����Ŀ¼
һ��ELKǰ��
1.1 ��Ҫ�ռ�����־
-
ϵͳ��־:Ϊ�������,Ҫ�ռ�tomcatϵͳ��־,tomcat���ڽڵ����־
-
������־:�������ݿ�mysql,�ռ�����ѯ��־��������־����ͨ��־,Ҫ�ռ�tomcat������־��
-
ҵ����־(ҵ����־�����ռ�):ҵ�������־��log4j,log4j����java����������,����tomcat��
1.2 ��־�ռ���,��ο��ӻ�
-
kibana
-
grafana:�����Ե�ͼ�ķ�ʽչʾ,���ܸ�ȫ��һЩ,�����ÿ�һЩ
1.3 ��־�ռ����ӻ���,��ôʹ��
-
���ڸ������ݷ���,��Ϊ���廯չʾ��һ������Դ
-
���з�ȥʹ��(���ϡ����bug��)
-
ͳ����������,��Ϊ�������������Դ
1.4 Ҫ��ô�ռ���־
������Ҫ������Ե�ȥ�ռ���־,��־�ռ��Ǹ����������õ���־����������,���ڲ��Ǻ���Ҫ����־,��־�������һ�㡣����error��ʱ����,��ͨ��־���ñ�������������Ч������־����������ҵ����־,���Dz��ʺϵ�error����,������Ҫ����warning����
����ELK���
2.1 ElasticSearch����
Elasticsearch��һ������ Lucene �����������������ṩ��һ���ֲ�ʽ���û�������ȫ����������,����RESTful web�ӿڡ�Elasticsearch����Java������,����ΪApache���������µĿ���Դ�뷢��,�ǵڶ����е���ҵ�������档��������Ƽ�����,�ܹ��ﵽʵʱ����,�ȶ�,����,��װʹ�÷��������
2.2 ElasticSearch���ĸ���
- �ӽ�ʵʱ
ElasticSearch��һ���ӽ�ʵʱ������ƽ̨
�����˵,���Ǵ�����һ���ĵ�ֱ������ĵ��ܹ�����������һ�������ӳ�(ͨ����1��)
- ��Ⱥ��
��Ⱥÿһ̨�����������Լ���һ��Ψһ��ʶ,����˵id,��ʶ�Լ��ڼ�Ⱥ�е�һ����λ��
����Ⱥ������һ�������ڵ���֯��һ��,���ǹ�ͬ����������������,��һ���ṩ�������������ܡ�����һ���ڵ�Ϊ���ڵ�,������ڵ��ǿ���ͨ��ѡ�ٲ�����,���ṩ��ڵ�����������������Ĺ��ܡ�
- �ڵ�
�ڵ����һ̨��һ�ķ�����,�Ǽ�Ⱥ��һ����,�洢���ݲ����뼯Ⱥ���������������ܡ���Ⱥһ��,�ڵ�Ҳ��ͨ����������ʶ,Ĭ�����ڽڵ�����ʱ���������ַ�������Ȼ,������Լ����塣������Ҳ����Ҫ,�ڼ�Ⱥ������ʶ���������Ӧ�Ľڵ㡣
- ����
һ����������һ��ӵ�м��������������ĵ��ļ��ϡ�����˵,�������һ���ͻ����ݵ�����,��һ����Ʒ��¼������,����һ���������ݵ�������һ��������һ����������ʶ(����ȫ����Сд��ĸ��),���ҵ�����Ҫ�Զ�Ӧ����������е��ĵ��������������������º�ɾ����ʱ��Ҫʹ�õ�������֡���һ����Ⱥ��,�������,���Զ���������������
- ����
��һ��������,����Զ���һ�ֻ�������͡�һ�����������������һ����.�ϵķ���/����,��������ȫ����������ͨ��,��Ϊ����һ�鹲ͬ�ֶε��ĵ�����һ�����͡�����˵,���Ǽ�������Ӫһ������ƽ̨���ҽ������е����ݴ洢��һ�������С������������,�����Ϊ�û����ݶ���һ������,Ϊ�������ݶ�����һ������,��Ȼ,Ҳ����Ϊ�������ݶ�����һ�����͡�
- �ĵ�
һ���ĵ���һ���ɱ������Ļ�����Ϣ��Ԫ������,�����ӵ��ijһ���ͻ����ĵ�,ijһ����Ʒ��һ���ĵ�,��Ȼ,Ҳ����ӵ��ij��������һ���ĵ����ĵ���JSON ��ʽ����ʾ,��JSON��һ���������ڵĻ��������ݽ�����ʽ�� ��һ��index/type����,ֻҪ����,����Դ洢�������ĵ���ע��,��Ȼһ���ĵ���������λ��һ��������,ʵ����һ���ĵ�������һ�������ڱ������ͷ���һ�����͡�
- ��Ƭ����(Ĭ���������5����Ƭ��1������,����ζ��,�����ļ�Ⱥ�����������ڵ�,�������������5����Ƭ������5������,)
�����������,�����ڵ�Ĵ洢�������Լ�I/O��дЧ���Ǻ���������ƿ���ġ�Ϊ�����ƿ������,����������,���ڴ洢����һ���ֲ�ʽ,����ڵ���һ����������ߴ洢����,���������������,ͬʱ���Լ���ѹ����̯��
elasticsearch�ṩ�������ֳɶ����Ƭ�Ĺ��ܡ����ڴ�������ʱ,���Զ�����Ҫ��Ƭ��������ÿһ����Ƭ����һ��ȫ���ܵĶ���������,����λ�ڼ�Ⱥ���κνڵ��ϡ�
-
��Ƭ����������Ҫԭ��:
(1)ˮƽ�ָ���չ,����洢��
(3)�ֲ�ʽ���п��Ƭ����,������ܺ������� -
�ֲ�ʽ��Ƭ�Ļ��ƺ�����������ĵ���λ�����ȫ����elasticsearch���Ƶ�,��Щ���û����������ġ�
-
��������ȵ���������������κ�ʱ���ڶ���,Ϊ�˽�׳��,ǿ�ҽ���Ҫ��һ�������л�����,���ۺ��ֹ����Է�ֹ��Ƭ���߽ڵ㲻���á�
-
����Ҳ����������Ҫԭ��:
(1)�߿�����,��Ӧ�Է�Ƭ���߽ڵ���ϡ��������ԭ��,��Ƭ����Ҫ�ڲ�ͬ�Ľڵ��ϡ�
(2)�����˶�д����(qps����),�������������������Բ��������и�����ִ�С�
2.2 ELK�����������
Logstash(��־�ռ�):��Ҫ�����ռ����������ʽ������
Elasticsearch(��־�洢������):���ڽ�������,��Ϊ���ĸ����ͷ�Ƭ,��������������ǿ��
PS:(ES�汾 7.10 �� 7.20),������:����ʱ,����Ϊ��root�û���es����ʱ�ܳ��ڴ�,���ܻῨ�ܾá�
Kibana(չʾ):��Ϊչʾ�õ�,չʾ�Ļ�������־�ռ�����es������������,�������kibana,ͨ��kibanaչ�ֳ��������ļ������ر�á�
2.3 ELK�Ĺ���ԭ��
-
��������Ҫ�ռ���־�ķ������ϲ���Logstash; �����Ƚ���־���м��л���������־��������, ����־�������ϲ��� Logs tash��
-
Logstash �ռ���־,����־��ʽ��������� Elasticsearch Ⱥ���С�
-
Elasticsearch �Ը�ʽ��������ݽ��������ʹ洢��
-
Kibana �� ES Ⱥ���в�ѯ��������ͼ��,������ǰ�����ݵ�չʾ��
���� ELK��־����ϵͳ��Ⱥ����
����:
���������� ϵͳ��IP��ַ ��Ҫ��װ����� Ӳ������
Node1�ڵ� CentOS7 192.168.24.20 Elasticsearch �� Kibana 2��4G
Node2�ڵ� CentOS7 192.168.24.30 Elasticsearch 2��4G
Apache�ڵ� CentOS7 192.168.24.40 Logstash Apache 2��4G
3.1 ELK Elasticsearch ��Ⱥ����(��Node1��Node2�ڵ��ϲ���)
3.1.1 ǰ����
#����������
Node1�ڵ�: hostnamectl set-hostname node1
Node2�ڵ�: hostnamectl set-hostname node2
Apache�ڵ�: hostnamectl set-hostname httpd
#������������
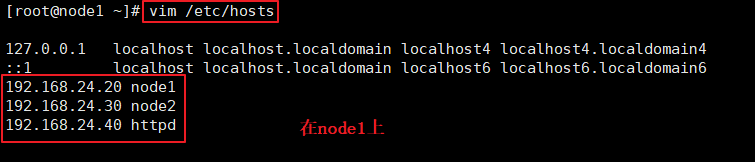
vim /etc/hosts
192.168.24.20 node1
192.168.24.30 node2
192.168.24.40 httpd
#�鿴Java����,���û�а�װ,yum -y install java
java -version
#����������



#������������

#�鿴Java����


3.1.2 ���� Elasticsearch ����
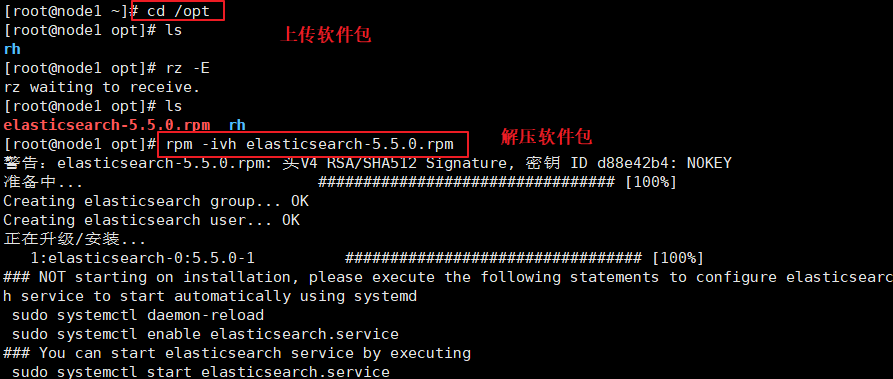
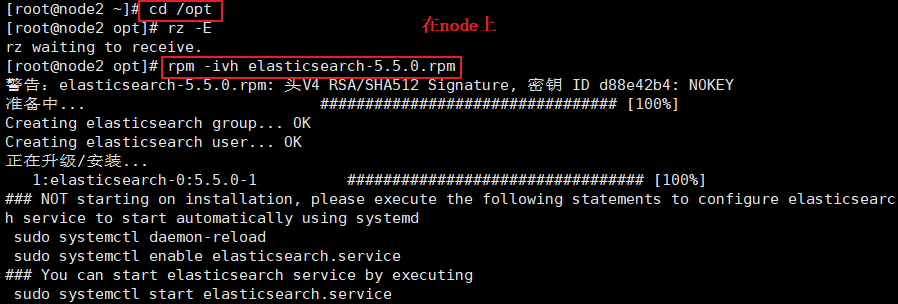
(1)#�ϴ�elasticsearch-5.5.0.rpm��/optĿ¼��
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm
(2)#����ϵͳ����
systemctl daemon-reload
systemctl enable elasticsearch.service
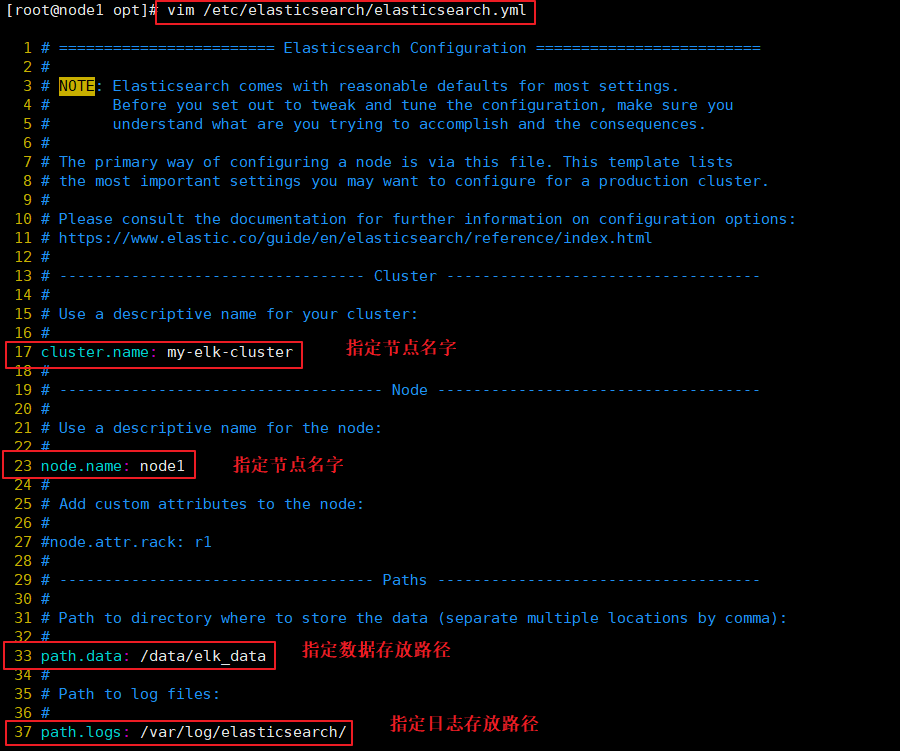
(3)#��elasticsearch�������ļ�
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
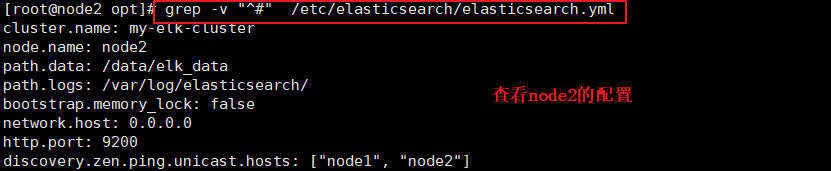
vim /etc/elasticsearch/elasticsearch.yml
--17--ȡ��ע��,ָ����Ⱥ����
cluster.name: my-elk-cluster
--23--ȡ��ע��,ָ���ڵ�����:Node1�ڵ�Ϊnode1,Node2�ڵ�Ϊnode2
node.name: node1
--33--ȡ��ע��,ָ�����ݴ��·��
path.data: /data/elk_data
--37--ȡ��ע��,ָ����־���·��
path.logs: /var/log/elasticsearch/
--43--ȡ��ע��,��Ϊ��������ʱ�������ڴ�
bootstrap.memory_lock: false
--55--ȡ��ע��,���ü�����ַ,0.0.0.0�������е�ַ
network.host: 0.0.0.0
--59--ȡ��ע��,ES �����Ĭ�ϼ����˿�Ϊ9200
http.port: 9200
--68--ȡ��ע��,��Ⱥ����ͨ������ʵ��,ָ��Ҫ���ֵĽڵ� node1��node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
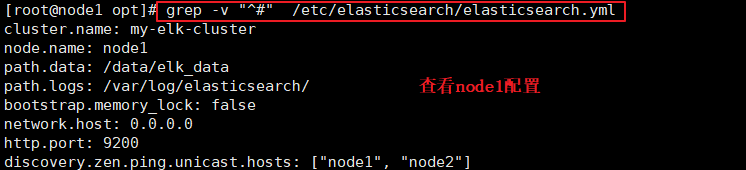
#�鿴�������ļ�
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
###node2��������node1��ͬ#######
(4)#�������ݴ��·������Ȩ
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
(5)#����elasticsearch�Ƿ�ɹ�����
systemctl start elasticsearch.service
netstat -antp | grep 9200
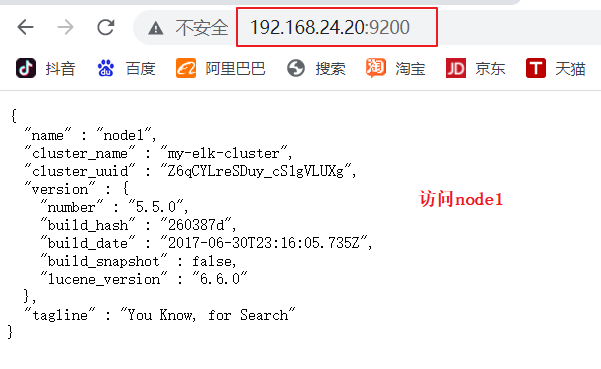
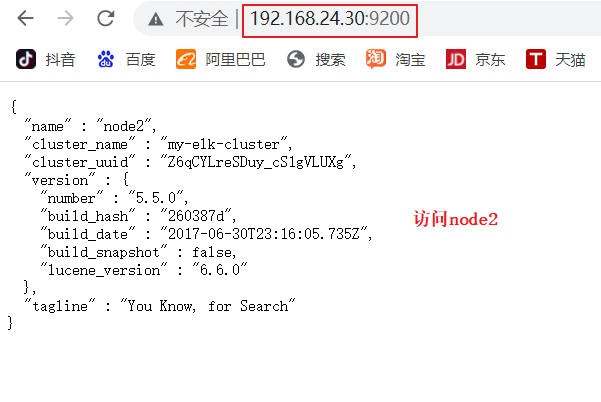
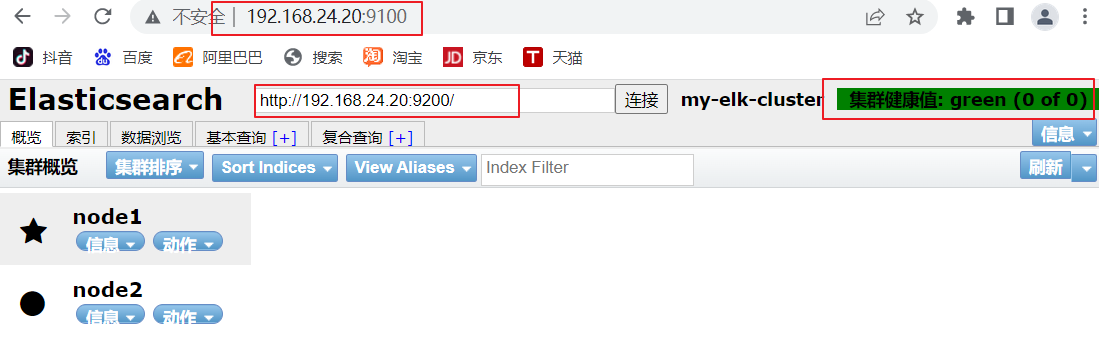
(6)#�鿴�ڵ���Ϣ
��������� ,�鿴�ڵ� Node1��Node2 ����Ϣ
http://192.168.24.20:9200 http://192.168.24.30:9200
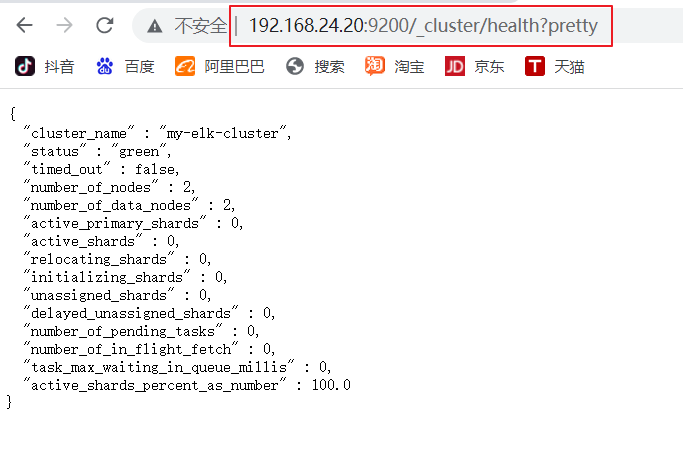
#ԭ��ɫ:green
http://192.168.24.20:9200/_cluster/health?pretty
http://192.168.24.30:9200/_cluster/health?pretty
#�ϴ�elasticsearch-5.5.0.rpm��/optĿ¼��
#����ϵͳ����


#��elasticsearch�������ļ�
��node1�ϵ������ļ�:

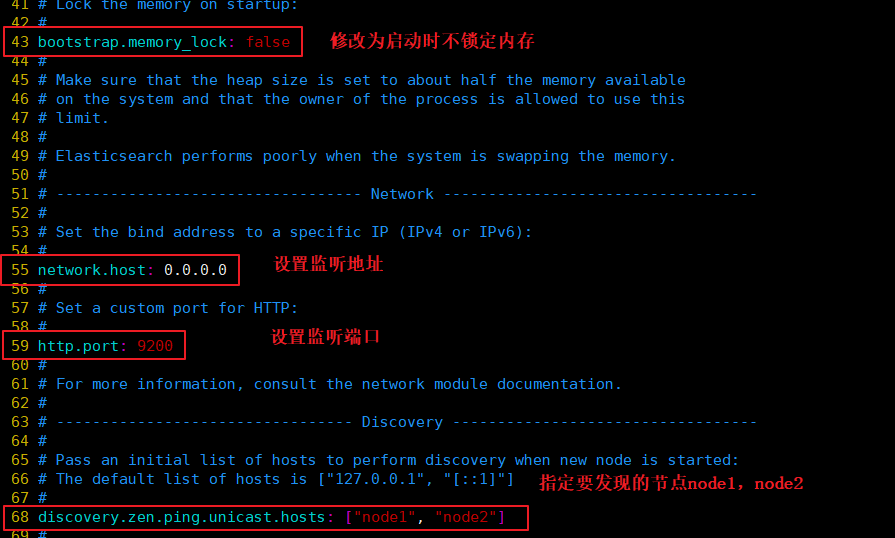
#��node2�ϵ������ļ�:

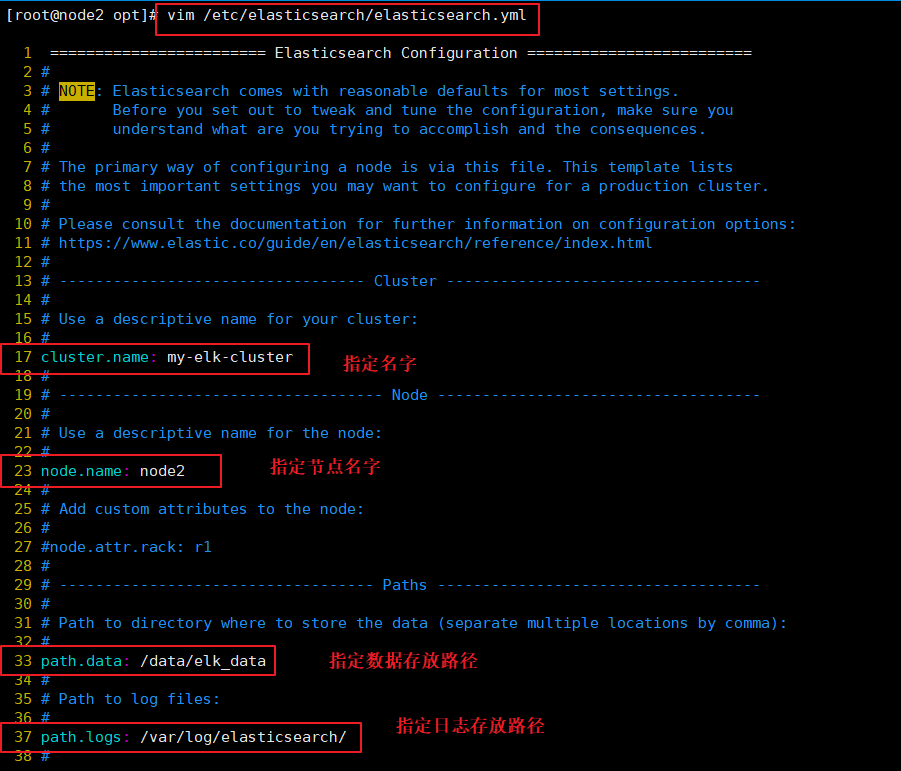
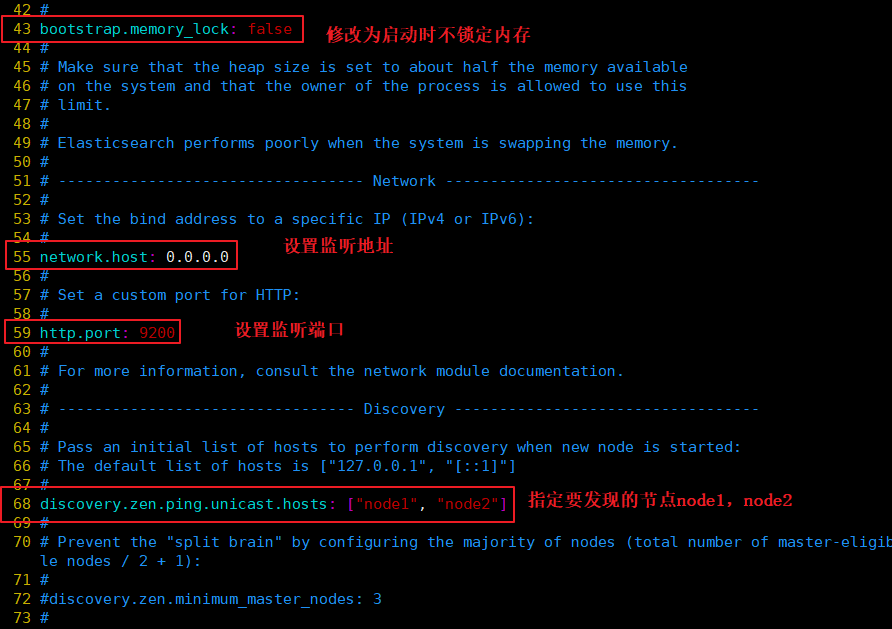
#�������ݴ��·������Ȩ


#����elasticsearch�Ƿ�ɹ�����


#�鿴�ڵ���Ϣ
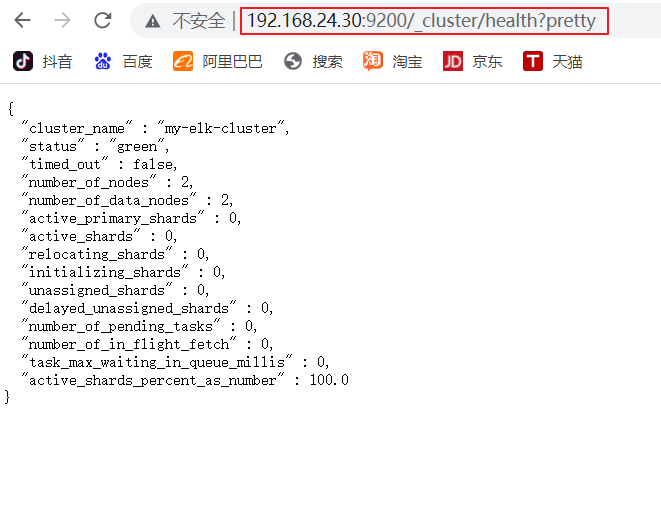
#���Ⱥ��״̬��Ϣ
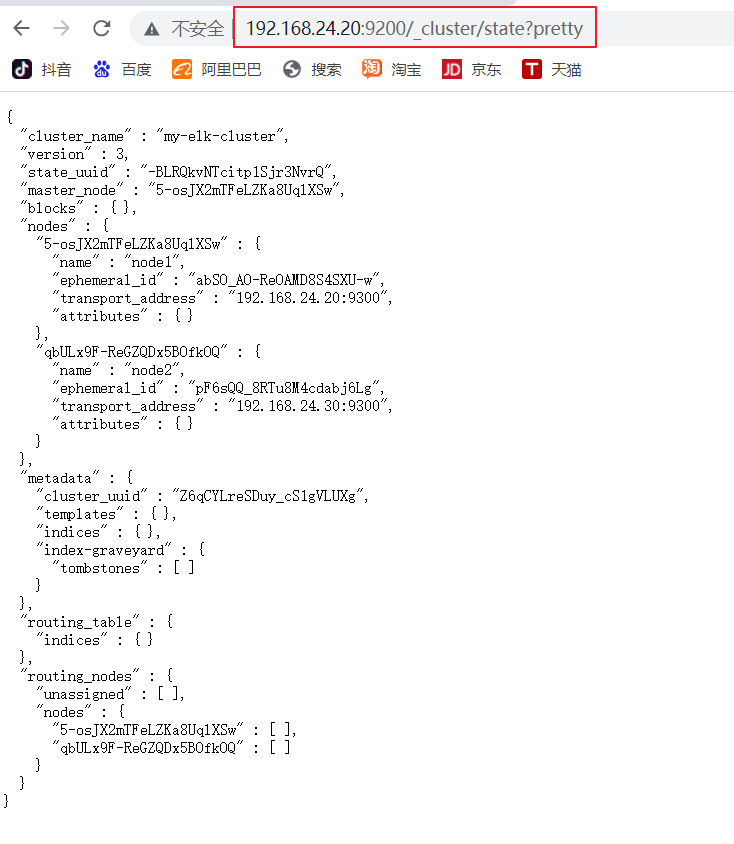

3.1.3 ��װ Elasticsearch-head ���
- Elasticsearch �� 5.0 �汾��,Elasticsearch-head �����Ҫ��Ϊ����������а�װ,��Ҫʹ��npm����(NodeJS�İ���������)��װ��
- ��װ Elasticsearch-head ��Ҫ��ǰ��װ���������� node �� phantomjs��
(1) node:��һ������ Chrome V8 ����� JavaScript ���л�����
(2) phantomjs:��һ������ webkit ��JavaScriptAPI,��������Ϊһ�����ε������,�κλ��� webkit �������������,��������������
(1)#���밲װ node
#�ϴ������� node-v8.2.1.tar.gz ��/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make -j4 && make install
(2)#��װ phantomjs
#�ϴ������� phantomjs-2.1.1-linux-x86_64.tar.bz2 ��
cd /opt
tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
(3)#��װ Elasticsearch-head ���ݿ��ӻ�����
#�ϴ������� elasticsearch-head.tar.gz ��/opt
cd /opt
tar zxf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
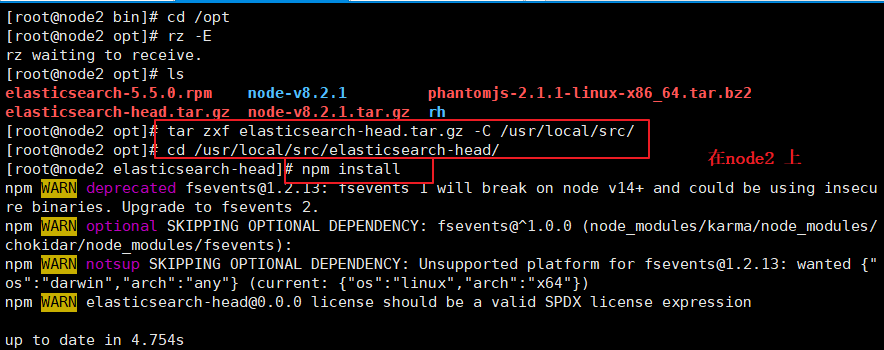
(4)#�� Elasticsearch �������ļ�
vim /etc/elasticsearch/elasticsearch.yml
......
--ĩβ������������--
http.cors.enabled: true #�����������֧��,Ĭ��Ϊ false
http.cors.allow-origin: "*" #ָ���������������������ַΪ����
systemctl restart elasticsearch
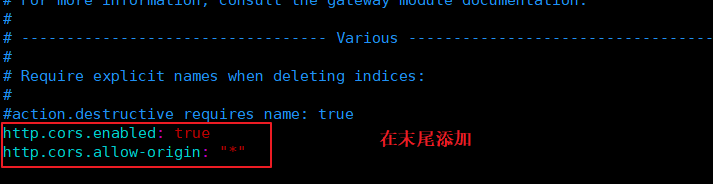
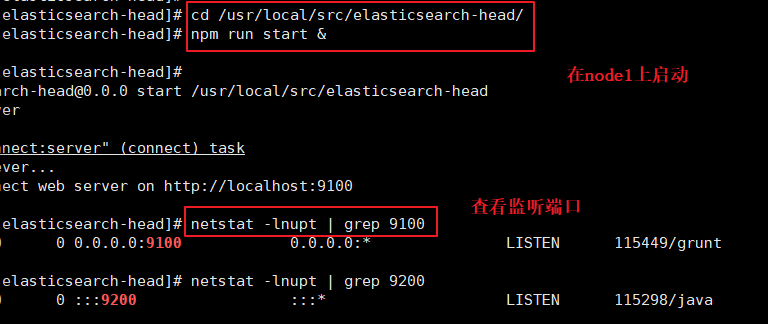
(5)#���� elasticsearch-head ����
#�����ڽ�ѹ��� elasticsearch-head Ŀ¼����������,���̻��ȡ��Ŀ¼�µ� gruntfile.js �ļ�,�����������ʧ�ܡ�
cd /usr/local/src/elasticsearch-head/
npm run start &
#elasticsearch-head �����Ķ˿��� 9100
netstat -lnutp | grep 9100
netstat -lnutp | grep 9200
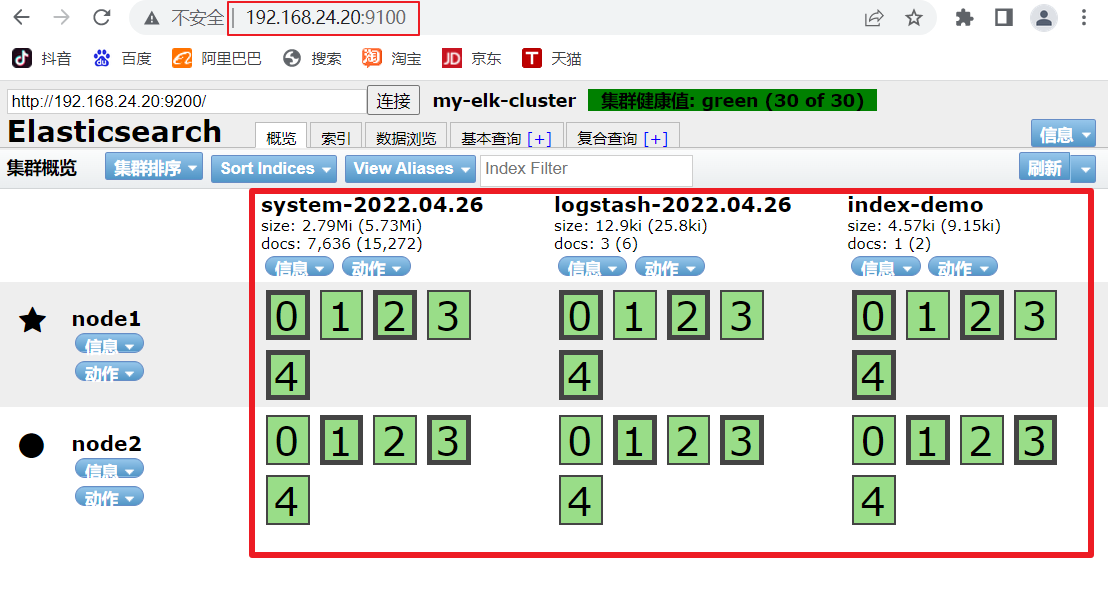
(6)#ͨ�� Elasticsearch-head �鿴 Elasticsearch ��Ϣͨ����������� http://192.168.24.20:9100/ ��ַ������Ⱥ�����������Ⱥ������ֵΪ green ��ɫ,����Ⱥ���ܽ��������������� ���Խ�localhost �ij�ip��ַ
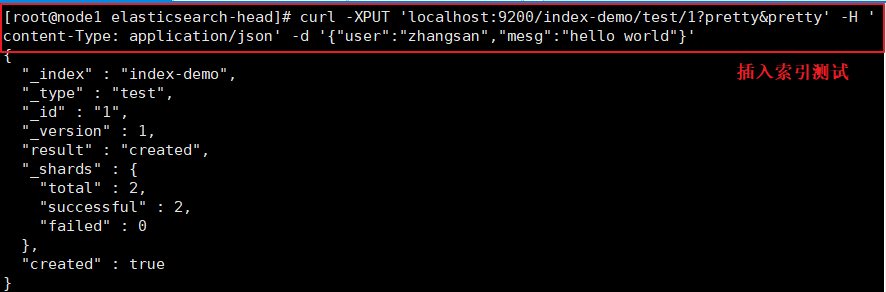
(7)#��������
##��¼192.168.24.20 node1����##### ����Ϊindex-demo,����Ϊtest,���Կ����ɹ�����
[root@node1 ~]# curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
####�ڱ��� ˢ����������뿴������Ϣ###
node1��Ϣ���� 01234
node2��Ϣ���� 01234
������ͼ���Կ�������Ĭ�ϱ���Ƭ5��,������һ������
����������--�ᷢ����node1�ϴ���������Ϊindex-demo,����Ϊtest, ��ص���Ϣ
#���밲װ node
#��װ phantomjs
#��װ Elasticsearch-head ���ݿ��ӻ�����
#�� Elasticsearch �������ļ�(node1��node2��ͬ)


#���� elasticsearch-head ����
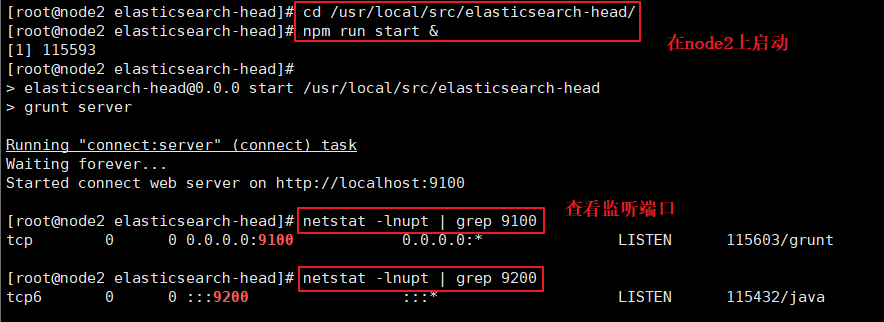
#���������:http://192.168.24.20:9100/
#��������
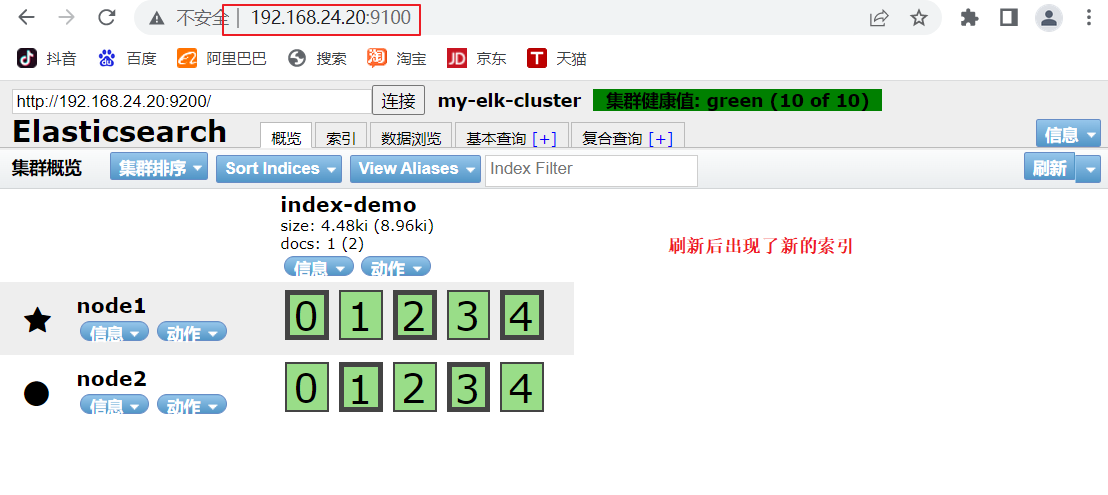
3.2 ELK Logstash ����(�� httpd �ڵ��ϲ���)
3.2.1 ��װ Logstash
(1)#��װhttpd������
yum -y install httpd
systemctl start httpd
(2)#��װjava����
yum -y install java
java -version
(3)#��װlogstash
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
cd /usr/share/logstash/
ls
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
#��װhttpd������


#��װjava���� ���һ��û�о�yum

#��װ logstash
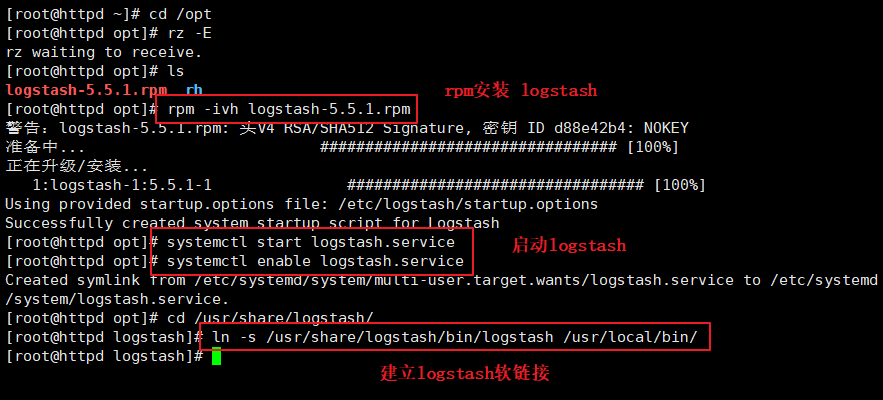
3.2.2 ���� Logstash(httpd)��elasticsearch(node)�����Ƿ�����,���Խ�
Logstash����������
�ֶ���������:
�� -f ͨ�����ѡ�����ָ��logstash�������ļ�,���������ļ�����logstash
�� -e ��������ַ��� ���ַ������Ա�����logstash������(����ǡ��ա���Ĭ��ʹ��stdin��Ϊ���롢stdout��Ϊ���)
�� -t ���������ļ��Ƿ���ȷ,Ȼ���˳�
logstash -f �����ļ����� ȥ����elasticsearch
(1)#������ñ����� ������ñ����---��¼192.168.24.20 ��Apache��������
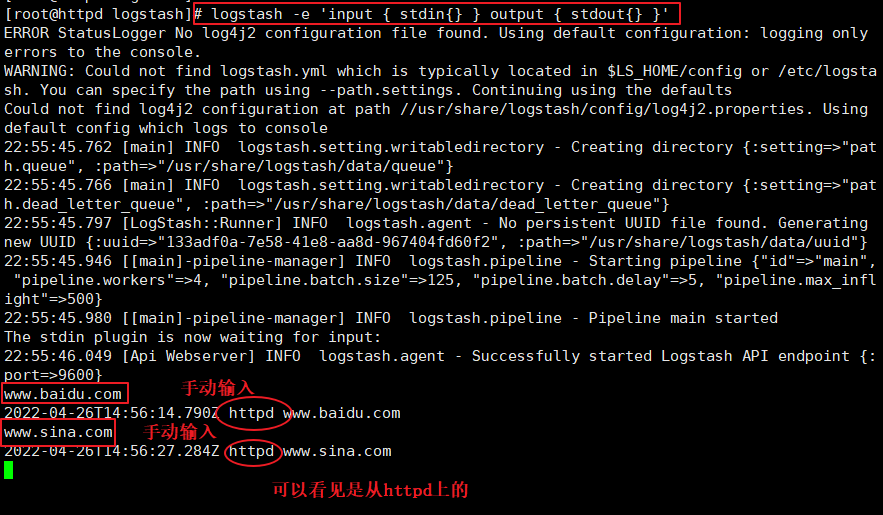
logstash -e 'input { stdin{} } output { stdout{} }'
22:55:45.980 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
The stdin plugin is now waiting for input:
22:55:46.049 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com ###�ֶ�����
2022-04-26T14:56:14.790Z httpd www.baidu.com
www.sina.com ###�ֶ�����
2022-04-26T14:56:27.284Z httpd www.sina.com
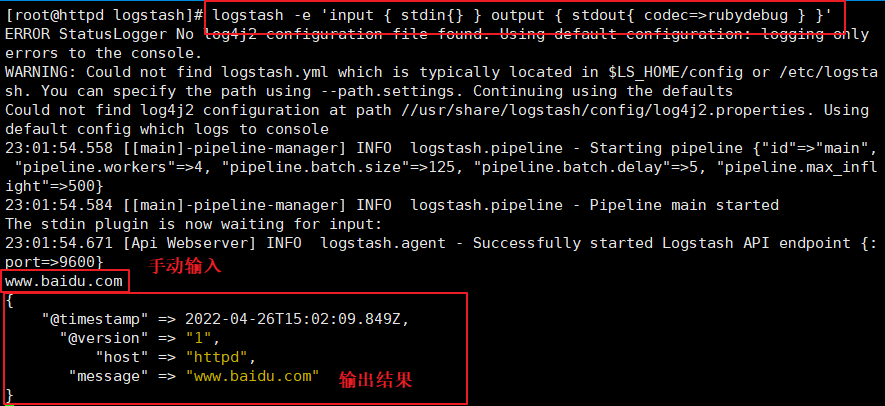
(2)#ʹ�� rubydebug �����ϸ��ʽ��ʾ,codec Ϊһ�ֱ������
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
23:01:54.558 [[main]-pipeline-manager] INFO logstash.pipeline - Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
23:01:54.584 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
The stdin plugin is now waiting for input:
23:01:54.671 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com
{
"@timestamp" => 2022-04-26T15:02:09.849Z,
"@version" => "1",
"host" => "httpd",
"message" => "www.baidu.com"
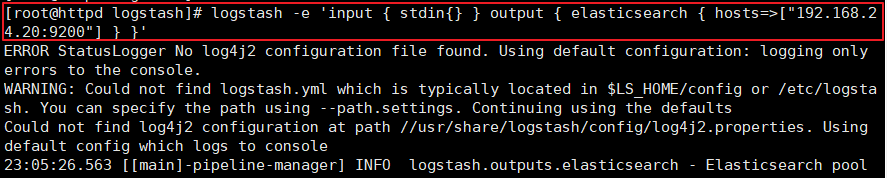
(3)##ʹ��logstash����Ϣд��elasticsearch��
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.24.20:9200"] } }'
#������ñ����� ������ñ���C��¼192.168.24.20 �� httpd ��������
#ʹ�� rubydebug �����ϸ��ʽ��ʾ,codec Ϊһ�ֱ������
#ʹ�� logstash ����Ϣд�� elasticsearch ��

3.2.3 ���� logstash �����ļ�
Logstash �����ļ����������������:input��output �Լ� filter(��ѡ,������Ҫѡ��ʹ��)��
(1)#����־Ŀ¼�ɶ�Ȩ��
chmod o+r /var/log/messages #�� Logstash ���Զ�ȡ��־
(2)#�� Logstash �����ļ�,�����ռ�ϵͳ��־/var/log/messages,����������� elasticsearch �С�
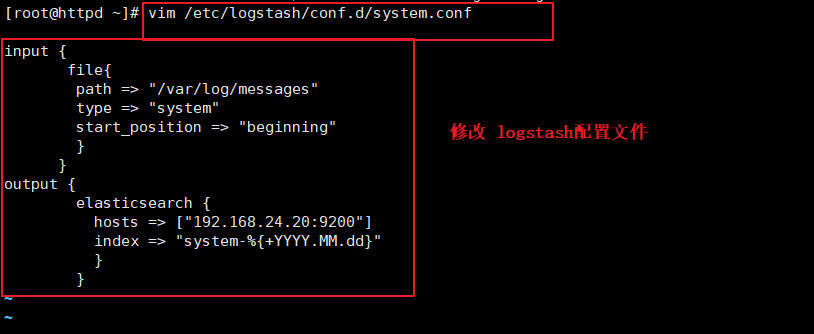
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages" #ָ��Ҫ�ռ�����־��λ��
type =>"system" #�Զ�����־���ͱ�ʶ
start_position =>"beginning" #��ʾ�ӿ�ʼ���ռ�
}
}
output {
elasticsearch { #����� elasticsearch
hosts => ["192.168.24.20:9200"] #ָ�� elasticsearch �������ĵ�ַ�Ͷ˿�
index =>"system-%{+YYYY.MM.dd}" #ָ������� elasticsearch ��������ʽ
}
}
(4)#��������
systemctl restart logstash
(5)#�������
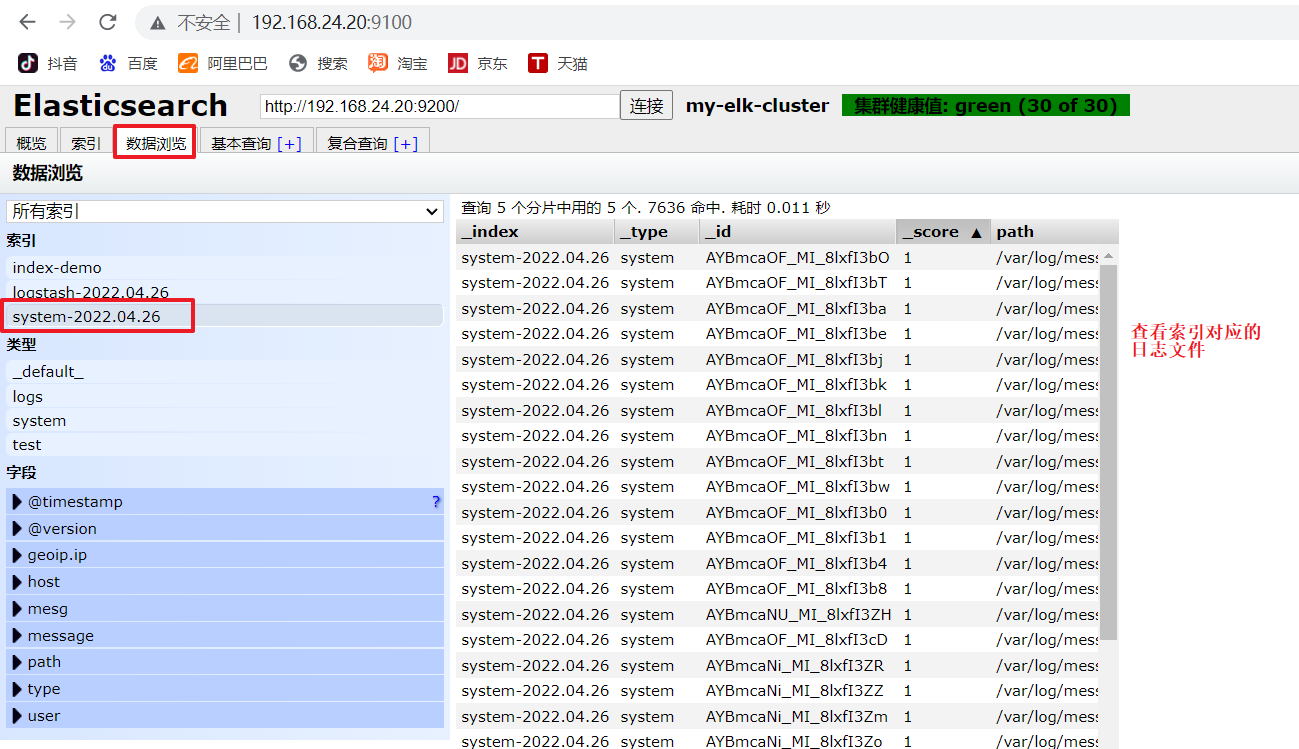
����http://192.168.24.20:9100/ �鿴������Ϣ###
��� system-xxxx
#����־Ŀ¼�ɶ�Ȩ��

#�� Logstash �����ļ�
#��������

#�������http://192.168.24.20:9100/
3.3 ELK Kiabana ����(�� Node1 �ڵ��ϲ���)
(1)#��װ Kiabana
#�ϴ������� kibana-5.5.1-x86_64.rpm ��/optĿ¼
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm
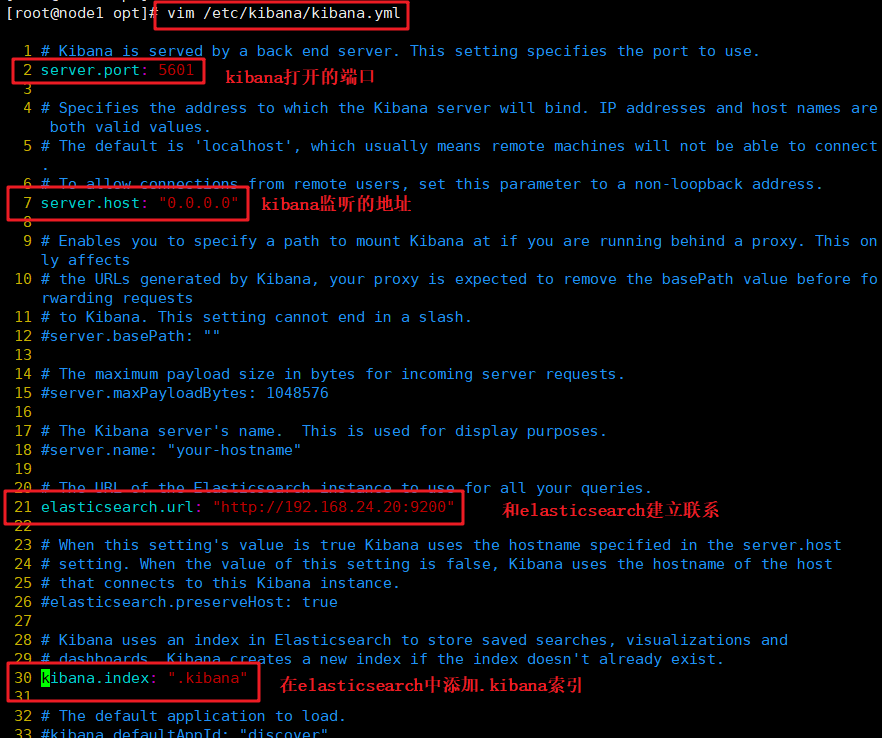
(2)#���� Kibana ���������ļ�
vim /etc/kibana/kibana.yml
--2--ȡ��ע��,Kiabana �����Ĭ�ϼ����˿�Ϊ5601
server.port: 5601
--7--ȡ��ע��,���� Kiabana �ļ�����ַ,0.0.0.0�������е�ַ
server.host: "0.0.0.0"
--21--ȡ��ע��,���ú� Elasticsearch �������ӵĵ�ַ�Ͷ˿�
elasticsearch.url: "http://192.168.24.20:9200"
--30--ȡ��ע��,������ elasticsearch ������.kibana����
kibana.index: ".kibana"
(3)#���� Kibana ����
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601
(4)#��֤ Kibana
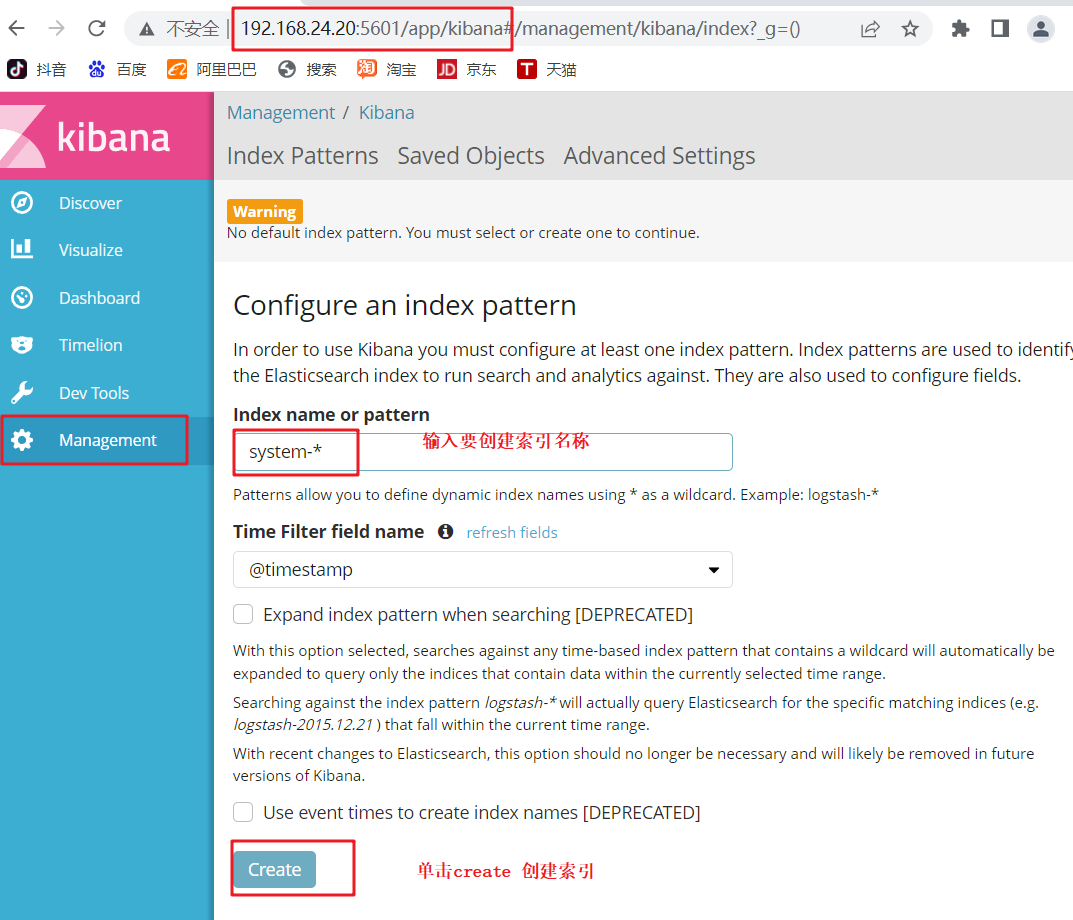
��������� http://192.168.24.20:5601
��һ�ε�¼��Ҫ����һ�� Elasticsearch ����:
Index name or pattern
//����:system-* #��������������֮ǰ���õ� Output ǰ��system��
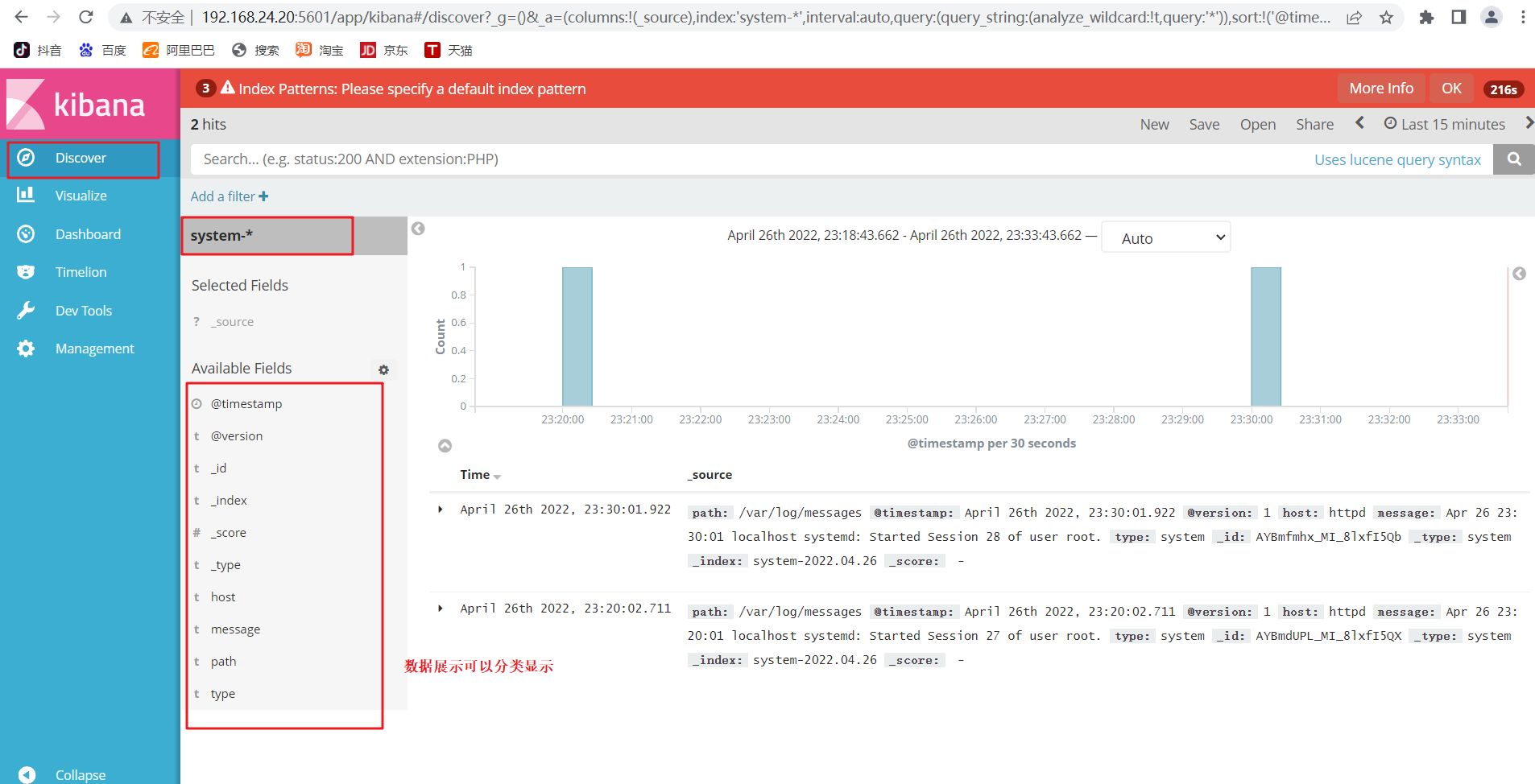
���� ��create�� ��ť����,���� ��Discover�� ��ť�ɲ鿴ͼ����Ϣ����־��Ϣ��
����չʾ���Է�����ʾ,�ڡ�Available Fields���еġ�host��,Ȼ�� ��add����ť,���Կ������ա�host��ɸѡ��Ľ��
(5)#�� httpd ����������־(���ʵġ������)���ӵ� Elasticsearch ��ͨ�� Kibana ��ʾ
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.24.20:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.24.20:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf
6.#���������http://192.168.24.20:9100/����,�鿴������Ϣ�ܷ���
apache_error-2019.04.16 apache_access-2019.04.16
#���������http://192.168.24.20:5601
������½��и�managementѡ��---index patterns---create index pattern
----�ֱ�apache_error-* �� apache_access-* ������
#��װ Kiabana
#���� Kibana ���������ļ�
#���� Kibana ����

#��֤ Kibana,��������� http://192.168.24.20:5601
#���������http://192.168.24.20:9100/����,�鿴������Ϣ�ܷ���������־


