Redis�־û����ڱ��ܹ��
RDB
save
��νRDB�����ļ�,ָ����redis�ᶨ�ڻ��߸�����������һ�������ļ�,����ƾ����������ļ��ָ�redis����;������redis����˵�ʱ����Զ�����RDB�ļ�,
redis���ݿ�����ļ����浽dump.rdb�ļ���;
��δ���?-----����ͨ������ #Sava n�� k���Ķ�;������redis��n���ڸ�����k������ʱ����save���������ļ�;
��ȻҲ�����ֶ�ִ��save�����;ÿ��ִ�ж�������ԭ����dump�ļ�;���һ���µĿ����ļ�;
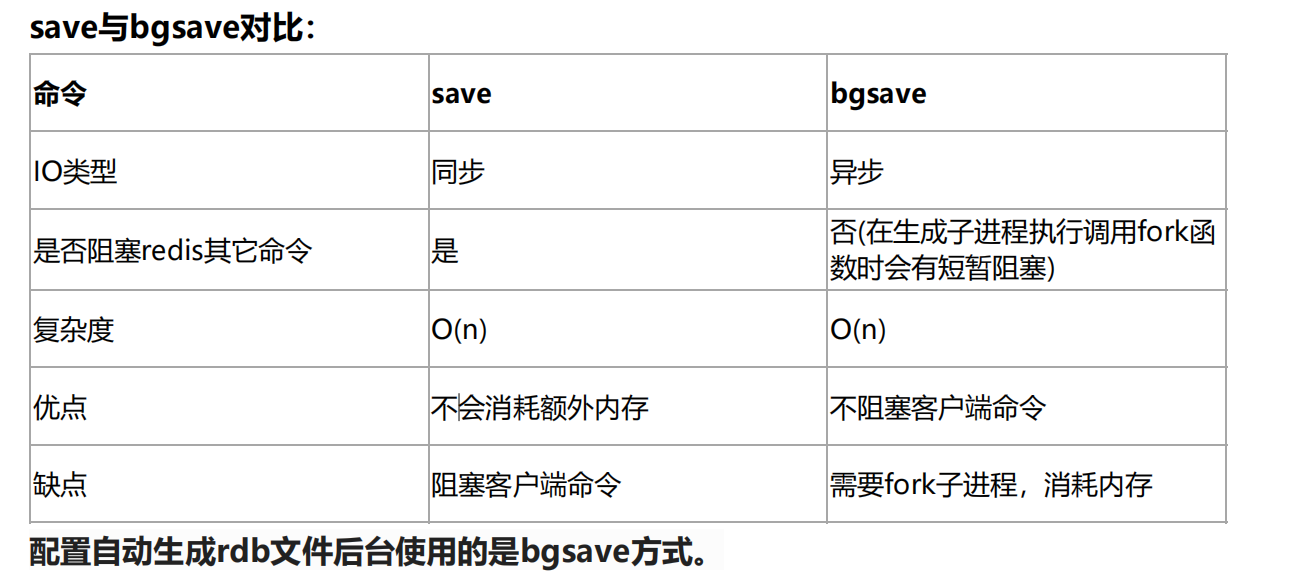
save��ͬ������,����Ҫ���������������ʱ�ͻ������ͻ�������,��Ϊredis�ǻ��ڵ��̲߳�����,Ϊ�˽���������redis��1.1�汾�Ƴ��첽ִ������bgsave;
bgsave
redis���ǵ��̵߳���?��ô�����첽ִ�в�����?�����Ҫ��������ϵͳ�ṩ�Ĺ�����:дʱ����;����˵�������߳�fork��һ�����߳� ,���߳̿��Թ������̵߳��ڴ�����;bgsave ����֮���ȡ���߳��ڴ�����,��д��dump�ļ�;
�����̲߳�������Ӱ��;�����ڶ����ݵ�ʱ���Ի�����������;����������̶߳����ݽ���д�����Ļ�,�ͻὫ���ݴ���һ������;bgsave�������������֮д���ļ�;
���߶Ա�
ȱ��:
- ���ݵij־û��ᵼ��һЩ�������ݶ�ʧ;
AOF
Rdb���ɵĿ����ļ���һ���������ļ�,��������֮���ļ����÷dz��Ӵ�;
AOF���Ǽ�¼���в���������;����Щ����д���ļ�,���������������ǾͿ���һ��ִ���ļ��е�����ɻָ�����;�ļ���ʽ����:
1 *3 # ���ٸ�����----set zhuge 666
2 $3
3 set
4 $5 #KEY����
5 zhuge
6 $3 #value����
7 666
�ǺŴ��������ĸ���;$��ʾ����;
��ο���:appendonly yes ,�������ļ���;
ִ��ʱ��:��������ѡ�����ѡ��:
1 appendfsync always:ÿ�����������ӵ� AOF �ļ�ʱ��ִ��һ�� fsync ,�dz���,Ҳ�dz���ȫ��
2 appendfsync everysec:ÿ�� fsync һ��,�㹻��,�����ڹ���ʱֻ�ᶪʧ 1 ���ӵ����ݡ�
3 appendfsync no:�Ӳ� fsync ,�����ݽ�������ϵͳ������������,Ҳ������ȫ��ѡ��
Ĭ��ÿ��ͬ��һ��;
ʱ����˾ͻ����һ������:����ܶ�,��������������ظ���,����ֻ�ں����Ľ������
����AOF��������һ����д����,�൱���ؽ�����������,�����ļ�����,ֻȡ���ս��;
AOF��д
�������?
1 # auto�\aof�\rewrite�\min�\size 64mb //aof�ļ�����Ҫ�ﵽ64M�Ż��Զ���д,�ļ�̫С�ָ��ٶȱ����� �ܿ�,��д�����岻��
2 # auto�\aof�\rewrite�\percentage 100 //aof�ļ�����һ����д���ļ���С������100%���ٴδ�����д
��Ȼ�����Զ������ֶ�:ͨ��bgrewirteaof����ʵ��;ͨ��bg���֪����bgsaveһ��ͨ���ӽ��̲���;
- ���ѡ��AOP��RDB?
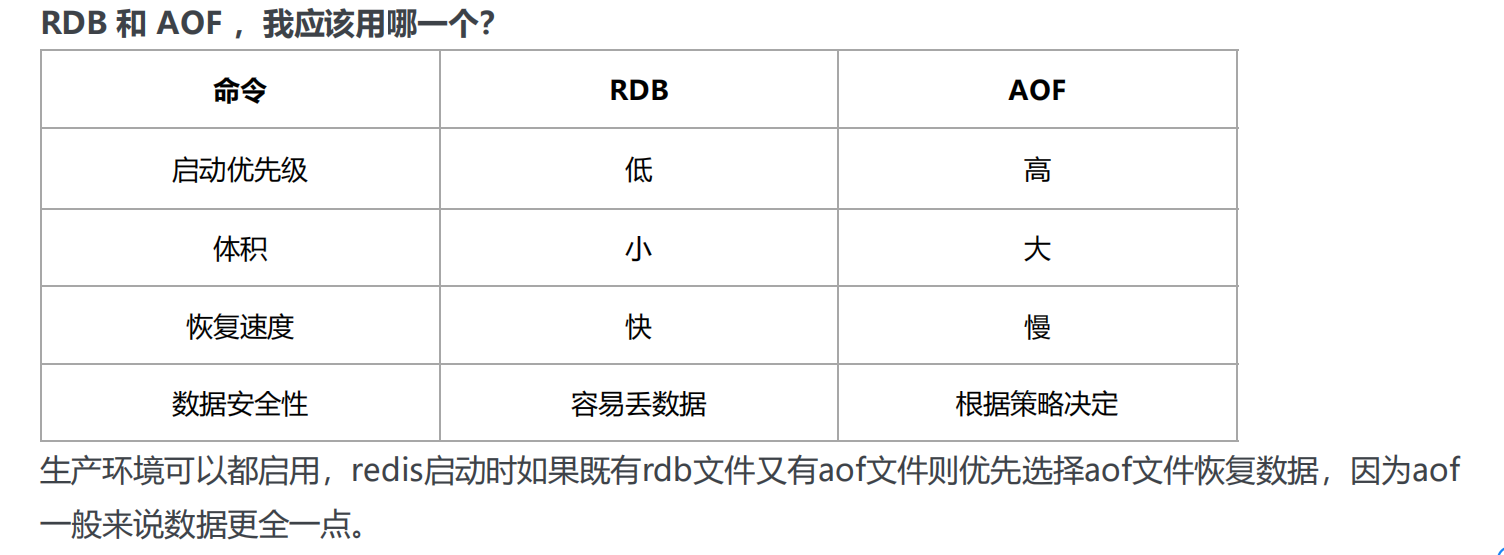
���Կ������и����ŵ�,��ôС���Ӳ���ѡ��,���˵�Ȼ�Ƕ�Ҫ;redis��4.0���Ƴ����ģʽ;
��ϳ־û�
����֪��:RDB��������,�������С;��ôʹ��RDB+ AOF����ok��;
��������:ǰ���ǿ���AOF;
# aof�\use�\rdb�\preamble yes //����:ʹ��RDB��ǰ;�൱�ڰ�RDB�ļ����ݷ���ǰ��;
ʵ��˼·:
ijһ��:����AOF,��ô�ý��˿�֮ǰ������תΪRDB����AOF�����ļ�;�ڴ˿������ľ�ʹ��AOF�ӵ��ļ�ĩβ;����д��ɺ�ԭ����aof�ļ������滻;
Redis���Ӽܹ�
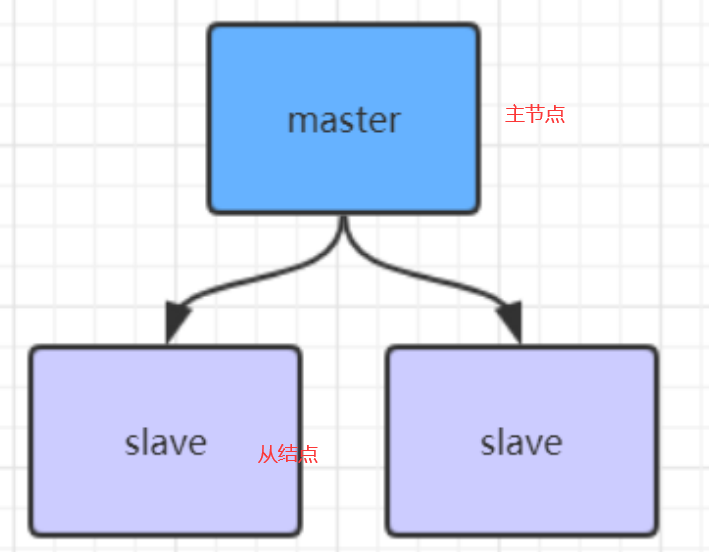
- ʲô�����Ӽܹ�?
redis�����ֻ��һ���Ļ����崻��˾�û�취��;������Ҫ���Ⱥ;����;��֤һ��������֮��Ҳ������
�����:
���������¸���һ���µ�rdis.conf�ļ��Ķ˿ں�
�����������Ϊ����ֵ:
port 6380 5 pidfile /var/run/redis_6380.pid # ��pid���̺�д��pidfile���õ��ļ�
logfile "6380.log"
dir /usr/local/redis�\5.0.3/data/6380 # ָ�����ݴ��Ŀ¼
# ��Ҫע�͵�bind 9 # bind 127.0.0.1(bind�����Լ�����������ip,����ж��������������ip,���������ͻ���ͨ ����������Щ����ipȥ����,����һ����Բ�����bind,ע�͵�����)
�������Ӹ��� 12 replicaof 192.168.0.60 6379 # �ӱ���6379��redisʵ����������,Redis 5.0֮ǰʹ��slaveof
replica�\read�\only yes # ���ôӽڵ�ֻ��
�����ӽڵ� 16 redis�\server redis.conf
���Ӵӽڵ� 19 redis�\cli �\p 6380
������6379ʵ����д����,6380ʵ���Ƿ��ܼ�ʱͬ����������
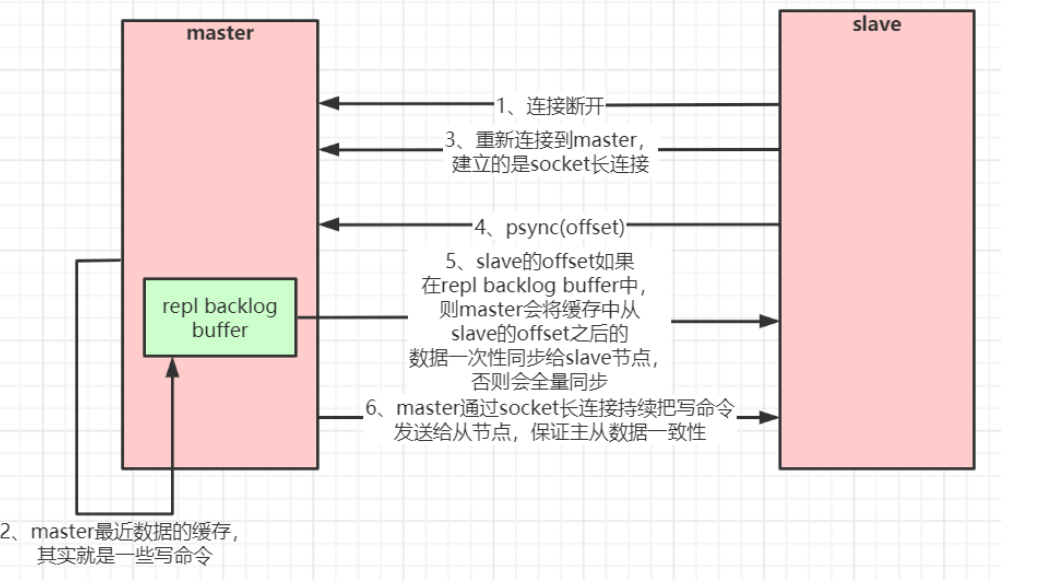
����ԭ��
���һ��master������һ��slave;�����slave������master֮��,�ᷢһ��psync���� ��master����������;master�յ��������ں�̨ʹ������bgsave�������µ�rdb�ļ�����slave,�ڳ־û��ڼ���ܵĿͻ�������Ỻ����һ��buff��,�־û��������ٽ��䷢��slave;��slave�ڴ��ڼ�һֱ�ڽ������ݲ�����rdb�ļ�,֮����ص��ڴ�ִ�����ݻָ�;
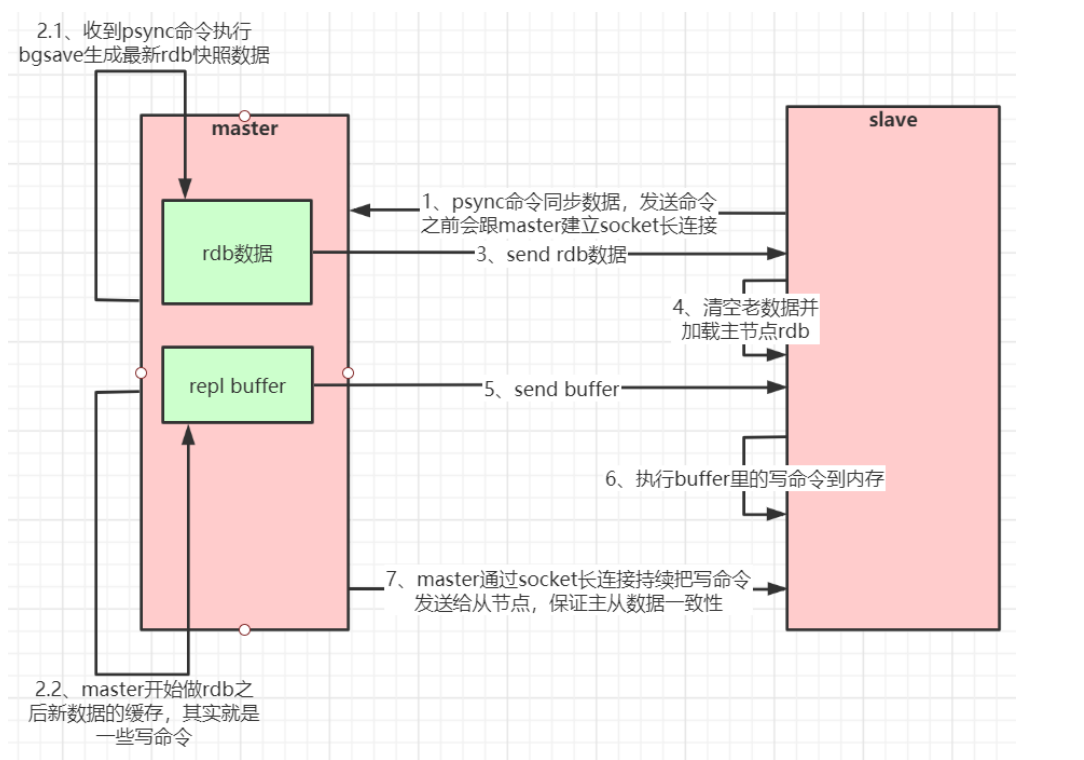
����������һ������,�Ǿ���ÿ�δӽ���������ڵ��Ƕ���ȫ����������,Ч�ʿ϶����Ǻܸ�;����redis��2.6���Ƴ����ָ���,���ļ��Ķϵ�����һ��;�����Ϳ���ʵ��������Ͽ�һ��ʱ�������������ûͬ��������;
ʵ��˼·:���ڵ�ά��һ�������±�,�����ӽ�㸴�����ݵ�λ��;master�����ݷŵ�������,slave�ӻ�������ȡ;���м�¼��master�Ľ���id��slaveʶ��,���id�����仯,Ҳ��˵��master����,�Ӷ�ȫ������,
�ܵ���Lua�ű�
�ͻ��˷�������������ִ������,ֻ���յ��ظ�֮��Ž�����һ��,������ӹ���ɺķѴ�������IO����;��Ϊʲô��һ�η��Ͷ�������,��һ���Է�����;����ǹܵ����ֵ�����;
�ܵ���Ŀ���Ǽ�������IO����,��������ִ��ʧ��Ҳ�ճ�����,����������Ĺ���;��ô��Ҫʵ������Ĺ��ܸ�����ʵ����?
- lua�ű�
�ܵ�����,Ҳ�ǽ������ӷ�����������;����ܵ���ͬ����,lua��ʵ������Ĺ���;�ű����᱾��Ϊһ��������ִ��;��ԭ�Ӳ���;
ʹ�÷���:
EVAL script numkeys key [key ...] arg [arg ...]
- script : ����ִ�еĽű�
- numkeys : key������----ͨ��KEYS[1]����key;
- arg : key��Ӧ��ֵ-----ͨ��ARGS[1]���ʲ���
����:
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1]+ARGV[2]}" 2 k1 k2 300 200
1) "k1"
2) "k2"
3) (integer) 500
����:return key1 �� key2,�����ǵ�ֵ�������;
�ɴ˿�֪,������lua�ű��н��м����жϵȲ���,���,��Ҫ��lua�ű��н��к�ʱ�ļ���,��Ȼ�ͻ�������ᱻ����;
Redis�ڱ��߿��üܹ�
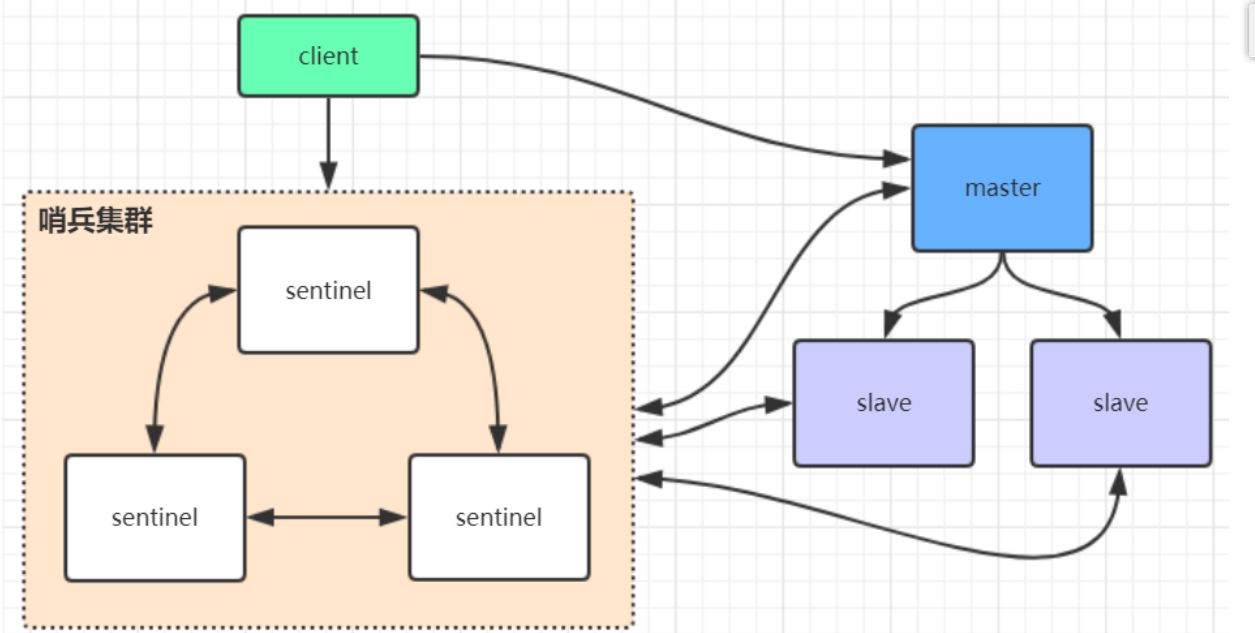
��ͼ�ɼ�,�ͻ��˲���ֱ�ӷ���master,�������ȷ����ڱ���Ⱥ,ͨ���ڱ���Ⱥ������ڵ�master����Ϣ���ٷ���֮;�������ʹ�ϵ֮��,�ڱ���ʵʱ��ؽ�㼯Ⱥ��Ϣ;��master�����䶯,�ڱ���ͨ�����Ĺ��ܷ���֪ͨ���ͻ���;
- �ڱ�������:
�ڱ���Ŀ�ľ���Ϊ�˼��redis-server��Ⱥ�ı䶯�����ڵ�,�����ڵ����֮���ڲ�ѡ�ٻ���ѡ�ٳ�һ���µ����ڵ㹩�ͻ�������ʹ��;����ô������ȷ�����ڵ������?����һ����ڱ�����Ϊmaster����֮��Żᴥ��ѡ��;ѡ�ٽ�����ͨ�����Ľ���Ϣ֪ͨ���ͻ���,�ͻ��˼�����Ϣ�Ӷ���̬�л�����;
�˽�һ�¼���,����ʹ�õĻ���cluster��Ⱥ
- ȱ��:��Ⱥ������ˮƽ��չ;���master�ڵ��� ��,����������л�,��ijһ̨slave��Ϊmaster,�ڱ�������������,�������ܺ߿����Եȸ�������� һ��,�ر����������л���˲����ڷ���˲�ϵ����,�����ڱ�ģʽֻ��һ�����ڵ�����ṩ����,û��֧�� �ܸߵIJ���,�ҵ������ڵ��ڴ�Ҳ�������õù���,����ᵼ�³־û��ļ�����,Ӱ�����ݻָ�������ͬ���� Ч��
�߿��ü�ȺCluster
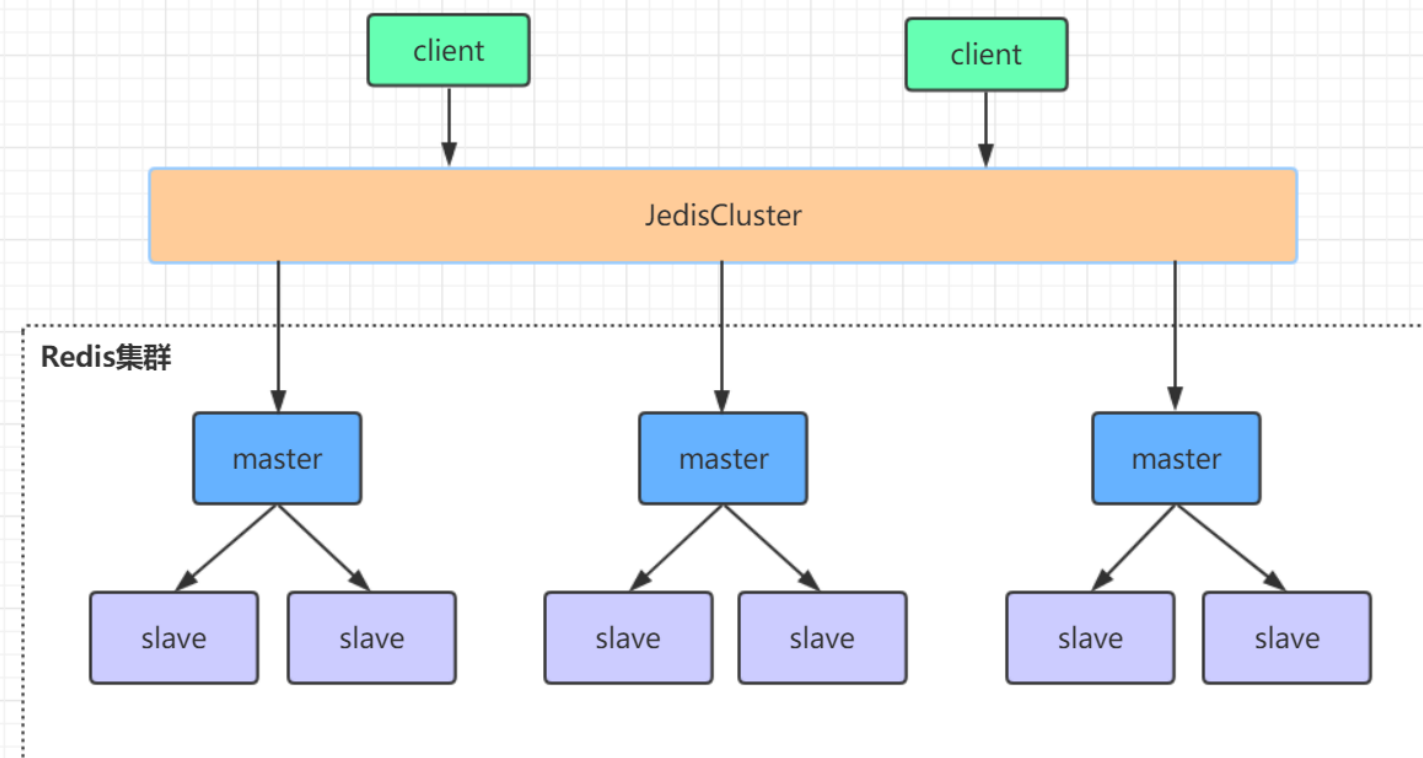
- ��ͼ�ɼ�,�ü�Ⱥģʽ�����Լ�ǿ,�Կͻ����ṩ����Ҳ��;ͬʱˮƽ��չҲ�ܷ���;����Ҳ������,��֮�ŵ���
�������;
��Ⱥԭ������
redis Cluster�����ݻ���Ϊ16384����λ;��ÿ�����ռ������һ���ֲ�λ,��λ��Ϣ�洢�ڽ��������;
�������ͻ������Ӽ�Ⱥ��Ҳ����һ�ݲ�λ��Ϣ,����������Ϣ�ǻ��ö�Ӧ�IJ�λ,���ݲ�λֱ�ӷ���Ŀ����������ӻ�ȡ����;
redis����crc16�㷨����hash�õ�һ������ֵ,Ȼ�����������ֵ��16384ȡģ�õ������λ;��HASH_SLOT = CRC16(key) mod 16384
�����һ����㷢�͵�key�IJ�λ�����ڸý���ǻ��ض���Ŀ������в���;
- ��ô��Ⱥ���֮������ν���ͨ�ŵ���?
redis cluster���֮����� gossip����ͨ��;���ڼ�Ⱥ��Ԫ���ݵ�ά��:ͨ���м���ʽ��gossip����;
����ʽ:��Ԫ������Ϣ���д����һ���ط�,����ÿ����㶼��������ط���ý��ͼ�Ⱥ��Ԫ����;�и���ʱҲ��������λ��,�������Ҳ�������õ�֪ͨ��Ӧ;�ܶ��м������zookeper�洢����;
gossip:���֮�以�����Ϣ;����Ԫ������Ϣ;

���綶��:����ʵ���绷����,��Ϊ��·������Ե��,ʹ��ijЩ����ͻȻ�Ͽ��ֺܿ�����,����ʹ�������л���Ƶ��;����ͨ������cluster--node--timeout ������������timeout֮���ſ���ѡ��
-
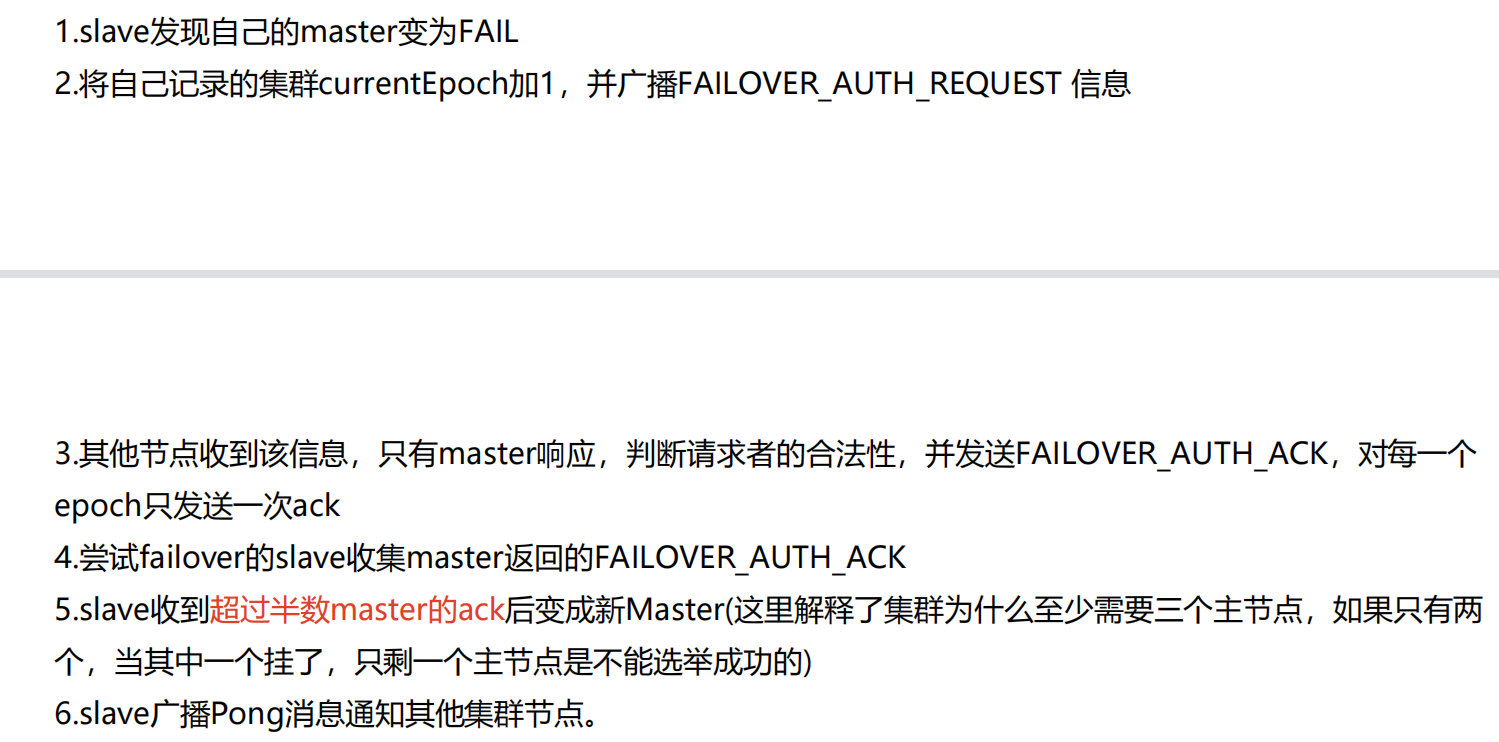
ѡ��ԭ��:
��slave�����Լ���master��ΪFAIL״̬֮��;��ý�������slave������Ϊmaster;��������:
-
��Ⱥ��������:
redis�ļ�Ⱥ������ָ��Ϊ��������,����redis master�ڵ��redis slave�ڵ��sentinel��Ⱥ���ڲ�ͬ���������,��ʱ��Ϊsentinel��Ⱥ����֪��master�Ĵ���,���Խ�slave�ڵ�����Ϊmaster�ڵ㡣��ʱ����������ͬ��master�ڵ�,����һ�����Է��ѳ���������
��Ⱥ����������,����ͻ��˻��ڻ���ԭ����master�ڵ����д������,��ô�µ�master�ڵ㽫��ͬ����Щ����,������������֮��,sentinel��Ⱥ��ԭ�ȵ�master�ڵ㽵Ϊslave�ڵ�,��ʱ�ٴ��µ�master��ͬ������,������ɴ��������ݶ�ʧ����ܷ���������redis��������ϲ���(���ַ��������ܰٷְٱ������ݶ�ʧ,�ο���Ⱥleaderѡ�ٻ���):
min�\replicas�\to�\write 1 //д���ݳɹ�����ͬ����slave����,�����������ģ�´��ڰ�����������,���� ��Ⱥ�ܹ������ڵ��������1,����leader����2,�����˰���Ŀ�ľ�����������Ⱥ�ܹ��ӽ������ͬ����������һ��ſ�ʼ�Ѷ�֮ǰ�����ڵ㽵��;



