产生背景:由于工作需要,目前现有查询业务,其他厂商数据库无法支持,高效率的查询响应速度,于是和数据总线对接,实现接入数据,自己进行数据结构化处理。
技术选型:SparkStreaming和Kafka和ElasticSearch
本人集群:SparkStreaming 版本2.3,Kafka的Scala版本2.11-Kafka版本0.10.0.0
(Kafka_2.11-0.10.0.0.jar)?????
消息总线集群:Kafka总线版本,Kafka_2.10-0.10.2.1.jar
由上述可知,Kafka版本均为0.10 只不过Scala版本相差0.01 直接上SparkStreaming消费Kafka代码。
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.collections.IteratorUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.api.java.function.VoidFunction2;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import java.util.*;
public class ShengPanChePai {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("ShengPanChePai")
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.serializer","org.apache.spark.serializer.KryoSerializer");
conf.setMaster("local[5]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("ERROR");
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(60));
String groupId = "test-10"; //指定消费者组id
String topics = "test-sjzx"; //指定topic
String brokers = "ip:9092,ip:9092,ip:9092"; //指定kafka地
Set<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//设置当前流消费数据为5MB ~ (10MB)
kafkaParams.put("fetch.message.max.bytes","5485760");
//每次程序启动获取最新的消费者偏移量
//kafkaParams.put("auto.offset.reset", "latest");
//开启消费之偏移量自动提交
kafkaParams.put("enable.auto.commit", true);
//链接kafka,获得DStream对象
JavaInputDStream<ConsumerRecord<String, String>> messages = KafkaUtils.createDirectStream
(ssc, LocationStrategies.PreferConsistent(), ConsumerStrategies.<String, String>Subscribe(topicsSet, kafkaParams));
messages.foreachRDD(new VoidFunction<JavaRDD<ConsumerRecord<String, String>>>() {
@Override
public void call(JavaRDD<ConsumerRecord<String, String>> consumerRecordJavaRDD) throws Exception {
consumerRecordJavaRDD.foreachPartition(new VoidFunction<Iterator<ConsumerRecord<String, String>>>() {
@Override
public void call(Iterator<ConsumerRecord<String, String>> consumerRecordIterator) throws Exception {
System.out.println(consumerRecordIterator);
}
});
}
});
ssc.start();
System.out.println("调用函数开始");
try {
ssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
直接运行,打印,发现无法遍历答应结果,发现程序已经阻塞(传统代码消费不存在问题,只有SparkStreaming消费存在阻塞),于是断点Debug发现,阻塞在启动函数ssc.start方法中,一直无法调用ssc.awaitTermination(); 回调函数。没有任何异常,没有任何信息,于是第一步考虑是否是,网络和端口的问题,通过telnet ip:9092 端口没有任何问题,远程调用控制台打印话题数据,完全没有问题,切换自己Kafka集群,同样没有问题,于是猜测是否SparkStreaming和 Kafka版本不一致问题,于是远程在官网查询,发现不是0.8客户端,通过0.10不存在集成问题。

?问题反思:只有还原真实场景才能发现问题
搭建本地环境:
? ? ? ? 在本地虚拟机搭建一套一摸一样的环境,使用SprakStreaming消费Kafka发现完全可以消费,没有问题,于是不是环境问题,继续研究发现,如果使用普通Java代码连接数据总线Kafka,测试是否出现问题)
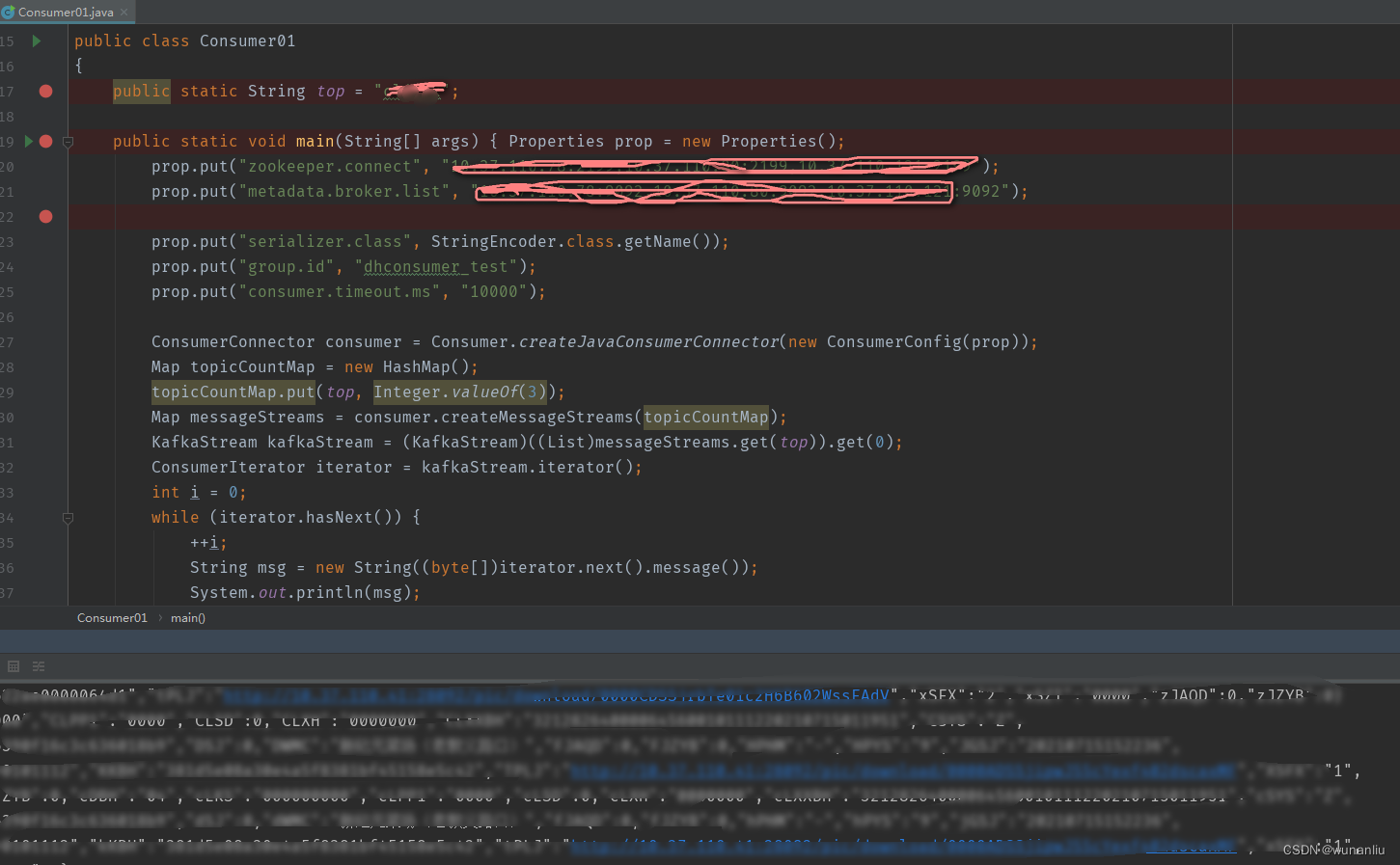
代码一:
package kafka.demo01;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringEncoder;
public class Consumer01 {
?????? public static void main(String[] args) {
????????????? Properties prop = new Properties();
????????????? prop.put("zookeeper.connect", “zkip:2181: zkip:2181: zkip:2181”);
prop.put("metadata.broker.list", “bkip:端口, bkip:端口, bkip:端口”);????????????
prop.put("serializer.class", StringEncoder.class.getName());
????????????? prop.put("group.id", "group1");
????????????? ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(prop));
????????????? Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
????????????? // 创建3个线程去消费topic中的内容,每一个线程一个stream流
????????????? topicCountMap.put(“kafka_topic”, 3);
????????????? Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = consumer
??????????????????????????? .createMessageStreams(topicCountMap);
????????????? System.out.println(messageStreams);
????????????? KafkaStream<byte[], byte[]> kafkaStream = messageStreams.get(
??????????????????????????? Config.TOPIC_NAME).get(0);
????????????? ConsumerIterator<byte[], byte[]> iterator = kafkaStream.iterator();
????????????? while (iterator.hasNext()) {
???????????????????? String msg = new String(iterator.next().message());
???????????????????? System.out.println("收到消息:" + msg);
????????????? }
?????? }
}由于上述两个版本客户端消费Kafka,所以尚未明确问题到底出现在什么地方,于是将两份测试代码拷贝到本地环境,进行本地环境测试,发现本地环境两份代码运行没有任何问题,于是,考虑对方集群问题。于是在对方集群,查找一个空白的Kafka话题进行数据推送,自己推送,自己消费,首先使用第一中客户端,发现数据消费没有问题,于是使用第二种客户端进行数据消费,发现也可以消费,于是马上使用原有自己环境中的SparkStreaming 进行消费Kafka打印数据,发现数据惊人的将数据打印出来了,于是断定是对方Kafka集群存在问题,于是将对方kafka集群所有话题进行查询,发现一半的话题是可以消费,一半话题无法消费,于是查看所有Kafka的Topic发现,无法消费的Kafka话题的Topic 中的Leader均不相同,于是想到了Kakfa的选举算法,可能是选举出现了问题,说明之前集群一定出现问题,于是电话沟通数据总线,证实了结论。于是查找解决办法,将Kafka 有问题问题的Topic的话题Leader 全部对元数据在Zookeeper进行修改,修改为正常选举状态发现问题都解决了~~~~。?

 ?
?
?集群异常对比发现(使用Kafka的查看集群命令)

由上述操作可知,对方集群存在问题,如果使用当前方法进行Kafka 消费,会永远紫色,回调函数无法调用,程序无法运行,于是 有两个思路,将kafka 数据通过代码消费,然后推送到自己的kafka 集群,于是通过测试发现,当前方法会出现,手动记录偏移量,并且需要维护偏移量,操作繁琐,于是寻求第二种方案,Kafka 数据跨集群同步方案。详情见后续文档,待完善.......
参考文档:Kafka数据集群异常(设计SparkStreaming)
kafka broker Leader -1引起spark Streaming不能消费的故障解决方法_微步229的博客-CSDN博客

