目录
? 3.1- 追踪 检查输出规格 checkSpecs(job);? 检查输出路径是否设置,是否已经存在
?3.2- 追踪计算切片数量的方法 JobSubmit.writeSplits()
?3.3- 追踪构建 存放 jar和conf的目录?????
3.4- 如果有认证的,需要的一些操作逻辑,先拷贝
?3.5- 真正的提交
3.5.1-yarnRunner?ctrl + h , 找到yarn的实现方法
?
Hadoop的版本是2.9.2
首选是需要找到入口,可以自己写个WordCount的例子,然后再idea打点Debug。但源码有提供WordCount例子,直接按照他的例子调试查看启动的流程。最后会附上流程图
找到例子
hadoop-mapreduce-client -> examples-> src -> wordCount
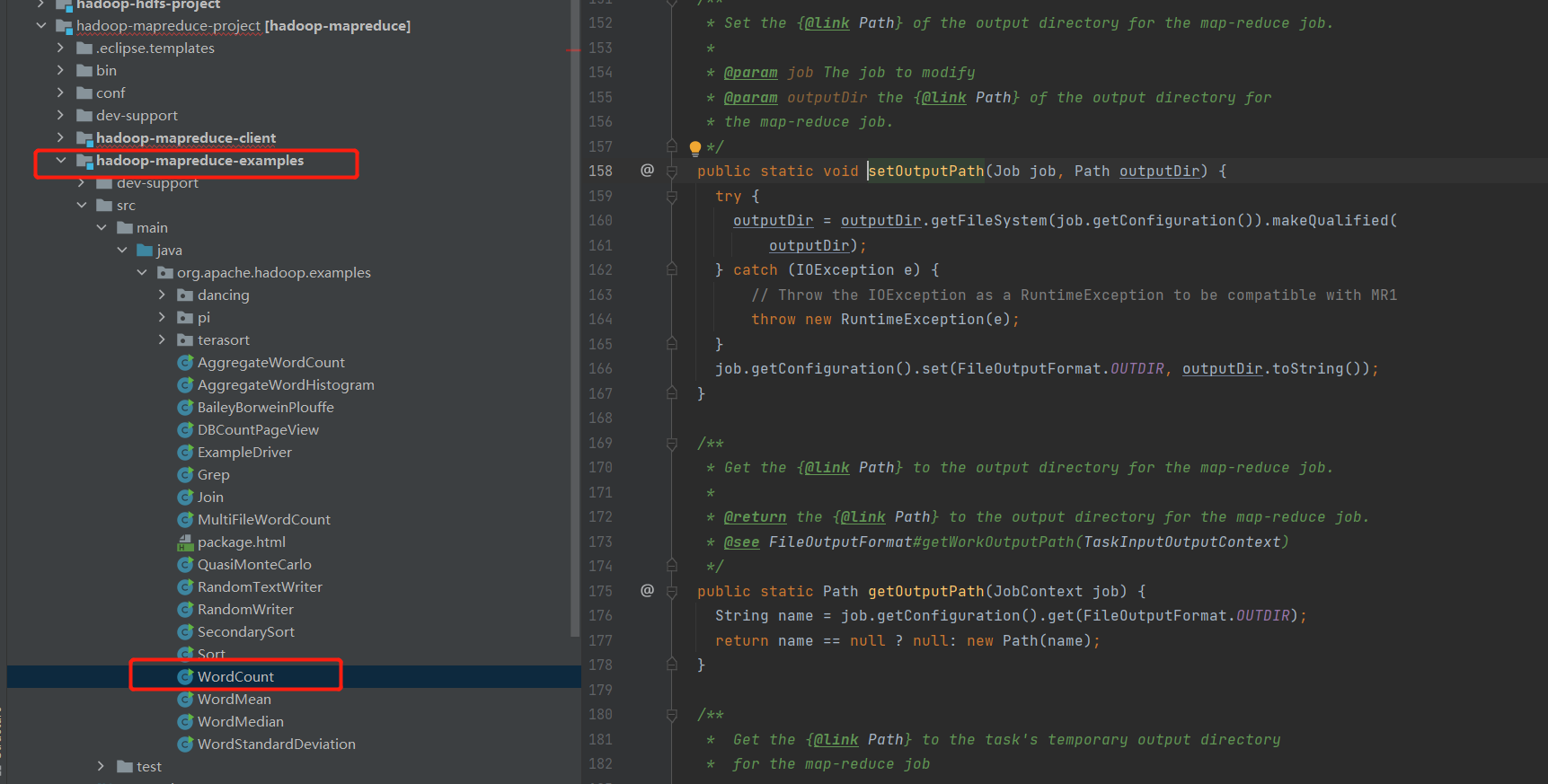
1. 追踪WordCount例子代码
看代码前面的都是设置配置项值(JarPath,MapperClass等),关键方法是Job.WaitForCompletion,ctrl + 左键追踪。发现整个方法是,提交(submit),监控并打印(monitorAndPrintJob),返回执行结果。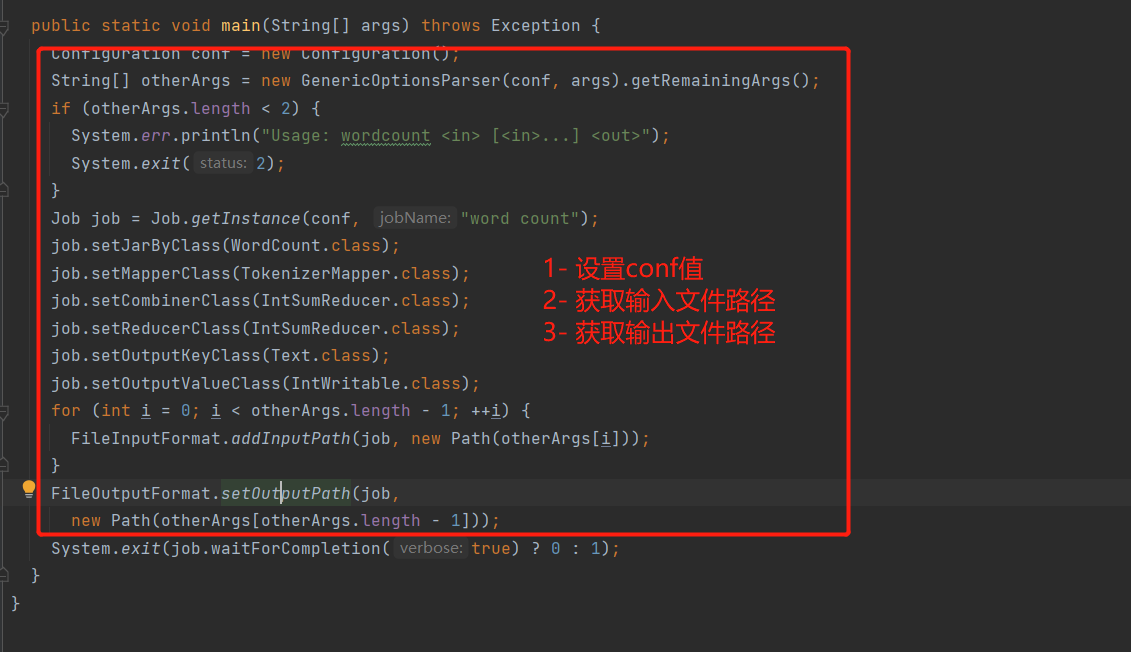
2. 追踪Job.submit()方法
通过代理生成具体的JobSubmit类对象,根据传入的client端对象(localRunner和YarnRunner)生成。后续以 yarn为例。点入方法 getJobSubmitter()。 有生成的对象继续提交job, submitJobInternal()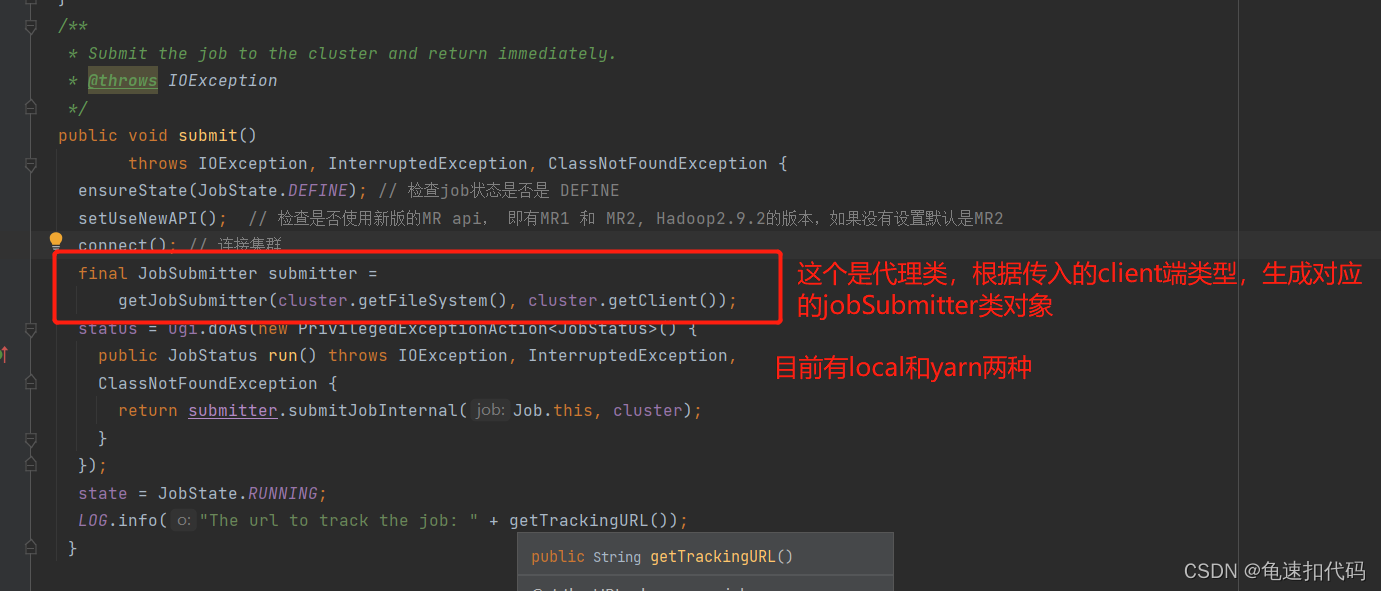
?
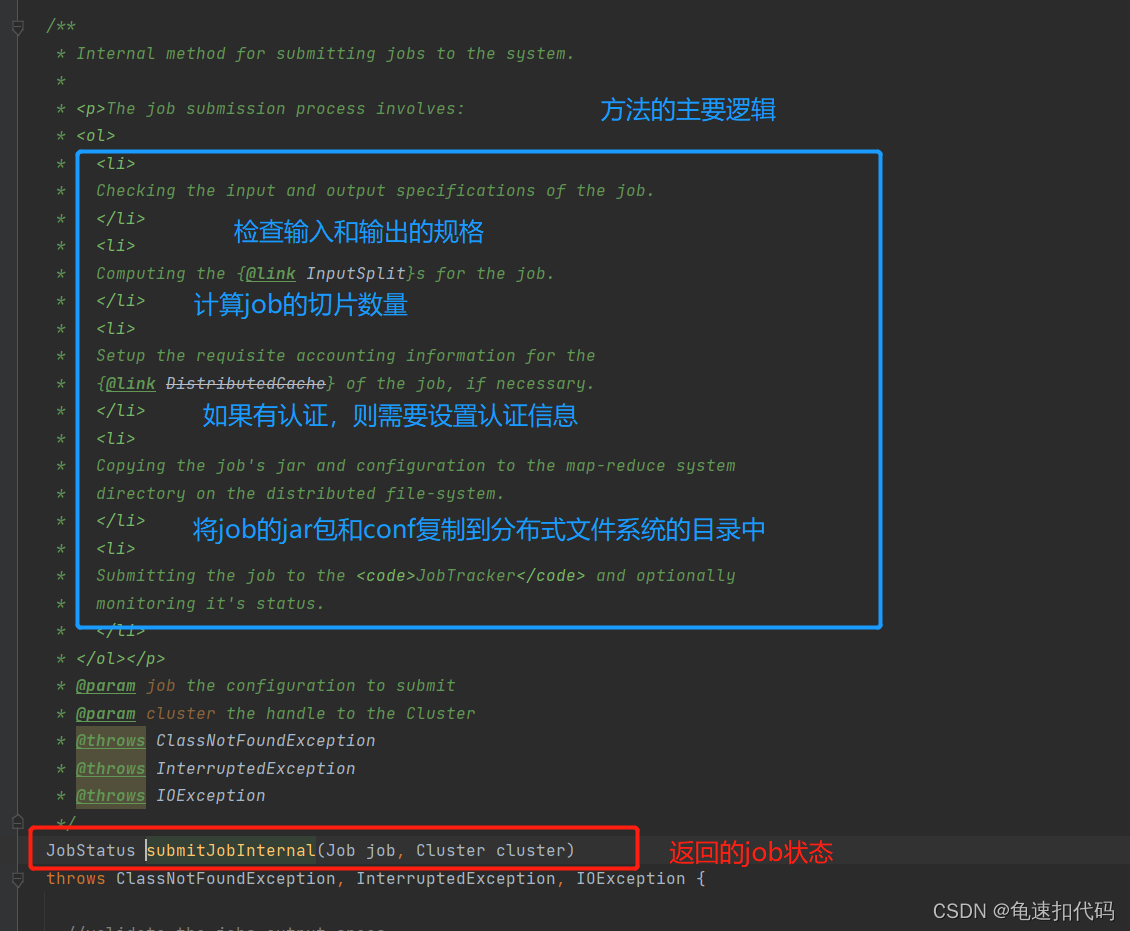
3.追踪Job.?submitJobInternal()
?
这个方法主要有四个逻辑步骤
1- 检查输出的规格是否符合设置
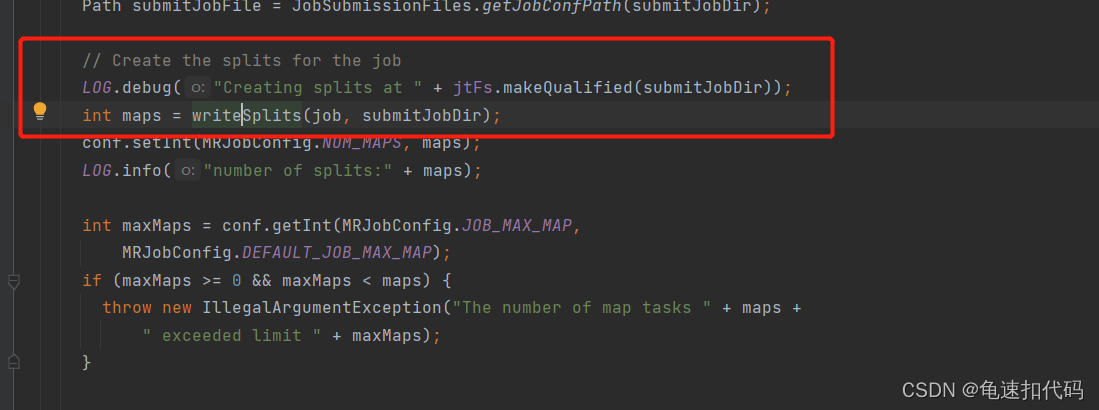
2- 计算这个job的切片数量
3- 如果有认证,需要上传token等
4- 将job的jar包和conf复制到分布式文件系统的目录中
 ?? ??????? 3.1- 追踪 检查输出规格 checkSpecs(job);? 检查输出路径是否设置,是否已经存在
?? ??????? 3.1- 追踪 检查输出规格 checkSpecs(job);? 检查输出路径是否设置,是否已经存在
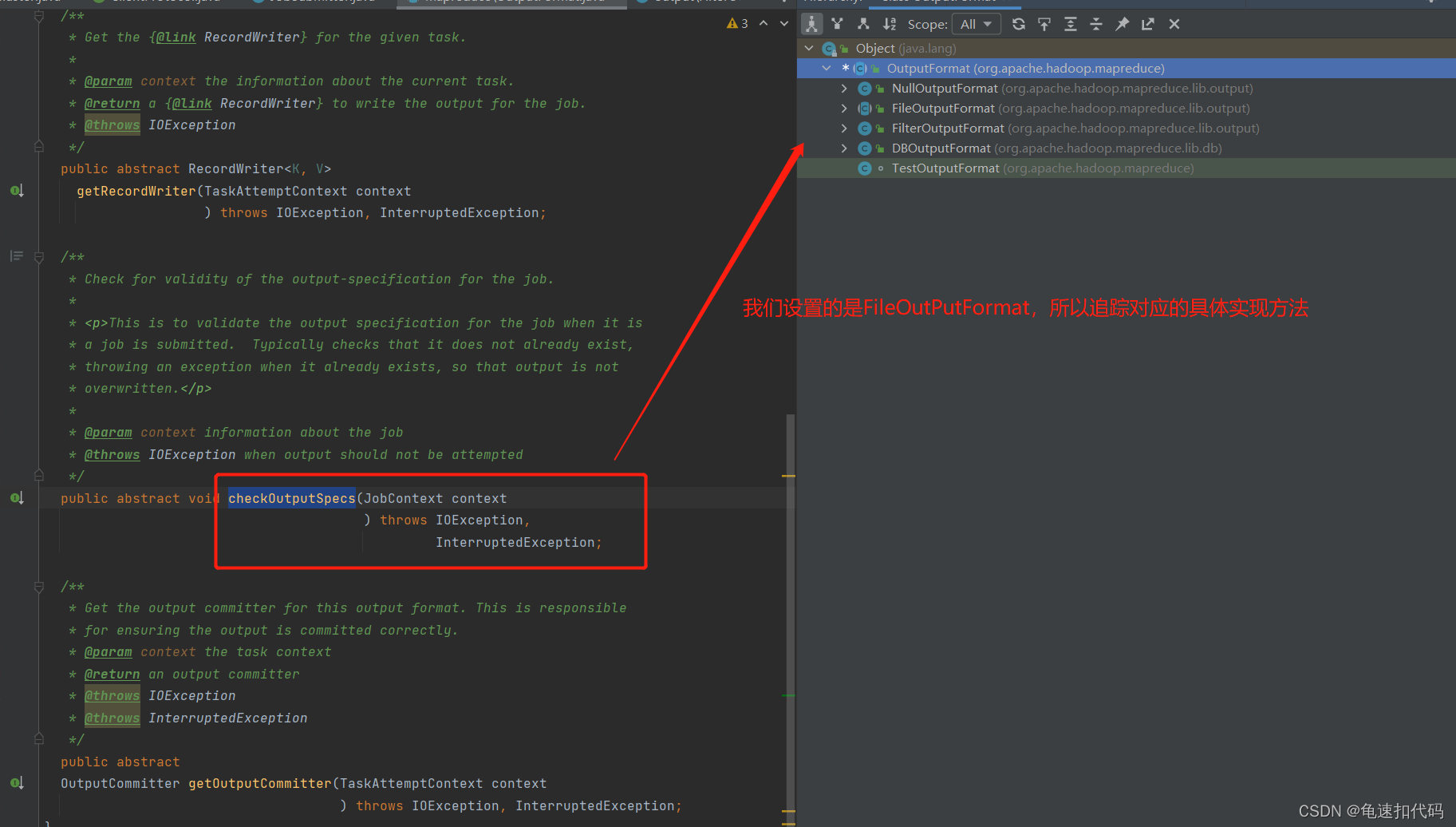
检查是否有reduce任务
若没有,则是只有mapper任务,输出默认是FileSystem,调用检查路径的方法。
若有reducer任务,则通过反射取到用户设置的outPutFormat对象,并调用检查路径的方法。

?
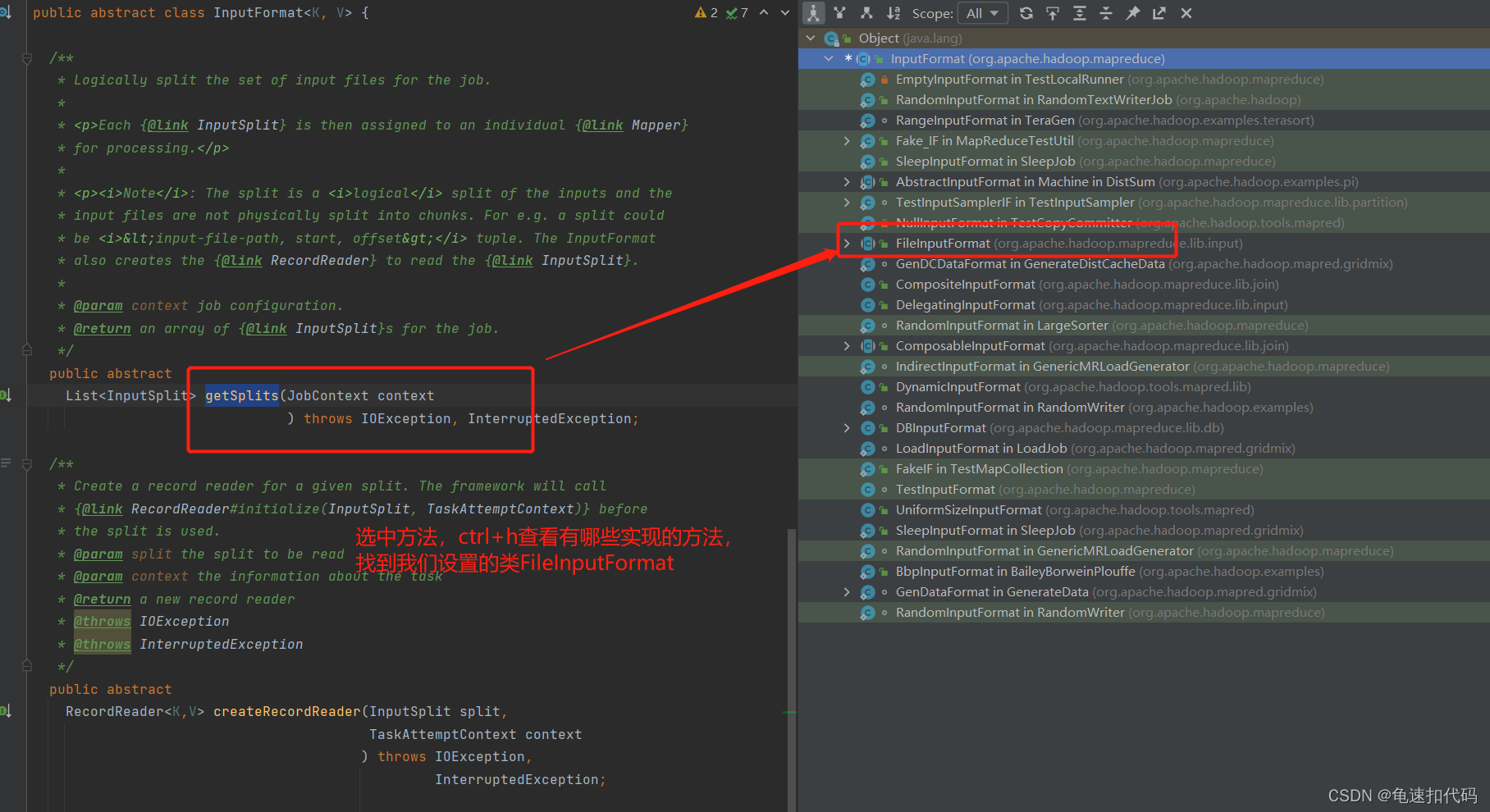
?3.2- 追踪计算切片数量的方法 JobSubmit.writeSplits()
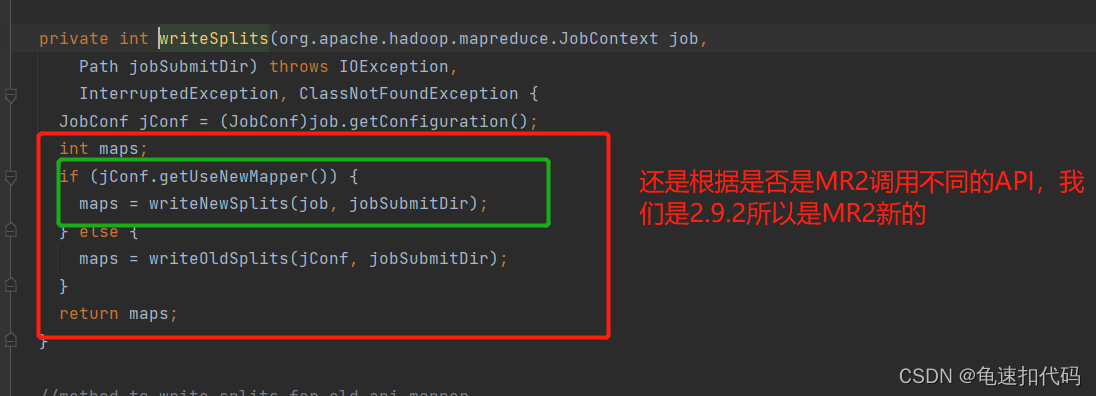
?不同的输入格式有不同的计算实现方法,我们这里是FileInputFormat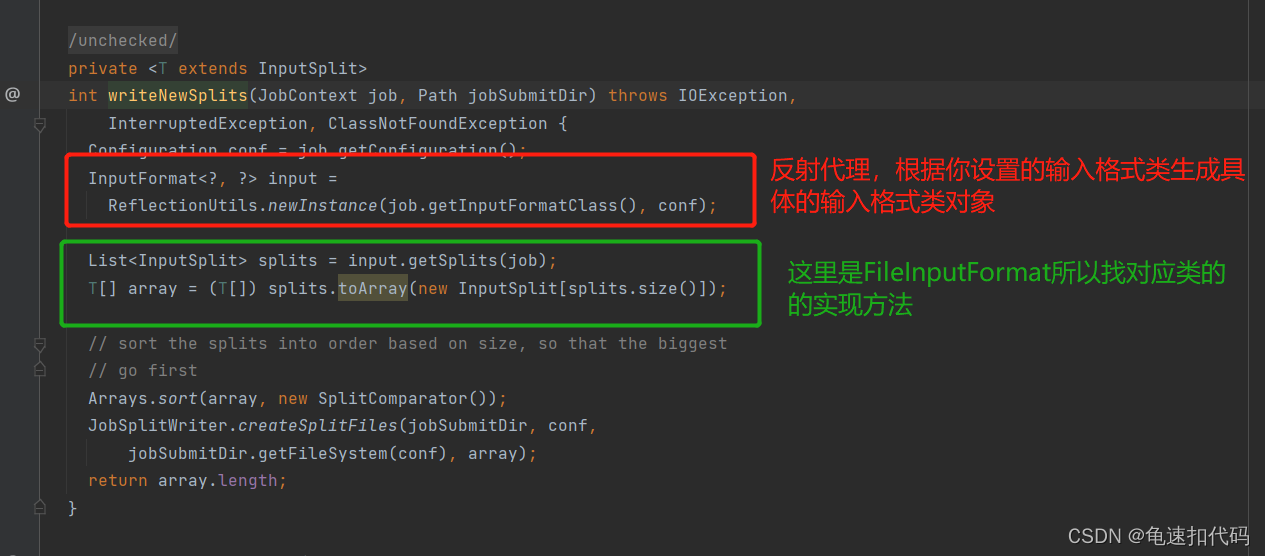
?
?发现具体的计算逻辑还是在 computeSplitSize()方法中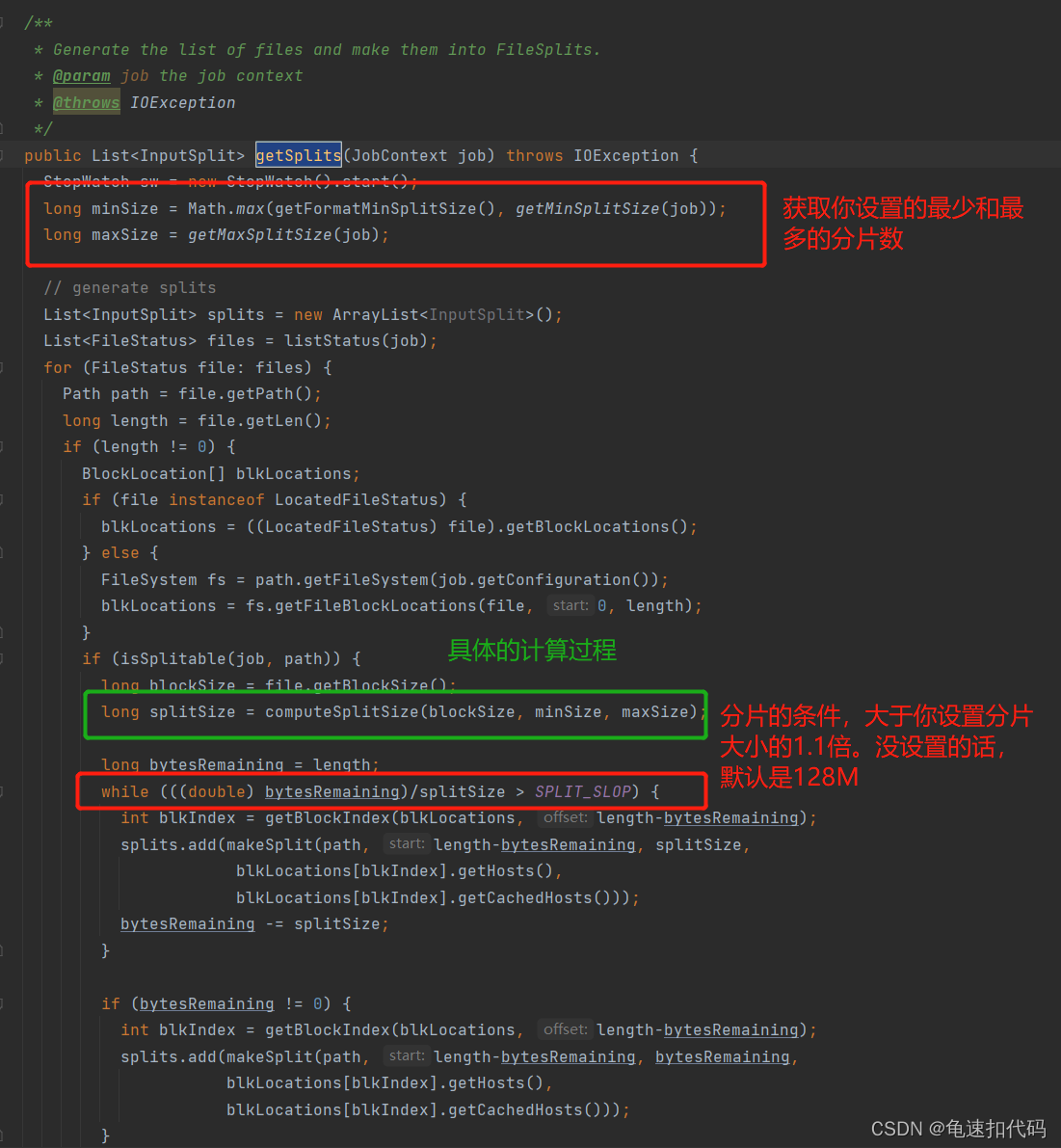
?追踪computeSplitSize()方法

?再回去看 minSize,maxSize,blockSize的值是什么
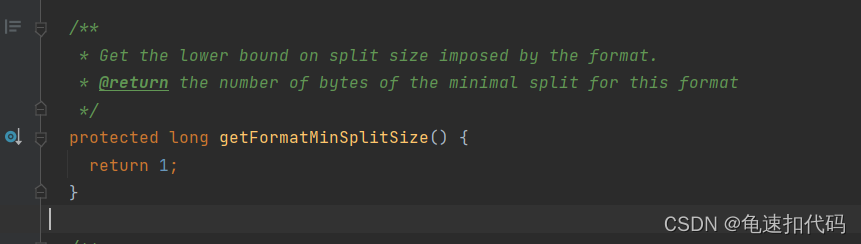
minSize是,没有设置块的最小字节数,则默认是1 。若设置了比1大的值,则取设置值

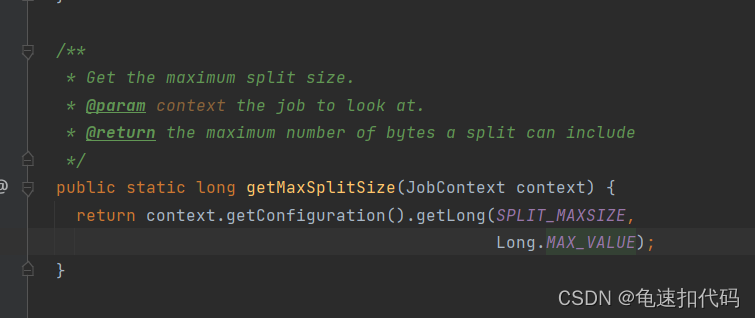
?maxSize? 没有设置每个块的最大字节数则取Long的值,设置了则取设置值
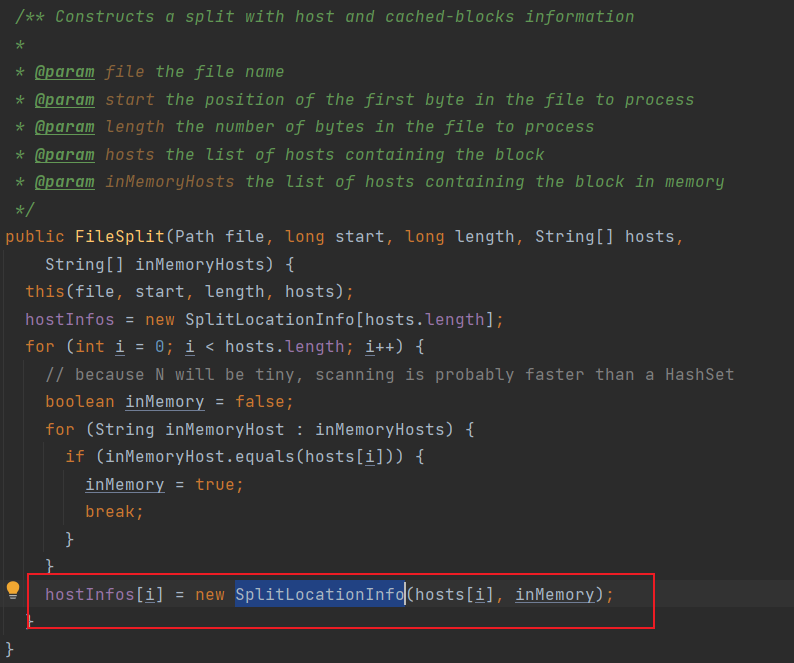
切片方法中还包含了 分片的存放元数据(存放在哪些机器节点上,是否存在内存中)

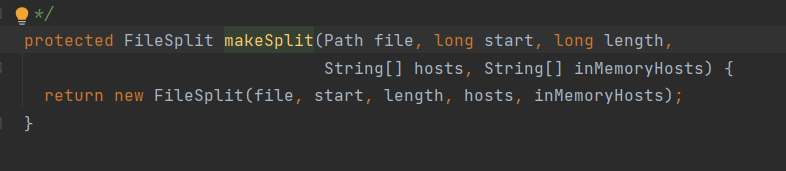 ?
?
?3.3- 追踪构建 存放 jar和conf的目录

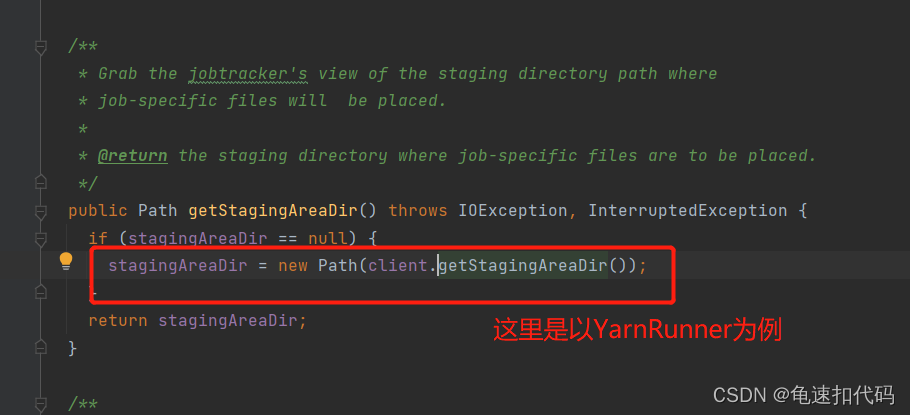

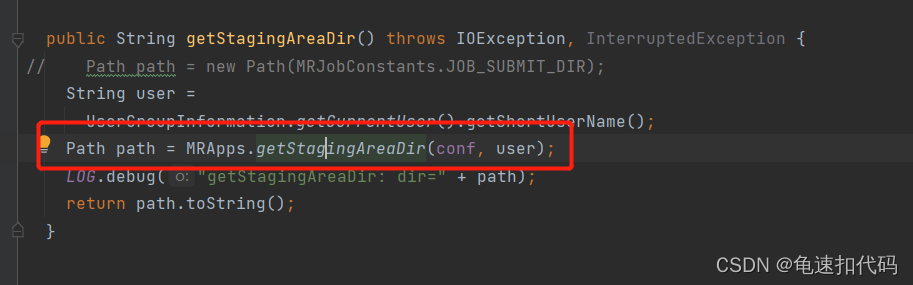

?上传conf和jar


3.4- 如果有认证的,需要的一些操作逻辑,先拷贝

3.5- 真正的提交
?也是反射,根据不同的客户端对象提交到不通的Runner,
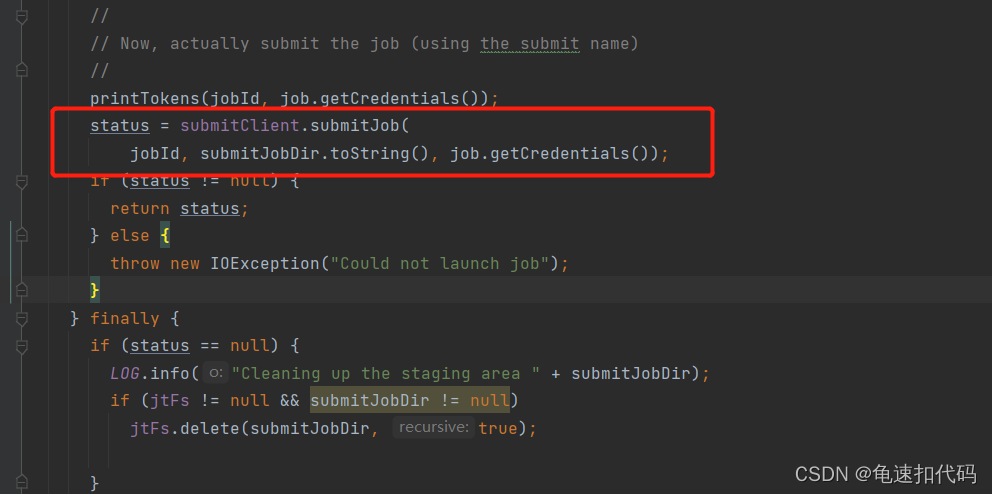

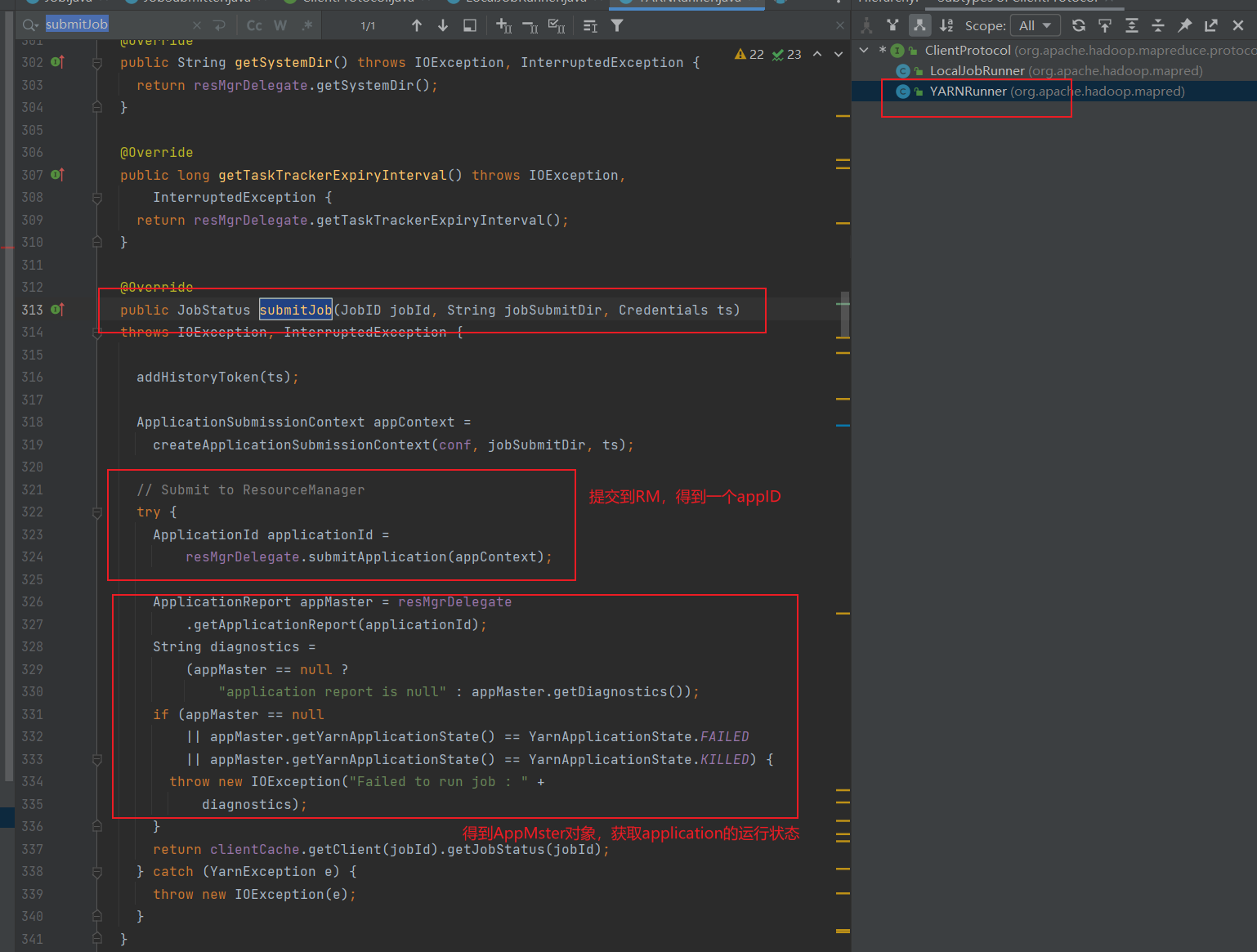
3.5.1-yarnRunner?
ctrl + h , 找到yarn的实现方法
?

