x.1 缓存穿透
- 缓存穿透是指当用户查询某个数据时,Redis 中不存在该数据,也就是缓存没有命中,此时查询请求就会转向持久层数据库 MySQL,结果发现 MySQL 中也不存在该数据,MySQL 只能返回一个空对象,代表此次查询失败。
- 如果这种类请求非常多,或者用户利用这种请求进行恶意攻击,就会给 MySQL 数据库造成很大压力,甚至于崩溃,这种现象就叫缓存穿透。
- 当 MySQL 返回空对象时, Redis 将该对象缓存起来,同时为其设置一个过期时间。
- 当用户再次发起相同请求时,就会从缓存中拿到一个空对象,用户的请求被阻断在了缓存层,从而保护了后端数据库。
- 但是这种做法也存在一些问题,虽然请求进不了 MSQL,但是这种策略会占用 Redis 的缓存空间。
- 布隆过滤器判定不存在的数据,那么该数据一定不存在,利用它的这一特点可以防止缓存穿透。
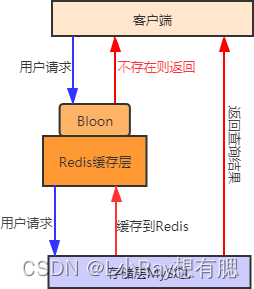
- 首先将用户可能会访问的热点数据存储在布隆过滤器中(也称缓存预热),当有一个用户请求到来时会先经过布隆过滤器,如果请求的数据,布隆过滤器中不存在,那么该请求将直接被拒绝,否则将继续执行查询。
- 相较于第一种方法,用布隆过滤器方法更为高效、实用。其流程示意图如下:
@Test
public void testBloomFilter {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.14.104:6379");
config.useSingleServer().setPassword("123");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("phoneList");
bloomFilter.tryInit(100000000L, 0.03);
bloomFilter.add("10086");
System.out.println(bloomFilter.contains("123456"));
System.out.println(bloomFilter.contains("10086"));
}
x.2 缓存击穿
- 缓存击穿是指用户查询的数据缓存中不存在,但是后端数据库却存在,这种现象出现原因是一般是由缓存中 key 过期导致的。
- 比如一个热点数据 key,它无时无刻都在接受大量的并发访问,如果某一时刻这个 key 突然失效了,就致使大量的并发请求进入后端数据库,导致其压力瞬间增大。这种现象被称为缓存击穿。
- 采用分布式锁的方法,重新设计缓存的使用方式
- 上锁:当我们通过 key 去查询数据时,首先查询缓存,如果没有,就通过分布式锁进行加锁,第一个获取锁的进程进入后端数据库查询,并将查询结果缓到Redis 中。
- 解锁:当其他进程发现锁被某个进程占用时,就进入等待状态,直至解锁后,其余进程再依次访问被缓存的 key。
RLock lock = redisson.getLock("myLock");
lock.lock();
lock.lock(10, TimeUnit.SECONDS);
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
x.3 缓存雪崩
- 缓存雪崩是指缓存中大批量的 key 同时过期,而此时数据访问量又非常大,从而导致后端数据库压力突然暴增,甚至会挂掉,这种现象被称为缓存雪崩。
- 它和缓存击穿不同,缓存击穿是在并发量特别大时,某一个热点 key 突然过期,而缓存雪崩则是大量的 key 同时过期,因此它们根本不是一个量级。
- 缓存雪崩和缓存击穿有相似之处,所以也可以采用热点数据永不过期的方法,来减少大批量的 key 同时过期。
- 再者就是为 key 设置随机过期时间,避免 key 集中过期。
| 
