在大数据的领域中,数据显得尤其的重要。在每一个组件、每一个步骤中,我们都要对数据进行妥善的处理、保护,才能得到更有说服力、有意义的数据。
所以数据丢失,就成为了一件非常严重的事情;所以在我们的生产环境中,防止数据丢失就显得尤其重要。
第1章 引言
Kafka作为我们消息队列的中间件,基于订阅和发布的消息队列;解除生产者(消息源)和消费者(数据接收处)的耦合关系,消除某时段数据传输速度高峰值,启动一个缓冲的作用。
Kafka以时间复杂度O(1)的方式提供消息持久化能力,即使应对TB级以上数据也能保证一定时间的访问性能。
Kafka具有高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100k条消息的传输。
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
Kafka同时支持离线数据处理和实时数据处理。
那么这样一个可靠的组件,也会发生数据丢失。那么针对这一问题,我们来对其多方位的进行分析。
第2章 如何发现问题
(1)是否多人在操作生产环境
(2)接收数据处有无数据
(3)反常现象:比如电商项目中双十一数据量正常来说会比之前高很多,但是却和平常日期数据量相似或者数据量还要少。
(4)如果生产者端丢失数据,那么每次结果应该完全一样;如果不一样,生产者端便出了问题。
(5)如果消费者端丢失数据,那么每次消费结果完全一样的几率很低。
第3章 问题所在
根据实际生产环境发生的Kafka数据丢失现象,我做了如下汇总。
3.1 多客户端操作问题
发生这种问题,不是真正的发生了数据丢失;我们的大数据开发环境中,是必须支持多客户端开发的,多人使用数据,那么会有几率造成,两人甚至多人同时操控一份数据。这就比如有同事操作了测试环境,动用了你本来要用的数据,所以你无法找到了你的数据,便认为发生了数据丢失。
3.2 组件流程问题
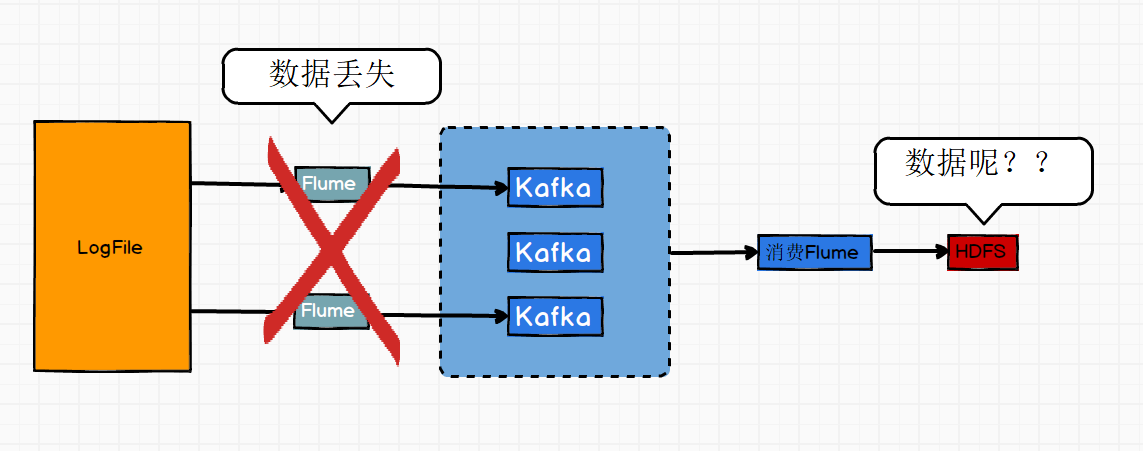
并不是真正Kafka发生了数据丢失,而是Kafka上游段或者下游段发生了数据丢失,比如上游段连接Flume组件,Flume发生了数据丢失,表现为Kafka内数据不全或者没有数据,之后认为Kafka发生了数据丢失;再或者Kafka下游连接Flume组件,Flume发生数据丢失,数据没有传输到HDFS上,导致HDFS无法找到数据,从而猜测Kafka数据丢失。

3.3 网络问题
Kafka速率超过了网络带宽,一旦发生发送失败情况,并且没有开重试机制,如果发生数据丢失,那么数据就真的丢失了。

3.4 数据大小问题
单批数据大小过长会造成数据丢失。坦白来说,就是单批数据的长度超过限制会丢失数据,会报kafka.common.MessageSizeTooLargeException异常,生产者生产的数据大小大于消费者配置的拉取的最大消息大小,远远超过了消费者拉取的能力,这条大数据将会被消费失败,严重可以导致Kafka卡死。从而造成数据丢失。
3.5 Kafka Producer丢失数据问题
关于Producer发生的数据丢失问题,主要由ack来阐述。
ack = 0
在ack = 0的模式下,消息传输到Broker端,不需要Broker发送应答的方式,即纯异步发送的方式,最容易发生数据丢失。不论Broker是否接收到,Producer只管发送消息,这种模式也是最不稳定的模式。
ack = 1
在ack = 1的模式下,只要消息传输到了Broker中partition的leader节点,leader节点返回ack应答Producer,即认为发送成功,无需等待副本全部同步完。在这种模式下,在leader发送完ack后,follower同步完成前,leader节点发生宕机,就会发生数据丢失。
ack = -1(all)
这一模式称为Kafka中最安全的模式,只有非常非常极端的情况下,才会发生数据丢失,当某个partition的ISR列表中的副本数,不满足min.inSync.replicate的时候,生产者发送消息就得不到ack确认,这时候生产者会进入重试,重试次数为配置的message.send.max.retries,如果在重试次数内ISR列表副本数仍然达不到最小同步副本数,那么,生产者会抛出NO_ENOUGH_REPLICATE的异常,如果没能正确处理这个异常,很可能这条数据就丢失了。
用一句白话来说,在Kafka生产集群中,我们一般设置副本数为2,然后Kafka的ISR队列中的follower全部挂掉,只有leader一个副本,导致ISR回应只有leader进行回应(与ack = 1模式很相似)。
那么什么情况下ISR列表的副本数不足最小副本数呢?
follower副本进程卡住,导致follower没有向leader副本发起同步请求,或者follower节点性能问题,导致一段时间内都无法追赶上leaer副本,或者IO开销过大。
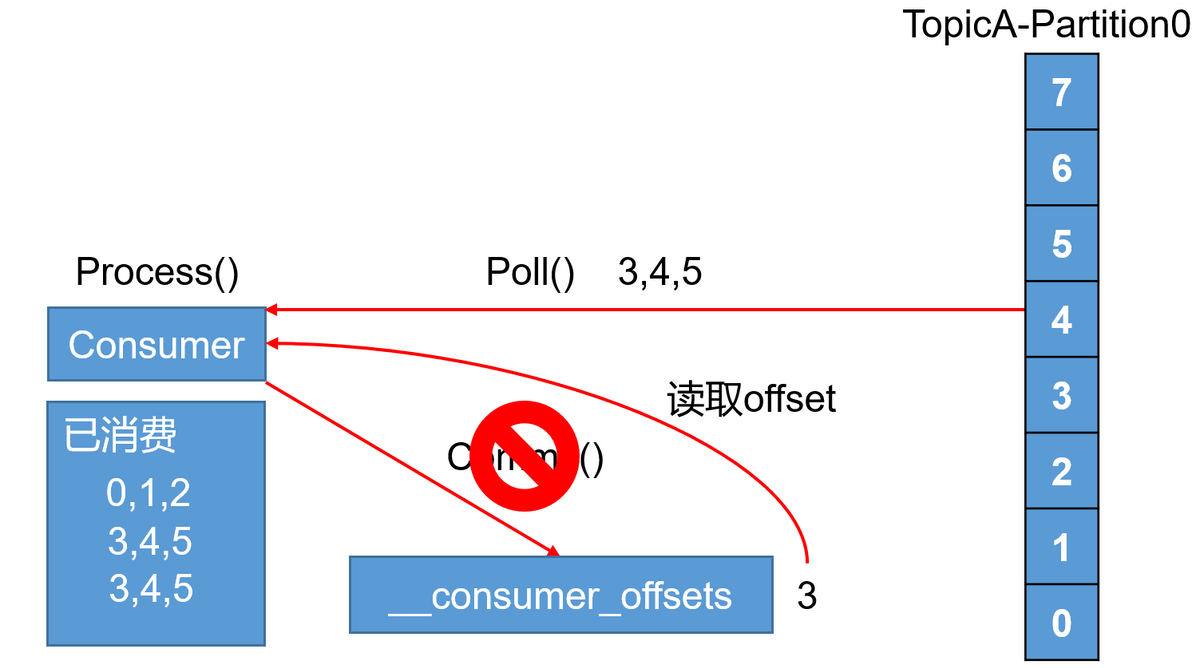
3.6 Kafka Consumer丢失数据问题
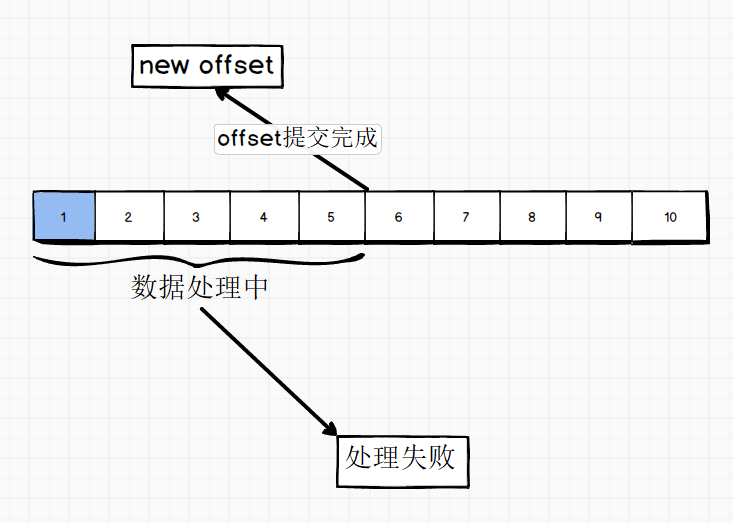
将Kafka中相关offset的参数设置成了自动定时提交。
auto.commit.enable=true
当offset被自动定时提交时,数据还在内存中未被处理,此时刚好把线程kill掉(可以理解为服务器宕机),那么如果offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
举个例子:每天早上,手机上各种终端都会给用户推送消息,那么在早晨这一段时间内,流量剧增,可能会出现Kafka发送的数据过快,导致服务器网卡爆满,或者磁盘处于繁忙状态,之后可能出现丢包现象。
总结起来:发送很快,接收很慢,但是offset在接受前就已经提交了。
3.7 副本数问题
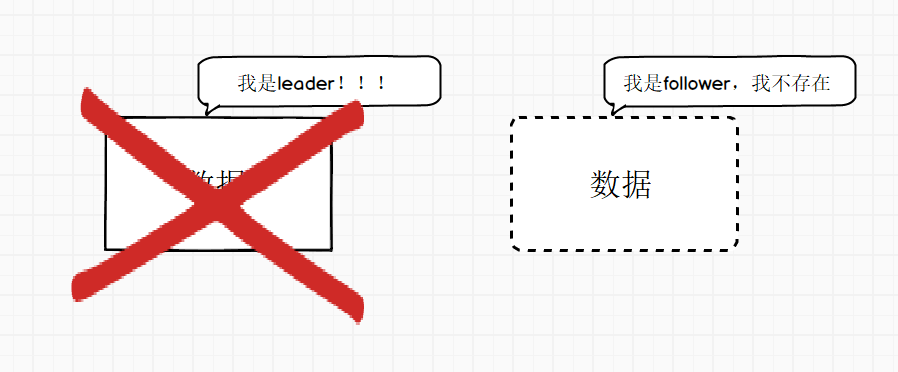
当然这是理论问题,不适用于真正的生产环境。基本上不会有公司将Kafka的副本数设置成了1,我们所知道的数据的重要性,告诉我们将副本数设置成为1,是相当不可靠的行为。
或者是章节2.6提出了ISR列表的副本数不足最小副本数,详情见3.5中ack=-1。
3.8 pagecache的缓存挂掉
Kafka的数据一开始都是存储在PageCache上的的,定期flush到磁盘上,也就是说,不是每个消息都被存在磁盘上,如果出现断电或者机器故障等,PageCache上的数据就丢失了。
可以通过两个参数来配置flush间隔。
--log.flush.interval.messages
--log.flush.interval.ms
log.flush.interval.messages设置大一些会导致数据丢得多一些,若设置小一些会影响性能。但是在0.8版本,可以通过副本机制保证数据发生丢失的可能性变得低一些,代价就是需要更多的资源,尤其是磁盘资源。
3.9 leader挂掉
partition leader在未完成副本数follower的备份就宕机的情况,即使controller选举出了新的leader,但是生产者发出的消息因为未备份就丢失了。
3.10 硬件问题
Kafka磁盘坏了,会丢失已经落盘的数据。
第4章 解决问题(性能优化)
除去一些硬件问题或非自然因素等等,我们能解决的问题有哪些呢。
4.1 个人工作---多客户端操作问题
确保每个人有每个人的业务,计量避免业务重复,若是需要数据,尽量去之后的数仓的dwd或者ods层去拿数据,减少在数据采集过程中多人操作客户端的可能性。
4.2 理清业务流程---组件流程问题
理清楚工作的业务流程,数据流向,数据到底在什么地方丢失,有时候Kafka莫名背了丢失数据的锅,可是很无辜的。是否是因为Flume组件接口的问题、日志服务器的问题,Flume拦截器没有激活等等一系列的问题。
4.3 重试机制---网络问题
网络问题,这就涉及到Kafka的重试机制。
网络负载很高或者磁盘很忙写入失败的情况下,没有自动重试重发消息。没有做限速处理,超出了网络带宽限速。Kafka一定要配置上消息重试的机制,并且重试时间间隔还不能太短,默认1s,但是在真正的生产集群环境中,网络波动或者网络终端时间可能超过1s。
4.3 生产数据大小适中---数据大小问题
如果传过来的数据大于Kafka要处理的数据大小,默认1M。
两种办法:找部门相关人员,要求埋点日志大小不能超过1M;或者将以下两个参数调大。
--message.max.bytes 1048576 broker可复制的消息的最大字节数, 默认为1M
--replica.fetch.max.bytes 1000012 kafka 会接收单个消息size的最大限制, 默认为1M左右
注意:message.max.bytes必须小于等于replica.fetch.max.bytes,否则就会导致replica之间数据同步失败。
4.4 Producer丢失数据问题
设计上保证数据的可靠安全性,一句分区数做好数据备份,设立副本数。
数据推送方式:同步or异步;权衡安全性和速度性。数据有问题,可以用同步来测试。
最终解决办法:幂等性 + 事务 + (ack = -1) = 精准一次性
理论上,由幂等性和事务来防止数据重复,由(ack = -1)来防止数据丢失。
linger.ms,默认值为0,即使batch不满,也会进行发送。但是虽然设置为0,但是producer中的send方法的执行还是有些许的延迟,因为永远会有一些外在因素。
4.5 Consumer丢失数据问题
对于Consumer造成数据丢失。
--auto.commit.enable=false
上面这个参数,我们要设置成false,默认为true;也就是说,我们要设置成手动提交。我们可以在数据处理完后,再去提交offset,这样就可以保证,不会造成数据丢失的问题。但是可能会造成数据重复的问题。对于数据重复,我们下游端还有其他更便捷的办法,这里就先不一一介绍了。
但是,数据丢失了,在大数据领域是相当严重的问题,如果数据丢失了,我们补救的措施非常非常有限,所以两个问题对比一下,还是数据重复有更多的办法解决。所以斟酌利弊,这种办法也能解决数据丢失。
还有一种方法,就是开启KafkaConsumer的事务,但是Consumer的事务保证相对于Producer的事务较弱,无法保证Commit的信息被精确消费。这是由于Consumer可以通过offset访问任意信息,而且不同的SegmentFile生命周期不同,同一事务的消息可能会出现重启后被删除的情况。如果像完成Consumer端的精准一次性消费,那么需要Kafka消费端讲消费过程和提交offset过程做原子绑定,即要么全部成功,要么全部失败,典型的有福同享,有难同当的例子。
4.6 副本数问题
副本,是为了提高组件的可靠性,数据的安全性。即使我们数据丢失,我们还有副本进行同步;也可以认为,两个副本同时丢失的概率会很小,那么两个以上副本同时丢失的概率更是微乎其微。所以,当我们配置了大于1个副本数时,那么在组件不出问题和一些外在因素除外的情况下,数据丢失将几乎不会发生。
但是副本数的配置,也是有一定的经验的。若是副本数配置的过少,比如1个,那么很容发生数据丢失,这当然不是我们想要看到的。但是若是配置过多的副本数,那么就会导致Kafka集群的可用性降低;副本之间需要不断同步,那么大量的副本,需要大量的资源进行同步,那么传输数据的性能必然下降,这样做,只能是弊大于利,所以我们不考虑将副本数设置过多。在一般企业,将Kafka集群的副本数一般设置为2~3个,设置2个的居多。
4.7 PageCache问题
对于这个PageCache,先对它进行一下介绍。Kafka很快,就很依赖PageCache,Kafka重度依赖底层操作系统提供的PageCache功能,当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。实际上PageCache是把尽可能多的空闲内存都当作了磁盘缓存来使用。
Kafka的数据一开始就是存储在PageCache上的,定期flush到磁盘上,也就是说,不是每个消息都被存储在磁盘了,如果出现断电或者机器故障等,PageCache上的数据就丢失了。
那么针对于这一现象。可以适当调整以下两个参数
--log.flush.interval.messages 默认值:Long.MaxValue
--log.flush.interval.ms 默认值:Long.MaxValue
官网对这两个参数这样解释:
log.flush.interval.messages:在我们对日志强制执行fsync之前,写入日志分区的消息数。 设置较低的值将使数据同步到磁盘的频率更高,但会对性能产生重大影响。 通常,我们建议人们使用复制来提高持久性,而不是依赖于单服务器fsync,但是可以使用此设置来确定。
log.flush.interval.ms:日志中fsync调用之间的最长时间。 如果与log.flush.interval.messages结合使用,则在满足任一条件时将刷新日志。
可通过调整这两个参数来配置flush间隔,log.flush.interval.messages设置过大,丢失的数据可能将会多些;设置过小,会影响性能。但在0.8版本,可以通过replica机制(副本机制)保证数据不丢失,代价就是需要更多的资源,尤其是磁盘资源。但是在大数据领域下,数据才是最重要的,磁盘相对于数据来说,是廉价的。并且我们还可以使用Gzip和Snappy压缩,来缓解这个问题,是否使用replica取决于可靠性和资源代价之间的平衡。
4.8 其他问题
那么针对其他的问题,我还没有找到,更有效的解决办法。这一类问题,通常属于,硬件问题和一些不可猜测的因素产生的,那么我们就只能好好维护集群性能,争取Kafka集群在运行过程中,没有瑕疵的出现,这样在生产环境下,我们进行数据传输或者数据处理,才能真正做到对数据的利用最大化。
第5章 总结
目前,Kafka在实际生产中,还有一定的地位。高吞吐量、低延迟、可扩展性、持久性、可靠性、容错性、高并发,集如此多的特性于一身。可适用于日志收集、消息系统、用户活动跟踪、运营指标、流式处理等场景。所以说,Kafka的表现相当出色。
那么以上就是Kafka数据丢失问题的部分汇总,可以根据一些问题现象推测出问题的所在。找到问题,并找到方法解决问题,Kafka在真正的生产环境中才能有更高的性能。

