🌿在前面的介绍中,我们介绍了kafka的基础架构主要包含以下几个部分:生产者、消费者、消费者组、 broker、Topic、Replica(副本)、leader、follower。今天我们来介绍其中的消息生产者。对往期内容感兴趣的同学可以参考👇:
- 链接: kafka入门基础.
🌰废话不多说,让我们开始今日份的学习吧。
1. 生产者消息发送
1.1 发送原理
如下图所示,我们展示的是一个消息发送的过程:
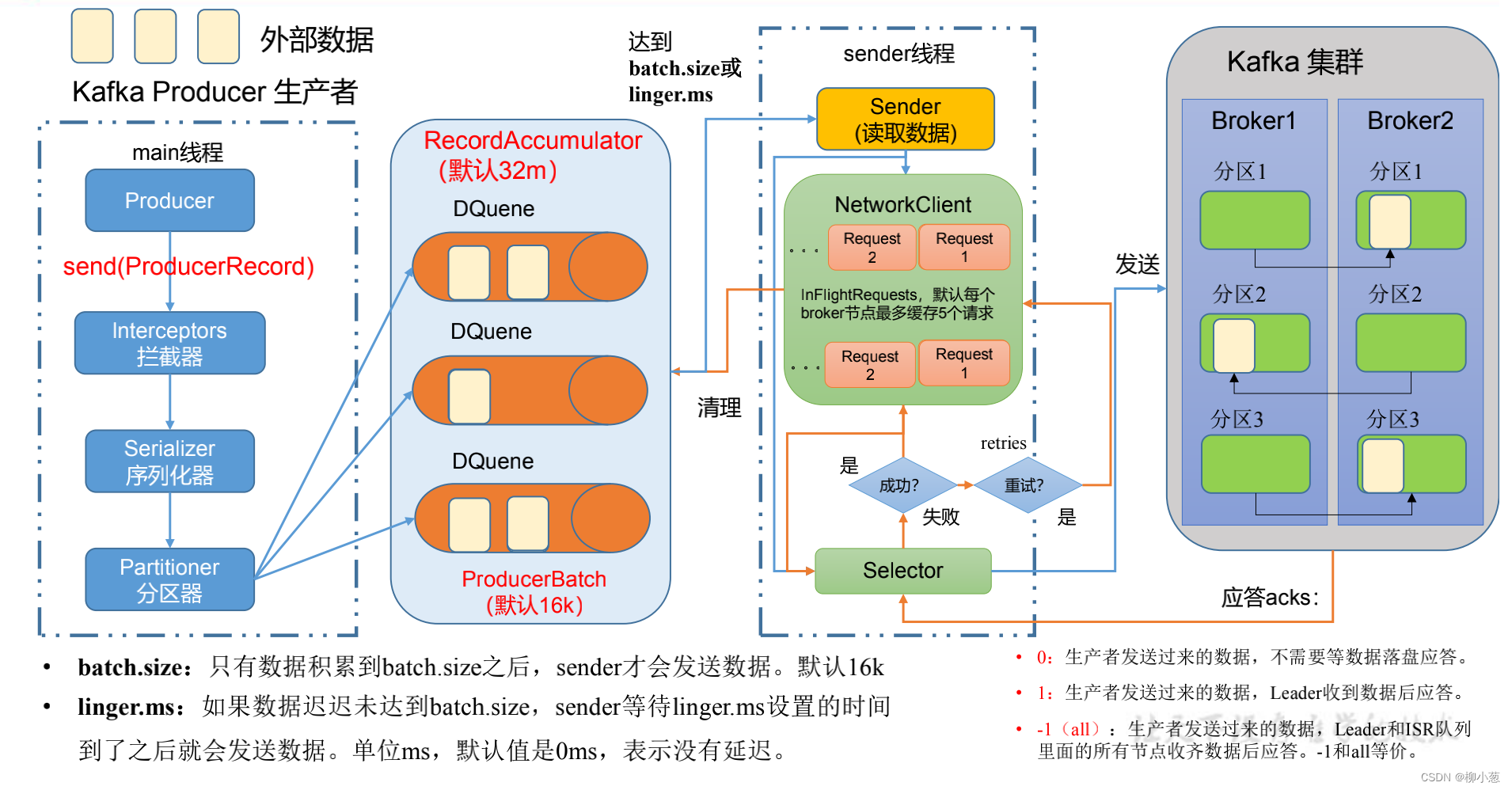
我们来解释一下这个过程:主要有main线程和sender线程2个部分
- 创建启动main线程,创建一个producer对象,调用send方法,将数据进行传输。
- 到达拦截器Interceptors,拦截器主要是对数据进行加工(很少使用)
- 进入序列化器,对数据进行序列化
- 进入分区器, 对数据进行分区,一个分区会创建一个队列,所有的分区队列都是在内存中创建的,总称双端队列 RecordAccumulator,大小默认为32m。
- sender 线程不断从 RecordAccumulator 中拉取数据,数据累加到producebatch的大小(默认16k)就进行发送,或者等到等待时间linger.ms结束拉取数据。
- 数据拉取到过程中是以分区为单位拉到某一个brock上,一个brock最多接受5个拉取数据的请求request
- selector主要是打通生产者与kafka集群brock这条链路的io流进行数据传输,数据达到对应的brock之后会进行复制备份
- 如果集群收到生产者的数据之后,会进行应答(acks),主要有 0:生产者发送过来的数据,不需要等数据落盘应答。1:生产者发送过来的数据,Leader 收到数据后应答。-1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。
- 生产者收到成功的请求之后,会将对应的传输请求request给取消掉,然后清理掉双端队列 RecordAccumulator里每一个分区中传输成功的数据。
- 生产者传输失败后,可以进行重试,可以不断发送,直到成功。
2. 生产者同步与异步发送
这里所说同步和异步发送,主要是指生产者将消息传输到双端队列 RecordAccumulator的方式。
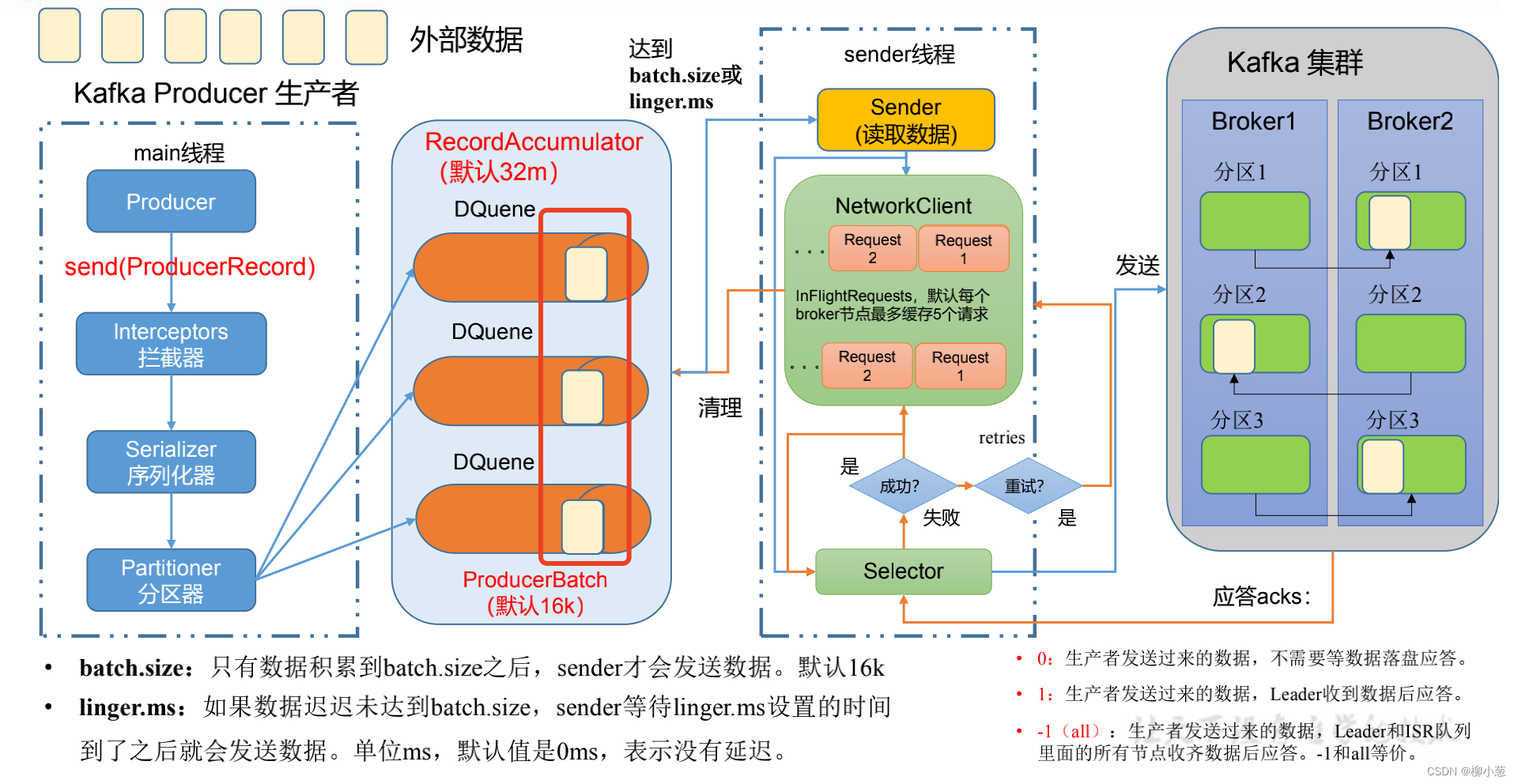
2.1 同步发送
如下图红色框框内的数据,同步发送是指外部数据从main线程穿输到双端队列中去后,直到该批数据被kafka集群拉取到brock中去后,下一批的数据才能继续传输到双端队列中去。
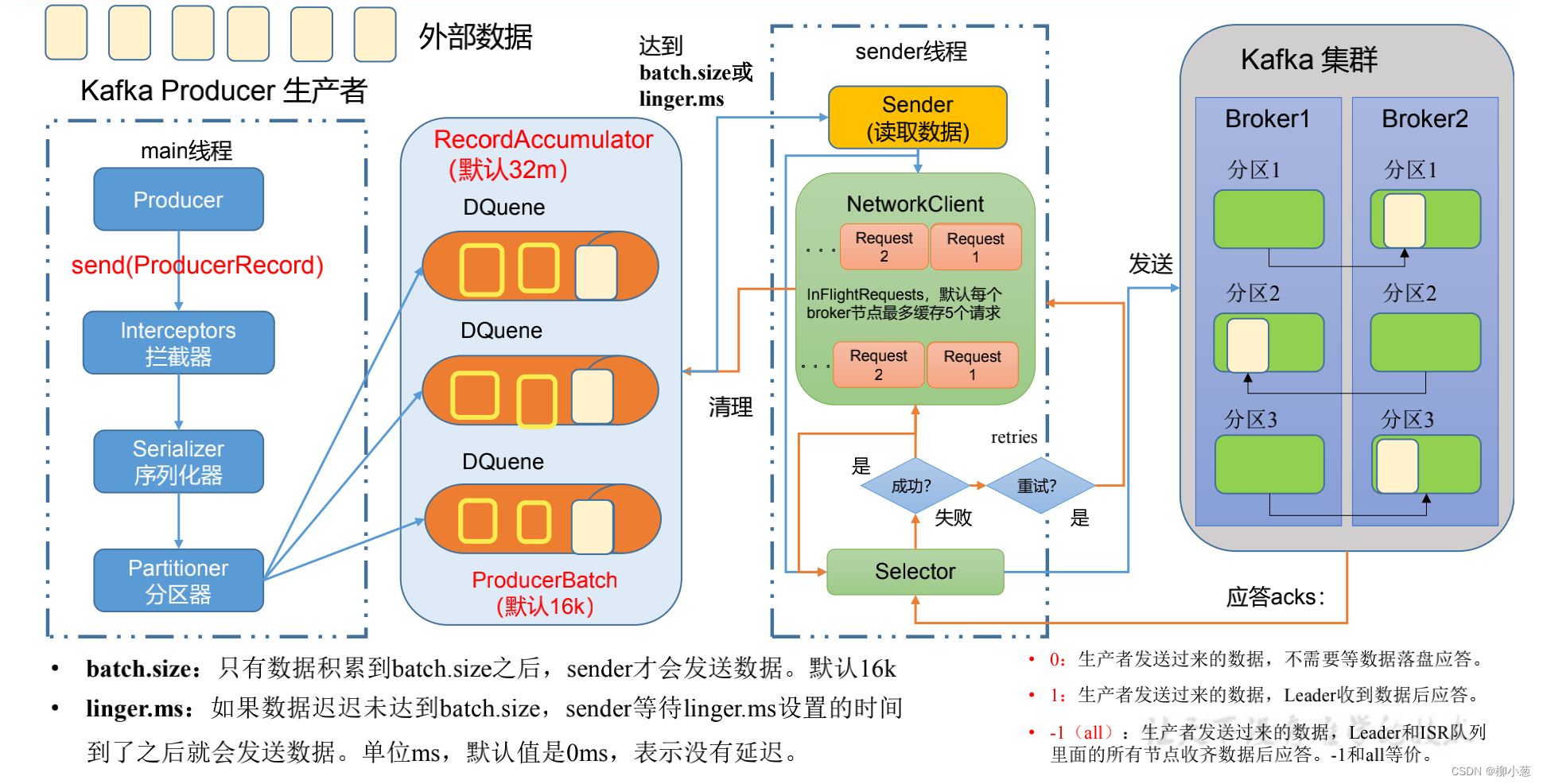
2.2 异步发送
如下图黄色框框,代表的是分区内一批一批的数据,main线程只管将数据写入双端队列,而不用管数据是否被kafka集群拉取成功。
3. 生产者分区
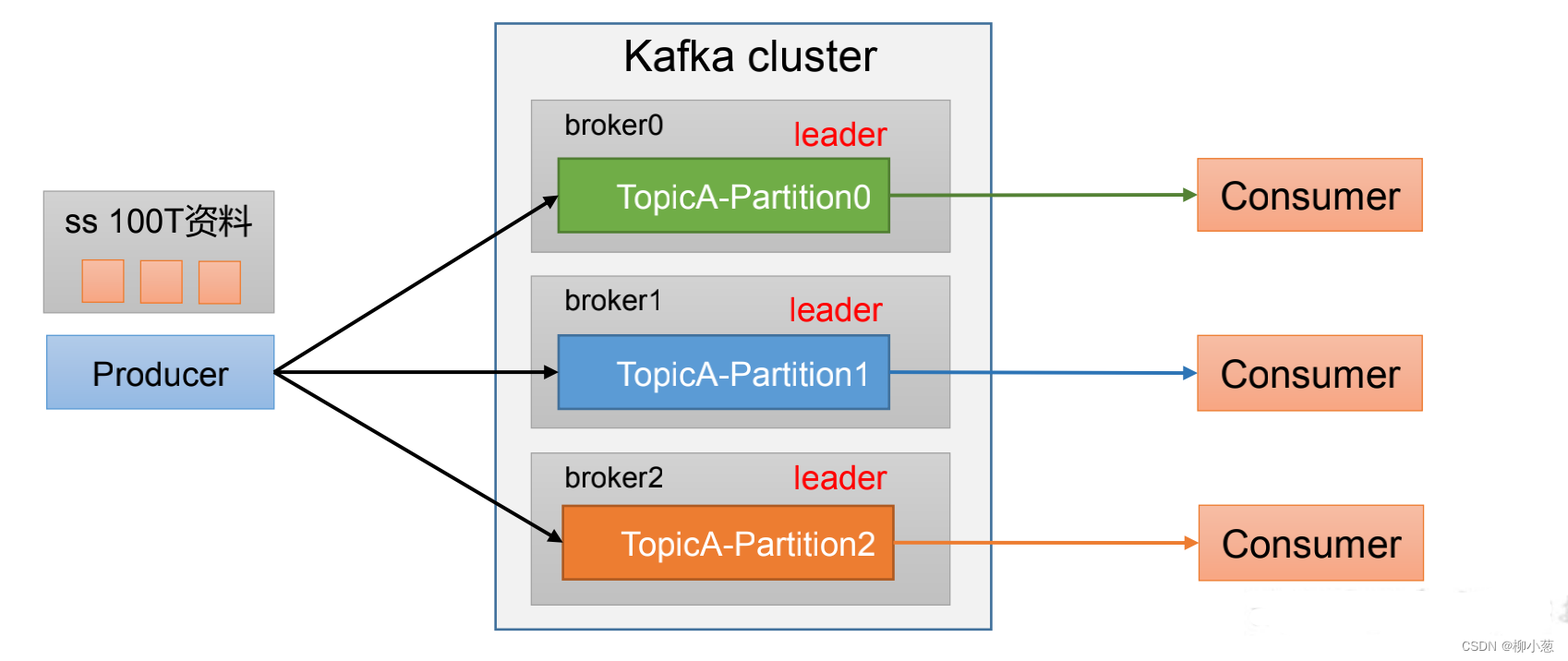
生产者的分区是在分区器partitioner中进行分区的,分区的概念就是将数据进行切割,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
如下图:100T的数据可以分区成3份,3份大小可以一样,也可以不一样,消费者可以根据分区同时消费数据。
kafka的默认分区方法叫做:DefaultPartitioner分区方法
1. If a partition is specified in the record, use it.
2. If no partition is specified but a key is present choose a
partition based on a hash of the key.
3. If no partition or key is present choose the sticky
partition that changes when the batch is full.
解释一下:
- 如果数据指定了分区,那么就按照指定的分区
- 没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值。
例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那 么key1 对应的value1写入1号分区,key2对应的value2写入0号分区。 - 既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进
行使用(如果还是0会继续随机)。
可以通过 1.定义类实现 Partitioner 接口。2. 重写 partition()方法。进行自定义分区操作。
4. 生产者吞吐量建议
生产者如何设置可以提高数据的吞吐量呢?
- batch.size:批次大小,默认16k
- linger.ms:等待时间,修改为5-100ms一次拉一个,来了就走
- compression.type:压缩snappy
- RecordAccumulator:缓冲区大小,修改为64m
5. 参考资料
-《尚硅谷大数据技术之 Kafka》
-《kafka权威指南》

