MySQL
八、MySQL中的日志
MySQL数据库中常见的额日志文件有:
-
错误日志(error log):记录出错信息,也记录一些警告信息或者正确的信息。
可以用`show variables like 'log_error'`来查看错误文件的位置。 -
查询日志(log):记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
-
慢查询日志(slow query log):设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
默认不启动,可用`set global slow_query_log='ON'`打开,也可以在配置文件中设置。 用` set global long_query_time=n;`用来设置阈值时间,执行超过设置值就会记录到日志中 -
二进制日志(bin log):记录对数据库执行更改的所有操作,不包括select和show这类操作,主要作用有恢复、复制和审计,更详细的内容放在后面与redo log一起。
-
中继日志(relay log):中继日志也是二进制日志,与bin log合作用来给slave 库复制主库数。
-
事务日志:重做日志redo和回滚日志undo。
undo log 可参考前面MVCC的部分,这里主要讲下redo log 和 bin log。
8.1redo log
先简单补充几个概念,具体的可参考innodb-buffer-pool、查询缓存和BufferPool
- Buffer Pool:位于存储引擎层,注意与查询缓存的区别,Cache位于server层。在Buffer Pool中有三个很重要的链表,分别是:
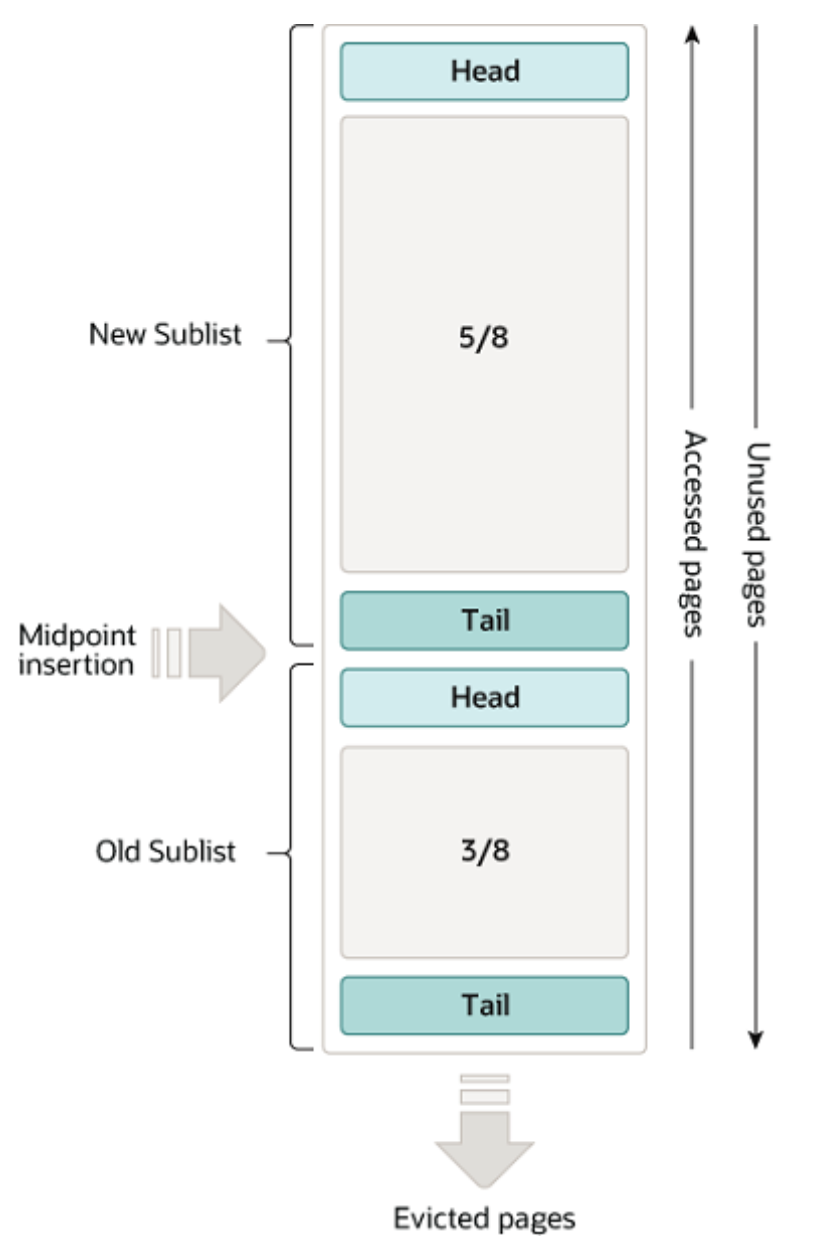
- LRU-List:由于缓存的局部性原理,从磁盘读取数据时会读取需要的数据及其周围地址的数据。MySQL也是存在预读机制的,这会导致传统的LRU链表出现全都不是经常使用的数据的极端情况,因此MySQL对LRU链表做了改进。LRU链表被MidPoint分成了New Sublist和Old Sublist两部分,默认New Sublist占比5/8,Old Sublist占比3/8,New Sublist存储着young page,而Old Sublist存储着Old Page。新页面插入时先加到Old Sublist,默认如果1s内再次访问,那么它就不会被移动到New Sublist。
- Free List:Buffer Pool中基于未被使用的缓存页描述信息组织起来的双向链表,当从磁盘中读取出一个数据页时,先从Free List中找一个节点,接着把读取数据页放入到该节点指向的缓存页中。基于一个hashtable判断读取的数据页是否有对应的缓存页。
key = 表空间号+数据页号
value = 缓存页地址
如果存在于hash table中,那就说明该数据页已经存在于Buffer Pool中了,优先使用Buffer Pool中的缓存页。免去了磁盘的随机IO,其次缓存页中的数据可能是已经被修改了的脏数据。
- Flush List:MySQL更新数据时,为提高效率使用WAL(Write Ahead Log),首先将数据写入日志,然后再写入 DB 文件中。MySQL在Buffer Pool中对数据进行修改后,LRU中的缓存页称为脏页,脏页的描述信息就会加到Flush List这个双向链表中。有一个后台线程Master Thread会按照每秒或者每十秒的速度,异步的将Buffer Pool中一定比例的页面刷新回磁盘中。有一些事件会触发刷新,比如Old Sublist淘汰数据、redo log文件写满了等。

磁盘里的 redo log 是一个顺序写入的、大小固定的环形日志,默认有2个作为一个group,1写完后写第2个,再写完后重新写第1个。redo log 文件写满要擦除数据时,会把redo log读进内存,把数据页更新为脏页,然后再刷入磁盘。redo log里的数据并不是一条一条持久化到磁盘的,而是几个作为一个redo log block,而几个block又组成一个redo log buffer,事务commit的时候就会触发持久化。
刷脏页过程不用动redo log文件的。
宕机redo log在“重放”的时候,如果一个数据页已经是刷过的,会识别出来并跳过。
什么情况会引发数据库的flush过程

一个简单的问题:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
这里涉及到了,“redo log里面到底是什么”的问题。
实际上,redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由redo log更新过去”的情况。
-
如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系。
-
在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
8.2bin log
bin log是MySQL的二进制日志文件,默认binlog不开启,可用show variable like '%datadir'查询存放位置。bin log一定是顺序写入的,如果一个事务过大会现将日志写到磁盘临时文件。
相关配置有
[mysqld]
# binlog相关配置
# 指定binlog日志存储的位置
datadir = /home/mysql/mysql/var
# 规范binlog的命名为 mysql-bin.0000XX
# 如果加这行配置,表示开启binlog,同时binlog文件名为主机名
log-bin = mysql-bin
# binlog的刷盘时机,1表示事务commit的触发
sync-binlog = 1
# binlog的格式,Row 格式的 binlog 会记录两条数据,更新前的更新后的,非常详细,便于日志的恢
# 复。但是占用硬盘空间较多,主从复制时的网络传输开销也会更多一些。statement 格式的话是记sql语句
binlog-format = ROW
redo log 和 binlog 的区别:
- redo log 中记录了 InnoDB Page 的具体修改,也就是物理页。binlog 中记录的是逻辑日志,如:对xxx表中的id=yyy的行做做了什么修改,更改后的值是什么。
- redo log 为 InnoDB 引擎所特有,而 binlog 则是在 MySQL Server 层所实现的,任何一个存储引擎都可以写入 binlog。
- redo log 大小固定,本质上是一个“循环队列”,而 binlog 则可以一直往下写,并创建新的binlog 文件。
通常我们说MySQL的“双1”配置,指的就是sync_binlog和innodb_flush_log_at_trx_commit都设置成 1。
8.3两阶段提交
以一条Update语句来介绍 binlog 和relog是如何记录的。
mysql> update T set c=c+1 where ID=2;

2PC的大致流程为:
- 两阶段提交的第一阶段 (prepare阶段):写rodo-log 并将其标记为prepare状态。
- 写binlog
- 两阶段提交的第二阶段(commit阶段):写bin-log 并将其标记为commit状态。
2PC的作用是:
保证redolog和binlog数据的安全一致性。关闭了bin log也就没有2PC了。开始bin log时,只有在这两个日志文件逻辑上高度一致才能放心的使用redolog将数据库中的状态恢复成crash之前的状态,使用binlog实现数据备份、恢复、以及主从复制。而两阶段提交的机制可以保证这两个日志文件的逻辑是高度一致的。没有错误、没有冲突。
如果在commit阶段宕机了,会根据redolog将修改后的recovey出来,然后提交。此时bin log已经写入,而mysql中断后最终是commit还是rollback完全取决于MySQL能不能判断出binlog和redolog在逻辑上是否达成了一致。只要逻辑上达成了一致就可以commit,否则只能rollback。
判断bin log和redo log一致
当MySQL写完redolog并将它标记为prepare状态时,会在redolog中记录一个XID,它全局唯一的标识着这个事务。当设置sync_binlog=1时,做完了上面第一阶段写redo log后,mysql就会对应bin log并且会直接将其刷新到磁盘中。bin log结束的位置上也有一个XID。只要这个XID和redolog中记录的XID是一致的,MySQL就会认为bin log和redo log逻辑上一致。就上面的场景来说就会commit,而如果仅仅是rodolog中记录了XID,binlog中没有,MySQL就会RollBack。
2PC初衷是用来做分布式事务的,分布式事务的实现方式有很多,既可以采用 InnoDB 提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。
MySQL 从 5.0.3 InnoDB 存储引擎开始支持XA协议的分布式事务。一个分布式事务会涉及多个行动,这些行动本身是事务性的。所有行动都必须一起成功完成,或者一起被回滚。
在MySQL中,使用分布式事务涉及一个或多个资源管理器和一个事务管理器。

如图,MySQL 的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM):
- 应用程序:定义了事务的边界,指定需要做哪些事务;
- 资源管理器:提供了访问事务的方法,通常一个数据库就是一个资源管理器;
- 事务管理器:协调参与了全局事务中的各个事务。
分布式事务采用两段式提交(two-phase commit)的方式:
- 第一阶段所有的事务节点开始准备,告诉事务管理器ready。
- 第二阶段事务管理器告诉每个节点是commit还是rollback。如果有一个节点失败,就需要全局的节点全部rollback,以此保障事务的原子性。
注:内容是从语雀上的学习笔记迁移过来的,有些参考来源已经无法追溯,侵权私删。

