�����ǻ����ļ�ת���;ۺ�,���ǻ��ڴ��ڵļ���,���Ƕ������һ�����ϵ����ݽ��д����ġ�����ʵ��Ӧ����,������Ҫ����ͬ��Դ���������Ӻϲ���һ����,Ҳ�п�����Ҫ��һ������ֿ�,���Ծ������жԶ��������д����ij������������Ǿ������� Flink �жԶ���������ת���IJ�����
���ֵĻ�,����ת�����Է�Ϊ���������͡������������ࡣĿǰ�����IJ���һ����ͨ���������(side output)��ʵ��,�����������ӱȽϷḻ,���ݲ�ͬ��������Ե��� union��connect��join �Լ� coGroup �Ƚӿڽ������Ӻϲ��������������Ǿͽ��о���Ľ��⡣
����
��ν��������,���ǽ�һ����������ֳ���ȫ������������������������Ҳ���ǻ���һ��DataStream,�õ���ȫƽ�ȵĶ���� DataStream,
һ����˵,���ǻᶨ��һЩɸѡ����,���������������ݼ�ѡ�����ŵ���Ӧ�����
��ʵ��������ɸѡ���ݵ�����,�����dz�����ʵ��:ֻҪ���ͬһ������ζ�������.filter()��������ɸѡ,�Ϳ��Եõ����֮������ˡ�
����,���ǿ��Խ�������վ�ռ������û���Ϊ���ݽ���һ�����,��������(type)�IJ�ͬ,��Ϊ��Mary����������ݡ���Bob����������ݵȵȡ���ô����Ϳ�������ʵ��:
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource());
// ɸѡ Mary �������Ϊ���� MaryStream ����
DataStream<Event> MaryStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Mary");
}
});
// ɸѡ Bob �Ĺ�����Ϊ���� BobStream ����
DataStream<Event> BobStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Bob");
}
});
// ɸѡ�����˵������Ϊ���� elseStream ����
DataStream<Event> elseStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return !value.user.equals("Mary") && !value.user.equals("Bob");
}
});
MaryStream.print("Mary pv");
BobStream.print("Bob pv");
elseStream.print("else pv");
env.execute();
}
}
��������:
Bob pv> Event{user='Bob', url='./home', timestamp=2021-06-23 17:30:57.388}
else pv> Event{user='Alice', url='./home', timestamp=2021-06-23 17:30:58.399}
else pv> Event{user='Alice', url='./home', timestamp=2021-06-23 17:30:59.409}
Bob pv> Event{user='Bob', url='./home', timestamp=2021-06-23 17:31:00.424}
else pv> Event{user='Alice', url='./prod?id=1', timestamp=2021-06-23 17:31:01.441}
else pv> Event{user='Alice', url='./prod?id=1', timestamp=2021-06-23 17:31:02.449}
Mary pv> Event{user='Mary', url='./home', timestamp=2021-06-23 17:31:03.465}
����ʵ�ַdz���,�������Ե���Щ���ࡪ�����ǵĴ������Բ�ֳ�����������ʵ��һ����,ȴ�ظ�д�����Ρ�������δ��뱳��ĺ���,�ǽ�ԭʼ������ stream ��������,Ȼ���ÿһ�ݷֱ���ɸѡ;�������Dz�����Ч�ġ�������Ȼ�뵽,�ܲ��ܲ��ø�����,ֱ����һ�����ӾͰ����Ƕ���ֿ���?
�����ڵİ汾��,DataStream API ���ṩ��һ��.split()����,ר��������һ�������з֡��ɶ�������Ļ���˼·��ʵ���ǰ��ո�����ɸѡ����,�����ݷ��ࡰ�Ǵ���;Ȼ����������Ǵ�֮�����,�ֱ��ѡ��Ҫ�ġ������Ϳ��Եõ���ֺ�������������ǾͲ����ٶ������и����ˡ��������ַ�����һ��ȱ��:��Ϊֻ�ǡ��Ǵ�����ѡ,�����������ݽ���ת��,��������������ͱ����ԭʼ������һ�¡���ͼ���������˷���������Ӧ�ó��������� split �����Ѿ���̭����,�����Ժ����ֻʹ������Ҫ���IJ��������
�������
�� Flink 1.13 �汾��,�Ѿ�������.split()����,ȡ����֮����ֱ���ô�������(process function)�IJ������(side output)��
����֪��,������������������Ϊ��һ��ת������,������������ǵ�һ��,����֮��õ�����Ȼ��һ�� DataStream;�����������������,���������Զ����������,���Ǿ���ӡ��������Ϸֲ���ġ�֧���������ܿ�����������֧����������,����ʵ�������Ƕ���ij�����͵� DataStream,���Ա����ϻ���ƽ�ȵġ����ò�������Ϳ��Ժܷ����ʵ�ַ�������,���ҵõ��Ķ��� DataStream ���Ϳ��Բ�ͬ,������ǵ�Ӧ�ô����˼���ı�����
���ڴ��������в���������÷�,�����Ѿ��� 7.5 ��������ϸ���ܡ�����˵,ֻ��Ҫ���������� ctx ��.output()����,�Ϳ�������������͵������ˡ�����������ı�Ǻ���ȡ,���벻��һ���������ǩ��(OutputTag),�����൱�� split()����ʱ�ġ�����,ָ���˲��������id �����͡�
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class SplitStreamByOutputTag {
// ���������ǩ,�����������������Ϊ��Ԫ��(user, url, timestamp)
private static OutputTag<Tuple3<String, String, Long>> MaryTag = new OutputTag<Tuple3<String, String, Long>>("Mary-pv") {};
private static OutputTag<Tuple3<String, String, Long>> BobTag = new OutputTag<Tuple3<String, String, Long>>("Bob-pv") {};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource());
SingleOutputStreamOperator<Event> processedStream = stream.process(new ProcessFunction<Event, Event>() {
@Override
public void processElement(Event value, Context ctx, Collector<Event> out) throws Exception {
if (value.user.equals("Mary")) {
ctx.output(MaryTag, new Tuple3<>(value.user, value.url, value.timestamp));
} else if (value.user.equals("Bob")) {
ctx.output(BobTag, new Tuple3<>(value.user, value.url, value.timestamp));
} else {
out.collect(value);
}
}
});
processedStream.getSideOutput(MaryTag).print("Mary pv");
processedStream.getSideOutput(BobTag).print("Bob pv");
processedStream.print("else");
env.execute();
}
}
��������:
Bob pv> (Bob,./prod?id=1,1624442886645)
Mary pv> (Mary,./prod?id=1,1624442887664)
Bob pv> (Bob,./home,1624442888673)
Mary pv> (Mary,./prod?id=1,1624442889676)
else> Event{user='Alice', url='./prod?id=1', timestamp=2021-06-23 18:08:10.693}
else> Event{user='Alice', url='./prod?id=1', timestamp=2021-06-23 18:08:11.697}
else> Event{user='Alice', url='./prod?id=1', timestamp=2021-06-23 18:08:12.702}
Mary pv> (Mary,./cart,1624442893705)
Bob pv> (Bob,./cart,1624442894710)
else> Event{user='Alice', url='./cart', timestamp=2021-06-23 18:08:15.722}
Mary pv> (Mary,./prod?id=1,1624442896725)
�������Ƕ����������������,�ֱ��ѡ Mary ������¼��� Bob ������¼�;���������Ѿ�ȷ��,���ǿ���ֻ����(�û� id, url, ʱ���)����һ����Ԫ�顣��ʣ����¼���ֱ�����������,������Ȼ���� Event,���൱��֮ǰ�� elseStream��������ʵ�ַ�ʽ��Ȼ�����,Ҳ������
����
��Ȼһ�������Էֿ�,��Ȼ�������Ϳ��Ժϲ�����ʵ��Ӧ����,���Ǿ�����������Դ��ͬ�Ķ�����,��Ҫ�����ǵ����ݽ������ϴ��������� Flink �к����IJ���������ձ�,��Ӧ��API Ҳ���ӷḻ��
����(Union)
��ĺ�������,����ֱ�ӽ�����������һ��,�������ġ����ϡ�(union),���ϲ���Ҫ��������е��������ͱ�����ͬ,�ϲ�֮�������������������е�Ԫ��,�������Ͳ��䡣���ֺ�����ʽ�dz��ֱ�,����·�϶����������һ��һ����
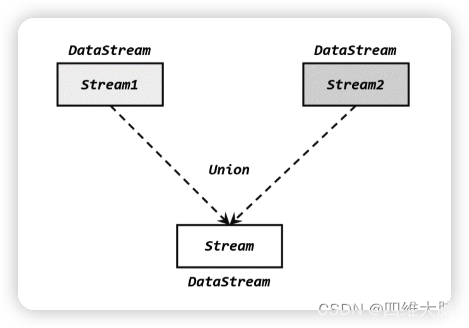
�ڴ�����,����ֻҪ���� DataStream ֱ�ӵ���.union()����,�������� DataStream ��Ϊ����,�Ϳ���ʵ������������;�õ�����Ȼ��һ�� DataStream:
stream1.union(stream2, stream3, ...)
ע��:union()�IJ��������Ƕ�� DataStream,�������ϲ�������ʵ�ֶ������ĺϲ���
������Ҫ����һ�����⡣���¼�ʱ��������,ˮλ����ʱ��Ľ��ȱ�־;��ͬ�����п���ˮλ�ߵĽ�չ������ȫ��ͬ,������Ǻϲ���һ��,ˮλ���ָ����ĸ�Ϊ��?
����Ҫ����ˮλ�ߵı��ʺ���,�ǡ�֮ǰ�����������Ѿ������ˡ�;���Զ��ں���֮���ˮλ��,Ҳ��Ҫ����С���Ǹ�Ϊ,�����ſ��Ա�֤�������������ٴ���֮ǰ�����ݡ����仰˵,�����ϲ�ʱ������ʱЧ�������������Ǹ���Ϊ�ġ�������Ȼ�����뵽,����֮ǰ���ܵIJ�������ˮλ�ߴ��ݵĹ�������ȫһ�µ�;�������ĺϲ�,ij��������Ҳ���Կ����Ƕ������������ͬһ�����������ϵĹ��̡�
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class UnionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream1 = env.socketTextStream("localhost", 7777)
.map(data -> {
String[] field = data.split(",");
return new Event(field[0].trim(), field[1].trim(), Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream1.print("stream1");
SingleOutputStreamOperator<Event> stream2 = env.socketTextStream("localhost", 7777)
.map(data -> {
String[] field = data.split(",");
return new Event(field[0].trim(), field[1].trim(), Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream2.print("stream2");
// �ϲ�������
stream1.union(stream2)
.process(new ProcessFunction<Event, String>() {
@Override
public void processElement(Event value, Context ctx, Collector<String> out) throws Exception {
out.collect(" ˮ λ �� : " + ctx.timerService().currentWatermark());
}
}).print();
env.execute();
}
}
����Ϊ�˸������ؿ���ˮλ�ߵĽ�չ,���Ǵ���������������ȡ socket �ı�����,������������ȡʱ�����Ϊ����ˮλ�ߵ����ݡ��� union ���������ϲ���,��һ�� ProcessFunction�����д���,��ȡ��ǰ��ˮλ�߽�����������ǻᷢ����������ÿ����һ������,�ϲ�֮������ж��������ݳ���;��ˮλ��ֻ������������ˮλ����Сֵ�����ʱ��,�Ż�������ǰ�ƽ���
�ں���֮��� ProcessFunction ��Ӧ������������,��ʱ�ӵij�ʼ״̬��ͼ��ʾ
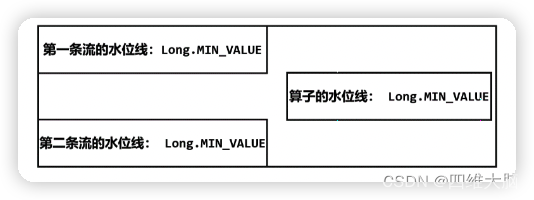
���� Flink �������Ŀ�ʼ��,����һ���������(Long.MIN_VALUE)��ˮλ��,���Ժ������ ProcessFunction ��Ӧ�Ĵ�������,��Ϊ�ϲ���ÿ��������һ��������ˮλ�ߡ�,��ʼֵ���� Long.MIN_VALUE;����ʱ���������ˮλ�������з���ˮλ�ߵ���Сֵ,���Ҳ��Long.MIN_VALUE��
�����ڵ�һ�� socket �ı�����������[Alice, ./home, 1000] ʱ,ˮλ�߲��������ı�,ֻ�е�ˮλ���������ڵ�ʱ���(200ms һ��)�Ż��ƽ��� 1000 - 1 = 999 ����;���������ڶ��¼�ʱ�䶨ʱ���IJ�����һ�µġ�������ʹ��һ��ˮλ���ƽ����� 999,������һ����û�б仯,���Ժ���֮��� Process ����ˮλ����Ȼ�dz�ʼֵ��
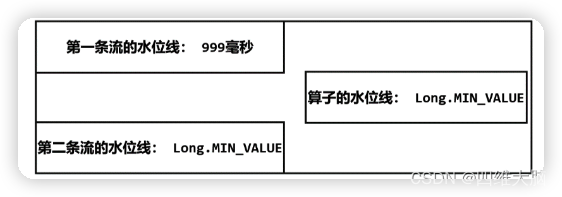
�����ʱ�����ڵڶ��� socket �ı�����������[Alice, ./home, 2000],��ô�ڶ�������ˮλ����֮�ƽ��� 2000 �C 1 = 1999 ����,Process ����������ĵڶ���������ˮλ�߸���Ϊ 1999;������������ˮλ��ȡ��Сֵ,Process �����ˮλ��Ҳ�Ϳ����ƽ��� 999 �ˡ�
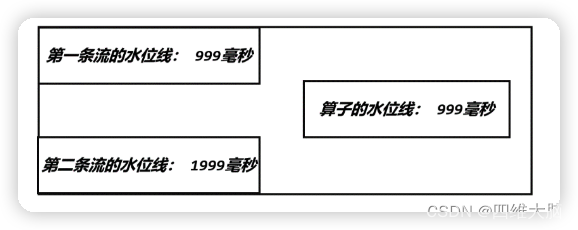
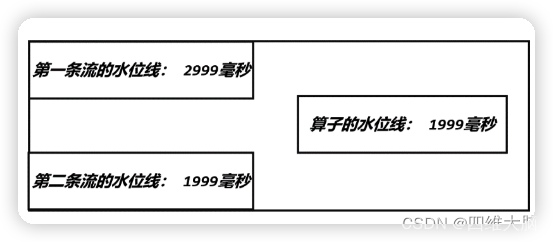
����������Ǽ����ڵ�һ��������������[Alice, ./home, 3000],Process ����ĵ�һ��������ˮλ�߾ͻ����Ϊ 2999,ͬʱ�����������ʱ���ƽ��� 1999��
����(Connect)
����������Ȼ��,�����������������Ͳ��ܸı�,����Դ���ۿ�,����ʵ��Ӧ�ý��ٳ��֡���������(union),Flink ���ṩ������һ�ַ���ĺ���������������(connect)������˼��,���ֲ�������ֱ�Ӱ������������һ���Խ�������
1. ������(ConnectedStreams)
Ϊ�˴����������,���Ӳ������������������Ͳ�ͬ��������֪��һ�� DataStream �е�����ֻ����Ψһ������,�������ӵõ��IJ����� DataStream,����һ������������(ConnectedStreams)�����������Կ�������������ʽ�ϵġ�ͳһ��,��������һ��ͬһ������;��ʵ���ڲ��Ա��ָ��Ե�������ʽ����,�˴�֮����������ġ�Ҫ��õ��µ� DataStream,����Ҫ��һ������һ����ͬ������(co-process)ת������,����˵�����ڲ�ͬ��Դ����ͬ���͵�����,�����ֱ���д���ת�����õ�ͳһ��������͡�������������,�����������Ӿ����ǡ�һ�����ơ�,���������Ա��ָ��Ե��������͡�������ʽҲ���Բ�ͬ,�������ջ��ǻ�ͳһ��ͬһ�� DataStream ��
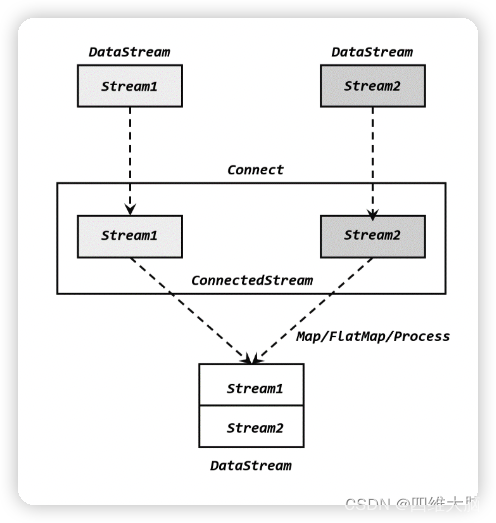
�ڴ���ʵ����,��Ҫ��Ϊ����:���Ȼ���һ�� DataStream ����.connect()����,��������һ�� DataStream ��Ϊ����,����������������,�õ�һ�� ConnectedStreams;Ȼ���ٵ���ͬ���������õ� DataStream��������Եĵ��õ�ͬ����������.map()/.flatMap(),�Լ�.process()������
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class CoMapExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<Integer> stream1 = env.fromElements(1, 2, 3);
DataStream<Long> stream2 = env.fromElements(1L, 2L, 3L);
ConnectedStreams<Integer, Long> connectedStreams = stream1.connect(stream2);
SingleOutputStreamOperator<String> result = connectedStreams.map(new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer value) {
return "Integer: " + value;
}
@Override
public String map2(Long value) {
return "Long: " + value;
}
});
result.print();
env.execute();
}
}
������:
Integer: 1
Integer: 2
Integer: 3
Long: 1
Long: 2
Long: 3
����Ĵ�����,ConnectedStreams ���������Ͳ���,�ֱ��ʾ�ڲ����������������Ե���������;������Ҫ��һ�����ơ�,��˵���.map()����ʱ����IJ�����һ���� MapFunction,����һ�� CoMapFunction,��ʾ�ֱ���������е�����ִ�� map ����������ӿ����������Ͳ���,���α�ʾ��һ�������ڶ�����,�Լ��ϲ�������е��������͡���Ҫʵ�ֵķ���Ҳ�dz�ֱ��:.map1()���ǶԵ�һ���������ݵ� map ����,.map2()������Եڶ��������������ǽ�һ�� Integer ����һ�� Long ���ϲ�,ת���� String ��������Ե�������һ�������������ֵʱ,����.map1();�������ڶ���������ij���������ʱ,����.map2():���ն�ת��Ϊ�ַ������,�ϲ�����һ���ַ�������
ֵ��һ�����,ConnectedStreams Ҳ����ֱ�ӵ���.keyBy()���а��������IJ���,�õ��Ļ���һ�� ConnectedStreams:
connectedStreams.keyBy(keySelector1, keySelector2);
���ﴫ���������� keySelector1 �� keySelector2,���������и��Եļ�ѡ����;��ȻҲ����ֱ�Ӵ������λ��ֵ(keyPosition),�������ֶ���(field),������ͨ�� keyBy �÷���ȫһ�¡�ConnectedStreams ���� keyBy ����,��ʵ���ǰ��������� key ��ͬ�����ݷŵ���һ��,Ȼ�������Դ�����������Դ���,����һЩ�����·dz����á�����,����Ҳ�����ںϲ�֮ǰ�ͽ��������ֱ���� keyBy,�õ��� KeyedStream �ٽ�������(connect)����,Ч����һ���ġ�Ҫע������������ļ������ͱ�����ͬ,������׳��쳣��
������������(connect),������(union)�������,�������ƾ��ǿ��Դ�����ͬ���͵����ĺϲ�,ʹ�ø���Ӧ�ø��㷺����Ȼ��Ҳ������,���Ǻϲ���������ֻ���� 2,�� union����ͬʱ���ж������ĺϲ�����Ҳ�dz���������:union ���������Ͳ���,����ֱ�Ӻϲ�û������;�� connect �ǡ�һ�����ơ�,���������Ľӿ�ֻ����������ת������,�����չ��Ҫ���¶���ӿ�,���Բ��ܡ�һ�����ơ�
2. CoProcessFunction
���������� ConnectedStreams �Ĵ�������,��Ҫ�ֱ�����������Ĵ���ת��,��˽ӿ��оͻ���������ͬ�ķ�����Ҫʵ��,�����֡�1����2������,���������е����ݵ���ʱ�ֱ���á����ǰ����ֽӿڽ�����Эͬ����������(co-process function)���� CoMapFunction ����,����ǵ���.flatMap()����Ҫ����һ�� CoFlatMapFunction,��Ҫʵ�� flatMap1()��flatMap2()��������;������.process()ʱ,���������һ�� CoProcessFunction��
public abstract class CoProcessFunction<IN1, IN2, OUT> extends AbstractRichFunction {
...
public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;
public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception {}
public abstract class Context {...}
...
}
���ǿ��Կ���,������ CoProcessFunction Ҳ�ǡ����������������е�һԱ,�÷��dz����ơ�����Ҫʵ�ֵľ��� processElement1()��processElement2()��������,��ÿ�����ݵ���ʱ,�������Դ�����������е�һ���������д�����CoProcessFunction ͬ������ͨ�������� ctx ������ timestamp��ˮλ��,��ͨ�� TimerService ע�ᶨʱ��;����Ҳ�ṩ��.onTimer()����,���ڶ��嶨ʱ�����Ĵ���������
������ CoProcessFunction ��һ������ʾ��:���ǿ���ʵ��һ��ʵʱ���˵�����,Ҳ����app ��֧�������͵�������֧��������һ��˫�� Join��App ��֧���¼��͵�������֧���¼����ụ��ȴ� 5 ����,����Ȳ�����Ӧ��֧���¼�,��ô�����������Ϣ��
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
// ʵʱ����
public class BillCheckExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// ���� app ��֧����־
SingleOutputStreamOperator<Tuple3<String, String, Long>> appStream = env.fromElements(
Tuple3.of("order-1", "app", 1000L),
Tuple3.of("order-2", "app", 2000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
})
);
// ���Ե�����֧��ƽ̨��֧����־
SingleOutputStreamOperator<Tuple4<String, String, String, Long>> thirdpartStream = env.fromElements(
Tuple4.of("order-1", "third-party", "success", 3000L),
Tuple4.of("order-3", "third-party", "success", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple4<String, String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple4<String, String, String, Long>>() {
@Override
public long extractTimestamp(Tuple4<String, String, String, Long> element, long recordTimestamp) {
return element.f3;
}
})
);
// ���ͬһ֧���������������Ƿ�ƥ��,��ƥ��ͱ���
appStream.connect(thirdpartStream)
.keyBy(data -> data.f0, data -> data.f0)
.process(new OrderMatchResult())
.print();
env.execute();
}
// �Զ���ʵ�� CoProcessFunction
public static class OrderMatchResult extends CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String> {
// ����״̬����,���������Ѿ�������¼�
private ValueState<Tuple3<String, String, Long>> appEventState;
private ValueState<Tuple4<String, String, String, Long>> thirdPartyEventState;
@Override
public void open(Configuration parameters) throws Exception {
appEventState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple3<String, String, Long>>("app-event", Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)));
thirdPartyEventState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple4<String, String, String, Long>>("thirdparty-event", Types.TUPLE(Types.STRING, Types.STRING, Types.STRING, Types.LONG)));
}
@Override
public void processElement1(Tuple3<String, String, Long> value, Context ctx, Collector<String> out) throws Exception {
// ����һ�������¼��Ƿ�����
if (thirdPartyEventState.value() != null) {
out.collect(" �� �� �� �� : " + value + " " + thirdPartyEventState.value());
// ���״̬
thirdPartyEventState.clear();
} else {
// ����״̬
appEventState.update(value);
// ע��һ�� 5 ���Ķ�ʱ��,��ʼ�ȴ���һ�������¼�
ctx.timerService().registerEventTimeTimer(value.f2 + 5000L);
}
}
@Override
public void processElement2(Tuple4<String, String, String, Long> value, Context ctx, Collector<String> out) throws Exception {
if (appEventState.value() != null) {
out.collect("���˳ɹ�:" + appEventState.value() + " " + value);
// ���״̬
appEventState.clear();
} else {
// ����״̬
thirdPartyEventState.update(value);
// ע��һ�� 5 ���Ķ�ʱ��,��ʼ�ȴ���һ�������¼�
ctx.timerService().registerEventTimeTimer(value.f3 + 5000L);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// ��ʱ������,�ж�״̬,���ij��״̬��Ϊ��,˵����һ�������¼�û��
if (appEventState.value() != null) {
out.collect("����ʧ��:" + appEventState.value() + " " + "������֧�� ƽ̨��Ϣδ��");
}
if (thirdPartyEventState.value() != null) {
out.collect("����ʧ��:" + thirdPartyEventState.value() + " " + "app ��Ϣδ��");
}
appEventState.clear();
thirdPartyEventState.clear();
}
}
}
��������:
���˳ɹ�:(order-1,app,1000) (order-1,third-party,success,3000)
����ʧ��:(order-2,app,2000) ������֧��ƽ̨��Ϣδ��
����ʧ��:(order-3,third-party,success,4000) app ��Ϣδ��
�ڳ�����,��������������״̬�����ֱ��������� App ��֧����Ϣ�͵�������֧����Ϣ��App ��֧����Ϣ�����Ժ�,�����Ӧ�ĵ�����֧����Ϣ�Ƿ��Ѿ��ȵ���(�ȵ���ᱣ���ڶ�Ӧ��״̬������),����Ѿ�������,��ô���˳ɹ�,ֱ��������˳ɹ�����Ϣ,�������������֧����Ϣ��״̬������ա���� App ��Ӧ�ĵ�����֧����Ϣû�е���,��ô���ǻ�ע��һ�� 5 ����֮��Ķ�ʱ��,Ҳ����˵�ȴ�������֧���¼� 5 ���ӡ�����ʱ������ʱ,��鱣��app ֧����Ϣ��״̬�����Ƿ���,�������,˵����Ӧ�ĵ�����֧����Ϣû�е���,�������������Ϣ��
3. �㲥������(BroadcastConnectedStream)
����������������,����һ�ֱȽ�������÷�:DataStream ����.connect()����ʱ,����IJ���Ҳ���Բ���һ�� DataStream,����һ�����㲥����(BroadcastStream),��ʱ�ϲ��������õ��ľͱ����һ�����㲥��������(BroadcastConnectedStream)��
�������ӷ�ʽ����������Ҫ��̬����ijЩ��������õij�������Ϊ������ʵʱ�䶯��,�������ǿ�����һ��������������ȡ��������;����Щ����������Ƕ�����Ӧ��ȫ����Ч��,���Բ���ֻ�������ݴ��ݸ�һ�����β�����������,����Ҫ���㲥��(broadcast)�����еIJ��������������������յ��㲥�����Ĺ���,����������һ��״̬,�������ν�ġ��㲥״̬��(broadcast state)��
�㲥״̬�ײ�����һ����ӳ�䡱(map)�ṹ������ġ��ڴ���ʵ����,����ֱ�ӵ���DataStream ��.broadcast()����,����һ����ӳ��״̬��������(MapStateDescriptor)˵��״̬�����ƺ�����,�Ϳ��Եõ��������ݵġ��㲥����(BroadcastStream):
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
���������ǾͿ��Խ�Ҫ������������,�������㲥����������(connect),�õ��ľ�����ν�ġ��㲥��������(BroadcastConnectedStream)������ BroadcastConnectedStream ����.process()����,�Ϳ���ͬʱ��ȡ���������,���ж�̬�����ˡ�
�����Ȼ������.process()����,��Ȼ����IJ���ҲӦ���Ǵ��������������һԱ������������������ù� keyBy �����˰�������,��ôҪ����ľ��� KeyedBroadcastProcessFunction;���û�а�������,�ʹ��� BroadcastProcessFunction��
DataStream<String> output = stream
.connect(ruleBroadcastStream)
.process( new BroadcastProcessFunction<>() {...} );
BroadcastProcessFunction �� CoProcessFunction ����,ͬ����һ��������,��Ҫʵ����������,��Ժϲ�����������Ԫ�طֱ��崦��������������������һ������������������,����һ��������Ҫ���¹��������¹㲥״̬,���Զ�Ӧ��������������.processElement()��.processBroadcastElement()��Դ���ж�������:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
...
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
...
}
����ʱ��ĺ�������˫������(Join)
�����������ĺϲ�,�ܶ�������Dz����Ǽؽ��������ݷ���һ��,����ϣ������ij���ֶε�ֵ��������������,����ԡ�ȥ�������������ô�������ػ���ʱ,������Ҫ�������¶ȴ������������������ɼ�������Ϣ,���մ����� ID ���顢�ٽ������������ݺϲ�����,���ͬʱ�����趨��ֵ��Ҫ������
���Ƿ���,�����������ϵ�����ݿ��б��� join �����dz��������ʵ��,Flink ���������� connect ����,�Ϳ���ͨ�� keyBy ָ�������з����ϲ�,ʵ���������� SQL �е� join ����;���� connect ֧�ִ�������,����ʹ���Զ���״̬�� TimerService ���ʵ�ָ�������,��ʵ�Ѿ��ܹ�����˫���ϲ��Ĵ����������
�������������ǵײ�ӿ�,���Ծ��� connect �����������,����һЩ����Ӧ�ó����»����Ե�̫�������ˡ�����,�������ϣ��ͳ�ƹ̶�ʱ�������������ݵ�ƥ�����,�Ǿ���Ҫ���ö�ʱ�����Զ��崥������ʵ�֡�����ʵ����ȫ�����ô���(window)����ʾ��Ϊ�˸������ʵ�ֻ���ʱ��ĺ�������,Flink �� DataStrema API �ṩ���������õ� join ����,�Լ�coGroup ���ӡ��������Ǿ�����һ����ϸ�Ľ��⡣
ע:SQL �� join һ��ᷭ��Ϊ�����ӡ�;��������Ϊ�����ֲ�ͬ������,һ��ĺ�������connect ����Ϊ�����ӡ�,���� join ����Ϊ�����ᡱ��
��������(Window Join)
����ʱ��IJ���,������ĵ�Ȼ����ʱ�䴰���ˡ�����֮ǰ�Ѿ����ܹ� Window API ���÷�,��Ҫ����Ե�һ��������ijЩʱ����ڵĴ������㡣���������ϣ���������������ݽ��кϲ�����ͬ�����ij��ʱ����д�����ͳ��,�ָ���ô����?
Flink Ϊ���ֳ���ר���ṩ��һ����������(window join)����,���Զ���ʱ�䴰��,�����������й���һ��������(key)�����ݷ��ڴ����н�����Դ�����
-
��������ĵ���
���������ڴ����е�ʵ��,������Ҫ���� DataStream ��.join()�������ϲ�������,�õ�һ�� JoinedStreams;����ͨ��.where()��.equalTo()����ָ��������������� key;Ȼ��ͨ��.window()������,������.apply()�������ᴰ�ں������д������㡣ͨ�õ�����ʽ����:
stream1.join(stream2) .where(<KeySelector>) .equalTo(<KeySelector>) .window(<WindowAssigner>) .apply(<JoinFunction>)���������.where()�IJ����Ǽ�ѡ����(KeySelector),����ָ����һ�����е� key; ��.equalTo()����� KeySelector ��ָ���˵ڶ������е� key��������ͬ��Ԫ��,�����ͬһ������,�Ϳ���ƥ������,��ͨ��һ�������ắ����(JoinFunction)���д����ˡ�
����.window()����ľ��Ǵ��ڷ�����,֮ǰ����������ʱ�䴰�ڶ�������������:��������(tumbling window)����������(sliding window)�ͻỰ����(session window)��
���������.apply()���Կ���ʵ����һ������Ĵ��ں�����ע������ֻ�ܵ���.apply(),û����������ķ�����
����� JoinFunction Ҳ��һ��������ӿ�,ʹ��ʱ��Ҫʵ���ڲ���.join()�����������������������,�ֱ��ʾ�������гɶ�ƥ������ݡ�JoinFunction ��Դ���еĶ�������:
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable { OUT join(IN1 first, IN2 second) throws Exception; }������Ҫע��,JoinFunciton �����������ġ����ں�����,��ֻ�Ƕ����˴��ں����ڵ���ʱ��ƥ�����ݵľ��崦������
��Ȼ,��Ȼ�Ǵ��ڼ���,��.window()��.apply()֮��Ҳ���Ե��ÿ�ѡ API ȥ��һЩ�Զ���,������.trigger()���崥����,��.allowedLateness()���������ӳ�ʱ��,�ȵȡ�
2. ��������Ĵ�������
JoinFunction �е���������,�ֱ�������������е�ƥ������ݡ�����ͻ���һ������:ʲôʱ��ͻ�ƥ�������,����.join()������?���������Ǿ�������һ�´��� join �ľ��崦�����̡�
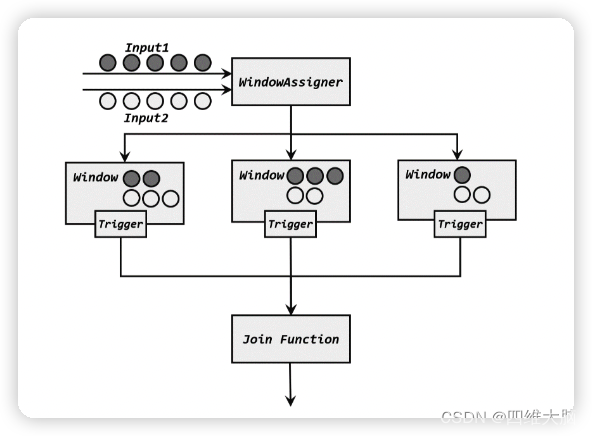
�����������ݵ���֮��,���Ȼᰴ�� key ���顢�����Ӧ�Ĵ����д洢;�����ﴰ�ڽ���ʱ��ʱ,���ӻ���ͳ�Ƴ������������������ݵ��������,Ҳ���Ƕ��������е�������һ���ѿ�����(�൱�ڱ��Ľ�������,cross join),Ȼ����б���,��ÿһ��ƥ�������,��Ϊ����(first,second)���� JoinFunction ��.join()�������м��㴦��,�õ��Ľ��ֱ�������ͼ��ʾ�����Դ�����ÿ��һ�����ݳɹ�����ƥ��,JoinFunction ��.join()�����ͻᱻ����һ��,�����һ�������
���� JoinFunction,��.apply()�����л����Դ��� FlatJoinFunction,�÷��dz�����,ֻ���ڲ���Ҫʵ�ֵ�.join()����û�з���ֵ������������ͨ���ռ���(Collector)��ʵ�ֵ�,���Զ���һ��ƥ�����ݿ�����������������
��ʵ��ϸ�۲���Է���,���� join �ĵ������������Ϥ�� SQL �б��� join �dz�����:
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
��� SQL �� where �Ӿ�ı���,�ȼ��� inner join �� on,���Ա�����ʾ�������ű����� id�ġ������ӡ�(inner join)���� Flink �е� window join,ͬ�������� inner join��Ҳ����˵,����������,ֻ�������������ݰ� key ��Գɹ�����Щ;���ij��������һ����������û���κ���һ����������ƥ��,��ô�Ͳ������ JoinFunction ��.join()����,Ҳ��û���κ�����ˡ�
3. ��������ʵ��
�ڵ�����վ��,������Ҫͳ���û���ͬ��Ϊ֮���ת��,�����Ҫ�Բ�ͬ����Ϊ������,�����û� ID ���з�����ٺϲ�,�Է�������֮��Ĺ����������Щ���Թ̶�ʱ������(����1 Сʱ)��ͳ�Ƶ�,�����ǾͿ���ʹ�ô��� join ��ʵ������������
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
// ���ڴ��ڵ� join
public class WindowJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
);
DataStream<Tuple2<String, Long>> stream2 = env.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
stream1
.join(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
})
.print();
env.execute();
}
}
������:
(a,1000)=>(a,3000)
(a,1000)=>(a,4000)
(a,2000)=>(a,3000)
(a,2000)=>(a,4000)
(b,1000)=>(b,3000)
(b,1000)=>(b,4000)
(b,2000)=>(b,3000)
(b,2000)=>(b,4000)
�������(Interval Join)
����Щ������,����Ҫ������ʱ�������ܲ����ǹ̶��ġ�����,�ڽ���ϵͳ��,��Ҫʵʱ�ض�ÿһ�ʽ����к���,��֤�����˻�ת��ת���������,Ҳ������ν�ġ�ʵʱ���ˡ�������ת�˵����ݿ���д���˲�ͬ����־��,���ǵ�ʱ���Ӧ������,�������ǿ��Կ���ֻ
ͳ��һ��ʱ�����Ƿ��г������˵�����ƥ�䡣��ʱ��Ȼ��Ӧ���ù������ڻ������������� ����Ϊƥ������������п��ܸպá����ڡ����ڱ�Ե����,���Ǵ����ھͶ�û��ƥ����;�Ự������Ȼʱ�䲻�̶�,��Ҳ���Բ��ʺ���������� ����ʱ��Ĵ��������Ѿ�����Ϊ���ˡ�
Ϊ��Ӧ������������,Flink �ṩ��һ�ֽ�����������ᡱ(interval join)�ĺ�������������˼��,��������˼·�������һ������ÿ������,���ٳ���ʱ���ǰ���һ��ʱ����,�����ڼ��Ƿ���������һ����������ƥ�䡣
1. ��������ԭ��
����������Ķ��巽ʽ��,���Ǹ�������ʱ���,�ֱ��������ġ��Ͻ硱(upperBound)�͡��½硱(lowerBound);���Ƕ���һ����(�������� A)�е�����һ������Ԫ�� a,�Ϳ��Կ���һ��ʱ����:[a.timestamp + lowerBound, a.timestamp + upperBound],���� a ��ʱ���Ϊ����,�����½�㡢�����Ͻ���һ��������:���ǾͰ����ʱ����Ϊ����ƥ����һ�������ݵġ����ڡ���Χ�����Զ�����һ����(������ B)�е�����Ԫ�� b,�������ʱ���������������䷶Χ��,a �� b �Ϳ��Գɹ����,�������м���������������ƥ�������Ϊ:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
������Ҫע��,���������������� A �� B,Ҳ���������ͬ�� key;�½� lowerBoundӦ��С�ڵ����Ͻ� upperBound,���߶������ɸ�;�������Ŀǰֻ֧���¼�ʱ�����塣
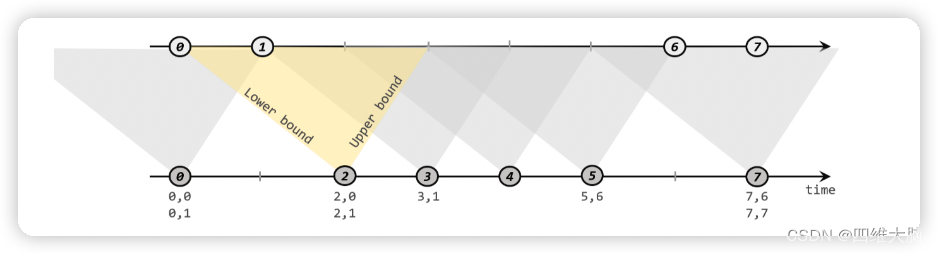
�·����� A ȥ��������Ϸ����� B,���Ի��� A ��ÿ������Ԫ��,�����Կ���һ��������䡣�������������½�Ϊ-2 ����,�Ͻ�Ϊ 1 ���롣���Ƕ���ʱ���Ϊ 2 �� A ��Ԫ��,���Ŀ�ƥ���������[0, 3],�� B ����ʱ���Ϊ 0��1 ������Ԫ�����������Χ��,���ԾͿ��Եõ�ƥ�����ݶ�(2, 0)��(2, 1)��ͬ����,A ��ʱ���Ϊ 3 ��Ԫ��,��ƥ������Ϊ[1, 4],B ��ֻ��ʱ���Ϊ 1 ��һ�����ݿ���ƥ��,���ǵõ�ƥ�����ݶ�(3, 1)��
�������ǿ��Կ���,�������ͬ����һ��������(inner join)���봰�����ͬ����,interval join ��ƥ���ʱ����ǻ����������ݵ�,���Բ���ȷ��;������ B �е����ݿ��Բ�ֻ��һ�������ڱ�ƥ�䡣
2. �������ĵ���
��������ڴ�����,�ǻ��� KeyedStream ������(join)������DataStream �� keyBy �õ�KeyedStream ֮��,���Ե���.intervalJoin()���ϲ�������,����IJ���ͬ����һ�� KeyedStream,���ߵ� key ����Ӧ��һ��;�õ�����һ�� IntervalJoin ���͡������IJ���ͬ������ȫ�̶���:��ͨ��.between()����ָ����������½�,�ٵ���.process()����,�����ƥ�����ݶԵĴ�������������.process()��Ҫ����һ����������,���Ǵ���������������һԱ:���������ắ����ProcessJoinFunction��
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(left + "," + right);
}
});
���Կ���,������ ProcessJoinFunction ������ ProcessFunction �� JoinFunction �Ľ��,�ڲ�ͬ����һ������.processElement()������������������ͬ����,������һ������,����Ȼ����Ϊ�����������������ݡ������� left ָ�ľ��ǵ�һ�����е�����,right ���ǵڶ�����������ƥ������ݡ�ÿ����һ��ƥ��,�ͻ���������.processElement()����,������ת��֮����������
3. �������ʵ��
�ڵ�����վ��,ijЩ�û���Ϊ�������ж�ʱ���ڵ�ǿ���������������һ������,������������,һ�����¶�������,һ����������ݵ��������ǿ������ͬһ���û�,��������һ�����ᡣҲ����ʹ��һ���û����¶������¼�������û������ʮ���ӵ�������ݽ���һ�������ѯ��
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
// ���ڼ���� join
public class IntervalJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> orderStream = env.fromElements(
Tuple3.of("Mary", "order-1", 5000L),
Tuple3.of("Alice", "order-2", 5000L),
Tuple3.of("Bob", "order-3", 20000L),
Tuple3.of("Alice", "order-4", 20000L),
Tuple3.of("Cary", "order-5", 51000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
})
);
SingleOutputStreamOperator<Event> clickStream = env.fromElements(
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 36000L),
new Event("Bob", "./home", 30000L),
new Event("Bob", "./prod?id=1", 23000L),
new Event("Bob", "./prod?id=3", 33000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(data -> data.user))
.between(Time.seconds(-5), Time.seconds(10))
.process(new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>() {
@Override
public void processElement(Tuple3<String, String, Long> left, Event right, Context ctx, Collector<String> out) throws Exception {
out.collect(right + " => " + left);
}
}).print();
env.execute();
}
}
������:
Event{user='Alice', url='./prod?id=100', timestamp=1970-01-01 08:00:03.0} => (Alice,order-2,5000)
Event{user='Alice', url='./prod?id=200', timestamp=1970-01-01 08:00:03.5} => (Alice,order-2,5000)
Event{user='Bob', url='./home', timestamp=1970-01-01 08:00:30.0} => (Bob,order-3,20000)
Event{user='Bob', url='./prod?id=1', timestamp=1970-01-01 08:00:23.0} => (Bob,order-3,20000)
����ͬ������(Window CoGroup)
����������ͼ������֮��,Flink ���ṩ��һ��������ͬ�����ᡱ(window coGroup)�����������÷��� window join �dz�����,Ҳ�ǽ��������ϲ�֮������ƥ���Ԫ��,����ʱֻ��Ҫ��.join()��Ϊ.coGroup()�Ϳ����ˡ�
stream1.coGroup(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction>)
�� window join ����������,����.apply()��������������ʱ,�������һ��CoGroupFunction����Ҳ��һ��������ӿ�,Դ���ж�������:
public interface CoGroupFunction<IN1, IN2, O> extends Function, Serializable {
void coGroup(Iterable<IN1> first, Iterable<IN2> second, Collector<O> out) throws Exception;
}
�ڲ���.coGroup()����,��Щ������ FlatJoinFunction ��.join()����ʽ,ͬ������������,�ֱ�����������е������Լ�����������ռ���(Collector)����ͬ����,�����ǰ�������������ǵ�����ÿһ�顰��ԡ�������,���Ǵ����˿ɱ��������ݼ��ϡ�Ҳ����˵,���ڲ�����ȥ���㴰�������������ݼ��ĵѿ�����,����ֱ�Ӱ��ռ�������������һ���Դ���,����Ҫ���������ȫ���Զ���ġ�����.coGroup()����ֻ�ᱻ����һ��,���Ҽ�ʹһ����������û���κ���һ����������ƥ��,Ҳ���Գ����ڼ����С���ȻҲ���Զ����������ˡ�
�����ܹ�����,coGroup �����ȴ��ڵ� join ����ͨ��,��������ʵ������ SQL �еġ������ӡ�(inner join),Ҳ����ʵ����������(left outer join)����������(right outer join)��ȫ������(full outer join)����ʵ��,���� join �ĵײ�,Ҳ��ͨ�� coGroup ��ʵ�ֵġ�
������һ�� coGroup ��ʾ������:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
// ���ڴ��ڵ� join
public class CoGroupExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String,
Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
);
DataStream<Tuple2<String, Long>> stream2 = env.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String,
Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
);
stream1
.coGroup(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1,
Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception {
collector.collect(iter1 + "=>" + iter2);
}
})
.print();
env.execute();
}
}
��������:
[(a,1000), (a,2000)]=>[(a,3000), (a,4000)]
[(b,1000), (b,2000)]=>[(b,3000), (b,4000)]
��yyds
ѧϰ�����������й��:https://www.bilibili.com/video/BV133411s7Sa?p=1

