Redis之消息队列的实现
消息队列一直是中间件三剑客(Redis、MQ、MySQL)中的重要一环,它能够实现异步、削峰、解耦等功能,特别在一些分布式系统架构中优势发挥的淋漓尽致,目前比较成熟的消息中间件种类很多如RabbitMQ、RocketMQ、ActiveMQ、Kafka等,而我们的缓存利器Redis也有对于消息队列的实现,简单概括为一种模式两种数据类型,一种模式指的是发布订阅模式(pub/sub),两种数据类型指的是List和Streams 。
消息队列的需求
一个消息队列在生产上的使用一般需要满足三个需求,保证消息的有序性、保证消息不会重复消费、保证消息的可靠性。
消息有序性
消费者虽然是异步执行,但如果消费顺序和生产顺序不一致可能造成业务错乱,如存在生产者按顺序生产了三个事件,事件A更新商品库存为10,事件B读取商品库存,事件C更新商品库存为5,按照顺序事件B读取的是事件A的更新结果,如果事件A更新后事件B还未读取商品库存事件C先更新了,那么事件B读取的商品库存就是事件C的更新结果,这样就会造成业务错乱。
消息的重复消费
消费者从消息队列中读取消息时,可能因为网络阻塞导致消息重复发送,这时消费者会收到多条重复的消息,如果没有做消息的重复性校验那么将执行多次重复逻辑,如果是插入数据库那么将存在多条重复记录,影响业务正常流转。
消息的可靠性
消息的可靠性主要指消费者在处理消息时,因为服务器宕机导致消息未处理完毕,而下次重启时因为未处理完毕的消息在宕机前是从消息队列中读取了,所以宕机后不会重新消费,这就导致了未处理完毕消息丢失。
发布订阅模式Pub/Sub
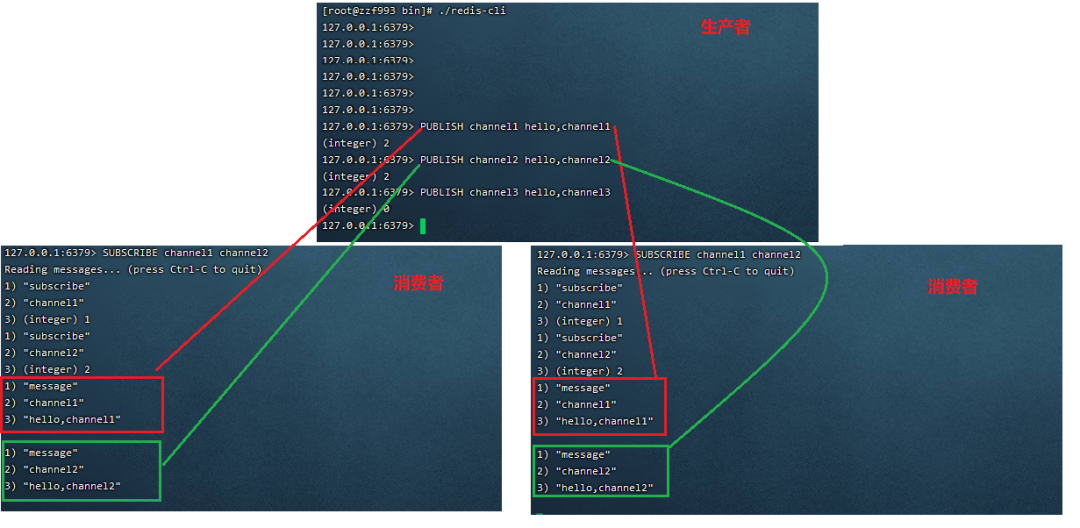
发布订阅模式是一种消息通信模式,生产者(pub)发布消息,消费者(sub)消费消息,结构图如下所示。

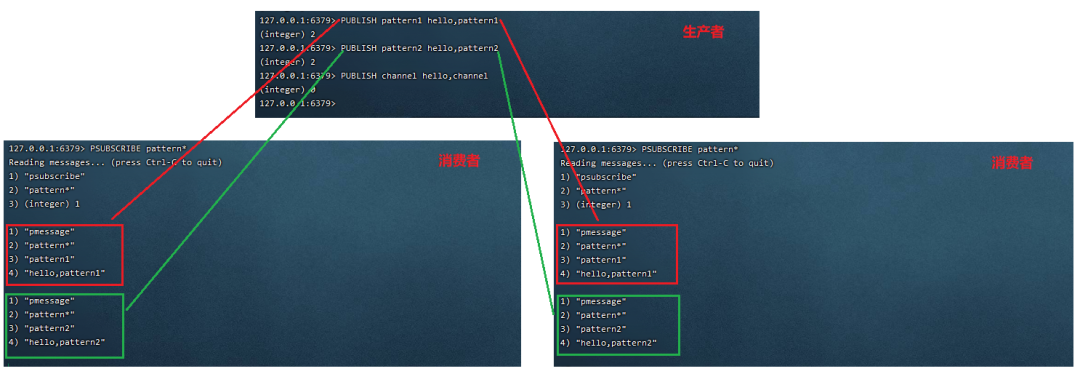
消息订阅分两种类型普通订阅以及模式订阅,普通订阅需要指定频道的名字(名字可以是多个),而模式订阅支持频道名字模糊匹配,命令演示如下。
普通订阅,消费者在订阅频道时必须指定频道的名称,不然生产者发布非指定频道的名称消费者无法接收到数据
模式订阅,不需要消费者指定到底是什么频道,可以采用模糊匹配的形式如PSUBSCRIBE pattern*。
发布订阅模式Pub/Sub使用简单,但是有个很大的缺陷就是无法持久化消息,消费者下线或者Redis宕机会导致消息丢失,这也导致了很多公司在技术选型上不会考虑RedisPub/Sub发布订阅模式的主要原因。
List实现消息队列
既然无法采用发布订阅模式实现消息队列的需求,那么在redis5.0之前我们可以采用List来做补偿方案。
实现消息有序性
List自身就是有序的,如果List类型入队采用Lpush出队采用Rpop这就是一个完整的队列,可以实现先进先出的效果,流程如下所示。
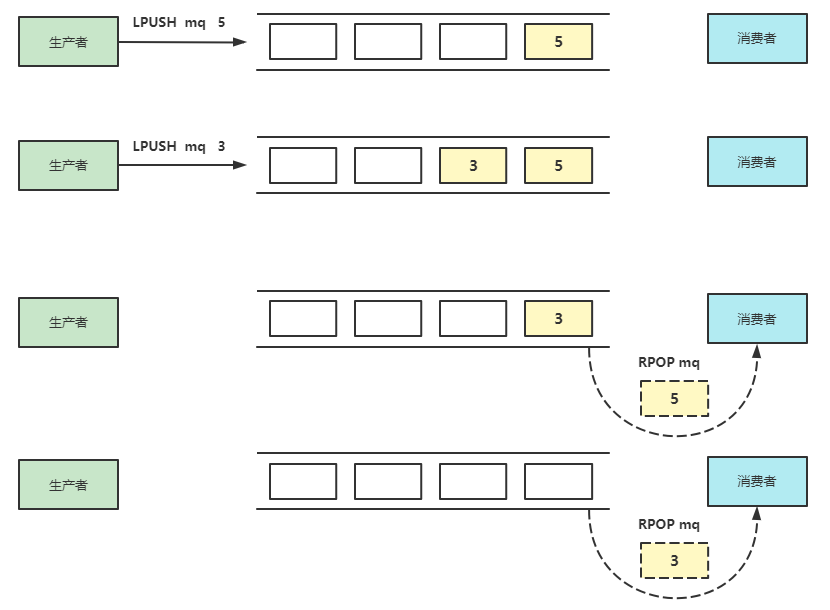
List用自身的特性保证了有序性,但是有一个问题在出队时消费者需要轮询消息队列,无论消息队列是否有值都需要轮询显然这是对资源的消耗不太合理,所以Redis中可以使用阻塞式读取命令BRPOP当消息队列是空时会阻塞等待,当消息队列有后会重新出队。
消息的重复消费
生产者可以创建唯一性ID来标识这个消息,消费者需要存储已经消费的消息ID列表,每处理一个消息需要对比消息ID在已消费列表中是否存在,如果ID已存在那么该消息不会再处理,这也是幂等性的保证。
消息的可靠性
消息的可靠性保证可以在消费者出队一个消息后将这个消息保存到未完成的队列中,只有当消费者处理完毕才从未完成的队列中移除,其核心思想就是采用BRPOPLPUSH备份。
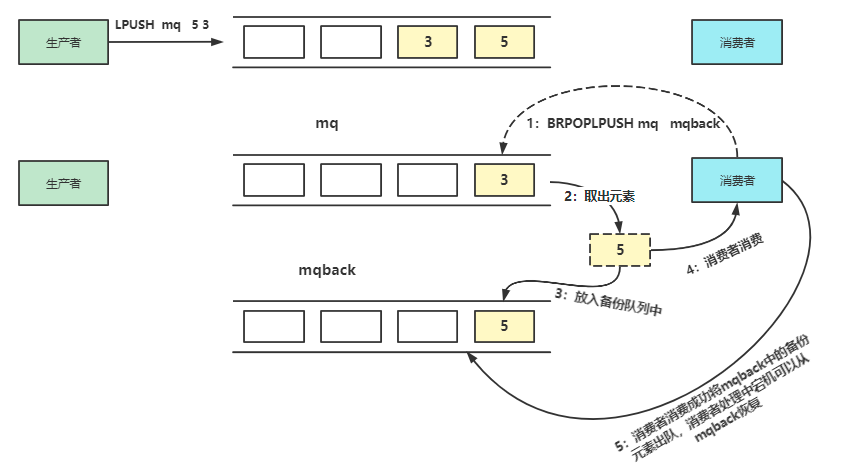
对于List可以简单满足消息队列的需求,但需要注意的是List处理消息队列肯定不能多个消费者一起消费,不然消息的有序性得不到保证,如果生产者的速度过快,而消费者的速度慢就会造成消息堆积,在Redis内存带来巨大的压力,所以在这种场景下需要考虑多个消费者共同分担压力的问题,这就需要依靠5.0 版本开始提供的Stream解决。
Streams实现消息队列
Stream是Redis5.0新增的数据结构,它提供了消息的持久化以及主备复制功能,可以让任何客户端访问任何时刻的数据,它有一个消息链表可以将所有加入的消息串起来,每个消息都存在一个唯一ID,并且这个ID是递增的。

last_delivered_id:游标,记录的是消息的id,游标到哪里就表示消费到哪里了。
pending_ids :消费者的状态变量,表示已经被消费者读取但是还没被消费者确认(ACK)的事件id。
简单消费
简单消费只针对单一的消费者而言,不需要创建消费组,命令演示如下
##?创建一个消息??*表自动创建id
127.0.0.1:6379>?xadd?mystream?*?f1?v1?f2?v2?f3?v3
"1650985928177-0"
##?创建消息时手动指定id?id必须比现有的大,不然会报错
127.0.0.1:6379>?xadd?mystream?1?f4?v4
(error)?ERR?The?ID?specified?in?XADD?is?equal?or?smaller?than?the?target?stream?top?item
127.0.0.1:6379>?xadd?mystream?1650985928177-1?f4?v4
"1650985928177-1"
##?查找id范围内的消息??-代表最小id??+代表最大id
127.0.0.1:6379>?XRANGE?mystream?-?+
1)?1)?"1650985928177-0"
???2)?1)?"f1"
??????2)?"v1"
??????3)?"f2"
??????4)?"v2"
??????5)?"f3"
??????6)?"v3"
2)?1)?"1650985928177-1"
???2)?1)?"f4"
??????2)?"v4"
??????
##?消息个数
127.0.0.1:6379>?XLEN?mystream
(integer)?2
##?根据消息id?删除消息
127.0.0.1:6379>?xdel?mystream?1650985928177-1
(integer)?1
###?从ID是0-0开始消费消息
###?XREAD?[COUNT?count]?[BLOCK?milliseconds]?STREAMS?key?[key?...]?ID?[ID?...]
###?COUNT?表示消费消息的个数,默认全部
###?BLOCK?表示阻塞获取的时间,单位毫秒,设置0表示永不过期
###?ID?表示消息id,为0表示从0-0的下一个消息开始读取
127.0.0.1:6379>?XREAD?streams?mystream?0
1)?1)?"mystream"
???2)?1)?1)?"1650985928177-0"
?????????2)?1)?"f1"
????????????2)?"v1"
????????????3)?"f2"
????????????4)?"v2"
????????????5)?"f3"
????????????6)?"v3"
??????2)?1)?"1650985928177-2"
?????????2)?1)?"f4"
????????????2)?"v4"
###?从阻塞队列的尾部读取
###?最后的ID为$表示使用mystream中最大的id为值读取(不会读取到本身的值,只有比自己大的)
###?在[XADD?mystream?*?key?value]没有执行时都会阻塞等待
127.0.0.1:6379>?XREAD?block?0??streams?mystream?$
?1)?1)?"mystream"
???2)?1)?1)?"1650986368128-0"
?????????2)?1)?"f5"
????????????2)?"v5"
(116.92s)
消费者组
###?创建消费组mygroup,消费组消费的队列是mystream??$表示从最新的开始消费(为0表示从头开始消费)
127.0.0.1:6379>?XGROUP?create?mystream?mygroup?$
OK
###?查看队列信息
127.0.0.1:6379>?xinfo?stream?mystream
?1)?"length"
?2)?(integer)?3?###?存在的元素个数
?3)?"radix-tree-keys"
?4)?(integer)?1
?5)?"radix-tree-nodes"
?6)?(integer)?2
?7)?"last-generated-id"
?8)?"1650986368128-0"
?9)?"groups"
10)?(integer)?1???####?一个消费组
11)?"first-entry"??###?第一个消息
12)?1)?"1650985928177-0"
????2)?1)?"f1"
???????2)?"v1"
???????3)?"f2"
???????4)?"v2"
???????5)?"f3"
???????6)?"v3"
13)?"last-entry"??###?最后一个消息
14)?1)?"1650986368128-0"
????2)?1)?"f5"
???????2)?"v5"
###?消费者组mygroup,c1消费者从streams消费最新的消息
###?>?号表示从当前消费组的?last_delivered_id?后面开始读
###?消费者组中的一个消费者读取一个消息后,该消息就不会被消费组的其它消费者读取,但是不同的消费组可以重复消费消息
127.0.0.1:6379>?XREADGROUP?group?mygroup?c1?count?1?streams?mystream?>
(nil)
###?支持阻塞获取,在XADD后
127.0.0.1:6379>?XREADGROUP?group?mygroup?c1?count?1?block?0??streams?mystream?>
1)?1)?"mystream"
???2)?1)?1)?"1650988435423-0"
?????????2)?1)?"f6"
????????????2)?"v6"
(43.91s)
##?查看消费组信息
127.0.0.1:6379>?xinfo?groups?mystream
1)?1)?"name"
???2)?"mygroup"?###?消费组名字
???3)?"consumers"
???4)?(integer)?1?###?消费组成员1
???5)?"pending"?
???6)?(integer)?1??###?正在处理没有确认的个数ACK
???7)?"last-delivered-id"??###?游标位置也就是最大的消息ID
???8)?"1650988435423-0"
##?查看PENDING数组信息
127.0.0.1:6379>?XPENDING?mystream?mygroup
1)?(integer)?1
2)?"1650988435423-0"??###?读取的最小的ID
3)?"1650988435423-0"??###?读取的最大的ID
4)?1)?1)?"c1"??###?消费者
??????2)?"1"
###?确认消息ACK
127.0.0.1:6379>?XACK?mystream?mygroup?1650988435423-0
(integer)?1
127.0.0.1:6379>?xinfo?groups?mystream
1)?1)?"name"
???2)?"mygroup"
???3)?"consumers"
???4)?(integer)?1
???5)?"pending"??###?确认后删除pending中的元素
???6)?(integer)?0
???7)?"last-delivered-id"
???8)?"1650988435423-0"
总结
Redis消息队列的实现真正能运用到生产环境的是List和Streams,两者区别如下所示
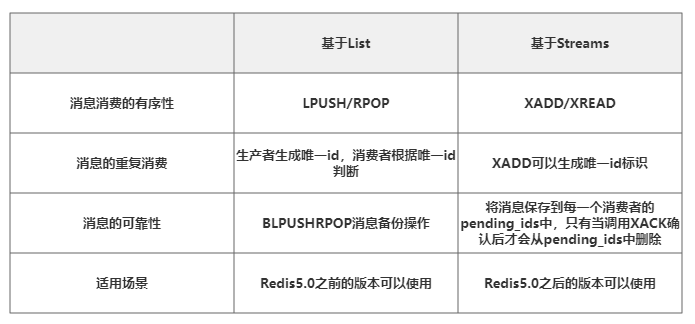
Redis实现消息队列在生产上的运用其实很多人都有争议,认为生产上应该尽量采用专业的消息中间件工具,其实在技术选型的时候应该从业务数据量出发,如果业务数据量不大而且不复杂那么运用Redis做消息中间件完全能解决,但如果业务数据量大这时Redis完全可以抛弃因为Redis本身就是将数据存储到内存,内存资源是非常有限的,这个应该交由专业的消息中间件完成,所以一个技术点存在必定有它的历史原因,只是我们在技术选型的时候从业务角度进行判断即可。

