ϵ������Ŀ¼
ʵ�����ݺ�iceberg ��һ�� ����
ʵ�����ݺ�iceberg �ڶ��� iceberg����hadoop�ĵײ����ݸ�ʽ
ʵ�����ݺ�iceberg ������ ��sqlclient��,��sql��ʽ��kafka�����ݵ�iceberg
ʵ�����ݺ�iceberg ���Ŀ� ��sqlclient��,��sql��ʽ��kafka�����ݵ�iceberg(�����汾��flink1.12.7)
ʵ�����ݺ�iceberg ����� hive catalog�ص�
ʵ�����ݺ�iceberg ������ ��kafkaд�뵽icebergʧ������ ���
ʵ�����ݺ�iceberg ���߿� ʵʱд�뵽iceberg
ʵ�����ݺ�iceberg �ڰ˿� hive��iceberg����
ʵ�����ݺ�iceberg �ھſ� �ϲ�С�ļ�
ʵ�����ݺ�iceberg ��ʮ�� ����ɾ��
ʵ�����ݺ�iceberg ��ʮһ�� ���Է�������������(�������������ϲ���ɾ����)
ʵ�����ݺ�iceberg ��ʮ���� catalog��ʲô
ʵ�����ݺ�iceberg ��ʮ���� metadata�������ļ���ܶ������
ʵ�����ݺ�iceberg ��ʮ�Ŀ� Ԫ���ݺϲ�(���Ԫ������ʱ�����Ӷ�Ԫ�������͵�����)
ʵ�����ݺ�iceberg ��ʮ��� spark��װ�뼯��iceberg(jersey����ͻ)
ʵ�����ݺ�iceberg ��ʮ���� ͨ��spark3��iceberg����֪֮��
ʵ�����ݺ�iceberg ��ʮ�߿� hadoop2.7,spark3 on yarn����iceberg����
ʵ�����ݺ�iceberg ��ʮ�˿� ���ֿͻ�����iceberg������������(��������)
ʵ�����ݺ�iceberg ��ʮ�ſ� flink count iceberg,�������
ʵ�����ݺ�iceberg �ڶ�ʮ�� flink + iceberg CDC����(�汾����,����ʧ��)
ʵ�����ݺ�iceberg �ڶ�ʮһ�� flink1.13.5 + iceberg0.131 CDC(���Գɹ�INSERT,�������ʧ��)
ʵ�����ݺ�iceberg �ڶ�ʮ���� flink1.13.5 + iceberg0.131 CDC(CRUD���Գɹ�)
ʵ�����ݺ�iceberg �ڶ�ʮ���� flink-sql��checkpoint����
ʵ�����ݺ�iceberg �ڶ�ʮ�Ŀ� icebergԪ������ϸ����
ʵ�����ݺ�iceberg �ڶ�ʮ��� ��̨����flink sql ��ɾ�ĵ�Ч��
ʵ�����ݺ�iceberg �ڶ�ʮ���� checkpoint���÷���
ʵ�����ݺ�iceberg �ڶ�ʮ�߿� flink cdc ���Գ����������:�ܴ��ϴ�checkpoint���������
ʵ�����ݺ�iceberg �ڶ�ʮ�˿� �ѹ��вֿ��ϲ����ڵİ������زֿ�
ʵ�����ݺ�iceberg �ڶ�ʮ�ſ� ������Ÿ�Ч��ȡflink��jobId
ʵ�����ݺ�iceberg ����ʮ�� mysql->iceberg,��ͬ�ͻ�����ʱ������
����Ŀ¼
ǰ��
mysql->flink-sql-cdc->iceberg����flink������ʱ��û����,��spark-sql��,ʱ��+8�ˡ������������м�¼
���������: Դ��û��timezone, ���α���Ҫ����local timezone,������û������!
һ��spark��ѯiceberg����,���ڼ�8, ����ԭ��
1��spark sql��ѯiceberg�������ڵ��ֶα�����timezone�Ĵ�
java.lang.IllegalArgumentException: Cannot handle timestamp without timezone fields in Spark. Spark does not natively support this type but if you would like to handle all timestamps as timestamp with timezone set 'spark.sql.iceberg.handle-timestamp-without-timezone' to true. This will not change the underlying values stored but will change their displayed values in Spark. For more information please see https://docs.databricks.com/spark/latest/dataframes-datasets/dates-timestamps.html#ansi-sql-and-spark-sql-timestamps
at org.apache.iceberg.relocated.com.google.common.base.Preconditions.checkArgument(Preconditions.java:142)
at org.apache.iceberg.spark.source.SparkBatchScan.readSchema(SparkBatchScan.java:127)
at org.apache.spark.sql.execution.datasources.v2.PushDownUtils$.pruneColumns(PushDownUtils.scala:136)
at org.apache.spark.sql.execution.datasources.v2.V2ScanRelationPushDown$$anonfun$applyColumnPruning$1.applyOrElse(V2ScanRelationPushDown.scala:191)
at org.apache.spark.sql.execution.datasources.v2.V2ScanRelationPushDown$$anonfun$applyColumnPruning$1.applyOrElse(V2ScanRelationPushDown.scala:184)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:481)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:82)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:481)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:457)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:425)
at org.apache.spark.sql.execution.datasources.v2.V2ScanRelationPushDown$.applyColumnPruning(V2ScanRelationPushDown.scala:184)
at org.apache.spark.sql.execution.datasources.v2.V2ScanRelationPushDown$.apply(V2ScanRelationPushDown.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2ScanRelationPushDown$.apply(V2ScanRelationPushDown.scala:35)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:211)
at scala.collection.LinearSeqOptimized.foldLeft(LinearSeqOptimized.scala:126)
at scala.collection.LinearSeqOptimized.foldLeft$(LinearSeqOptimized.scala:122)
at scala.collection.immutable.List.foldLeft(List.scala:91)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:208)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:200)
at scala.collection.immutable.List.foreach(List.scala:431)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:200)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:179)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:88)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:179)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$optimizedPlan$1(QueryExecution.scala:138)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:196)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:196)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan$lzycompute(QueryExecution.scala:134)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan(QueryExecution.scala:130)
at org.apache.spark.sql.execution.QueryExecution.assertOptimized(QueryExecution.scala:148)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executedPlan$1(QueryExecution.scala:166)
at org.apache.spark.sql.execution.QueryExecution.withCteMap(QueryExecution.scala:73)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:163)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:101)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:69)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:384)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.$anonfun$processLine$1(SparkSQLCLIDriver.scala:504)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.$anonfun$processLine$1$adapted(SparkSQLCLIDriver.scala:498)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processLine(SparkSQLCLIDriver.scala:498)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:287)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:955)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1043)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1052)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2��������ʾ,����ȥʱ������
set spark.sql.iceberg.handle-timestamp-without-timezone=true;
spark-sql (default)> set `spark.sql.iceberg.handle-timestamp-without-timezone`=true;
key value
spark.sql.iceberg.handle-timestamp-without-timezone true
Time taken: 0.016 seconds, Fetched 1 row(s)
spark-sql (default)> select * from stock_basic2_iceberg_sink;
i ts_code symbol name area industry list_date actural_controller update_time update_timestamp
0 000001.SZ 000001 ƽ������ ���� ���� 19910403 NULL 2022-04-14 03:53:24 2022-04-21 00:58:59
1 000002.SZ 000002 ���A ���� ȫ���ز� 19910129 NULL 2022-04-14 03:53:31 2022-04-21 00:59:06
4 000006.SZ 000006 ����ҵA ���� ����ز� 19920427 �������������������ʲ��ල����ίԱ�� NULL NULL
2 000004.SZ 000004 �������� ���� �������� 19910114 ��ӳͮ 2022-04-14 03:53:34 2022-04-21 00:59:11
3 000005.SZ 000005 ST��Դ ���� �������� 19901210 ֣����,���M 2022-04-14 03:53:40 2022-04-22 00:59:15
Time taken: 1.856 seconds, Fetched 5 row(s)
���ݺ���ʱ����mysql��ʱ��,���Բ�һ�¡�spark��iceberg��ʱ�����Լ���8Сʱ��

����:���ܼ�ȥʱ��
3. ����local timezone
SET `table.local-time-zone` = 'Asia/Shanghai';
set spark.sql.iceberg.handle-timestamp-without-timezone=true; ��
������ʱ��,������Ч:
����Ϊ�Ϻ�ʱ��:
spark-sql (default)> SET `table.local-time-zone` = 'Asia/Shanghai';
key value
table.local-time-zone 'Asia/Shanghai'
Time taken: 0.014 seconds, Fetched 1 row(s)
spark-sql (default)> select * from stock_basic2_iceberg_sink;
i ts_code symbol name area industry list_date actural_controller update_time update_timestamp
0 000001.SZ 000001 ƽ������ ���� ���� 19910403 NULL 2022-04-14 03:53:24 2022-04-21 00:58:59
1 000002.SZ 000002 ���A ���� ȫ���ز� 19910129 NULL 2022-04-14 03:53:31 2022-04-21 00:59:06
4 000006.SZ 000006 ����ҵA ���� ����ز� 19920427 �������������������ʲ��ල����ίԱ�� NULL NULL
2 000004.SZ 000004 �������� ���� �������� 19910114 ��ӳͮ 2022-04-14 03:53:34 2022-04-21 00:59:11
3 000005.SZ 000005 ST��Դ ���� �������� 19901210 ֣����,���M 2022-04-14 03:53:40 2022-04-22 00:59:15
Time taken: 0.187 seconds, Fetched 5 row(s)
����Ϊutcʱ��:
spark-sql (default)> SET `table.local-time-zone` = 'UTC';
key value
table.local-time-zone 'UTC'
Time taken: 0.015 seconds, Fetched 1 row(s)
spark-sql (default)> select * from stock_basic2_iceberg_sink;
i ts_code symbol name area industry list_date actural_controller update_time update_timestamp
0 000001.SZ 000001 ƽ������ ���� ���� 19910403 NULL 2022-04-14 03:53:24 2022-04-21 00:58:59
1 000002.SZ 000002 ���A ���� ȫ���ز� 19910129 NULL 2022-04-14 03:53:31 2022-04-21 00:59:06
4 000006.SZ 000006 ����ҵA ���� ����ز� 19920427 �������������������ʲ��ල����ίԱ�� NULL NULL
2 000004.SZ 000004 �������� ���� �������� 19910114 ��ӳͮ 2022-04-14 03:53:34 2022-04-21 00:59:11
3 000005.SZ 000005 ST��Դ ���� �������� 19901210 ֣����,���M 2022-04-14 03:53:40 2022-04-22 00:59:15
Time taken: 0.136 seconds, Fetched 5 row(s)
����ʱ��,������Ч
spark.sql.session.timeZone ������
���� ʹ��flink-sql��ѯ,����ʱ��û����
����: ʱ��������mysql����һ�µ�:
- flink sql �˲�ѯ���:
Flink SQL> select i,ts_code,update_time,update_timestamp from stock_basic2_iceberg_sink;

2. mysql�˲�ѯ���:

����:ʱ��������mysql����һ�µ�
����ǿ�и�source ����timezone,����
��timestamp��ΪTIMESTAMP_LTZ
String createSql = "CREATE TABLE stock_basic_source(\n" +
" `i` INT NOT NULL,\n" +
" `ts_code` CHAR(10) NOT NULL,\n" +
" `symbol` CHAR(10) NOT NULL,\n" +
" `name` char(10) NOT NULL,\n" +
" `area` CHAR(20) NOT NULL,\n" +
" `industry` CHAR(20) NOT NULL,\n" +
" `list_date` CHAR(10) NOT NULL,\n" +
" `actural_controller` CHAR(100),\n" +
" `update_time` TIMESTAMP_LTZ\n," +
" `update_timestamp` TIMESTAMP_LTZ\n," +
" PRIMARY KEY(i) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'hadoop103',\n" +
" 'port' = '3306',\n" +
" 'username' = 'xxxxx',\n" +
" 'password' = 'XXXx',\n" +
" 'database-name' = 'xxzh_stock',\n" +
" 'table-name' = 'stock_basic2'\n" +
")" ;
�����,
Caused by: java.lang.IllegalArgumentException: Unable to convert to TimestampData from unexpected value '1649879611000' of type java.lang.Long
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema$12.convert(RowDataDebeziumDeserializeSchema.java:504)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema$17.convert(RowDataDebeziumDeserializeSchema.java:641)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.convertField(RowDataDebeziumDeserializeSchema.java:626)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.access$000(RowDataDebeziumDeserializeSchema.java:63)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema$16.convert(RowDataDebeziumDeserializeSchema.java:611)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema$17.convert(RowDataDebeziumDeserializeSchema.java:641)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.extractAfterRow(RowDataDebeziumDeserializeSchema.java:146)
at com.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.deserialize(RowDataDebeziumDeserializeSchema.java:121)
at com.ververica.cdc.connectors.mysql.source.reader.MySqlRecordEmitter.emitElement(MySqlRecordEmitter.java:118)
at com.ververica.cdc.connectors.mysql.source.reader.MySqlRecordEmitter.emitRecord(MySqlRecordEmitter.java:100)
at com.ververica.cdc.connectors.mysql.source.reader.MySqlRecordEmitter.emitRecord(MySqlRecordEmitter.java:54)
at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:128)
at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:294)
at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:69)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:423)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:684)
at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:639)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:650)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:623)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:779)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)
at java.lang.Thread.run(Thread.java:748)
22/04/21 10:49:30 INFO akka.AkkaRpcService: Stopping Akka RPC service.
�ܲ��ܸ����α���timezone?
�ġ� ���α�ûtimezone,���α���timezone
���α�:mysql��datetime��timestamp, ��ԭ����Ӧ��TIMESTAMP,��ΪTIMESTAMP_LTZ
LTZ: LOCAL TIME ZONE����˼
mysql���ṹ:
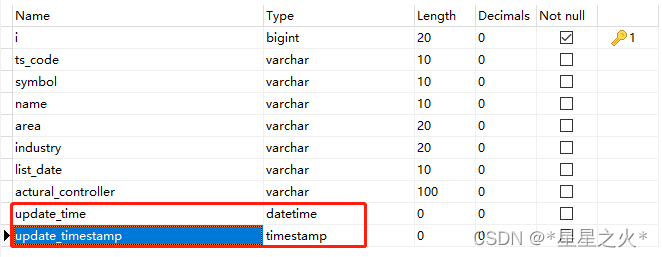
mysql��:
String createSql = "CREATE TABLE stock_basic_source(\n" +
" `i` INT NOT NULL,\n" +
" `ts_code` CHAR(10) NOT NULL,\n" +
" `symbol` CHAR(10) NOT NULL,\n" +
" `name` char(10) NOT NULL,\n" +
" `area` CHAR(20) NOT NULL,\n" +
" `industry` CHAR(20) NOT NULL,\n" +
" `list_date` CHAR(10) NOT NULL,\n" +
" `actural_controller` CHAR(100),\n" +
" `update_time` TIMESTAMP\n," +
" `update_timestamp` TIMESTAMP\n," +
" PRIMARY KEY(i) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'hadoop103',\n" +
" 'port' = '3306',\n" +
" 'username' = 'XX',\n" +
" 'password' = 'XX" +
" 'database-name' = 'xxzh_stock',\n" +
" 'table-name' = 'stock_basic2'\n" +
")" ;
���α�:
String createSQl = "CREATE TABLE if not exists stock_basic2_iceberg_sink(\n" +
" `i` INT NOT NULL,\n" +
" `ts_code` CHAR(10) NOT NULL,\n" +
" `symbol` CHAR(10) NOT NULL,\n" +
" `name` char(10) NOT NULL,\n" +
" `area` CHAR(20) NOT NULL,\n" +
" `industry` CHAR(20) NOT NULL,\n" +
" `list_date` CHAR(10) NOT NULL,\n" +
" `actural_controller` CHAR(100) ,\n" +
" `update_time` TIMESTAMP_LTZ\n," +
" `update_timestamp` TIMESTAMP_LTZ\n," +
" PRIMARY KEY(i) NOT ENFORCED\n" +
") with(\n" +
" 'write.metadata.delete-after-commit.enabled'='true',\n" +
" 'write.metadata.previous-versions-max'='5',\n" +
" 'format-version'='2'\n" +
")";
���Ժ�,����OK�ˡ�
spark-sql�IJ�ѯ���:

flink-sql ��ѯ�Ľ��:

����
�������ڵ�����:Դ��û��timezone, ���α���Ҫ����local timezone

