问题描述:

ods_to_dwd_log报以下错误
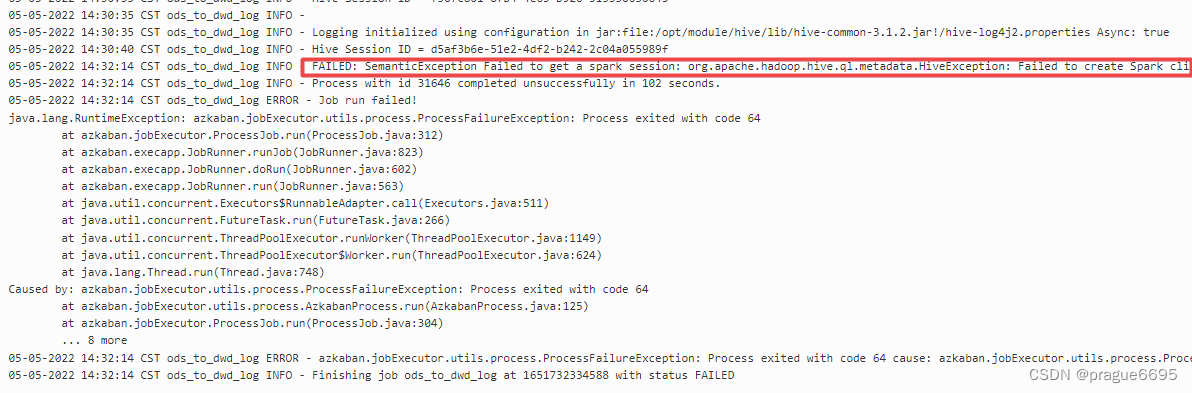
ods_to_dim_db报一下错误
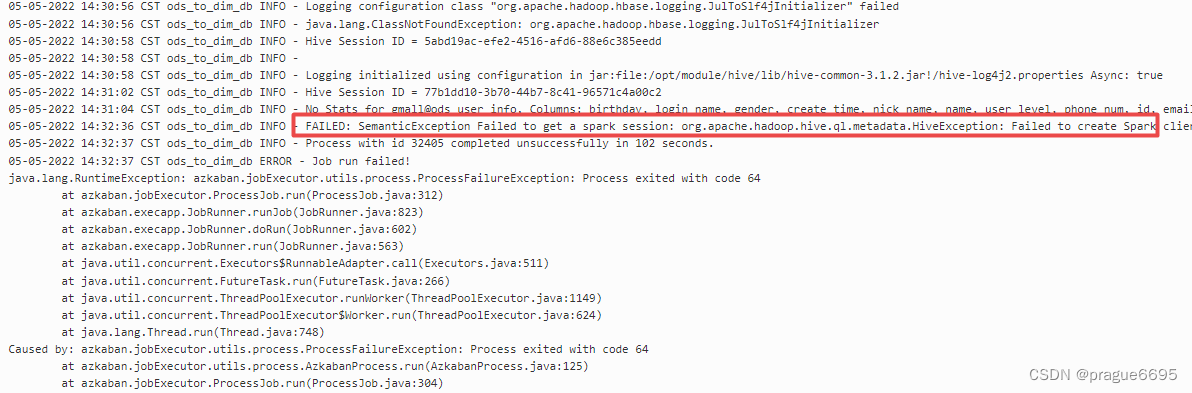
可以看出都是相同报错,无法创建spark事务
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
05-05-2022 14:31:02 CST ods_to_dim_db INFO - Hive Session ID = 77b1dd10-3b70-44b7-8c41-96571c4a00c2
05-05-2022 14:31:04 CST ods_to_dim_db INFO - No Stats for gmall@ods_user_info, Columns: birthday, login_name, gender, create_time, nick_name, name, user_level, phone_num, id, email, operate_time
05-05-2022 14:32:36 CST ods_to_dim_db INFO - FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session 6115db31-a456-4b8a-bd68-2b9defe20b95
05-05-2022 14:32:37 CST ods_to_dim_db INFO - Process with id 32405 completed unsuccessfully in 102 seconds.
05-05-2022 14:32:37 CST ods_to_dim_db ERROR - Job run failed!
java.lang.RuntimeException: azkaban.jobExecutor.utils.process.ProcessFailureException: Process exited with code 64
at azkaban.jobExecutor.ProcessJob.run(ProcessJob.java:312)
at azkaban.execapp.JobRunner.runJob(JobRunner.java:823)
at azkaban.execapp.JobRunner.doRun(JobRunner.java:602)
at azkaban.execapp.JobRunner.run(JobRunner.java:563)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: azkaban.jobExecutor.utils.process.ProcessFailureException: Process exited with code 64
at azkaban.jobExecutor.utils.process.AzkabanProcess.run(AzkabanProcess.java:125)
at azkaban.jobExecutor.ProcessJob.run(ProcessJob.java:304)
... 8 more
排除问题
先对问题进行排除:
首先,在该服务器上尝试启动hive,并且手动执行该脚本。
ods_to_dwd_log执行成功。
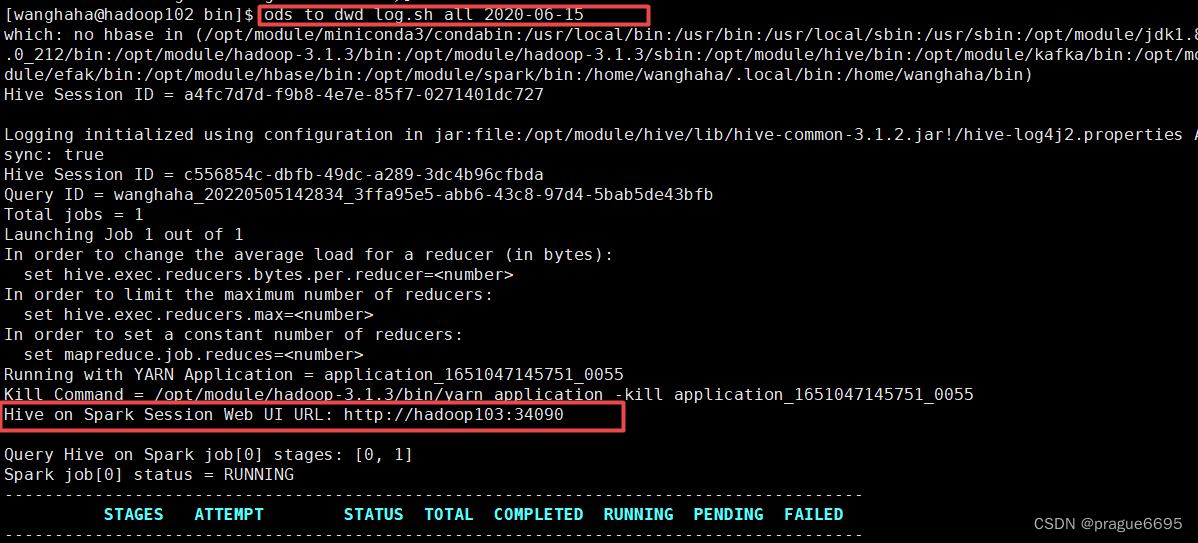
ods_to_dim_db也执行成功
 如果执行成功,说明hive-on-spark搭建成功。如果失败,则搭建失败。就要考虑是版本兼容性问题还是配置文件出错。
如果执行成功,说明hive-on-spark搭建成功。如果失败,则搭建失败。就要考虑是版本兼容性问题还是配置文件出错。
解决方案一
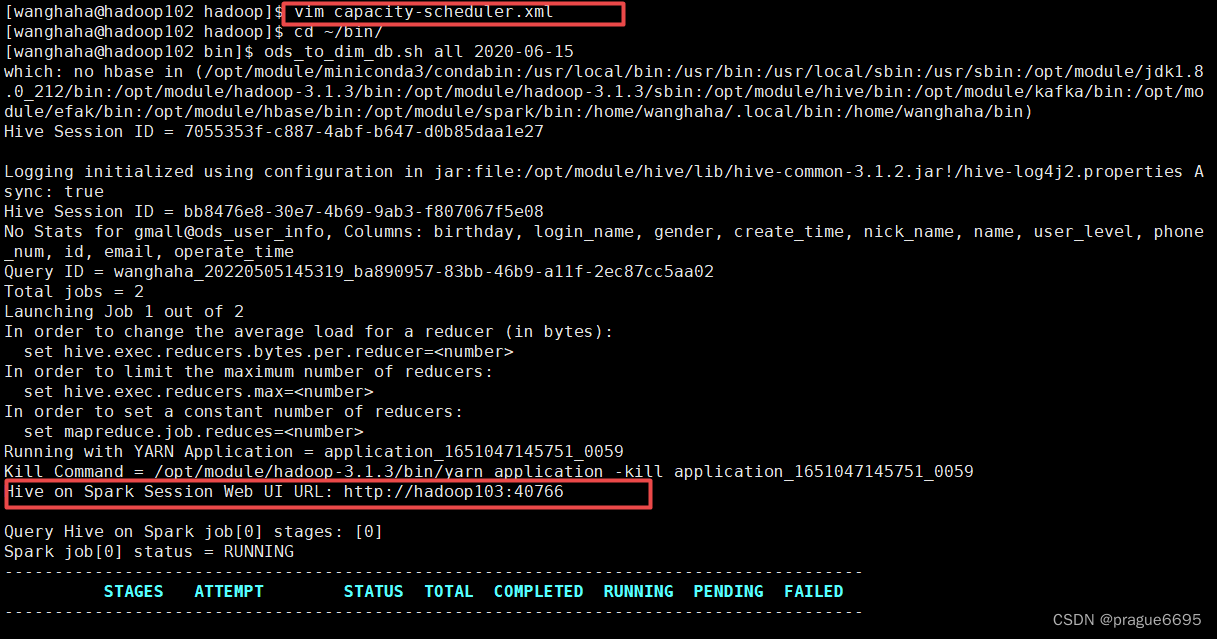
尝试解决方法一:
可以尝试调整hadoop/etc/hadoop/capacity-scheduler.xml中yarn.scheduler.capacity.maximum-am-resource-percent参数,application master资源比例,默认为0.8,如果该值设置过大,就会导致mapreduce时内存不足,就会报上面错误。如果该值是默认值,在学习环境下application master分配内存较少,可能同时只能执行一个job,影响效率。可以尝试调整0.5,
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.5</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
成功执行。
但是再运行一次还是失败,说明是存在偶然性。
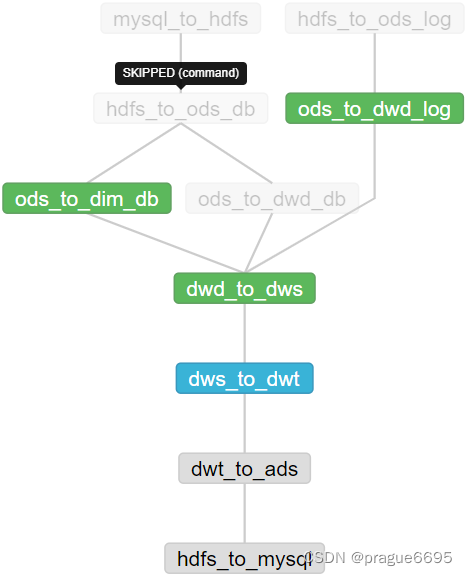
然后去yarn的web:http://hadoop103:8088/cluster/apps界面查看具体的报错信息。
通过Hive Session ID = c1fbe469-6f9d-4dba-b7e8-d6092676f8b8找到对应的task
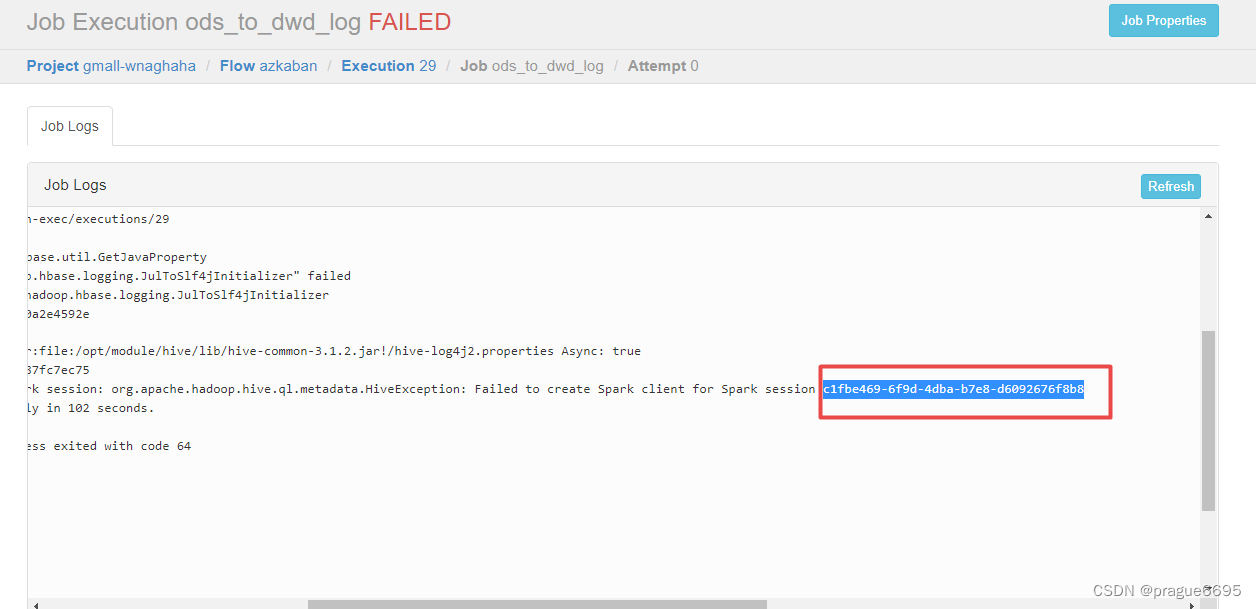
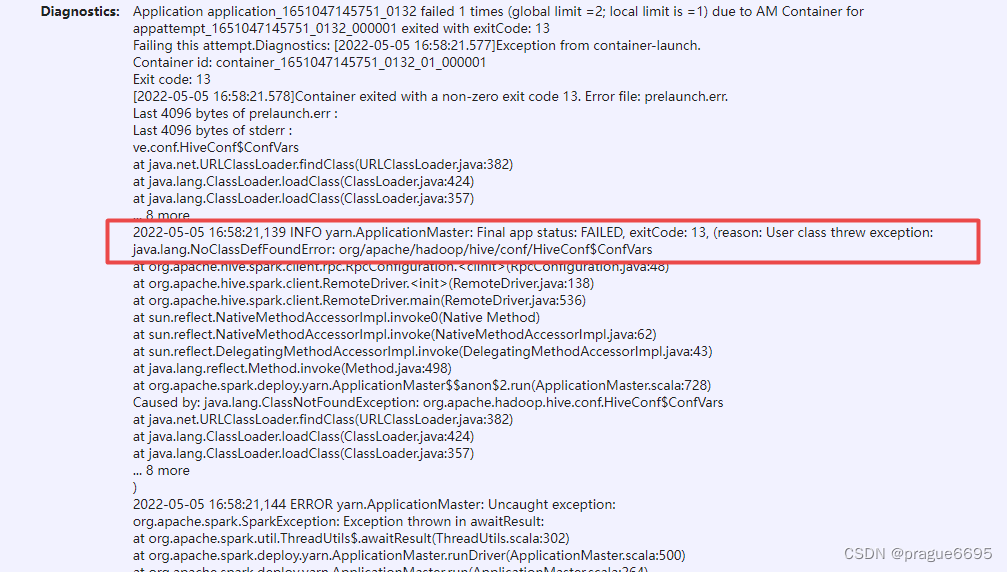
2022-05-05 16:58:21,139 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 13, (reason: User class threw exception: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/conf/HiveConf$ConfVars
at org.apache.hive.spark.client.rpc.RpcConfiguration.<clinit>(RpcConfiguration.java:48)
at org.apache.hive.spark.client.RemoteDriver.<init>(RemoteDriver.java:138)
at org.apache.hive.spark.client.RemoteDriver.main(RemoteDriver.java:536)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:728)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf$ConfVars
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 8 more
后来发现这几个报错都有个共同点,就是任务都是在hadoop104的节点上进行的。然后在104的节点上手动跑了这个任务,确实发生了报错。
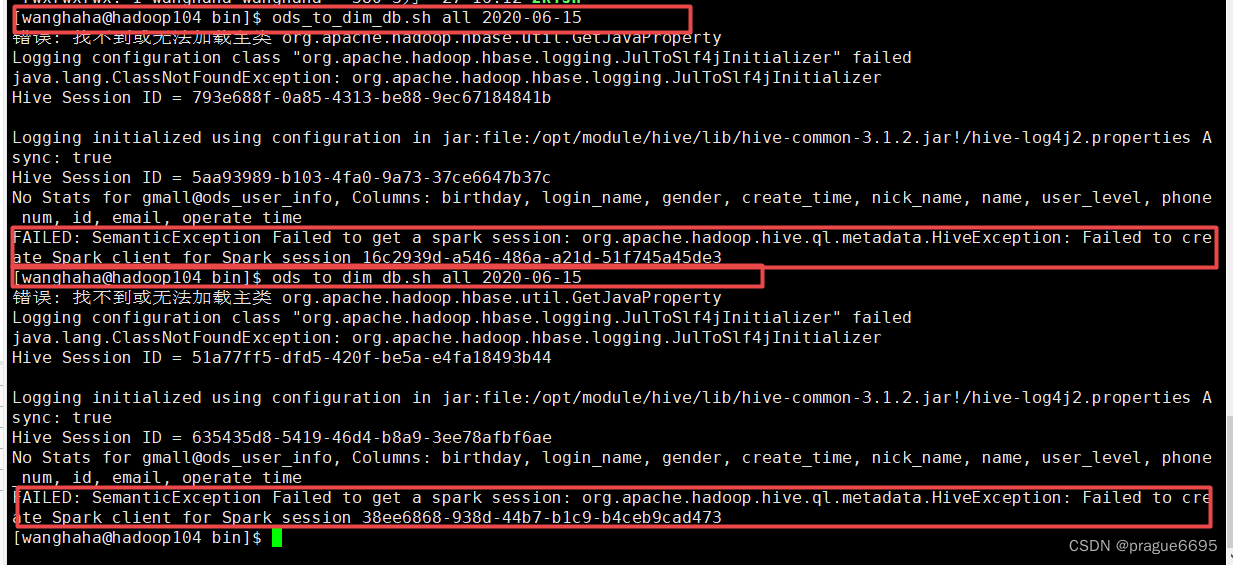
查了好多资料都不知道为社么。
解决方案二
其实当出现报错的时候,就感觉是内存太小,以至于同时跑几个脚本都跑不了。
所以尝试关闭虚拟机,将虚拟机的内存由4G调升至8G。
再尝试跑一下,成功
然后我们再分析下hive on spark的具体内存开销是什么样的?
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
当运行ods_to_dwd_log.sh数据装载脚本时,会启动hive,然后经过驱动器(解析器,编译器,优化器,装载器)就会向yarn提交spark任务。
当脚本执行前,jvm进程主要有Hadoop,azkaban进行
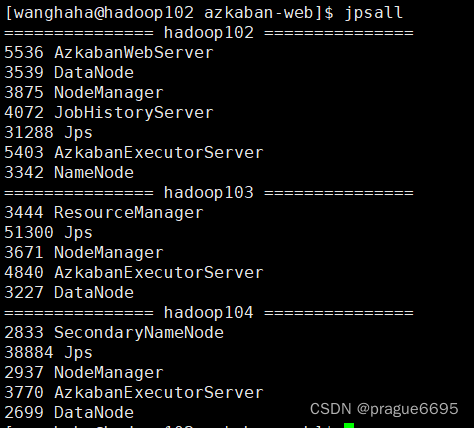
然后当spark任务提交时
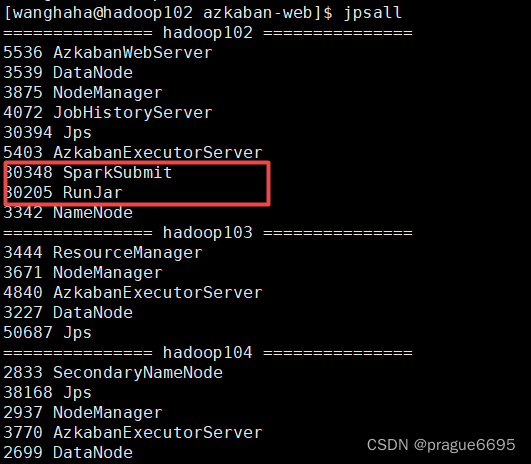
当运行任务时
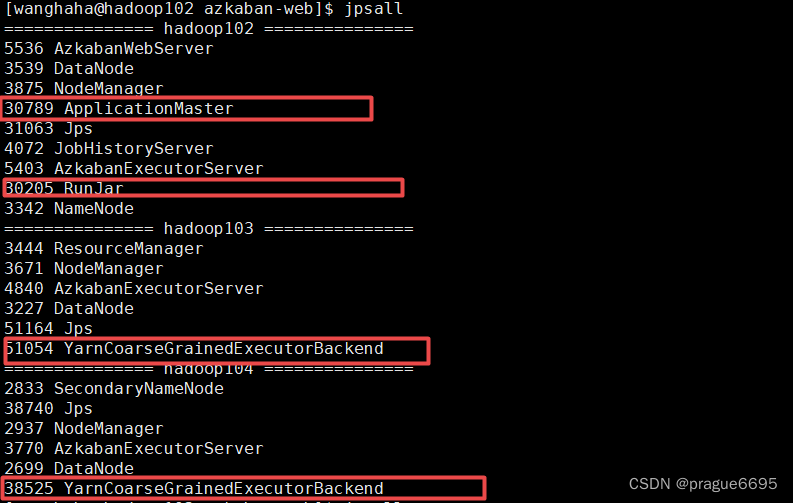
Spark在Yarn-Cluster部署模式下,程序在提交之后会依次创建三个进程:SparkSubmit,ApplicationMaster和CoarseGrainedExecutorBackend。
Cluster 模式将用于监控和调度的 Driver 模块启动在 Yarn 集群资源中执行。一般应用于实际生产环境。
? 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster,
? 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
? Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动Executor 进程
? Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数,
? 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
Executor参数设置
参考
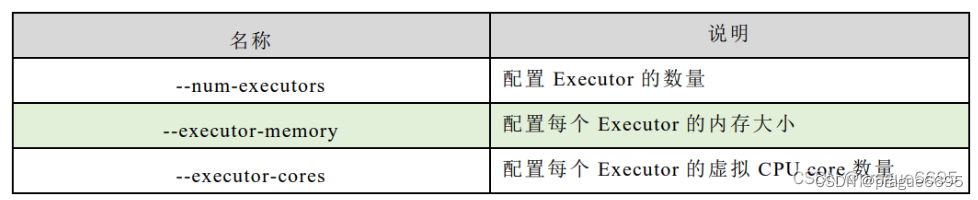
在spark的的一个工作节点的上的一个jvm进程Executor,是整个集群专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:
yarn-site相关调优
/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
- 调度器的选择,默认容量
- ResourceManager处理调度器请求的线程数量,默认50
- 是否让yarn自动检测硬件进行配置,默认是false
- 是否将虚拟核数当作CPU核数,默认是false,采用物理CPU核数
- 虚拟核数和物理核数乘数,默认是1.0
- NodeManager使用内存数 和 cpu核数
- 容器最大内存,最小内存,最小cpu核数,最大cpu核数
- 关闭虚拟内存检查
- 虚拟内存和物理内存设置比例,默认2.1
- 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true
- 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true
capacity-scheduler相关调优
/opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml
[atguigu@hadoop102 hadoop]$ vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property
容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配10%的资源给Application Master,则可能出现,同一时刻只能运行一个Job的情况,因为一个Application Master使用的资源就可能已经达到10%的上限了。故此处可将该值适当调大
JVM相关调优
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
JVM heap一般设置为4G或更高
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。
hive ob spark的相关调优
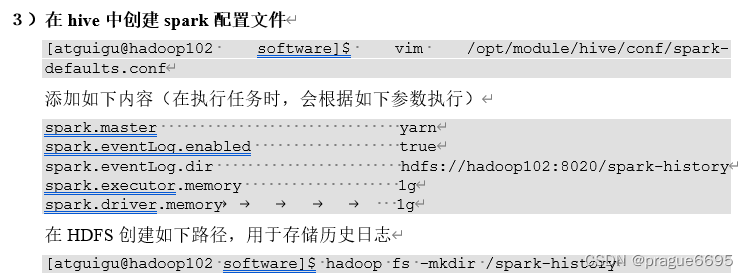
容量调度器的调优
参考
hive-on-spark报错:org.apache.hadoop.hive.ql.parse.SemanticException:Failed to get a spark session

