Spark���ٴ����ݷ�������Spark�µ�WSL������װ��Hadoop��������(��)
ϵ������Ŀ¼
Spark���ٴ����ݷ�������Scala���Ի���(Ҽ)��
Spark���ٴ����ݷ�������Spark��װ��IDEA ����(��)
����Ŀ¼
��������:
- Hadoop-3.2
- Spark-3.1.3
- JDK 8
- WSL2 Ubuntu20.04
- Windos10 20H2
Hadoop��WSL2������װ:
Hadoop�����������˵�,����caffe������������ĵ�,װ��caffe�Ժ�װʲô���������š�
��˵�ĺ�windos����õ�linux���а�,WSL2��֤������۵��ǿ������֤�ݡ�������Ц��
����˵��ΰ�װWSL2,ע������˵����WSL2������WSL!
�����ĵ�����Windosרҵ��,����ֱ������WSL��װ����,�����ĵ����Ǽ�ͥ���İ�������¿���
�ʼDZ�Windos��������ʡ������רҵ��?
�ҵ����windos��������Ȳ鿴�Լ�windos�汾,����Ǽ�ͥ�����Ҫ��������ȡ����ϵͳ���,������IJ�Ʒ��Կ:

���������Կ:

������������Կ������,��Կ�Ļ�ȡ��Ȼ�����ܵ�TB��,ֱ������windos������Ȼ�����ʵ����һ������������һ�������뼴�ɡ�(ע����������!)

�������������������,��������ʹ�ü�������м���,һ��7��Ǯ�Ϳ��Ը��,��Ȼ�кܶ������취,�������������ʡ�µ�,����������ò��ϵ�,��ֹû�硣����������Ϊû�취��ͼ��û�н�ͼ,���̶����Զ���,����Ҫ̫���������Ͳ���ϸ���ˡ�
������ɺ���ϵͳ���������뼤����ֱ�Ӽ����:

������ɽ���:

����һ�������������רҵ�档
WSL�İ�װ
Ȼ�����WSL�İ�װ:
��������ϵͳ���:


ȷ����ȴ����:

��windos�̵��в���Ubuntu:

ֱ�ӵ������Ȼ��ȴ���װ����,��װ����Ժ��,����һ���û���������:

�ȹرս���,��Ϊ������ܰ�װ����WSL1,����û��ϵ,���ǿ�������һ��ֱ���þ���,�ȼ��һ�°汾:
��windos cmd����powershell(�Թ���Ա���ݴ�):
��������:wsl -l -v

�����ͼ,��ô��Ͱ�װ����WSL2,����ֱ������hadoop��װ,������������1�����¿���������:
����֮ǰ��Ҫע��һ���������windos�İ汾:
��Ҫ���µ� WSL 2:
- ���� x64 ϵͳ:�汾 1903 ����߰汾,�����ڲ��汾 18362 ����߰汾��
- �ҵ���20H2����û����,������汾������������windos��

����WSL��WSL2
��������Linux�ں˸��°�:���������
������ɺ�ֱ�Ӱ�װ����:

�����û�а�װ�ں˸��°�ֱ�Ӵ�WSL���п����������´���:
WslRegisterDistribution failed with error: 0x800701bc
Error: 0x800701bc WSL 2 ?????????????????? https://aka.ms/wsl2kernelPress any key to continue.. .
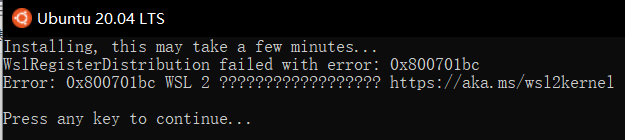
��װ�ں˰��Ժ��û�������ˡ�
��ʱ������������һ��WSL��Ĭ�ϰ汾:
��cmdʹ������:
wsl --set-version Ubuntu-20.04 2
ʹ����ɺ��ٴ�WSL�Ϳ��Կ���:

��һ��ʱ��Ȼ��һ�»س��Ϳ��Կ���:
���Կ���WSL�Ѿ����µ���WSL2��

�����û�����������߸���ʧ��,���ⲻ��,��Ҫ��,ж��Ȼ�ص���װ��������һ�鼴��:

Hadoop��������
���Ƚ���һ��,WSL��һЩ���õĹ���:
��WSL�´�windos���ļ������������linux�µ��ļ���
��������:
explorer.exe .
ע��exe�����һ���ո�
����hadoop�û�
����㰲װ Ubuntu ��ʱ�����õ� ��hadoop�� �û�,��ô��Ҫ����һ����Ϊ hadoop ���û���
$ sudo useradd -m hadoop -s /bin/bash
����������˿��Ե�½�� hadoop �û�,��ʹ�� /bin/bash ��Ϊ shell��(��Ubuntu�ն˴�����,����ճ���Ŀ�ݼ���Ҫ���� shift,��ճ���� ctrl+shift+v��)
$ sudo passwd hadoop
Ϊhadoop�û����ӹ���ԱȨ��:
$ sudo adduser hadoop sudo
�������:
$ su hadoop
�л���hadoop�û���
����apt
�� hadoop �û���¼��,�����ȸ���һ�� apt,��������ʹ�� apt ��װ����,���û���¿�����һЩ������װ���ˡ� �� ctrl+alt+t ���ն˴���,ִ����������:
$ sudo apt-get update
���������� ��HashУ��Ͳ����� ����ʾ,��ͨ����������Դ���������û�и�����,����Ҫ���ġ�������Դ����ij Щ�����Ĺ�����,�����������緽���ԭ�����û�����ص����,��ô�����������Դ��
��װVim
$ sudo apt-get install vim
vim�ij���ģʽ�з�Ϊ����ģʽ,����ģʽ,����ģʽ,����ģʽ�����̳���,ֻ��Ҫ�õ�����ģʽ�Ͳ���ģʽ���� ����л�������������ɱ�ָ�ϵ�ѧϰ��
- ����ģʽ ����ģʽ��Ҫ��������ı����ݡ�һ��ʼ��vim��������ģʽ�����κ�ģʽ�°���Esc���Ϳ��Է�������ģʽ
- ����༭ģʽ ����༭ģʽ���������ı����������ݵġ�������ģʽ��,����i�����ɽ������༭ģʽ
- �˳�vim ���������vim���κε��ı�,һ��Ҫ�ǵñ��档Esc���˻ص�����ģʽ��,Ȼ������:wq���ɱ����ı����˳� vim��
��װSSH������SSH�������½
��Ⱥ�����ڵ�ģʽ����Ҫ�õ� SSH ��½(������Զ�̵�½,����Ե�¼ij̨ Linux ����,������������������), Ubuntu Ĭ���Ѱ�װ�� SSH client,�����Ҫ��װ SSH server:
$ sudo apt-get install openssh-server
��װ��,��Ҫ��������һ��:
$ sudo service ssh restart
����������ֱ���:
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ sudo service ssh restart
sshd: no hostkeys available -- exiting.
ʹ��exit�л���root�û�:
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ exit
exit
jszszzy@LAPTOP-74GAR8S9:~$
���ssh�Ƿ�������Կ,����û��:
jszszzy@LAPTOP-74GAR8S9:~$ cd ~/.ssh/
-bash: cd: /home/jszszzy/.ssh/: No such file or directory
���л���hadoop�û���������һ�±���ssh:
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ sudo ssh localhost
[sudo] password for hadoop:
ssh: connect to host localhost port 22: Connection refused
���ֱ���:
ssh: connect to host localhost port 22: Connection refused
�ⱨ����ʹ���±ߵ�������,����ж��ssh�����°�װһ��Ҳ���ܻ�����
ʹ�ù���Ȩ��ʼssh����:
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ sudo service ssh start
* Starting OpenBSD Secure Shell server sshd sshd: no hostkeys available -- exiting.
**sshd: no hostkeys available �C exiting.**�Ա���
û�취�ֶ�����һ��hostkey,���ּ��ܷ�ʽ:
ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
sudo ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
sudo ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
Generating public/private dsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /etc/ssh/ssh_host_dsa_key
Your public key has been saved in /etc/ssh/ssh_host_dsa_key.pub
The key fingerprint is:
SHA256:Oizwqo5xcIIVUTAetxHLW8StQ2+oRT/FMAWei/EoKIA root@LAPTOP-74GAR8S9
The key's randomart image is:
+---[DSA 1024]----+
| *+=o..+=. |
|.. * =+..oo |
|E o +oo=o. |
|o. . o===. |
|= + ooooS. |
| = o.o . |
|. . o + |
|.o . . . |
|+o. |
+----[SHA256]-----+
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ sudo ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /etc/ssh/ssh_host_rsa_key
Your public key has been saved in /etc/ssh/ssh_host_rsa_key.pub
The key fingerprint is:
SHA256:2iivZii9bXWn7GXnkK3oVoEbjuVkfKuVnjocVyABTcM root@LAPTOP-74GAR8S9
The key's randomart image is:
+---[RSA 3072]----+
| .=+. |
| E.. |
| . o . |
| B o . |
| BS+ = |
| o+* Bo |
| . ...o+.X=.o |
|. o.+o B+o= |
| ..=o..+=o. . |
+----[SHA256]-----+
�ٴδ�ssh,���ֳɹ�:
sudo service ssh restart
* Restarting OpenBSD Secure Shell server sshd
Ȼ����ҽ����Ƿ����:
hadoop@LAPTOP-74GAR8S9:/home/jszszzy$ sps -e | grep ssh
12765 ? 00:00:00 sshd
���ɱ���Կ������������:
hadoop@LAPTOP-74GAR8S9:~/.ssh$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:kMkQ2+migmrgDhEKXw4k7pBs8k88Eawq6aqqhFnz2iw hadoop@LAPTOP-74GAR8S9
The key's randomart image is:
+---[RSA 3072]----+
|. ..+. |
|o+ .* + |
|*+..+ B |
|B+.= o . |
|o+= * . S |
|B+ * o |
|@.. o |
+----[SHA256]-----+
����������:
ע�ǰ����λ��:~/.ssh
hadoop@LAPTOP-74GAR8S9:~/.ssh$ sudo cat ./id_rsa.pub >> ./authorized_keys
����һ��ssh,����������:
hadoop@LAPTOP-74GAR8S9:~/windos_pubkey$ ssh localhost
Welcome to Ubuntu 20.04.4 LTS (GNU/Linux 5.10.16.3-microsoft-standard-WSL2 x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Tue Apr 12 22:00:21 CST 2022
System load: 0.0 Processes: 13
Usage of /: 0.8% of 250.98GB Users logged in: 0
Memory usage: 1% IPv4 address for eth0: 172.20.4.176
Swap usage: 0%
19 updates can be applied immediately.
12 of these updates are standard security updates.
To see these additional updates run: apt list --upgradable
Last login: Tue Apr 12 21:38:02 2022 from 127.0.0.1
Java��������
�Ƽ�ʹ��openjdk��
��������ֱ�Ӱ�װ:
hadoop@LAPTOP-74GAR8S9:~/windos_pubkey$ sudo apt-get install openjdk-8-jdk
��װ��ɺ����һ��:
hadoop@LAPTOP-74GAR8S9:~/windos_pubkey$ java -version
openjdk version "1.8.0_312"
OpenJDK Runtime Environment (build 1.8.0_312-8u312-b07-0ubuntu1~20.04-b07)
OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
JAVAHOME������������:
������������:
hadoop@LAPTOP-74GAR8S9:~$ vim ~/.bashrc
�����±�����һ������:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
Hadoop��������
����hadoop 3.2:hadoop3.2������
ʹ��windos���ļ�����������غõ�hadoopֱ����ק��rootĿ¼��Ӧλ�ü���:
�����ٽ���һ�ַ������ļ������:
���������������:
\\wsl$
������:

�ҿ����������Ŀ¼��:

Ȼ��ʹ�������ѹ��/usr/localĿ¼��:
hadoop@LAPTOP-74GAR8S9:~$ sudo tar -zxf /home/jszszzy/hadoop/hadoop-3.2.2.tar.gz -C /usr/local
Ȼ��ת�Ƶ��ļ�����,����һϵ�в���:
$ cd /usr/local/
$ sudo mv ./hadoop-3.1.3/ ./hadoop # ���ļ�������Ϊhadoop
$ sudo chown -R hadoop ./hadoop # ���ļ�Ȩ��
�������һ��:
$ cd /usr/local/hadoop
$ ./bin/hadoop version
��ʾ:
���·�������·�� �����ע�������е����·�������·��,���ĺ������ֵ� ./bin/�� , ./etc/�� �Ȱ��� ./ ��·��,�� Ϊ���·��,�� /usr/local/hadoop Ϊ��ǰĿ¼�������� /usr/local/hadoop Ŀ¼��ִ�� ./bin/hadoop version ��ͬ��ִ�� /usr/local/hadoop/bin/hadoop version �����Խ����·���ijɾ���·����ִ��,�� ������������ļ��� ~ ��ִ�� ./bin/hadoop version ,ִ�еĻ��� /home/hadoop/bin/hadoop version , �Ͳ�����������Ҫ���ˡ�
��һƪ�������Hadoop�������á�Hadoopα�ֲ�ʽ���á�

