hadoopЮБЗжВМЪНХфжУКЭАВзА
АВзАЛЗОГ:Centos7.5,жСЩй2КЫ4GФкДц
ЬсЧАзМБИ:LinuxжавЊАВзАjdk1.8,Zookeeper-3.5.8
1.ЙиБеЗРЛ№ЧН:
systemctl stop firewalld
systemctl disable firewalld
2.аоИФжїЛњУћ
vim /etc/hostname
ЩОГ§дРДЕФжїЛњУћ,ЬэМгздМКЕФжїЛњУћ
Р§Шч:hadoop01
3.ашвЊНЋжїЛњУћКЭIPНјаагГЩф
vim /etc/hosts
ЬэМгЕБЧАЕФжїЛњУћIP жїЛњУћ,Р§Шч
192.168.112.128 hadoop01
4.ЙиБеSELINUX
vim /etc/selinux/config
НЋSELINUXЪєадЕФжЕИФЮЊdisabled
5.жиЦє
reboot
6.ХфжУУтУмЕЧТМ
ssh-keyen
ssh-copy-id
ЪфШыжїЛњЕФУмТы
ВтЪдЪЧЗёУтУмГЩЙІ:ssh hadoop01
ШчЙћВЛашвЊУмТы,ФЧУДЫЕУїУтУмГЩЙІ,ЪфШыlogoutЭЫГі
7.ЯТдиhadoop
ЯТдиЕижЗ:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
ЗХШы/home/softwareФПТМЯТВЂНтбЙ
tar -xvf hadoop-3.1.3.tar.gz
8.НјШыhadoopЕФХфжУЮФМўФПТМ
cd /home/software/hadoop-3.1.3/etc/hadoop
9.БрМЮФМў
vim hadoop-env.sh
дкЮФМўжаЬэМг:
export JAVA_HOME=/home/software/jdk1.8.0_321
БЃДцЭЫГі,жиаТЩњаЇетИіЮФМў
source hadoop-env.sh
10.БрМЮФМў
vim core-site.xml
дкЮФМўжаБъЧЉФкЬэМг:
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-3.1.3/tmp</value>
</property>
11.БрМЮФМў
vim hdfs-site.xml
дкЮФМўжаБъЧЉФкЬэМг:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
12.БрМЮФМў
vim mapred-site.xml
дкЮФМўжаБъЧЉФкЬэМг:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
13.БрМЮФМў
vim yarn-site.xml
дкЮФМўжаБъЧЉФкЬэМг:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
14.БрМЮФМў
vim workers-----зЂвт,ШчЙћЪЧдкhadoop2.X,ФЧУДетИіЮФМўЪЧslaves
НЋдРДЕФlocalhostЩОГ§Еє,ШЛКѓЬэМгЕБЧАжїЛњЕФжїЛњУћ
15.ХфжУЛЗОГБфСП
vim /etc/profile
дкЮФМўФЉЮВЬэМг
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
БЃДцЭЫГі,ЩњаЇетИіЮФМў
source /etc/profile
ЭЈЙ§hadoop versionУќСюРДШЗЖЈХфжУЪЧЗёгааЇ

16.ЕквЛДЮЦєЖЏHadoopжЎЧА,ашвЊЯШНјвЛДЮИёЪНЛЏ
hadoop namenode -format
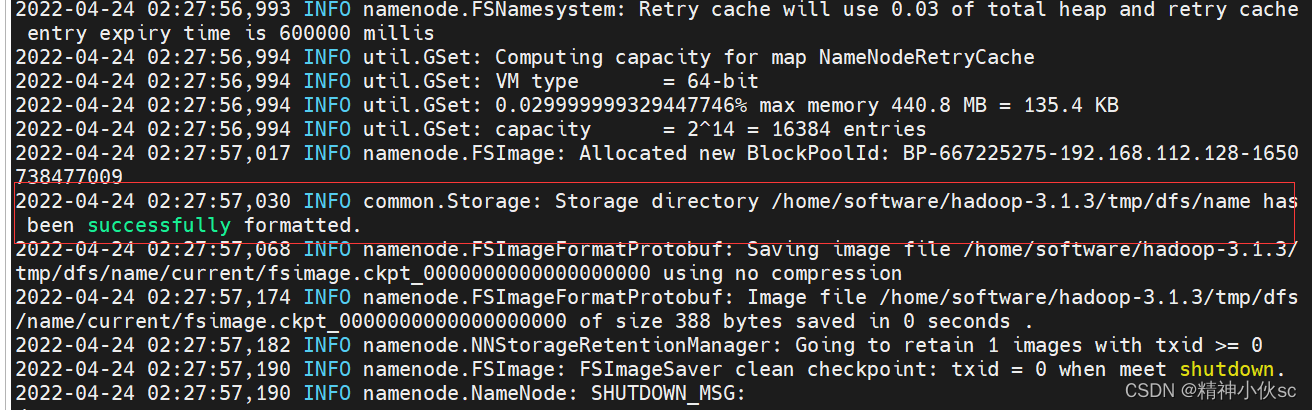
ГіЯжЭМжаетОфЛАБэЪОГЩЙІ
17.НјШыHadoopАВзАФПТМЯТЕФзгФПТМsbinЯТ
cd /home/software/hadoop-3.1.3/sbin
18.БрМЮФМў
vim start-dfs.sh
дкЮФМўЭЗВПМгШы
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
19.ЦєЖЏHDFS
start-dfs.sh
ЭЈЙ§jpsВщПДЖрГіШчЯТЭМШ§ИіНјГЬ
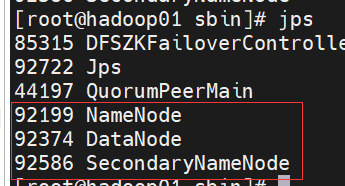
20.БрМЮФМў
vim start-yarn.sh
дкЮФМўЭЗВПМгШы
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
21.ЦєЖЏyarn
start-yarn.sh
ЭЈЙ§jpsВщПДЖрГіШчЯТЭМСНИіНјГЬ
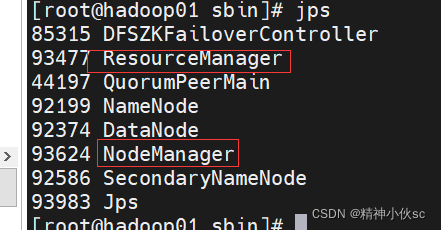
22.ЦєЖЏжЎКѓ:ЬсЙЉСЫПЩЪгЛЏвГУцРДНјааВщПД,ашвЊЭЈЙ§IP:portЕФаЮЪНВщПД
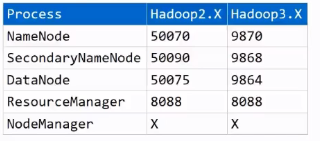
ЂйNameNodeвГУцЗУЮЪ
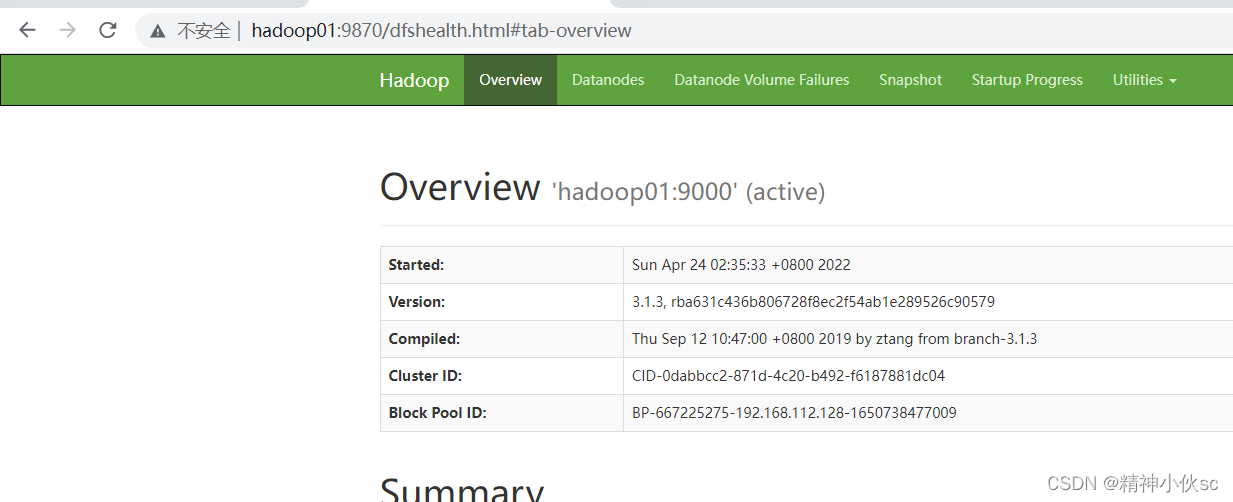
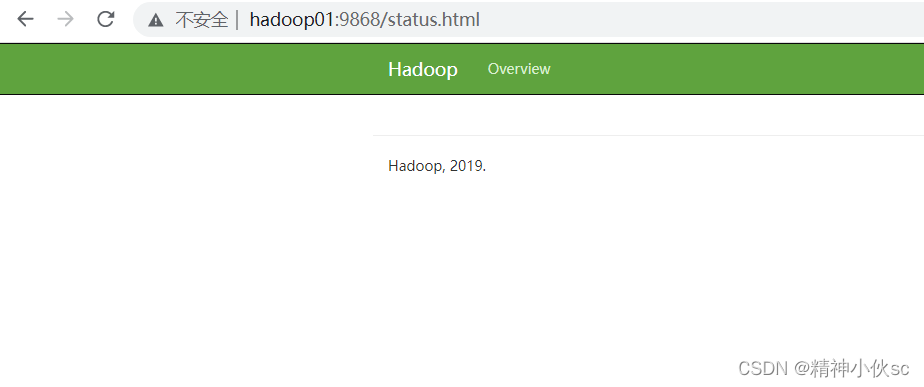
ЂкSecondaryNameNodeвГУцЗУЮЪ
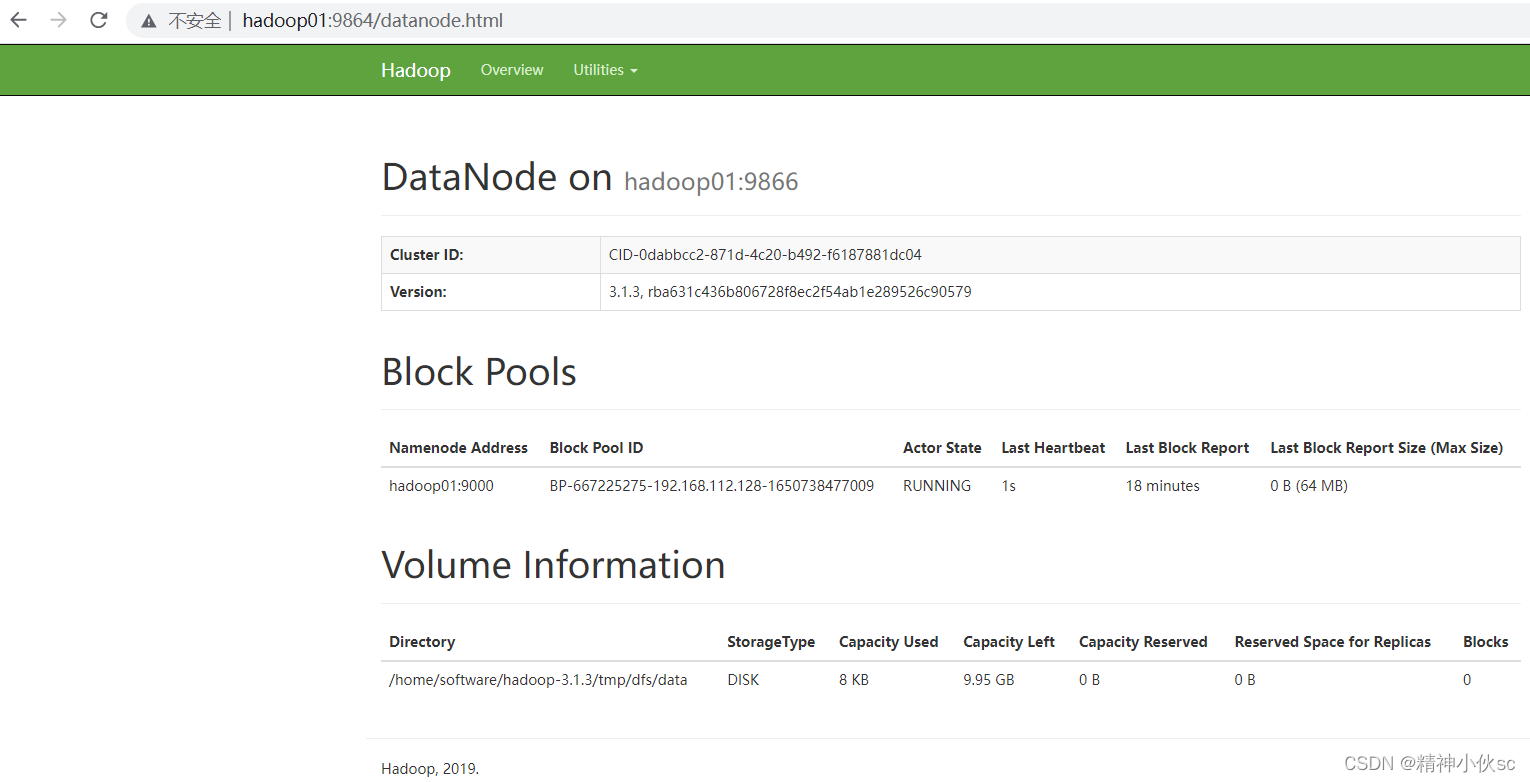
ЂлDataNodeвГУцЗУЮЪ
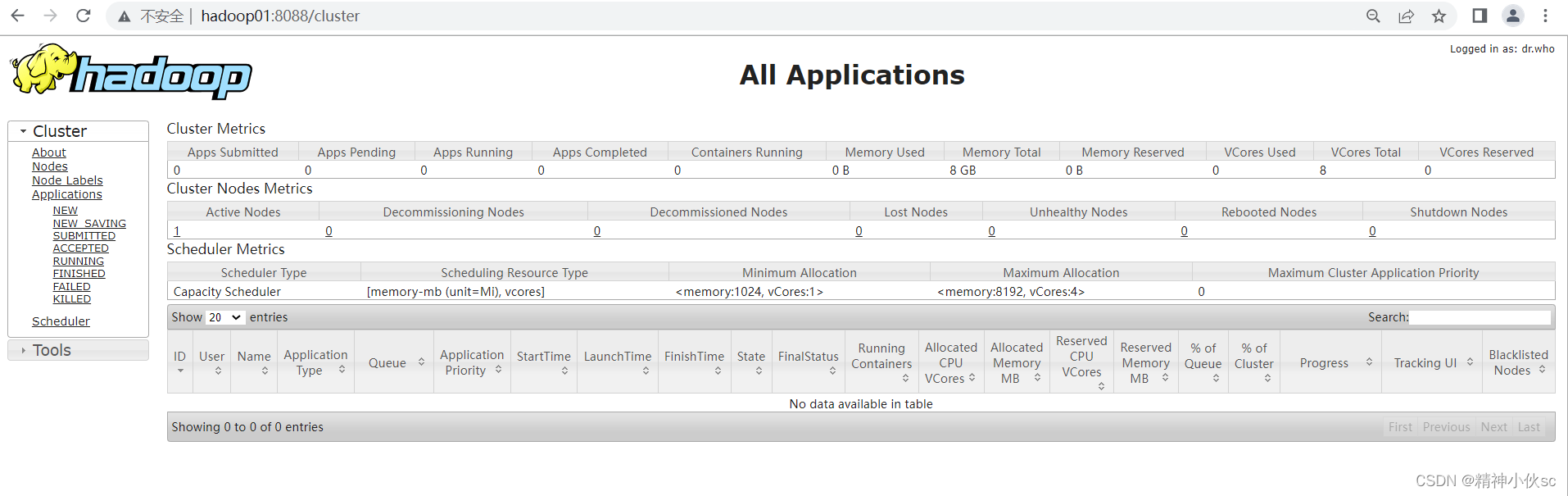
ЂмResourceManagerвГУцЗУЮЪ
ЂнNdeManagerУЛгавГУц,ВЛЖдЭтНчЗУЮЪ

