Ŀ¼
һ��NoSQL���ݿ�
���ݿ�ʹ������: https://db-engines.com/en/ranking
1.1��ʲô��nosql���ݿ�
- NoSQL(
NoSQL = Not Only SQL),�⼴����������SQL��,��ָ�ǹ�ϵ�͵����ݿ⡣ - NoSQL ������ҵ������ʽ�洢,���Լ�key-valueģʽ�洢����˴������������ݿ����չ������
- ����ѭSQL��
��֧��ACID- Զ����SQL������
1.2��NoSQL����
- �����ݸ߲����Ķ�д
- �������ݵĶ�д
- �����ݸ߿���չ�Ե�
- �ò���sql�ĺ�����sqlҲ���е����,���Կ�����NoSql
1.3��NoSQL������
- ��Ҫ����֧��
- ����sql�Ľṹ����ѯ�洢,�������ӵĹ�ϵ,��Ҫ��ϯ��ѯ
1.4��Redis��MongoDB
1.4.1��Redis
- ���ݶ����ڴ���,
֧�ֳ־û�,��Ҫ�������ݻָ� - ����֧�ּ�key-valueģʽ,��֧�ֶ������ݽṹ�Ĵ洢,����
string�� list��set��hash��zset���� - һ������Ϊ�������ݿ⸨���־û������ݿ�
1.4.1��MongoDB
- �����ܡ���Դ��ģʽ����(schema free)��
�ĵ������ݿ� - ���ݶ����ڴ���, ����ڴ治��,�Ѳ����õ����ݱ��浽Ӳ��
- ��Ȼ��key-valueģʽ,���Ƕ�value(������json)�ṩ�˷ḻ�IJ�ѯ����
֧�ֶ��������ݼ����Ͷ������Ը������ݵ��ص����RDBMS,��Ϊ���������ݿ⡣�������RDBMS,�洢�ض�������
1.5����ʽ���ݿ����ʽ���ݿ�
1.5.1��Hbase
- HBase��Hadoop��Ŀ�е����ݿ�
- ��������Ҫ�Դ��������ݽ��������ʵʱ�Ķ�д�����ij����С�
HBase��Ŀ����Ǵ����������dz��Ӵ�ı�,��������ͨ�ļ������������10��������,���ɴ�������������Ԫ�ص����ݱ���
1.5.2��Cassandra
- Apache Cassandra��һ����ѵĿ�ԴNoSQL���ݿ�,�����Ŀ�����������ɴ������÷����������������Ӵ�Ⱥ�ϵĺ������ݼ�(
������ͨ���ﵽPB����) - ���ڶ��������Ե���,
Cassandra��ΪԽ�ij����Ƕ�д�뼰��ȡ�������й�ģ����,�����䲻ǿ������Ⱥ�����˼·�ܹ������ֱ�۵ķ�ʽ����Ⱥ�Ĵ�������չ������
1.5.3��������洢��λ
������洢��λһ����B,KB,MB,GB,TB,EB,ZB,YB,BB
ע:���ס�Ϊ����������λ��
- λ bit (����)(Binary Digits):���һλ��������,�� 0 �� 1,��С�Ĵ洢��λ��
- �ֽ� byte:8��������λΪһ���ֽ�(B),��õĵ�λ��
- 1KB (Kilobyte ǧ�ֽ�)=1024B
- 1MB (Megabyte ���ֽ� ��ơ��ס�)=1024KB
- 1GB (Gigabyte ���ֽ� �ֳơ�ǧ�ס�)=1024MB
- 1TB (Trillionbyte �����ֽ� ̫�ֽ�)=1024GB,����1024=2^10 ( 2 ��10�η�)
- 1PB(Petabyte ǧ�����ֽ� ���ֽ�)=1024TB
- 1EB(Exabyte �������ֽ� ���ֽ�)=1024PB
- 1ZB (Zettabyte ʮ�������ֽ� ���ֽ�)= 1024 EB
- 1YB (Jottabyte һ�������ֽ� Ң�ֽ�)= 1024 ZB
- 1BB (Brontobyte һǧ�������ֽ�)= 1024 YB
1.6��ͼ��ϵ�����ݿ� Neo4j
��ҪӦ��:����ϵ,������ͨ����,��ͼ����������(n*(n-1)/2)
����Redis ��װ�������ļ�
1.1������
Redis�ٷ���վ:http://redis.io
Redis���Ĺٷ���վ:http://redis.cn/
���ص�ַ:http://redis.io/download
1.2����װ
docker ��װrredis�鿴==>docker��װredis�����ݹ���
��װC ���Եı��뻷��-centos7����
yum install centos-release-scl scl-utils-build
yum install -y devtoolset-8-toolchain
scl enable devtoolset-8 bash
�鿴gcc�汾
gcc --version
����,��������optĿ¼
# ���û��wget,���Ȱ�װ
# ���� redis6.x Ҳ���Թ�������ѹ����Ȼ���ϴ�
wget http://download.redis.io/releases/redis-6.2.6.tar.gz
tar -zxvf redis-6.2.6.tar.gz
����Դ��Ŀ¼���밲װ
cd redis-6.2.6/src
����
# ����
make
# �������Jemalloc/jemalloc.h ����Ϊ û������C���Ա��뻷��
# ����
#make distclean
��װ
make install
��װĿ¼��:/usr/local/bin

- redis-benchmark:���ܲ��Թ���,�鿴����������
- redis-check-aof:���������AOF�ļ�
- redis-check-dump:���������dump.rdb�ļ�
- redis-sentinel:Redis��Ⱥʹ��
- redis-server:Redis��������������
- redis-cli:�ͻ���,�������
1.3�������ļ�
����Դ��Ŀ¼src,�ȸ���һ�������ļ���Ϊ����
# ����
cp redis.conf redis.conf.bak
# �༭�ļ�
vi redis.conf
# vi ����
# �����ַ��� Ӣ��ģʽ�µ� :/���ҵ�����
# ��ʾ�к� set nu
# �ر��к� set nonu
# �༭ģʽ i
# �˳��༭ esc��
# �����˳� :wq
1.1.1����������
-
������̨����=>daemonize no�ij�yes
-
��������: ע�͵�bind 127.0.0.1 -::1 ����Զ�̷���,��������д������ip,��д�������,�����ƽ����κ�ip��ַ�ķ���

-
���������ʱ���ģʽ����no=>protected-mode yes�ij�no

-
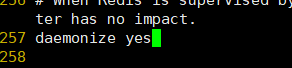
�˿�6379�ij�6300
-
��������

1.1.1.1������redis
����:
redis-server
����˿ڿ���
redis-cli -p6300
����ͻ���
redis-cli
�ر�
redis-cli shutdown
��ʵ���ر�,ָ���˿ڹر�:
redis-cli -p 6300 shutdown
�鿴����
ps -ef |grep redis
ɱ������
kill -9 ���̺�
1.1.2�������ļ����
1.1.2.1��INCLUDES����ģ��
����jsp�е�include,��ʵ����������ѹ��õ������ļ���ȡ����
1.1.2.2�������������
- Ĭ�����bind=127.0.0.1ֻ�ܽ��ܱ����ķ������� ��д�������,�����ƽ����κ�ip��ַ�ķ���
- ���������protected-mode,��ô��
û���趨bind ip��û��������������,Redisֻ�������ܱ�������Ӧ - rotected-mode ����������
����ģʽ����no - port �˿ں�,Ĭ�� 6379
- timeout һ�����еĿͻ���ά�ֶ������ر�,
0��ʾ�رոù��ܡ��������ر��� - tcp-keepalive �Է��ʿͻ��˵�һ��
�������,ÿ��n����һ�Ρ�
��λΪ��,�������Ϊ0,�����Keepalive���,�������ó�60 - tcp-backlog
a.����tcp��backlog,backlog��ʵ��һ�����Ӷ���,backlog�����ܺ�=δ����������ֶ��� + �Ѿ�����������ֶ���
b.�ڸ߲�������������Ҫһ����backlogֵ���������ͻ�������������
c.ע��Linux�ں˻Ὣ���ֵ��С��/proc/sys/net/core/somaxconn��ֵ(128)
������Ҫȷ������/proc/sys/net/core/somaxconn��/proc/sys/net/ipv4/tcp_max_syn_backlog(128)����ֵ���ﵽ��Ҫ��Ч��
1.1.2.3��ͨ��
daemonize:�Ƿ�Ϊ��̨����,����Ϊyespidfile:���pid�ļ���λ��,ÿ��ʵ�������һ����ͬ��pid�ļ�loglevelָ����־��¼����,Redis�ܹ�֧���ĸ�����:debug��verbose��notice��warning,Ĭ��Ϊnoticelogfile��־�ļ�����databases 16�趨������� Ĭ��16,Ĭ�����ݿ�Ϊ0
1.1.2.4��SECURITY��ȫģ��
- requirepass ����C������Ч
1.1.2.5��LIMITS����ģ��
1.1.2.5.1 ��������
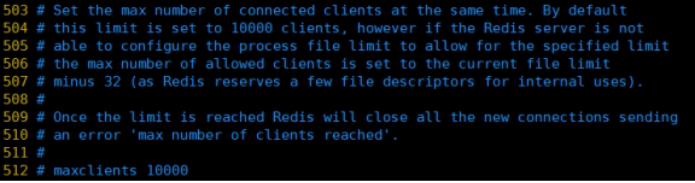
- ����redisͬʱ��������ٸ��ͻ��˽������ӡ�
Ĭ�������Ϊ10000���ͻ���- ����ﵽ�˴�����,redis���ܾ��µ���������,��������Щ������������max number of clients reached��������Ӧ��
1.1.2.5.2 maxmemory
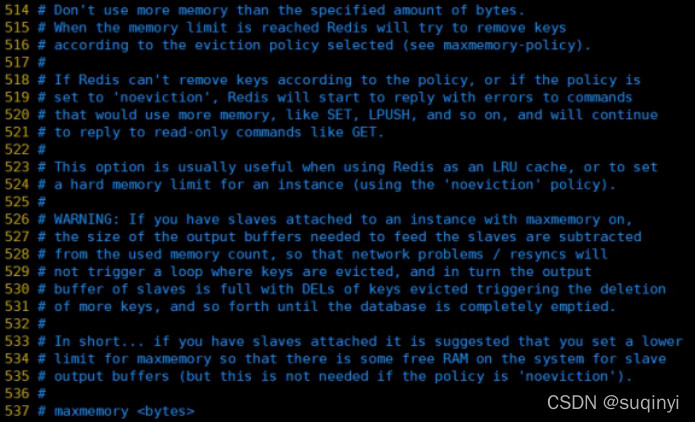
�����������,����,���ڴ�ռ��,��ɷ�����崻�����redis����ʹ�õ��ڴ�����һ�������ڴ�ʹ������,redis������ͼ�Ƴ��ڲ�����,�Ƴ���������ͨ��maxmemory-policy��ָ����- ���redis�������Ƴ��������Ƴ��ڴ��е�����,���������ˡ��������Ƴ���,��ôredis��������Щ��Ҫ�����ڴ��ָ��ش�����Ϣ,����SET��LPUSH�ȡ�
- ���Ƕ������ڴ������ָ��,��Ȼ��������Ӧ,����GET�ȡ�������redis����redis(˵�����redis�д�redis),��ô�������ڴ�ʹ������ʱ,��Ҫ��ϵͳ������һЩ�ڴ�ռ��ͬ�����л���,ֻ���������õ��ǡ����Ƴ����������,�Ų��ÿ���������ء�
1.1.2.5.3. maxmemory-policy
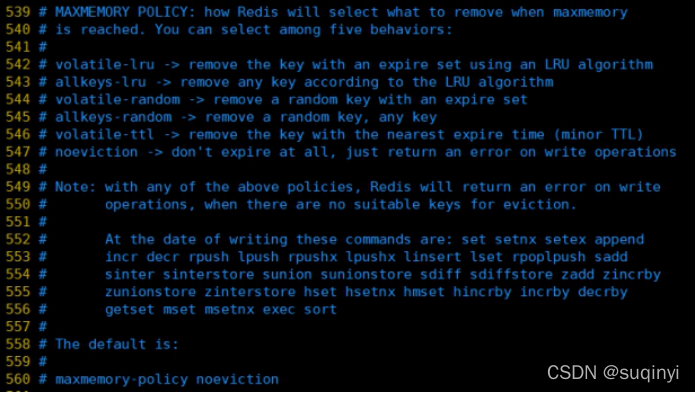
- volatile-lru:ʹ��LRU�㷨�Ƴ�key,ֻ�������˹���ʱ��ļ�;(�������ʹ��)
- allkeys-lru:�����м���key��,ʹ��LRU�㷨�Ƴ�key
- volatile-random:�ڹ��ڼ������Ƴ������key,ֻ�������˹���ʱ��ļ�
- allkeys-random:�����м���key��,�Ƴ������key
- volatile-ttl:�Ƴ���ЩTTLֵ��С��key,����Щ���Ҫ���ڵ�key
- noeviction:�������Ƴ������д����,ֻ�Ƿ��ش�����Ϣ
1.1.2.5.4. 4.6.4.maxmemory-samples
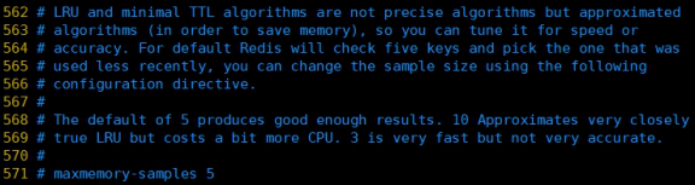
- ������������,
LRU�㷨����СTTL�㷨�������Ǿ�ȷ���㷨,��������ֵ,������������������Ĵ�С,redisĬ�ϻ�����ô���key��ѡ������LRU���Ǹ� - һ������3��7������,
��ֵԽС����Խ��ȷ,����������ԽС��
�������ݳ־û�ģʽRDB��AOF
AOF��RDBͬʱ����,ϵͳĬ��ȡAOF������(���ݲ�����ڶ�ʧ)
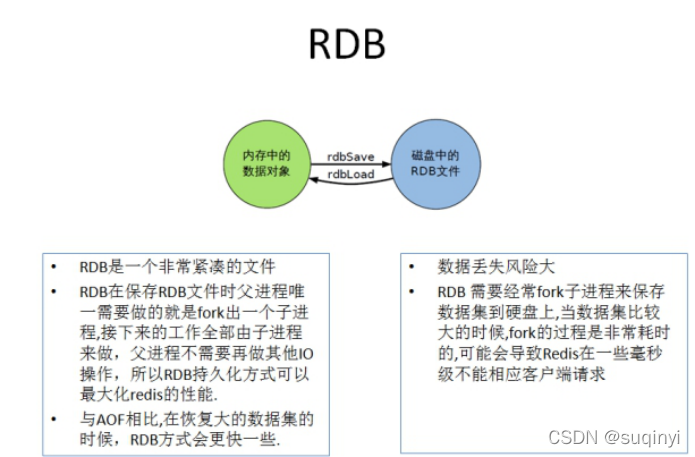
1.1��RDBģʽ(Redis DataBase)
��������:http://www.redis.io
1����ָ����ʱ�����ڽ��ڴ��е����ݼ�����д�����, Ҳ�����л�����Snapshot����,���ָ�ʱ�ǽ������ļ�ֱ�Ӷ����ڴ���
2��Ĭ���ļ���dump.rdb
1.1.1��RDB�־û�����ͼ
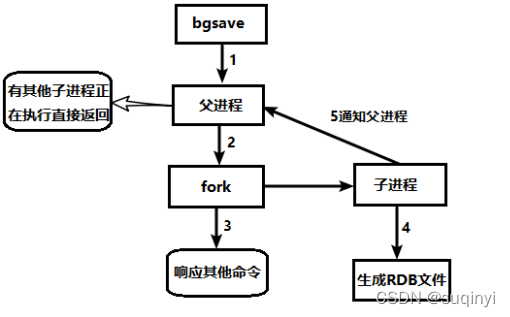
1.1.2���־û�����˵��
- Redis�ᵥ������(fork)һ���ӽ��������г־û�,���Ƚ�����д�뵽 һ����ʱ�ļ���,���־û����̶�������,���������ʱ�ļ��滻�ϴγ־û��õ��ļ���
- ����������,
�������Dz������κ�IO������,���ȷ�������ߵ����� �����Ҫ���д��ģ���ݵĻָ�,�Ҷ������ݻָ������������Ƿdz�����,��RDB��ʽҪ��AOF��ʽ���ӵ���Ч�� RDB��ȱ�������һ�γ־û�������ݿ��ܶ�ʧ��
1.1.3��ʲô��Fork
Fork�������Ǹ���һ���뵱ǰ����һ���Ľ�����- �½��̵���������(���������������������������)
��ֵ����ԭ����һ��,������һ��ȫ�µĽ���,����Ϊԭ���̵��ӽ��� - ��Linux������,
fork()�����һ����������ȫ��ͬ���ӽ���,���ӽ����ڴ˺���execϵͳ����,����Ч�ʿ���,Linux�������ˡ�дʱ���Ƽ����� - һ����������̺��ӽ���
�Ṳ��ͬһ�������ڴ�,ֻ�н��̿ռ�ĸ��ε�����Ҫ�����仯ʱ,�ŻὫ�����̵����ݸ���һ�ݸ��ӽ��̡�
1.1.4����ֹ̬ͣRDB����
save�����ֵ,��ʾ���ñ������
redis-cli config set save ""
1.1.5��redis.conf�е����úʹ�������
- ��redis.conf�������ļ�����,
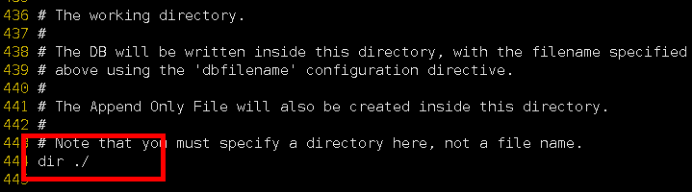
Ĭ��Ϊdump.rdb - rdb�ļ��ı���·��,
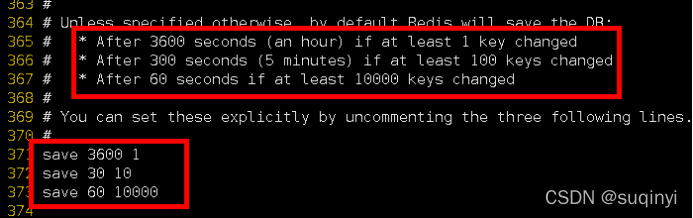
Ĭ��ΪRedis����ʱ���������ڵ�Ŀ¼�� dir ./ - save 3600 1 ��ʾ 3600����һ��key���ָı�ʹ���д��(�־û�)
�Ƽ�ʹ��:bgsave
a��save :saveʱֻ�ܱ���,��������,ȫ��**����**���ֶ����档������
b��bgsave:Redis������̨�첽���п��ղ���, ����ͬʱ��������Ӧ�ͻ�������
c������ͨ��lastsave �����ȡ���һ�γɹ�ִ�п��յ�ʱ�� - stop-writes-on-bgsave-error:��Redis ��д����� �Ļ�,ֱ�ӹص�Redis��д�������Ƽ�yes.
- rdbcompression :ѹ���ļ�
a�����ڴ洢�������еĿ���,���������Ƿ����ѹ���洢��
b������ǵĻ�,redis�����LZF�㷨����ѹ����
c������㲻������CPU������ѹ���Ļ�,��������Ϊ�رմ˹��ܡ�
c���Ƽ�yes. - rdbchecksum ���������
a���ڴ洢���պ�,��������redisʹ��CRC64�㷨����������У��
b�����������������Ӵ�Լ10%����������,���ϣ����ȡ��������������,���Թرմ˹���
c���Ƽ�yes.
��ͼ:




1.1.6 RDBģʽ�����ƺ�����
1.1.6.1������
- �ʺϴ��ģ�����ݻָ�
- �����������Ժ�һ����Ҫ�߸��ʺ�ʹ��
- ��ʡ���̿ռ�
- �ָ��ٶȿ�
1.1.6.2������
- fork��ʱ��,�ڴ��е����ݱ���¡��һ��,����2������������Ҫ����
- ��ȻRedis��forkʱʹ����дʱ��������,������������Ӵ�ʱ���DZȽ��������ܡ�
- �ڱ���������һ�����ʱ����һ�α���,�������Redis����down���Ļ�,�ͻᶪʧ���һ�ο��պ�������ġ�
1.1.7.3������ͼ
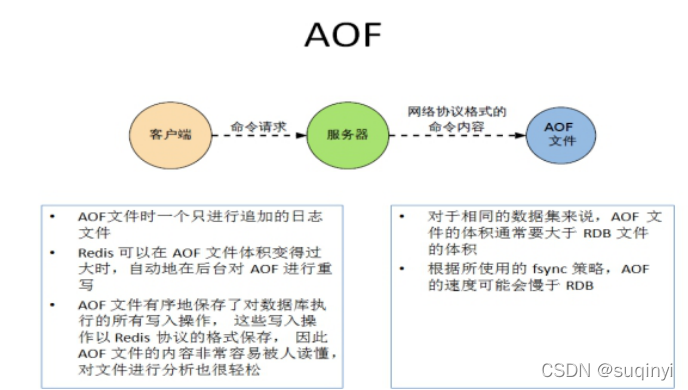
1.2��AOFģʽ(Append Only File)
- AOFģʽĬ�ϲ�����
- `����־����ʽ����¼ÿ��д����(��������),��Redisִ�й�������дָ���¼����(����������¼), ֻ�����ļ��������Ը�д�ļ�
- redis����֮�����ȡ���ļ����¹�������,����֮,redis �����Ļ�������־�ļ������ݽ�дָ���ǰ����ִ��һ����������ݵĻָ�����
- ������redis.conf�������ļ�����,Ĭ��Ϊ appendonly.aof
- AOF�ļ��ı���·��,ͬRDB��·��һ�¡�
1.1.1�� AOF�־û�����
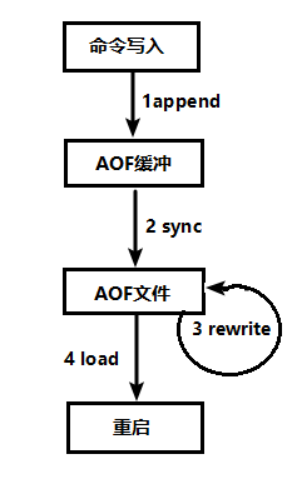
- �ͻ��˵�����д����ᱻappend�ӵ�AOF��������;
- AOF����������AOF�־û�����[always,everysec,no]������syncͬ�������̵�AOF�ļ���
- AOF�ļ���С������д���Ի��ֶ���дʱ,���AOF�ļ�rewrite��д,ѹ��AOF�ļ�����
- Redis��������ʱ,������load����AOF�ļ��е�д�����ﵽ���ݻָ���Ŀ��
1.1.2�� AOF�������쳣��
����:
�������ļ�,Ĭ�ϵ�appendonly no,��Ϊyes
�쳣��(AOF�ļ���)
ͨ��/usr/local/bin/redis-check-aof--fix appendonly.aof���лָ�
�ָ�:
����redisȻ���Զ����¼���
1.1.3�� AOFͬ��Ƶ������
- appendfsync always
ʼ��ͬ��,ÿ��Redis��д�붼�����̼�����־;���ܽϲ���������ԱȽϺ� - appendfsync everysec
ÿ��ͬ��,ÿ�������־һ��,���崻�,��������ݿ��ܶ�ʧ�� - appendfsync no
redis����������ͬ��,��ͬ��ʱ����������ϵͳ��
1.1.4��Rewrite��дѹ��
1.1.4.1��˵��
- AOF
�����ļ��ӷ�ʽ,�ļ���Խ��Խ��Ϊ������ִ������,��������д����, - ��AOF�ļ��Ĵ�С�������趨����ֵʱ,Redis�ͻ�����AOF�ļ�������ѹ��, ֻ�������Իָ����ݵ���Сָ�.
- ����ʹ������bgrewriteaof
1.1.4.2����д����ͼ
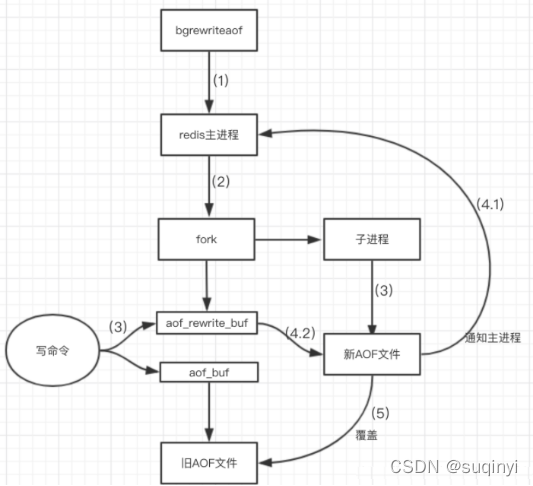
bgrewriteaof������д,�ж��Ƿ�ǰ��bgsave��bgrewriteaof������,�����,��ȴ�������������ټ���ִ�С�- ������fork���ӽ���ִ����д����,��֤�����̲���������
- �ӽ��̱���redis�ڴ������ݵ���ʱ�ļ�
- �ͻ��˵�д����ͬʱд��aof_buf��������aof_rewrite_buf��д��������֤ԭAOF�ļ������Լ���AOF�ļ������ڼ���µ������Ķ������ᶪʧ��
- �ӽ���д���µ�AOF�ļ���,�������̷��ź�,�����̸���ͳ����Ϣ.
- �����̰�aof_rewrite_buf�е�����д�뵽�µ�AOF�ļ���
- ʹ���µ�AOF�ļ����Ǿɵ�AOF�ļ�,���AOF��д��
1.1.4.3����дԭ���ʹ�����д����
1��AOF�ļ���������������ʱ,��fork��һ���½��������ļ���д(Ҳ����д��ʱ�ļ������rename)
2��redis4.0�汾������д,��ָ�Ͼ��ǰ�rdb �Ŀ���,�Զ����Ƶ���ʽ�����µ�aofͷ��,��Ϊ���е���ʷ����,�滻��ԭ������ˮ�˲�����
- ��д��Ȼ����
��Լ�������̿ռ�,���ٻָ�ʱ���� - ����ÿ����д������һ���ĸ�����
- ����趨Redis
Ҫ����һ�������Ż������д
����:
no-appendfsync-on-rewrite=yes (�������ݰ�ȫ��,�������)
��д��aof�ļ�ֻд�뻺��,�û���������,���������ʱ�����崻��ᶪʧ���ʱ��Ļ������ݡ�
no-appendfsync-on-rewrite=no (���ݰ�ȫ,�������ܽ���)
���ǻ��������������ˢ,����������д����,���ܻᷢ��������
auto-aof-rewrite-percentage:
������д�Ļ�ֵ,�ļ��ﵽ100%ʱ��ʼ��д(�ļ���ԭ����д���ļ���2��ʱ����)
auto-aof-rewrite-min-size:
������д�Ļ�ֵ,��С�ļ�64MB���ﵽ���ֵ��ʼ��д��
ʾ��˵��:
����:�ļ��ﵽ70MB��ʼ��д,����50MB,�´�ʲôʱ��ʼ��д?
��:100MB
- ϵͳ����ʱ�����ϴ���д���ʱ,Redis���¼��ʱAOF��С,��Ϊbase_size
- ���Redis��AOF��ǰ��С>= base_size +base_size*100% (Ĭ��)�ҵ�ǰ��С>=64mb(Ĭ��)�������,Redis���AOF������д��
1.1.5�����ƺ�����
1.1.5.1������
- ���ݻ��Ƹ��Ƚ�,��ʧ���ݸ��ʸ���
- �ɶ�����־�ı�,ͨ������AOF�Ƚ�,���Դ��������
1.1.5.2������
- ?����RDBռ�ø���Ĵ��̿ռ䡣
- �ָ������ٶ�Ҫ����
- ÿ�ζ�д��ͬ���Ļ�,��һ��������ѹ��
- ���ڸ���Bug,��ɻָ�����
1.1.5.1������ͼ
1.3���Ƽ�һ��ʹ��
rdbģʽ�䱸��aofģʽ�ȱ�
- ��������ݲ�����,����ѡ������RDB��
- �����鵥���� AOF,��Ϊ���ܻ����Bug��
1.4����������˵��
1.4.1��RDB��AOF����˵��
- RDB�־û���ʽ�ܹ���ָ����ʱ�����ܶ�������ݽ��п��մ洢
- AOF�־û���ʽ��¼ÿ�ζԷ�����д�IJ���,��������������ʱ�������ִ����Щ�������ָ�ԭʼ������,AOF������redisЭ���ӱ���ÿ��д�IJ������ļ�ĩβ.
- Redis���ܶ�AOF�ļ����к�̨��д,ʹ��AOF�ļ�����������ڹ���
- ֻ������:�����ֻϣ����������ڷ��������е�ʱ�����,��Ҳ���Բ�ʹ���κγ־û���ʽ.
1.4.2��ͬʱ�������ֳ־û���ʽ
- �����������,��redis������ʱ�����������AOF�ļ����ָ�ԭʼ������, ��Ϊ��ͨ�������AOF�ļ���������ݼ�Ҫ��RDB�ļ���������ݼ�Ҫ����.
- RDB�����ݲ�ʵʱ,ͬʱʹ������ʱ����������Ҳֻ����AOF�ļ�
- ��Ҫ��Ҫֻʹ��AOF��?
- ���鲻Ҫ,��ΪRDB���ʺ����ڱ������ݿ�(AOF�ڲ��ϱ仯���ñ���), ��������,���Ҳ�����AOF����DZ�ڵ�bug,������Ϊһ����һ���ֶΡ�
1.4.2�����ܽ���
- ��ΪRDB�ļ�ֻ��������;,����ֻ��Slave�ϳ־û�RDB�ļ�,����ֻҪ15���ӱ���һ�ξ���,ֻ����
save 900 1(��ʾ900�� ��key�仯 )��������(Ҳ�����䱸) - ���ʹ��AOF,�ô���������������Ҳֻ�ᶪʧ��������������,�����ű��ϼ�ֻload�Լ���AOF�ļ��Ϳ����ˡ�
- ����:һ�Ǵ����˳�����IO,����AOF rewrite�����rewrite�����в�����������д�����ļ���ɵ����������Dz��ɱ���ġ�
- ֻҪӲ������,
Ӧ�þ�������AOF rewrite��Ƶ��,AOF��д�Ļ�����СĬ��ֵ64M̫С��,�����赽5G���ϡ� - Ĭ�ϳ���ԭ��С100%��Сʱ��д���Ըĵ��ʵ�����ֵ��

