文章目录
pyspark写入数据
一、参数说明
官网通用的写数据方式如下:
DataFrameWriter.save(path=None, format=None, mode=None, partitionBy=None, **options)
或者也可将参数提至前面:
DataFrameWriter.format(source).save()
使用案例如下:
df.write.format('json').save(os.path.join(tempfile.mkdtemp(), 'data'))
各种写法相当灵活,具体参考后文。对于各种参数我们在此先做一个说明。
1.1 mode
DataFrameWriter.mode(saveMode)
saveMode指定数据的不同写入模式,一共有以下四种模式:
- append: 向已有数据文件或者数据表中追加写入数据,需保证数据列名一致。
- overwrite: 覆盖写入数据,如果数据表已经存在,则会先删除数据表,然后创建新表,再将数据写入。
- error or errorifexists: 如果数据已经存在则会报错。
- ignore: 如果数据已经存在则忽略本次操作。
1.2 format
DataFrameWriter.format(source)
source可以指定不同的格式,如:json, parquet, orc等。实际在写入hive数据表时,常使用orc格式。数据格式除了用format指定,也可以直接在点号后跟数据格式,如:df.write.json(path)。
1.3 partitionBy
DataFrameWriter.partitionBy(*cols)
指定列进行分区,实际工作中通常使用日期作为分区列。
1.4 bucketBy
DataFrameWriter.bucketBy(numBuckets, col, *cols)
指定分桶的数量和分桶依据的列。分桶表常见的使用是在数据抽样:
select id,name,age from test_bucket tablesample(bucket 1 out of 2 on age);
1.5 sortBy
DataFrameWriter.sortBy(col, *cols)
根据指定列,在每个分桶中进行排序。
1.6 option
DataFrameWriter.option(key, value)
DataFrameWriter.options(**options)
将前述介绍的各种参数用key-value的形式进行指定。
二、数据准备
我们先创建一个dataframe,如下所示:
value = [("alice", 18), ("bob", 19)]
df = spark.createDataFrame(value, ["name", "age"])
df.show()
+-----+---+
| name|age|
+-----+---+
|alice| 18|
| bob| 19|
+-----+---+
查看数据的分区情况:
print(df.rdd.getNumPartitions())
print(df.rdd.glom().collect())
结果为8个分区,未指定的情况下,默认使用了本地机器的CPU核数。
8
[[], [], [], [Row(name='alice', age=18)], [], [], [], [Row(name='bob', age=19)]]
为了让后续数据文件集中,方便查看,我们将数据进行重分区,分区数设定为1个,如下所示:
df = df.coalesce(1)
三、写入文件
3.1 csv文件
官网api接口:
DataFrameWriter.csv(path, mode=None, compression=None, sep=None, quote=None, escape=None, header=None, nullValue=None, escapeQuotes=None, quoteAll=None, dateFormat=None, timestampFormat=None, ignoreLeadingWhiteSpace=None, ignoreTrailingWhiteSpace=None, charToEscapeQuoteEscaping=None, encoding=None, emptyValue=None, lineSep=None)
简单的使用如下:
df.write.csv("../output/data_csv")
# 或者
df.write.format("csv").save("../output/data_csv")
生成的结果如下,一个csv文件,以及标志成功的文件和crc校验文件。
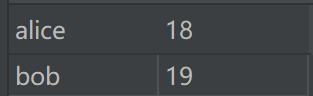
csv文件内容如下:
3.2 txt文件
DataFrameWriter.text(path, compression=None, lineSep=None)
需要注意官网有这么一句话:The DataFrame must have only one column that is of string type. Each row becomes a new line in the output file. 意思是写txt文件时dataframe只能有一列,而且必须是string类型。
使用如下:
value = [("alice",), ("bob",)]
df = spark.createDataFrame(value, schema="name: string")
df.show()
df = df.coalesce(1)
df.write.text("../output/data_txt")
结果如下:
alice
bob
3.3 json文件
DataFrameWriter.json(path, mode=None, compression=None, dateFormat=None, timestampFormat=None, lineSep=None, encoding=None, ignoreNullFields=None)[source]
使用如下:
df.write.json("../output/data_json")
# 或者
df.write.format("json").save("../output/data_json")
结果如下:

json数据文件的内容如下:
{"name":"alice","age":18}
{"name":"bob","age":19}
3.4 parquet文件
参考:parquet文件
官网api接口:
DataFrameWriter.parquet(path, mode=None, partitionBy=None, compression=None)
使用方式如下:
df.write.parquet("../output/data.parquet")
# 或者
df.write.format("parquet").save("../output/data.parquet")
生成的数据文件如下所示:

parquet文件内容如下(用Sublime打开):

也可以使用默认的save保存数据:
df.write.save("../output/data_default")
默认生成的文件格式为parquet,如下:

3.5 orc文件
参考:orc文件
DataFrameWriter.orc(path, mode=None, partitionBy=None, compression=None)
使用案例如下:
df.write.orc("../output/data_orc")
# 或者
df.write.format("orc").save("../output/data_orc")
结果如下:
orc文件中内容如下,与parquet的内容类似,也是采用二进制编码存储的。相同内容的数据,用orc文件明显比parquet文件占用的大小更小。本案例中,parquet文件664字节,而orc文件只有366字节。在实际工作中,我们一般选用orc格式保存数据。

四、写入数据表
4.1 api介绍
4.1.1 saveAsTable
DataFrameWriter.saveAsTable(name, format=None, mode=None, partitionBy=None, **options)
在实际工作中,这个api通常是结合hive来进行使用。spark配置好外部的hive,并开启hive的支持,则可以进行hive数据表的读写。
对于数据表的写入,如果是overwrite模式,则数据表会覆盖已有的表。如果是append模式,则会在原有数据表的基础上新增数据,且这种模式不需要指定列的顺序,dataframe会依据列名自动进行匹配数据列。官网有这么一段话可做参考:
Unlike
DataFrameWriter.insertInto(),DataFrameWriter.saveAsTable()will use the column names to find the correct column positions.
4.1.2 insertInto
DataFrameWriter.insertInto(tableName, overwrite=None)
insertInto在写入hive表时,不会按照列名插入数据,而只会按照数据列的顺序插入,因此在使用时尤其需要注意列的顺序不要发生变化。官网原话如下:
Unlike
DataFrameWriter.saveAsTable(),DataFrameWriter.insertInto()ignores the column names and just uses position-based resolution.
4.1.3 jdbc
DataFrameWriter.jdbc(url, table, mode=None, properties=None)
通过jdbc连接一个外部数据库并写入数据。需要注意的是不要一次写入太多分区,否则容易导致数据库崩溃。参考官网提示:
Don’t create too many partitions in parallel on a large cluster; otherwise Spark might crash your external database systems.
在工作中这种情况也可能碰到,比如将数据写入到mysql数据库中。
4.2 写入hive数据表
4.2.1 append
其实这种方式在实际工作中很少会用到,因为它无法保证数据不重复。举例来说,对于一张无分区表,如果是每天append追加数据,万一某一天数据写入一半出错了,重新写入前,必须手动把这部分数据删掉,徒增了工作量。而对于分区表来说,数据通常是按照分区表整个覆盖写入的,append方式行不通。
使用如下:
df.write.format("orc").mode("append").saveAsTable("db.tablename")
4.2.2 overwrite
overwrite通常是针对非分区表进行操作,每次写入数据前,会自动删除原表,然后依据新的数据列创建一个新表,然后再将数据写入。
使用如下:
df.write.format("orc").mode("overwrite").saveAsTable("db.tablename")
对于分区表则需要结合其他操作来执行数据写入。
4.2.3 分区表
参考链接:pyspark覆盖hive分区表
在第一次写入数据时,可以采用如下操作:
df.write.format("orc").mode("overwrite").partitionBy("part_col").saveAsTable("db.tablename")
part_col是指定用来进行分区的列,必须包含于dataframe中。初次写入的时候,会自动生成一个分区表。
第二次及后续写入数据时,我们通常会希望数据能按照分区进行覆盖写。比如某个分区的数据写入出错,或者需要重新往这个分区写入数据时,指定分区能够被覆盖掉。
这个时候如果还继续使用上面的方法写入数据,会发现整张数据表都被覆盖掉,显然这不是我们希望看到的。针对这个需求,可以采用如下方法写入数据:
df.write.format("orc").mode("overwrite").insertInto("db.tablename")
同时,需要配置参数:
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
需要注意的是dataframe数据的列顺序不能发生改变。
4.3 写入mysql数据表
参考链接:官网参考
url = "jdbc:mysql://IPaddress:3306/database"
driver = "com.mysql.jdbc.Driver"
user = "username"
passwd = "12345"
db = "database"
table = "tablename"
df.write.format("jdbc").mode("append")
.options(
url=url,
driver=driver,
user=user,
password=passwd,
dbtable=db + "." + table)
.save()
一个常规的写入mysql代码便是上述这样,IPaddress指定mysql服务器IP地址,database为数据库名,其他参数依次填入即可。
实际项目中,有可能会碰到编码的问题,也可以在写入数据的时候指定编码方式,如下:
database = "database"
url = "jdbc:mysql://IPaddress:3306/%s"%database
table = "tablename"
user = "username"
password = "12345"
df.write.format("jdbc").mode("append")
.option("url", url)
.option("useUnicode","true")
.option("characterEncoding","utf-8")
.option("dbtable", table)
.option("user", user)
.option("password", password)
.save()
或者将参数写在url中也可以:
database = "test"
url = "jdbc:mysql://IPaddress:3306/%s?useUnicode=true&characterEncoding=utf-8"%database
table = "t_1202"
user = "username"
password = "password"
df.write.format("jdbc").mode("append")
.option("url", url)
.option("dbtable", table)
.option("user", user)
.option("password", password)
.save()
如果是使用df.write.jdbc这个api,则可以用如下方式:
df_m.write.jdbc(
url="jdbc:mysql://172.10.2.70/nic"
"?user=username&password=passwd&useUnicode=true&characterEncoding=utf8",
mode="append",
table="tablename",
properties={"driver": 'com.mysql.jdbc.Driver'})
格式灵活多样,可根据需要选择。

