一、安装Hadoop
Hadoop集群需要java环境支持,所以要提前安装好并配置好JDK。
Hadoop下载地址https://www. oracle. com/technetwork/java/javase/downloads/index. html。
在第一台虚拟机上(Hadoop-01)将下载完毕的Hadoop(我的是2.7.4的版本)安装包上传至Linux系统的/export/software/目录下。
进入Hadoop安装包目录将Hadoop安装包解压到/export/servers/目录下。
cd /export/software/
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/安装比较简单,到此就安装完了,接下来就是配置Hadoop了。
二、Hadoop的相关配置
1.检验是否安装成功
执行hadoop version,出现版本相关信息就说明安装成功了。

2.配置环境变量
vi /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH3.配置Hadoop集群主节点
(1)修改hadoop-env.sh文件
? ? ? ?进入到主节点hadoop01解压包下的etc/hadoop/目录,使用“vi hadoop-env.sh”指令打 开其中的hadoop-env.sh文件,找到JAVA_HOME参数位置进行修改(注意JDK路径,你自己的路径是什么就改成什么)。
cd /export/servers/hadoop-2.7.4/etc/hadoop/
vi hadoop-env.sh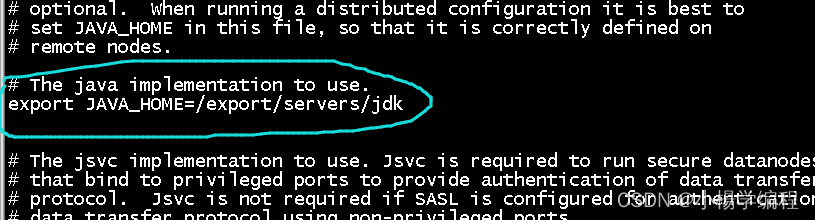
?(2)修改core-site.xml文件。
? ? ? ? ? ? 该文件是Hadoop的核心配置文件,配置HDFS地址、端口号,以及临时文件 目录。打开该配置文件,添加如下配置内容。
cd /export/servers/hadoop-2.7.4/etc/hadoop/
vi core-site.xml
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在hadoop01机器上-->
<value>hdfs://hadoop01:9000</value>
</property>
<!--配置Hadoop的临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration>
??(3)修改hdfs-site.xml文件。
? ? ? ? ?该文件用于设置HDFS的NameNode和DataNode两大进程。
cd /export/servers/hadoop-2.7.4/etc/hadoop/
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>
(4)修改mapred-site.xml文件。
? ? ?该文件是MapReduce的核心配置文件,指定MapReduce运行时框架。在etc/ hadoop/目录中默认没有该文件,将“mapred-site.xml.template ”文件复制并重命名为“mapred-site.xml”。打开mapred-site.xml文件进 行修改。
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<!--指定MapReduce运行时框架,默认是local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)修改yarn-site.xml文件。
? ? ? 本文件是YARN框架的核心配置文件,需要指定YARN集群的管理者。打开该配置 文件,添加如下配置内容。
vi yarn-site.xml
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)修改slaves文件。
? ? ? 该文件用于记录Hadoop集群所有从节点(HDFS的DatalNode和YARN的 NodeManager所在主机)的主机名,用来配合一键启动脚本启动集群从节点(关联节点需要提前配置了SSH免密登录)。打开该配置文件,先删除里面的内容, 然后输入你自己的三台主机名。
4.将主节点的配置文件分发到其他子节点
? ? ?将hadoop安装目录分发至hadoop-02和hadoop-03服务器上。具体命令如下
scp -r /export/servers/hadoop-2.7.4/ hadoop-02:/export/servers/
scp -r /export/servers/hadoop-2.7.4/ hadoop-03:/export/servers/5.分发环境变量配置
scp -r /etc/profile hadoop-02:/etc/
scp -r /etc/profile hadoop-03:/etc/6.启用环境变量
分别在hadoop-01、hadoop-02和hadoop-03服务器上刷新profile配置文件,使环境变量生效。
source /etc/profile三、hadoop的启动和关闭
1.一键启动
(1)在主节点hadoop01上使用以下指令启动所有HDFS服务进程:
?start-dfs.sh
(2)在主节点hadoop01上使用以下指令启动所有YARN服务进程:
start-yarn.sh
2.一键关闭
(1)在主节点hadoop01上使用以下指令启动所有HDFS服务进程:
?stop-dfs.sh
(2)在主节点hadoop01上使用以下指令启动所有YARN服务进程:
stop-yarn.sh
3.单节点启动
(1)在主节点上使用以下指令启动HDFS NameNode进程:
hadoop-daemon.sh start namenode
(2)在每个从节点上使用以下指令启动HDFS DatalNode 进程:
hadoop-daemon.sh start datanode
(3)在主节点上使用以下指令启动YARN ResourceManager 进程:
yarn-daemon.sh start resourcemanager
(4)在每个从节点上使用以下指令启动YARN nodemanager进程:
yarn-daemon.sh start nodemanager
(5)在规划节点hadoop02使用以下指令启动SecondaryNameNode 进程:
hadoop-daemon.sh start secondarynamenode
4.单节点关闭
(1)在主节点上使用以下指令启动HDFS NameNode进程:
hadoop-daemon.sh stop namenode
(2)在每个从节点上使用以下指令启动HDFS DatalNode 进程:
hadoop-daemon.sh stop datanode
(3)在主节点上使用以下指令启动YARN ResourceManager 进程:
yarn-daemon.sh stop resourcemanager
(4)在每个从节点上使用以下指令启动YARN nodemanager进程:
yarn-daemon.sh stop nodemanager
(5)在规划节点hadoop02使用以下指令启动SecondaryNameNode 进程:
hadoop-daemon.sh stop secondarynamenode

