前言
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统。
HDFS,是Hadoop Distributed File System的简称,是Hadoop抽象文件系统的一种实现。Hadoop抽象文件系统可以与本地系统、Amazon S3等文件系统集成。HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。
HDFS设计原则
简单的一致性模型:HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能
- 存储非常大的文件:这里非常大指的是几百M、G、或者TB级别。实际应用中已有很多集群存储的数据达到PB级别。
- 采用流式的数据访问方式: 最有效的数据处理模式是一次写入、多次读取数据集。从数据源生成或者拷贝一次,然后在其上做很多分析工作 。
- 硬件错误检测和快速恢复:HDFS可能是由成百上千的服务器构成的,每个服务器上存储着文件系统的部分数据,构成系统的组件数目也是巨大的,任意一个组件都有失效的可能,总有一部分HDFS组件不工作。
HDFS不适合的应用类型
- 低延时的数据访问:对延时要求在毫秒级别的应用,不适合采用HDFS。
- 大量小文件 :文件的元数据(如目录结构,文件block的节点列表,block-node mapping)保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
- 多方读写,需要任意的文件修改.HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改。不支持多个写入器(writer).
HDFS的安装
可参考《使用docker安装hadoop2.7.7》或者《hadoop集群环境搭建》
HDFS架构
HDFS是一个主从体系结构,它由四部分组成,分别是HDFS Client、NameNode、DataNode以及Seconary NameNode.

- HDFS集群是由一个Namenode和一定数目的Datanodes组成。
- Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
- Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
Client写的过程
- 客户端会对文件进行切分,分成一个个block。
- 通过与NameNode进行交互确定文件的位置信息
- 通过与DataNode进行交互写入数据
Client读的过程
- 客户端使用文件系统的名字空间通过NameNode确定文件对就的位置信息
- 通过与DataNode进行交互读数据
- 客户端会对block进行组装
Blocks
- 物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。
- 文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。通常为几KB。
- HDFS的Block块比一般单机文件系统大得多,默认为128M
Block抽象的好处
block的拆分使得单个文件大小可以大于整个磁盘的容量,构成文件的Block可以分布在整个集群
block的大小设置原理
- 文件块越大,寻址时间越短,但磁盘传输时间越长;
- 文件块越小,寻址时间越长,但磁盘传输时间越短。
为什么HDFS中块(block)不能设置太大,也不能设置太小
如果块设置过大?
- 从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
- mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢
如果块设置过小
- 存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的内存是有限的,不可取;
- 文件块过小,寻址时间增大,导致程序一直在找block的开始位置。
HDFS中块(block)的大小为什么设置为128M?
- HDFS中平均寻址时间大概为10ms;
- 经过前人的大量测试发现,寻址时间为传输时间的1%时,为最佳状态;所以最佳传输时间为10ms/0.01=1000ms=1s
- 目前磁盘的传输速率普遍为100MB/s;计算出最佳block大小:100MB/s x 1s = 100MB,所以我们设定block大小为128MB。
Packet
Packet是Client端向Dataode,或者DataNode的PipLine之间传输数据的基本单位,默认64kB.
Chunk
Chunk是最小的Hadoop中最小的单位,是Client向DataNode或DataNode的PipLne之间进行数据校验的基本单位,默认512Byte,因为用作校验(自己校验自己),故每个chunk需要带有4Byte的校验位。
所以世纪每个chunk写入packet的大小为526Byte,真实数据与校验值数据的比值为128:1。
Namenode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上:
- fsimage:它是NameNode启动时对整个文件系统的快照。
- edits:它是在NameNode启动后,对文件系统的改动序列(即日志)。
NameNode目录结构
运行中的NameNode有如下所示的目录结构:

- VERSION文件 :是一个Java属性文件,其中包含正在运行的HDFS的版本信息。该文件一般包含以下内容:
# 文件系统命名空间的唯一标识符,是在NameNode首次格式化时创建的。
namespaceID=1342387246
# 在HDFS集群上作为一个整体赋予的唯一标识符
clusterID=CID-01b5c398-959c-4ea8-aae6-1e0d9bd8b142
# 标记了NameNode存储系统的创建时间。刚格式化的存储系统,值为0,但升级后,该值会更新到新的时间戳
cTime=0
# 该存储目录包含的时NameNode的数据结构
storageType=NAME_NODE
# 数据块池的唯一标识符,数据块池中包含了由一个NameNode管理的命名空间中的所有文件
blockpoolID=BP-526805057-127.0.0.1-1411980876842
# 这是一个负整数,描述HDFS持久性数据结构(也称布局)的版本,但是该版本号与Hadoop发布包的版本号无关。只要布局变更,版本号将会递减,此时HDFS也要升级。否则,新版本的NameNode(或DataNode)就无法正常工作。
layoutVersion=-57
- seen_txid文件 :该文件对于NameNode非常重要,它是存放transactionId的文件,format之后是0,它代表的是NameNode里面的edits_文件的尾数,NameNode重启的时候,会按照seen_txid的数字,循序从头跑edits_00001~到seen_txid的数字。
- in_use.lock文件 :是一个锁文件,NameNode使用该文件为存储目录加锁。
在NameNode重启时,edits才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在生产环境集群中的NameNode是很少重启的,这意味者当NameNode运行来很长时间后,edits文件会变的很大。在这种情况下就会出现下面这些问题:
- edits文件会变的很大,如何去管理这个文件?
- NameNode的重启会花费很长的时间,因为有很多改动要合并到fsimage文件上。
- 如果NameNode宕掉了,那我们就丢失了很多改动,因为此时的fsimage文件时间戳比较旧。
Secondary Namenode
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edits文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。而Secondary NameNode就是为了帮助解决上述问题提出的,它的职责是合并NameNode的edits到fsimage文件中。如图所示:
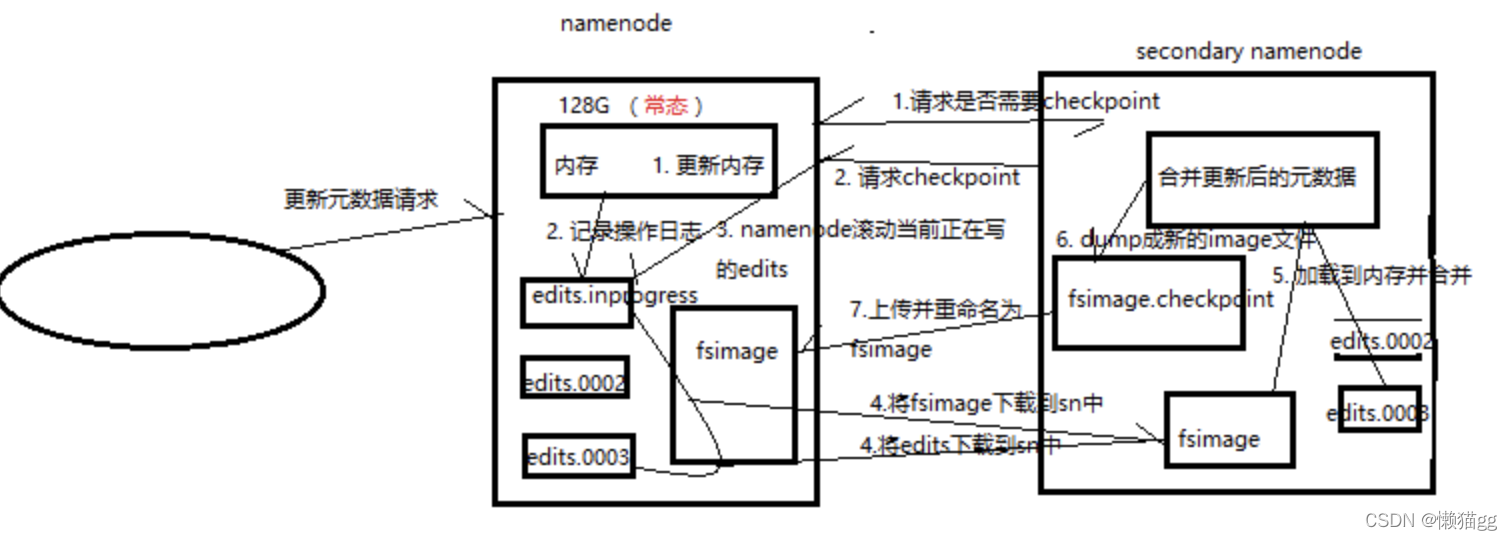
- 日志文件是滚动的,一个正在写,几个已经写好的滚动;
- checkpoint时,把正在写的滚动一下,然后把fsimage和日志文件下载到secondarynamenode上,只有第一次才会下载fsimage,这时候不会很大,以后就光下载日志文件,日志文件下载不会很大;
- 如果namenode硬盘损坏,可以将secondarynamenode的元数据拷贝到namenode,但是secondarynamenode虽然有元数据信息,但是只能恢复大部分数据,最新更新的数据可能由于没有来得及下载到secondarynamenode,而无法全部恢复。
- secondarynamenode虽然有元数据信息但是不能更新元数据,不能充当namenode使用。
Namenode HA
NameNode这很重要,如果发生故障怎么办?Hadoop2.0+可以通过NameNode HA解决单点故障的问题。
- 一个 NameNode 有单点问题,如果再提供一个 NameNode 作为备份,不是能解决问题?这便是主备模式的思想。
- 继续这个思路,光有备份的 NameNode 够吗?我们知道 NameNode 上存储的是 HDFS 上所有的元数据信息,因此最关键的问题在于 NameNode 挂了一个,备份的要及时顶上,这就意味着我们要把所有的元数据都同步到备份节点。好,接下来我们考虑如何同步呢?
- 每次 HDFS 写入一个文件,都要同步写 NameNode 和其备份节点吗?如果备份节点挂了就会写失败?显然不能这样,只能是异步来同步元数据。
- 如果 NameNode 刚好宕机却没有将元数据异步写入到备份节点呢?那这部分信息岂不是丢失了?这个问题就自然要引入第三方的存储了,在 HA 方案中叫做“共享存储”。每次写文件时,需要将日志同步写入共享存储,这个步骤成功才能认定写文件成功。然后备份节点定期从共享存储同步日志,以便进行主备切换。
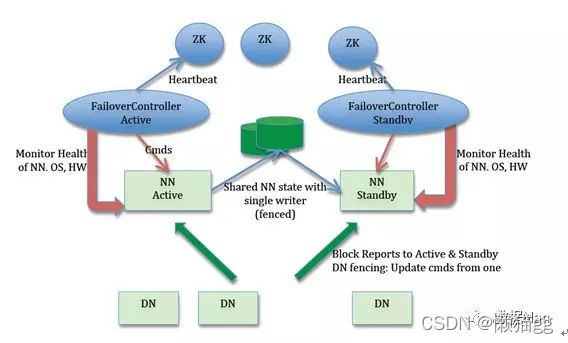
- Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
- 主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
- Zookeeper 集群:为主备切换控制器提供主备选举支持。
- 共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。Active NameNode 和 Standby NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
可以看出,这里的核心是共享存储的实现,这些年有很多的 NameNode 共享存储方案,比如 Linux HA, VMware FT, shared NAS+NFS, BookKeeper, QJM/Quorum Journal Manager, BackupNode 等等,目前社区已经把由 Clouderea 公司实现的基于 **QJM(Quorum Journal Manager)**的方案合并到 HDFS 的 trunk 之中并且作为默认的共享存储实现。
QJM
基于 QJM 的共享存储系统主要用于保存 EditLog,并不保存 FSImage 文件。FSImage 文件还是在 NameNode 的本地磁盘上。QJM 共享存储的基本思想来自于 Paxos 算法,采用多个称为 JournalNode 的节点组成的 JournalNode 集群来存储 EditLog。每个 JournalNode 保存同样的 EditLog 副本。每次 NameNode 写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向 JournalNode 集群之中的每一个 JournalNode 发送写请求,只要大多数 (majority) 的 JournalNode 节点返回成功就认为向 JournalNode 集群写入 EditLog 成功。如果有 2N+1 台 JournalNode,那么根据大多数的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
HDFS Federation
HDFS HA是热备份,提供高可用性,但是无法解决可扩展性、系统性能和隔离性。HDFS Federation就是使得HDFS支持多个命名空间,并且允许在HDFS中同时存在多个Name Node。
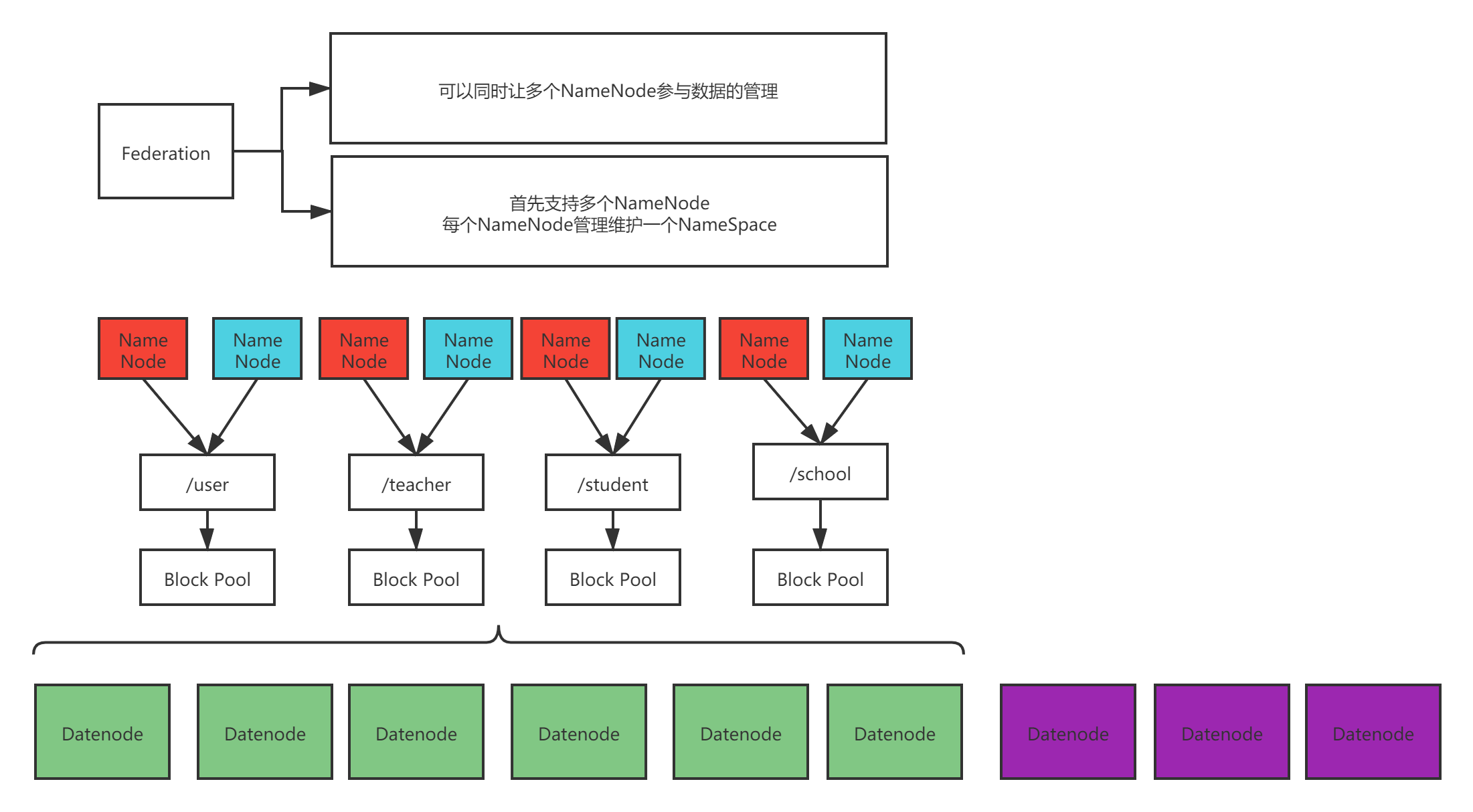
- NameNode提供了命名空间(NameSpace)和块(Block)管理功能。
- HDFS 联邦拥有多个独立的命名空间,每个空间管理属于自己的一组块,这些同组的块构成了“块 池”(Block Pool)。
- 所有的NameNode 会共享底层的数据节点的存储资源。数据节点是一个物理概念,块池则属于逻辑概念。
datanode
在HDFS中,我们真实的数据是由DataNode来负责来存储的,但是数据具体被存储到了哪个DataNode节点等元数据信息则是由我们的NameNode来存储的。
DataNode目录结构
DataNode的关键文件和目录如下所示:
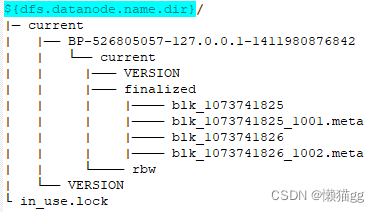
从上图可以看出,dataNode的文件结构主要由blk_前缀文件、BP-random integer-NameNode-IP address-creation time和VERSION构成。
-
BP-random integer-NameNode-IP address-creation time :
- BP代表BlockPool的,就是Namenode的VERSION中的集群唯一blockpoolID
- 从上图可以看出我的DataNode是一个BP
- 一个NameNode管理全部的文件系统命名空间,如果有两个以上的BP,该HDFS是Federation HDFS,所以该目录下有两个BP开头的目录,
- IP部分和时间戳代表创建该BP的NameNode的IP地址和创建时间戳。
-
rbw :是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
-
blk_前缀文件 : HDFS中的文件块,存储的是原始文件内容。
-
meta文件: 块的元数据信息,每一个块有一个相关联的.meta文件,一个文件块由存储的原始文件字节组成。
-
VERSION:记录块的基本信息
# 相对于DataNode来说是唯一的,用于在NameNode处标识DataNode
storageID=DS-c478e76c-fe1b-44c8-ba45-4e4d6d26654
# 是系统生成或手动指定的集群ID
clusterID=CID-01b5c398-959c-4ea8-aae6-1e0d9bd8b142
# 表示DataNode存储时间的创建时间
cTime=0
# 表示DataNode的ID号
datanodeUuid=75ffabf0-813c-4798-9a91-e7b1a26ee6f1
# 将这个目录标志位DataNode数据存储目录
storageType=DATA_NODE
# 是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
layoutVersion=-57
- in_use.lock : 是一个锁文件,DataNode使用该文件为存储目录加锁
命令
可以通过hdfs fsck 命令来查看一文件的块分部,及检测块的好坏。可参考
《HDFS中的fsck命令(检查数据块是否健康) 》
HDFS异构存储
Hadoop在2.6.0版本中引入了一个新特性异构存储.异构存储可以根据各个存储介质读写特性的不同发挥各自的优势
- 针对冷数据,采用容量大的,读写性能不高的存储介质存储,比如最普通的Disk磁盘.
- 而对于热数据而言,可以采用SSD的方式进行存储,这样就能保证高效的读性能,在速率上甚至能做到十倍于或百倍于普通磁盘读写的速度.
HDFS的异构存储主要支持 RAM_DISK,SSD,DISK,ARCHIVE
- ARCHIVE:高存储密度但耗电较少的存储介质,通常用来存储冷数据。
- DISK:磁盘介质,这是HDFS默认的存储介质。
- SSD:固态硬盘,是一种新型存储介质,目前被不少互联网公司使用。
- RAM_DISK:数据被写入内存中,同时会往该存储介质中再(异步)写一份。
hdfs不会自动识别磁盘,在配置属性dfs.datanode.data.dir中进行本地对应存储目录的设置
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///grid/dn/disk, [SSD]file:///grid/dn/ssd</value>
</property>
上述指南的存储性质,当然hdfs也提供了策略

对应命令
- 查看所有策略: hdfs storagepolicies -listPolicies
- 查看yoyo文件的策略: hdfs storagepolicies -getStoragePolicy -path /hdfs/yoyo
- 设置yoyo文件的策略: storagepolicies -setStoragePolicy -path /hdfs/yoyo -policy ALL_SSD
setStoragePolicy的不会立即生效策略,要通过hdfs mover进行目录扫描,可参考《HDFS异构存储实战》
副本策略
通常来说,HDFS整体的副本冗余策略,是默认保存3个副本的策略。大型 HDFS 实例通常分布运行在由许多机架组成的集群中,一个机房中有很多机架,一个机架上有多个服务器,不同机架的机器通信需要经过交换机,受带宽等因素的影响,需要更高的网络通信成本。
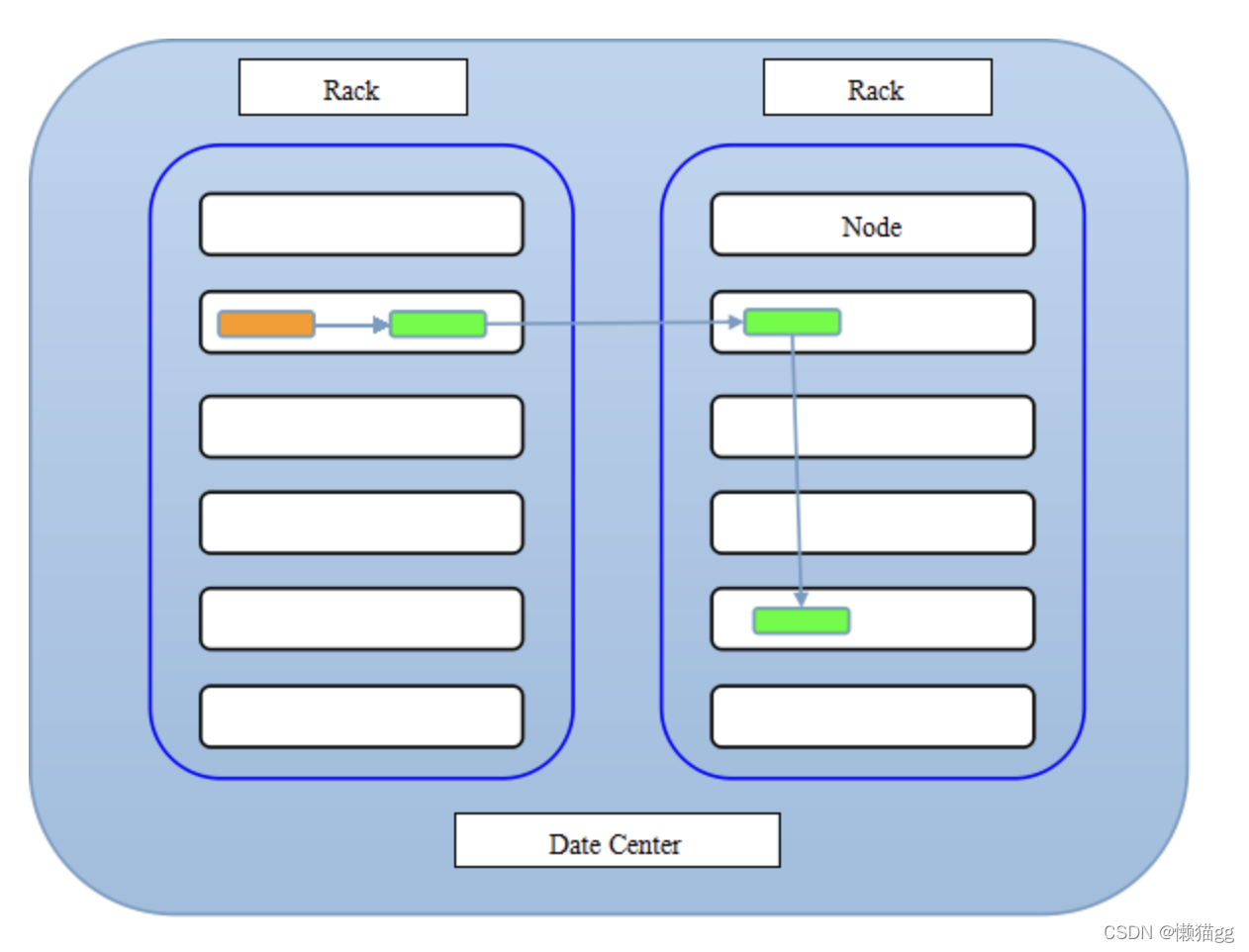
在默认 3 个副本的情况下,HDFS采用如下的放置策略:
- 1st replica. 如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
- 2nd replica. 第二个副本存放于不同第一个副本的所在的机架.
- 3rd replica.第三个副本存放于第二个副本所在的机架,但是属于不同的节点.
如果有更多的副本,则随机选择机架,每个机架的副本数量有个上限值,计算方式通常是:(replicas - 1) / racks + 2
这样放置的好处:
- 避免一个机架出故障,导致所有数据丢失;
- 同一个机架上的节点通信网络会比不同机架节点通信更好,副本二与副本三放置在同一个机架能够节省带宽;
从单个文件看来,考虑带宽似乎没有多大意义,但是对于大规模数据的情况下,请求并发量大时,网络是非常重要的一个因素,特别是对于写请求,这里要了解 HDFS 写的流程。因为写副本的过程类似于流水线
- 先写副本一,但这里写完后就将写成功的结果返回给客户端了。
- 之后由副本一将内容写到副本二,接着由副本二将内容写到副本三。
假设副本三和副本一放置在一个机架上,那么就会产生两次不同机架间的写操作。而目前的情况是副本二和副本三在同一个机架,机架间的写操作只会发生在副本一到副本二之间,副本二和副本三的写操作是在同一个机架,节省了网络流量。
为了最大的减少带宽和延迟,HDFS 读取文件采用就近原则,如果与客户端在同一机架上的 DataNode 上存有副本,则直接读取该副本。如果 HDFS 是跨数据中心的,则优先选择同一数据中心的副本。
更多功能
- 缓存《HDFS中的集中缓存管理详解》
- 快照《[知识讲解篇-31] HDFS 快照》
- 视图《HDFS_视图文件系统》
以上有讲到的,都是作为开发者关心的功能与架构,还有没讲到的运维及扩展方面请参考《HDFS精华文章汇总》
主要参考
《hdfs 中chunk_HDFS读写流程》
《为什么HDFS文件块(block)大小设定为128M》
《Hadoop的HDFS中的namenode和secondarynamenode的内容总结》
《HDFS NameNode 高可用实现》
《HDFS(3):Hadoop优化与发展》
《hadoop基本原理架构讲解(HDFS部分)》
《大数据入门:HDFS数据副本存放策略》

