使用Spark进行岗位数据分析
配置详解
本文是使用Scrapy来获取数据,再使用Spark来进行分析
各版本如下
| 软件 / 库 | 版本 |
|---|---|
| Pycharm社区版 | 2021.3.3 |
| Python | 3.8 |
| Pandas | 1.4.1 |
| Numpy | 1.22.3 |
| PyMySQL | 1.0.2 |
| scrapy | 2.4.1 |
| MySQL | 5.7 |
| Spark | 2.0.0 |
由于社区原因,Scrapy部分不会讲解,只贴代码。
数据获取
MySQL建表语句
DROP TABLE IF EXISTS `job`;
CREATE TABLE `job` (
`address` varchar(255) DEFAULT NULL,
`company` varchar(255) DEFAULT NULL,
`edu` varchar(255) DEFAULT NULL,
`jobName` varchar(255) DEFAULT NULL,
`salary` varchar(255) DEFAULT NULL,
`size` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Settings文件
BOT_NAME = 'job'
SPIDER_MODULES = ['job.spiders']
NEWSPIDER_MODULE = 'job.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
ITEM_PIPELINES = {
'job.pipelines.JobPipeline': 300,
}
主项目代码
import scrapy
import re
import lxml.html
from job.items import JobItem
class TestSpider(scrapy.Spider):
name = 'Test'
# allowed_domains = ['baidu.com']
start_urls = ['https://job001.cn/jobs?keyType=0&keyWord=java']
basic_url = 'https://job001.cn/jobs?keyType=0&keyWord=java&jobTypeId=&jobType=%E8%81%8C%E4%BD%8D%E7%B1%BB%E5%9E%8B&industry=&industryname=%E8%A1%8C%E4%B8%9A%E7%B1%BB%E5%9E%8B&workId=&workPlace=&salary=&entType=&experience=&education=&entSize=&benefits=&reftime=&workTypeId=&sortField=&pageNo=3&curItem='
def parse(self, response):
html = response.text
selector = lxml.html.fromstring(html)
maxPage = selector.xpath('//*[@id="pagediv"]/a[11]/text()')[0]
for num in range(int(maxPage)):
url = self.basic_url.replace('pageNo=3', f'pageNo={num + 1}')
yield scrapy.Request(url=url, callback=self.getUrl)
def getUrl(self, response):
html = response.text
selector = lxml.html.fromstring(html)
hrefList = selector.xpath('//*[@id="infolists"]/div')
for hrefL in hrefList:
href = None if len(hrefL.xpath('./div[1]/div[1]/dl/dt/div[1]/a/@href')) == 0 else \
hrefL.xpath('./div[1]/div[1]/dl/dt/div[1]/a/@href')[0]
if (href != None):
url = 'https://job001.cn' + href
yield scrapy.Request(url=url, callback=self.parsePage)
def parsePage(self, response):
item = JobItem()
page_html = response.text
selector = lxml.html.fromstring(page_html)
item['jobName'] = selector.xpath('/html/body/div[14]/div[1]/div[1]/div[1]/h1/text()')[0]
datas = str(selector.xpath('string(/html/body/div[14]/div[1]/div[1]/div[2])')).replace('\t', '').replace('\n',
'').split(
'・')
item['address'] = datas[0]
if (len(datas) == 4):
item['edu'] = datas[2]
else:
item['edu'] = datas[1]
item['salary'] = str(selector.xpath('/html/body/div[14]/div[1]/div[1]/div[1]/span/text()')[0]).replace('\t',
'').replace(
'\n',
'')
item['company'] = selector.xpath('/html/body/div[15]/div[2]/div[1]/div/div[2]/a/text()')[0]
item['size'] = selector.xpath('/html/body/div[15]/div[2]/div[1]/ul/li[3]/text()')[0]
yield item
items部分代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class JobItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
jobName = scrapy.Field()
address = scrapy.Field()
edu = scrapy.Field()
salary = scrapy.Field()
company = scrapy.Field()
size = scrapy.Field()
pipelines部分代码**
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class JobPipeline:
def process_item(self, item, spider):
conn = pymysql.connect(host='localhost', port=3306, db='crawler', user='root', password='123456',
charset='utf8')
cursor = conn.cursor()
sql = """
insert into job values(%s,%s,%s,%s,%s,%s)
"""
cursor.execute(sql,
(item['address'],
item['company'],
item['edu'],
item['jobName'],
item['salary'],
item['size']))
conn.commit()
return item
结果展示
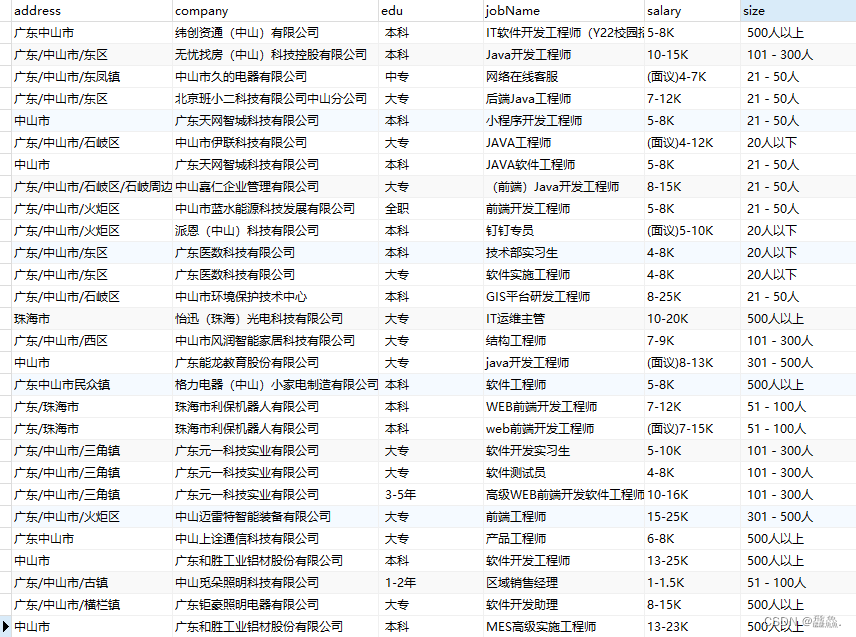
数据分析
读取数据
val spark = SparkSession.builder()
.master("local[6]")
.appName("job")
.config("spark.sql.warehouse.dir", "C:/")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
val source = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/crawler")
.option("dbtable", "job")
.option("user", "root")
.option("password", "123456")
.load()
.rdd
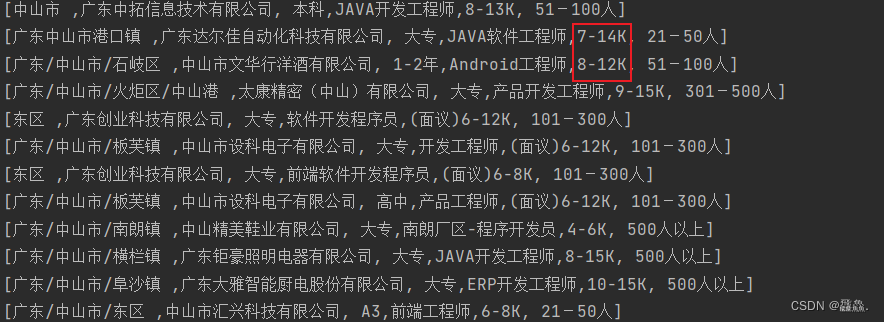
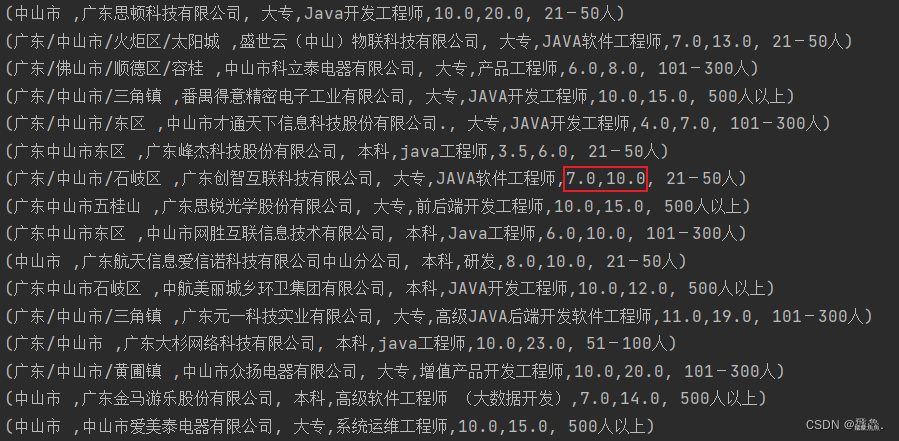
我们可以看到薪资的格式,此时我们需要将其格式做一些变化
val data = source.map(datas => {
val salary = datas(4)
val minSalary = if (salary.toString.split("-")(0).contains("面议")) salary
.toString.split("-")(0).substring(4) else salary.toString.split("-")(0)
val maxSalary = salary.toString.split("-")(1).substring(0, salary.toString.split("-")(1).length - 1)
(datas(0).toString, datas(1).toString, datas(2).toString, datas(3).toString, minSalary.toFloat, maxSalary.toFloat, datas(5).toString)
})
分析不同学历的平均薪资
import org.apache.spark.sql.functions._
import spark.implicits._
val dataDF = data.toDF("address", "company", "edu", "jobName", "minSalary", "maxSalary", "size")
//求每个学历的平均估值(最高薪资平均值、最低薪资平均值求平均)
val eduData = dataDF.select('edu, 'minSalary, 'maxSalary)
.groupBy('edu)
.agg(avg("minSalary") as "avgMinSalary", avg("maxSalary") as "avgMaxSalary")
.withColumn("avgSalary", ('avgMinSalary + 'avgMaxSalary) / 2)
.select('edu, expr("round(avgSalary,2)") as "avgSalary")
.sort('avgSalary desc)
.show()

分析不同岗位的平均薪资
val jobData = dataDF.select('jobName, 'minSalary, 'maxSalary)
.groupBy('jobName)
.agg(avg("minSalary") as "avgMinSalary", avg("maxSalary") as "avgMaxSalary")
.withColumn("avgSalary", ('avgMinSalary + 'avgMaxSalary) / 2)
.select('jobName, expr("round(avgSalary,2)") as "avgSalary")
.sort('avgSalary desc)
.show()

分析各公司提供的岗位
val comData = dataDF.select('company, 'address)
.groupBy('company)
.agg(count("address") as "jobNum")
.sort('jobNum desc)
.show()


