前言
日常开发中,我们经常会碰到有延时任务的场景,譬如30分钟后关闭订单、在指定时间上架某个活动等,如果是最简单的场景,不考虑服务水平扩容、服务宕机等因素,可能内部用github.com/robfig/cron加MYSQL存储延时信息即可。当然,一般线上服务,不可能不考虑道这些因素的影响,所以才有很多任务调度框架,比如:Quartz、xxl-job、Temporal等。但这次这里想讨论的是中间情况,也就是,既想保证服务能水平扩容、服务宕机任务不丢失,又不想使用那些调度框架(毕竟有部署成本和学习成本)。
延时任务存储
我们知道,要想服务能够自由地水平扩缩容,服务内部不能持有数据,也就是变成无状态服务,一般我们都选择放到Redis这种缓存框架中去。那对于延时任务来说,延时时间也是一种数据,我们把它存在哪里呢?首先不管存在哪里,一定要满足以下要求:
1. 截止时间到期后,能主动通知服务
这里肯定是要用PUSH的,如果存储器没有通知能力,那么只能用轮询的方案,但一是轮询的时间间隔不好设置,二是比较吃资源,三是任务的可靠性没有保障,如果轮询服务宕机,可能任务就得不到执行。
2. 保证任务执行的唯一性
一般来说,除非特殊需要,我们只想让延时任务只执行一次,比如指定时间上架活动,假如我们水平扩展了三个节点,总不能时间到期后三个节点同时做上架活动操作,这里就需要分布式协调机制。
3. 保证任务的可追溯性
比如任务即使到期了,通知也发出去了,但整个流程并没有结束,因为不能保证任务一定被执行了,如果通知消息没有被正确接收,被通知端需要有机制可以回溯消息。
那么,基于以上需求,我们依次来看手边常用的存储系统能否满足:
- 数据库
数据库一般没有主动通知的机制,要存到数据库,只能做轮询方案,这里直接PASS。 - Redis
Redis绝对是我们除了数据库外接触的最多的存储,而且Redis本身也提供了过期策略和通知机制,我们也可以直接通过Redis成熟的分布式锁方案来保证任务唯一性。然而,Redis的通知机制采用的是“发送即忘”的策略,也就是说,如果在事件发生时,没有监听者订阅这一事件,那么它就永远消失了。那么,实际上Redis不满足第三条要求。 - MQ
MQ不是专门的存储系统,没法存储截止时间。当然,它设计上必然会满足第二条、第三条要求,可是MQ毕竟还是偏实时的推送。当然有例如RocketMQ这种能支持一定程度的延时队列,或者RabbitMQ、Kafka等,也有手段来支持做延时队列。不过这毕竟不是它们的主业,在不同的MQ中需要使用不同的方法来实现延时队列,做不到通用性。
这样分析一圈下来,好像以上几个常见组件都不太行,难道除了使用专门的任务调度框架,就没有别的办法了吗?仔细看以上三个要求,我突然觉得有个组件很适合:ETCD,首先它有成熟的Watch通知机制,K8S都用它;其次它提供了KeyValue存储,和过期策略,那么我们就可以把延时时间和任务信息存在它这里,它会保证我们存储的信息不丢失;再次,它提供了MVCC版本控制,我们可以方便的回溯之前时间点的键值数据;最后,它比Redis更适合做分布式锁,能够保证任务唯一性。
如果使用ETCD来实现分布式延时队列,虽然它能提供的吞吐量可能比较有限,但正好符合我们的需求:简单,在业务的量没有那么大的时候,我觉得ETCD来做延时队列完全没问题。
延时任务设计
既然确定了存储器,那接下来就好办了,我们根据以上三个要求,细化出一个接口,包含以下几个方法:
type BackendStorage interface {
// Save 将 key 和 value 存到 Storage 中,并设置 key 的过期时间
Save(key string, value string, delay time.Duration) error
// Watch 接收 storage 的到期通知,调用相关回调函数处理
Watch() WatchChan
// TryLock 分布式锁
TryLock(key string) error
// UnLock 分布式锁
UnLock(key string) error
Close() error
}
我们可以做两个实现:etcdStorage和redisStorage,前面说过,Redis也可以过期、通知、分布式锁,区别只是Redis没有版本回溯机制,这里可以实现一个与ETCD对比。
在ETCD实现中,我们把延时任务的信息保存到Value中,Key做唯一标识,同时在后台起一个goroutine,监听ETCD的Key过期事件,当Key过期后,即调用相关的回调函数处理,处理时通过分布式锁保证只有一个回调函数被得到执行,这在多个副本节点场景下非常关键。
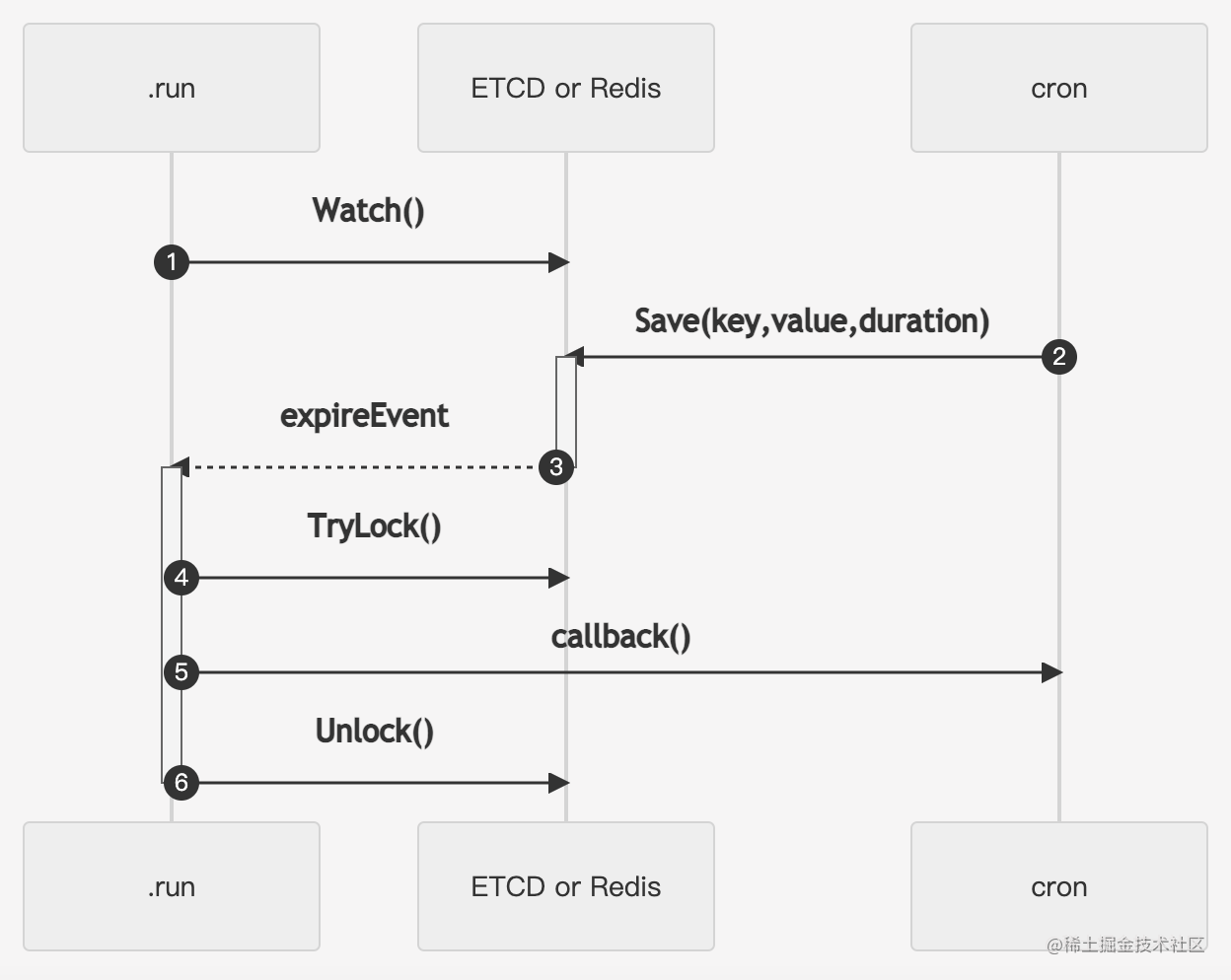
在Redis实现中,由于Redis的键空间通知只会通知过期的key,不会发送key对应的value,我们还得另外存一份key value的对应关系,其它流程与ETCD差不多。
延时任务测试
在集成测试时,碰到了一个有趣的bug,就是分布式锁在Redis上失效的问题,测试代码流程很简单,就是在Storage上存一个5秒后过期的任务,然后开启两个goroutine模拟两个节点同时监听到期事件。收到到期事件后,利用分布式锁保证只有一个节点能够执行,其它节点获取不到锁直接退出,正常日志如下:
2022-05-04T11:29:20.835+0800 INFO elastic_job/cron.go:115 a notification event: test_after
2022-05-04T11:29:20.835+0800 INFO elastic_job/cron.go:115 a notification event: test_after
cron_test.go:67: hello, world! <-- 此goroutine 获取到锁,运行代码
2022-05-04T11:29:20.867+0800 INFO elastic_job/cron.go:139 the job has already running. <-- 此goroutine 未获取到锁,直接退出
但是如果Storage换成Redis,则两个goroutine都会执行回调代码,分布式锁失效:
2022-05-04T11:31:49.228+0800 INFO elastic_job/cron.go:115 a notification event: test_after
cron_test.go:202: hello, world!
2022-05-04T11:31:49.241+0800 INFO elastic_job/cron.go:115 a notification event: test_after
cron_test.go:202: hello, world!
可以看到hello,world被打印了两次,而且这种PUSH机制比较难调试。最后我是发现日志上接收时间的时间不对,正常用ETCD的日志,可以看到过期事件几乎是同时推送过来的,而Redis的日志,过期事件推送存在时间差,猜测可能是Redis推送用的是队列,一个一个推送?具体代码我没有了解过,但可以肯定Redis的订阅推送机制不如ETCD来的及时,存在一定时延。
存在时间差就导致,如果上个事件的回调函数执行的太快(比如本例的hello,world),当下个事件推送到其它goroutine时,此分布式锁早已被释放了,那么在这个场景中,就会出现这种bug。
改进方案也很简单,获取锁的goroutine不要马上释放锁,而是等一会儿再释放,这个等的时间我设置了3秒,在简单场景中这足够事件全部推送出去了。
但这样的方案不够完美,不能保证3秒一定能推送到全部节点,所以可能不能用分布式锁,而应该选出一个主节点,由它负责回调函数的执行,这样比较好,但代码也更复杂了,为了保证简单性,这里没有改换方案。
代码
以上代码都放在github中,感兴趣可以fork、运行。

