Ŀ¼
- ΪʲôҪ���쳣����
- ����Ҫ��ʲô
- �쳣����ʵ��
- �ܽ���չ��
ժҪ
TC��Դ�����ǽ���ƽ̨ҵ����·�пͻ�������ط������ط�����Դ�йܵĹ�������,�����ǽ�����Դ�����������������ĺ��ķ���ÿ����ڵĵ�����,TC��Դ���������쳣��������ʧҲ�Ƿdz���ġ����ڴ�,������Ҫ�����TC��Դ���ĵĽ���Ԥ��,����һЩ�쳣������صij��Ժ�ʵ����
����
- ΪʲôҪ���쳣����
���ڽ���ƽ̨TC��Դ����,�������������������¹�:
(1)2019�� ����ƽ̨TCϵͳ�����쳣(���յ������������쳣,Ӱ�����β������������)
(2)2020�� ����ƽ̨TC̯�������쳣(���յ������������쳣,Ӱ�����β������������)
�ܽ�:�κλ�����ʩ(��Ҫ������ϵͳ)���κ�����(ҵ��������������)�����ܳ�������,û�о����ش�������֤��������ʩ����ˣ��å��
-
���ڽ���ƽ̨TC��Դ����,���ǵ�ʹ��:
(1)�����:�����,������ϵ����,�ֲ�ʽ,�߿��õ�
(2)���츴�ӳ�������:���������쳣���츴��,����쳣����ͬʱģ������,��ڵ������
(3)���Գɱ���:�˹�ִ���쳣,�쳣Ч���ȶ�����,�쳣���Իع�Ч�ʵ�,��ͬʱ�ζԷ�������쳣����,�����Բ�����
(4)ѧϰ�ɱ���:��Ҫѧϰ�����쳣������ص�֪ʶ���������ո���ϵͳ����/������繤�ߵ�,����Ҫ�߱���������쳣�ű��������� -
���ڽ���ƽ̨TC��Դ����,���ǵ�Ŀ��:
ϣ��ͨ�������ֶ�����֤TC����ĸ߿��ú��ȶ��ԡ�������4��9�Ĺ�˾���� -
���ڽ���ƽ̨TC��Դ����,ʵ�ַ���߿���/���ȶ��Ե�һЩ���õļ����ֶ�:(��ƪ�����ص��ڡ����������쳣����ʵ��,������δ�漰)
1)���ؾ����뷴�����(��:Nginx)
2)��������(��:�̸߳��롢���̸��롢��Ⱥ���롢�������롢��д���롢�������롢�������롢������롢�ȵ���롢��Դ�����)
3)����(��:Ӧ�ü��������ֲ�ʽ������)
4)����(��:����Ԥ�����˹����ؽ������Զ����ؽ�������������д�������༶������)
5)��ʱ�����Ի���(��:�����㳬ʱ��Web������ʱ���м����ʱ�����ݿⳬʱ��NoSQL��ʱ��ҵ��ʱ��ǰ�˳�ʱ��)
6)�ع�����(��:����ع��������ع�������汾�ع������ݰ汾�ع�����̬��Դ�汾�ع���)
7)ѹ����Ԥ��(��:ϵͳѹ��(���ϻ�����)��ϵͳ���֡�Ӧ��Ԥ����)
-
����Ҫ/����ʲô
�쳣��������/������(�����ܽ�����ο�)

(1)�쳣֪ʶor����ѧϰ(�������쳣�������)
(2)�쳣ģ��ű�/�����(��ʵ����ͨ���ű�������ģ������ij����쳣)
(3)����ѹ������ģ��ѹ��(��Щ�쳣��ģ��,��Ҫͨ��ѹ��������)
(4)��ʼ������(�쳣������Ҫ�Ļ���)
(5)�ֹ�����Զ���ִ���쳣�ű�/����
(6)������־��ȷ��(�����쳣��ҵ�����ͨ���Ჶ��дlog,���ϻ������ԶԱ��н�����û�����������������/�������仯����) -
�쳣����ʵ��
��ʵ��һ��:A���������������������
-
����:
��ǰA����Ľ������:
A����ǰÿ������4������,�߷�QPSΪ15000��/s,�ӿ�ƽ����Ӧʱ��Ϊ2ms���ҡ����A������κ�һ���쳣������Ӱ�춼���������Ѽ��ġ�
����:
��ͼΪij�ε�����������ʱ�ij���,������Ӱ������Ƕ�ʱ���ڶ�ʧƽʱ������֮һ��������
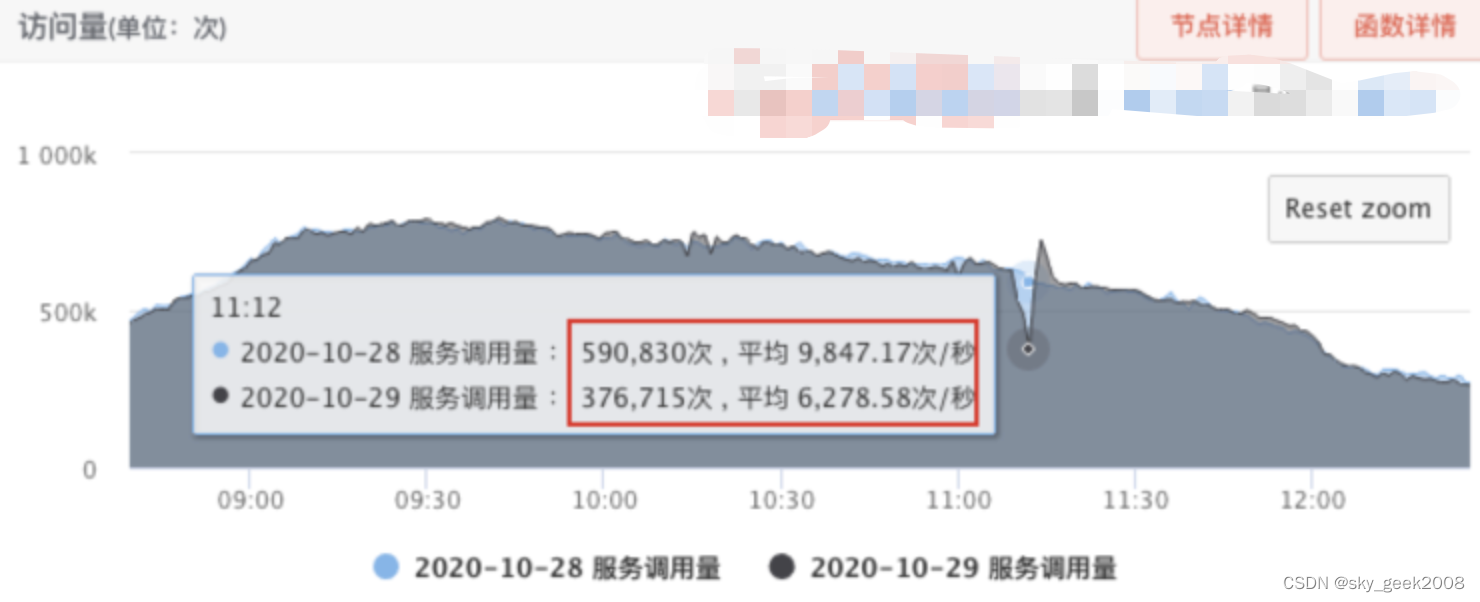
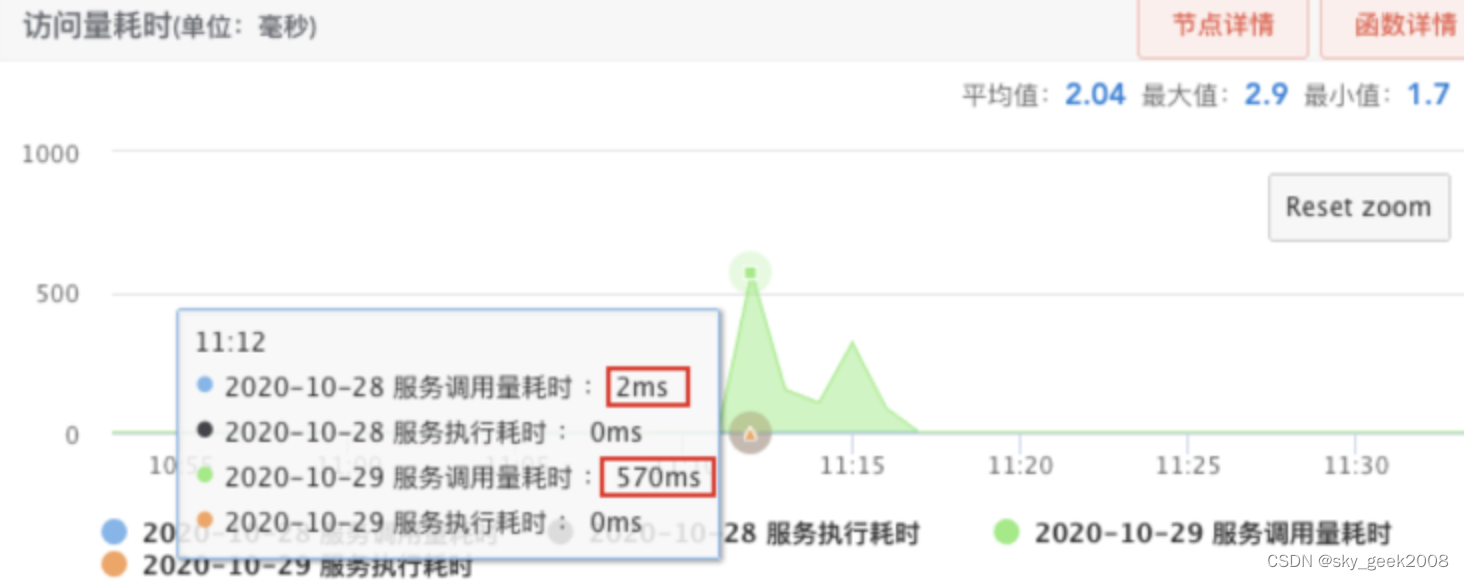
-
��������ѡ��:Sentinel
ΪʲôѡSentinel?
Sentinel���:https://sentinelguard.io/zh-cn/ https://github.com/alibaba/Sentinel/wiki
���弼��ϸ����,����Ȥ����˽��! -
������쳣������?ֱ�����������ᵽ�ġ��쳣�������̡�
1��ѧϰ����C��Ҫѧϰ����Sentinel�Ĵ���ʵ��(ÿһ�ּ�������ؿ��ܶ���Щ�Զ������컯�Ķ���,���Դ���϶���Ҫߣ��)
2�����ӿں�д�ӿڽ���ԭ��ͬ,��β������ܴ�������?
a.���ڴ�����IJ�ѯ�ӿ���˵,���������ֱ�ӿ���ʧ��,��Ӧ�ò㲻��������Ĵ���,����ֱ�ӷ��ز�ѯ�쳣��Ӧ�ò�,�ϲ�Ӧ���յ���ѯ��������ܻ��������������
b.����д�ӿ��ڽ�����͵ð���ͬ��ҵ�����д���,��������ṩ���������߾ܾ�����
i) �����ṩ�������:����֧��ϵͳ�ij�ֵ�������ڳ�ֵ�ƹ��ֽ�ʱ��Ҫȥ��ѯVIP�����ŻݵĻ��,��ʱ�Բ�ѯ�ŻݵĽӿڽ�������ó�ֵ������������,���Ǽ�¼��������־,���Ժ����ȷ���ָ����ٰѳ�ֵ���Żݲ�����,��ʱ�൱���ṩ������ķ���
ii) �ܾ�����:��nresource����Դ���Ӳ���ʱ,��Ҫ����payId��ѯ�ñʳ�ֵ�����Ƿ���������֧���ɹ���,����ѯ������Ҫ�ܾ�����,��ֹ�쳣��payId��������Դ���ӡ�
3��������ֵ������
a.ż�������綶�����ܴ�������;
b.���������ܵ�Ѹ��;
��ֵ�������ǽ����������Ҫ��һ��,���õIJ����ʵĻ�����ɸý�����ʱ��û����,ż�������綶���ֽ����˽���(ż�������綶����Ӧ�ý��н���,���ԶԳ�ʱ��������)��
4���������Ⱦ����ܵ�ϸ,��RPC�������ͬʱ����A��B�����ط���,������Ϊ��A�Ľ�����Ӱ��B�Ľ�����
(���ںܶ�������������з���������,����A�����Ľ������ܰѶ�B�����ĵ���Ҳһ��������,��Ϊ��ʱ����A��B�����ڷ���ͬ�ķ���,��ʱ����ֻ��A���ڵķ���������,BӦ�������������õġ������˵һ��,scf�Դ���Hystrix���Ҳ�Ƕ��������н�����,��������û�п��ǵ����ط���,���Կ����ڶ�A������ʱ��Ҳ��B�����ˡ���������ǽ�Sentinel����ʱ��resource key��������ϸ����,ʹ�� ServiceName() + ��.�� +Lookup() + ��.�� + MethodName()+��������������������֤������Դ��Ψһ�ԡ������ͱ�֤��ֻ��Ψһ�ķ������н���)
5�����������1~4,�����Ѿ��˽��˴�������ʵ��ϸ��,��ʼ����Ե����쳣ģ�⼰���ԡ�
a. Ӱ�췶Χ(��������ķ���),Ӱ��ӿ�����9��(����ӿھͲ�һһ�г���)
b. ���������ķ�ʽ3��:
i) unionbrokerscf���ó�ʱ����
ii) nresource���ó�ʱ����
iii) matrix��ʱ��������
c. ���ģ��3���쳣����������(�˴�ֻ�Ե�1�ֽ�����˵��,�����������Ʋ�������)
unionbrokerscf���ó�ʱ����
n�ַ�ʽ:
(1)�Ѳ��Ի�����Ӧ����������unionbrokerscf���ڻ����ر� --��Ա���!
(2)�Ѳ��Ի�����Ӧ����������unionbrokerscf���ڻ��������ر� --��Ա���!
(3)�Ѳ��Ի�����Ӧ����������unionbrokerscf���ڻ�����Դ���� --��Ա���!
(4)�Ѳ��Ի�����Ӧ����������unionbrokerscf�����ر� --��Ա���!
(5)�Ѳ��Ի�����Ӧ����������unionbrokerscfѹ������ --��Ա���!
(6)�Ѳ��Ի�����Ӧ����������unionbrokerscf���ó�ʱ��Ϊ1ms --��Ȼ���ָ����������쳣����!
��������ѡ���(6)�ַ�ʽ,��manager����ƽ̨���õ���������unionbrokerscf����ʱʱ��Ϊ1ms,����ͼ:
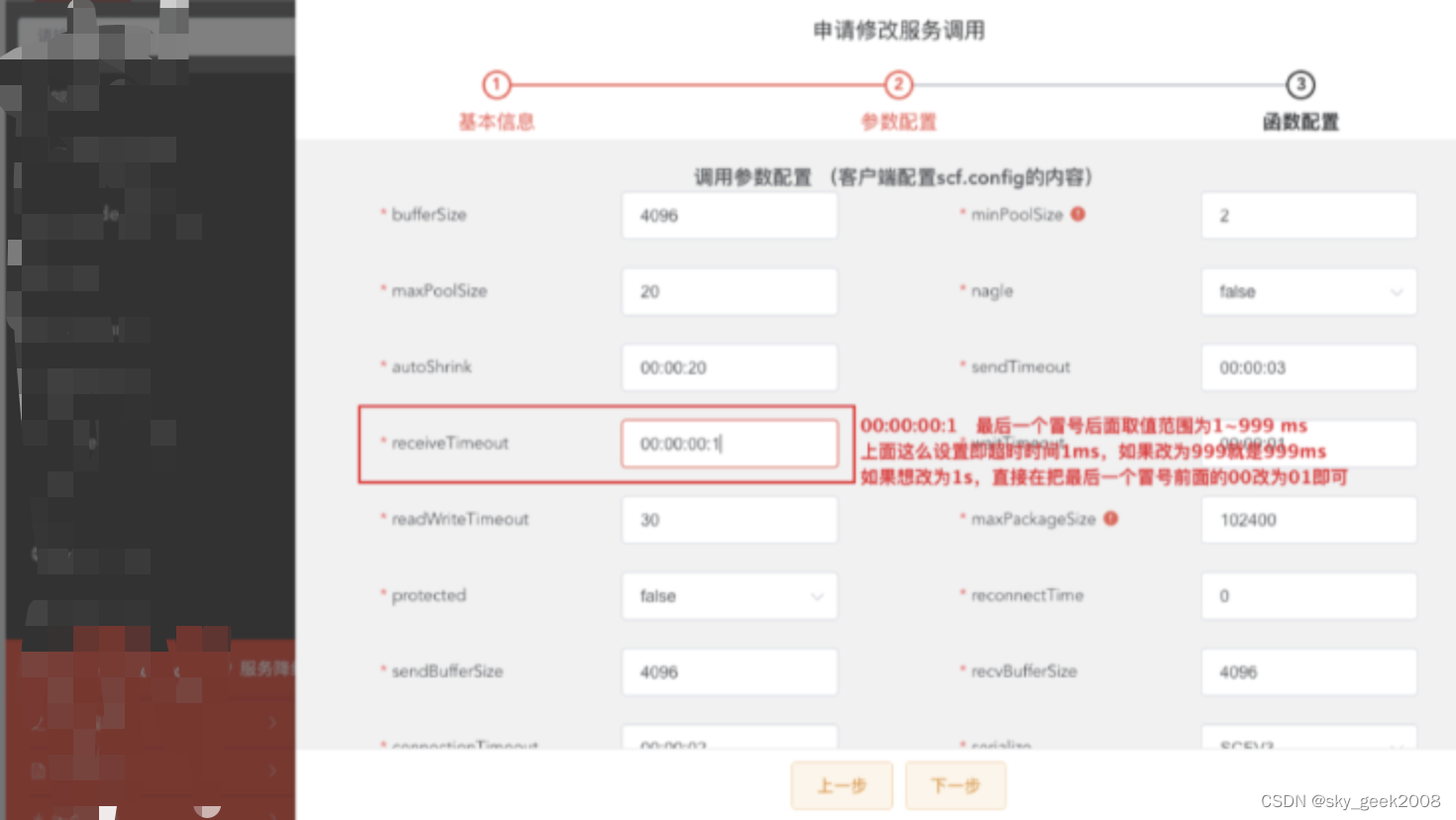
������ɺ�,�������ǵı������A(Ҳ�����Ȳ���,�����ó�ʱʱ��)��
6����дѹ��ű�(����:getOrders�ӿڵ�jmeterѹ��ű�����)
�ԡ�����Ƚϼ�,�Ͳ�����!
7��Ȼ��ִ��ѹ��ʱ,��Ҫ����sentinelע���еIJ���(������´���)�����ú����IJ�����������������
@DemotionSettings(
count = 0.2d,
statIntervalMs = 1000,
timeWindow = 1,
serviceName = "unionbrokerscf",
lookUp = "UnionbrokerServiceImpl",
minRequestAmount = 20
)
@Override
public UnionBrokerAccount queryUnionBrokerAccount(Long aLong, Integer integer) {
/**
* ������ע��:
* 1��������д�ӿ�һ������ֵΪnull,���������������,����������Ĵ����������Ϊ
* 2�������Ķ��ӿڷ���null,���緿vip(getLastPack,getLastItem)�ӿ�ֻ�ܲ�ѯ���Ϊ58��Ա,�����Ļ�Ա��ѯ����,Ҳ����Ӱ������ҵ��IJ���
* 3������getBalance,getOrders�ӿ�ֻ�ܲ�ѯ���Ϊ58��58��һ���ֵ���Դ
*/
logger.error("queryUnionBrokerAccount ��������,userId {} userType {}", aLong, integer);
return null;
}
����:timeWindow=1��ʾͳ�ƴ���1��;minRequestAmount = 20��ʾÿ�����ٵ���������20��,Ȼ��count = 0.2d��ʾ��ÿ��n��(n>=20)����ʱ,��ʱ�ﵽ��n��0.2��(����:20*0.2=4)�ͻᴥ������!serviceName=unionbrokerscf������unionbrokerscf������!
����,���ǾͿ�������jmeter�IJ�������,����:����ͼ
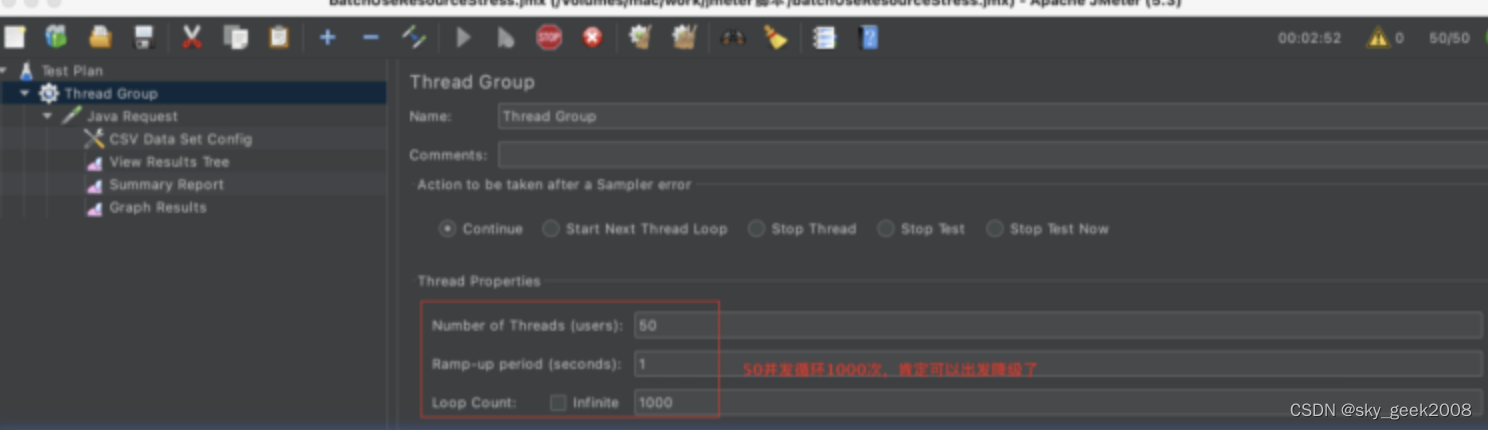
��ע:��ͬ����Ľ���������ע�����value����һ��,������Բ�ͬ����Ľ���,��ӦӰ��ӿڵ�ѹ��ű�Ҳ��ͬ!�м���ߣ����,��д�ű�,��������(��ѷ�������)!
8����ôȷ���Ƿ�����?���ǿ���ͨ����־�(ǰ���ÿ������ϴ�����������־)
[work(work)@tjtxcs99-11-22 AAAAAAA]$ grep ���� * | wc -l
4345
ֵ��һ�����:���ϻ��������ԶԱ��н�����û�����������������/�������仯����,��ȷ�Ͻ�����Ч���Ƿ�ﵽԤ��!
����,���Ǿ�����˻���sentinel�ij�ʱ�����쳣����!
- �ܽ���չ��
��֮,�����쳣����Ҳ�dz��γ���,Ŀǰ�������쳣����(�ֹ�����)���DZȽϵ�һ�ġ�
-
������������
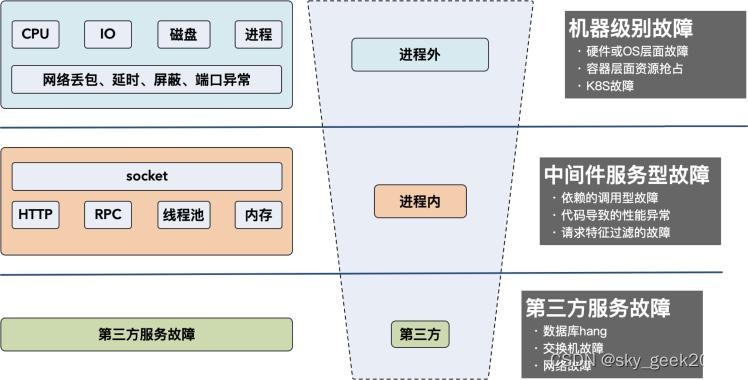
-
�������ϻ���
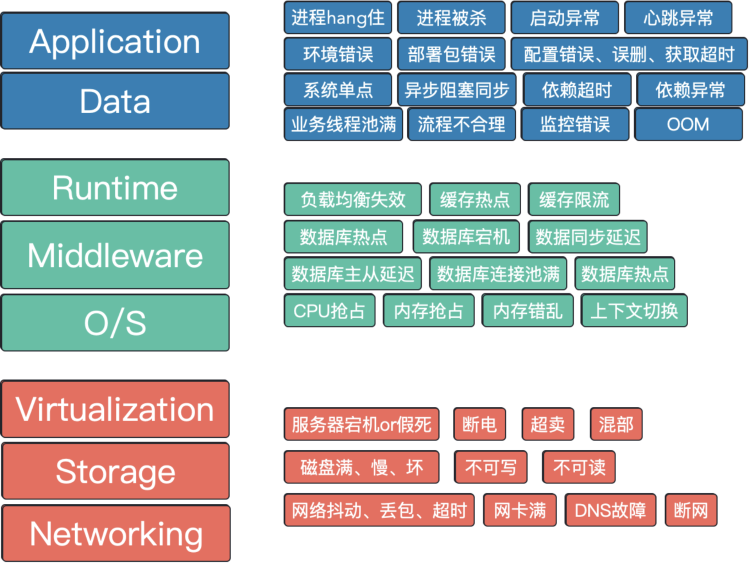
-
δ�����ǻ��кܳ���·Ҫ��,����Ҫ�˷�����(������������):
1����ģ����������,�����ڲ��Ի������쳣������ʱ��ȷ�Խϵ�;
2���������͵��쳣���ڲ��Ի���ȫ��ģ��;
3��������7*24Сʱ�ڲ�ͬ�����²�ͬʱ��ε��쳣����;
4����ģ�������η����쳣,ֻ����Ա���������쳣����;
5���ֹ����ԺķѾ�������ɱ�,��Ͷ������ȿ��ܽϵ�;
6������

