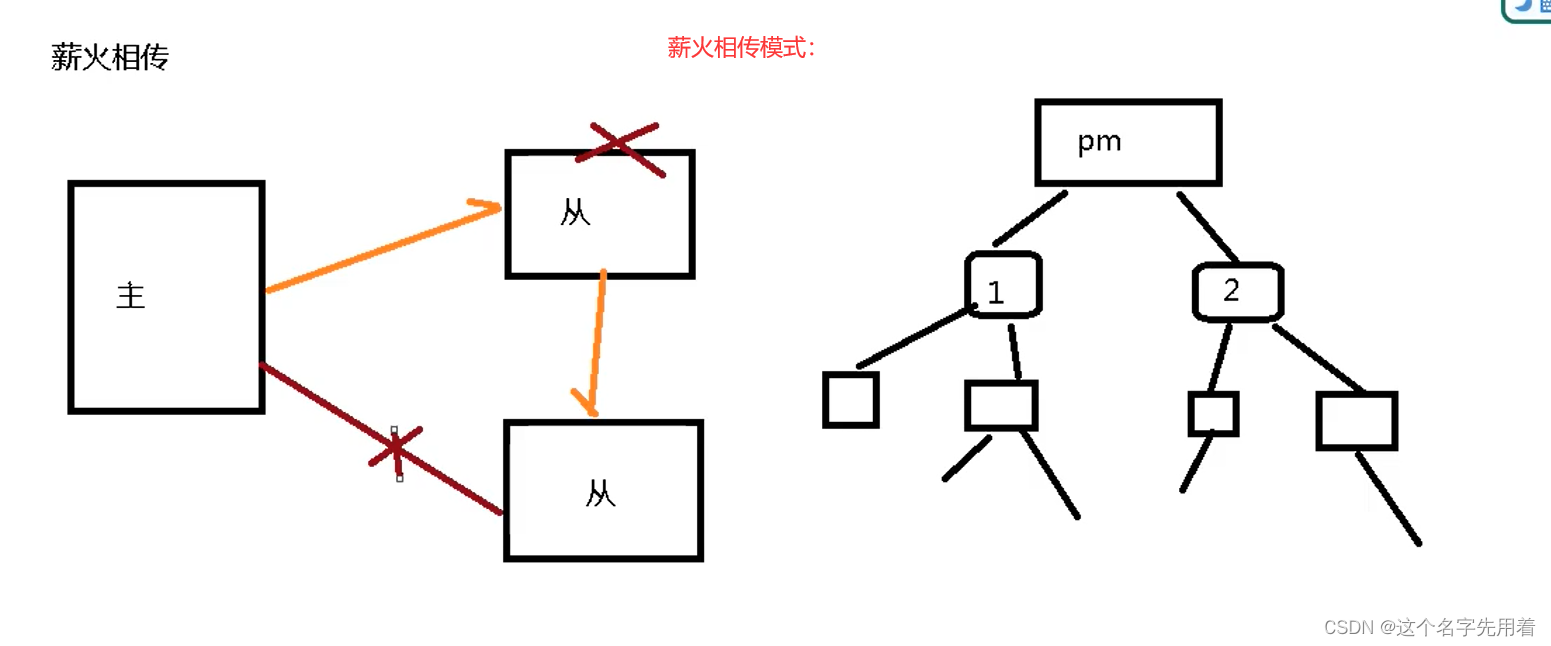
����Ϊ��:(�����ҵ�,�ӻ���λ������)
����Ϊ���ص�:
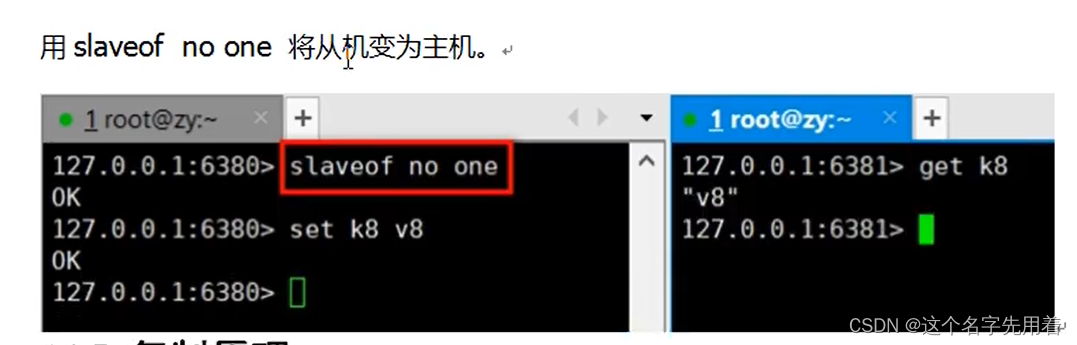
��ijһ���ӻ��ֶ�ʹ������ slaveof no one ����ǰ�ӻ����������

�ڱ�ģʽ:(��������)
�ڱ�ģʽ����:

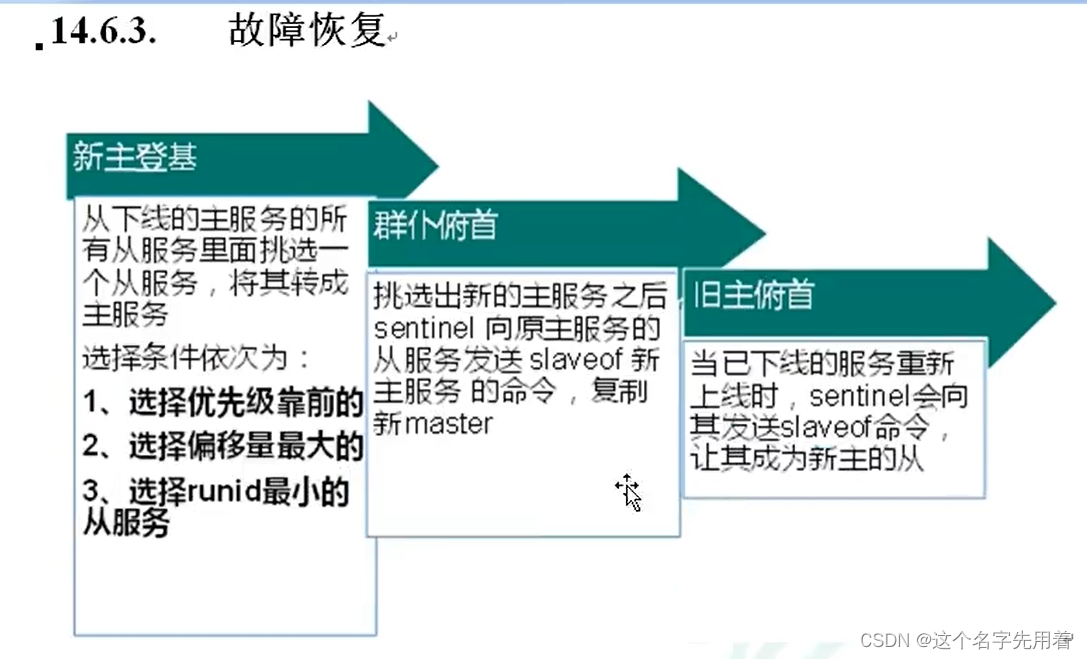
�����л������ķ�����:����������崻���,��Ҫ�ֶ���һ̨�ӷ������л�Ϊ��������,�����Ҫ�˹���Ԥ,���·���,�������һ��ʱ���ڷ����á��ⲻ��һ���Ƽ��ķ�ʽ,����ʱ��,�������ȿ����ڱ�ģʽ��Redis��2.8��ʼ��ʽ�ṩ��Sentinel(�ڱ�)�ܹ������������� ��
�ڱ�ģʽ��һ�������ģʽ,����Redis�ṩ���ڱ�������,�ڱ���һ�������Ľ���,��Ϊ����,����������С���ԭ�������ڱ�ͨ����������,�ȴ�Redis��������Ӧ,�Ӷ�������еĶ��Redisʵ����
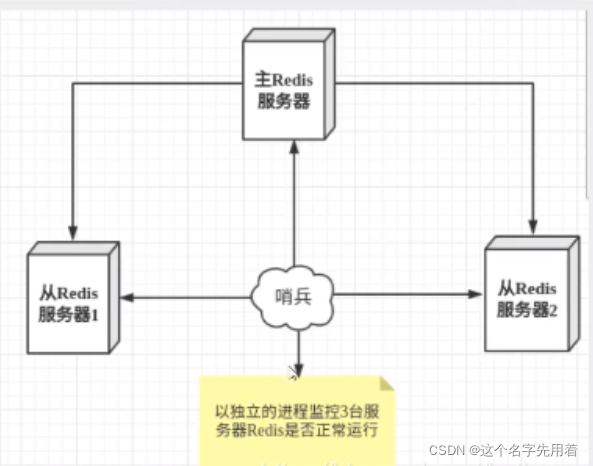
������ڱ�����������:
- ͨ����������,��Redis���������ؼ��������״̬,�������������ʹӷ�������
- ���ڱ���master崻�,���Զ���slave�л���master,Ȼ��ͨ����������ģʽ ֪ͨ�����Ĵӷ�����,�������ļ�,�������л�������
Ȼ��һ���ڱ����̶�Redis���������м��,���ܻ��������,Ϊ��,���ǿ���ʹ�ö���ڱ����м�ء������ڱ�֮�仹����� ������,�������γ��˶��ڱ�ģʽ��
���ڱ�ģʽ:
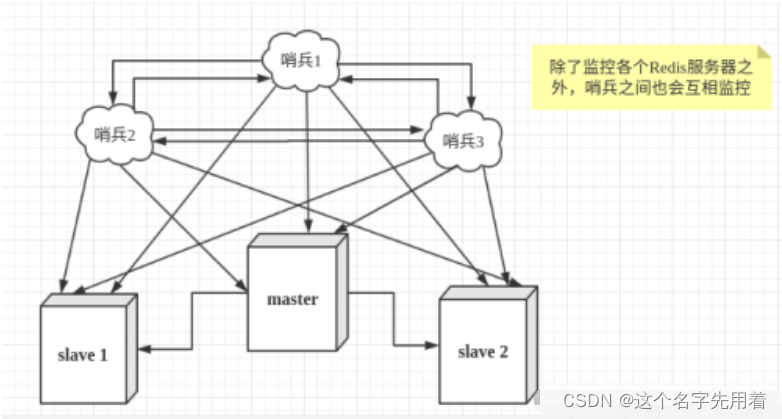
������������崻�,�ڱ�1�ȼ�������,ϵͳ���������Ͻ���failover(����ת��)����,�������ڱ�1���۵���Ϊ��������������,��������Ϊ������������������ڱ�Ҳ����������������,���������ﵽһ��ֵʱ,��ô�ڱ�֮��ͻ����һ��ͶƱ,ͶƱ�Ľ����һ���ڱ�����,����failover�������л��ɹ���,�ͻ�ͨ����������ģʽ,�ø����ڱ����Լ���صĴӷ�����ʵ���л�����,������̳�Ϊ��������
�ڱ�ģʽʹ��:
��һ��:����Ϊһ�����͵�ģʽ,������������������ӹ�ϵ:
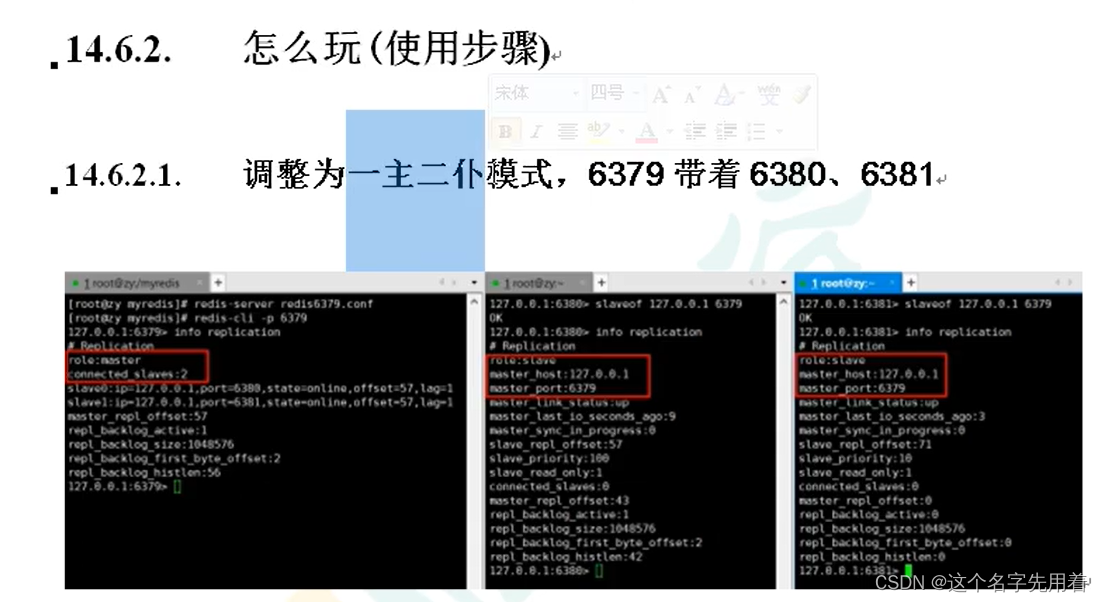
�ڶ���:�������ļ���ͬ��Ŀ¼,�½�һ���ļ�sentinel.conf
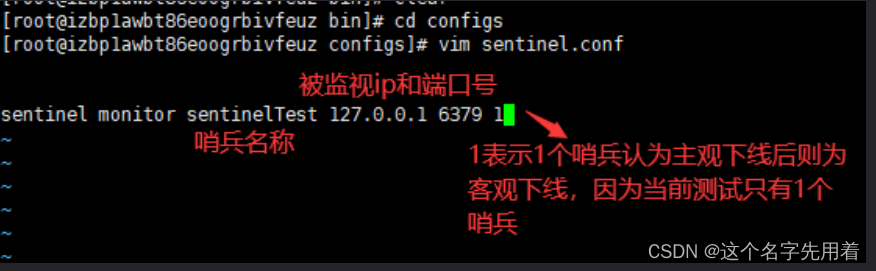
vim sentinel.conf
�ļ�����:
sentinel monitor mymaster 127.0.0.1 6379 1


������:�����ڱ�:

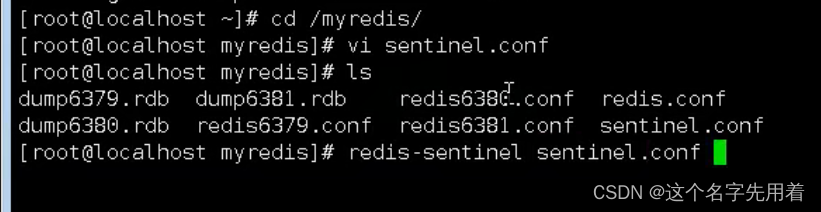
��������:
cd /myredis
ls
redis-sentinel sentinel.conf
������:



�ڱ����л����ӹ���:
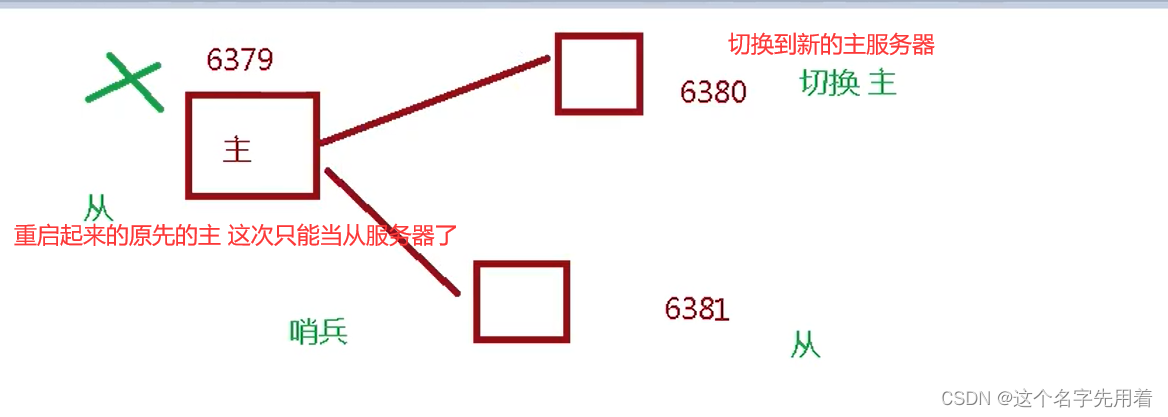
���ڱ�ģʽ,���ò�ͬ�˿ڵ������ļ�����������ڱ��ͻ���,Ȼ���պ�«��ư����:
2.1 �����
2.1.1 ��6379�ڱ�����
˵��:����ϢΨһ��ʶ�ڱ�,�����Ϣ���ڱ�������,���ڱ��Զ�д���
2.�����ڱ���
˵��:������ڱ��Զ���ѡ�����ӽṹ,���±ߵ�master������ڱ���ѡ���Զ��ı仯. 2��ʾ�ɶ���ڱ� ������2̨������ѡ���. һ����ڱ�Ϊ������.
2.1.2 ����6380�ڱ�
˵��:���ö�̨�ڱ�ʱ��2�ַ�ʽ.
ֱ�Ӹ����Ѿ����úõ��ڱ������ļ�,������
a) ������myid�����ڱ���������
b) ���ڱ��˿� 26380
2.1.3 ��6381�ڱ�
˵��:����ȫ�µ������ļ������ڱ�������
�رձ���ģʽ
˵��:ֻ�йرձ���ģʽ,�ڱ����ڱ�֮������ͨ��
�Ķ˿�
�������� �˿� ��ѡ��
����ѡʱ��
˵��:����ѡʱ��Ϊ�˲��Է���.����ȴ�ʱ��ϳ�.һ�����Ĭ�ϵ�ʱ��,������.
˵��:10��û�м�����,�������ѡ.


�°汾����:

java�е����Ӹ���:
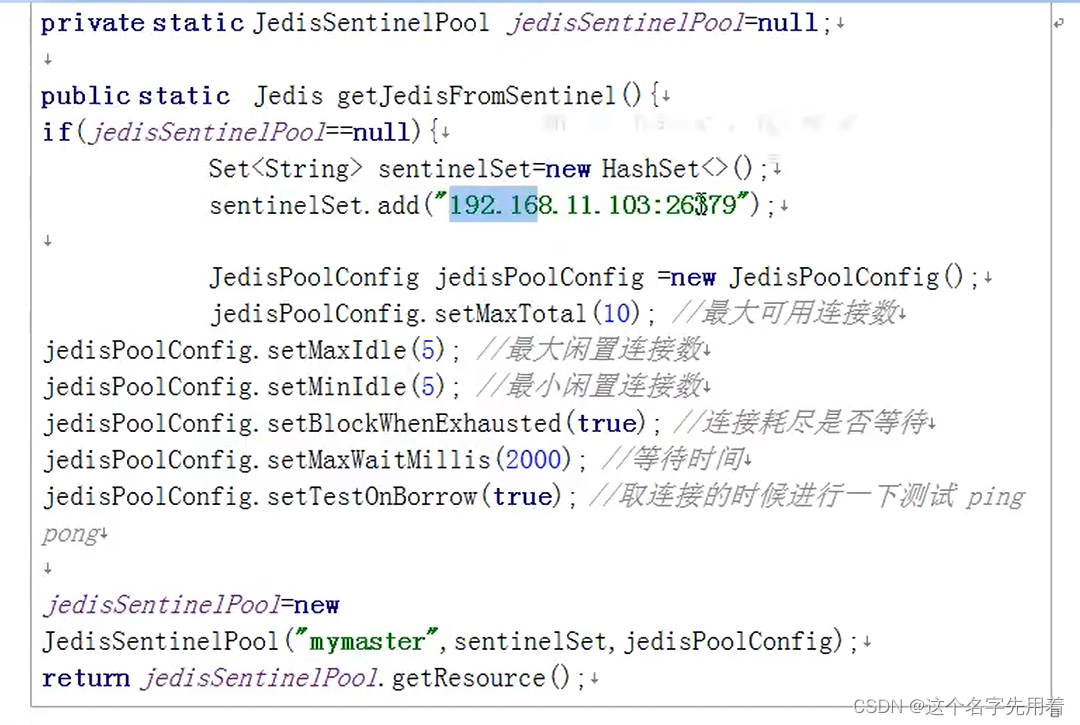
�ο�:
https://xie.infoq.cn/article/d28c092f8c090dddcae3888bc

