文章目录
逻辑日志与物理日志

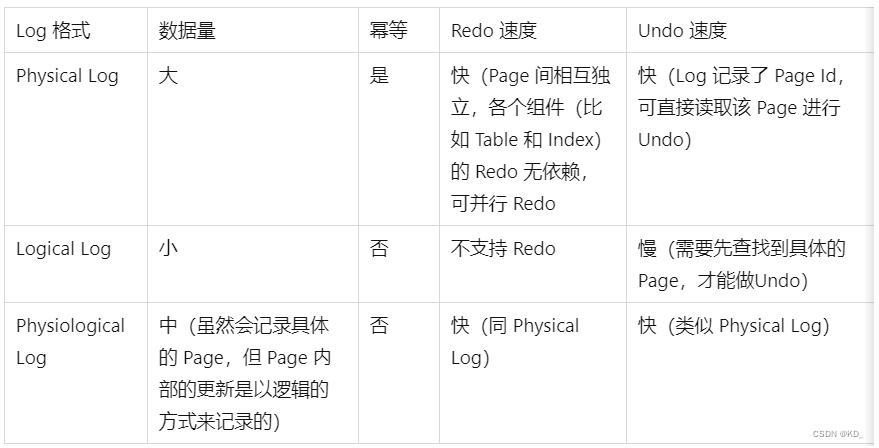
redo log为什么使用物理日志?
Logical log 只能作用于 Operation Consistency 的数据上。如果磁盘上的数据只反映了一些操作的部分更新,它就不是 Operation Consistency 的。例如 Insert 一个 Tuple 导致一个 Index Page 发生了 Split,这个 Index Page 上的一半数据会被挪到另一个新的 Index Page 上。Logical Log 只会记录我们 Insert 了一个 Tuple,不会记录这两个 Page 上的细节变化。如果数据库挂掉时这两个 Index Page 只有一个刷盘了,我们仍然按照 Logical Log 来 Redo,最终的数据是什么样的,就不知道了。
那Physical log怎么处理上述问题呢?mini-transaction!mtr + redolog可以保证Operation Consistency。
undo log为什么使用逻辑日志?
Logical Undo是可以正常使用的,因为redo log +mini-transaction保证了数据库的数据始终是Operation Consistency的。
Undo 应该采用 Logical 的方式(Logical Undo) 而不是 Page-Oriented 的方式(Page-Oriented Undo)。原因有两点:
- Logical Undo 能够大大提高事务的并发度,因为
-
采用 Physical Undo 或者 Physiological Undo,不同事务不能并发更新同一个 Index Page。设想这样一个场景,事务 T1 向 Index Page 插入了一条 Index Entry,接着事务 T2 插入了另外一些 Index Entry,正好触发了 Page Split。事务 T1 插入的那条 Index Entry 被挪到了另外一个 Page 上,然后事务 T1 执行出错要进行回滚。
Physical Undo 会死板地用更新前的镜像做覆盖式地 Undo,显然是无效的。Physiological Undo 也没法工作,尽管它可以处理 Index Entry 在 Page 内任意挪动的场景,但是对于 Index Entry 挪到了其他 Page 上的这种场景,Physiological Undo 在 Page 内做逻辑地 Undo 也回天乏术。因此,要正确使用这两种方式来做 Undo,必须配合 Index Page 的 Lock 而不是 Latch(违反了 Early Lock Release 技术,并发度低),保证事务执行期间更新的 Index Page 不会被别的事务并发更新。与之相反,Logical Undo 只需要对 Index Page 加 Latch。因为 Logical Undo 不关心数据具体存在哪个 Page,它在 Undo 的时候会先查找数据所在的 Index Page,然后再在做逻辑地 Undo。 -
采用 Physical Undo,不同事务不能并发更新同一个 Table 的统计信息(例如 Free Space 的大小,Tuple 的数量)。
设想这样一个场景,某个 Table 当前 Tuple 数量为 10,事务 T1 插入 2 个 Tuple 后将 Tuple 数量增加到 12,事务 T2 插入 1 个 Tuple 后将 Tuple 数量增加到 13,然后事务 T1 执行出错要进行回滚。
Physical Undo 会将 Tuple 数量覆盖式地更新为 10,如果事务 T2 最终提交,那么数据就不一致了。
Logical Undo 在 Undo 的时候可以对 Tuple 数量执行逻辑减 2 操作,更新为 11,即便事务 T2 提交,数据也是一致的。
Physiological Undo 在这里和 Logical Undo 作用的一样的,因为统计信息一般都是在一个固定的 Table Page 中。
-
- Undo 并不频繁,Logical Undo 因查找 Page 导致的速度慢是可以接受的。
Mini Transaction
Mini transaction(简称mtr)是InnoDB对物理数据文件操作的最小事务单元,用于管理对Page加锁、修改、释放、以及日志提交到公共buffer等工作。一个mtr操作必须是原子的,一个事务可以包含多个mtr。每个mtr完成后需要将本地产生的日志拷贝到公共缓冲区,将修改的脏页放到flush list上。
mini-transaction遵循以下三个协议:
- The FIX Rules:修改一个页需要获得该页的x-latch,访问一个页是需要获得该页的s-latch或者x-latch,持有该页的latch直到修改或者访问该页的操作完成
- Write-Ahead Log:持久化一个数据页之前,必须先将内存中相应的日志页持久化,每个页有一个LSN,每次页修改需要维护这个LSN,当一个页需要写入到持久化设备时,要求内存中小于该页LSN的日志先写入到持久化设备中
- Force-log-at-commit:一个事务可以同时修改了多个页,Write-AheadLog单个数据页的一致性,无法保证事务的持久性,Force -log-at-commit要求当一个事务提交时,其产生所有的mini-transaction日志必须刷到持久设备中,这样即使在页数据刷盘的时候宕机,也可以通过日志进行redo恢复
Mysql中所有的事务在innodb存储引擎内部都是通过mini transaction完成的,将一个事务划分成多个mini transaction的依据是 : 每条语句都作为一个mini transaction来执行(不确定)。
虽然,innodb将事务划分成了多个mini transaction,但是mini transaction和mysql中的事务并不一样。根据事务应该具有的ACID特性,事务是用来保证整个数据库中数据的ACID而存在的;但是mini transaction是mysql内部的对底层page的一个原子操作,保证并发事务操作下以及数据库异常时page中数据的一致性,主要用于innodb redo log 和 undo log写入,保证两种日志的ACID特性。事务对于数据一致性和持久性的保证在Innodb存储引擎内部是通过mini transaction来实现的。
所有对页的操作都要在mini_transaction中执行。在一个mini-transaction操作中,需要对对应的page加锁。锁中代码逻辑主要就是操作页,然后生成redo和undolog,完成之后释放锁。 mini transaction虽然是用来保证单个page中数据的一致性,但是mini transaction可能需要修改多个page,那么该mini transaction必须持有多个page的latch,并在操作完成之后,按照获取latch相反的顺序释放latch。
Innodb的重做日志是物理逻辑日志,分为MLOG_SINGLE_REC和MLOG_MULTI_REC两种类型。通过在每条日志头部的type字段设置MLOG_SINGLE_REC_FLAG来标志该mini transaction操作是否只涉及一个page的修改。如果一个mini transaction需要同时维护多个page中数据的一致性,那么其在mini-transaction结束时会额外写入1个字节大小的MLOG_MULTI_REC_END信息,表示该mini-transaction产生了修改多个page的日志。当一个mini-transaction涉及到多个page的修改时,只有读到最后一个0x1F的日志,才应用前面所有的操作,否则丢弃前面所有的操作。
总而言之,mtr就是对多个page进行加锁操作,并在mtr局部缓冲区上生成对应的redo log和undo log。当mtr提交时,才将redo log和undo log拷贝到公共缓冲区(真正的redo、undo log缓冲区),以及对page解锁。其有三个作用:
- 保证了单个page的一致性,加锁访问,多线程并发安全
- 保证了多个page的一致性,mtr保证了对底层页面的一组操作的原子性,要么全部成功,要么全部失败,不存在中间状态。多个page的log同时生效或者同时无效。
- 保证了redo log生成的顺序性正确性,redo log的顺序必须和内存操作执行的顺序一致,加锁保证了同一个page先执行的操作的redo log肯定先写入公共缓冲区。
ARIES Recovery
术语
● LSN:全称是 Log Sequence Number。它是 Log 的编号,始终单调递增。
● Log Header:每一条 Log Record 都是由 Log Header 和具体的 Log 数据组成。Log Header 中一般有 Log Size,LSN,Transaction ID,Prev LSN(见下面介绍),LogType(见下面介绍) 等字段。
● Prev LSN:同一个事务中后一条 Log 会把前一条 Log 的 LSN 记录在 Log Header 的 Prev LSN 字段中,形成一个反向链表,便于 Undo 时逆序回溯事务的 Log。
● Log Type:一般有事务相关的 Type:Begin,Commit,Abort,End(End 有点特殊,下文会详细介绍);普通 Log(包含 Redo Log,Undo Log 和 CLR(见下面介绍))的 Type:Insert,Update,MarkDelete,ApplyDelete,RollbackDelete 等;Checkpoint Log 的 Type:Checkpoint;为一个文件分配新 Page 的 Type:NewPage。
● CLR:全称是 Compensation Log Record,中文一般翻译为补偿日志。由于 ARIES 采用 Logical Undo,Undo 操作不是幂等的,不可以重复执行。我们通过为 Undo 操作记录 Redo Log 来物化 Undo 操作,同时记录 Undo 的进展(通过 UndoNextLSN 的实现,见下面介绍),保证已经 Undo 了的操作不会再被 Undo。Undo 产生的这些 Redo Log 就叫做 CLR。此外,CLR 是 Redo-Only 的,不支持 Undo,这一特点保证了 Undo 是有界的,Recovery 期间 Undo 过程中挂掉并不会增加 Undo 的工作量。这就是为什么 ARIES 要「Logging changes during undo」。
● UndoNext LSN:每条 CLR 中都会记录 UndoNext LSN,用来指示下一条需要 Undo 的 Log 的 LSN。如果 Undo 到一半数据库挂掉后重启,我们在重新执行 Undo 时,只需先取出最后一条 CLR Log 的 UndoNext LSN,就能继续之前的 Undo 工作。
● Log Buffer:内存中分配的用来临时存放 Log 的一段空间。事务执行期间写 Log 只写到 Log Buffer 中,直到事务提交的时候统一刷盘。这种做法有利于减少磁盘 IO,提升性能。(很方便我们实现 Group Commit 特性,本文不展开。)
● Master Record:磁盘上的一个文件,记录最近一次 Checkpoint Log 的 LSN。它能够帮助我们在 Recovery 期间快速找到最近一次 Checkpoint 的 Log。
● Flushed LSN:已经刷到磁盘上的 Log 中最大的 LSN。它是一个内存中的变量。
● Page LSN:对于一个 Page,最近一次更新操作对应的 Log 的 LSN。记录在 Page Header 中。
● Rec LSN:对于一个 Page,自从上一次刷盘以来,第一次更新操作对应的 Log 的 LSN。
● Last LSN:每个事务最近一次更新操作对应的 Log 的 LSN。
● DPT:全称是 Dirty Page Table。记录了所有的 Dirty Page 以及它们的 Rec LSN。它是一个内存中的数据结构。
● ATT:全称是 Active Transaction Table。记录了所有活跃事务(事务在执行中,还没有提交或回滚)以及它们的状态(Undo Candidate,Committed,下文会介绍)和 Last LSN。它也是内存中的一个数据结构。
ARIES主要思想
● WAL with STEAL/NO-FORCE
○ 我们要 Runtime 性能!
● Repeating history during redo
○ Recovery 期间做 Redo 的时候重放历史,无论是已提交,未提交还是已回滚的事务,都要 Redo 一遍。
● Logging changes during undo
○ 在事务回滚做 Undo 的时候,要为 Undo 产生的更新操作记录 Redo Log。
Consistent Checkpoint 的Recovery
Consistent Checkpoint 在执行checkpoint时:
- 禁止新事务启动,等待正在执行的事务结束(其实就是停服)。
- 遍历 Buffer Pool,将所有 Dirty Page 刷盘。
- 记录一条 Checkpoint Log。
- 允许所有事务正常执行(恢复服务)
所以checkpoint时,ATT和DPT都为空,即没有活跃事务和脏页。
Recovery 直接从 Checkpoint Log 开始,之前的 Log 一律跳过。因为 Consistent Checkpoint 先停服然后把所有 Dirty Page 刷盘,保证了 Checkpoint Log 之前的所有 Log 对应的 Page 的改动已经被刷到了磁盘上,并且这些 Page 不包含未提交的数据,不需要再考虑 Redo 或者 Undo,它们的 Log 自然也就不再关心了。
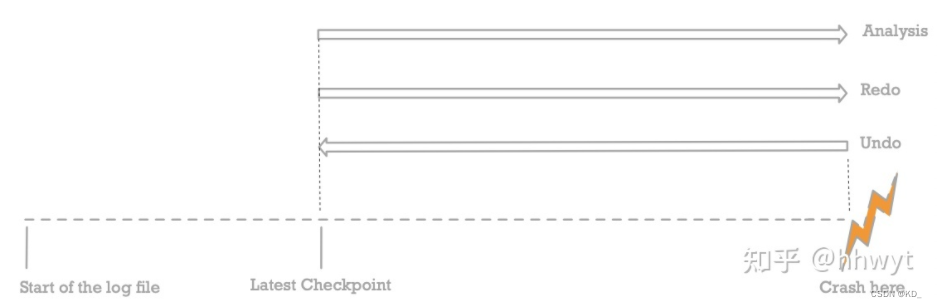

当上述三个阶段执行完毕,Recovery 流程结束,数据库即可正常对外提供服务。
Fuzzy Checkpoint的Recovery
Fuzzy Checkpoint 是一个在线 Checkpoint 方案。Checkpoint 时可能会有并发的活跃事务(ATT 不为空),并且并发事务可能更新了一些 Page(DPT 不为空)。如果此时做 Checkpoint,记录一条 Checkpoint Log,实际上 Redo 的起始位置应该在 Checkpoint Log 之前(DPT 中最小的 Rec LSN),要 Undo 的一些事务的部分 Log 也在 Checkpoint Log 之前(ATT 中所有事务最小的 LSN)。换句话说,我们不能像 Consistent Checkpoint 那样,Recovery 直接从 Checkpoint Log 的位置开始了。如何保证 Recovery 的时候把 Checkpoint Log 之前的 Log 对应的更新操作该 Redo 的 Redo,该 Undo 的 Undo ?
ARIES 说,我们做 Checkpoint 的时候把 Checkpoint 时刻的 ATT 和 DPT 一同记录下来不就行了。Checkpoint Log 中记录的 ATT 和 DPT 将作为 Recovery 启动时 ATT 和 DPT 的初始状态,依据初始状态我们可以知道 Checkpoint Log 之前有哪些 Log 需要处理。然后我们从 Checkpoint Log 位置开始执行 Analysis 阶段,重做 ATT 和 DPT 后续的增量改动,恢复出完整的 ATT 和 DPT,接下来不就和 Consistent Checkpoint 一样了么。
如何记录 ATT 和 DPT 呢?方案有一点 Trick。我们可以先对 Log Buffer(新事务和更新操作的 Log 会被延后)加 Latch,接着对 ATT 和 DPT 加 Latch,然后拷贝 ATT 和 DPT 并记录 Checkpoint Log。Checkpoint Log 中记录的是 Checkpint 时刻 ATT 和 DPT 的快照。这种做法的缺点是 Latch 的持有时间有点长,对系统负载影响比较大。实际上我们并不需要拿到 ATT 和 DPT 快照。我们可以把 ATT 和 DPT 分成很多个 Partition,每次只加单个 Partition 的 Latch, 然后拷贝这个 Partition,最终经过多次拷贝我们就能够得到一份完整的 ATT 和 DPT。这种做法 Latch 的持有时间很短,对系统的负载影响很小。拷贝出来的 ATT 和 DPT 相当于某一时刻的快照加该时刻后续的部分增量改动。Analysis 阶段拿着这份 ATT 和 DPT 从这个「某一时刻」开始,重做后续的全部增量改动,Checkpoint 期间拷贝过程中漏掉的增量改动会被重做,已经包含的增量改动也会被重做但不影响正确性,因为增量改动的重做是幂等的。
ARIES 通过记录一条 Checkpoint Begin Log 来明确这个「某一时刻」的位置。
详细步骤如下:
- 先记录一条 Checkpoint Begin Log。
- 通过多次对 ATT 和 DPT 加单个 Partition 的 Latch,拷贝出一份完整的 ATT 和 DPT。
- 记录一条 Checkpoint End Log。Log 内容包括 ATT 和 DPT 的信息。然后把 Log 刷盘。
- 把 Checkpoint Begin Log (也可以加上 Checkpoint End Log)的 LSN 信息记录到 Master Record 中。
Recovery 的时候,先从 Master Record 中找到 Checkpoint Begin Log 的位置,然后找到 Checkpoint End Log 的位置,恢复出 ATT 和 DPT 的初始状态,接着从 Checkpoint Begin Log 位置开始执行 Analysis 阶段即可。
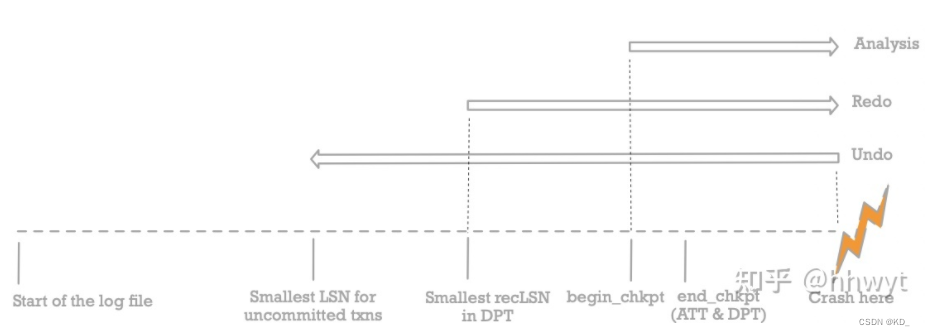
个人理解:
Recovery 依靠的就是两个数据结构,即ATT和DPT。
ATT记录活跃的事务,即数据库宕机时已经写入磁盘的redo log中还未提交的事务,那么这些事务是需要回滚的,未提交的事务的页可能持久化到磁盘中,即undo。
DPT记录的是内存脏页,即数据库宕机时已经写入磁盘的redo log在内存中修改的页面,这些脏页有可能没有写入磁盘,需要进行redo。
DPT中包含已经提交的事务、未提交的事务、正在回滚的事务的脏页,其都是需要redo的:
- 已经提交的事务的页面redo是为了持久性。
- 未提交的事务的页面redo是为了执行Logical Undo时的正确性。(Logical log 只能作用于 Operation Consistency 的数据上)
- 正在回滚的事务的脏页redo是因为Logical Undo不具备幂等性,所以从之前undo的中断点继续(所以undo时还要记录CLR redo log)。
所以只需要恢复内存中的ATT和DPT,即可进行redo和undo。
- Consistent Checkpoint是停服的,checkpoint时ATT和DPT为空,只需要对checkpoint log后面的log进行analysis即可。
- Fuzzy Checkpoint是与事务并发的,所以checkpoint时ATT和DPT不为空,所以使用checkpoint begin log记录ATT和DPT的快照生成时刻,checkpoint end log记录ATT和DPT的快照。Recover时分析checkpoint begin log之后的所有log再加上ATT和DPT的快照,即可得到数据库宕机时内存中的ATT和DPT。
参考:
逻辑日志与物理日志
MySQL ・ 引擎特性 ・ InnoDB redo log漫游
MySQL ・ 引擎特性 ・ InnoDB mini transation

