kafkaФЌШЯЧщПіЯТ,ЬсЙЉЕФЪЧжСЩйвЛДЮЕФПЩППадБЃеЯЁЃМДbrokerБЃеЯвбЬсНЛЕФЯћЯЂЕФЗЂЫЭ,ЕЋЪЧгіЩЯФГаЉвтЭтЧщПі,Шч:ЭјТчЖЖЖЏ,ГЌЪБЕШЮЪЬт,ЕМжТProducerУЛгаЪеЕНbrokerЗЕЛиЕФЪ§Онack,дђProducerЛсМЬајжиЪдЗЂЫЭЯћЯЂ,ДгЖјЕМжТЯћЯЂжиИДЗЂЫЭЁЃ
ШчЙћЮвУЧНћжЙProducerЕФЪЇАмжиЪдЗЂЫЭЙІФм,ЯћЯЂвЊУДаДШыГЩЙІ,вЊУДаДШыЪЇАм,ЕЋОјВЛЛсжиИДЗЂЫЭЁЃетбљОЭЪЧзюЖрвЛДЮЕФЯћЯЂБЃеЯФЃЪНЁЃЕЋЖдгкЯћЯЂзщМў,ХХГ§ЬиЪтвЕЮёГЁОА,ЮвУЧзЗЧѓЕФвЛЖЈЪЧОЋШЗвЛДЮЕФЯћЯЂБЃеЯФЃЪНЁЃkafkaЭЈЙ§ УнЕШад(Idempotence)КЭЪТЮё(Transaction) ЕФЛњжЦ,ЬсЙЉСЫетжжОЋШЗЕФЯћЯЂБЃеЯЁЃ
дкжЎЧАЕФОЩАцБОжа,KafkaжЛФмжЇГжСНжжгявх:At most onceКЭAt least onceЁЃЖјKafkaдк 0.11.0.0 АцБОжЇГждіМгСЫЖдУнЕШЕФжЇГжЁЃУнЕШЪЧеыЖдЩњВњепНЧЖШЕФЬиадЁЃУнЕШПЩвдБЃжЄЩЯЩњВњепЗЂЫЭЕФЯћЯЂ,ВЛЛсЖЊЪЇ,ЖјЧвВЛЛсжиИДЁЃ
УнЕШадвЊНтОіЕФЮЪЬт?
дк 0.11.0 жЎЧА,Kafka ЭЈЙ§ Producer ЖЫКЭ Server ЖЫЕФЯрЙиХфжУПЩвдзіЕН Ъ§ОнВЛЖЊ ,вВОЭЪЧ at least once,ЕЋЪЧдквЛаЉЧщПіЯТ,ПЩФмЛсЕМжТЪ§ОнжиИД,БШШч:ЭјТчЧыЧѓбгГйЕШЕМжТЕФжиЪдВйзї,дкЗЂЫЭЧыЧѓжиЪдЪБ Server ЖЫВЂВЛжЊЕРетЬѕЧыЧѓЪЧЗёвбОДІРэ(УЛгаМЧТМжЎЧАЕФзДЬЌаХЯЂ),ЫљвдОЭЛсгаПЩФмЕМжТЪ§ОнЧыЧѓЕФжиИДЗЂЫЭ,етЪЧ Kafka здЩэЕФЛњжЦ(вьГЃЪБЧыЧѓжиЪдЛњжЦ)ЕМжТЕФЪ§ОнжиИДЁЃ
ЖдгкДѓЖрЪ§гІгУЖјбд,Ъ§ОнБЃжЄВЛЖЊЪЧПЩвдТњзуЦфашЧѓЕФ,ЕЋЪЧЖдгквЛаЉЦфЫћЕФгІгУГЁОА(БШШчжЇИЖЪ§ОнЕШ),ЫќУЧЪЧвЊЧѓОЋШЗМЦЪ§ЕФ,етЪБКђШчЙћЩЯгЮЪ§ОнгажиИД,ЯТгЮгІгУжЛФмдкЯћЗбЪ§ОнЪБНјааЯргІЕФШЅжиВйзї,гІгУдкШЅжиЪБ,зюГЃгУЕФЪжЖЮОЭЪЧИљОнЮЈвЛ id Мќзі check ШЅжиЁЃ
дкетжжГЁОАЯТ,вђЮЊЩЯгЮЩњВњЕМжТЕФЪ§ОнжиИДЮЪЬт,ЛсЕМжТЫљгагаОЋШЗМЦЪ§ашЧѓЕФЯТгЮгІгУЖМашвЊзіетжжИДдгЕФЁЂжиИДЕФШЅжиДІРэЁЃЪдЯывЛЯТ:ШчЙћдкЗЂЫЭЪБ,ЯЕЭГОЭФмБЃжЄ exactly once,етЖдЯТгЮНЋЪЧЖрУДДѓЕФНтЭбЁЃетОЭЪЧУнЕШадвЊНтОіЕФЮЪЬт,жївЊЪЧНтОіЪ§ОнжиИДЕФЮЪЬт,е§ШчЧАУцЫљЪі,Ъ§ОнжиИДЮЪЬт,ЭЈгУЕФНтОіЗНАИОЭЪЧМгЮЈвЛ id,ШЛКѓИљОн id ХаЖЯЪ§ОнЪЧЗёжиИД,Producer ЕФУнЕШадвВЪЧетбљЪЕЯжЕФЁЃ
Kafka ЪЧдѕУДБЃжЄУнЕШадЕФ?
KafkaЮЊСЫЪЕЯжУнЕШад,ЫќдкЕзВуЩшМЦМмЙЙжав§ШыСЫProducerIDКЭSequenceNumberЁЃ
- ProducerID:дкУПИіаТЕФProducerГѕЪМЛЏЪБ,ЛсБЛЗжХфвЛИіЮЈвЛЕФProducerID,етИіProducerIDЖдПЭЛЇЖЫЪЙгУепЪЧВЛПЩМћЕФЁЃ
- SequenceNumber:ЖдгкУПИіProducerID,ProducerЗЂЫЭЪ§ОнЕФУПИіTopicКЭPartitionЖМЖдгІвЛИіДг0ПЊЪМЕЅЕїЕндіЕФSequenceNumberжЕЁЃ
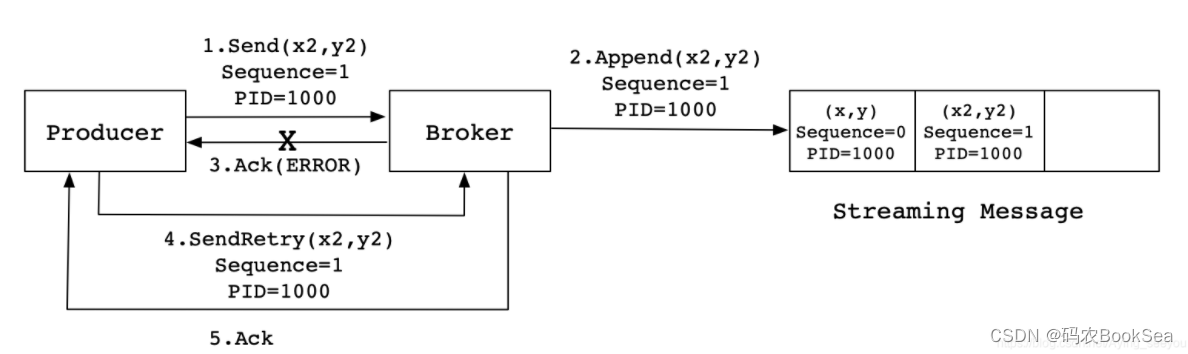
ЕБProducerЗЂЫЭЯћЯЂ(x2,y2)ИјBrokerЪБ,BrokerНгЪеЕНЯћЯЂВЂНЋЦфзЗМгЕНЯћЯЂСїжаЁЃДЫЪБ,BrokerЗЕЛиAckаХКХИјProducerЪБ,ЗЂЩњвьГЃЕМжТProducerНгЪеAckаХКХЪЇАмЁЃЖдгкProducerРДЫЕ,ЛсДЅЗЂжиЪдЛњжЦ,НЋЯћЯЂ(x2,y2)дйДЮЗЂЫЭ,ЕЋЪЧ,гЩгкв§ШыСЫУнЕШад,дкУПЬѕЯћЯЂжаИНДјСЫPID(ProducerID)КЭSequenceNumberЁЃЯрЭЌЕФPIDКЭSequenceNumberЗЂЫЭИјBroker,ЖјжЎЧАBrokerЛКДцЙ§жЎЧАЗЂЫЭЕФЯрЭЌЕФЯћЯЂ,ФЧУДдкЯћЯЂСїжаЕФЯћЯЂОЭжЛгавЛЬѕ(x2,y2),ВЛЛсГіЯжжиИДЗЂЫЭЕФЧщПіЁЃ
ПЊЦєУнЕШадХфжУ
жЛашвЊАб Producer ЕФХфжУ enable.idempotence ЩшжУЮЊ true МДПЩ
props.put(ЁАenable.idempotenceЁБ, ture)
//Лђеп
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)
KafkaУнЕШадЕФОжЯоад
ПЊЦєenable.idempotenceКѓ,kafkaОЭЛсздЖЏАяФузіКУЯћЯЂШЅжиЕФвЛЯЕСаЙЄзїЁЃЕзВуОпЬхЪЕЯждРэКмМђЕЅ,ОЭЪЧгУПеМфЛЛЪБМфЕФгХЛЏЫМТЗ,МДдкbrokerЖЫЖрДцвЛаЉзжЖЮРДБъЪЖЪ§ОнЕФЮЈвЛадЁЃЕБProducerЗЂЫЭСЫОпгаЯрЭЌзжЖЮжЕЕФЯћЯЂКѓ,brokerЛсНјааЦЅХфШЅжи,ЖЊЦњжиИДЕФЪ§ОнЁЃЪЕМЪЕФДњТыУЛетУДМђЕЅ,ЕЋДѓжТЪЧетУДИіДІРэТпМЁЃ
ЙйЗНЕФетИіУнЕШЪЕЯжПДЫЦМђЕЅИпаЇ,ЕЋвВДцдкЫћЕФОжЯоадЁЃЫћжЛФмБЃжЄЕЅЗжЧјЩЯЕФУнЕШад,МДвЛИіУнЕШадProducerжЛФмЙЛБЃжЄФГИіtopicЕФвЛИіЗжЧјЩЯВЛГіЯжжиИДЯћЯЂ,ЮоЗЈЪЕЯжЖрЗжЧјЕФУнЕШЁЃДЫЭт,ШчЙћProducerжиЦє,вВЛсЕМжТУнЕШжижУЁЃ
ЪТЮё
ЖдгкЖрЗжЧјБЃжЄУнЕШЕФГЁОА,дђашвЊЪТЮёЬиадРДДІРэСЫЁЃkafkaЕФЪТЮёИњЮвУЧГЃМћЪ§ОнПтЪТЮёИХФюВюВЛЖр,вВЪЧЬсЙЉОЕфЕФACID,МДдзг(Atomicity)ЁЂвЛжТад (Consistency)ЁЂИєРыад (Isolation) КЭГжОУад (Durability)ЁЃ
ЪТЮёProducerБЃжЄЯћЯЂаДШыЗжЧјЕФдзгад,МДетХњЯћЯЂвЊУДШЋВПаДШыГЩЙІ,вЊУДШЋЪЇАмЁЃДЫЭт,ProducerжиЦєЛиРДКѓ,kafkaвРШЛБЃжЄЫќУЧЗЂЫЭЯћЯЂЕФОЋШЗвЛДЮДІРэЁЃЪТЮёЬиадЕФХфжУвВКмМђЕЅ:
КЭУнЕШProducerвЛбљ,ПЊЦєenable.idempotence = trueЩшжУProducerЖЫВЮЪ§transctional.idЪТЮёProducerЕФДњТыЩдЮЂвВгаЕуВЛвЛбљ,ашвЊЕївЛаЉЪТЮёДІРэЕФAPIЁЃЪ§ОнЕФЗЂЫЭашвЊЗХдкbeginTransactionКЭcommitTransactionжЎМфЁЃConsumerЖЫЕФДњТывВашвЊМгЩЯisolation.levelВЮЪ§,гУвдДІРэЪТЮёЬсНЛЕФЪ§ОнЁЃЪОР§ДњТы:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
ЪТЮёProducerЫфШЛдкЖрЗжЧјЕФЪ§ОнДІРэЩЯБЃжЄСЫУнЕШ,ЕЋЪЧДІРэадФмЩЯЯргІЕФЪЧЛсгавЛаЉЯТНЕЕФЁЃ

