����Ŀ¼
HDFS�������̺ͻ���
һ��HDFS��Ⱥ��ɫ��ְ��
�ٷ��ܹ�ͼ
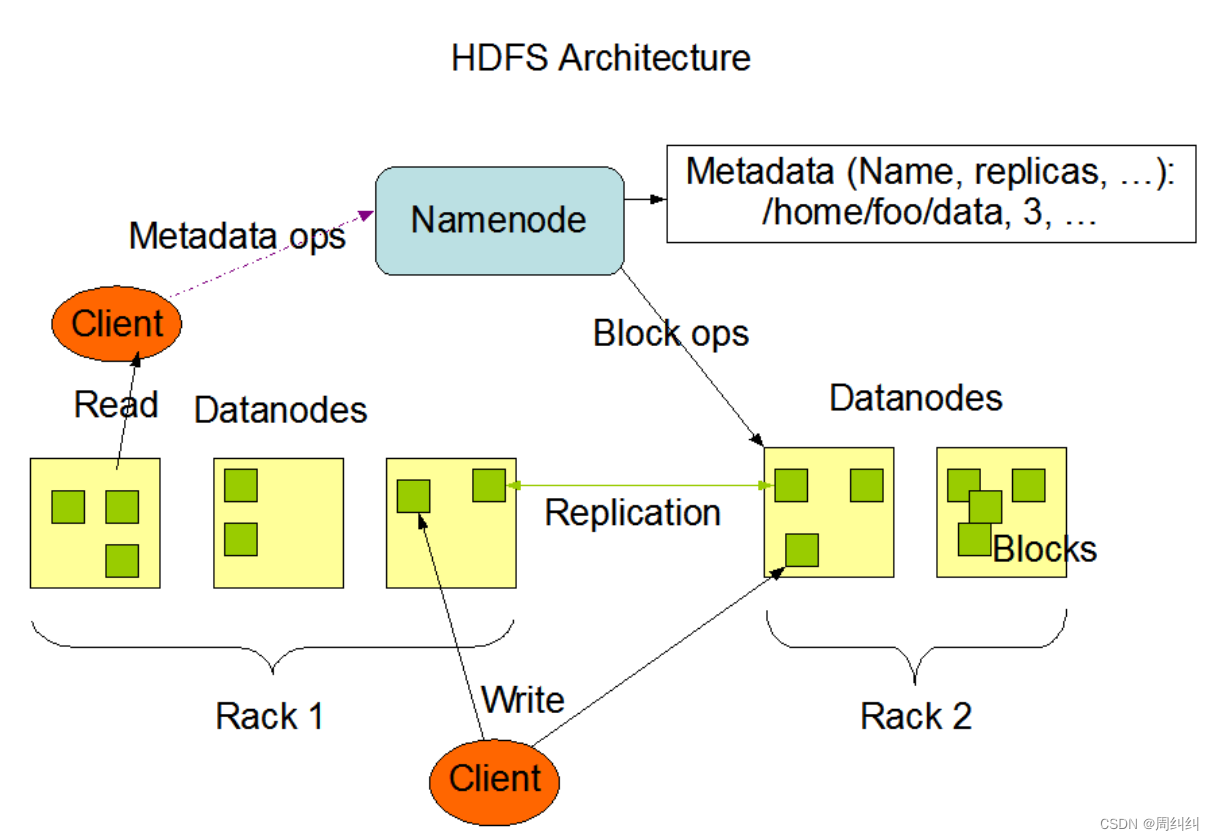
����ɫ:namenode
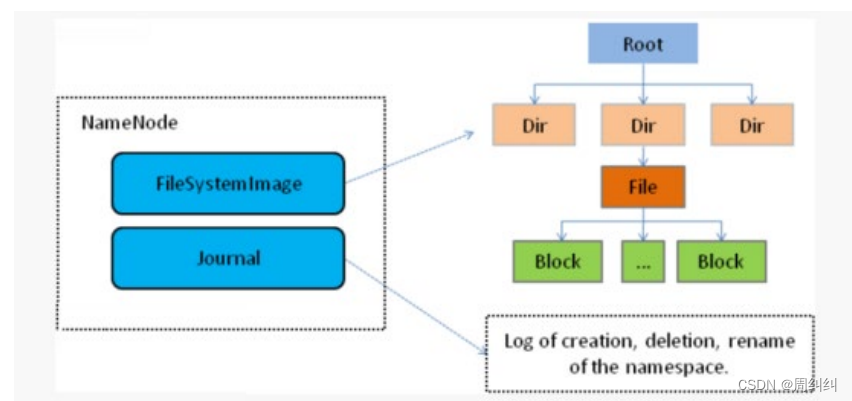
- NameNode��Hadoop�ֲ�ʽ�ļ�ϵͳ�ĺ���,�ܹ��е�����ɫ��
- NameNodeά�������ļ�ϵͳԪ����,�������ƿռ�Ŀ¼���ṹ���ļ��Ϳ��λ����Ϣ������Ȩ����Ϣ��
- ���ڴ�,NameNode��Ϊ������HDFS��Ψһ�����
- NameNode�ڲ�ͨ���ڴ��ʹ����ļ����ַ�ʽ����Ԫ���ݡ�
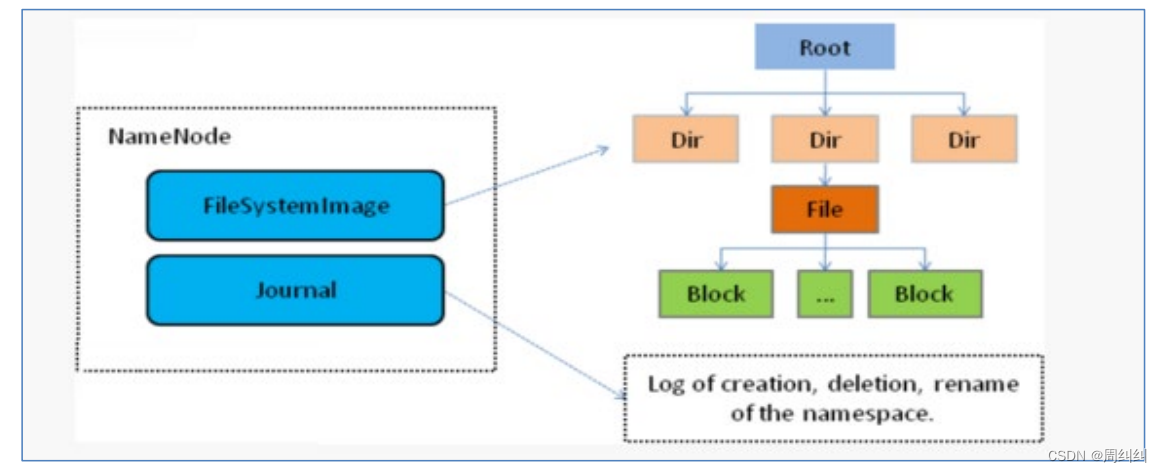
- ���д����ϵ�Ԫ�����ļ�����Fsimage�ڴ�Ԫ���ݾ����ļ���edits log(Journal)�༭��־��
�ӽ�ɫ:datanode
- DataNode��Hadoop HDFS�еĴӽ�ɫ,�����������ݿ�洢��
- DataNode������������HDFS��Ⱥ���������ݴ洢������ͨ����NameNode���ά�������ݿ�
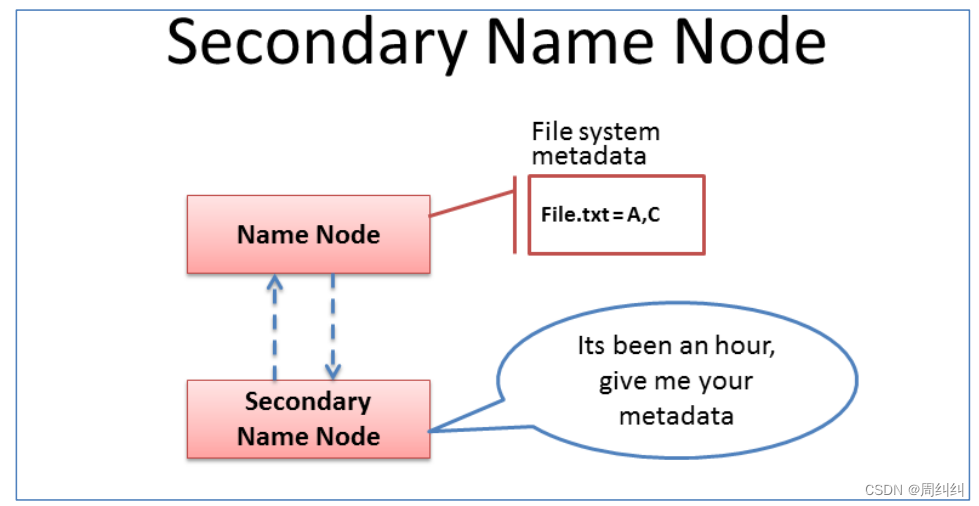
����ɫ������ɫ: secondarynamenode
- Secondary NameNode�䵱NameNode�������ڵ�,���������NameNode��
- ��Ҫ�ǰ�������ɫ����Ԫ�����ļ��ĺϲ�����������ͨ������Ϊ����ɫ�ġ����顱��
namenodeְ��
- NameNode���洢HDFS��Ԫ����:�ļ�ϵͳ�������ļ���Ŀ¼��,������������Ⱥ�е��ļ�,���洢ʵ�����ݡ�
- NameNode֪��HDFS���κθ����ļ��Ŀ��б�����λ�á�ʹ�ô���ϢNameNode֪����δӿ��й����ļ���
- NameNode���־û��洢ÿ���ļ��и��������ڵ�datanode��λ����Ϣ,��Щ��Ϣ����ϵͳ����ʱ��DataNode�ؽ���
- NameNode��Hadoop��Ⱥ�е��������(һ�������ɶ��ģ�����,����ijһ���ֲ���������,���������������)��( һ��NameNode��������,�����еĶ�д����û����)
- NameNode���ڻ���ͨ���������д����ڴ�(RAM)��
datanodeְ��
- DataNode�����������ݿ�block�Ĵ洢���Ǽ�Ⱥ�Ĵӽ�ɫ,Ҳ��ΪSlave��
- DataNode����ʱ,�Ὣ�Լ�ע�ᵽNameNode���㱨�Լ�������еĿ��б���
- ��ij��DataNode�ر�ʱ,����Ӱ�����ݵĿ����ԡ� NameNode������������DataNode�����Ŀ���и�������
- DataNode���ڻ���ͨ�������д�����Ӳ�̿ռ�,��Ϊʵ�����ݴ洢��DataNode�С�
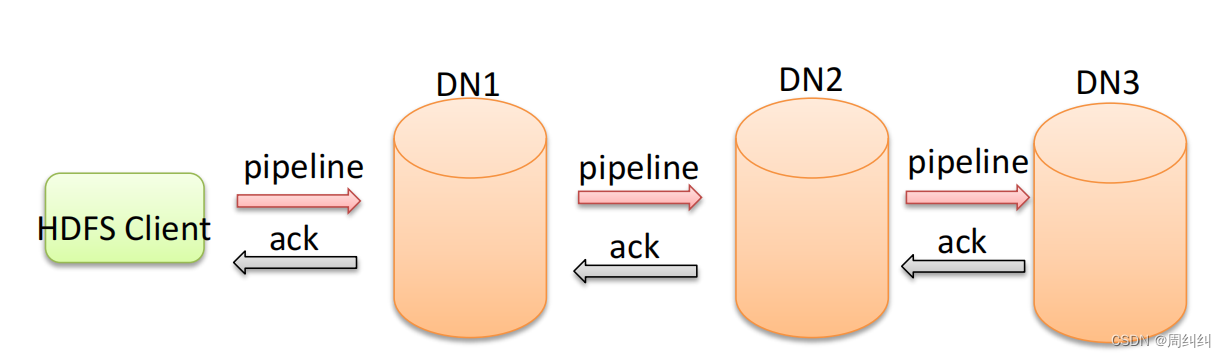
����HDFSд��������(�ϴ��ļ�)
д������������ͼ
HDFS Client �ͻ���:���ķ��������
������:DataNode
���ĸ���CPipeline�ܵ�
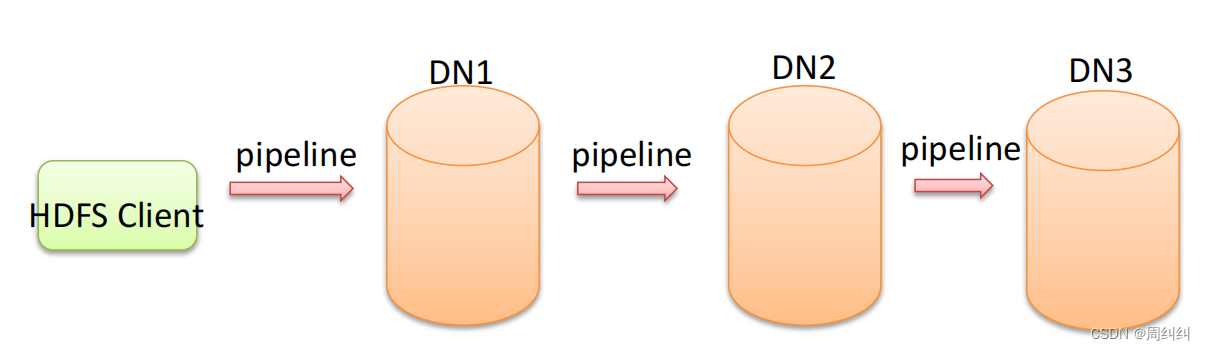
- Pipeline,���ķ���Ϊ�ܵ�������HDFS���ϴ��ļ�д���ݹ����в��õ�һ�����ݴ��䷽ʽ��
- �ͻ��˽����ݿ�д���һ�����ݽڵ�,��һ�����ݽڵ㱣������֮���ٽ��鸴�Ƶ��ڶ������ݽڵ�,���߱�����临�Ƶ����������ݽڵ㡣
- Ϊʲôdatanode֮�����pipeline���Դ���,������һ�θ�����datanode����ʽ������?
- ��Ϊ�����Թܵ��ķ�ʽ,˳�������һ��������,�����ܹ��������ÿ�������Ĵ���,��������ƿ�����ӳ�ʱ������,��С�������������ݵ���ʱ��
- ����������ģʽ��,ÿ̨�������еij��ڿ����������������ٶȴ�������,�������ڶ��������֮����������
���ĸ���CACKӦ����Ӧ
- ACK (Acknowledge character)����ȷ���ַ�,������ͨ����,���շ��������ͷ���һ�ִ���������ַ�����ʾ������������ȷ�Ͻ�������
- ��HDFS pipeline�ܵ��������ݵĹ�����,����ķ���������ACKУ��,ȷ�����ݴ��䰲ȫ��
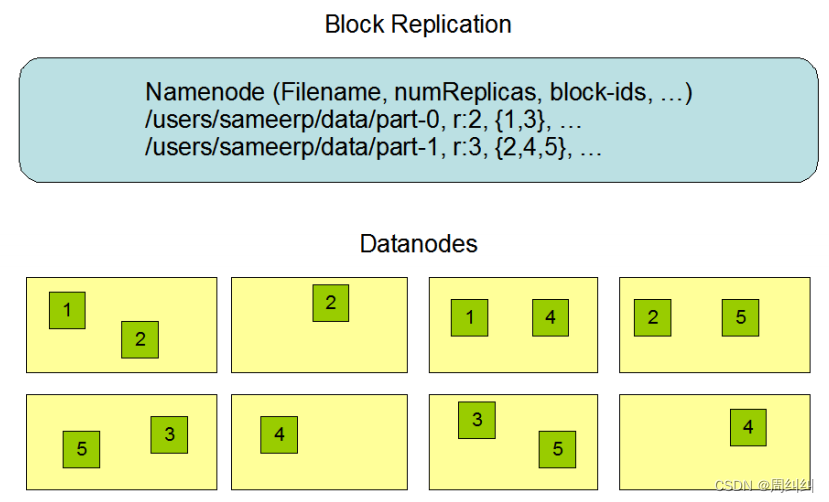
���ĸ���CĬ��3�����洢����
- Ĭ�ϸ����洢��������BlockPlacementPolicyDefaultָ����
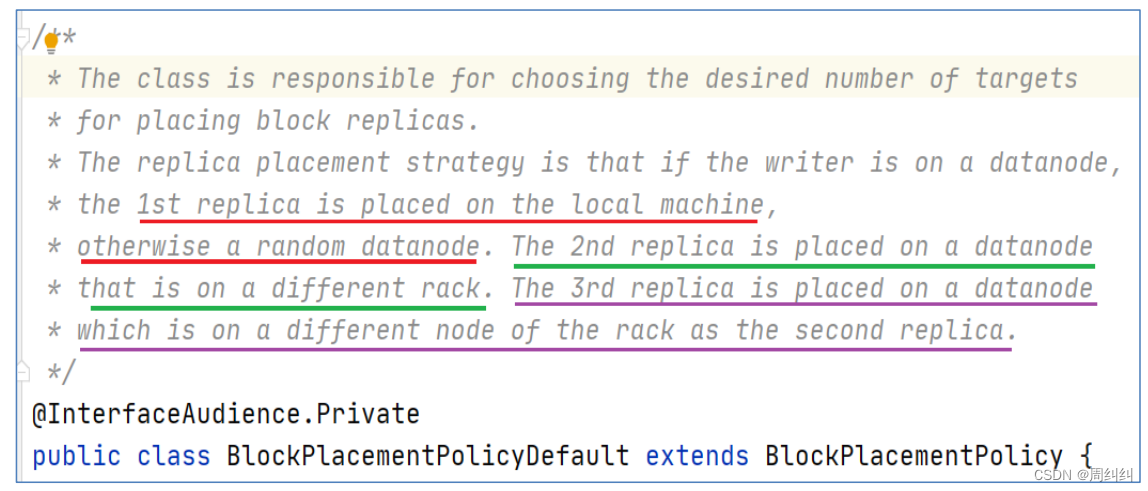
- ��һ�鸱��:���ȿͻ��˱���,�������
- �ڶ��鸱��:��ͬ�ڵ�һ�鸱���IJ�ͬ���ܡ�
- �����鸱��:�ڶ��鸱����ͬ���ܲ�ͬ������
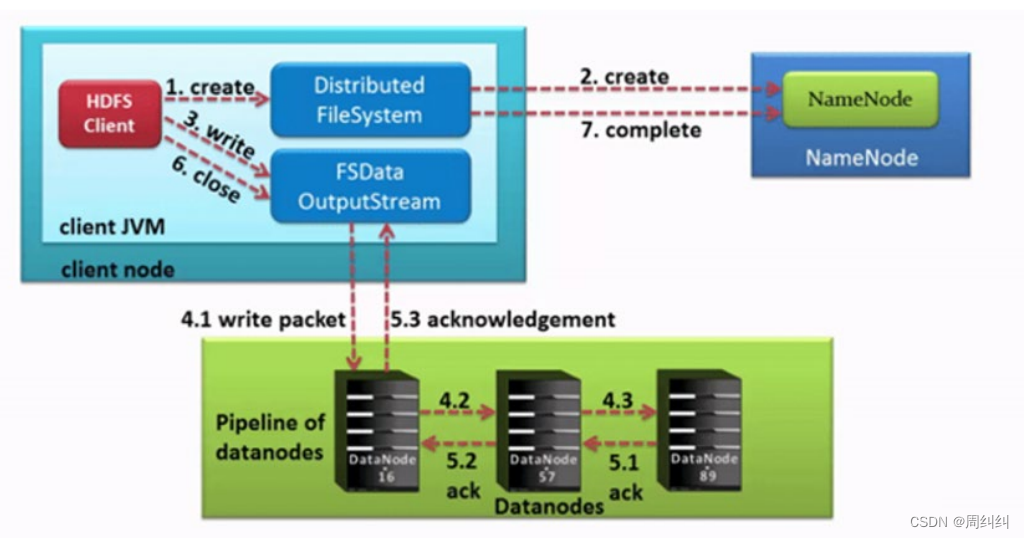
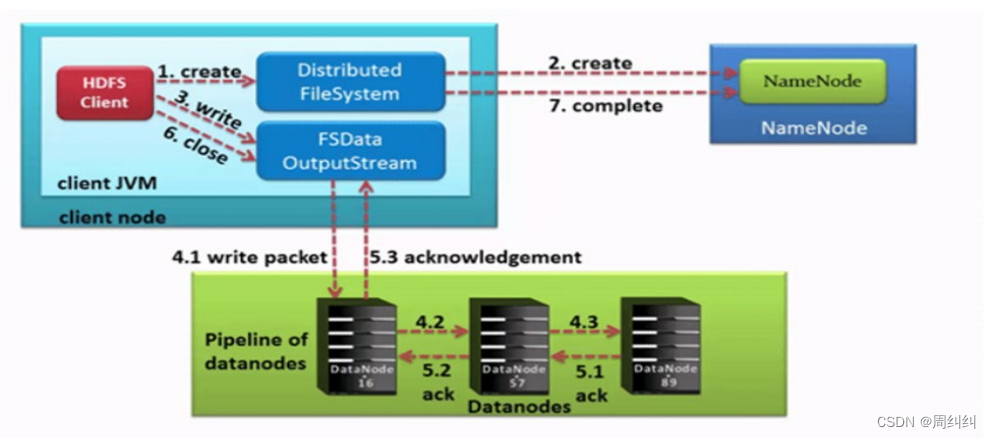
1��HDFS�ͻ��˴�������ʵ��DistributedFileSystem, �ö����з�װ����HDFS�ļ�ϵͳ��������ط�����
2������DistributedFileSystem�����create()����,ͨ��RPC����NameNode�����ļ���
NameNodeִ�и�������ж�:Ŀ���ļ��Ƿ���ڡ���Ŀ¼�Ƿ���ڡ��ͻ����Ƿ���д������ļ���Ȩ�ޡ����ͨ��,NameNode�ͻ�Ϊ�����������һ����¼,����FSDataOutputStream�����������ͻ�������д���ݡ�
3���ͻ���ͨ��FSDataOutputStream�������ʼд�����ݡ�
4���ͻ���д������ʱ,�����ݷֳ�һ�������ݰ�(packet Ĭ��64k), �ڲ����DataStreamer����NameNode��ѡ���ʺϴ洢���ݸ�����һ��DataNode��ַ,Ĭ����3�����洢��
DataStreamer�����ݰ���ʽ���䵽pipeline�ĵ�һ��DataNode,��DataNode�洢���ݰ����������͵�pipeline�ĵڶ���DataNode��ͬ��,�ڶ���DataNode�洢���ݰ����ҷ���������(Ҳ�����һ��)DataNode��
5������ķ�������,��ͨ��ACK����У�����ݰ������Ƿ�ɹ�;
6���ͻ����������д���,��FSDataOutputStream������ϵ���close()�����رա�
7��DistributedFileSystem��ϵNameNode��֪���ļ�д�����,�ȴ�NameNodeȷ�ϡ�
��Ϊnamenode�Ѿ�֪���ļ�����Щ�����(DataStream����������ݿ�),��˽���ȴ���С���ƿ鼴�ɳɹ����ء�
��С�������ɲ���dfs.namenode.replication.minָ��,Ĭ����1
����HDFS����������(�����ļ�)
��������������ͼ
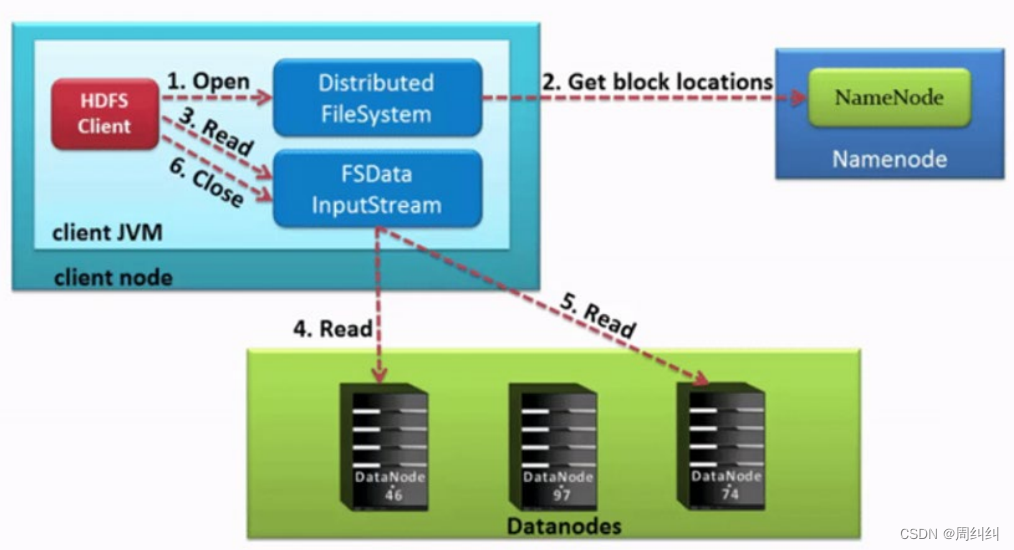
1��HDFS�ͻ��˴�������ʵ��DistributedFileSystem, ���øö����open()��������ϣ����ȡ���ļ���
2��DistributedFileSystemʹ��RPC����namenode��ȷ���ļ���ǰ������Ŀ�λ��(�����ζ�ȡ)��Ϣ��
����ÿ����,namenode���ؾ��иÿ����и�����datanodeλ�õ�ַ�б�,���Ҹõ�ַ�б�������õ�,��ͻ��˵��������˾����������ǰ��
3��DistributedFileSystem��FSDataInputStream���������ص��ͻ����Թ����ȡ���ݡ�
4���ͻ�����FSDataInputStream�������ϵ���read()������Ȼ��,�Ѵ洢DataNode��ַ��InputStream���ӵ��ļ��е�һ����������DataNode�����ݴ�DataNode���ؿͻ���,����ͻ��˿����������ظ�����read()��
5�����ÿ����ʱ,FSDataInputStream���ر���DataNode������,Ȼ��Ѱ����һ��block������datanodeλ�á���Щ�������û���˵�����ġ������û��о�������һֱ�ڶ�ȡһ������������
�ͻ��˴����ж�ȡ����ʱ,Ҳ�������Ҫѯ��NameNode��������һ�����ݿ��DataNodeλ����Ϣ��
6��һ���ͻ�����ɶ�ȡ,�Ͷ�FSDataInputStream����close()������

