本篇博客说说DataX如何进行全量和增量数据同步,虽然用演示oracle同步到mysql,但其他数据库之间的同步都差不多
1.DataX介绍
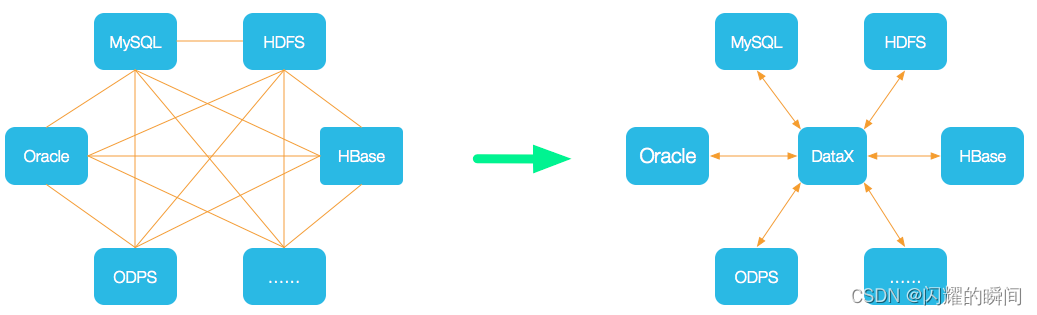
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
Github主页地址:https://github.com/alibaba/DataX
DataX工具下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
DataX采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件

- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
下面是DataX3.0支持的插件,也就是能在这些数据源直接根据json脚本配置互相同步数据
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
2.DataX实战
2.1.DataX基础环境搭建
-
1.把下载好的 datax.tar.gz 上传到Linux
-
2.解压 tar -xzvf datax.tar.gz ,会有 servers/datax 目录,进入cd servers/datax 目录

-
3.先删除datax目录中的所有隐藏文件,否则执行脚本会失败
find ./ -name '._*' -print0 |xargs -0 rm -rf
# rm -rf ./._*
# rm -rf ./plugin/*/._*
- 4.执行测试脚本:./bin/datax.py job/job.json ,看到下图的效果,说明环境正常

2.2.DataX 全量同步数据,oracle 到 mysql
从上面的介绍中可以知道,datax是通过不同的插件去同步数据的,每个插件都有 reader 和 writer ,要从oracle同步数据到mysql,执行: ./bin/datax.py -r oraclereader -w mysqlwriter ,获取示例json配置,然后去修改里面的参数
#在job 目录中创建 vi oracle_to_mysql.json,这是改完后能同步的参数配置
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["INVESTOR_ID","INVESTOR_NAME","ID_TYPE","ID_NO","CREATE_TIME"],
"splitPk": "INVESTOR_ID",
"where" : "INVESTOR_ID is not null",
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@172.17.112.177:1521:helowin"],
"table": ["CXX.CUSTOMER"]
}
],
"password": "123456",
"username": "admin"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"customer_no",
"customer_name",
"id_type",
"id_no",
"create_time"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://172.17.112.176:3306/customer_db?useUnicode=true&characterEncoding=UTF-8",
"table": ["customer_datax"]
}
],
"username": "admin",
"password": "123456",
"preSql": [],
"session": ["set session sql_mode='ANSI'"],
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}
执行全量同步:./bin/datax.py job/oracle_to_mysql.json ,可以看到有 1045条记录被同步到mysql了

2.3.DataX 增量同步数据,oracle 到 mysql
增量同步需要Linux的crontab定时任务配合,再通过shell脚本计算时间,并传递到json脚本的Where条件中,"where" : "CREATE_TIME > unix_to_oracle(${create_time}) and CREATE_TIME <= unix_to_oracle(${end_time})"
${create_time} 和 ${end_time}由shell脚本计算
vi /home/datax/servers/datax/job/oracle_to_mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["INVESTOR_ID","INVESTOR_NAME","ID_TYPE","ID_NO","CREATE_TIME"],
"splitPk": "INVESTOR_ID",
"where" : "CREATE_TIME > unix_to_oracle(${create_time}) and CREATE_TIME <= unix_to_oracle(${end_time})",
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@172.17.112.177:1521:helowin"],
"table": ["CXX.CUSTOMER"]
}
],
"password": "123456",
"username": "admin"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"customer_no",
"customer_name",
"id_type",
"id_no",
"create_time"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://172.17.112.176:3306/customer_db?useUnicode=true&characterEncoding=UTF-8",
"table": ["customer_datax"]
}
],
"username": "admin",
"password": "123456",
"preSql": [],
"session": ["set session sql_mode='ANSI'"],
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}
vi /home/datax/servers/datax/job/increment_sync.sh
#!/bin/bash
source /etc/profile
# 截至时间设置为当前时间戳
end_time=$(date +%s)
# 开始时间设置为300s前时间戳
create_time=$(($end_time - 300))
# 执行datax脚本,传入时间范围
/home/datax/servers/datax/bin/datax.py /home/datax/servers/datax/job/oracle_to_mysql.json -p "-Dcreate_time=$create_time -Dend_time=$end_time" &
并给increment_sync.sh赋可执行权限:chmod -R 777 increment_sync.sh
然后设置 crontab 定时任务,每5分钟执行一次,和上面脚本中的300s对应
crontab -e
*/5 * * * * /home/datax/servers/datax/job/increment_sync.sh >/dev/null 2>&1
tip:oralce是没有 unix_to_oracle 函数的,需要自行在oracle中创建
create or replace function unix_to_oracle(in_number NUMBER) return date is
begin
return(TO_DATE('19700101','yyyymmdd') + in_number/86400 +TO_NUMBER(SUBSTR(TZ_OFFSET(sessiontimezone),1,3))/24);
end unix_to_oracle;
好了,此时就完成了增量同步
3.DataX同步流程:
- 1.第一次部署datax时,手动执行全量同步脚本,同步已有客户数据
- 2.再进行增量同步,用Linux的crontab和脚本配合,能按时间进行增量同步
- 3.oracle同步mysql时,有几种同步模式,建议"writeMode"设置为"update":
- 3.1.mysql的"writeMode"设置为"insert",在有重复数据记录时,不会同步,直接跳过,就算oracle中该条数据已经修改了,也不会同步
- 3.2.mysql的"writeMode"设置为"replace",在有重复数据记录时,会先删除mysql中的记录,再把oracle中的记录新增进去
- 3.3.mysql的"writeMode"设置为"update",在有重复数据记录时,会把oracle中的列,覆盖mysql中的列,未配置同步的列,不会覆盖
- 4.需要在oracle库创建uninx_to_date() 函数
4.增量同步方式优化
上面需要在oracle库创建一个uninx_to_date()函数,下面用shell脚本把uninx时间戳转为yyyy-MM-dd hh:mm:ss 类型,然后传到oracle_to_mysql.json配置中,就不用创建这个uninx_to_date()函数了
increment_sync.sh 脚本获取字符串类型时间:
#!/bin/bash
source /etc/profile
#当前时间戳
cur_time=$(date +%s)
#结束时间
end_time="'$(date -d @$cur_time +"%Y-%m-%d %H:%M:%S")'"
#开始时间,为当前时间的前300s
create_time="'$(date -d @$(($cur_time-120)) +"%Y-%m-%d %H:%M:%S")'"
# 执行datax脚本,传入时间范围
/home/datax/servers/datax/bin/datax.py /home/datax/servers/datax/job/oracle_to_mysql.json -p "-Dcreate_time=$create_time -Dend_time=$end_time" &
修改oracle_to_mysql.json的where参数,去掉uninx_to_date()函数
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["INVESTOR_ID","INVESTOR_NAME","ID_TYPE","ID_NO","CREATE_TIME"],
"splitPk": "INVESTOR_ID",
"where" : "CREATE_TIME >to_date('${create_time}','yyyy-mm-dd hh24:mi:ss') and CREATE_TIME <= to_date('${end_time}','yyyy-mm-dd hh24:mi:ss')",
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@172.17.112.177:1521:helowin"],
"table": ["CXX.CUSTOMER"]
}
],
"password": "123456",
"username": "admin"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"customer_no",
"customer_name",
"id_type",
"id_no",
"create_time"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://172.17.112.176:3306/customer_db?useUnicode=true&characterEncoding=UTF-8",
"table": ["customer_datax"]
}
],
"username": "admin",
"password": "123456",
"preSql": [],
"session": ["set session sql_mode='ANSI'"],
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}

