进Q群11372462领取专属报名福利!
#说在前面
当你在Youtube排队下载Trap的beats、当你在网易云音乐排队下载TeamWang的Music Album,甚至当你在星巴克排队Coffee,这一系列的场景潜移默化的会把你拉进消息队列(MQ)的世界,与此同时,消息队列中以Kafka为代表,秉承着先进先出(FIFO)的原则,正在悄悄帮你"消费"。也就是说,当你正在排队,突然快递小哥给你打电话,告诉正在你公司等你收快递,此时尴尬的一批,好不容易快排到自己为了展示自己的高素质选择暂时离开,等拿到快递再回来的时候,原先的位置早就过号,So不得不重新排队,也就是说之前排在你后面的小姐姐们都已经买到了自己钟爱的咖啡(已在消息队列中被消费掉)。
如果对消息队列还是不够了解,请回忆UP楠哥之前唠过一篇文章《就因为是一只“兔子”?受宠爱的RabbitMQ》

,这篇文章已经较为详细的描述了消息队列的原理&工作方式;从那时起,消息队列MQ的话题已然开始,消息队列的核心就是"消费";今天再唠一唠爱“消费”的Kafka。

#什么是Kafka

Kafka最初是由Linkedin公司开发的,使用Scala语言编写的,一个分布式、多分区、多副本、多订阅者的消息系统。他通常用于异常及运行日志、搜索日志、用户行为日志、监控日志、访问日志等日志系统的搭建。
Kafka目前支持多种客户端语言:Java,python,C++,php,.net等等。(Confluent.Net,LibrdKafka)
Kafka是一个分布式的发布订阅模式的消息系统,可以处理大量的数据,Kafka适合离线和在线计算,Kafka的消息保留在磁盘上,并在集群内复制以防止数据丢失。Kafka依赖Zookeeper分布式同步服务。
Kafka能与Storm、Spark、Flink、Flume等非常好的集成,用于实时流式数据分析处理。
#Why Kafka
为啥要用Kafka呢 ,Kafka的应用场景包含如下:
○ 异步通信
○ 应用系统解耦
耦合性高:不易维护,牵一发而动全身。
○ 流量削峰
大部分网站系统在大部分时间的流量比较稳定。但是在搞活动,比如开篇提到的大家都在星巴克排队抢购、秒杀的时候,流量瞬间暴涨,对系统造成了巨大的压力。如果按照流量峰值配置相应的资源,无疑是巨大的浪费。我们将流量存储在消息系统中,根据消费者能力去处理业务高峰,缓解瓶颈压力,就能起到流量削峰的作用。
○ 系统扩展
基于发布订阅的特性,对于同一个消息,可以扩展不同的处理程序用于支持不同的业务需求。
#Kafka优势
○ 高性能
Kafka对于发布-订阅信息具有非常高的吞吐量,即使存储了TB级别的消息,他也保持稳定的性能。
○ 高可用
Kafka是分布式的,并且拥有分区机制,复制备份机制使得Kafka容错能力大大提升。
○ 可扩展性
Kafka消息系统动态缩放,无需停机。
○ 消息持久化
大部分MQ都是走的发送-缓存-消费-删除的路线,消息在消息队列中存储的时间很短,被消费之后,消息就被删除。
然而很多时候,我们需要多个程序不同时间、不同业务场景下对消息进行多次消费,以满足我们业务需求。所以,Kafka的消息持久化特性就显得尤为突出。
#Kafka整体架构
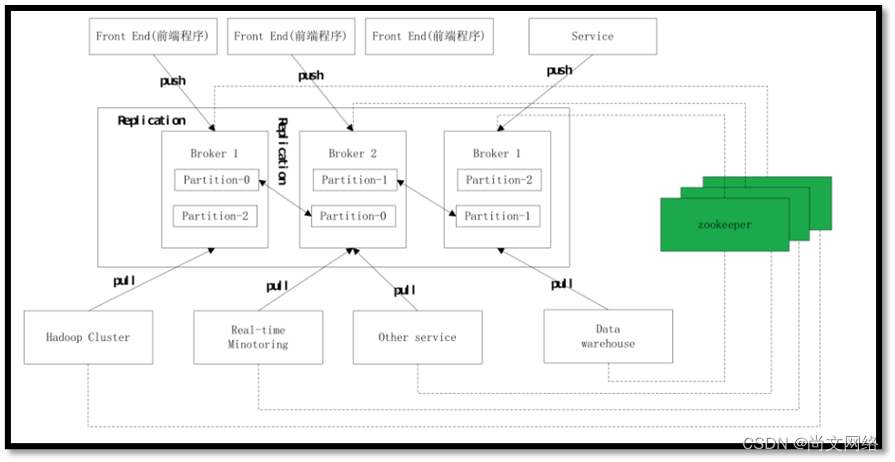
如图所示,一个典型的Kafka集群中包含若干Producer,Broker,Consumer.
Producer发布(push)消息到Broker(消息存储代理),消费者(也是客户端程序)从broker获取数(poll),然后完成一些列对数据的处理操作。
多个Broker协同合作,Producer和Consumer部署在各个业务逻辑中被频繁调用,三者通过Zookeeper协调管理者请求和转发,这样就组成了分布式的发布订阅消息系统。
Zookeeer在kafka中的作用:
1、Broker和Topic等meta信息都存储在Zookeeper中。
2、Consumer的Offset信息也存储在Zookeeper中。
3、Borkder和Consumer以及Topic之间的订阅关系,也是存在Zookeeper中。
#Kafka相关概念
##Broker(消息代理)
一个单独的KafkaServer就是一个Broker,Broder的主要作用就是用于接受Producer发送过来的消息,并保存到磁盘上。同时用于接受Consumer的连接,拉取消息进行消费。
##Topic(消息主题)
Topic用于存储消息的逻辑概念,可以看做是一组消息集合。每个Topic可以有多个Producer向其中推送消息,也可以任意多个消费者消费其中的数据。
##Partition(主题分区)
Parition是物理上的概念,每个Topic可以划分为多个Partitiion,同一个Topic的不同Partiiton存储的消息是不同的。每个Partition可以拥有多个副本,用以实现消息的冗余备份。
##Producer(生产者)
发布消息到Kafka broker。
##Consumer(消费者)
消息消费者,从Kafka broker读取消息。
##Consumer Group(消费者组)
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
##Replication和ISR
Kafka的高可靠性来源于健壮的副本机制。Kafka副本是针对Topic和Parition而言的。
可以通过kafka/config/server.propertities配置文件中的default.replication.refactor参数来设置当前topic-patition所拥有的副本数量。
##Consumer如何消费
当一个Consumer和Consumer Group初始化时,每个分区的Consumer一般会从最早或者最近的数据开始读,然后再从每个分区依次把消息读取出来。消费者消费过程中,消费者会自动(或手动)提交已经成功处理的消息偏移量。
当一个分区被重新分配给组中的另一个消费者时,这个消费者会从上一个消费者最后一次提交的偏移量处开始读。保证消息被顺序消费。
#写在最后
生活的每一个细节都会成为与你工作相关联的素材,生活工作中,缺的不是素材,缺的是善于发现真善美的眼睛!IT中的PAAS技术&大数据技术中非常重要的消息队列,我们要学会好好使用,像Redis、Kafka、RabbitMQ、ActiveMQ等,都是消息队列精英,擅长“消费”!

