kafka(��)�� ͼ�ⲿ��ԭ��
1.������ԭ��
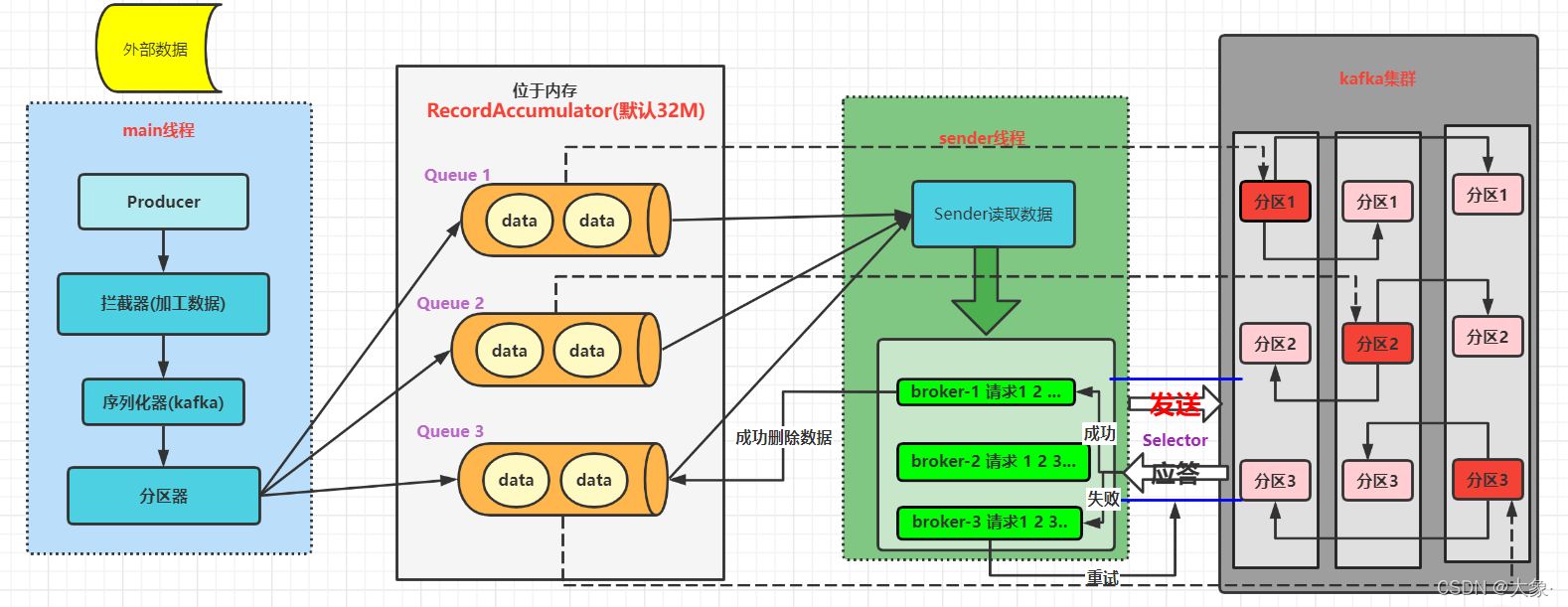
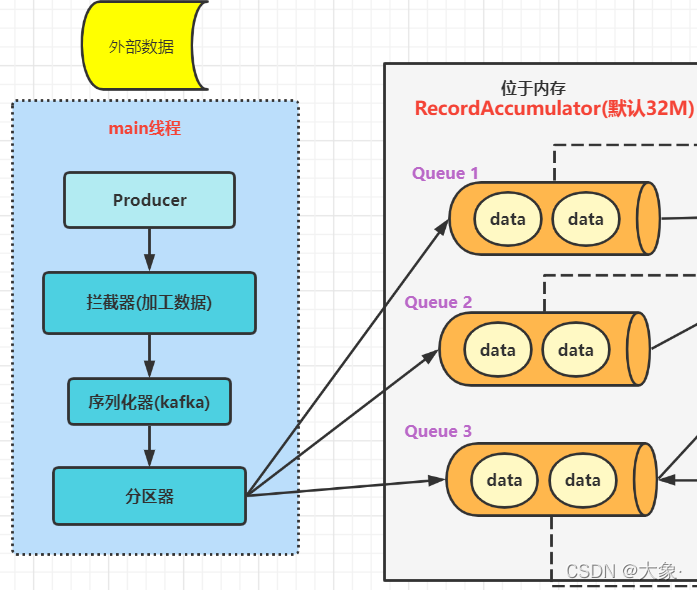
1.���ȴ���main�߳�,����Producer����,����send������������,�����������ʹ�������,Ȼ���������л�(kafka���������л���,����Ҫ�ֶ�ָ��),Ȼ����������,���ݷ��������з���
2.Ȼ�ֺ��������ݷ���һ��λ���ڴ�Ļ�����(Ĭ��32M),ÿ��������Ӧһ��˫�˶���,�����߷������ݵ����δ�СΪ16K
3.sender�߳���Sender��ȡ����,��ȡ���ٽ�������ÿ�������ڵ����ݴ�С�ܺʹﵽbatch.size(Ĭ��16K)����sender�ȴ�ʱ��ﵽ��linger.ms(Ĭ��0ms)
4.ÿ�����е����ݱ���ת����������,�����������,ȥ����Ⱥ�϶�Ӧ�ڵ�Ķ�Ӧ����,Ҫͨ���ײ㴴����Selector���͵���Ⱥ,����Ӧ����Ʒ�Ϊ��������Ӧ�����Ϊ0:������ֻ��Ҫ��������,����ɶ�����ù� ��Ӧ�����Ϊ1 ��Ҫ�ȴ�leader�յ����ݺ�ŷ���Ӧ�� �� -1(all) leader��follower���յ����ݺ��Ӧ�������ڵ㲻Ӧ��,�����ۼ�5������
5.���ͳɹ���Kafka��Ⱥ,��ô����ڴ��ж�Ӧ������,���ɹ�����(���Դ����ɴ�int�����ֵ��)
2.�������
����Ϊʲô����
������,�����ݷ���,���Ժ�����ʹ�ô洢��Դ
���,����ʵ�ֲ��ж�,�����߿����Է���Ϊ��λ���з�������,�����߿��Է���Ϊ��λ���з���
�����������
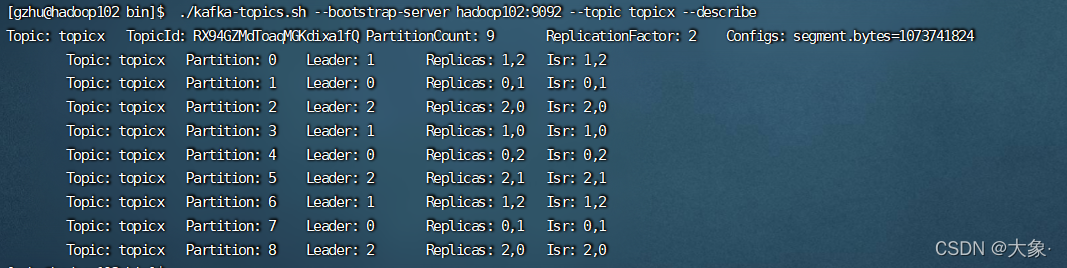
������ֻ��3̨������,���Ҷ�ij�������9������,ÿ������2������,������9��������leader����?follower����? ע��,���������ܳ���������(�����ᱨ��)
����
./kafka-topics.sh --bootstrap-server hadoop102:9092 --topic topicx --create --partitions 9 --replication-factor 2
./kafka-topics.sh --bootstrap-server hadoop102:9092 --topic topicx --describe
���Կ���,leader��ȡ����ѯ�ķ�ʽ,ʵ����leader�Զ�ƽ��������follower,��ÿ���ڵ�Ϊ��λ��,���ǿ��Կ���,λ�ڽڵ�0��leader�ĸ���������������,[0,1] [0,2] [0,1],�������һ��leaderλ��0,�����ĸ���������[0,2],Ҳ��Ϊ�˸��ؾ���
�������� �ķ���������λ��
��������ѷ���0�ĸ�����[1,2]��Ϊ[0,1]
��kafkaĿ¼��vim increase-replication-factor.json
{
"version":1,
"partitions":[{"topic":"topicx","partition":0,"replicas":[0,1]}
}
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
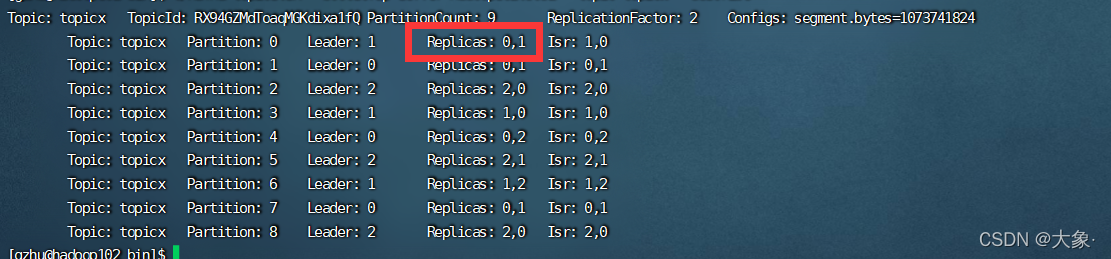
����,������ͨ���ַ�ʽ���Ӹ���,�����Ұ�����json�ļ�����һ��,�ij�[0,1,2],�Ǹ÷����ĸ������ͻ�����!
���ݷ�������(���ݱ��ֵ��ĸ���������)
���Կ���,�����ߵĹ��캯��������6��
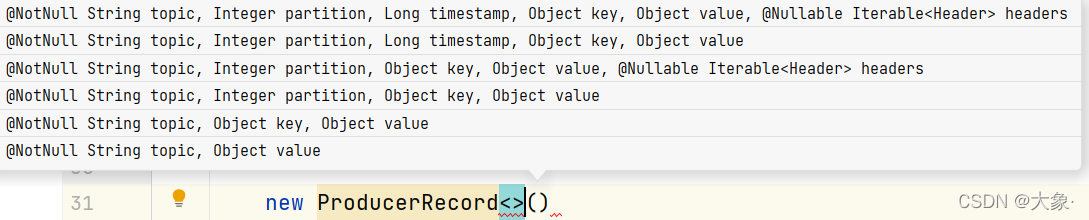
����ǰ4��,���ǿ���ͨ���ڶ�������ֱ��ָ������
���ڵ�5��,��Ȼû��ָ������,����ָ����key,��ô�������ĸ������� key��hashֵ��topic��partition������ȡ������õ�������,�������ǿ��Խ�һ��mysql�ı�������Ϊkey,��ô���ű������ݾͻ����һ��������
���ڵ�6��,��û��partitionֵ��û��keyֵ�������,Kafka����Sticky Partition(��Է�����),�����ѡ��һ������,��������һֱʹ�ø÷���,���÷�����batch�������������,Kafka�����һ����������ʹ��(����һ�εķ�����ͬ)
����:��һ�����ѡ��0�ŷ���,��0�ŷ�����ǰ��������(Ĭ��16k)����linger.ms���õ�ʱ�䵽, Kafka�����һ����������ʹ��(�������0��������)
�Զ������ݷ�����
ʵ��Partitioner�ӿ�,��д����
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// ���͵����� value
String str = value.toString();
int partition;
if(str.length() <= 3){
partition = 0;
}else {
partition = 1;
}
return partition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
��������ָ��������,������Ϣ�ͻ���ݷ��������з�����
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.gzhu.MyPartitioner");
3.������������
��Ҫ��4�ַ�ʽ�ı�������
1.�ı�RecordAccumulator�Ĵ�С,����������,���ݴ�������Ҳǿ��
2.�ı�batch.size�Ĵ�С,���Ҫ����ʵ������ı�,���̫С���·�������̫Ƶ��,̫���������ӳٸ�
3.�ı�linger.ms��ʱ��,���̫С���·�������̫Ƶ��,̫���������ӳٸ�
4.��ѹ����ʽ
// ���Ļ�������С Ĭ��33554432 = 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
// ���δ�С Ĭ��16K 16384
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
// linger.ms 1ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);
// ѹ������ snappy�ö�һЩ
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
4.���ݿɿ��� ISRԭ��
ÿ�����е����ݱ�ת�����������,ȥ����Ⱥ�϶�Ӧ�ڵ�Ķ�Ӧ����,Ҫͨ���ײ㴴����Selector���͵���Ⱥ,��ȺӦ����Ʒ�Ϊ����
��Ӧ�����Ϊ0 ������ֻ��Ҫ��������,����ɶ�����ù� ,������,���leaderû�յ�,�Ͷ�ʧ��,������������Ϊ���ͳɹ���,������ֻ��ƺܲ��ɿ�,��������
��Ӧ�����Ϊ1 ��Ҫ�ȴ�leader�յ����ݺ�ŷ���Ӧ�� ,Ҳ��ȱ��,leader�յ�ij���ݲ���Ӧ����,����follower��û���ü�ͬ��,��ʱleader����,����û�б�����Ψһ�յ����ݵ�leader������,��ʱ�������Ѿ��յ���Ӧ����,��Ϊ�Ѿ����ͳɹ���,���ݾͶ�ʧ��
�� -1(all) leader��follower���յ����ݺ��Ӧ�� ����ʮ�ֿɿ�,�����и�����,����ijfollowerͬ����ʱ��,���ڹ��Ϲҵ���,��ʱ���follower��������Ӧ����,������ȴһ���ڵ�,��������Ⱥ����̱������?
Ϊ��,Leaderά����һ����̬��In-Sync Replicas(ISR),��Ϊ��Leader��������ͬ����Follower+Leader���� (leader:0,isr:0,1,2),�������ֻҪ��עISR��ڵ��Ӧ��Ϳ���
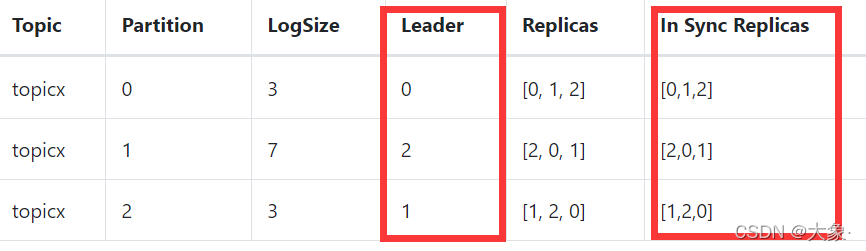
���Follower��30s��δ��Leader����ͨ�������ͬ������,���Follower�����Ƴ�ISR����ʱ����ֵ��replica.lag.time.max.ms�����趨,Ĭ��30s������ڵ�2�ĸ�����ʱ,��(leader:0, isr:0,1)
�����Ͳ��õȳ�����ϵ���ϻ����Ѿ����ϵĽڵ�
���������������Ϊ1��,����ISR��Ӧ�����С��������( min.insync.replicas Ĭ��Ϊ1)����Ϊ1,��ack=1��Ч����һ����,��Ȼ�ж����ķ���(leader:0,isr:0)�����,��Ҫ��֤������ȫ�ɿ�,ACK��������Ϊ-1 + �����������ڵ���2 + ISR��Ӧ�����С�����������ڵ���2,�ص�����������,[ijfollowerͬ����ʱ��,���ڹ��Ϲҵ���,��ʱ���follower��������Ӧ����,������ȴһ���ڵ���������Ⱥ����̱������?],����ISR����,���follower���߳�,�����ߵȵ�������������Ӧ��,Ҳ��Ϊ�ɹ�
����ѡ��
������������,acks=0����ʹ��
acks=1,һ�����ڴ�����ͨ��־,��������������
acks=-1,һ�����ڴ����Ǯ��ص�����,�Կɿ���Ҫ��Ƚϸߵij���
�ڿ�����,��Ҫ������������
// Ӧ�����,Ĭ��Ϊall
properties.put(ProducerConfig.ACKS_CONFIG,"all");
// ���Դ���,Ĭ��int�����ֵ��
properties.put(ProducerConfig.RETRIES_CONFIG,1000);
5.�����ظ����� �ݵ���ԭ��
������һ��,����Ŀǰ��Ե�ij��������������
�������ij������,һ��leader������follower,���ɹ��յ�������,���Ǿ��ڷ���Ӧ���ʱ��,leader����,��ô�������ղ���ȫ����Ӧ��(Ӧ�����Ϊall),����ISR����,���������·�������,��ʱԭ��������follower(�и�follower��leader���˺���Ϊ�µ�leader)�Ѿ���������,�ٽ���һ�ξͲ��������������������ظ�����
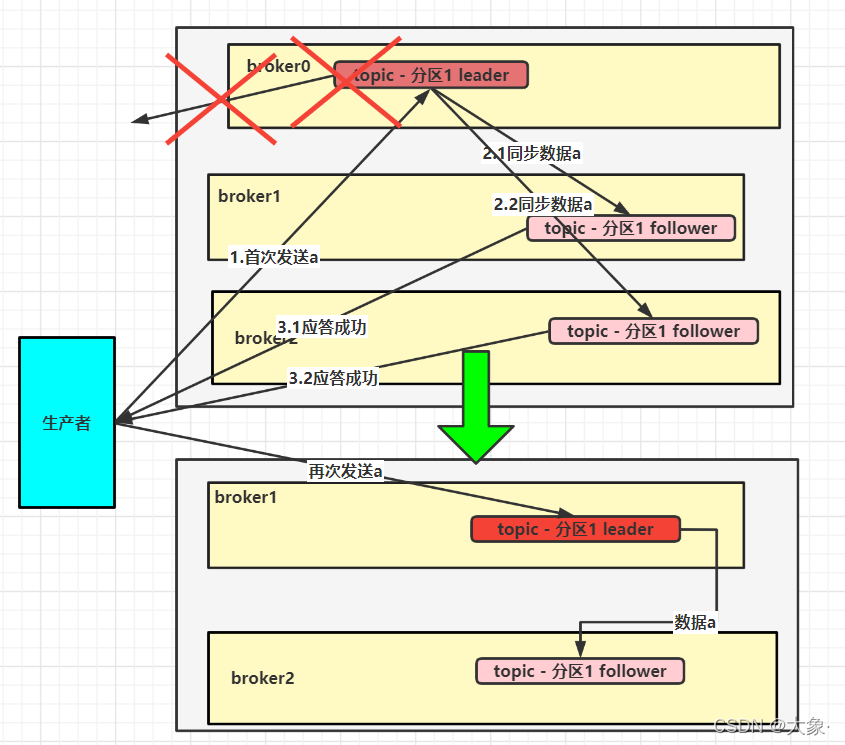
���ڷ��ʹ�����һЩ����
1.�����ٷ���һ��(At Least Once)= ACK��������Ϊ-1 + �����������ڵ���2 + ISR��Ӧ�����С�����������ڵ���2
2.���������һ��(At Most Once)= ACK��������Ϊ0
At Least Once���Ա�֤���ݲ���ʧ,���Dz��ܱ�֤���ݲ��ظ�
At Most Once���Ա�֤���ݲ��ظ�,���Dz��ܱ�֤���ݲ���ʧ(ʵ�����Dz���)
3.��ȷһ��(Exactly Once):����һЩ�dz���Ҫ����Ϣ,�����Ǯ��ص�����,Ҫ�����ݼȲ����ظ�Ҳ����ʧ,������ôʵ����???�ݵ���
�ݵ��Ծ���ָProducer������Broker���Ͷ��ٴ��ظ�����,Broker��ij������ֻ��־û�һ��,��֤�˲��ظ�
�ݵ�����Ҫͨ������������ʵ��:����<PID, Partition, SeqNumber>��ͬ��������Ϣ�ύʱ,Brokerij����ֻ��־û�һ��
����PID��Kafkaÿ�������������һ���µ�;Partition��ʾ������;Sequence Number�ǵ���������,��ÿ�����ݵ����л���,��ͬ�����Dz�ͬ��
������,�ݵ���ֻ�ܱ�֤�����ڵ��Ự�������ڲ��ظ�,Ϊʲôֻ�ܱ�֤���Ự?ʾ��,����һ����Ϣa,kafka��Ⱥ����������,����PID��ͬ,������Ϊ���Dz�ͬ������,������Ϊ����ȵ�����(ʵ�ʶ�������a)
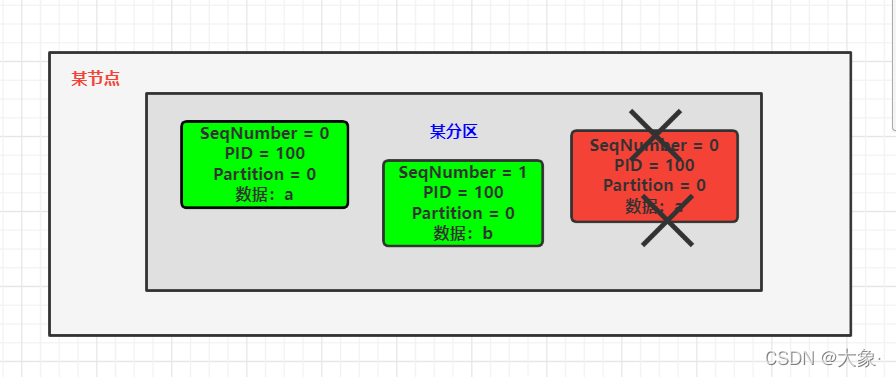
�ٻص��������龰,�ڵ�0����,���������·�������,�µ�leader�ٴν��յ�aʱ,����PIDû��,������û��,SeqNumberû��,�ظ���,������,�ɹ���������ڵ������ظ�����!
�������������ʵ���ݵ���?
��������enable.idempotenceĬ��Ϊtrue,false �ر�,ʵ����,�ײ��ݵ�����Ĭ�Ͽ�����,���Dz�дҲ����
6.Kafka����ԭ��
�ݵ���ֻ�ܱ�֤�����ڵ��������Ự�ڲ��ظ�,�ݵ��Բ��ܿ����������������֮�䲻���ظ�������ôʵ��,��ô��? ����,kafka������Ա�֤�Զ������д�������ԭ����
��������,���뿪���ݵ���,����ײ������ݵ���
����ȷ��ʹ���ĸ�����Э����(��Ϊÿ���ڵ㶼������Э����,ɶ?ɶ������Э����?kafka��Ⱥ�Ϳͻ��˽�������ͨ���ܵ��и�������?����ͨ����!),���ȷ��?��Ⱥ����һ�����������,�����洢�������Ϣ,Ĭ����50������,ÿ���������Ḻ��һ�����������ȷ����������50���е��ĸ�����?��Ҫ����Ա�ֶ�����һ��transactional.id(ȫ��Ψһ),��transactional.id��hashcode%50����������ĸ�����,�÷���leader���ڵĽڵ����Ǹ������������������Ҫʹ�õ�
���Ǽ������ǵ�������3������,��ʹ��broker0�����������
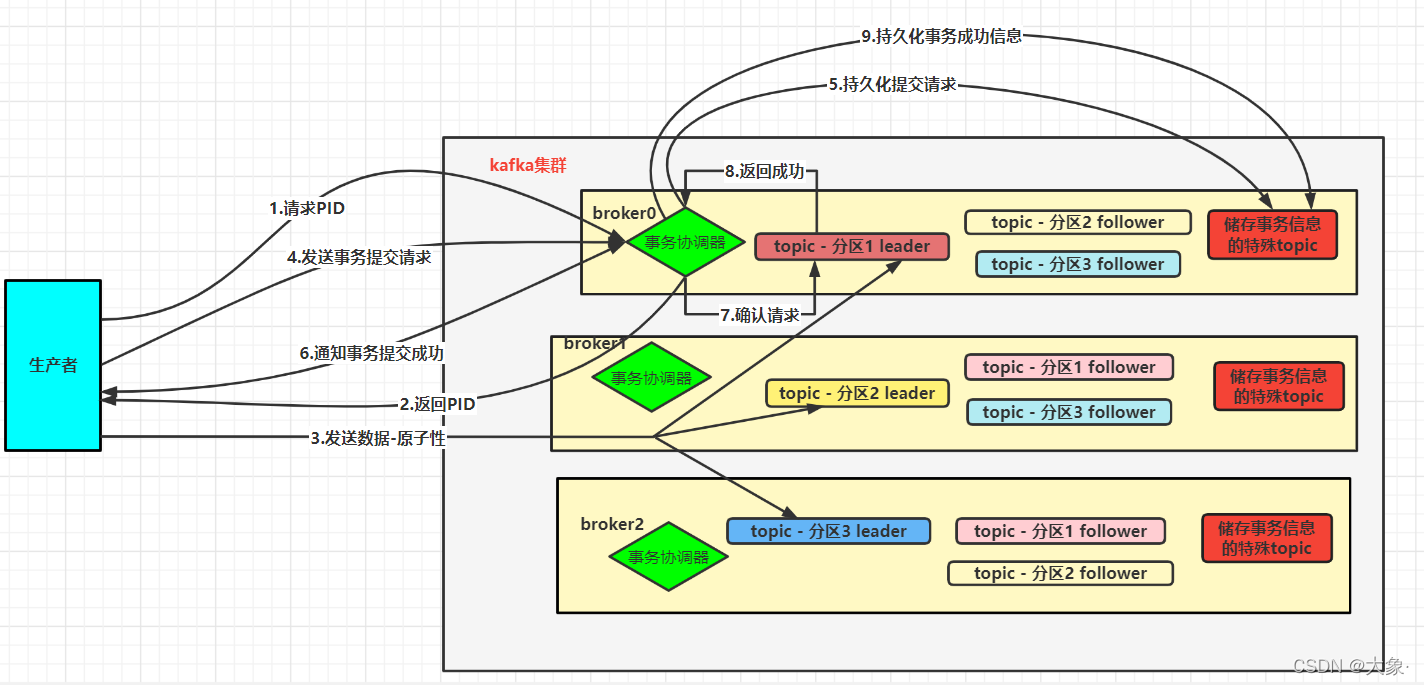
1.��Ϊ�����������ݵ���,��֤���������ڵ����ݲ��ظ�,��������������Ҫ������Э������ȡProducer ID,Ҳ��PID
2.����Э�������ص�ǰ��PID
3.�����������������Ⱥ�IJ�ͬ������������,��ԭ���Բ���
4.��������Э���������ύcommit����
5.����Э����֪ͨ�������������,������г־û�����,������֤�˿ͻ��˹��˺�,������������Լ�������δ��ɵ�����
6.����Э������֪�����������ύ�ɹ�
7.����Э�����ᷢ������ÿ������,ȷ��ÿ�������Ƿ��յ�������,ȷ������ɹ�
8.ÿ������Ӧ�������Э����,��֪һ������
9.����Э�����յ�֪ͨ��,�����������ִ�гɹ��־û�,ȷ��������ִ�и�������
IDEA ����
public class TransactionsTest {
public static void main(String[] args) {
// 1.��������
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.102:9092");
// ָ����Ӧ��key��value���л�
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// ָ������id ����ȡ,��Ψһ
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"100");
// 2.����������
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// 3.��ʼ������������
producer.initTransactions();
producer.beginTransaction();
try {
// 4.��������
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<>("first","Hello " + i));
}
// 5.�ύ����
producer.commitTransaction();
}catch (Exception e){
// ���쳣��ֹ����
producer.abortTransaction();
}finally {
// 6.�ر�������
producer.close();
}
}
}
7.��������ԭ��
�����֤����������,����������,�����������ָ�����߷��� 1 2 3,��Ⱥ�յ�������Ϊ1 2 3,������2 1 3 �ȵ�
ʲô������?
û�п����ݵ���,����û�����л���(���л��Ŵ���Ǻ�����,��Ϊ���л����ǵ�����)!��֪��˭������,˭������,���Ϊ�˱�֤����,ֱ��������ͼ������ֻ�ܴ�һ��,max.in.flight.requests.per.connection��Ҫ����Ϊ1,��ǰ����ɹ���ŷ�����һ������
�������ݵ��Բ���max.in.flight.requests.per.connection��Ϊ1,���赱����������ʱ,����1������,��������ʧ����,����2�ɹ���,��������1�ٴ�����ɹ���,1��2�ĺ�����,���ֻ��max.in.flight.requests.per.connectionֻ��Ϊ1
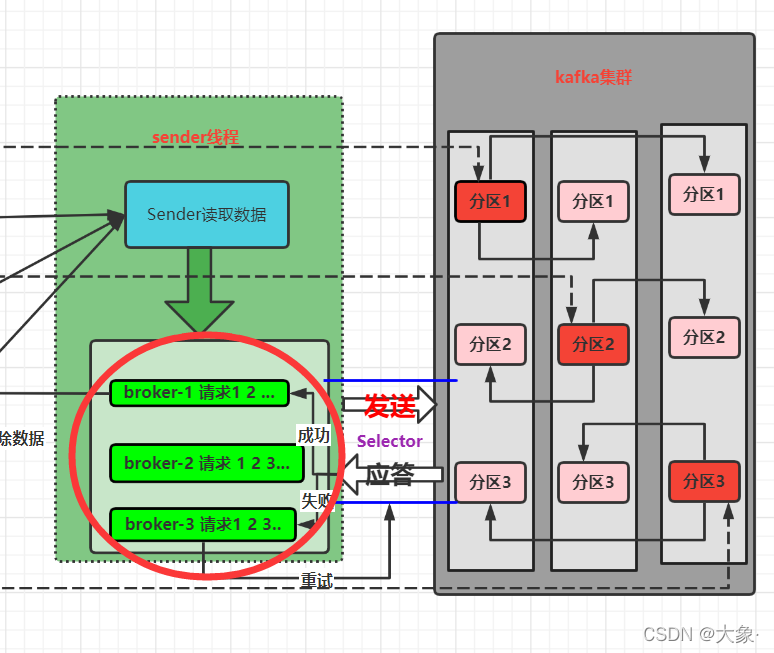
�������ݵ���,���ĺô��������л�����,���Ը������л����ж��Ⱥ���!
max.in.flight.requests.per.connection��Ҫ����С�ڵ���5,�����Ҿ��ܱ�֤���5������ʱ�������
�����ݵ���,���赱����������ʱ,����1������,��������ʧ����,����2�ɹ���,���Ǽ�Ⱥ֪����һ��Ӧ��������1,�����ڴ��������2,�ȴ�����1,��������1�ٴ�����ɹ���,����1�ŵ�ǰ��ȥ,������,��֤������
ע��,ֻ��֤�˷���������,�����ʵ�ַ���������,ֻ�����з������ݵ��˼�Ⱥ������
8.ZooKeeperһЩ��Ϣ
1.kafka/brokers/ids ���Կ�����Щ�ڵ���������

2.kafka/brokers/topics���Կ���ÿ�������ÿ��������leader��ISR
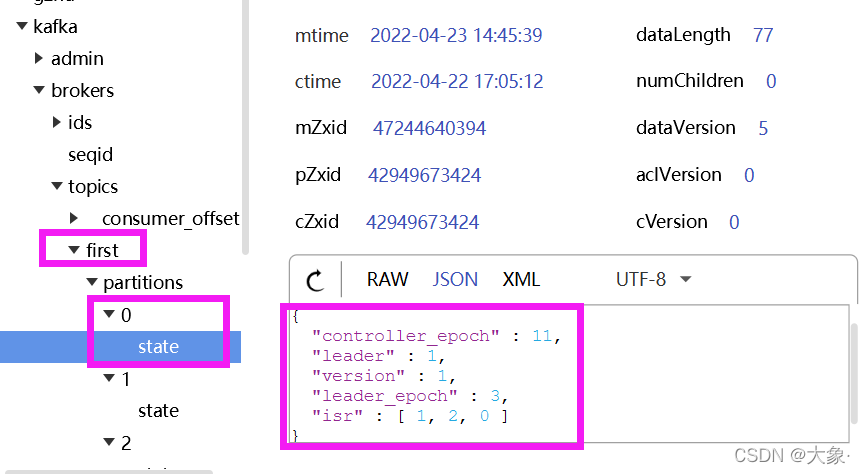
3.kafka/controller�Ǹ�����ѡ��leader��

���߽��ʹ��ԭ��
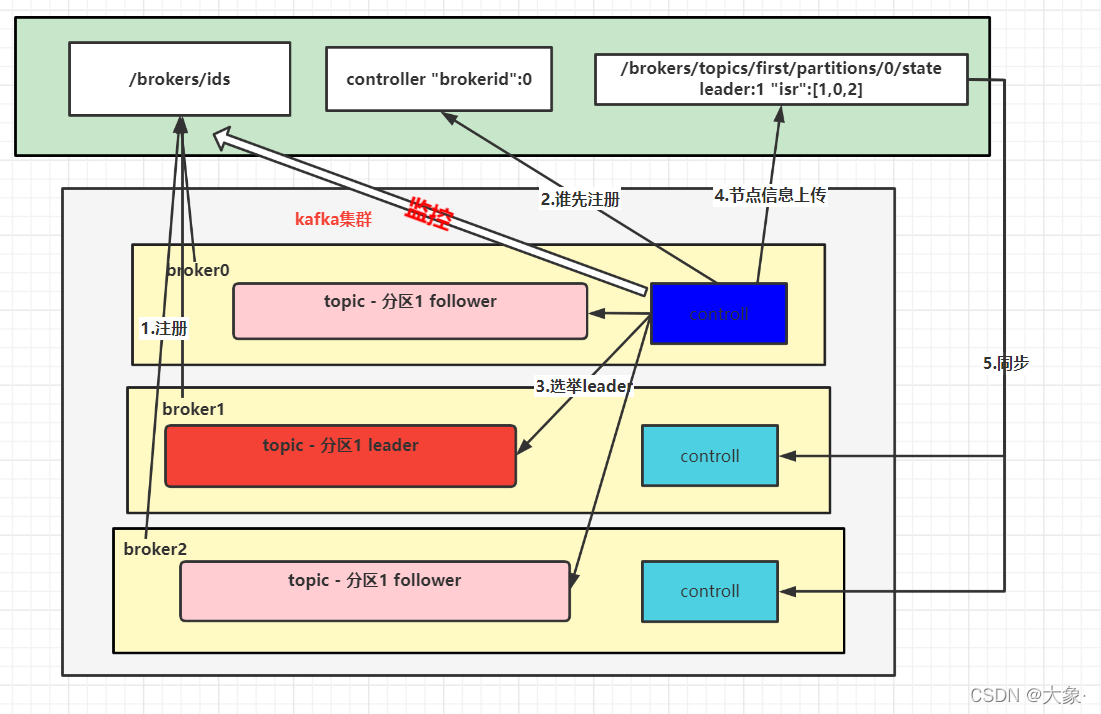
ÿ��kafka�Ľڵ����������/brokers/ids/ ע��,Ȼ��ÿ���ڵ㶼����controller������,��ȡ��ռʽ,�ĸ��ڵ��controller������,˭��˵����,Ȼ���ɸ�controller���ids������ÿ��������leaderѡ��,ѡ�ٹ���:��ISR���Ϊǰ��,˭��AR(Assigned Replicas) ������ǰ��˭����leader(AR:�������и���ͳ��),���ڷ���1,������ʱ��AR��������������[1,0,2],��ô�ͻ�ѡ��broker1����Ϊleader,Ȼ��controller�Ὣ������Ϣ�ϴ���zookeeper,�����controller��ͬ����Ϣ(��֤�ݴ���)
����leader����,controller��������,��ôcontroller��������ȡzookeeper�ϵ�ISR��Ϣ,����ѡ�ٹ����ٴ�ѡ��,�һ��ŵ�,������AR��ǰ��ľ����µ�leader
�����ڷ�������ô�洢��
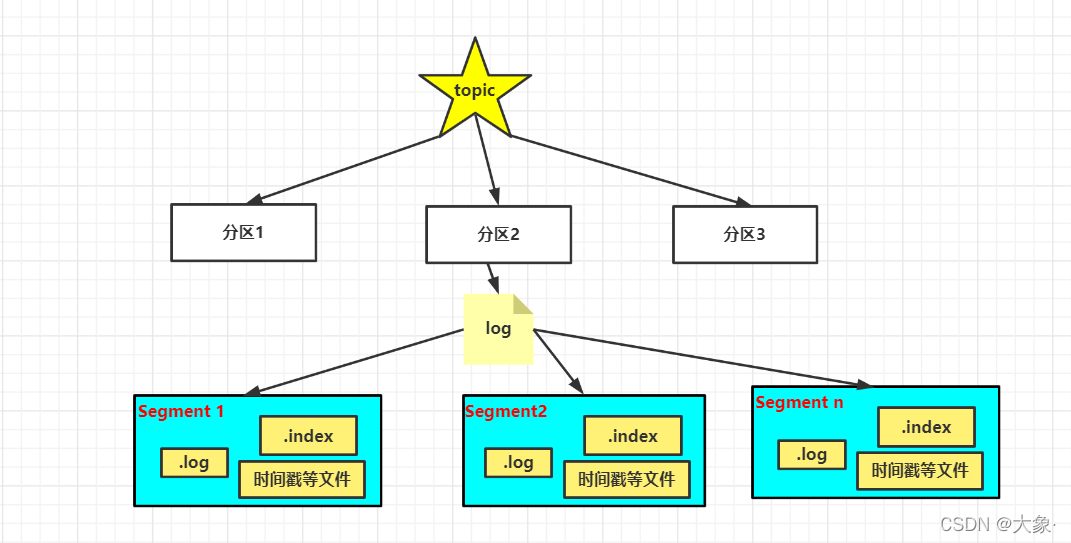
ʵ�������������ּӷ�����������
ÿ�����������и�log�ļ�,log���ж��Segment���,�����ߵ�topic�����ݾͱ�����Segment
��Segment(1G)Ϊ��λ�洢,Ϊ�˼ӿ�����ٶ�,���и�.index�ļ�,ʹ�������ӿ��ѯ�ٶ�,������ϡ������,����log�ļ�д��4kb����ʱ,index�Ż�����һ������,Ҳ������4kb����һ������,�����ݵ�ʱ�����ҵ�����ʱ�ĸ�������,Ȼ�����������Ϣȥlog����

�������
һ.ɾ��
ÿ��segment����������ݵ�ʱ���,����7��ɾ��(���ʱ�������),Ҳ��������������ݹ���,�Ż����,������Ķ�������,����Ŀ϶�������
��.ѹ��
�ʺ�K-V��������,������ͬ��key,valueֻ�������µ�value
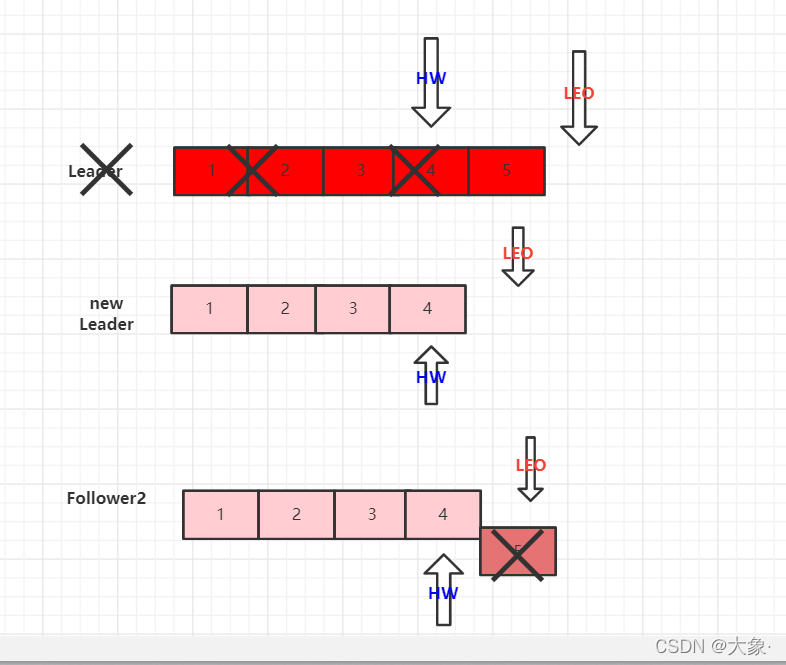
9.leader��followerͬ������
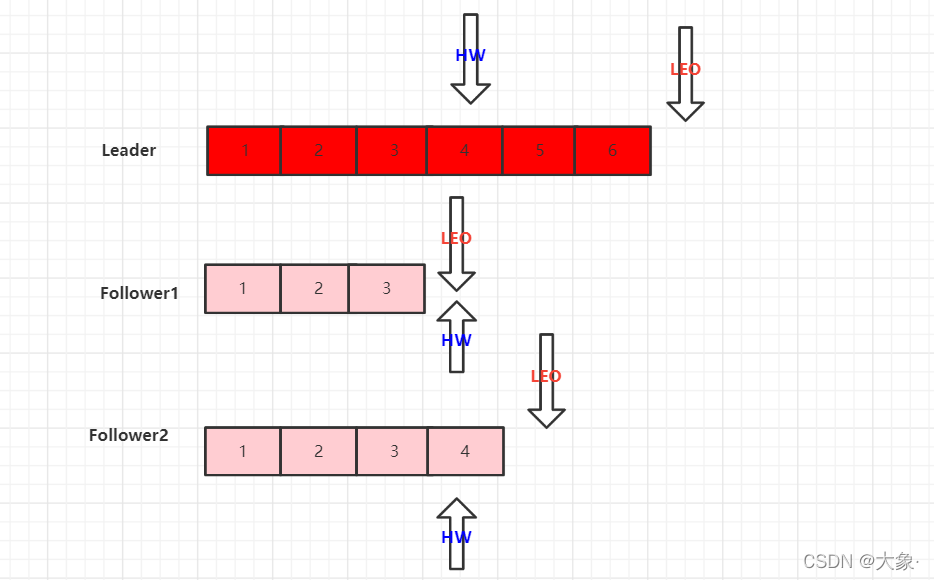
LEO(Log End Offset) : ÿ�����������һ��offset,��ͼ
HW(High Watermark):���и�����С��LEO,��ͼ��,Follower1��LEO��С,��ô���и�����HWΪ4��λ
Follower���ֹ���
������ͼ��,Follower2���ֹ���,ISR���ȻὫ�ڵ�ɾ��,����Follower1��Leader�������������
Follower2�ָ���,���ȡ���ش��̵�HW,�����ļ��и���HW�IJ���ɾ��,��Ϊ��������Щ����ûУ��,Ȼ��ʼͬ��Leader������,ֱ����Follower��LEO���ڵ��ڸ÷�����HW,���������Ļָ�,���뵽ISR
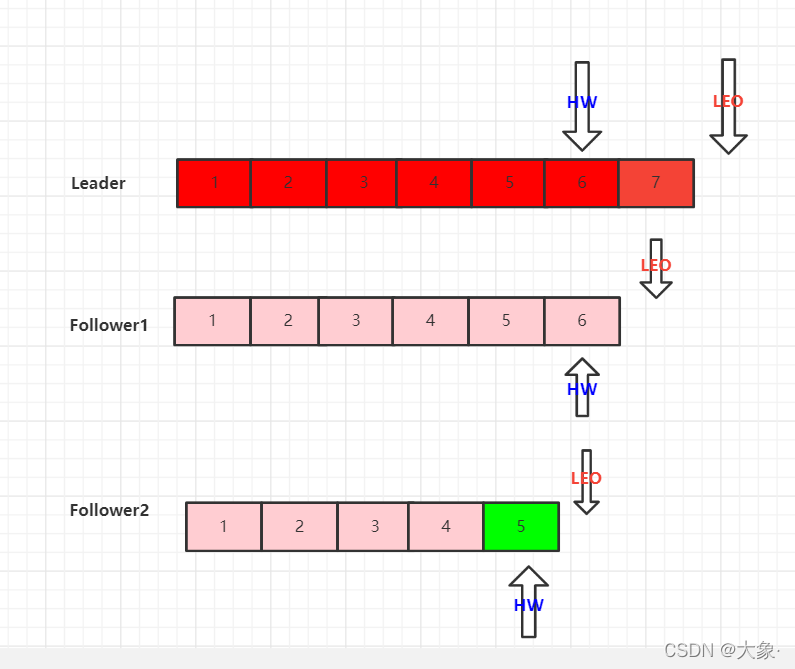
Leader���ֹ���
Leader���ֹ��Ϻ�,����ѡ�ٹ����ѡ��һ���µ�leader,��ô��ʱ��leader��LEO��HW��Ϊ�µı�,���е�follower�����ݶ�Ҫ���µ�leader����,Ҳ��follower��������ݵ����ݻᱻ����,������,�������ܻᵼ�����ݶ�ʧ
10.kafka��Ч��дԭ��
1.kafka�����Ƿֲ�ʽ,������������˲��ж�
2.���ݲ���ϡ������,���Կ��ٶ�λҪ���ѵ�����
3.kafkaд����ʱ�ӵ�log�����,��˳��д,д���ٶȷdz���,�ɴ�600M/s
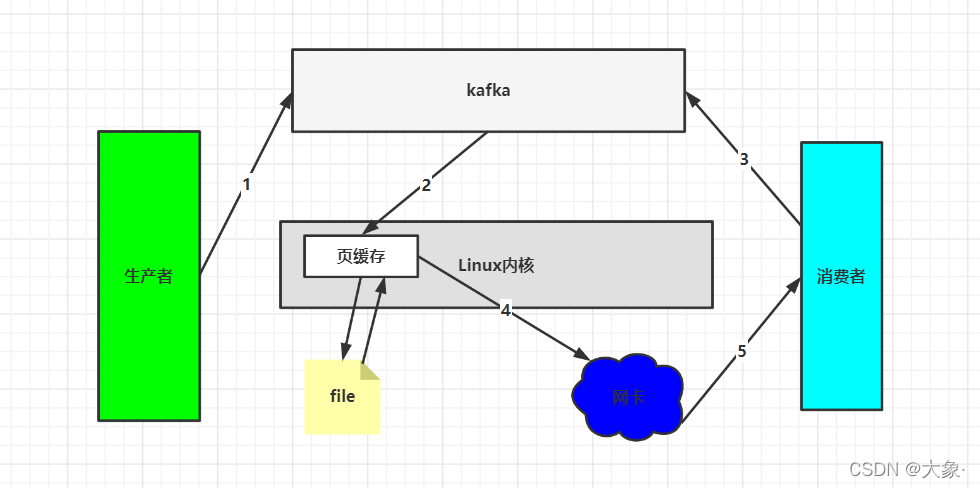
4.ҳ����+�㿽��
�����߽����ݷ��͵�kafka��,kafka�Ὣ���ݷ������ϵͳ��ҳ����(Page Cache��Linux�ں˹������ڴ�����)��,�ں����ڴ�����Ĺ���,�����Խ����ݳ־û������̻��������ڴ档����д����������ʱ��,kafka�ȿ�ҳ������û������,û�еĻ��Ӵ��̶�ȡ,Ȼ��ֱ��ͨ�����ظ�������(�����ڵ���漰����)������˵,��ȡ���ݲ���kafkaӦ�ò�,�����Ч��
11.������ԭ��
���ѷ�ʽ
������������kafka��ȡ����,ԭ��ܼ�,��ͬ�����ߵ������ٶȲ�ͬ,���Ը����Լ�����������,���kafka�����ݵĻ�,��Ϊ��һ���̶����ٶ�,������������������,����,kafkaû���ݵ�ʱ��,������һֱ����������,�Ǿ�һֱ���ؿ�,��������ѭ��
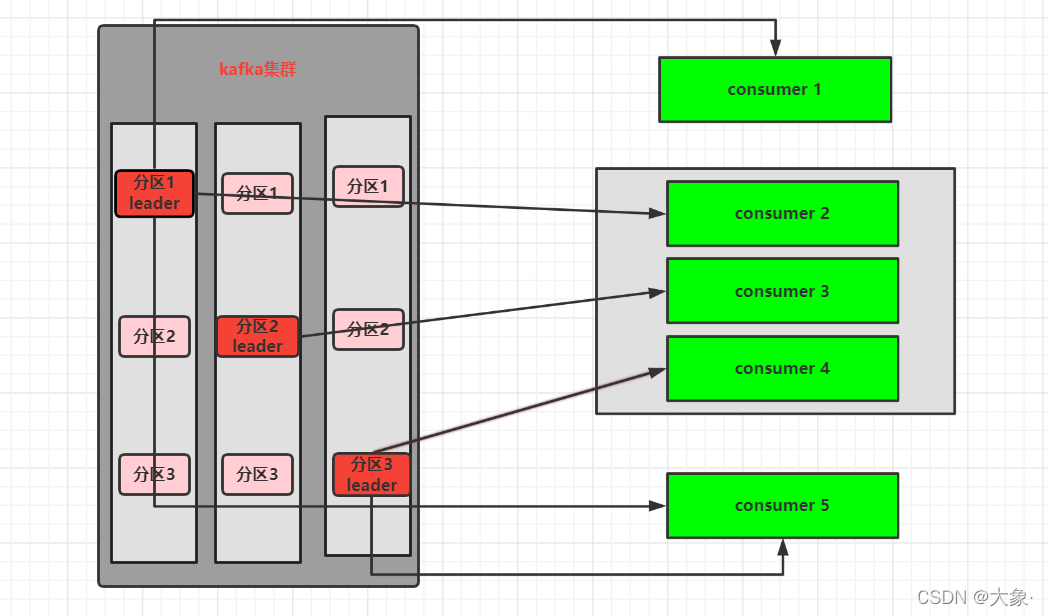
���ѹ���
���������߿���ͬʱ�����������������
����������������(�����ߵ�groupid��ͬ),ÿһ��ֻ��������δ���������������ѵķ���
���һ�����������ĵ������߸���С�ڷ�����,��ôһ�������߿������Ѷ������(ǰ���⼸������û�б�������������������)
�����������ĵ������߸������ڷ�����,һ��һ�պ�
�����������ĵ������߸������ڷ�����,�Ǿ��п��е���
offset
1.˭�ύ,�ύ������?
���Ѽ�¼��kafkaһ�����������,_consumer_offsets�洢,��¼ÿ���������ѵ�������(offset��ʶ),ʵ������ÿ��5��(�ɸ���)����ǰoffset�Զ�(Ҳ���������Լ��ֶ��ύ)�ύ����Ӧ������������K-V�洢,K��group.id+topic+������,value���ǵ�ǰoffset��ֵ,�������ܱ�֤ÿ�������߹�����������Լ���������
�Զ��ύoffset����
// �Ƿ��Զ��ύ offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,
true);
// �ύ offset��ʱ������ 1000ms,Ĭ�� 5s
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,
1000);
�ֶ��ύoffset����
// �Ƿ��Զ��ύ offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,
"false");
// ������Ϣ.........
// �첽�ύ offset �첽�ύ����offset����ȥ,����_consumer_offset���յ�û��,�Ϳ�ʼ������һ�������� ͬ���ύ����offset����ȥ,_consumer_offset���յ�,�ſ�ʼ������һ������
consumer.commitAsync();
2.offsetʹ��
����ͨ�����ò������涨���ʹ��offset
auto.offset.reset = earliest | latest | none Ĭ���� latest
- earliest:�Զ���ƫ��������Ϊ�����ƫ����,�Cfrom-beginning
- latest(Ĭ��ֵ):�Զ���ƫ��������Ϊ����ƫ����
- none:���δ�ҵ������������ǰƫ����,�����������׳��쳣��
- ����ָ��offsetλ�ƿ�ʼ����
�ֶ�ָ��offset
public class CustomConsumerSeek {
public static void main(String[] args) {
// 1.����
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");
// 2.�����л�
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
// 3.����������id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"100");
// 4.����������
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 5.��������
ArrayList<String> topics = new ArrayList<>();
topics.add("topicx");
consumer.subscribe(topics);
// 6.ָ��offset
// 6.1 ��ȡ��ǰ����ķ�����Ϣ
Set<TopicPartition> assignment = consumer.assignment();
// 6.2 ��֤�����Ѵ���
while(assignment.size() == 0){
consumer.poll(Duration.ofSeconds(1));
assignment = consumer.assignment();
}
// 6.3 ָ��offset
for(TopicPartition topicPartition : assignment){
consumer.seek(topicPartition,200);
}
// 6.����
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.partition()+" " + record.offset() + " "+ record.value());
}
}
}
}

ָ������һ��ʱ���ڵ�����(����offset��ʱ���)
public class CustomConsumerSeekTime {
public static void main(String[] args) {
// 1.����
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");
// 2.�����л�
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
// 3.����������id
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"1111");
// 4.����������
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 5.��������
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
consumer.subscribe(topics);
// 6.ָ��offset
// 6.1 ��ȡ��ǰ����ķ�����Ϣ
Set<TopicPartition> assignment = consumer.assignment();
// 6.2 ��֤�����Ѵ���
while(assignment.size() == 0){
consumer.poll(Duration.ofSeconds(1));
assignment = consumer.assignment();
}
// 6.3 ָ��offset��ʱ�� ÿ��������Ӧʱ��
HashMap<TopicPartition, Long> hashMap = new HashMap<>();
for(TopicPartition topicPartition : assignment){
hashMap.put(topicPartition,System.currentTimeMillis() - 24 * 3600 * 1000);
}
// ͨ��ʱ���ȡoffset
Map<TopicPartition, OffsetAndTimestamp> map = consumer.offsetsForTimes(hashMap);
// 6.4 ָ��offset
for(TopicPartition topicPartition : assignment){
OffsetAndTimestamp time = map.get(topicPartition);
consumer.seek(topicPartition,time.offset());
}
// 7.����
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
}
}
}
�ĸ������������ĸ�������?
1.Range����(���ÿ������):
���Ƚ�����ķ��������������,Ȼ��������Ҳ����
�����������7������t1-t7,����������C1-C3
Ȼ��ͨ��������/��������������ÿ��������Ӧ�����Ѽ�������,���������,��ôǰ�漸�������߽��������1������
7/3 = 2�� ����ÿ��������Ӧ������2��,���һ���ɵ�һ����������
Ҳ����C1����t1-t3 C2����t4-t5 C3����t6-t7,��������һ��C3����,��ô���������Ҫ���ѵķ��������Ȳ��ᱻ����,������45��,�ȹ���45���û�����Ѿ�ȷ����Ĺ���,��ôt6-t7�ᱻ�ֵ������������,ʵ����ƽ��
����������һ���������,����ܶ���������,��ôC1�������������������N��!����������б
2.RoundRobin����(�����������)
�����еķ��������е��������г���,����hashcode����,Ȼ��ͨ����ѯ�㷨����
�����и�������7������t1-t7,����������C1-C3,�����ź����
��t1��C1 t2��C2 t3��C3 t4��C1 t5��C2��
3. Sticky����
��Range���Բ�ͬ���Ƿ�����������,��������ֵ�ÿ������(7/3 = 2�� ����ÿ��������Ӧ������2��,���һ���ɵ�һ����������),Ҳ����C1��������t2 t3 t6 ,C2����t1 t4 C3����t5 t7
4.IDEA���÷�������
XX��ȫ����
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"XX")
�����߹���
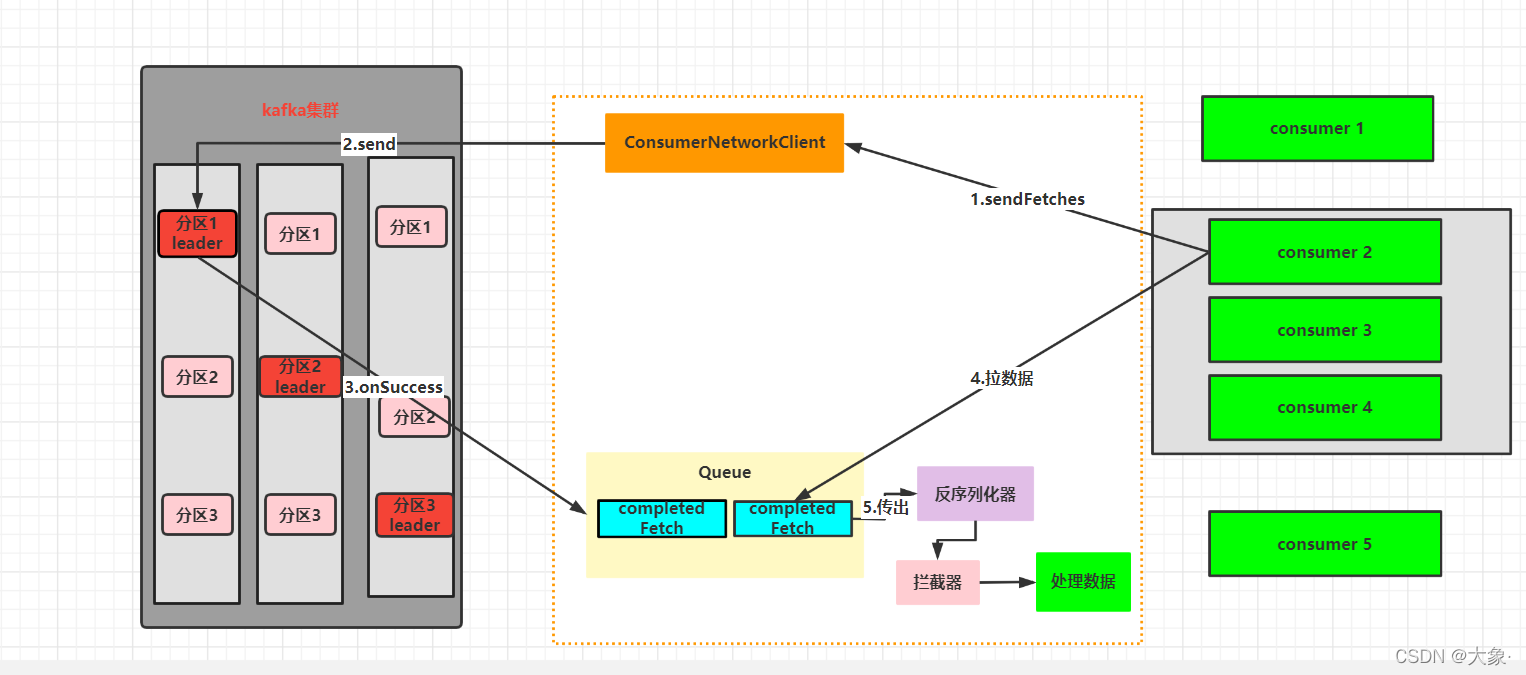
1.�����߷�����ȡ����ComsumerNetworkClient
2.������Ⱥ
3.���ȴ�ʱ�䳬��fetch.max.wait.ms(Ĭ��500ms)�����������γ���Fetch.min.bytes(Ĭ��1�ֽ�,�����50M)��Ⱥ�������ݵ�һ����Ϣ����
4.�����ߴӶ�������ȡ����,Ĭ�������500��
5.�������л�������������õ���������
���������������(���ݻ�ѹ����ô��)
1.���Ծ��������������� = ������
2.�������������ȡ�Ĵ�С
3.������Ҳ���Ե���4������������

