实验二 :HDFS+ MapReduce 数据处理与存储实验
1. 实验目的
- 了解HDFS的基本特性及其适用场景;
- 熟悉HDFS Shell常用命令;
- 学习使用HDFS的Java API,编程实现HDFS常用功能;
- 了解MapReduce中“Map”和“Reduce”基本概念和主要思想;
- 掌握基本的MapReduce API编程,并实现合并、去重、排序等基本功能;
2. 实验环境
实验平台:基于实验一搭建的虚拟机Hadoop大数据实验平台上的HDFS、MapReduce;
编程语言:JAVA(推荐使用)、Python等;
3. 实验内容
3.1 HDFS部分
查看命令使用方法
首先启动hadoop,打开终端输入start-dfs.sh
HDFS的命令行接口类似传统的Shell命令,可以通过命令行接口与HDFS系统进行交互,从而对系统中的文件进行读取、移动、创建等操作。命令行接口的格式如下:/bin/hadoop fs -命令 文件路径 或者/bin/hdfs dfs -命令 文件路径
在终端输入如下命令,查看hdfs支持的操作
cd /usr/local/hadoop-2.6.5/
./bin/hdfs dfs
可以看到hdfs命令的统一格式是hdfs dfs-"具体命令", 如dfs -ls
可以使用dfs -help命令查看具体用法,如dfs -help put
Hadoop 系统安装好后,第一次使用HDFS时,需要先在HDFS种创建用户目录。因为采用的是hadoop用户登录的Linux系统,需要在HDFS中为hadoop用户创建一个用户目录,命令如下:
./hdfs -mkdir -p /user/hadoop
该命令中表示在 HDFS中创建一个/user/hadoop目录,-mkdir是创建目录的操作,-p表示如果是多级目录,则父目录和子目录一起创建。
/user/hadoop目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:
./hdfs dfs -ls .
// 等价于
./hdfs dfs -ls /user/hadoop
该命令中-ls表示列出 HDFS某个目录下的所有内容,.表示HDFS中的当前用户目录,也就是/user/hadoop目录,因此,上面的命令和命令./hdfs dfs -ls /user/hadoop是等价的。
然后采用相对路径的方法,在用户目录下创建名为input的文件夹
./hdfs dfs -mkdir input
还可以使用rm命令删除一个目录,例如./hdfs dfs -rm -r user/hadoop/input 。上面命令中,-r参数表示如果删除/input目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用-r参数,否则会执行失败。
3.1.1 上传文件
向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件;
#创建存放该次作业目录
./hdfs dfs -mkdir lab2
# 查看是否目录是否创建成功
./hdfs dfs -ls /user/hadoop

#创建一个文本
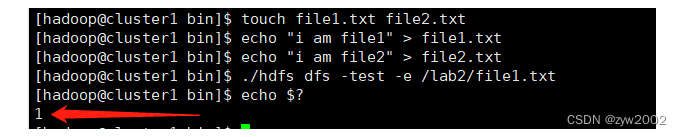
touch file1.txt file2.txt
#随便写入内容
echo "i am file1" > file1.txt
echo "i am file2" > file2.txt
#判断指定文件是否在hdfs存在
./hdfs dfs -test -e /lab2/file1.txt #-e 判断路径是否存在,如果路径存在,则返回0。
echo $? #shell中的特殊变量,用来查看上一个命令执行后的退出状态,0表示成功
#上传到HDFS
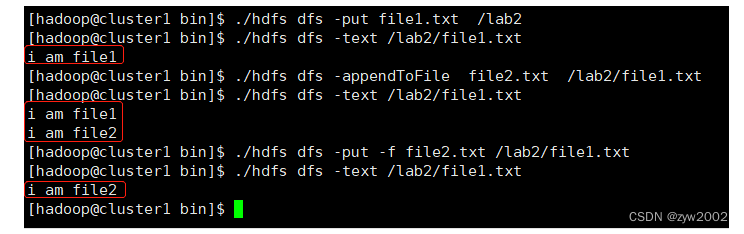
./hdfs dfs -put file1.txt /lab2
#查看上传后的文件内容
./hdfs dfs -text /lab2/file1.txt #cat也可以
#追加到原有文件末尾
./hdfs dfs -appendToFile file2.txt /lab2/file1.txt
#查看追加后的文件内容
./hdfs dfs -text /lab2/file1.txt
#覆盖原有的文件
./hdfs dfs -put -f file2.txt /lab2/file1.txt
#查看覆盖后的文件内容
./hdfs dfs -text /lab2/file1.txt
3.1.2 下载文件
从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
编辑shell脚本vi downloadfile.sh
#!/bin/bash
if $(hadoop fs -test -e /home/hadoop/lab2/file1.txt);
then $(hadoop fs -copyToLocal /lab2/file1.txt /home/hadoop/file1.txt);
else $(hadoop fs -copyToLocal /lab2/file2.txt /home/hadoop/file1.txt);
fi
# 给脚本加执行权限
chmod +x downloadfile.sh
# 然后执行脚本
sh downloadfile.sh
第一次执行该脚本后,会成功的将file1.txt下载到本地
第二次执行脚本时,由于本地已经存在file1.txt, 则自动为文件重命名为file2.txt
3.1.3 显示文件信息
显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息;
hadoop fs -ls /lab2/file1.txt
hadoop fs -ls -h /lab2/file1.txt
3.1.4 显示目录信息
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
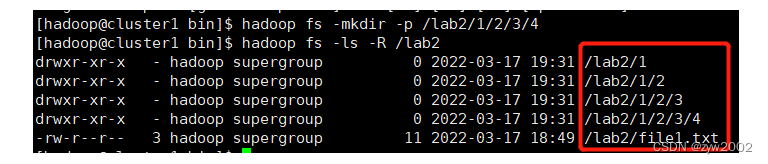
hadoop fs -mkdir -p /lab2/1/2/3/4 #-p 递归创建
hadoop fs -ls -R /lab2
3.1.5 删除文件
删除HDFS中指定的文件;
# 查看文件信息
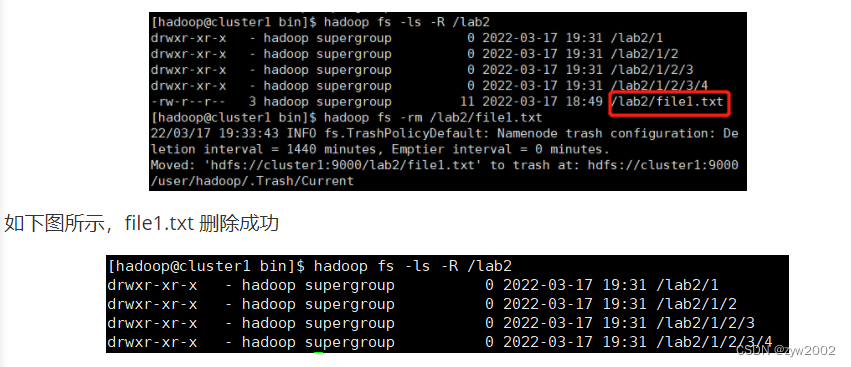
hadoop fs -ls -R /lab2
# 删除文件 /lab2/file1.txt
hadoop fs -rm /lab2/file1.txt
# 查看文件信息, 检查是否删除成功
hadoop fs -ls -R /lab2
3.1.6 移动文件
在HDFS中,将文件从源路径移动到目的路径。
# 重新上传file1.txt文件到HDFS
./hdfs dfs -put file1.txt /lab2
# 将 /lab2/file1.txt 复制到 /lab2/1/file1.txt,源文件仍然存在
./hdfs dfs -cp /lab2/file1.txt /lab2/1/file1.txt
# 查看文件信息
hadoop fs -ls -R /lab2
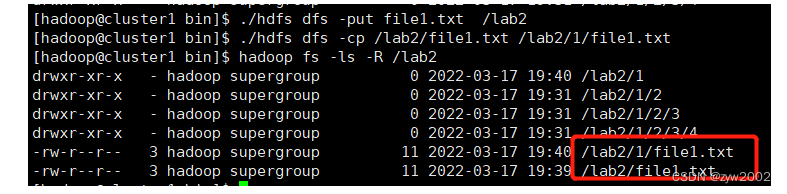
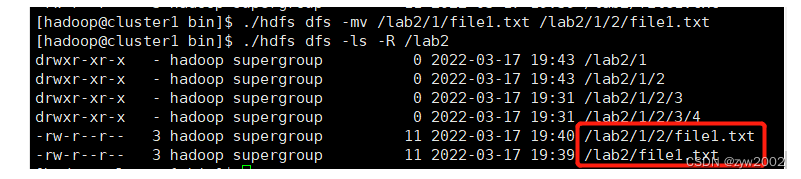
# 将 /lab2/1/file1.txt 复制到 /lab2/1/2/file1.txt,源文件不存在
./hdfs dfs -mv /lab2/1/file1.txt /lab2/1/2/file1.txt
# 查看文件信息
./hdfs dfs -ls -R /lab2
3.2 MapReduce 部分
3.2.0 Mapreduce 原理
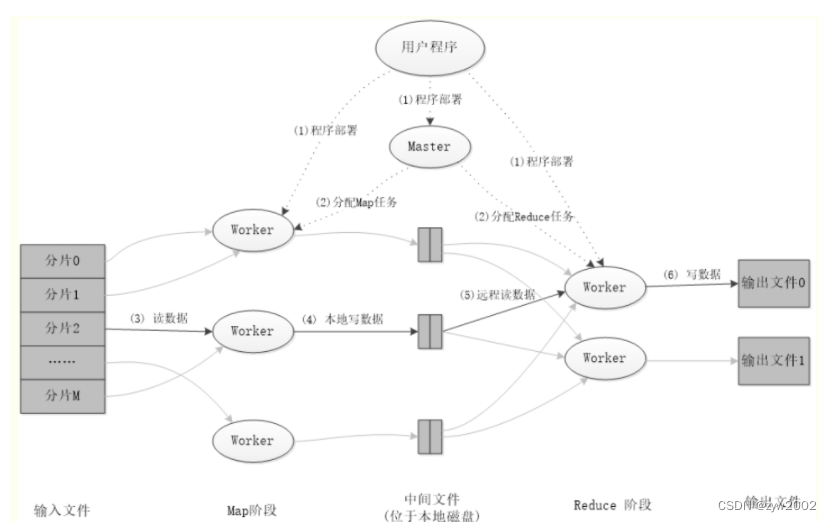
MapReduce是一个分布式、并行处理的计算框架。MapReduce 把任务分为 Map 阶段和 Reduce 阶段。开发人员使用存储在HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
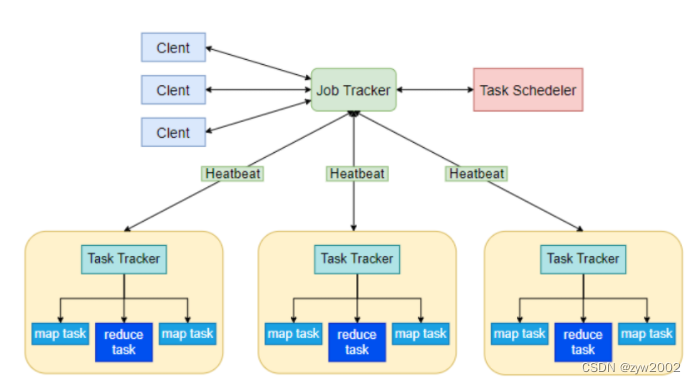
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。 其架构主要如下:
-
Client
用户编写的MapReduce程序通过Client提交到JobTracker端 用户可通过Client提供的一些接口查看作业运行状态。
-
JobTracker
JobTracker负责资源监控和作业调度 JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点 JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。
-
TaskTracker
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等) TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。
-
Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。
MapReduce的各个执行阶段:
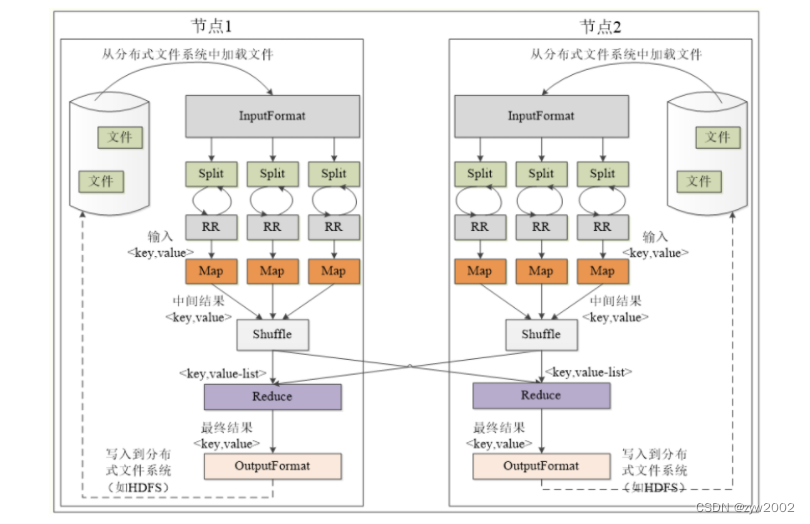
MapReduce应用程序的执行过程:
3.2.1 合并和去重
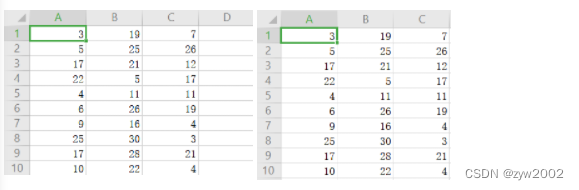
编写程序实现文件合并和去重操作;对于每行至少具有三个字段的两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。
其中文件A,文件B的格式如下
3.2.1.1 编写Merge.java代码
-
Map类
Mapper类是一个抽象类,位于
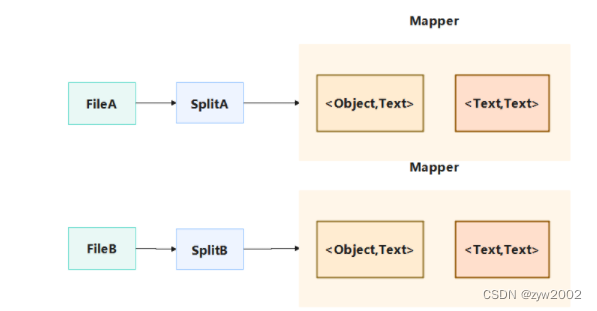
hadoop-mapreduce-client-core-2.x.x.jar中,其完整类名是:org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>,需派生子类使用,在子类中重写map方法:map(KEYIN key,VALUEIN value,Mapper.Context context)对出入的数据分块每个键值对调用一次。Mapper类从分片后传出的上下文中接收数据,数据以类型<Object,Text>的键值对接收过来,通过重写map方法读取数据并且以<key,value>形式进行遍历赋值。
Mapper的工作流程如下:
Map类的具体实现如下:
/* Map类,对Mapper抽象类进行具体的实现 KEYIN:是map阶段输入的key (Object基类) VALUEIN:是map阶段输入的value (原始文本) KEYOUT:是map阶段输出的key (合并后的文本) VALUEOUT:是map阶段输出的value (空文本) */ public static class Map extends Mapper<Object, Text, Text, Text> { private static Text text = new Text(); // 新建文本类型的text对象 public void map(Object key, Text value, Context content) throws IOException, InterruptedException { text = value; // 将value值赋给text content.write(text, new Text("")); // 输出的键值对为<Text,Text>,其中只有第一个元素含有有效文本 } } -
Reduce类
Reduce类是一个抽象类,位于
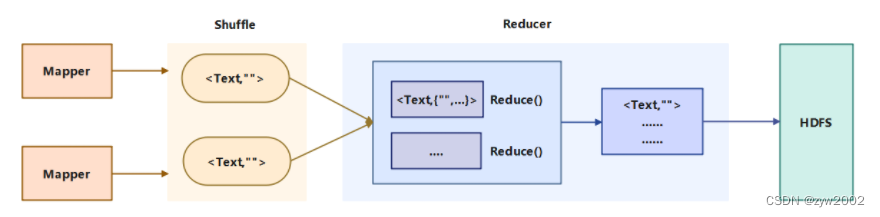
hadoop-mapreduce-client-core-2.x.x.jar中,其完整类名是:org.apache.hadoop.mapreduce.Reduce<KEYIN,VALUEIN,KEYOUT,VALUEOUT>,需派生子类使用,在子类中重写reduce方法:reduce(KEYIN key,Inerable <VALUEIN> value,Reducer.Context context)对出入的数据分块每个键值对调用一次。Reduce类主要是接受Map任务输出的数据,中间经过Shuffle的分区、排序和分组。最终进入Reducer进行规约处理,第一步规约会把key相同的合并在一起,value是一个list集合。第二步规约对于每个键值,只保留一个value, 因此达到了去重的目的。然后再把合并去重后的文件写入HDFS中,具体的流程如下图所示:
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// reduce的工作就是规约处理,对于Key值相同的键值对,值存入一个(不会出现重复的数据,因此保证了去重操作)
context.write(key, new Text(""));
}
}
-
Main方法
main 方法中主要是设置先前定义好的Map和Reduce类,并生成运行的主类Merge, 然后提交Job的任务,并等待任务完成,将结果输出到指定的文件路径下。
/* main方法 */ public static void main(String[] args) throws Exception { // 初始化信息设置 final String INPUT_PATH = "zyw_lab2_input";// 定义全局的输入目录 final String OUTPUT_PATH = "zyw_lab2_output";// 定义全局的输出目录 Configuration conf = new Configuration(); // 生成配置对象 // conf.set("fs.defaultFS", "hdfs://localhost:9000"); Path path = new Path(OUTPUT_PATH); // 生成路径对象 FileSystem fileSystem = path.getFileSystem(conf); // 加载配置文件 if (fileSystem.exists(new Path(OUTPUT_PATH))) { fileSystem.delete(new Path(OUTPUT_PATH), true);// 输出目录若存在则删除 } // Job提交代码 Job job = Job.getInstance(conf, "Merge"); // 获取Job实例 job.setJarByClass(Merge.class); // 设置运行的主类 Merge job.setMapperClass(Map.class); // 设置Mapper的主类 job.setReducerClass(Reduce.class); // 设置Reduce的主类 job.setOutputKeyClass(Text.class); // 设置输出key的类型 job.setOutputValueClass(Text.class); // 设置输出value的类型 FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); // 设置文件的输入路径 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); // 设置计算结果的输出路径 System.exit(job.waitForCompletion(true) ? 0 : 1); // 提交任务并等待任务完成 }
3.2.1.2 编译执行
然后用xftp软件将Merge.java ,data1.csv,data2.csv(实验数据改成英文名了,内容不变)文件上传到/home/hadoop目录下
在cluster1的/home/hadoop 目录下创建文件夹zyw_lab2_input 和zyw_lab2_output 分别存放实验数据(data1.csv / data2.csv )和输出结果。
$ cd ~
// 创建输入文件夹
mkdir zyw_lab2_input
// 创建输出文件夹
mkdir zyw_lab2_output
// 将数据文件移动到输入文件夹内
mv data1.csv zyw_lab2_output/
mv data2.csv zyw_lab2_output/
// 查看文件是否移动成功
ls zyw_lab2_output
// 构造新的命令zyw_javac
alias zyw_javac="javac -cp /usr/local/hadoop-2.6.5/share/hadoop/common/*:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/*:"
// 构造新的命令zyw_java
alias zyw_java="java -cp /usr/local/hadoop-2.6.5/share/hadoop/common/*:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/*:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/yarn/*:"
//编译
zyw_javac Merge.java
//运行
zyw_java Merge
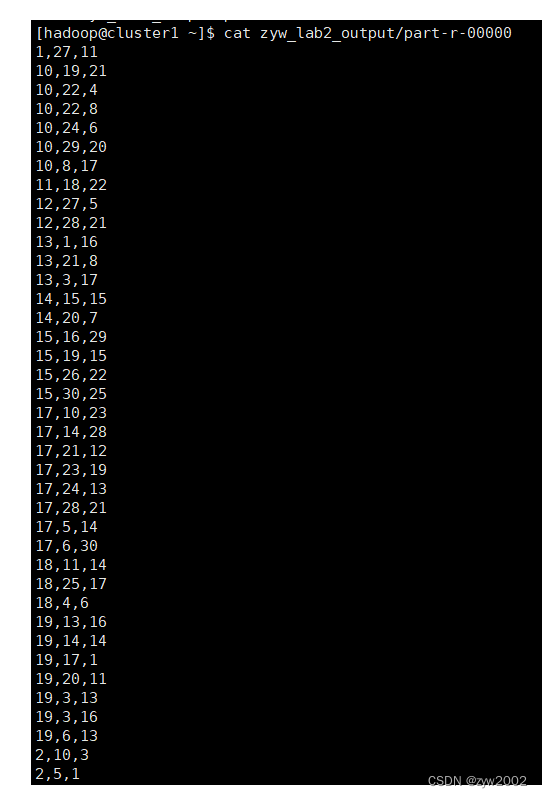
查看输出结果,说明文件合并去重成功。
3.2.2 文件的排序
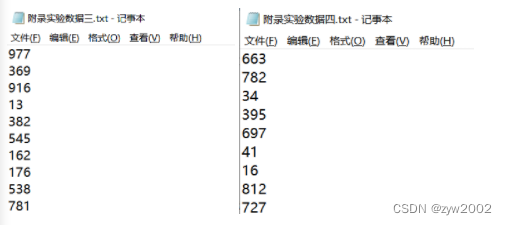
编写程序实现对输入文件的排序;现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取文件D和E中的整数,进行升序排序后,输出到一个新的文件F中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。
其中数据的格式如下:
3.2.2.1 编写Sort.java 代码
-
Partition类
hadoop默认是根据散列值来派发,但是实际中,这并不能很高效或者按照我们要求的去执行任务。我们继承Partitioner的类来实现自定义的分配方式,使得每个节点的Reducer尽量均衡。同时我们还要保证Partition之间是有序的。即保证Partition1的最大值小于Partition2的最小值
/*
Partition 类
*/
public static class Partition extends Partitioner<IntWritable, IntWritable> {
@Override
public int getPartition(IntWritable key, IntWritable value, int numPartitions) {
int MaxNumber = 65223; // 最大记录数
int bound = MaxNumber / numPartitions + 1; // bound= 最大记录数除以要分组的个数,然后向上取整
int keynumber = key.get(); // 得到键值key
for (int i = 0; i < numPartitions; i++) {
if (keynumber < bound * i && keynumber >= bound * (i - 1))
return i - 1; // 根据key值的大小分配到不同的组中
}
return 0;
}
}
-
SortMapper类
继承Mapper抽象类,并重写map方法
SortMapper类的具体实现如下:
/* Map类,对Mapper抽象类进行具体的实现 KEYIN:是map阶段输入的key (Object) VALUEIN:是map阶段输入的value (Text,文本类型) KEYOUT:是map阶段输出的key (IntWritable,整形) VALUEOUT:是map阶段输出的value (IntWritable,整形) */ public static class SortMapper extends Mapper<Object, Text, IntWritable, IntWritable> { private static IntWritable data = new IntWritable(); // 创建一个整形的数据data public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // 重写map方法 String line = value.toString(); // 将value的值转换为字符串的格式 data.set(Integer.parseInt(line)); context.write(data, new IntWritable(1)); // 写入键值对<data,1> } }-
SortReducer类
继承抽象类Reduce,并对其中的reduce方法重写。
public static class SortReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { private static IntWritable linenum = new IntWritable(1); // linenum记录在原始的数据中的排列次序 public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { for (IntWritable val : values) { // 遍历value中的数 context.write(linenum, key); // 写入键值对<排列次序,原始值> linenum = new IntWritable(linenum.get() + 1); // 排列次序递增1 } } }- main 类
public static void main(String[] args) throws Exception { final String INPUT_PATH = "zyw_lab2_input2";// 输入目录 final String OUTPUT_PATH = "zyw_lab2_output2";// 输出目录 Configuration conf = new Configuration(); // 配置信息 // conf.set("fs.defaultFS", "hdfs://localhost:9000"); Path path = new Path(OUTPUT_PATH); // 创建path对象 FileSystem fileSystem = path.getFileSystem(conf); // 设置配置文件 if (fileSystem.exists(new Path(OUTPUT_PATH))) { // 输出目录若存在则删除 fileSystem.delete(new Path(OUTPUT_PATH), true); } // 分配并执行Job任务 Job job = Job.getInstance(conf, "Sort"); job.setJarByClass(Sort.class); job.setMapperClass(SortMapper.class); job.setPartitionerClass(Partition.class); job.setReducerClass(SortReducer.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true) ? 0 : 1); } -
3.2.2.2 编译执行
然后用xftp软件将Sort.java ,data3.txt,data2.txt(实验数据改成英文名了,内容不变)文件上传到/home/hadoop目录下
在cluster1的/home/hadoop 目录下创建文件夹zyw_lab2_input2 和zyw_lab2_output2 分别存放实验数据(data3.txt/ data4.txt )和输出结果
cd ~
// 创建输入文件夹
mkdir zyw_lab2_input2
// 创建输出文件夹
mkdir zyw_lab2_output2
// 将数据文件移动到输入文件夹内
mv data3.txt zyw_lab2_input2/
mv data4.txt zyw_lab2_input2/
// 查看文件是否移动成功
ls zyw_lab2_input2
// 编译
zyw_javac Sort.java
// 运行
zyw_java Sort
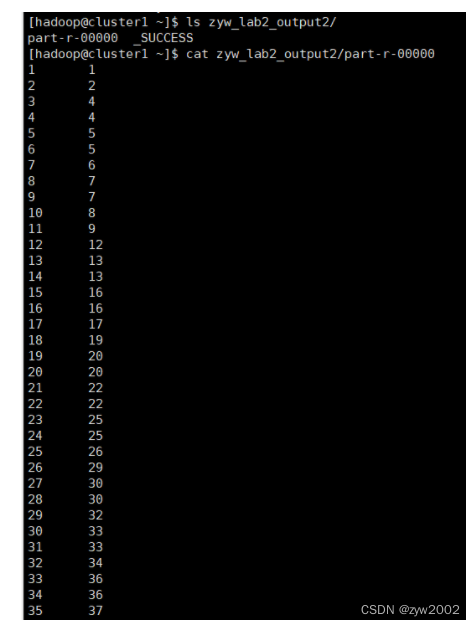
查看输出结果
ls zyw_lab2_output2/
cat zyw_lab2_output2/part-r-00000
发现排序成功,第一列是序号,第二列是真实值,升序排列。
4. 踩坑记录
【问题背景】编译java文件的时候出现API已过时的提示
【解决思路】首先为了查看具体的报错信息,根据提示在编译的时候添加-Xlint:deprecation 后缀,然后重新编译。
zyw_javac Sort.java -Xlint:deprecation
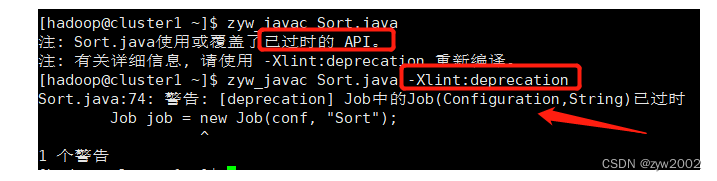
发现是第74行的Job(Configuration,String)已经过时,
【解决方案】
-
方案1 ―― 添加注解
@SuppressWarnings("deprecation") Job job = new Job(conf, "Sort"); -
方案2 ―― 使用
Job.getInstance(Configuration conf,String jobName )静态方法,创建job对象:Job job = Job.getInstance(conf, "Sort");
修改完代码后,重新编译成功。
5. 心得体会
通过这次实验学习到了hdfs的基本命令的使用以及mapreduce的工作原理。在做hdfs部分,首先我学习了一些hdfs的基本命令,如一些文件操作和目录操作。在熟悉了这些基本的操作之后,又去学了一些shell脚本的编写语法和小的demo, 了解了shell的工作原理。然后将二者贯通在一起,实现用脚本的方法实现hdfs操作。在做mapreduce的时候,首先重点回顾了老师上课讲的原理部分,原理的理解是实现代码的基础,更进一步的理解了在map阶段,reduce阶段的工作方式,以及对键值对<key,value>的处理过程。由于之前并未系统的学过java, 在编写代码上,进一步熟悉了java语言。然后小组内的同学在讨论过程中一如既往的积极,比如有同学找到优质的资源或者文档会在群里分享,有问题大家都帮忙找找解决方案,互帮互助的氛围促使我们每一个人都不断的进步。
6. 源码附录
6.1 Merge.java 完整代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class Merge {
// Map类,继承自Mapper类--一个抽象类
public static class Map extends Mapper<Object, Text, Text, Text> {
private static Text text = new Text();
// 重写map方法
public void map(Object key, Text value, Context content) throws IOException, InterruptedException {
text = value;
// 底层通过Context content传递信息(即key value)
content.write(text, new Text(""));
}
}
// Reduce类,继承自Reducer类--一个抽象类
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 对于所有的相同的key,只写入一个,相当于对于所有Iterable<Text> values,只执行一次write操作
context.write(key, new Text(""));
}
}
// main方法
public static void main(String[] args) throws Exception {
final String INPUT_PATH = "zyw_lab2_input";// 输入目录
final String OUTPUT_PATH = "zyw_lab2_output";// 输出目录
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://localhost:9000");
Path path = new Path(OUTPUT_PATH);
// 加载配置文件
FileSystem fileSystem = path.getFileSystem(conf);
// 输出目录若存在则删除
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "Merge");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class); // 初始化为自定义Map类
job.setReducerClass(Reduce.class); // 初始化为自定义Reduce类
job.setOutputKeyClass(Text.class); // 指定输出的key的类型,Text相当于String类
job.setOutputValueClass(Text.class); // 指定输出的Value的类型,Text相当于String类
FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); // FileInputFormat指将输入的文件(若大于64M)进行切片划分,每个split切片对应一个Mapper任务
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
6.2 Sort.java 完整代码
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.fs.FileSystem;
public class Sort {
public static class Partition extends Partitioner<IntWritable, IntWritable> {
@Override
public int getPartition(IntWritable key, IntWritable value, int numPartitions) {
int MaxNumber = 65223;
int bound = MaxNumber / numPartitions + 1;
int keynumber = key.get();
for (int i = 0; i < numPartitions; i++) {
if (keynumber < bound * i && keynumber >= bound * (i - 1))
return i - 1;
}
return 0;
}
}
public static class SortMapper extends Mapper<Object, Text, IntWritable, IntWritable> {
private static IntWritable data = new IntWritable();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class SortReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private static IntWritable linenum = new IntWritable(1);
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
for (IntWritable val : values) {
context.write(linenum, key);
linenum = new IntWritable(linenum.get() + 1);
}
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
final String INPUT_PATH = "zyw_lab2_input2";// 输入目录
final String OUTPUT_PATH = "zyw_lab2_output2";// 输出目录
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://localhost:9000");
Path path = new Path(OUTPUT_PATH);
// 加载配置文件
FileSystem fileSystem = path.getFileSystem(conf);
// 输出目录若存在则删除
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
//Job job = new Job(conf, "Sort");
Job job = Job.getInstance(conf, "Sort");
job.setJarByClass(Sort.class);
job.setMapperClass(SortMapper.class);
job.setPartitionerClass(Partition.class);
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); // FileInputFormat指将输入的文件(若大于64M)进行切片划分,每个split切片对应一个Mapper任务
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

