目录
这篇文章的写作契机是疑惑大数据和数据仓库的关系,于是参考多篇文章,总结记录大数据领域数据管理工具相关的概念,旨在从多个角度区分概念加深理解,是系统化学习大数据和数据仓库理论的宏观基础。
1. 定义
1.1 大数据
虽然大数据这个概念是最近才提出的,但大型数据集的起源却可追溯至 1960 - 70 年代。当时数据世界正处于萌芽阶段,全球第一批数据中心和首个关系数据库便是在那个时代出现的。2005 年左右,人们开始意识到用户在使用 Facebook、YouTube 以及其他在线服务时生成了海量数据。同一年,专为存储和分析大型数据集而开发的开源框架 Hadoop 问世,NoSQL 也在同一时期开始慢慢普及开来。
Hadoop 及后来 Spark 等开源框架的问世对于大数据的发展具有重要意义,正是它们降低了数据存储成本,让大数据更易于使用。在随后的几年中,大数据的数量呈现出爆炸式增长。用户目前仍在持续生成海量数据,但并非只有人类在产生数据。随着物联网 (IoT) 的兴起,如今越来越多的设备接入了互联网,它们大量收集客户的使用模式和产品性能数据,而机器学习的出现也进一步加速了数据量的增长。
大数据的定义:大量(Volume)、高速(Velocity)涌现的多样(Variety)、有价值(Value)、真实(Veracity)的数据。这一定义还表明大数据具有 5V 特性。
1.2 数据仓库
数据仓库(Data warehouse,DW/DWH)是上世纪 90 年代就已经出现的概念,其出现的背景是企业的信息化及伴随着各种信息系统的出现如 CRM、ERP等,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的。
Bill Inmon的定义接受度最广:数据仓库是面向主题的、集成的、反应时间变化的、相对稳定的数据集合,用于支持管理决策。它包括了ETL、调度、建模在内的完整的理论体系。数据仓库的方案建设的目的,是为前端查询和分析做基础,其主要功能是将组织透过资讯系统之联机事务处理(OLTP)经年累月所累积的大量资料,透过数据仓库理论所特有的资料储存架构,作一有系统的分析整理,以利各种分析方法如联机分析处理(OLAP)、数据挖掘(Data Mining)之进行,并进而支持如决策支持系统(DSS)、主管资讯系统(EIS)之创建,帮助决策者能快速有效的自大量资料中,分析出有价值的资讯,以利决策拟定及快速回应外在环境变动,帮助建构商业智能(BI)。目前使用Hive构建数据仓库的比较多。
- 所谓主题:是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的
- 所谓集成:是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息
- 所谓随时间变化:是指数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测
1.3 数据库
数据库是按照数据结构来组织、存储和管理数据的仓库。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
一般而言,我们所说的数据库指的是数据库管理系统,并不单指一个数据库实例。
根据数据存储的方式不同,可以将数据库分为三类:分别为行存储、列存储、行列混合存储,其中行存储的数据库代表产品有Oracle、MySQL、PostgresSQL等;列存储的数据代表产品有Greenplum、HBASE、Teradata等;行列混合存储的数据库代表产品有TiDB,ADB for Mysql等。
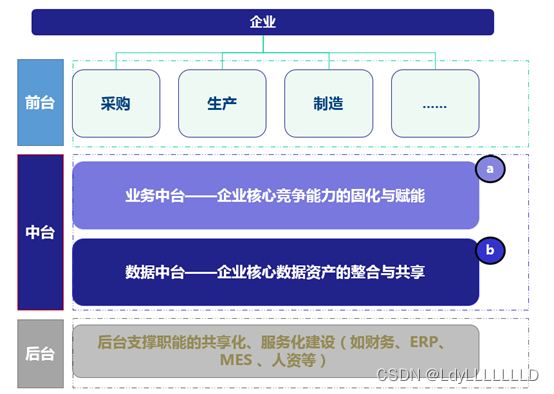
1.4 数据中台
阿里巴巴于2017年云栖大会正式对外提出数据中台概念,数据中台的出现,就是为了弥补数据开发和应用开发之间,由于开发速度不匹配,出现的响应力跟不上的问题。中台不是一个产品,而与业务强相关。广义上来给数据中台一个企业级的定义:“聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念”。
数据中台是指通过企业内外部多源异构的数据采集、治理、建模、分析,应用,使数据对内优化管理提高业务,对外可以数据合作价值释放,成为企业数据资产管理中枢。数据中台建立后,会形成数据API,为企业和客户提供高效各种数据服务。
数据中台整体技术架构上采用云计算架构模式,将数据资源、计算资源、存储资源充分云化,并通过多租户技术进行资源打包整合,并进行开放,为用户提供“一站式”数据服务。
利用大数据技术,对海量数据进行统一采集、计算、存储,并使用统一的数据规范进行管理,将企业内部所有数据统一处理形成标准化数据,挖掘出对企业最有价值的数据,构建企业数据资产库,提供一致的、高可用大 数据服务。
数据中台不是一套软件,也不是一个信息系统,而是一系列数据组件的集合,企业基于自身的信息化建设基础、数据基础以及业务特点对数据中台的能力进行定义,基于能力定义利用数据组件搭建自己的数据中台。
1.5 数据湖
维基百科对数据湖的定义
数据湖(Data Lake)是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖是以其自然格式存储的数据的系统或存储库,通常是对象blob或文件。数据湖通常是企业所有数据的单一存储,包括源系统数据的原始副本,以及用于报告、可视化、分析和机器学习等任务的转换数据。数据湖可以包括来自关系数据库(行和列)的结构化数据,半结构化数据(CSV,日志,XML,JSON),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像,音频,视频)。
目前,Hadoop是最常用的部署数据湖的技术,所以很多人会觉得数据湖就是Hadoop集群。数据湖是一个概念,而Hadoop是用于实现这个概念的技术。
2. 区别与联系
2.1 大数据与数据仓库
大数据是一种技术手段;数据仓库是一个存放数据的集合。大数据会涉及到各种工具,离线计算:Hadoop、Hive…,实时计算:flink,storm,spark,kafka…
1、用途和价值不同
数据仓库相对用途比较单一,主要用于支持管理决策,多服务于各种 BI 报表、仪表盘、自助分析等应用。
大数据用途非常广泛,除了决策支持外,还常见于互联网搜索、市场营销、实时计算、物联网、机器学习等各种新型应用中。
2、处理的数据量与类型不同
数据仓库是小数据时代的产物,且主要用于结构化数据的分析,一般处理的数据量从 GB 至 TB 不等。数据来源包括企业的各种信息化系统,如ERP、CRM、SCM、MES…
大数据是互联网时代的产物,用于海量的各种类型的数据存储、处理与分析,包含结构化、半结构化、非结构化的数据,其处理的数据量一般起始以 TB 为单位,PB 也非常常见。其数据来源非常广泛,包括企业的信息系统、在线网站、物联网设备、网络爬虫、甚至第三方购买数据。
3、技术与产品成熟度不同
数据仓库发展了这么多年,技术与产品相对较为成熟,且有完整的建设方法论。技术上大多以大规模并行处理(MPP)、内存计算、列式存储为核心,产品上以 Teradata, Oracle, Vertica, Greenplum, SAP BW 等为代表。
大数据技术经过10多年的发展,尽管以 Hadoop 为代表的大数据生态圈已经非常繁荣,在技术上拥有出色的可扩展性,包含了丰富的各式数据处理引擎或框架,但相比数据仓库,其技术与产品的成熟度还相对欠缺,企业的大数据平台往往需要大量优秀的大数据人才进行开发和运维。
数据仓库与大数据的区别
大数据技术的发展把数据仓库带入了一个新的发展阶段,新一代的企业数据仓库越来越多的基于大数据技术构建,在向海量、实时、弹性、应用场景丰富等方向发展。在此过程中,涌现了一批优秀的国产大数据开源技术,比如 Apache Kylin, Apache Doris,RocketMQ 等。
一文读懂大数据环境下的数据仓库建设
2.2 数据仓库与数据库
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing) 一般针对某些主题的历史数据进行分析,支持管理决策。
数据库的大规模应用,使得信息行业的数据爆炸式的增长,为了研究数据之间的关系,挖掘数据隐藏的价值,人们越来越多的需要使用OLAP来为决策者进行分析,探究一些深层次的关系和信息。但很显然,不同的数据库之间根本做不到数据共享,就算同一家数据库公司,数据库之间的集成也存在非常大的挑战(最主要的问题是庞大的数据如何有效合并、存储)。数据仓库就是为了解决数据库不能解决的问题而提出的,旨在进一步挖掘数据资源、为了决策需要而产生的,它绝不是所谓的“大型数据库”。
数据仓库的出现,并不是要取代数据库。
- 数据库是面向事务的设计,数据仓库是面向主题设计的
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用 户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余, 依照分析需求,分析维度、分析指标进行设计
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计
| 特性 | 数据仓库 | 事务数据库 |
|---|---|---|
| 适合的工作负载 | 分析、报告、大数据 | 事务处理 |
| 数据源 | 从多个来源收集和标准化的数据 | 从单个来源(例如事务系统)捕获的数据 |
| 数据捕获 | 批量写入操作通过按照预定的批处理计划执行 | 针对连续写入操作进行了优化,因为新数据能够最大程度地提高事务吞吐量 |
| 数据标准化 | 非标准化schema,例如星型Schema或雪花型schema | 高度标准化的静态schema |
| 数据存储 | 使用列式存储进行了优化,可实现轻松访问和高速查询性能 | 针对在单行型物理块中执行高吞吐量写入操作进行了优化 |
| 数据访问 | 为最小化I/O并最大化数据吞吐量进行了优化 | 大量小型读取操作 |
参考链接:数据仓库与数据库的来龙去脉
参考链接:数据仓库与数据库的区别
参考链接:数据仓库与数据库的区别
2.3 数据仓库与数据集市
什么是数据集市?
数据集市(Data Mart),也叫数据市场,就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
从范围上来说,数据集市的数据是从数据库,或者是更加专业的数据仓库中抽取出来的。数据集市分为从属的数据集市与独立的数据集市:
独立型数据集市的数据来自于操作型数据库,是为了满足特殊用户而建立的一种分析型环境。这种数据集市的开发周期一般较短,具有灵活性,但是因为脱离了数据仓库,独立建立的数据集市可能会导致信息孤岛的存在,不能以全局的视角去分析数据。
从属型数据集市的数据来自于企业的数据仓库,这样会导致开发周期的延长,但是从属型数据集市在体系结构上比独立型数据集市更稳定,可以提高数据分析的质量,保证数据的一致性。
| 特性 | 数据仓库 | 数据集市 |
|---|---|---|
| 数据来源 | OLTP系统、外部数据 | 数据仓库 |
| 范围 | 企业级 | 部门级或工作组级 |
| 主题 | 企业主题 | 部门或特殊的分析主题 |
| 数据粒度 | 最细的粒度 | 较粗的粒度 |
| 历史数据 | 大量的历史数据 | 适度的历史数据 |
| 目的 | 适度的历史数据 | 便于某个维度数据访问和分析,快速查询 |
2.4 数据仓库与数据中台
数据仓库与数据中台的区别与联系
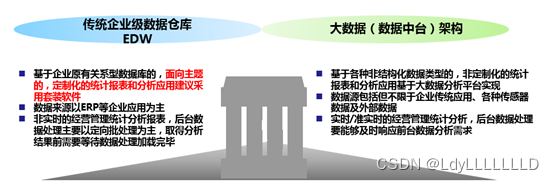
| 特性 | 数据仓库 | 数据中台 |
|---|---|---|
| 计算存储 | 基于OLAP类型的数据库构建一套数据存储体系 | 混合架构,随需搭配,满足各类数据 的计算要求 |
| 技术体系 | 传统的ETL开发和报表开发为主 | 数仓建设、数据开发IDE、任务调度、数据集成、数据治理、统一数据服务、数据资产管理、元数据管理、数据质量管理、流批计算、敏捷BI报表开发等多个功能 |
| 应用场景 | 报表为主 | 多元化场景:除了传统报表,还支持商品推荐、精准推送、客满评价等非确定场景的业务,数据服务业务、业务与数据互补,形成闭环 |
| 价值体现 | 面向管理层和业务人员的辅助决策 | 除了完成传统的业务人员辅助决策,还能面向业务系统推动优化升级、数据变现等,把数据资产变成数据服务能力 |
2.5 数据仓库与数据湖
Pentaho的CTO James Dixon 在2011年提出了“Data Lake”的概念。在面对大数据挑战时,他声称:不要想着数据的“仓库”概念,想想数据 的“湖”概念。数据“仓库”概念和数据湖概念的重大区别是:数据仓库中数据在进入仓库之前需要是事先归类,以便于未来的分析。这在OLAP时代很常见,但是对于离线分析却没有任何意义,不如把大量的原始数据保存下来,而现在廉价的存储提供了这个可能。
数据仓库是高度结构化的架构,数据在转换之前是无法加载到数据仓库的,用户可以直接获得分析数据。数据湖中,数据直接加载到数据湖中,然后根据分析的需要再转换数据。
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 写入型 Schema, 数据存储之前需要定义Schema, 数据集成之前需要完成大量清洗工作 ,数据的价值需要提前明确 | 读取型 Schema, 数据存储之后才需要定义Schema 提供敏捷、简单的数据集成 ,数据的价值尚未明确 |
| 扩展性 | 中等开销获得较大的容量扩展 | 低成本开销获得极大容量扩展 |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果会带来较高存储成本 |
| 连接方式 | 标准的SQL接口或者BI接口、ANSI SQL | 标准的SQL接口或者BI接口、ANSI SQL |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 复杂性 | 复杂的SQL链接 | 复杂的SQL链接 |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 批处理报告、BI 和可视化 |
| 优势 | 高并发、快速响应、干净安全的数据、数据一次转换多次使用 | 无限扩展性、支持编程框架、数据存储成本低 |
参考链接:数据库、数据仓库、大数据平台、数据中台、数据湖对比分析
参考链接:数据仓库、数据湖、数据中台终于有人说清楚了,建议收藏
2.6 数据中台与数据湖
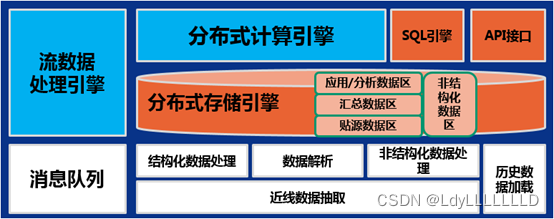
目前,Hadoop是最常用的部署数据湖的技术,所以很多人会觉得数据湖就是Hadoop集群。数据湖是一个概念,而Hadoop是用于实现这个概念的技术。

数据中台整体技术架构上采用云计算架构模式,将数据资源、计算资源、存储资源充分云化,并通过多租户技术进行资源打包整合,并进行开放,为用户提供“一站式”数据服务。
参考链接:数据湖、数据中台概念
数据湖是将复杂的事物具象化,反映了它在大数据存储和大数据处理方面的优势和能力。数据湖作为一个集中的存储库,可以在其中存储任何形式(结构化和非结构化)、任意规模的数据。在数据湖中,可以不对存储的数据进行结构化,只有在使用数据的时候,再利用数据湖强大的大数据查询、处理、分析等组件对数据进行处理和应用。因此,数据湖具备运行不同类型数据分析的能力。
中台概念的鼻祖――阿里巴巴的数据产品部总经理朋新宇表示:数据中台是数据+技术+产品+组织的组合,是企业开展新型运营的一个中枢系统。具体的说,它是一套解决方案,抽象的理解,它是一种新的公司运营理念。
数据中台从技术层面承接了数据湖的技术,通过数据技术,对海量、多源、多样的数据进行采集、处理、存储、计算,同时统一标准和口径,把数据统一后,以标准形式存储,形成大数据资产层,以满足前台数据分析和应用的需求。数据中台更强调应用,离业务更近,更强调服务于前台的能力,实现逻辑、算法、标签、模型、数据资产的沉淀和复用,能更快速的满足业务和应用开发的需求。
参考链接:浅析数据湖和数据中台的关系

