0����Ŀ��ַ
������Ŀ��GitHub��ַ
https://github.com/taw19960426/learning-go-language/tree/main/go-log-collect
һ����־�ռ�ϵͳ����
1. ��Ŀ����
- a. ÿ��ϵͳ������־,��ϵͳ��������ʱ,��Ҫͨ����־�������
- b. ��ϵͳ�����Ƚ���ʱ,��½���������ϲ鿴��������
- c. ��ϵͳ������ģ��,��½�������ϲ鿴��������ʵ
2. �������
- a. �ѻ����ϵ���־ʵʱ�ռ�,ͳһ�Ĵ洢������ϵͳ
- b. Ȼ���ٶ���Щ��־��������,ͨ�������������ҵ���Ӧ��־
- c. ͨ���ṩ�����Ѻõ�web����,ͨ��web�����������־����
3. ����������
- a. ʵʱ��־���dz���,ÿ�켸ʮ����
- b. ��־ʵʱ�ռ�,�ӳٿ����ڷ��Ӽ���
- c. �ܹ�ˮƽ����չ
4. ҵ�緽��ELK
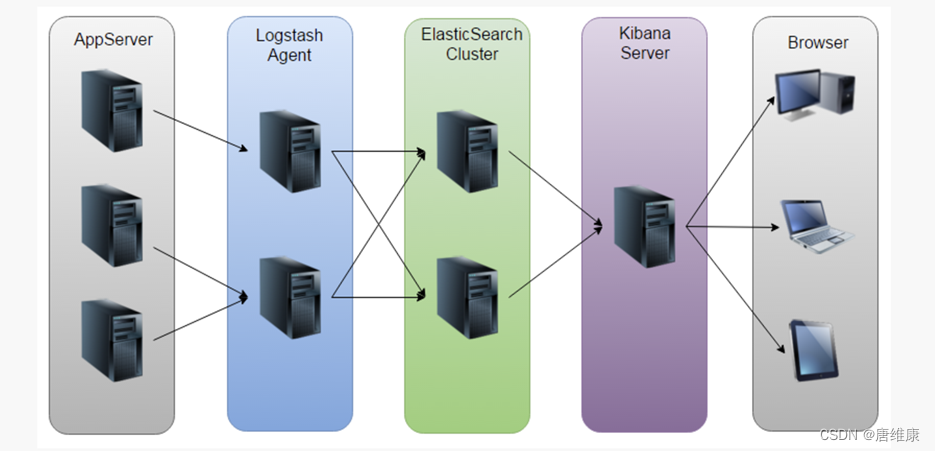
5. ELK��������
- a. ��ά�ɱ���,ÿ����һ����־�ռ�,����Ҫ�ֶ�������
- b. ���ȱʧ,��ȷ��ȡlogstash��״̬
- c. �������ƻ������Լ�ά��
������־�ռ�ϵͳ�ܹ�
1. ��־�ռ�ϵͳ���
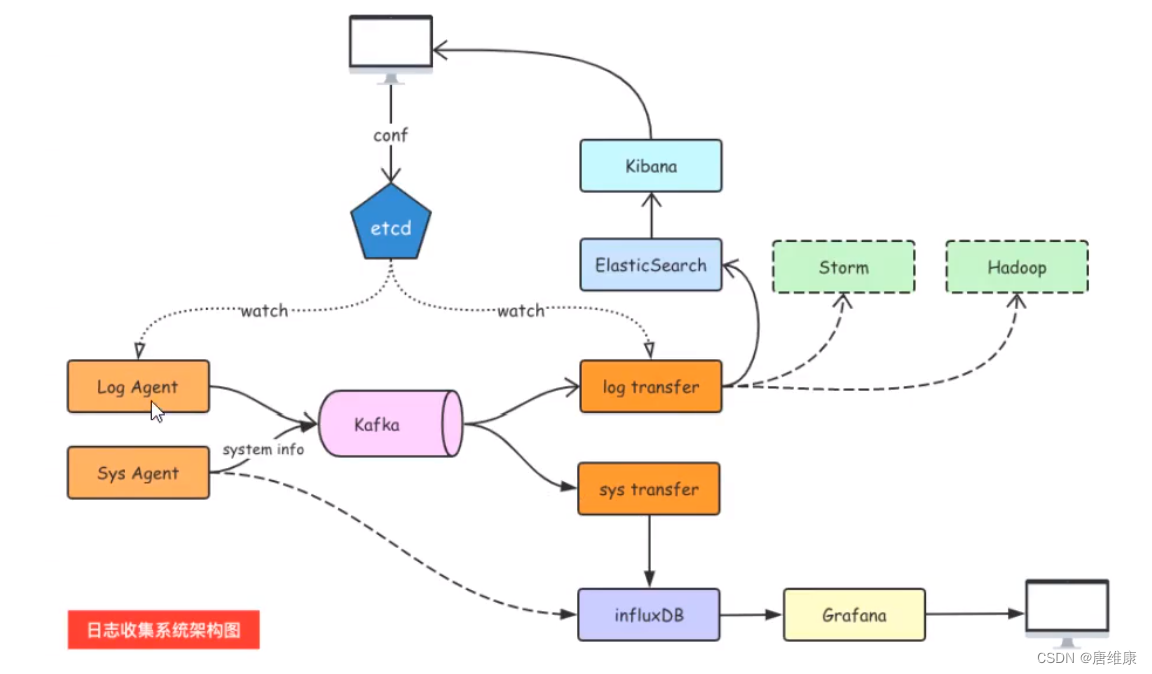
2. ���������
- Log Agent,��־�ռ��ͻ���,�����ռ��������ϵ���־
- Kafka,���������ķֲ�ʽ����,linkin����,apache������Դ��Ŀ
- ES,elasticsearch,��Դ����������,�ṩ����http restful��web�ӿ�
- Kibaa:��Դ��ES���ݷ����Ϳ��ӻ�����
- Hadoop,�ֲ�ʽ������,�ܹ��Դ������ݽ��зֲ�ʽ������ƽ̨
- Storm:һ����Ѳ���Դ�ķֲ�ʽʵʱ����ϵͳ
3. ���ܸ���
- �����agent����
- ��˷����������
- etcd��ʹ��
- Kafka��zookeeper��ʹ��
- ES��Kibana��ʹ��
4. ��Ϣ���е�ͨ��ģ��
4.1 ��Ե�ģʽ(queue)

? ��Ϣ������������Ϣ���͵�queue��,Ȼ����Ϣ�����ߴ�queue��ȡ������������Ϣ��һ����Ϣ�������Ժ�,queue�о�û����,�������ظ����ѡ�
4.2 ����/����(topic)
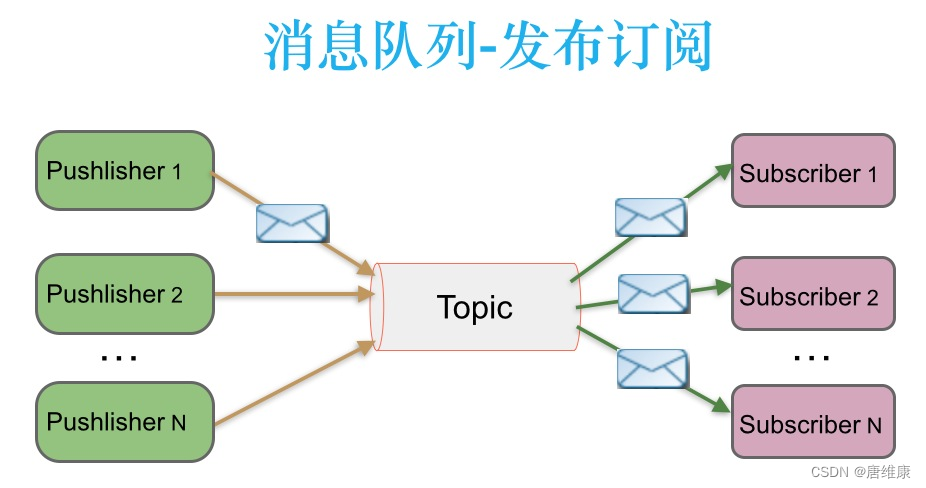
? ��Ϣ������(����)����Ϣ������topic��,ͬʱ�ж����Ϣ������(����)���Ѹ���Ϣ���͵�Ե㲻ͬ,������topic����Ϣ�ᱻ���ж���������(�����ڹ�ע���Ź��ںŵ��˶����յ����͵�����)��
����:��������ģʽ��,����������Ϣ���ܴ�ʱ,��Ȼ���������ߵĴ��������Dz���ġ�ʵ������ʵ�������Ƕ�������߽ڵ����һ�������鸺�ؾ�������topic��Ϣ�����鶩��,���������ߺ�����ʵ����������������չ�����Կ�����һ��topic���ж��Queue,ÿ��Queue�ǵ�Ե�ķ�ʽ,Queue֮���Ƿ������ķ�ʽ��
5. Kafka
5.1 ����
? Apache Kafka������ְҵ�罻��˾LinkedLn����,����DZ�����������Linkedln��˾�ڲ�������־�������⡣kafkaʹ��Scala���Ա�д,��2011�꿪Դ������Apache������,2012��10����ʽ��ҵ,����ΪApache������Ŀ��
? Kafka��һ���ֲ�ʽ������ƽ̨,���������ڵ�̨��������,Ҳ�����ڶ�̨�������ϲ����γɼ�Ⱥ�����ṩ�˷����Ͷ��Ĺ���,ʹ���߿��Է������ݵ�Kafka��,Ҳ���Դ�Kafka�ж�ȡ����(�Ա���к����Ĵ���)��Kafka���и����¡����ӳ١����ݴ����ص㡣������ھ��Ƿֲ�ʽ��,�����ĺͿɸ��Ƶ��ύ��־����
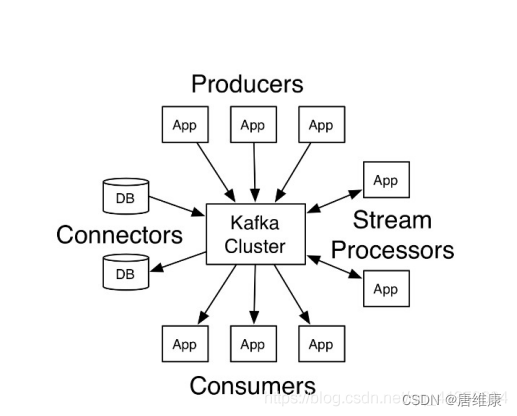

5.2 �ܹ����
- Producer: Producer��������,��Ϣ�IJ�����,����Ϣ�����,������Kafka�з�������(record)��
- kafka cluster: kafka��Ⱥ,һ̨���̨���������
- Broker:Broker��ָ������kafkaʵ���ķ������ڵ�,ÿ������������һ������kafka��ʵ��,���ǹ��Ҷ���ÿ��broker��Ӧһ̨��������ÿ��kafka��Ⱥ�ڵ�broker����һ�����ظ��ı��,��ͼ�е�broker-0��broker-1�ȡ�
- Topic:��Ϣ������,��������Ϊ��Ϣ�ķ���,�������ֲ�ͬ������Ϣ�����⡣kafka�����ݾͱ�����topi����ÿ��broker�϶����Դ������topic��ʵ��Ӧ����ͨ����һ��ҵ���߽�һ��topic������Ӧ�ó���A����������t1,Ӧ�ó���B����������t2��û�ж���t1,��ô���͵�����t1�е����ݽ�ֻ�ܱ�Ӧ�ó���A����,�����ᱻӦ�ó���B������
- Partition:Topic�ķ���,ÿ��topic������һ������partition(����),�����������Ǹ���,���kafka����������ͬһ��topic�ڲ�ͬ�ķ����������Dz��ظ���,partition�ı�����ʽ����һ��һ�����ļ��С�Kafkaʹ�÷���֧�������ϵIJ���д��Ͷ�ȡ,�Ӷ�����������������
- Replication: ÿһ���������ж������,����������������̥����������(Leader)���ϵ�ʱ���ѡ��һ����̥(Follower)��λ,��ΪLeader����kafka��Ĭ�ϸ��������������10��,�Ҹ������������ܴ���Broker������,follower��leader�������ڲ�ͬ�Ļ���,ͬһ������ͬһ����Ҳֻ�ܴ��һ������(�����Լ�)
- Record ��Ϣ
ʵ��д��Kafka�в����Ա���ȡ����Ϣ��¼��ÿ��record������key��value��timestamp�� - Consumer:������,����Ϣ�����ѷ�,����Ϣ�ij���,������ȡKafka�е�����(record)��
- Consumer Group:������,һ���������������һ�����������ߡ���kafka�������ͬһ������������ֻ�ܱ����������е�ijһ�����������ѡ�ͬһ����������������߿�������ͬһ��topic�IJ�ͬ����������,ʹ�ö����+�������߷�ʽ���Լ�������������صĴ����ٶȡ�
- Segment:��Ϣ�ľۺϵ�λ,����һ������Ϣ������
5.3 ��������
���ǿ�����ļܹ�ͼ��,producer����������,�����ݵ���ڡ�Producer��д�����ݵ�ʱ����Զ����leader,����ֱ�ӽ�����д��follower!��leader��ô����?д�����������ʲô������?����ͼ��

-
�����ߴ�kafka��Ⱥ�л�ȡ����Leader��Ϣ
-
�����߽���Ϣ����leader
-
leader����Ϣд�뱾�ش���
-
follower��leader��ȡ��Ϣ����
-
follower����Ϣд�뱾�ش��̺���leader����ACK
-
leader�յ����е�follower��ACK���������߷���ACK

5.4 ѡ��partition��ԭ��
? ��kafka��,���ij��topic�ж��partion,producer����ô֪���ý����ݷ����ĸ�partition��?kafka���뼸��ԭ��:
- partition��д���ʱ�����ָ����Ҫд���partition,�����ָ��,��д���Ӧ��partition��
- ���û��ָ��partition,�������������ݵ�key,������key��ֵhash��һ��partition��
- �����ûָ��partition,��û������key,��������ѯ��ʽ,��ÿ��ȡһС��ʱ�������д��ij��partiton,��һС�ε�ʱ��д����һ��partition��
5.5 ACKӦ�����
? producer����kafkaд����Ϣ��ʱ��,�������ò�����ȷ���Ƿ�ȷ��kafka���յ�����,�������������Ϊ0��1��all��
- 0����producer����Ⱥ�������ݲ���Ҫ�ȵ���Ⱥ�ķ���,��ȷ����Ϣ���ͳɹ�����ȫ����͵���Ч����ߡ�
- 1����producer����Ⱥ��������ֻҪleaderӦ��Ϳ��Է�����һ��,ֻȷ��leader���ͳɹ���
- all����producer����Ⱥ����������Ҫ���е�follower����ɴ�leader��ͬ���Żᷢ����һ��,ȷ��leader���ͳɹ������еĸ�������ɱ��ݡ���ȫ�����,����Ч����͡�
? ���Ҫע�����,����������ڵ�topicд����,�ܲ���д��ɹ���?kafka���Զ�����topic,������������������Ĭ�����ö���1��
5.6 Topic��������־
? topic��ͬһ������Ϣ��¼(record)�ļ��ϡ���Kafka��,һ������ͨ���ж�������ߡ�����ÿ������,Kafka��Ⱥά����һ������������־�ļ��ṹ����:

? ÿ��partition����һ�������Ҳ��ɱ����Ϣ��¼���ϡ����µ�����д��ʱ,�ͱ��ӵ�partition��ĩβ����ÿ��partition��,ÿ����Ϣ���ᱻ����һ��˳���Ψһ��ʶ,�����ʶ����Ϊoffset,��ƫ������ע��,Kafkaֻ��֤��ͬһ��partition�ڲ���Ϣ�������,�ڲ�ͬpartition֮��,�����ܱ�֤��Ϣ����
? Kafka��������һ����������,������ʶ��־����Kafka��Ⱥ�ڱ����ʱ�䡣Kafka��Ⱥ�ᱣ���ڱ������������б���������Ϣ,������Щ��Ϣ�Ƿ����ѹ������籣����������Ϊ����,��ô���ݱ�������Kafka��Ⱥ����������,���е���Щ���ݶ����Ա����ѡ�����������,��Щ���ݽ��ᱻ���,�Ա�Ϊ�����������ڳ��ռ䡣����Kafka�Ὣ���ݽ��г־û��洢(��д�뵽Ӳ����),���Ա��������ݴ�С��������Ϊһ���Ƚϴ��ֵ��
5.7 Partition�ṹ
? Partition�ڷ������ϵı�����ʽ����һ��һ�����ļ���,ÿ��partition���ļ���������ж���segment�ļ�,����segment�ļ��ְ���.index�ļ���.log�ļ���.timeindex�ļ������ļ�,����.log�ļ�����ʵ�ʴ洢message�ĵط�,��.index��.timeindex�ļ�Ϊ�����ļ�,���ڼ�����Ϣ��
5.8 ��������
? ���������ʵ���������һ����������,����һ����ǩ����ʶ����������顣һ�����������еIJ�ͬ������ʵ�����������ڲ�ͬ�Ľ���������ͬ�ķ������ϡ�
? ������е�������ʵ������ͬһ������������,��ô��Ϣ��¼�ᱻ�ܺõľ���ķ��͵�ÿ��������ʵ����
? ������е�������ʵ�����ڲ�ͬ����������,��ôÿһ����Ϣ��¼�ᱻ�㲥��ÿһ��������ʵ����
? �ٸ����ӡ�����ͼ��ʾ,һ�������ڵ��Kafka��Ⱥ��ӵ��һ���ĸ�partition(P0-P3)��topic���������������鶼���������topic�е�����,��������A������������ʵ��,��������B���ĸ�������ʵ������ͼ�����ǿ��Կ���,��ͬһ������������,ÿ��������ʵ���������Ѷ������,����ÿ���������ֻ�ܱ����������е�һ��ʵ�����ѡ�Ҳ����˵,�����һ��4������������,��ô�������������ֻ����4��������ʵ��ȥ����,������Ķ����ᱻ���䵽��������ʵ��Ҳ�ܺ�����,�����������������ʵ��ͬʱ����ͬһ������,��ô������¼�����������������������ѵ�offset�ˡ���������������ж�̬����������������,��ôKafka��Ⱥ���Զ�����������������ʵ����Ķ�Ӧ��ϵ��
5.9 ʹ�ó���
��Ϣ����(MQ)
��ϵͳ�ܹ������,������ʹ����Ϣ����(Message Queue)����MQ��MQ��һ�ֿ���̵�ͨ�Ż���,���������ε���Ϣ����,ʹ��MQ����ʹ�����ν���,��Ϣ��������ֻ��Ҫ����MQ,���Ϻ������϶�����Ҫ�����������η���MQ�ij���ʹ�ó������������塢�������������������ȵȡ���MQ����,����Kafka��д�ͳ����Ϣ������ActiveMQ��RabbitMQ�ȡ�
����վ�
Kafka������DZ��������������վ�(����PV��UV��������¼��)���١����Խ���ͬ�Ļ���벻ͬ������,��������ʵʱ���㡢ʵʱ��صȳ���ʹ��,Ҳ���Խ����ݵ��뵽���ݲֿ��н��к��������ߴ��������ɱ����ȡ�
Metrics
Kafka�������������������ݡ���Ҫ�����ۺϷֲ�ʽӦ�ó����ͳ������,�����ݼ��к����ͳһ�ķ�����չʾ�ȡ�
��־�ۺ�
�ܶ���ʹ��Kafka��Ϊ��־�ۺϵĽ����������־�ۺ�ͨ��ָ����ͬ�������ϵ���־�ռ�����������һ����־����,����һ̨�ļ�����������HDFS�е�һ��Ŀ¼,���������з��������������Flume��Scribe����־�ۺϹ���,Kafka���и���ɫ�����ܡ�
5.10 �ŵ�
- �ɿ��� - Kafka�Ƿֲ�ʽ,����,���ƺ��ݴ��ġ�
- ����չ�� - Kafka��Ϣ����ϵͳ��������,����ͣ����
- ������ - Kafkaʹ�÷ֲ�ʽ�ύ��־,����ζ����Ϣ�ᾡ���ܿ�ر����ڴ�����,������dz־õġ�
- ���� - Kafka���ڷ����Ͷ�����Ϣ�����и��������� ��ʹ�洢������TB����Ϣ,��Ҳ�����ȶ������ܡ�
- Kafka�dz���,����֤��ͣ���������ݶ�ʧ��
5.11 kafkaΪʲô��?
Kafka����Ϣ�DZ�����ڴ����ϵ�,һ����Ϊ�ڴ����϶�д�����ǻή�����ܵ�,��ΪѰַ��Ƚ�����ʱ��,����ʵ����,Kafka������֮һ���Ǹ������ʡ�
��ʹ����ͨ�ķ�����,KafkaҲ��������֧��ÿ�����д������,�����˴ֵ���Ϣ�м��,��������Ҳʹ��Kafka����־�����Ⱥ������ݳ����㷺Ӧ�á�
Kafka�ٶȵ��ؾ�����,�������е���Ϣ�����һ���������ļ�,���ҽ��к���������ѹ��,��������IO���,ͨ��mmap���I/O�ٶ�,д�����ݵ�ʱ�����ڵ���Partion��ĩβ���������ٶ�����;��ȡ���ݵ�ʱ�����sendfileֱ�ӱ��������
��ϸ���ܲο�:https://www.cnblogs.com/binyue/p/10308754.html
6. Zookeeper
Zookeeper��һ���ֲ�ʽ��,����Դ��ķֲ�ʽӦ�ó���Э������,��Google��Chubbyһ����Դ��ʵ��,���Ǽ�Ⱥ�Ĺ�����,������Ⱥ�и����ڵ��״̬,���ݽڵ��ύ�ķ���������һ����������������,�������õĽӿں����ܸ�У�������ȶ���ϵͳ�ṩ���û���
ZooKeeper��Ҫ�������¼������:
- Client(�ͻ���):���ǵķֲ�ʽӦ�ü�Ⱥ�е�һ���ڵ�,�ӷ�����������Ϣ�������ض���ʱ����,ÿ���ͻ����������������Ϣ��ʹ������֪���ͻ����ǻ�Ծ�ġ����Ƶ�,���ͻ�������ʱ,����������ȷ���롣������ӵķ�����û����Ӧ,�ͻ��˻��Զ�����Ϣ�ض�����һ����������
- Server(������):������,���ǵ�ZooKeeper�����е�һ���ڵ�,Ϊ�ͻ����ṩ���еķ�����ͻ��˷���ȷ�����Ը�֪�������ǻ�Ծ�ġ�
- Ensemble:ZooKeeper�������顣�γ�ensemble�������С�ڵ���Ϊ3��
- Leader: �������ڵ�,����κ����ӵĽڵ�ʧ��,��ִ���Զ��ָ���Leader�ڷ�������ʱ��ѡ�١�
- Follower:����leaderָ��ķ������ڵ㡣
ZooKeeper��Ӧ�ó���:
����ע��&������
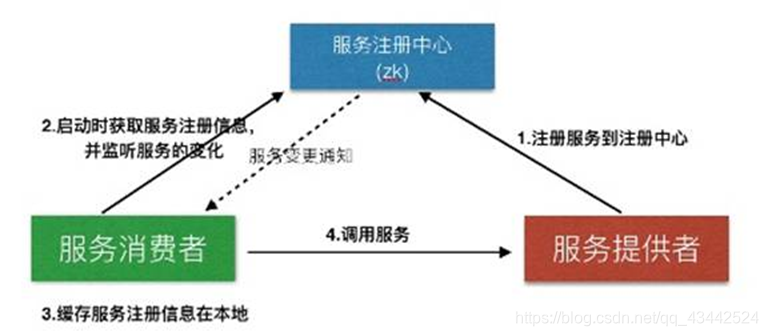
��������
- �ֲ�ʽ��
Zookeeper��ǿһ�µĶ���ͻ���ͬʱ��Zookeeper�ϴ�����ͬznode,ֻ��һ�������ɹ�
������־�ռ�ϵͳ�����
1. JDK�������밲װ
-
��װ�ļ�:http://www.oracle.com/technetwork/java/javase/downloads/index.html ����JDK
-
jdk����:https://repo.huaweicloud.com/java/jdk/
-
��װ��ɺ���Ҫ�������µĻ�������(�Ҽ�������ҵĵ��ԡ� -> ����ϵͳ���á� -> ������������ ):
- JAVA_HOME: F:\jdk11 (jdk�İ�װ·��)
- Path: �����е�ֵ��������"; %JAVA_HOME%\bin"
-
��cmd���� ��java -version�� �鿴��ǰϵͳJava�İ汾:

2. ��װZOOKEEPER
Kafka������������Zookeeper,����������Kafka֮ǰ������Ҫ��װ������Zookeeper,��װzookeeper�����ַ�ʽ,����Kafka 0.5.x�汾�����Ѿ��Դ�ZooKeper,����Ҫ�Լ���װZooKeeper�����Կ���ʹ��kafka�Դ���zoopeeper,Ҳ�����Լ�������װ��������ܵ�����װ��ʽ:
-
���ذ�װ�ļ�:http://www.apache.org/dyn/closer.cgi/zookeeper/
-
��ѹ�ļ�
-
��zookeeper�ļ��е�confĿ¼,��zoo_sample.cfg��������zoo.cfg
-
���ı��༭�����zoo.cfg
-
��dataDir��ֵ�ij�zoopeeper���ļ���Ŀ¼�µ�data(zoopeeper���ݴ�ŵ�ַ)
-
��������ϵͳ����:
? ZOOKEEPER_HOME: zookeeperĿ¼
? Path: �����е�ֵ�������� ��;%ZOOKEEPER_HOME%\bin;��
-
����Zookeeper: ��cmdȻ��ִ�� zkserver
3. ��װKAFKA
-
����kafka������Ŀ¼,�༭server.properties�ļ�,��log.dirs=XXX(XXX��ʾkafka��־·��),zookeeper.connect=XXX(Ĭ����localhost:2181,��������һ����Zookeeper�Ķ˿�,��Ҫ��������)
-
kafka���Զ�Ĭ��ʹ��9092�˿�,����䶯,������listeners=PLAINTEXT://:XXXX(��XXXX���ɱ䶯��Ķ˿�)
-
��kafkaĿ¼,����bin/windowsĿ¼��,shift+����Ҽ�ѡ��������(Ҳ����ֱ��ͨ��cmd cd �ļ�Ŀ¼�ķ�ʽ����)
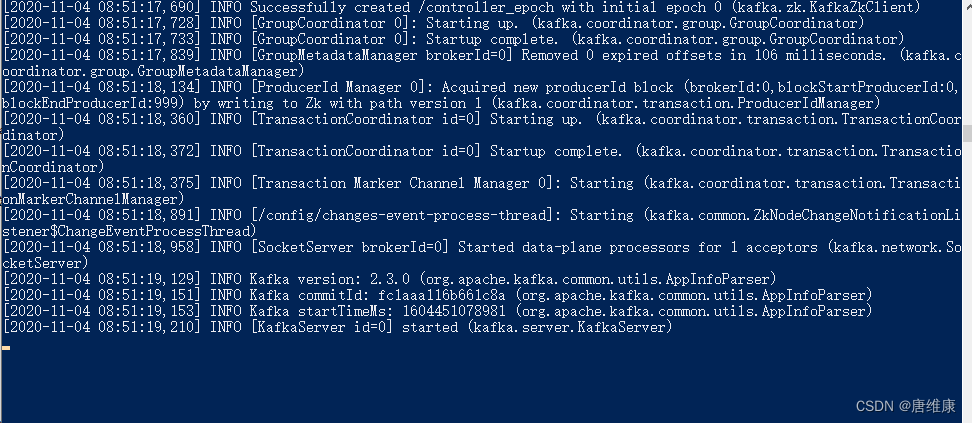
# ����zoopeeper bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties # ����kafka bin\windows\kafka-server-start.bat .\config\server.properties![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-NaYyOe47-1651574076489)(images/06_����zookeeper.png)]](https://img-blog.csdnimg.cn/561430ed698c4784a31c5680d0bba657.png)
�ġ�LogAgent
��������linux��ͨ��tail�ķ�������־�ļ�,����ȡ�����ݷ���kafka,�����tailf�ǿ��Զ�̬�仯��,�������ļ������仯ʱ,����֪ͨ���dz����Զ�������Ҫ���ӵ������ļ���tailfȥ��ȡ��Ӧ����־������kafka producer����Ҫ����kafka��tailf��configlog��
LogAgent��������
- ����־�C
tailf�������� - ��
kafkaд��־ �Csarama�������� - ��ȡ�����ļ� �C
"gopkg.in/ini.v1"
1. tail
-
����
"github.com/hpcloud/tail" -
ʹ��ʾ��
package main import ( "fmt" "github.com/hpcloud/tail" "time" ) func main() { fileName := "./my.log" config := tail.Config{ ReOpen: true, // ���´� Follow: true, // �Ƿ���� Location: &tail.SeekInfo{Offset: 0, Whence: 2}, // ���ļ����ĸ��ط���ʼ�� MustExist: false, // �ļ������ڲ����� Poll: true, } tails, err := tail.TailFile(fileName, config) if err != nil { fmt.Println("tail file failed, err:", err) return } var ( line *tail.Line ok bool ) for { line, ok = <-tails.Lines//����chan,��ȡ��־���� if !ok { fmt.Printf("tail file close reopen, filename:%s\n", tails.Filename) time.Sleep(time.Second) continue } fmt.Println("line:", line.Text) } } -
ʹ��˵��
- ���ȳ�ʼ�����ýṹ��config
- ����
TailFile����,�������ļ�·����config,�����и�tail�Ľṹ��,tail�ṹ���Lines�ֶη�װ���õ�����Ϣ - ����
tail.Lnes�ֶ�,ȡ����Ϣ(ע������Ҫѭ����ȡ,��Ϊtail����ʵ��ʵʱ���)
-
����


2. sarama
-
����
go get github.com/Shopify/sarama -
������Ϣʾ��
package main import ( "fmt" "github.com/Shopify/sarama" ) func main() { config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll // ������������Ҫleader��follow��ȷ�� config.Producer.Partitioner = sarama.NewRandomPartitioner // ��ѡ��һ��partition config.Producer.Return.Successes = true // �ɹ���������Ϣ����success channel���� // ����һ����Ϣ msg := &sarama.ProducerMessage{} msg.Topic = "web_log" msg.Value = sarama.StringEncoder("this is a test log") // ����kafka client, err := sarama.NewSyncProducer([]string{"127.0.0.1:9092"}, config) if err != nil { fmt.Println("producer closed, err:", err) return } fmt.Println("kafka ���ӳɹ�!") defer client.Close() // ������Ϣ pid, offset, err := client.SendMessage(msg) if err != nil { fmt.Println("send msg failed, err:", err) return } fmt.Printf("pid:%v offset:%v\n", pid, offset) print("���ͳɹ�!") } -
����

kafka�ļ�����

-
����ʾ��
package main import ( "fmt" "github.com/Shopify/sarama" ) // kafka consumer func main() { consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil) if err != nil { fmt.Printf("fail to start consumer, err:%v\n", err) return } partitionList, err := consumer.Partitions("web_log") // ����topicȡ�����еķ��� if err != nil { fmt.Printf("fail to get list of partition:err%v\n", err) return } fmt.Println("����: ", partitionList) for partition := range partitionList { // �������еķ��� // ���ÿ����������һ����Ӧ�ķ��������� pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err) return } defer pc.AsyncClose() // �첽��ÿ������������Ϣ go func(sarama.PartitionConsumer) { for msg := range pc.Messages() { fmt.Printf("Partition:%d Offset:%d Key:%s Value:%s\n", msg.Partition, msg.Offset, msg.Key, msg.Value) } }(pc) } select {} }
3. ���װ�LogAgent
-
��Ŀ�ṹ
�� go.mod �� go.sum �� main.go �� my.log ����conf �� config.go �� config.ini �� ����kafka �� kafka.go �� ����taillog taillog.go -
conf/config.ini:�����ļ�[kafka] address=127.0.0.1:9092 topic=web_log [taillog] filename=./my.log -
conf/config.go:���ö�ȡ�����ļ��Ľṹ��package conf type Config struct { Kafka Kafka `ini:"kafka"` TailLog TailLog `ini:"taillog"` } type Kafka struct { Address string `ini:"address"` Topic string `ini:"topic"` } type TailLog struct { FileName string `ini:"filename"` } -
kafka/kafka.go:kafka��ʼ���Լ�����Ϣд��kafkapackage kafka import ( "fmt" "github.com/Shopify/sarama" ) // ר����kafkaд��־��ģ�� var ( client sarama.SyncProducer // ����һ��ȫ�ֵ�����kafka��������client ) // init��ʼ��client func Init(addrs []string) (err error) { config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll // ������������Ҫleader��follow��ȷ�� config.Producer.Partitioner = sarama.NewRandomPartitioner // ��ѡ��?��partition config.Producer.Return.Successes = true // �ɹ���������Ϣ����success channel���� // ����kafka client, err = sarama.NewSyncProducer(addrs, config) if err != nil { fmt.Println("producer closed, err:", err) return } return } func SendToKafka(topic, data string) { msg := &sarama.ProducerMessage{} msg.Topic = topic msg.Value = sarama.StringEncoder(data) // ���͵�kafka pid, offset, err := client.SendMessage(msg) if err != nil{ fmt.Println("sned mage failed, err:", err) } fmt.Printf("pid:%v offset:%v\n", pid, offset) fmt.Println("���ͳɹ�") } -
taillog/taillog.go:��ȡ��־ģ��,��ʼ��tail�Լ�������־�ļ���ȡchan����package taillog import ( "fmt" "github.com/hpcloud/tail" ) // ר���ռ���־��ģ�� var ( tailObj *tail.Tail logChan chan string ) func Init(filename string) (err error) { config := tail.Config{ ReOpen: true, Follow: true, Location: &tail.SeekInfo{Offset: 0, Whence: 2}, MustExist: false, Poll: true} tailObj, err = tail.TailFile(filename, config) if err != nil { fmt.Println("tail file failed, err:", err) return } return } func ReadChan() <-chan *tail.Line { return tailObj.Lines } -
main.go:������
- �����ļ���
package main
import (
"fmt"
"gopkg.in/ini.v1"
"logagent/conf"
"logagent/kafka"
"logagent/taillog"
"strings"
"time"
)
var config = new(conf.Config)
// logAgent ��ڳ���
func main() {
// 0. ���������ļ�
//cfg, err := ini.Load("./conf/config.ini")
//address := cfg.Section("kafka").Key("address").String()
//topic := cfg.Section("kafka").Key("topic").String()
//path := cfg.Section("taillog").Key("path").String()
err := ini.MapTo(config, "./conf/config.ini")
if err != nil {
fmt.Printf("Fail to read file: %v", err)
return
}
fmt.Println(config)
// 1. ��ʼ��kafka����
err = kafka.Init(strings.Split(config.Kafka.Address, ";"))
if err != nil {
fmt.Println("init kafka failed, err:%v\n", err)
return
}
fmt.Println("init kafka success.")
// 2. ����־�ļ����ռ���־
err = taillog.Init(config.TailLog.FileName)
if err != nil {
fmt.Printf("Init taillog failed,err:%v\n", err)
return
}
fmt.Println("init taillog success.")
run()
}
func run() {
// 1. ��ȡ��־
for {
select {
case line := <-taillog.ReadChan():
// 2. ���͵�kafka
kafka.SendToKafka(config.Kafka.Topic, line.Text)
default:
time.Sleep(time.Second)
}
}
}
kafka�ն˴������߳���,����kafka��װĿ¼
bin\windows\kafka-console-consumer.bat --bootstrap-server=127.0.0.1:9092 --topic=web_log --from-beginning



4. etcd
etcd��ʹ��Go���Կ�����һ����Դ���߿��õķֲ�ʽkey-value�洢,�����������ù����ͷ���ע��ͷ���,���Ƶ���Ŀ��Zookeeper��consul,�ṩRestful`�Ľӿ�,ʹ�ü�,����raft�㷨��ǿһ����,�߿��õķ���洢Ŀ¼��
4.1 �ص�
- ��ȫ����:��Ⱥ�е�ÿ���ڵ㶼����ʹ�������Ĵ浵
- �߿�����:Etcd�����ڱ���Ӳ���ĵ�����ϻ���������
- һ����:ÿ�ζ�ȡ���᷵�ؿ������������д��
- ��:����һ���������á������û���API(gRPC)
- ����:ÿ��10000��д��Ļ��ٶ�
- �ɿ�:ʹ��Raft�㷨ʵ��ǿһ���ԡ��߿��÷���洢Ŀ¼
4.2 Ӧ�ó���
- ������

������Ҫ�����Ҳ�Ƿֲ�ʽϵͳ�����������֮һ,����ͬһ���ֲ�ʽ��Ⱥ�еĽ��̻����,Ҫ��β����ҵ��Է����������ӡ���������˵,�����־�����Ҫ�˽⼯Ⱥ���Ƿ��н����ڼ��� udp �� tcp �˿�,����ͨ�����־Ϳ��Բ��Һ����ӡ�
-
��������(����ʵ�ֵ���־�ռ��ͻ�����Ҫ�õ�)
��һЩ������Ϣ�ŵ�etcd�Ͻ��м��й�����
���ೡ����ʽͨ����������:Ӧ����������ʱ��������etcd��ȡһ��������Ϣ,ͬʱ��etcd�ڵ���ע��һ��Watcher���ȴ�,�Ժ�ÿ�������и��µ�ʱ��,etcd����ʵʱ֪ͨ������,�Դ˴ﵽ��ȡ����������Ϣ��Ŀ�ġ� -
�ֲ�ʽ��
��Ϊ etcd ʹ�� Raft �㷨���������ݵ�ǿһ����,ij�β����洢����Ⱥ�е�ֵ��Ȼ��ȫ��һ�µ�,���Ժ�����ʵ�ֲַ�ʽ����������������ʹ�÷�ʽ,һ�DZ��ֶ�ռ,���ǿ���ʱ��
- ���ֶ�ռ�����л�ȡ�����û�����ֻ��һ�����Եõ���etcd Ϊ���ṩ��һ��ʵ�ֲַ�ʽ��ԭ�Ӳ��� CAS(
CompareAndSwap)�� API��ͨ������prevExistֵ,���Ա�֤�ڶ���ڵ�ͬʱȥ����ij��Ŀ¼ʱ,ֻ��һ���ɹ����������ɹ����û��Ϳ�����Ϊ�ǻ�������� - ����ʱ��,��������Ҫ��������û����ᱻ����ִ��,�����������˳��Ҳ��ȫ��Ψһ��,ͬʱ������ִ��˳����etcd Ϊ��Ҳ�ṩ��һ�� API(�Զ����������),��һ��Ŀ¼��ֵʱָ��Ϊ
POST����,���� etcd ���Զ���Ŀ¼������һ����ǰ����ֵΪ��,�洢����µ�ֵ(�ͻ��˱��)��ͬʱ������ʹ�� API ��˳���г����е�ǰĿ¼�µļ�ֵ����ʱ��Щ����ֵ���ǿͻ��˵�ʱ��,����Щ���д洢��ֵ�����Ǵ����ͻ��˵ı�š�
- ���ֶ�ռ�����л�ȡ�����û�����ֻ��һ�����Եõ���etcd Ϊ���ṩ��һ��ʵ�ֲַ�ʽ��ԭ�Ӳ��� CAS(

4.3 etcd�ܹ�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-MTOv12Ja-1651574076509)(images/20_etcd�ܹ�.jpg)]](https://img-blog.csdnimg.cn/cf4c2efb14b94c91aad777fbc10cefb0.png)
��etcd�ļܹ�ͼ�����ǿ��Կ���,etcd��Ҫ��Ϊ�ĸ����֡�
- HTTP Server: ���ڴ����û����͵�API�����Լ�����etcd�ڵ��ͬ����������Ϣ����
- Store:���ڴ���etcd֧�ֵĸ���ܵ�����,���������������ڵ�״̬���������뷴�����¼�������ִ�еȵ�,��etcd���û��ṩ�Ĵ����API���ܵľ���ʵ�֡�
- Raft:Raftǿһ�����㷨�ľ���ʵ��,��etcd�ĺ��ġ�
- WAL:Write Ahead Log(Ԥдʽ��־),��etcd�����ݴ洢��ʽ���������ڴ��д����������ݵ�״̬�Լ��ڵ����������,etcd��ͨ��WAL���г־û��洢��WAL��,���е������ύǰ�������ȼ�¼��־��Snapshot��Ϊ�˷�ֹ���ݹ�������е�״̬����;Entry��ʾ�洢�ľ�����־���ݡ�
ͨ��,һ���û�����������,�ᾭ��HTTP Serverת����Store���о����������,����漰���ڵ����,��Raftģ�����״̬�ı������־�ļ�¼,Ȼ����ͬ�������etcd�ڵ���ȷ�������ύ,���������ݵ��ύ,�ٴ�ͬ����
��Ҫ����:
- Raft:etcd�����õı�֤�ֲ�ʽϵͳǿһ���Ե��㷨��
- Node:һ��Raft״̬��ʵ����
- Member: һ��etcdʵ������������һ��Node,���ҿ���Ϊ�ͻ��������ṩ����
- Cluster:�ɶ��Member���ɿ���Эͬ������etcd��Ⱥ��
- Peer:��ͬһ��etcd��Ⱥ������һ��Member�ijƺ���
- Client: ��etcd��Ⱥ����HTTP����Ŀͻ��ˡ�
- WAL:Ԥдʽ��־,etcd���ڳ־û��洢����־��ʽ��
- snapshot:etcd��ֹWAL�ļ���������õĿ���,�洢etcd����״̬��
- Proxy:etcd��һ��ģʽ,Ϊetcd��Ⱥ�ṩ�����������
- Leader:Raft�㷨��ͨ����ѡ�������Ĵ������������ύ�Ľڵ㡣
- Follower:��ѡʧ�ܵĽڵ���ΪRaft�еĴ����ڵ�,Ϊ�㷨�ṩǿһ���Ա�֤��
- Candidate:��Follower����һ��ʱ����ղ���Leader������ʱת��ΪCandidate��ʼ��ѡ��
- Term:ij���ڵ��ΪLeader����һ�ξ�ѡʱ��,��Ϊһ��Term��
- Index:�������š�Raft��ͨ��Term��Index����λ���ݡ�
4.3 Ϊʲô�� etcd ������ZooKeeper?
? etcd ʵ�ֵ���Щ����,ZooKeeper����ʵ�֡���ôΪʲôҪ�� etcd ����ֱ��ʹ��ZooKeeper��?
- Ϊʲô��ѡ��ZooKeeper?
- ����ά������,��ʹ�õ�
Paxosǿһ�����㷨�����Ѷ����ٷ�ֻ�ṩ��Java��C�������ԵĽӿڡ� - ʹ��
Java��д�����������������ά��Աά�������Ƚ��鷳�� - ������귢չ����,����
etcd��consul�Ⱥ���֮�㡣
- Ϊʲôѡ��etcd?
- ��ʹ�� Go ���Ա�д�����;֧��HTTP/JSON API,ʹ�ü�;ʹ�� Raft �㷨��֤ǿһ�������û��������⡣
- etcd Ĭ������һ���¾ͽ��г־û���
- etcd ֧�� SSL �ͻ��˰�ȫ��֤��
? ���,etcd ��Ϊһ���������Ŀ,���ڸ��ٵ����Ϳ�����,�����һ���ŵ�,Ҳ��һ��ȱ�㡣�ŵ�������δ���������Ŀ�����,ȱ�������õ�����Ŀ��ʱ��ʹ�õļ��顣Ȼ��,Ŀǰ CoreOS��Kubernetes��CloudFoundry��֪����Ŀ��������������ʹ����etcd,�����ܵ���˵,etcdֵ����ȥ���ԡ�
4.4 raft��
-
����Ҫ��
- Leaderѡ��(Leader Election)
- ��־ͬ�� (Log Replication)
- leader�յ�client�ĸ��������,�Ὣ���µ�����ͬ��������follower��
- ��Ⱥ״̬����ȷ�� (Safety)
- ��֤��־��һ����
- ��֤ѡ�ٵ���ȷ��
-
zookeeper��zad�������
-
�ο�:https://www.cnblogs.com/zhangyafei/p/13926838.html
-
etcd��watch
- etcd�ײ����ʵ��watch���ͻ���֪ͨ(websocket)
4.5 etcd�����غͰ�װ
-
����
https://github.com/coreos/etcd/releases
ѡ���Ӧ�汾�����ؼ���,����֮���ѹ

-
etcd����
˫��etcd.exe����
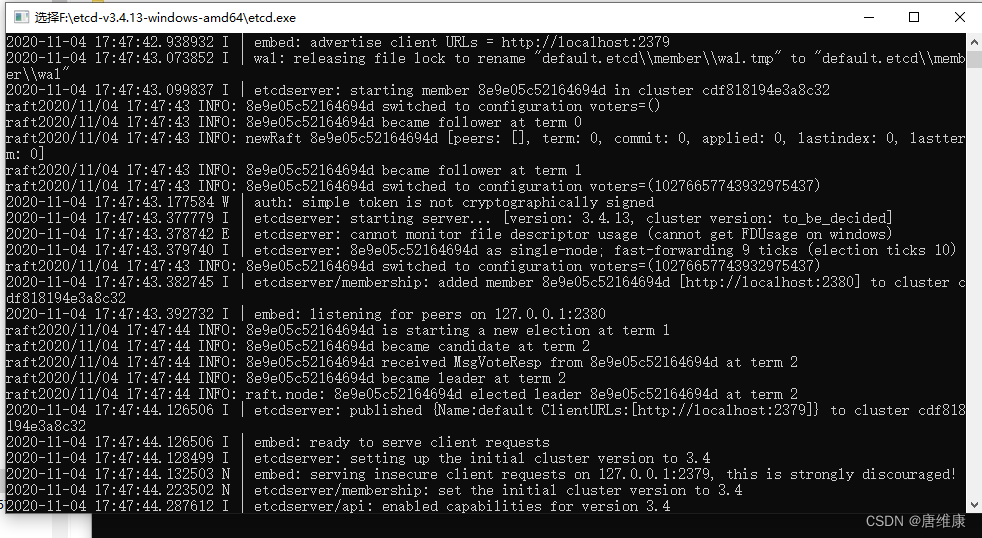
-
etcd�ͻ���
etcdctl.exe --endpoints=127.0.0.1:2379 put zhangyafei "hahaha"![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-OS5BwxKk-1651574076514)(images/22_�ն˲���etcd.png)]](https://img-blog.csdnimg.cn/9d7aefce7495490f89fe10b0677a28d7.png)
4.6 go����etcd
-
����
go get "go.etcd.io/etcd/clientv3"ע:����װ�����б�undefined: balancer.PickOptions���ƴ���,ԭʼΪgrpc�汾������,��Ҫ��go.mod
replace google.golang.org/grpc => google.golang.org/grpc v1.26.0 -
put��get
package main import ( "context" "fmt" "time" "go.etcd.io/etcd/clientv3" ) func main() { // etcd client put/get demo // use etcd/clientv3 cli, err := clientv3.New(clientv3.Config{ Endpoints: []string{"127.0.0.1:2379"}, DialTimeout: 5 * time.Second, }) if err != nil { // handle error! fmt.Printf("connect to etcd failed, err:%v\n", err) return } fmt.Println("connect to etcd success") defer cli.Close() // put ctx, cancel := context.WithTimeout(context.Background(), time.Second) _, err = cli.Put(ctx, "zhangyafei", "dsb") cancel() if err != nil { fmt.Printf("put to etcd failed, err:%v\n", err) return } // get ctx, cancel = context.WithTimeout(context.Background(), time.Second) resp, err := cli.Get(ctx, "zhangyafei") cancel() if err != nil { fmt.Printf("get from etcd failed, err:%v\n", err) return } for _, ev := range resp.Kvs { fmt.Printf("%s:%s\n", ev.Key, ev.Value) } }

-
watch
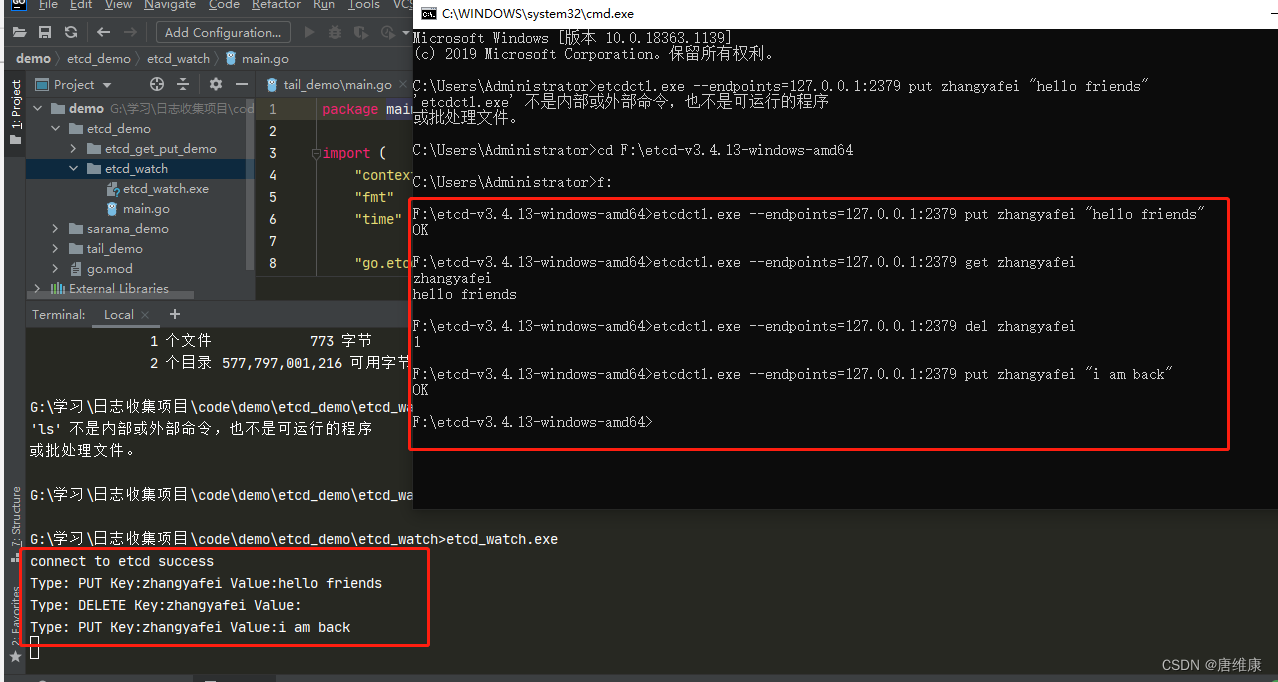
package main import ( "context" "fmt" "time" "go.etcd.io/etcd/clientv3" ) // watch demo func main() { cli, err := clientv3.New(clientv3.Config{ Endpoints: []string{"127.0.0.1:2379"}, DialTimeout: 5 * time.Second, }) if err != nil { fmt.Printf("connect to etcd failed, err:%v\n", err) return } fmt.Println("connect to etcd success") defer cli.Close() // watch key:q1mi change // ��һ���ڱ� һֱ������ zhangyafei���key�ı仯(���� ɾ�� ��)) rch := cli.Watch(context.Background(), "zhangyafei") // <-chan WatchResponse // ��ͨ������ȡֵ(���ӵ���Ϣ) for wresp := range rch { for _, ev := range wresp.Events { fmt.Printf("Type: %s Key:%s Value:%s\n", ev.Type, ev.Kv.Key, ev.Kv.Value) } } }������etcdĿ¼�ն�������������,���Բ鿴��������ɾ��key
etcdctl.exe --endpoints=http://127.0.0.1:2379 put zhangyafei "hello" etcdctl.exe --endpoints=http://127.0.0.1:2379 get zhangyafei etcdctl.exe --endpoints=http://127.0.0.1:2379 del zhangyafei
-
lease��Լ
package main import ( "fmt" "time" ) // etcd lease import ( "context" "log" "go.etcd.io/etcd/clientv3" ) func main() { cli, err := clientv3.New(clientv3.Config{ Endpoints: []string{"127.0.0.1:2379"}, DialTimeout: time.Second * 5, }) if err != nil { log.Fatal(err) } fmt.Println("connect to etcd success.") defer cli.Close() // ����һ��5�����Լ resp, err := cli.Grant(context.TODO(), 5) if err != nil { log.Fatal(err) } // 5����֮��, /nazha/ ���key�ͻᱻ�Ƴ� _, err = cli.Put(context.TODO(), "/nazha/", "dsb", clientv3.WithLease(resp.ID)) if err != nil { log.Fatal(err) } } -
keepAlive
package main import ( "context" "fmt" "log" "time" "go.etcd.io/etcd/clientv3" ) // etcd keepAlive func main() { cli, err := clientv3.New(clientv3.Config{ Endpoints: []string{"127.0.0.1:2379"}, DialTimeout: time.Second * 5, }) if err != nil { log.Fatal(err) } fmt.Println("connect to etcd success.") defer cli.Close() resp, err := cli.Grant(context.TODO(), 5) if err != nil { log.Fatal(err) } _, err = cli.Put(context.TODO(), "/nazha/", "dsb", clientv3.WithLease(resp.ID)) if err != nil { log.Fatal(err) } // the key 'foo' will be kept forever ch, kaerr := cli.KeepAlive(context.TODO(), resp.ID) if kaerr != nil { log.Fatal(kaerr) } for { ka := <-ch fmt.Println("ttl:", ka.TTL) } } -
����etcdʵ�ֲַ�ʽ��
����
import "go.etcd.io/etcd/clientv3/concurrency"go.etcd.io/etcd/clientv3/concurrency��etcd֮��ʵ�ֲ�������,��ֲ�ʽ�������Ϻ�ѡ�١�ʾ��
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints}) if err != nil { log.Fatal(err) } defer cli.Close() // �������������ĻỰ������ʾ������ s1, err := concurrency.NewSession(cli) if err != nil { log.Fatal(err) } defer s1.Close() m1 := concurrency.NewMutex(s1, "/my-lock/") s2, err := concurrency.NewSession(cli) if err != nil { log.Fatal(err) } defer s2.Close() m2 := concurrency.NewMutex(s2, "/my-lock/") // �Ựs1��ȡ�� if err := m1.Lock(context.TODO()); err != nil { log.Fatal(err) } fmt.Println("acquired lock for s1") m2Locked := make(chan struct{}) go func() { defer close(m2Locked) // �ȴ�ֱ���Ựs1�ͷ���/my-lock/���� if err := m2.Lock(context.TODO()); err != nil { log.Fatal(err) } }() if err := m1.Unlock(context.TODO()); err != nil { log.Fatal(err) } fmt.Println("released lock for s1") <-m2Locked fmt.Println("acquired lock for s2")���
acquired lock for s1 released lock for s1 acquired lock for s2 -
�ٷ��ĵ�:https://godoc.org/go.etcd.io/etcd/clientv3
4.7 etcd ��Ⱥ
etcd ��Ϊһ���߿��ü�ֵ�洢ϵͳ,��������Ϊ��Ⱥ������Ƶġ����� Raft �㷨��������ʱ��Ҫ�����ڵ��ͶƱ,���� etcd һ�㲿��Ⱥ�Ƽ��������ڵ�,�Ƽ�������Ϊ 3��5 ���� 7 ���ڵ㹹��һ����Ⱥ��
�һ��3�ڵ㼯Ⱥʾ��:
��ÿ��etcd�ڵ�ָ����Ⱥ��Ա,Ϊ�����ֲ�ͬ�ļ�Ⱥ���ͬʱ����һ����һ����token��
��������ǰ����õļ�Ⱥ��Ϣ,����n1��n2��n3��ʾ3����ͬ��etcd�ڵ㡣
TOKEN=token-01
CLUSTER_STATE=new
CLUSTER=n1=http://10.240.0.17:2380,n2=http://10.240.0.18:2380,n3=http://10.240.0.19:2380
��n1��̨������ִ����������������etcd:
etcd --data-dir=data.etcd --name n1 \
--initial-advertise-peer-urls http://10.240.0.17:2380 --listen-peer-urls http://10.240.0.17:2380 \
--advertise-client-urls http://10.240.0.17:2379 --listen-client-urls http://10.240.0.17:2379 \
--initial-cluster ${CLUSTER} \
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
��n2��̨������ִ��������������etcd:
etcd --data-dir=data.etcd --name n2 \
--initial-advertise-peer-urls http://10.240.0.18:2380 --listen-peer-urls http://10.240.0.18:2380 \
--advertise-client-urls http://10.240.0.18:2379 --listen-client-urls http://10.240.0.18:2379 \
--initial-cluster ${CLUSTER} \
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
��n3��̨������ִ��������������etcd:
etcd --data-dir=data.etcd --name n3 \
--initial-advertise-peer-urls http://10.240.0.19:2380 --listen-peer-urls http://10.240.0.19:2380 \
--advertise-client-urls http://10.240.0.19:2379 --listen-client-urls http://10.240.0.19:2379 \
--initial-cluster ${CLUSTER} \
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
etcd �����ṩ��һ�����Թ������ʵ� etcd �洢��ַ�������ͨ����������õ� etcd �����Ŀ¼,��������Ϊ-discovery����ʹ�á�
curl https://discovery.etcd.io/new?size=3
https://discovery.etcd.io/a81b5818e67a6ea83e9d4daea5ecbc92
# grab this token
TOKEN=token-01
CLUSTER_STATE=new
DISCOVERY=https://discovery.etcd.io/a81b5818e67a6ea83e9d4daea5ecbc92
etcd --data-dir=data.etcd --name n1 \
--initial-advertise-peer-urls http://10.240.0.17:2380 --listen-peer-urls http://10.240.0.17:2380 \
--advertise-client-urls http://10.240.0.17:2379 --listen-client-urls http://10.240.0.17:2379 \
--discovery ${DISCOVERY} \
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
etcd --data-dir=data.etcd --name n2 \
--initial-advertise-peer-urls http://10.240.0.18:2380 --listen-peer-urls http://10.240.0.18:2380 \
--advertise-client-urls http://10.240.0.18:2379 --listen-client-urls http://10.240.0.18:2379 \
--discovery ${DISCOVERY} \
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
etcd --data-dir=data.etcd --name n3 \
--initial-advertise-peer-urls http://10.240.0.19:2380 --listen-peer-urls http://10.240.0.19:2380 \
--advertise-client-urls http://10.240.0.19:2379 --listen-client-urls http:/10.240.0.19:2379 \
--discovery ${DISCOVERY} \
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
����etcd��Ⱥ�ʹ������,����ʹ��etcdctl������etcd��
export ETCDCTL_API=3
HOST_1=10.240.0.17
HOST_2=10.240.0.18
HOST_3=10.240.0.19
ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379
etcdctl --endpoints=$ENDPOINTS member lis
5. logagent��etcd�����ռ�������
-
����
value := `[{"path":"c:/nginx/nginx.log","topic":"web_log"},{"path":"d:/redis/redis.log","topic":"redis_log"},{"path":"e:/mysql/mysql.log","topic":"mysql_log"}]` -
��������Ϣ���͵�etcd

- etcd��ȡ����

-
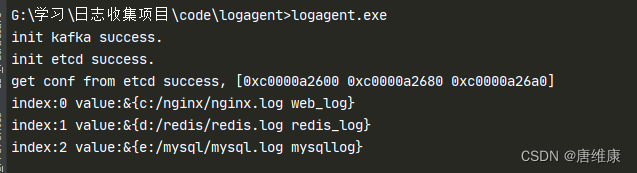
logagent��etcd�����ռ�������conf/config.ini[kafka] address=127.0.0.1:9092 [etcd] address=127.0.0.1:2379 timeout=5 collect_log_key=/logagent/collect_configconf/config.gopackage conf type Config struct { Kafka Kafka `ini:"kafka"` Etcd Etcd `ini:"etcd"` } type Kafka struct { Address string `ini:"address"` //Topic string `ini:"topic"` } type Etcd struct { Address string `ini:"address"` Key string `ini:"collect_log_key"` Timeout int `ini:"timeout"` }etcd/etcd.gopackage etcd import ( "context" "encoding/json" "fmt" "go.etcd.io/etcd/clientv3" "strings" "time" ) var ( cli *clientv3.Client ) type LogEntry struct { Path string `json:"path"` // ��־��ŵ�·�� Topic string `json:"topic"` // ��־����kafka�е��ĸ�Topic } // ��ʼ��etcd�ĺ��� func Init(addr string, timeout time.Duration) (err error) { cli, err = clientv3.New(clientv3.Config{ Endpoints: strings.Split(addr, ";"), DialTimeout: timeout, }) return } // ��etcd�л�ȡ��־�ռ����������Ϣ func GetConf(key string) (logEntryConf []*LogEntry, err error) { ctx, cancel := context.WithTimeout(context.Background(), time.Second) resp, err := cli.Get(ctx, key) cancel() if err != nil { fmt.Printf("get from etcd failed, err:%v\n", err) return } for _, ev := range resp.Kvs { //fmt.Printf("%s:%s\n", ev.Key, ev.Value) err = json.Unmarshal(ev.Value, &logEntryConf) if err != nil { fmt.Printf("unmarshal etcd value failed,err:%v\n", err) return } } return }main.gopackage main import ( "fmt" "gopkg.in/ini.v1" "logagent/conf" "logagent/etcd" "logagent/kafka" "strings" "time" ) var config = new(conf.Config) // logAgent ��ڳ��� func main() { // 0. ���������ļ� err := ini.MapTo(config, "./conf/config.ini") if err != nil { fmt.Printf("Fail to read file: %v", err) return } // 1. ��ʼ��kafka���� err = kafka.Init(strings.Split(config.Kafka.Address, ";")) if err != nil { fmt.Println("init kafka failed, err:%v\n", err) return } fmt.Println("init kafka success.") // 2. ��ʼ��etcd err = etcd.Init(config.Etcd.Address, time.Duration(config.Etcd.Timeout) * time.Second) if err != nil { fmt.Printf("init etcd failed,err:%v\n", err) return } fmt.Println("init etcd success.") // 2.1 ��etcd�л�ȡ��־�ռ����������Ϣ logEntryConf, err := etcd.GetConf(config.Etcd.Key) // 2,.2 ��һ���ڱ� if err != nil { fmt.Printf("etcd.GetConf failed, err:%v\n", err) return } fmt.Printf("get conf from etcd success, %v\n", logEntryConf) for index, value := range logEntryConf{ fmt.Printf("index:%v value:%v\n", index, value) } }
6. ����etcd��logagent�����Ż�
-
ʵ�ֹ���
logagent����etcd�����ô������tailtasklogagentʵ��watch������logagentʵ�������ռ�����logagentɾ����������û�е��Ǹ�����logagent����IP��ȡ�Լ�������
-
config/config.ini[kafka] address=127.0.0.1:9092 chan_max_size=100000 [etcd] address=127.0.0.1:2379 timeout=5 collect_log_key=/logagent/%s/collect_config -
config/config.gopackage conf type Config struct { Kafka Kafka `ini:"kafka"` Etcd Etcd `ini:"etcd"` } type Kafka struct { Address string `ini:"address"` ChanMaxSize int `ini:"chan_max_zise"` } type Etcd struct { Address string `ini:"address"` Key string `ini:"collect_log_key"` Timeout int `ini:"timeout"` } -
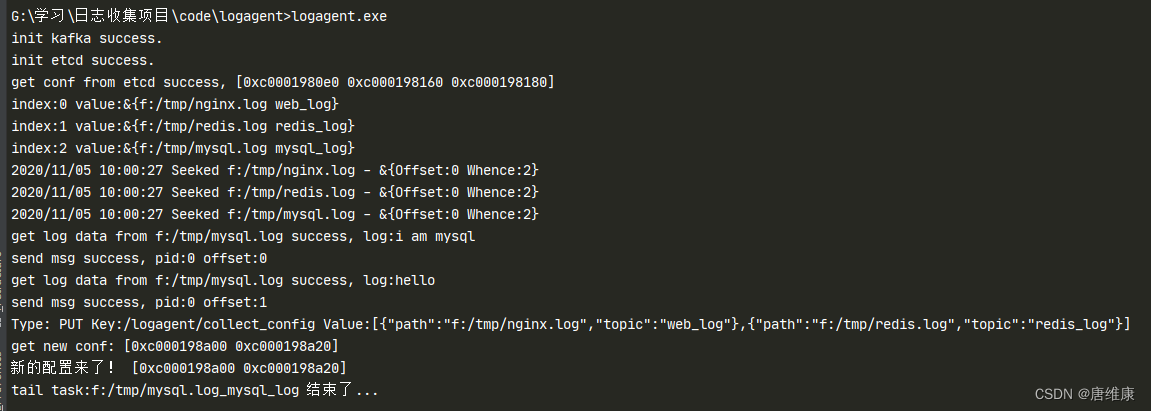
main.gopackage main import ( "fmt" "gopkg.in/ini.v1" "logagent/conf" "logagent/etcd" "logagent/kafka" "logagent/taillog" "logagent/tools" "strings" "sync" "time" ) var config = new(conf.Config) // logAgent ��ڳ��� func main() { // 0. ���������ļ� err := ini.MapTo(config, "./conf/config.ini") if err != nil { fmt.Printf("Fail to read file: %v", err) return } // 1. ��ʼ��kafka���� err = kafka.Init(strings.Split(config.Kafka.Address, ";"), config.Kafka.ChanMaxSize) if err != nil { fmt.Println("init kafka failed, err:%v\n", err) return } fmt.Println("init kafka success.") // 2. ��ʼ��etcd err = etcd.Init(config.Etcd.Address, time.Duration(config.Etcd.Timeout) * time.Second) if err != nil { fmt.Printf("init etcd failed,err:%v\n", err) return } fmt.Println("init etcd success.") // ʵ��ÿ��logagent����ȡ�Լ����е�����,����Ҫ���Լ���IP��ַʵ���ȼ��� ip, err := tools.GetOurboundIP() if err != nil { panic(err) } etcdConfKey := fmt.Sprintf(config.Etcd.Key, ip) // 2.1 ��etcd�л�ȡ��־�ռ����������Ϣ logEntryConf, err := etcd.GetConf(etcdConfKey) if err != nil { fmt.Printf("etcd.GetConf failed, err:%v\n", err) return } fmt.Printf("get conf from etcd success, %v\n", logEntryConf) // 2.2 ��һ���ڱ� һֱ������ zhangyafei���key�ı仯(���� ɾ�� ��)) for index, value := range logEntryConf{ fmt.Printf("index:%v value:%v\n", index, value) } // 3. �ռ���־����kafka taillog.Init(logEntryConf) var wg sync.WaitGroup wg.Add(1) go etcd.WatchConf(etcdConfKey, taillog.NewConfChan()) // �ڱ��������µ�������Ϣ��֪ͨ�����ͨ�� wg.Wait() } -
kafka/kafka.gopackage kafka import ( "fmt" "github.com/Shopify/sarama" ) // ר����kafkaд��־��ģ�� type LogData struct { topic string data string } var ( client sarama.SyncProducer // ����һ��ȫ�ֵ�����kafka��������client logDataChan chan *LogData ) // init��ʼ��client func Init(addrs []string, chanMaxSize int) (err error) { config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll // ������������Ҫleader��follow��ȷ�� config.Producer.Partitioner = sarama.NewRandomPartitioner // ��ѡ��?��partition config.Producer.Return.Successes = true // �ɹ���������Ϣ����success channel���� // ����kafka client, err = sarama.NewSyncProducer(addrs, config) if err != nil { fmt.Println("producer closed, err:", err) return } // ��ʼ��logDataChan logDataChan = make(chan *LogData, chanMaxSize) // ������̨��goroutine,��ͨ����ȡ���ݷ���kafka go SendToKafka() return } // ���ⲿ��¶��һ������,������ֻ����־���ݷ��͵�һ���ڲ���channel�� func SendToChan(topic, data string) { msg := &LogData{ topic: topic, data: data, } logDataChan <- msg } // ������kafka������־�ĺ��� func SendToKafka() { for { select { case log_data := <- logDataChan: // ����һ����Ϣ msg := &sarama.ProducerMessage{} msg.Topic = log_data.topic msg.Value = sarama.StringEncoder(log_data.data) // ���͵�kafka pid, offset, err := client.SendMessage(msg) if err != nil{ fmt.Println("sned msg failed, err:", err) } fmt.Printf("send msg success, pid:%v offset:%v\n", pid, offset) //fmt.Println("���ͳɹ�") } } } -
etcd/etcd.gopackage etcd import ( "context" "encoding/json" "fmt" "go.etcd.io/etcd/clientv3" "strings" "time" ) var ( cli *clientv3.Client ) type LogEntry struct { Path string `json:"path"` // ��־��ŵ�·�� Topic string `json:"topic"` // ��־����kafka�е��ĸ�Topic } // ��ʼ��etcd�ĺ��� func Init(addr string, timeout time.Duration) (err error) { cli, err = clientv3.New(clientv3.Config{ Endpoints: strings.Split(addr, ";"), DialTimeout: timeout, }) return } // ��etcd�л�ȡ��־�ռ����������Ϣ func GetConf(key string) (logEntryConf []*LogEntry, err error) { ctx, cancel := context.WithTimeout(context.Background(), time.Second) resp, err := cli.Get(ctx, key) cancel() if err != nil { fmt.Printf("get from etcd failed, err:%v\n", err) return } for _, ev := range resp.Kvs { //fmt.Printf("%s:%s\n", ev.Key, ev.Value) err = json.Unmarshal(ev.Value, &logEntryConf) if err != nil { fmt.Printf("unmarshal etcd value failed,err:%v\n", err) return } } return } // etcd watch func WatchConf(key string, newConfChan chan<- []*LogEntry) { rch := cli.Watch(context.Background(), key) // <-chan WatchResponse // ��ͨ������ȡֵ(���ӵ���Ϣ) for wresp := range rch { for _, ev := range wresp.Events { fmt.Printf("Type: %s Key:%s Value:%s\n", ev.Type, ev.Kv.Key, ev.Kv.Value) // ֪ͨtaillog.taskMgr var newConf []*LogEntry //1. ���жϲ��������� if ev.Type != clientv3.EventTypeDelete { // ���������ɾ������ err := json.Unmarshal(ev.Kv.Value, &newConf) if err != nil { fmt.Printf("unmarshal failed, err:%v\n", err) continue } } fmt.Printf("get new conf: %v\n", newConf) newConfChan <- newConf } } } -
taillog/taillog.gopackage taillog import ( "context" "fmt" "github.com/hpcloud/tail" "logagent/kafka" ) // ר���ռ���־��ģ�� type TailTask struct { path string topic string instance *tail.Tail // Ϊ����ʵ���˳�r,run() ctx context.Context cancelFunc context.CancelFunc } func NewTailTask(path, topic string) (t *TailTask) { ctx, cancel := context.WithCancel(context.Background()) t = &TailTask{ path: path, topic: topic, ctx: ctx, cancelFunc: cancel, } err := t.Init() if err != nil { fmt.Println("tail file failed, err:", err) } return } func (t TailTask) Init() (err error) { config := tail.Config{ ReOpen: true, // ���´� Follow: true, // �Ƿ���� Location: &tail.SeekInfo{Offset: 0, Whence: 2}, // ���ļ��ĸ��ط���ʼ�� MustExist: false, // �ļ������ڲ����� Poll: true} t.instance, err = tail.TailFile(t.path, config) // ��goroutineִ�еĺ����˳���ʱ��,goriutine���˳��� go t.run() // ֱ��ȥ�ɼ���־���͵�kafka return } func (t *TailTask) run() { for { select { case <- t.ctx.Done(): fmt.Printf("tail task:%s_%s ������...\n", t.path, t.topic) return case line :=<- t.instance.Lines: // ��TailTask��ͨ����һ��һ�еĶ�ȡ��־ // 3.2 ����kafka fmt.Printf("get log data from %s success, log:%v\n", t.path, line.Text) kafka.SendToChan(t.topic, line.Text) } } } -
taillog/taillog_mgrpackage taillog import ( "fmt" "logagent/etcd" "time" ) var taskMrg *TailLogMgr type TailLogMgr struct { logEntry []*etcd.LogEntry taskMap map[string]*TailTask newConfChan chan []*etcd.LogEntry } func Init(logEntryConf []*etcd.LogEntry) { taskMrg = &TailLogMgr{ logEntry: logEntryConf, taskMap: make(map[string]*TailTask, 16), newConfChan: make(chan []*etcd.LogEntry), // ��������ͨ�� } for _, logEntry := range logEntryConf{ // 3.1 ѭ��ÿһ����־�ռ���,����TailObj // logEntry.Path Ҫ�ռ���ȫ��־�ļ���·�� // ��ʼ����ʱ�����˶��ٸ�tailTask ��Ҫ������,Ϊ�˺����жϷ��� tailObj := NewTailTask(logEntry.Path, logEntry.Topic) mk := fmt.Sprintf("%s_%s", logEntry.Path, logEntry.Topic) taskMrg.taskMap[mk] = tailObj } go taskMrg.run() } // �����Լ���newConfChan,�����µ���Ϲ���֮�������Ӧ�Ĵ��� func (t *TailLogMgr) run() { for { select { case newConf := <- t.newConfChan: // 1. �������� for _, conf := range newConf { mk := fmt.Sprintf("%s_%s", conf.Path, conf.Topic) _, ok := t.taskMap[mk] if ok { // ԭ������,����Ҫ���� continue }else { // ������ tailObj := NewTailTask(conf.Path, conf.Topic) t.taskMap[mk] = tailObj } } // �ҳ�ԭ��t.logEntry��,����newConf��û�е�,ɾ�� for _, c1 := range t.logEntry{ // ѭ��ԭ�������� isDelete := true for _, c2 := range newConf{ // ȡ���µ����� if c2.Path == c1.Path && c2.Topic == c1.Topic { isDelete = false continue } } if isDelete { // ��c1��Ӧ�����tailObj��ͣ�� mk := fmt.Sprintf("%s_%s", c1.Path, c1.Topic) // t.taskNap[mk] ==> tailObj t.taskMap[mk].cancelFunc() } } // 2. ����ɾ�� // 3. ���ñ�� fmt.Println("�µ���������!", newConf) default: time.Sleep(time.Second) } } } // һ������,���Ⱪ¶taskMgr��newConfChan func NewConfChan() chan <-[]*etcd.LogEntry { return taskMrg.newConfChan } -
tools/get_ippackage tools import ( "net" "strings" ) // ��ȡ���ض���IP func GetOurboundIP() (ip string, err error) { conn, err := net.Dial("udp", "8.8.8.8:80") if err != nil { return } defer conn.Close() localAddr := conn.LocalAddr().(*net.UDPAddr) //fmt.Println(localAddr.String()) ip = strings.Split(localAddr.IP.String(), ":")[0] return }
7. ����kafka��������
-
���ռ������÷���etcd
package main import ( "context" "fmt" "net" "strings" "time" "go.etcd.io/etcd/clientv3" ) // ��ȡ���ض���IP func GetOurboundIP() (ip string, err error) { conn, err := net.Dial("udp", "8.8.8.8:80") if err != nil { return } defer conn.Close() localAddr := conn.LocalAddr().(*net.UDPAddr) fmt.Println(localAddr.String()) ip = strings.Split(localAddr.IP.String(), ":")[0] return } func main() { // etcd client put/get demo // use etcd/clientv3 cli, err := clientv3.New(clientv3.Config{ Endpoints: []string{"127.0.0.1:2379"}, DialTimeout: 5 * time.Second, }) if err != nil { // handle error! fmt.Printf("connect to etcd failed, err:%v\n", err) return } fmt.Println("connect to etcd success") defer cli.Close() // put ctx, cancel := context.WithTimeout(context.Background(), time.Second) value := `[{"path":"f:/tmp/nginx.log","topic":"web_log"},{"path":"f:/tmp/redis.log","topic":"redis_log"},{"path":"f:/tmp/mysql.log","topic":"mysql_log"}]` //value := `[{"path":"f:/tmp/nginx.log","topic":"web_log"},{"path":"f:/tmp/redis.log","topic":"redis_log"}]` //_, err = cli.Put(ctx, "zhangyafei", "dsb") //��ʼ��key ip, err := GetOurboundIP() if err != nil { panic(err) } log_conf_key := fmt.Sprintf("/logagent/%s/collect_config", ip) _, err = cli.Put(ctx, log_conf_key, value) //_, err = cli.Put(ctx, "/logagent/collect_config", value) cancel() if err != nil { fmt.Printf("put to etcd failed, err:%v\n", err) return } // get ctx, cancel = context.WithTimeout(context.Background(), time.Second) resp, err := cli.Get(ctx, log_conf_key) //resp, err := cli.Get(ctx, "/logagent/collect_config") cancel() if err != nil { fmt.Printf("get from etcd failed, err:%v\n", err) return } for _, ev := range resp.Kvs { fmt.Printf("%s:%s\n", ev.Key, ev.Value) } } -
�����ߴ���
package main import ( "fmt" "github.com/Shopify/sarama" ) // kafka consumer func main() { consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil) if err != nil { fmt.Printf("fail to start consumer, err:%v\n", err) return } partitionList, err := consumer.Partitions("web_log") // ����topicȡ�����еķ��� if err != nil { fmt.Printf("fail to get list of partition:err%v\n", err) return } fmt.Println("����: ", partitionList) for partition := range partitionList { // �������еķ��� // ���ÿ����������һ����Ӧ�ķ��������� pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err) return } defer pc.AsyncClose() // �첽��ÿ������������Ϣ go func(sarama.PartitionConsumer) { for msg := range pc.Messages() { fmt.Printf("Partition:%d Offset:%d Key:%s Value:%s\n", msg.Partition, msg.Offset, msg.Key, msg.Value) } }(pc) } select {} } -
�����
- ����zookeeper
- ����kafka
- ����etcd
- �����ռ������õ�etcd
- ����logagent��etcd�����ռ�������,ʹ��taillog������־�ļ�����,����������־���ݷ���kafka
- ����kafka��������
- ������־����,�۲�logagent������kafka����״̬
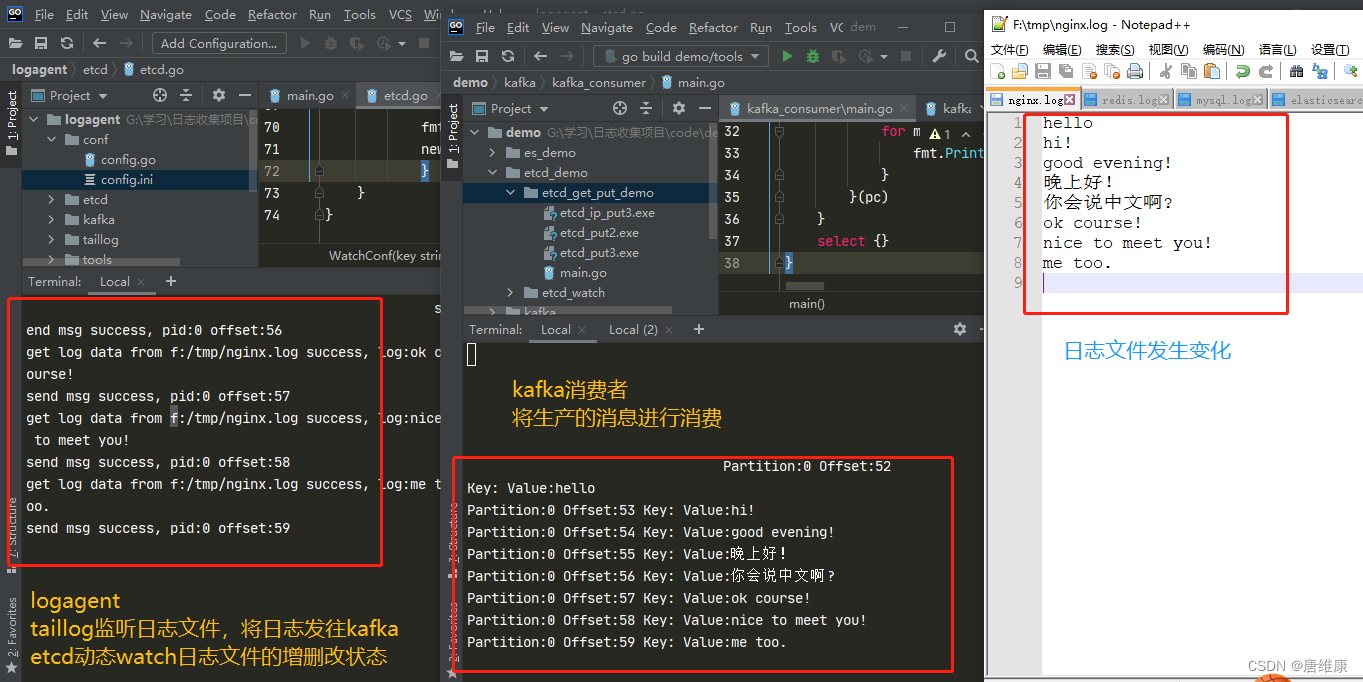
�塢LogTransfer
��kafka�������־ȡ����,д��ES,ʹ��Kibana�����ӻ�չʾ
1. ElasticSearch
1.1 ����
Elasticsearch(ES)��һ������Lucene�����Ŀ�Դ���ֲ�ʽ��RESTful�ӿڵ�ȫ���������档Elasticsearch����һ���ֲ�ʽ�ĵ����ݿ�,����ÿ���ֶξ��ɱ�����,����ÿ���ֶε����ݾ��ɱ�����,ES�ܹ�������չ�����ټƵķ������洢�Լ�����PB�������ݡ������ڼ��̵�ʱ���ڴ洢�������ͷ������������ݡ�ͨ����Ϊ���и���������������µĺ��ķ�������
1.2 Elasticsearch����ʲô
- ���㾭Ӫһ�������̵�,���������Ŀͻ�������������Ʒ�������������,�����ʹ��ElasticSearch���洢���������ƷĿ¼�Ϳ����Ϣ,Ϊ�ͻ��ṩ������,����Ϊ�ͻ��Ƽ������Ʒ��
- �������ռ���־���߽������ݵ�ʱ��,��Ҫ�������ھ���Щ����,Ѱ������,����ͳ��,�ܽ�,�����쳣�������������,�����ʹ��Logstash�������������������ռ�����,�����������ݴ洢��ElasticsSearch�С�����������ͻ�����Щ����,�ҵ��κ������Ȥ����Ϣ��
- ���ڳ���Ա��˵,�Ƚ������İ�����GitHub,GitHub�������ǻ���ElasticSearch������,��github.com/searchҳ��,�����������Ŀ���û���issue��pull request,���д��롣����40~50��������,�ֱ�����������վ��Ҫ���ٵĸ������ݡ���Ȼֻ������Ŀ������֧(master),�������������Ȼ��,����20�ڸ������ĵ�,30TB�������ļ���
1.3 Elasticsearch��������
- Near Realtime(NRT) ����ʵʱ
Elasticsearch��һ������ʵʱ������ƽ̨����˼��,������һ���ĵ�������ĵ��ɱ�����ֻ��Ҫһ�����ӳ�,���ʱ��һ��Ϊ���뼶��
- Cluster ��Ⱥ
Ⱥ����һ�������ڵ�(������)�ļ���, ��Щ�ڵ㹲ͬ������������,�������нڵ����ṩ�����������������ܡ�һ����Ⱥ��һ��Ψһ��ȺIDȷ��,��ָ��һ����Ⱥ��(Ĭ��Ϊ��elasticsearch��)���ü�Ⱥ���dz���Ҫ,��Ϊ�ڵ����ͨ�������Ⱥ������Ⱥ��,һ���ڵ�ֻ����Ⱥ����һ���֡�
ȷ���ڲ�ͬ�Ļ����в�Ҫʹ����ͬ��Ⱥ������,������ܻᵼ�����Ӵ����Ⱥ���ڵ㡣����,�����ʹ��logging-dev��logging-stage��logging-prod�ֱ�Ϊ�������β�Ʒ��������Ⱥ����¼��
- Node�ڵ�
�ڵ��ǵ���������ʵ��,����Ⱥ����һ����,���Դ洢����,������Ⱥ�����������������ܡ�����һ����Ⱥ,�ڵ������Ĭ��Ϊһ�������ͨ��Ψһ��ʶ��(UUID),ȷ��������ʱ������ýڵ㡣�����ϣ��Ĭ��,���Զ����κνڵ�����������ֶԹ�������Ҫ,Ŀ����Ҫȷ����������������Ӧ�����ElasticSearchȺ���ڵ㡣
���ǿ���ͨ��Ⱥ�������ýڵ��������ض���Ⱥ����Ĭ�������,ÿ���ڵ����ü�����Ϊ��elasticSearch���ļ�Ⱥ������ζ���������������ڵ���������,���������ܷ��ֱ˴˶����Զ��γɺͼ���һ����Ϊ��elasticsearch���ļ�Ⱥ��
�ڵ���Ⱥ����,�����ӵ�о����ܶ�Ľڵ㡣����,�����elasticsearch����ͬһ��������,û�������ڵ���������,�ӵ����ڵ��Ĭ������»��γ�һ���µĵ��ڵ���Ϊ��elasticsearch���ļ�Ⱥ��
- Index����
�����Ǿ����������Ե��ĵ����ϡ�����,����Ϊ�ͻ������ṩ����,Ϊ��ƷĿ¼������һ������,�Լ�Ϊ�������ݽ�����һ������������������(����ȫ��ΪСд)��ʶ,�����������ڶ����е��ĵ�ִ�����������������º�ɾ������ʱ�����������ڵ���Ⱥ����,����Զ��御���ܶ��������
- Type����
��������,���Զ���һ���������͡������������������/����,��������ȫȡ�����㡣һ����˵,���Ͷ���Ϊ���й����ֶμ����ĵ�������,����������һ������ƽ̨,�����������ݴ洢��һ�������С������������,�����Ϊ�û����ݶ���һ������,Ϊ�������ݶ�����һ������,�Լ�Ϊע�����ݶ�����һ���͡�
- Document�ĵ�
�ĵ��ǿ��Ա���������Ϣ�Ļ�����λ������,�����Ϊ�����ͻ��ṩһ���ĵ�,������Ʒ�ṩ��һ���ĵ�,�Լ����������ṩ��һ���ĵ������ļ��ı�ʾ��ʽΪJSON(JavaScript Object Notation)��ʽ,����һ�ַdz��ձ�Ļ��������ݽ�����ʽ��
������/������,����Դ洢�����ܶ���ĵ�����ע��,�����ĵ�����פ����������,�ĵ�ʵ���ϱ�����������䵽�����е����͡�
- Shards & Replicas��Ƭ�븱��
�������Դ洢����������,��Щ���ݿ��ܳ��������ڵ��Ӳ�����ơ�����,ʮ�ڸ��ļ�ռ�ô��̿ռ�1TB�ĵ�ָ����ܲ��ʺ϶Ե����ڵ�Ĵ��̻����̫��������ӵ����ڵ����������
Ϊ�˽����һ����,Elasticsearch�ṩϸ�����ָ��ֳɶ�����Ϊ��Ƭ�����������㴴��һ������,����Լض�������Ҫ�ķ�Ƭ������ÿ����Ƭ������һ��ȫ���ܵġ������ġ�ָ����,�����й��ڼ�Ⱥ�е��κνڵ㡣
Shards��Ƭ����Ҫ����Ҫ������������������:**
- ��Ƭ������ˮƽ��ֻ��������ݵĴ�С
- ��Ƭ���������Ͳ��в�������Ƭ(�����ڶ���ڵ���)�Ӷ��������/������ ��������е���Ƭ�Ƿֲ�ʽ���Լ����ļ����ܵ�������������ȫ��ElasticSearch����,���û���˵�����ġ�
��ͬһ����Ⱥ������ƻ�����,�������κ�ʱ����ֵ�,ӵ��һ������ת�ƻ����Է���Ƭ�ͽڵ���ΪijЩԭ��������ʧ�Ƿdz����õ�,���ұ�ǿ���Ƽ���Ϊ��,Elasticsearch�����㴴��һ����������,���������Ƭ������ν�ĸ������������Ʒ�ķ�Ƭ,���Replicas��
- Replicas����Ҫ����Ҫ������������������:
- ����Ϊ��Ƭ��ڵ�ʧ���ṩ�˸߿����ԡ�Ϊ��,��Ҫע�����,һ�������ķ�Ƭ���������ͬһ���ڵ���Ϊԭʼ�Ļ�����Ƭ,�����Ǵ�����Ƭ���︴�ƹ����ġ�
- ���������û���չ�����������������,��Ϊ�������������и����ϲ���ִ�С�
1.4 ES�����������ϵ�����ݿ�ıȽ�
| ES���� | ��ϵ�����ݿ� |
|---|---|
| Index(����)֧��ȫ�ļ��� | Database(���ݿ�) |
| Type(����) | Table(��) |
| Document(�ĵ�),��ͬ�ĵ������в�ͬ���ֶμ��� | Row(������) |
| Field(�ֶ�) | Column(������) |
| Mapping(ӳ��) | Schema(ģʽ) |
1.5 ES���ؼ���װ
- ����
? ���� Elasticsearch �������ذ�װ��,�������֮��,��ѹ��ָ��Ŀ¼��
? �������ٶ���,��ʹ�ù��ھ���,��Ϊ��:https://mirrors.huaweicloud.com/elasticsearch
-
��װ
�ն˽���ES�Ľ�ѹĿ¼,��������
\bin\elasticsearch.bat
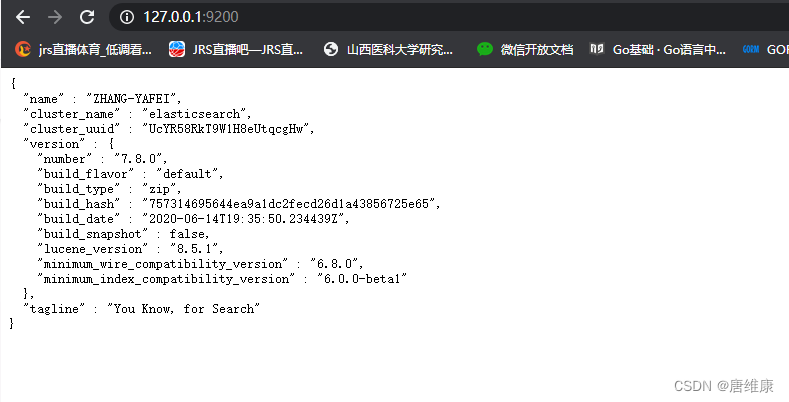
����127.0.0.1::9200,���ɹ�����������Ϣ,��˵����װ�ɹ���
1.6 Go����ES
-
����
go get github.com/olivere/elastic/v7 ע��汾��esһ�� -
ʾ��
package main import ( "context" "fmt" "github.com/olivere/elastic/v7" ) // Elasticsearch demo type Student struct { Name string `json:"name"` Age int `json:"age"` Married bool `json:"married"` } func main() { // 1, ��ʼ������,�õ�һ��client���� client, err := elastic.NewClient(elastic.SetURL("http://127.0.0.1:9200")) if err != nil { // Handle error panic(err) } fmt.Println("connect to es success") p1 := Student{Name: "ball", Age: 22, Married: false} put1, err := client.Index().Index("student").Type("go").BodyJson(p1).Do(context.Background()) if err != nil { // Handle error panic(err) } fmt.Printf("Indexed user %s to index %s, type %s\n", put1.Id, put1.Index, put1.Type) }
-
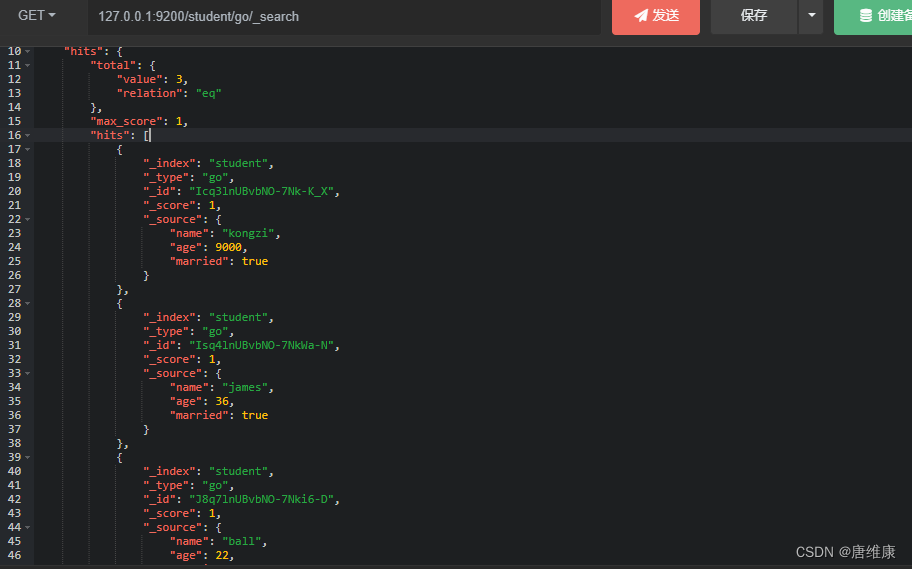
��ѯ���
get 127.0.0.1:9200/student/go/_search ֮ǰ�������������� post 127.0.0.1:9200/student/go { "name": "james", "age": 36, "married": true } { "name": "kongzi", "age": 9000, "married": true }
- �ο��ĵ�:https://shimo.im/docs/kXHT89xV3vYxVVvw/
- ����ʹ����ο�:https://godoc.org/github.com/olivere/elastic
2. Kibana
2.1 ���
Kibana��һ����Դ�����Ϳ��ӻ�ƽ̨,ּ����ElasticsearchЭͬ��������ʹ��Kibana����,�鿴����洢��Elasticsearch�����е����ݽ��н��������������ɵ�ִ�и����ݷ���,���ڸ���ͼ��,����͵�ͼ�п��ӻ��������ݡ�
Kibanaʹ��������������������ݡ���Ļ���������Ľ���ʹ���ܹ����ٴ���������̬�DZ���,ʵʱ��ʾElasticsearch��ѯ�ĸ��ġ�
����Kibana�dz����ס�������װKibana���ڼ������ڿ�ʼ̽������Elasticsearch���� - �������,�������Ļ����ܹ���
2.2 ����
-
�汾Ҫ��
Ӧ��Kibana��Elasticsearch����Ϊ��ͬ�汾��,���ǹٷ��Ƽ������á�
��֧��Kibana��Elasticsearch�����ڲ�ͬ��Ҫ�汾(����Kibana 5.x��Elasticsearch 2.x),Ҳ��֧�ֱ�Elasticsearch�汾���µ�Kibana��Ҫ�汾(����Kibana 5.1��Elasticsearch 5.0)��
���и���Kibana�Ĵ�Ҫ�汾��Elasticsearchͨ���������ڴٽ���������Elasticsearch����������(����Kibana 5.0��Elasticsearch 5.1)���ڴ�������,����Kibana����������ʱ��¼����,�����Kibana��������Elasticsearch��ͬ�İ汾֮ǰ,��ֻ����ʱ�ġ�
ͨ��֧��Kibana��Elasticsearch�����ڲ�ͬ�����汾(����Kibana 5.0.0��Elasticsearch 5.0.1),�����ǹ����û���Kibana��Elasticsearch��������ͬ�İ汾�Ͳ����汾��
-
����
����:https://www.elastic.co/cn/downloads/kibana
���ڼ���:https://mirrors.huaweicloud.com/kibana
����ָ���汾��kibanaѹ��������
2.3 ����
-
�������ļ�
��
config/kibana.yml�ļ�,���Ա༭��������ַ�Ͷ˿�,�Լ�����ģʽ
# Kibana is served by a back end server. This setting specifies the port to use.
#server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
#server.host: "localhost"
...
#i18n.locale: "en"
i18n.locale: "zh-CN"
-
����,����֮ǰ��������elasticsearch
bin\kibana.bat![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-v4dfDDlc-1651574076543)(images/36_kibana����.png)]](https://img-blog.csdnimg.cn/607dabd0d4f640f2b522fde1e122bcf1.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-TxZec4PQ-1651574076544)(images/37_kibana��������.png)]](https://img-blog.csdnimg.cn/b70d46061f7d491193362abc8797c0fd.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-PsXLhgfh-1651574076547)(images/38_�����ֶ�����.png)]](https://img-blog.csdnimg.cn/d464cafe77e142c9b40c505462f608e3.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-3xB4egXr-1651574076548)(images/39_kibana����.png)]](https://img-blog.csdnimg.cn/bbe664cd690f4d5f9f5006398f347025.png)
3. LogTransferʵ��
3.1 ���������ļ�
-
conf/config.ini[kafka] address=127.0.0.1:9092 topic=web_log [es] address=127.0.0.1:9200 chan_max_size=100000 workers=16 -
conf/config.gopackage conf type LogTansfer struct { Kafka Kafka `ini:"kafka"` ES ES `ini:"es"` } type Kafka struct { Address string `ini:"address"` Topic string `ini:"topic"` } type ES struct { Address string `ini:"address"` ChanMaxSize int `ini:"chan_max_size"` Workers int `ini:"workers"` } -
���������ļ�
// 0. ���������ļ� var cfg conf.LogTansfer err := ini.MapTo(&cfg, "./conf/config.ini") if err != nil { fmt.Println("init config, err:%v\n", err) return } fmt.Printf("cfg:%v\n", cfg)ע���:
- ��һ���������ı���һ��Ҫ��ָ��
- �������ļ���Ӧ�Ķ�ӹ�����һ��Ҫ����tag(�ر���Ƕ�Ľṹ��)
3.2 ��ʼ��ES
-
ʵ��˼·:��ʼ��ES,�����մ�kafka��ȡ��������
- ��ʼ��ES�ͻ�������
- ��ʼ����־channel
- �������ɸ�Э�̼���channel�����ݵı仯,��channel�е����ݷ���ES
-
����ʵ��
es/es.gopackage es import ( "context" "fmt" "github.com/olivere/elastic/v7" "strings" "time" ) var ( esClient *elastic.Client logESChan chan LogData ) type LogData struct { Topic string `json:"topic"` Data string `json:"data"` } // ��ʼ��ES,������KAFKA�DZ߷����������� func Init(address string, chan_max_size int, workers int) (err error) { if !strings.HasPrefix(address, "http://") { address = "http://" + address } esClient, err = elastic.NewClient(elastic.SetURL(address)) if err != nil { return } fmt.Println("connect to es success") logESChan = make(chan LogData, chan_max_size) for i := 0; i < workers; i++ { go SendToES() } return } func SendToChan(data LogData) { logChan <- data } // �������ݵ�ES func SendToES() { for { select { case msg := <-logESChan: // ��ʽ���� put1, err := esClient.Index().Index(msg.Topic).BodyJson(msg).Do(context.Background()) if err != nil { // Handle error fmt.Printf("send to es failed, err: %v\n", err) continue } fmt.Printf("Indexed user %s to index %s, type %s\n", put1.Id, put1.Index, put1.Type) default: time.Sleep(time.Second) } } }main.gofunc main() { // 0. ���������ļ� ... // 1. ��ʼ��ES // 1.1 ��ʼ��һ��ES���ӵ�client err = es.Init(cfg.ES.Address, cfg.ES.ChanMaxSize, cfg.ES.Workers) if err != nil { fmt.Printf("init ES client failed,err:%v\n", err) return } fmt.Println("init ES client success.") ... }
3.3 ��ʼ��Kafka
-
ʵ��˼·:��ʼ��
kafka- ����kafka����������
- ��ʼ��kafka�ͻ���,����kafka���������ӡ�addrs��topic
-
����ʵ��
kafka/kafka.gopackage kafka import ( "fmt" "github.com/Shopify/sarama" "logtransfer/es" "sync" ) // ��ʼ��kafka���ӵ�һ��client type KafkaClient struct { client sarama.Consumer addrs []string topic string } var ( kafkaClient *KafkaClient ) // init��ʼ��client func Init(addrs []string, topic string) (err error) { consumer, err := sarama.NewConsumer(addrs, nil) if err != nil { fmt.Printf("fail to start consumer, err:%v\n", err) return } kafkaClient = &KafkaClient{ client: consumer, addrs: addrs, topic: topic, } return } // ��Kafka���ݷ���ES func Run(){ ... } -
main.gofunc main() { // 0. ���������ļ� ... // 1. ��ʼ��ES // 1.1 ��ʼ��һ��ES���ӵ�client ... // 2. ��ʼ��kafka // 2.1 ����kafka,���������������� // 2.2 ÿ�������������߷ֱ�ȡ������ ͨ��SendToChan()�����ݷ����ܵ� // 2.3 ��ʼ��ʱ�Ϳ���Э��ȥchannel��ȡ���ݷ���ES err = kafka.Init(strings.Split(cfg.Kafka.Address, ";"), cfg.Kafka.Topic) if err != nil { fmt.Printf("init kafka consumer failed,err:%v\n", err) return } fmt.Println("init kafka success.") ... }
3.4 ��Kafka�е����ݷ���ES
-
ʵ��˼·
- kafka�ͻ�����ÿ�������������߷ֱ�ȡ������
- �첽ͨ��SendToChan()�����ݷ���channel
- ��ʼ��ʱ�Ϳ���Э��ȥchannel��ȡ���ݷ���ES
-
����ʵ��
kafka/kafka.gofunc Run() { partitionList, err := kafkaClient.client.Partitions(kafkaClient.topic) // topicȡ�����еķ��� if err != nil { fmt.Printf("fail to get list of partition:err%v\n", err) return } fmt.Println("����: ", partitionList) for partition := range partitionList { // �������еķ��� // ���ÿ����������һ����Ӧ�ķ��������� pc, err := kafkaClient.client.ConsumePartition(kafkaClient.topic, int32(partition), sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err) return } defer pc.AsyncClose() // �첽��ÿ������������Ϣ go func(sarama.PartitionConsumer) { for msg := range pc.Messages() { fmt.Printf("Partition:%d Offset:%d Key:%s Value:%s\n", msg.Partition, msg.Offset, msg.Key, msg.Value) log_data := es.LogData{ Topic: kafkaClient.topic, Data: string(msg.Value), } es.SendToChan(log_data) // ���������� һ��������ִ��ʱ�����һ���������,Ӧ��ͨ��channel���������Ż� } }(pc) } defer kafkaClient.client.Close() select {} }main.gofunc main() { // 0. ���������ļ� var cfg conf.LogTansfer err := ini.MapTo(&cfg, "./conf/config.ini") if err != nil { fmt.Println("init config, err:%v\n", err) return } fmt.Printf("cfg:%v\n", cfg) // 1. ��ʼ��ES // 1.1 ��ʼ��һ��ES���ӵ�client err = es.Init(cfg.ES.Address, cfg.ES.ChanMaxSize, cfg.ES.Workers) if err != nil { fmt.Printf("init ES client failed,err:%v\n", err) return } fmt.Println("init ES client success.") // 2. ��ʼ��kafka // 2.1 ����kafka,���������������� // 2.2 ÿ�������������߷ֱ�ȡ������ ͨ��SendToChan()�����ݷ����ܵ� // 2.3 ��ʼ��ʱ�Ϳ���Э��ȥchannel��ȡ���ݷ���ES err = kafka.Init(strings.Split(cfg.Kafka.Address, ";"), cfg.Kafka.Topic) if err != nil { fmt.Printf("init kafka consumer failed,err:%v\n", err) return } fmt.Println("init kafka success.") // 3. ��kafkaȡ��־���ݲ�����channel�� kafka.Run() }
3.5 ��Ŀ����
-
�����
- ����
zookeeper - ����
kafka - ����
etcd - ����
elasticsearch - ����
kibana - ����
logagent - ����
logtransfer - ����������־�ļ�д������,�۲�
logagent(������־���ݷ���kafka)��logtransfer(��kafka�е����ݷ���ES)����̨�е������Ϣ,��kibana��Web������ַ,�鿴ES�����Ƿ�ʵʱ����
- ����
-
������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-rWZGQBWN-1651574076549)(images/image-20220503182030474.png)]](https://img-blog.csdnimg.cn/79ac5d9611284916929b4d0eb5dd6a75.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-jHH3rWpH-1651574076550)(README.assets/image-20220503182134033.png)]](https://img-blog.csdnimg.cn/4cebcc8c38a744cfa635d8dcf70f1508.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-b1796gyv-1651574076552)(images/41_kabana����web_log����.png)]](https://img-blog.csdnimg.cn/bfe5b0903b7545a5950889b2f7131eb6.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-7aENBoxn-1651574076553)(images/43_ͨ��kibana�鿴kafka����ES������.png)][����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-1f4aoiNR-1651574076554)(images/42_kibana����.png)]](https://img-blog.csdnimg.cn/051ae02e877a4168a39d0eb5f96e9620.png)
����ϵͳ���
-
gopsutil��ϵͳ�����Ϣ�IJɼ�,д��influxDB,ʹ��grafanna��չʾ
-
prometheus���:�ɼ�����ָ������,��������,ʹ��grafana��չʾ
-
https://prometheus.io/

- https://grafana.com/
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-aNOaPCnm-1651574076556)(images/44_grafana.png)]](https://img-blog.csdnimg.cn/e0dd61a57cd740a4ade1798df8e8bcdb.png)
�ߡ���Ŀ�ܽ�
- ��Ŀ�ܹ�
- Ϊʲô����ELK
- logAgent������α�֤��־����/����֮������ռ���־(��¼��ȡ�ļ���offset)
- kafka
- etcd��watchԭ��
- es���

