本文目录
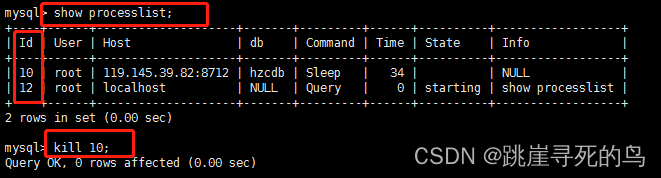
查看mysql的连接数
有时候mysql数据库卡是因为连接数过多导致的。所以查看链接数然后关闭一些不必要的连接也是调优的一种手段。
查看连接数:
show processlist;
主动断开链接
id是查看连接数时的id(如下例子)
kill id
例子
索引
聚簇索引:就是主键索引
非聚簇索引:非主键的索引(普通索引、唯一索引)
索引都是B+树的结构。
聚簇索引和非聚簇索引(二级索引)的区别
聚簇索引包含了表中所用字段的信息。
非聚簇索引只是包含了索引字段和主键信息
所以用非聚簇索引的查询中包含了非索引字段信息时,就要用id去聚簇索引再查一次(回表操作)
普通索引和唯一索引的区别
唯一索引比普通索引多了唯一的约束。
创建索引语法
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY]
[index_name] (col_name[length],…) [ASC | DESC]
例子
给表【student】的字段【name】添加普通索引【index】索引的名称是【name_index】
ALTER TABLE student ADD index name_index(name)
删除索引语法
ALTER TABLE table_name DROP INDEX index_name;
例子
删除表【student】名称为【name_index】的索引
ALTER TABLE student DROP INDEX name_index;
explain
我们建立索引后想查看mysql是否用上了?用上了哪个个索引?explain就可以清楚的展示出来。
explain语法
explain <sql语句>
例子

| id | 在一个大的查询语句中每个SELECT关键字都对应一个 唯一的id |
|---|---|
| select_type | SELECT关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
explain输出字段介绍
前言-表结构
s1表
CREATE TABLE `s1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`key1` varchar(100) DEFAULT NULL,
`key2` int(11) DEFAULT NULL,
`key3` varchar(100) DEFAULT NULL,
`key_part1` varchar(100) DEFAULT NULL,
`key_part2` varchar(100) DEFAULT NULL,
`key_part3` varchar(100) DEFAULT NULL,
`common_field` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_key1` (`key1`),
KEY `idx_key3` (`key3`),
KEY `idx_key_part` (`key_part1`,`key_part2`,`key_part3`),
KEY `idx_key2` (`key2`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=110002 DEFAULT CHARSET=utf8;
s2表
CREATE TABLE `s2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`key1` varchar(100) DEFAULT NULL,
`key2` int(11) DEFAULT NULL,
`key3` varchar(100) DEFAULT NULL,
`key_part1` varchar(100) DEFAULT NULL,
`key_part2` varchar(100) DEFAULT NULL,
`key_part3` varchar(100) DEFAULT NULL,
`common_field` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_key2` (`key2`),
KEY `idx_key1` (`key1`),
KEY `idx_key3` (`key3`),
KEY `idx_key_part` (`key_part1`,`key_part2`,`key_part3`)
) ENGINE=InnoDB AUTO_INCREMENT=110002 DEFAULT CHARSET=utf8;
id
id如果相同,可以认为是一组,从上往下顺序执行
在所有组中,id值越大,优先级越高,越先执行
关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好

table
不论我们的查询语句有多复杂,里边儿 包含了多少个表 ,到最后也是需要对每个表进行 单表访问 的,所以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
select_type
SIMPLE
普通查询(包含连接查询)
explain select * from s1 join s2 on s1.key1=s2.key1;

PRIMARY
主表(最外层的表)
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 where s2.key1='a') OR key3 = 'a';

图中可以看出最外层的表是【s1 】
SUBQUERY
非依赖子查询
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 where s2.key1='a') OR key3 = 'a';

DEPENDENT SUBQUERY
依赖子查询,子查询条件上依赖主表
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 where s2.key1=s1.key1) OR key3 = 'a';

MATERIALIZED
MATERIALIZED物化子查询结果集
explain select * from s1 where key1 in (select key1 from s1 where key2=10003);

图中id为2的是MATERIALIZED,然后注意看table中有就是被物化出来的表,然后进行连接查询。
DERIVED
查询派生出来的表,如下sql
EXPLAIN SELECT * FROM (SELECT key1, count(*) as c FROM s1 GROUP BY key1) AS
derived_s1 where c > 1;

type
type有如下值: system , const , eq_ref , ref , fulltext , ref_or_null ,
index_merge , unique_subquery , index_subquery , range , index , ALL 。
system
在MyISAM中表字段只有一个的情况下查询会出现,速度最快。
const
根据表中主键去查询,或者根据唯一索引去查询唯一索引的字段(唯一覆盖索引)。
1主键查询例子:
explain select * from s1 where id=100001;

2唯一覆盖索引
说明:key2 是唯一索引
注意:这里查询字段只能是key2,如果包含了唯一主键之外的字段要重新走聚簇索引进行回表查询
explain select key2 from s2 where key2=2710006;

eq_ref
用主键作为关联查询的条件
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;

ref
查询条件用上了非聚簇索引
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';

index_merge
两个索引合并使用
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';

unique_subquery
unique _subquery 是针对在一些包含IN子查询的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的 type 列的值就是 unique_subquery
EXPLAIN SELECT * FROM s1 WHERE id IN (SELECT id FROM s2 where s1.key2 =s2.key2) OR key3 = 'a';

index_subquery
子查询用了普通索引
EXPLAIN SELECT * FROM s1 WHERE common_field IN (SELECT key3 FROM s2 where s1.key1 = s2.key1) OR key3 = 'a';

range
用上索引范围查找
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');

index
在组合索引中有要查询的字段,但是where条件中没有出现组合索引的第一个索引字段。
例如:有组合索引:idx_key_part (key_part1,key_part2,key_part3)
查询了【key_part2】 但是where没有出现【key_part1】
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';

ALL
全表扫描
小结:
结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range > index > ALL
possible_keys和key
possible_keys可能用上的索引
key是最后用上的索引
key_len
key_len是用上索引的大小,组合索引可以看这个字段判断出组合索引生效了多少个
EXPLAIN select * from s1 where key_part1 ='aa' and key_part2='aa' and key_part3 = 'aa';

key_len的计算方法:
varchar(10)变长字段且允许NULL = 10 * ( character set:
utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchar(10)变长字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)
例子中组合索引idx_key_part (key_part1,key_part2,key_part3)
三个字段都是 varchar(100),一个key_len就是303,图上看到key_len是909所以是三个都用上了。
ref
是指查询的参数类型
rows
预估符合行数,就是经过条件过滤出来的数据。注意是预估值
filtered
索引的命中率
Extra
执行SQL的一些日志说明

