andy��cmu15-445���������Ҫ�����ݿ�ϵͳ��ʹ��mmap
��Ϊ���,������������������� mmap ������,��һ���ⶼ�Ƕ� mmap �İ���, ����mmap���ܴ����ĸ���Ӱ����֮����,���������һ��andy�����ġ�
��������
ͨ�������,���ݿ�ϵͳ�����ļ�IO����������ѡ��:
- �������Լ�ʵ��
buffer pool�������ļ�io�����ڴ������ - ʹ��linuxʵ�ֵ�
mmapϵͳ���ý��ļ�ֱ��ӳ�䵽�û���ַ�ռ�, �������öԿ���������page cache��ʵ��ҳ��Ļ��뻻��
���ڵڶ��ַ���,�����߲���Ҫ�ֶ������ڴ�,ʵ��������,��˺ܶ����ݿ�ϵͳ����ʹ��MMAP������buffer pool,
��������һЩ�������������������MMAP(��һ��Ҳ�����ĵ�һ����Ҫ���۾�),��Ϊ�Լ������ļ�I/O��
���۽���
buffer pool��ԭ��
���ڴ�ͳ��IO��ʽ,�ײ�ʵ����ͨ������read()��write()��ʵ�֡�
- ���ļ����ݴ�Ӳ�̶�ȡ��
bufferpool - �����ݸ��Ƶ�
�������� - ������ҳ����Ҫ����д�ش�����,ͨ���������û��㷨�������������
�ڲ�����socket�������,�����Ĺ��̷���������仯:�û�̬���ں�̬�ı仯��
- �û�����ͨ��
read()���������ϵͳ������á�������:�û�̬ -->�ں�̬ - �����ݴ�Ӳ�̿�����
������(buffer pool)�� - cpu�����������ݿ�����
�û���������,������:�ں�̬�C>�û�̬,read()����
���Ϲ��̷����� 2���������л� �� 2�ο���
mmap��ԭ��
����mmap��ԭ��,���� 0�������� ��ͨ���Ż������ݴ�ϵͳ�������Ƶ��û������������,������1�ο�����
ʹ�� mmap ϵͳ����,���Խ��û��ռ�� �����ڴ��ַ ���ļ�����ӳ��, ��ӳ���������ڴ��ַ���ж�д �͵ȼ��� ���ļ����ж�д������
����ԭ��:mmapֱ��ӳ���˻�������ҳ����,���Ǵ����е��ļ�������
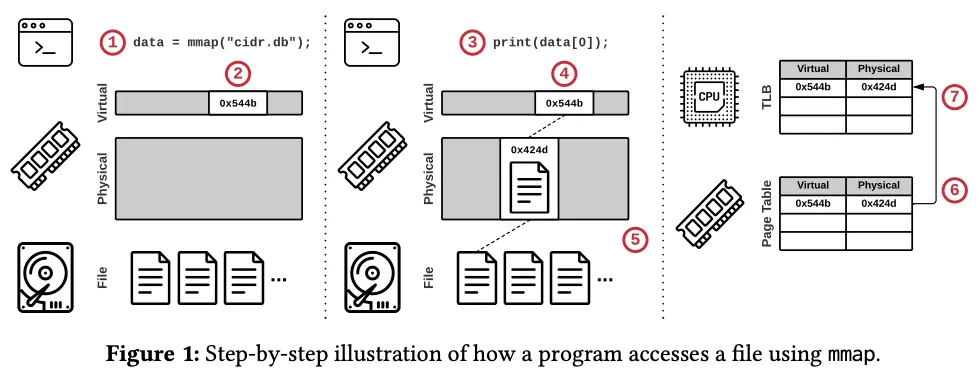
�����н����˳���ʹ��MMAP�����ļ�,��������
- ����ʼ���� mmap (������:�û�̬�C>�ں�̬)
- ����ϵͳ����һ���������ַ�ռ�(���̵�ַ�ռ���),��ʱû�п�ʼ�����ļ���
- ���ݴ�Ӳ���п������� ����������(ϵͳ����)
- ����ϵͳ������
ϵͳ�������ҵ������ ҳ���������ַ - ���� �ڴ�ҳ ������(ȱҳ),��˴�����
ҳ����,��ʼ���ⲿ�洢����3����ȡ���Dz������ݼ��ص������ڴ�ҳ�� - ����ϵͳ��ҳ��������һ����Ŀ,��
�����ַӳ�䵽�µ�������ַ - ��������ʹ�õ�cpu���Ľ�ҳ������ص�ҳ������(TLB)��(������: �ں�̬ --> �û�̬ )
������Կ���������,2���������л�,1�ο���
��������ʲ����ڴ��е�ҳ��,os�Ὣ���Ǽ��ص��ڴ��С����ҳ�滺������,������û��㷨���ҳ�档
- ����ϵͳ��ҳ����ÿ��cpu�ں˵�
tlb��ɾ��ӳ��
����tlb�ܼ�,����ɾ��tlb��Ҫos���� ����Ĵ��������ж� ˢ��,�ⱻ��ΪTLB������ TLB���� �Ժ���ʵ���кܴ��Ӱ�졣
mmap��api
���߸������ڴ�ӳ���ļ�io��POSIXϵͳ������
- mmap:������
MAP_SHARED��MAP_PRIVATE�ڿɼ����ϵ����� - madvise:������
MADV_NORMAL,MADV_RANDOM��MADV_SEQUENTIAL��Ԥ���ϵ����� - mlock:���Գ����Ե���ס�ڴ��е�ҳ��,һ���̶��Ϸ�ֹ��д�ش洢��(Ȼ��������ȷ���Ե���ס)
- msync:��ҳ����ڴ�д�ش洢�Ľӿ�
mmap
��Ҫ������MAP_SHARED��MAP_PRIVATE������
�˵��õ����ļ�ӳ�䵽DBMS�������ַ�ռ�,Ȼ��DBMS����ʹ����ͨ���ڴ������ȡ��д���ļ����ݡ�
- MAP_SHARED:���ĺ���ļ� ��д �صײ��ļ�
- MAP_PRIVATE:����һ��ֻ�е����߿��Է��ʵ�дʱ����ӳ��,������д�� �ײ��ļ���
madvise
������MADV_NORMAL��MADV_RANDOM,MADV_SEQUENTIAL���ֱ�־������
- MADV_NORMAL:����linuxϵͳִ��Ĭ�ϲ���,ϵͳ���᷵�ؽ�����
ǰ15��ҳ������16��ҳ����
��ʹֻ��Ҫһ��ҳ��,ϵͳҲ�᷵��32��ҳ��,�����˼����ϵͳ���� - MADV_RANDOM:����ϵͳ,����ҳ��������ġ�
- MADV_SEQUENTIAL:����ϵͳ,���ǽ�Ҫ˳��ִ�С�
mlock
�õ�������dbms��ҳ��̶����ڴ���,����֤����ϵͳ��Զ����������
���Ǹ���POSIX����linuxʵ��,��ʹ���̶���,����ϵͳ��ʱ�Ὣ��ҳ��д�ش����С����,mlockֻ�ܱ�֤ҳ�治�ᱻ����,���ܹ���֤��ҳ���ᱻ��д�ش�����,���������ȫ�кܴ��Ӱ�졣
msync
���ڴ淶Χ������ʾˢ�µ� �ⲿ�洢�� ,���û���������,DBMS��û������������ ���� ˢ�µ� �ⲿ�洢��
���ߵĶԱ�
����������,����io���������Ŀ���
buffer pool:2���������л�,2�ο���mmap:2���������л�,1�ο���
������,�ƺ� mmap ����������,�����潫����� mmap �������������⡣
ͬʱ,Խ��Խ������ݿⶼ��ʹ�� mmap ֮��,����buffer pool
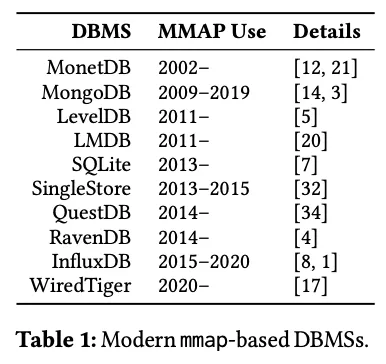
�������
�����о����ĸ�ʹ��MMAP��������������
����һ:����ȫ
�ڻ���MMAP��DBMS����ҳ�������ܴ����ս��
��������ҳ,����ϵͳ������ʱ����ҳ��д���ⲿ�豸, ������д�������Ƿ��Ѿ��ύ��
DBMS����ֹˢ��,���Ҳ�����ˢ��ʱ�յ��κξ��������,����Ҫ�ø��ӵ�Э����ȷ������ҳ���� Υ������ȫ��֤��
���ǽ����µķ�����Ϊ:
- ����ϵͳдʱ����
- �û��ռ�дʱ����
- Ӱ�ӷ�ҳ
����ϵͳдʱ����(copy-on-write)
ʹ��MAP_PRIVATE��ʶλ����һ��������д�ռ�(�����ڴ渴��),д���������д�ռ�ִ��,�������Զ�ȡԭ���Ŀռ䡣ͬʱʹ��WAL��֤д��������־û��� �����ύ��,��д�ռ��������ݸ��Ƶ����ռ�,����Ӧ��WAL���Ƶ������洢�С�
ע��: ����ϵͳ����ȷ�����и��¶�д�뵽���ռ���,�Ż�ɾ��˽�пռ䡣����ϵͳ����ʹ��mremap����������˽�пռ�
�û��ռ�дʱ����(copy-on-write)
���Ʋ���ϵͳдʱ����,����д�ռ����û��ռ俪��,ͬ��д��WAL��֤�־��ԡ������ύ��,���û��ռ�д�ض��ռ䡣
Ӱ�ӷ�ҳ
Ӱ�ӷ�ҳ���Ƶ�һ�ַ���,����û��WAL�IJ���,����ֱ�ӳ������ݷ�ҳ,һ��ֻ����,��һ�ݿ�д,�����ύ�����ڿ�дҳ����msync֮������ֻ��ҳ�����Զ������µ�ҳ��
��������:
- �ֳ�����ҳ��,һ��Ϊ��ҳ��,һ��ΪӰ��ҳ��
- ��Ӱ��ҳ�������,����Ӧ������д���ⲿ�洢��
- ��Ӱ��ҳ����Ϊ�µ���ҳ��,ԭ������ҳ����ΪӰ��ҳ��
�����:ioͣ��
�����:����ʹ���첽io�������ѯִ���ڼ������̡߳�
mmap:���Ի������������
- dbms�����첽��ȡ��
- ����ϵͳ���Զ�ҳ��������,������Ľ�ҳ������ڴ档����ȱҳ����
��,���ڻ����ҳ���û�����os���Ƶ�,����������page cache�Ļ��뻻��,����ioͣ�١�
����ϵͳʹ��ҳ����û�ж����ݿⳡ�������ر��Ż�,����ʹ�õ�ʱ���Ӱ������
������:������
����ض����ļ����ݵ�У�����Զ��ҳ������,mmapֻ���Ե���ҳ������,��Ϊ��ǰҳ�治�ܿ���,���������������
����,ָ�������ܻᵼ��ҳ�����,����ؿ�����ˢ��ǰ����ļ��������������,��mmapֻ��ֱ��ˢ��,���ܼ��
����,mmapӦ�Ե�ϵͳ���û����sigbus�źű���,������io��ʽ��buffer pool���Ը��õĽ��io����
������:��������
ҵ���ձ���ΪMMAP�ȴ�ͳ��read/write����,��Ҫ������������ԭ��:
- ����ϵͳ���ں�̨�����ļ�ӳ���ҳ�����,�����ļ�ӳ�����,������page falut�����ں�,������Ӧ�ó���
- MMAP�����������û��ռ�Ķ���ĸ��Ʋ���,��Ӧ�ļ������ڴ�ռ��
������������������ǵķ���:MMAP����ڴ�ͳread/write I/O��Ŀǰ�ߴ����Ĵ洢�豸���Ǹ���ġ���ָ��������ԭ��:
- ҳ������
- ���̵߳�ҳ�滻��:ҳ�滻���ǵ��̵߳�(ʹ��kswapd),�����cpu���
- TLB���� :��һ��ҳ��ʧЧ,ÿ�ζ���Ҫһ���ж�����ˢ�²���,���Ƕ���һ���жϻ���ļ�ǧ��ʱ������,�Ƿdz���ʱ��
ʵ��˵��
������,����ʹ�����������ʷ�ʽ����ʵ��:�������,ѭ�����
�������
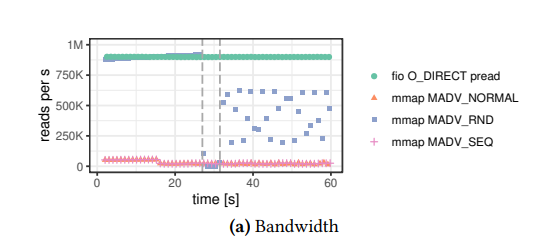
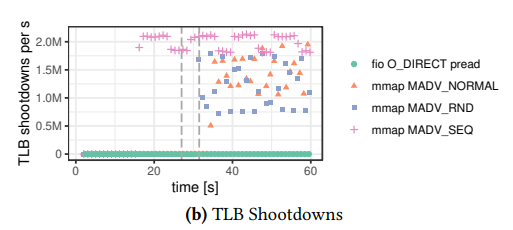
��ͼ���������������,io��ȡ��mmap���ֶ�ȡ��ʽ��,100���߳�ÿ���ȡ��ҳ����
���Կ���,��ͳio��ȡ��Ȼ����,���߸���������ԭ�����
- tlb����
- MMAP�в���ϵͳ��ʹ�õ�������(kswapd)����ҳ������,����ܵ�cpu������
- MMAP�в���ϵͳ����ͬ��ҳ��,ͬ�����������������߳̾���
�����������������,��ͳio������ͨ��DBMS���������� �������ȼ� �� ����̲���
ѭ�����
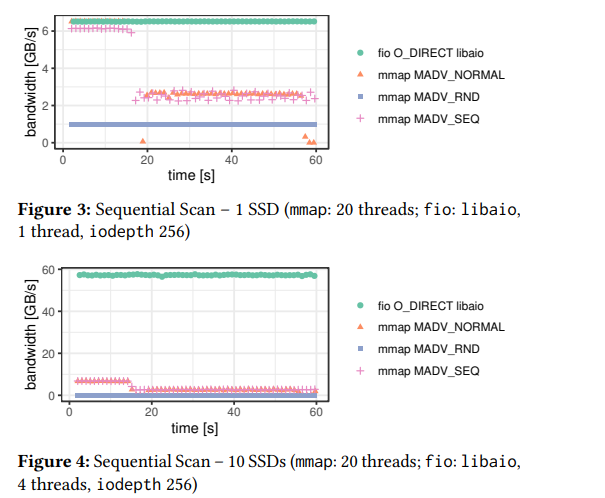
��Ҫ������������������
- ������ʵ�����ȱ��
- ��ѭ�������,MMAP���ܷ��ʶ��SSD,�����������Ϊ�����¿���
�ܽ�
mmap��Ҫ�ŵ����ڸ���ʵ��,������������ڴ�ͳio�豸,���Ŷ�Ƕȷ���������¶������
���߸���db������Ա���½���
���㲻Ӧ����dbms��ʹ��mmap�����
- ��Ҫ����ȫ�ķ�ʽִ�и���
- ϣ���ڲ���������io������´���ҳ�����,������Ҫ�����ڴ��е�����
- ���Ĵ���������Ҫ������ȷ�Ľ��
- ��Ҫ���ٳ־ô洢�豸�ĸ�������
��ʹ��mmapʱ��Ҫע��
- ���ݿ���߹����� �ʺ��ڴ沢�ҹ���������ֻ����
- ����������һ���Ի��ڵĹ�������

