Redis缓存之String的滥用
在我们日常开发中如果使用Redis做缓存,那么使用最多的可能为String类型,String类型使用简单而且容易理解但这只是开发方面,如果业务数据量过大使用String类型存储可行性是否还是最高,我们可以依靠在线Redis内存预估统计工具http://www.redis.cn/redis_memory/如下统计
模拟1亿个String类型的键值对,key占用4个字节value占用4个字节,仅key,value占用内存800M,那Redis的String类型需要占用多少呢?如下所示
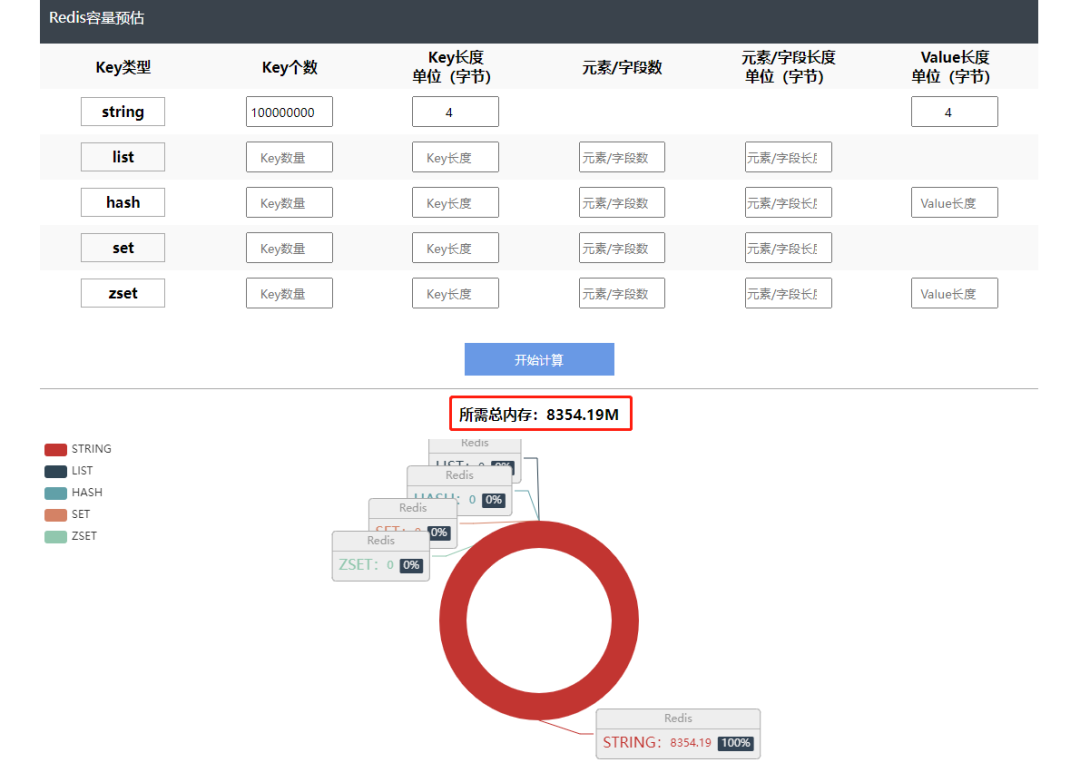
key和value单纯的内存消耗只占据了Redis的String类型所需总内存的十分之一,也是说有十分之九是存储其它信息,那到底是什么呢?如下分析。
简单动态字符串SDS
Redis使用的String类型底层实现就是SDS简单动态字符串,为什么Redis需要封装而不是c自带的字符串呢?
SDS的优势
-
SDS获取字符串的长度时间复杂度为O(1),而C语言自带的需要遍历数组时间复杂度为O(N)。
-
SDS有效避免缓冲区溢出(在长度不足时可以扩容)。
-
SDS可以减少修改字符串带来的内存分配(C语言字符串修改N次都需要重新分配内存,SDS最多需要重新分配N次内存)。
SDS结构
SDS底层结构从3.x到6.x版本变化挺大需要分开学习,3.x结构简单如下所示
typedef?char?*sds;
struct?sdshdr?{
????//?记录buf数组已使用的长度
????unsigned?int?len;
????
????//?记录buf数组没有使用的长度
????unsigned?int?free;
????
????//?字符串保存位置
????char?buf[];
};
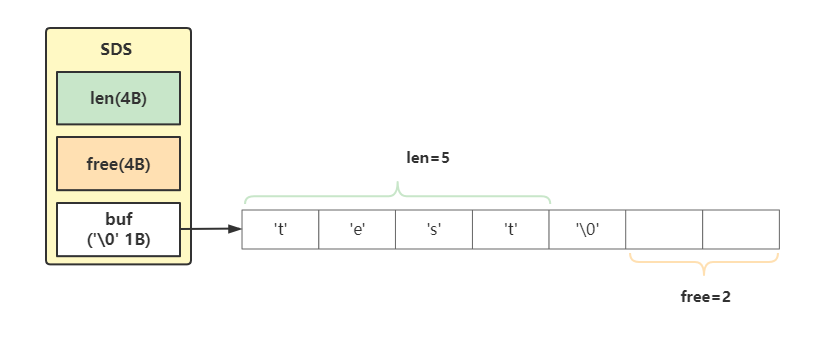
需要注意的是buf结尾是结束符’‘\0’是一定存在的,占用一个字节,但是在计算len时是不会计算结束标识符’\0’的。
6.x版本SDS结构代码如下所示
typedef?char?*sds;
/*?
?*?Note:?sdshdr5?is?never?used,?we?just?access?the?flags?byte?directly.
?*?However?is?here?to?document?the?layout?of?type?5?SDS?strings.?
?*?sdshdr5未使用,其余都有使用
?*/
struct?__attribute__?((__packed__))?sdshdr5?{
????unsigned?char?flags;?/*?3?lsb?of?type,?and?5?msb?of?string?length?*/
????char?buf[];
};
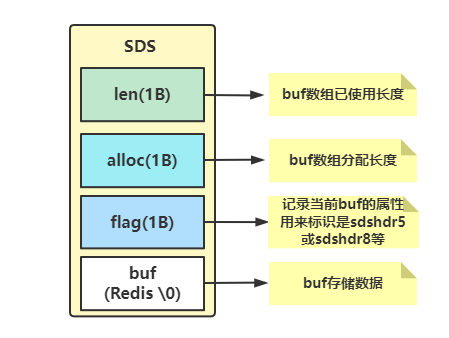
struct?__attribute__?((__packed__))?sdshdr8?{
????uint8_t?len;?/*?used??已使用长度*/
????uint8_t?alloc;?/*?分配长度?不包括报头和空终止符,1个字节存储?*/
????unsigned?char?flags;?/*?高3位存储、低5位预留?*/
????char?buf[];
};
struct?__attribute__?((__packed__))?sdshdr16?{
????uint16_t?len;?
????uint16_t?alloc;?/*?分配长度?不包括报头和空终止符,2个字节存储?*/
????unsigned?char?flags;?
????char?buf[];
};
struct?__attribute__?((__packed__))?sdshdr32?{
????uint32_t?len;?
????uint32_t?alloc;?/*?分配长度?不包括报头和空终止符,4个字节存储?*/
????unsigned?char?flags;?
????char?buf[];
};
struct?__attribute__?((__packed__))?sdshdr64?{
????uint64_t?len;?
????uint64_t?alloc;?/*?分配长度?不包括报头和空终止符,8个字节存储?*/
????unsigned?char?flags;?
????char?buf[];
};
结构图如下所示
RedisObject结构
Redis存在不同的数据类型,在这些不同的数据类型中又需要记录一些相同的信息如key最后访问时间、引用次数等所以需要将其封装为一个结构体(JAVA中的对象)来存储这些元素这就是RedisObject结构图如下所示。
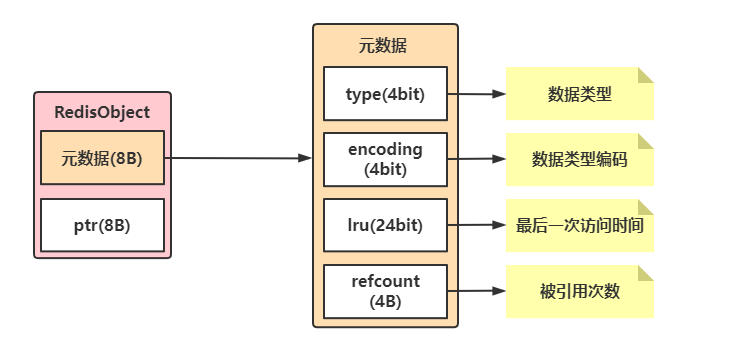
元数据type
元数据中的type为数据类型目前存在六种数据类型:string,hash,set,list,zset,stream可以通过命令type {key}获取类型
####?String类型
127.0.0.1:6379>?set?name?zhangsan
OK
127.0.0.1:6379>?type?name
string
####?List类型
127.0.0.1:6379>?lpush?keylist?1?zhangsan
(integer)?2
127.0.0.1:6379>?type?keylist
list
####??Hash类型
127.0.0.1:6379>?hmset?keyhash?name?zhangsan
OK
127.0.0.1:6379>?type?keyhash
hash
####??Set类型
127.0.0.1:6379>?sadd?keyset?name?zhangsan
(integer)?2
127.0.0.1:6379>?type?keyset
set
####??Sort?Set类型
127.0.0.1:6379>?zadd?keyzset?1?zhangsan
(integer)?1
127.0.0.1:6379>?type?keyzset
zset
####??Bitmaps?类型
127.0.0.1:6379>?setbit?keybitmap?10?1
(integer)?0
127.0.0.1:6379>?type?keybitmap
string
####??Hyperloglogs类型?
127.0.0.1:6379>?pfadd?keyhyperloglogs?2?23?42?2
(integer)?1
127.0.0.1:6379>?type?keyhyperloglogs
string
####??Geospatial类型
127.0.0.1:6379>?geoadd?keygeo?13.361389?38.115556?test
(integer)?1
127.0.0.1:6379>?type?keygeo
zset
####??Stream类型
127.0.0.1:6379>?xadd?keystream?*?name?zhangsan
"1650552771376-0"
127.0.0.1:6379>?type?keystream
stream
元数据encoding
encoding表示当前value值的编码格式有三种int、embstr、raw,可以通过命令object encoding key获取
####??如果值是数字编码类型就是int
127.0.0.1:6379>?set?name?1
OK
127.0.0.1:6379>?object?encoding?name
"int"
####?如果值是字符串同时长度小于等于44那么就是embstr
127.0.0.1:6379>?set?name1?"zhangsan"
OK
127.0.0.1:6379>?object?encoding?name1
"embstr"
####?如果值是字符串同时长度大于44
127.0.0.1:6379>?set?name2?"qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq"
OK
127.0.0.1:6379>?object?encoding?name2
"raw"
元数据refcount
refcount为被引用对象,当refcount=0表示可回收对象,可以通过命令refcount key查看引用次数。
RedisObject指针ptr
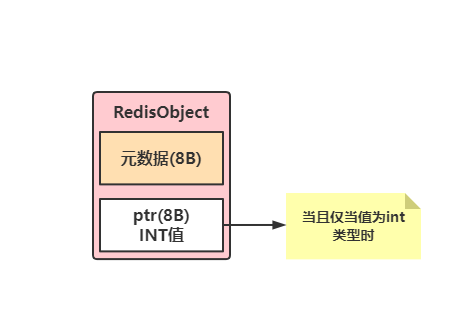
如果值的类型为int,那么ptr直接存储的就是这个int类型的值,不会去指向其它内存地址,如下所示。
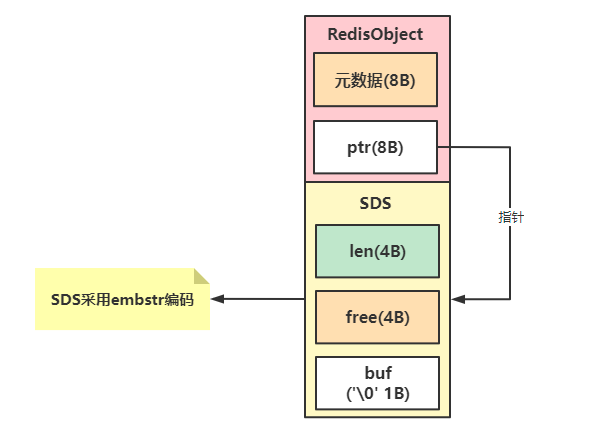
当值为字符串类型,同时字符串的长度小于等于44时,数据采用embstr编码格式编码,将RedisObject对象的元数据、指针、SDS分配到一片连续的内存空间,避免内存碎片。
为什么字符串长度需要小于等于44呢?
在CPU缓存行为64字节,而元数据占8字节、指针占8字节,SDS分两种情况
1、如果是6.x版本SDS其它内存消耗4个字节(1B(len)+1B(alloc)+1B(flag)+1B(‘\0’))所以是64-8-8-4=44。
2、如果是3.x版本SDS其它内存消耗9个字节(4B(len)+4B(free)+1B(‘\0’))所以是64-8-8-9=39。
版本不同编码格式判断的临界值会有稍微不同。
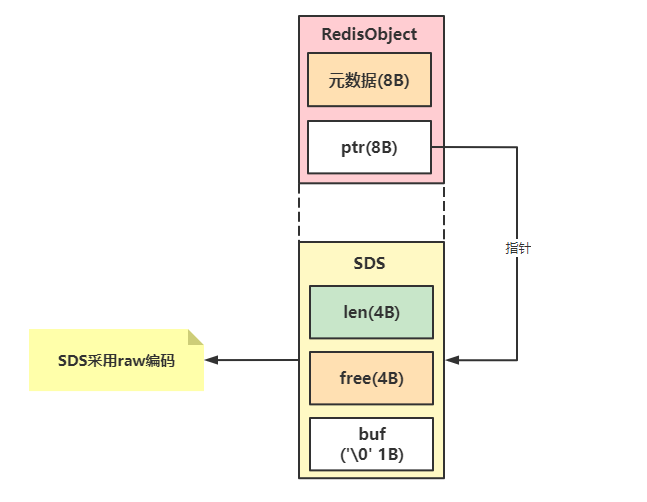
当值是字符串但是长度大于44时,编码格式变为raw,SDS和RedisObject的内存分配不再连续,SDS内存空间将独立分配,如下所示。
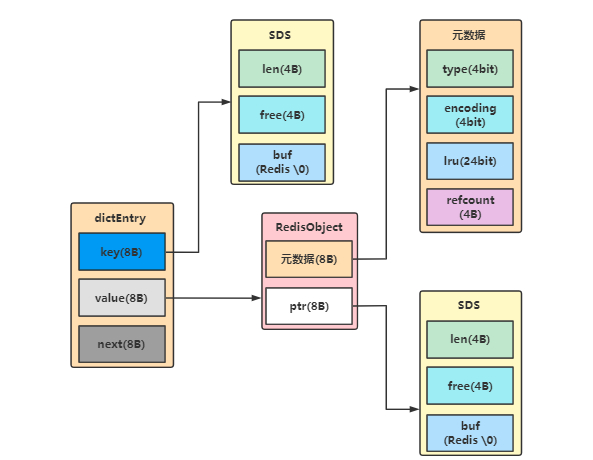
dictEntry结构
那么除了SDS动态字符串和RedisObject结构,一个简单的String操作还会涉及到哪些内存分配呢?当然是有的那就是哈希桶中的元素dictEntry,dictEntry中包含key、value、next等值如下所示。
总结
String使用虽然简单但不是万金油哪里都能使用,在数据量大的时候我们需要选择合适的数据结构来避免这种情况的发生,如list、set、sort set、hash等这些数据结构就能节省dictEntry所需要的内存,下面以6.x版本演示如下所示( info memory可以查看内存使用情况)。
#########################hash集合类型#############################
127.0.0.1:6379>?info?memory
#?Memory
used_memory:866600
127.0.0.1:6379>?hset?obj?name?zhangsan
(integer)?1
127.0.0.1:6379>?info?memory
#?Memory???第一次创建hash结构需要?消耗80字节
used_memory:866680
127.0.0.1:6379>?hset?obj?addr?beijin
(integer)?1
127.0.0.1:6379>?info?memory
#?Memory????后续在hash结构中加入属性??只消耗16字节
used_memory:866696
#########################String类型###############################
127.0.0.1:6379>?info?memory
#?Memory
used_memory:866720
127.0.0.1:6379>?set?teststr?zhangsan
OK
127.0.0.1:6379>?info?memory
#?Memory??消耗72字节
used_memory:866792
127.0.0.1:6379>?set?teststr1?zhangsan
OK
127.0.0.1:6379>?info?memory
#?Memory??消耗72字节
used_memory:866864
如果开发中需要存储业务数据到Redis中,对数据类型的选择一定要慎重,一味的滥用String在数据量大时对Redis的负担将是巨大的,会影响RDB持久化、故障转移、主从同步等。

