一、集群环境规划
| 服务器名称 | IP | HDFS | YARN |
|---|---|---|---|
| master | 192.168.0.100 | NameNode | ResourceManager |
| node1 | 192.168.0.101 | DataNode | NodeManager |
| node2 | 192.168.0.102 | DataNode | NodeManager |
| node3 | 192.168.0.103 | DataNode | NodeManager |
二、相关软件包
| 软件名 | 下载链接 |
|---|---|
| CentOS 7.9 | 下载 |
| Hadoop 3.2.3 | 下载 |
| Spark 3.2.1 | 下载 |
| JDK 1.8.0.321 | 下载 |
| Anaconda3 | 下载 |
注:安装完虚拟机后,这里将下载的安装包放到/opt/bigdadata目录下
三、安装配置虚拟机
1.虚拟机安装
使用VirtualBox新建虚拟机,内存以及硬盘大小依据物理机自身内存和硬盘大小配置即可:
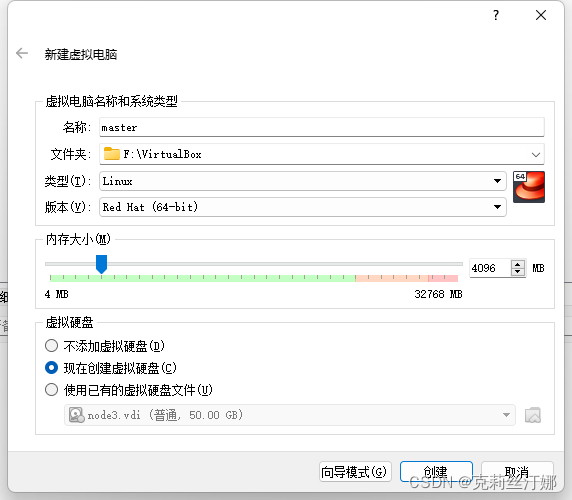
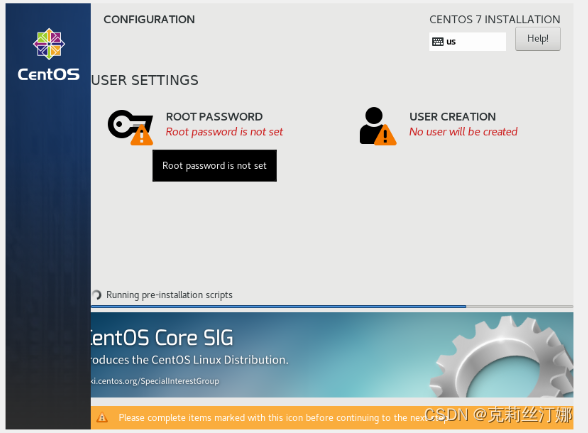
虚拟机镜像选择下载的CentOS,按照安装提示进行即可,安装向导最后一步创建完root用户密码后,点右边的USER CREATION,新建一个用户名hduser,作为spark用户
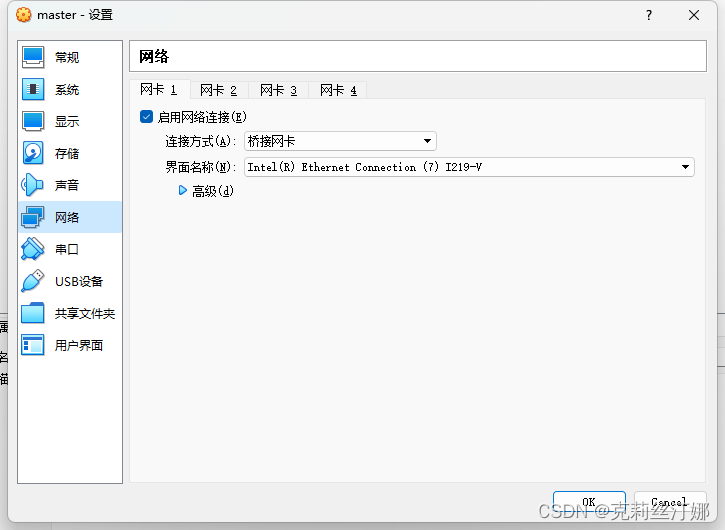
安装完成后,关闭虚拟机,在虚拟机设置中修改网络配置为桥接方式(方便主机和虚拟机以及虚拟机和虚拟机之间进行通信)
2.虚拟机(master)配置
1.配置主机名:
hostnamectl set-hostname master
2.设置静态IP
编辑网卡配置, IP需和物理机在同一网段
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
修改BOOTPROTO为static, ONBOOT为yes, 并添加IP相关配置
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
UUID=13795826-58dd-479b-ad39-194a1949edaf
DEVICE=enp0s3
ONBOOT=yes
#ip
IPADDR=192.168.0.100
GATEWAY=192.168.0.1
NETMASK=255.255.255.0
3.禁用防火墙
systemctl disable firewalld
4.修改SSH配置
禁用DNS配置项(前面的#号得去掉),解决连接缓慢问题
sed -i 's/GSSAPIAuthentication yes/GSSAPIAuthentication no/g' /etc/ssh/sshd_config
sed -i '/UseDNS yes/ a UseDNS no' /etc/ssh/sshd_config
5.给当前用户添加权限
visudo
添加hduser:

6.修改hosts文件,添加如下配置
192.168.0.100 master
192.168.0.101 node1
192.168.0.102 node2
192.168.0.103 node3
7.重启
重启刷新下主机名和IP以及SSH配置
reboot
四、JDK配置
解压:
cd /opt/bigdata
tar -zxvf jdk-8u321-linux-x64.tar.gz
设置环境变量:
vi /etc/profile
export JAVA_HOME=/opt/bigdata/jdk1.8.0_321
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:
五、Hadoop配置(master)
解压:
cd /opt/bigdata
tar -zxvf hadoop-3.2.3.tar.gz
1.设置环境变量:
vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop-3.2.3
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
2. 配置hadoop-env.sh:
cd /opt/bigdata/hadoop-3.2.3/etc/hadoop
vi hadoop-env.sh
修改JAVA_HOME,并去掉前面的#号
JAVA_HOME=/opt/bigdata/jdk1.8.0_321
3. 配置core-site.xml:
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-3.2.3/data/tmp</value>
</property>
</configuration>
4. 配置hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property><!--NameNode的本地文件系统路径-->
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property><!--数据需要备份的数量,不能大于集群的机器数量,默认为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
5. 配置mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6. 配置yarn-site.xml:
<configuration>
<property><!--NodeManager上运行的附属服务,用于运行mapreduce-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
7. 配置workers:
node1
node2
node3
8. 创建并格式化HDFS:
mkdir /home/hduser/hadoop/dfs/data
mkdir /home/hduser/hadoop/dfs/name
mkdir /home/hduser/hadoop/data/tmp
hadoop namenode -format
六、Anaconda3配置
执行下载的脚本:
cd /opt/bigdata
sh ./Anaconda3-2021.11-Linux-x86_64.sh
空格跳过License说明,并输入yes,接着输入安装路径:/opt/bigdata/ananconda3,等待完成后再次输入yes进行初始化即可
更新源,添加国内源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --set show_channel_urls yes
创建一个python3.9的环境:
conda create -n pyspark python=3.9
七、Spark配置
解压
cd /opt/bigdata
tar -zxvf spark-3.2.1-bin-hadoop3.2.tgz
1. 配置环境变量
vi /etc/profile
export SPARK_HOME=/opt/bigdata/spark-3.2.1-bin-hadoop3.2
export PYSPARK_PYTHON=/opt/bigdata/anaconda3/envs/pyspark/bin/python3.9
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/Hadoop
vi /home/hduser/.bashrc
export PYSPARK_PYTHON=/opt/bigdata/anaconda3/envs/pyspark/bin/python3.9
export JAVA_HOME=/opt/bigdata/jdk1.8.0_321
2. 配置workers
vi /opt/bigdata/spark-3.2.1-bin-hadoop3.2/conf/workers
node1
node2
node3
3. 配置spark-env.sh
vi /opt/bigdata/spark-3.2.1-bin-hadoop3.2/conf/spark-env.sh
# 设置JAVA安装目录
JAVA_HOME=/opt/bigdata/jdk1.8.0_321
# HADOOOP软件配置文件目录
HADOOP_CONF_DIR=/opt/bigdata/hadoop-3.2.3/etc/hadoop
YARN_CONF_DIR=/opt/bigdata/hadoop-3.2.3/etc/hadoop
# MASTER 主机名
export SPARK_MASTER_HOST=master
# spark master通讯端口
export SPARK_MASTER_PORT=7077
# webui
SPARK_MASTER_WEBGUI_PORT=8080
# worker cpu核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=4g
# worker通讯地址
SPARK_WORKER_PORT=7078
# worker的webui地址
SPARK_WORKER_WEBUI_PORT=8081
# 设置历史日志目录
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://master:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
4. 配置spark-defaults.conf
# 开启日志记录功能
spark.eventLog.enabled true
# 设置日志记录路径
spark.eventLog.dir hdfs://master:8020/sparklog/
# 设置spark日志是否压缩
spark.eventLog.compress true
5. log4j.properties配置
修改打印级别由INFO改为WARN
log4j.rootCategory=WARN, console
八、node1主机配置
1、关闭配置好的Master虚拟机,之后选中,并点击复制
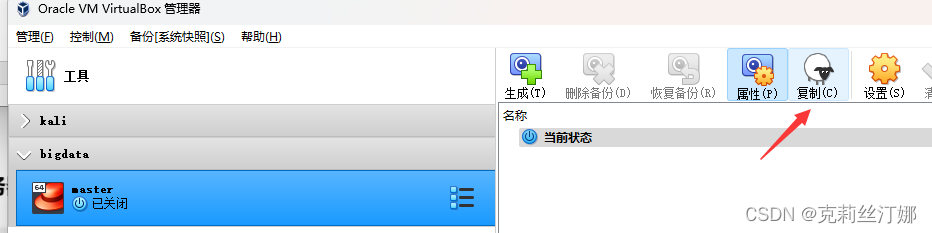
2、名称改为node1,MAC地址选择重新生成:
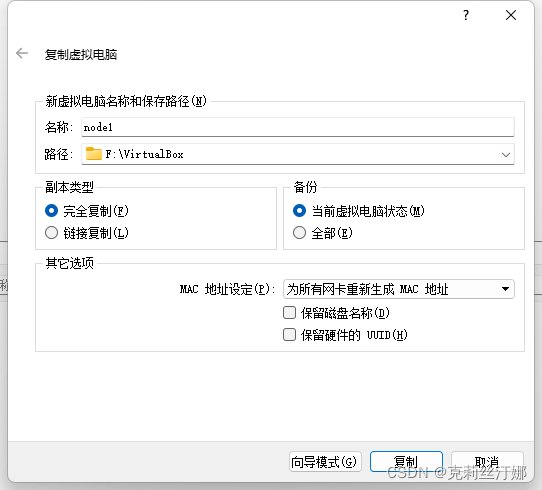
3、参照master主机和IP配置方法配置node1主机的主机名和IP
4、修改hdfs-site.xml配置:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property><!--DataNode的本地文件系统路径-->
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property><!--数据需要备份的数量,不能大于集群的机器数量,默认为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
5、重复上述步骤,复制出node2、node3主机
6、配置免密码访问:
在各个主机上执行如下命令(hduser用户下),生成SSH key:
ssh-keygen -t rsa
接着在任意一台主机(如master) 上执行:
cp /home/hduser/.ssh/id_rsa.pub /home/hduser/.ssh/authorized_keys
然后将其他主机上生成的id_rsa.pub中的内容拷贝到authorized_keys中,再将authorized_keys文件拷贝到其他主机上:
scp /home/hduser/.ssh/authorized_keys node1:/home/hduser/.ssh
scp /home/hduser/.ssh/authorized_keys node2:/home/hduser/.ssh
scp /home/hduser/.ssh/authorized_keys node3:/home/hduser/.ssh
7、启动Hadoop:
start-all.sh
8、创建历史日志目录
在HDFS上创建对应的历史日志目录
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
9、启动spark:
/opt/bigdata/spark-3.2.1-bin-hadoop3.2/sbin/start-all.sh
10、本地浏览器访问相关页面,看是否正常:
http://192.168.0.100:8088/cluster/nodes
http://192.168.0.100:50070/dfshealth.html#tab-datanode
http://192.168.0.100:8080/

