elasticsearch
elasticsearch��һ��dz�ǿ��Ŀ�Դ��������,���������ǴӺ��������п����ҵ���Ҫ�����ݡ�
elasticsearch���kibana��Logstash��Beats,ͳ��elastic stack(ELK),���㷺Ӧ������־���ݷ�����ʵʱ��ص�����
elasticsearch��elastic stack�ĺ���,����洢����������������,kibana�������ݿ��ӻ�,Logstash��Beats��������ץȡ��
һ������docker��������
docker network Ϊ����������һ��ָ�����������������
����һ����������elasticsearch��kibana�������绥��,�����ͬһ������,kibana����ֱ��ͨ���������ʵ�es
1. ����������
docker network create es-net
2. ���Ӿ�����
�����ڴ���������ʱ��ʹ�èCnetwork������������,Ҳ�����ڴ���������֮���������������������
docker exec -it es bash
docker network connect es-net
���� ��װelasticsearch
1. ��ȡes����
//��ȡelasticsearch��7.12.1�汾�ľ���
docker pull elasticsearch:7.12.1
�����Լ�pull,Ҳ������ǰ���غþ����ϴ���������ʹ��docker load -i elasticsearch.tar ���ؾ���(�������ӷ����������)
2. ����es����
docker run
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
-d elasticsearch:7.12.1
3. ����˵��
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":�ڴ��С
esĬ��Ϊ1g�ڴ�,��Ͳ��ܵ���512,������ܳ����ڴ治������,�������ڴ��㹻�Ŀ���������-e "discovery.type=single-node":�Ǽ�Ⱥģʽ-v es-data:/usr/share/elasticsearch/data:��������,��es������Ŀ¼-v es-logs:/usr/share/elasticsearch/logs:��������,��es����־Ŀ¼-v es-plugins:/usr/share/elasticsearch/plugins:��������,��es�IJ��Ŀ¼--privileged:������������Ȩ--network es-net:����һ����Ϊes-net��������-p 9200:9200:�˿�ӳ������
elasticsearch ��HTTP Э��� RESTful �ӿ�ʹ�� 9200 �˿�; 9300 �� TCP ͨѶ�˿�,��Ⱥ��� TCP Client��9300-e "cluster.name=es-docker-cluster":���ü�Ⱥ����-e "http.host=0.0.0.0":�����ĵ�ַ,������������
������װkibana
1. ��ȡkibana����
kibana�汾��Ҫ��elasticsearch����һ��,Ҳ���Լ���kibana����������ľ����,�����������������
docker pull kibana:7.12.1
2. ����kibana����
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
3. ����˵��
--network es-net:��elasticsearch��ͬһ��������-e ELASTICSEARCH_HOSTS=http://es:9200":elasticsearch�ĵ�ַ,kibana��elasticsearch��һ������,��˿�����������ֱ�ӷ���elasticsearch-p 5601:5601:�˿�ӳ������
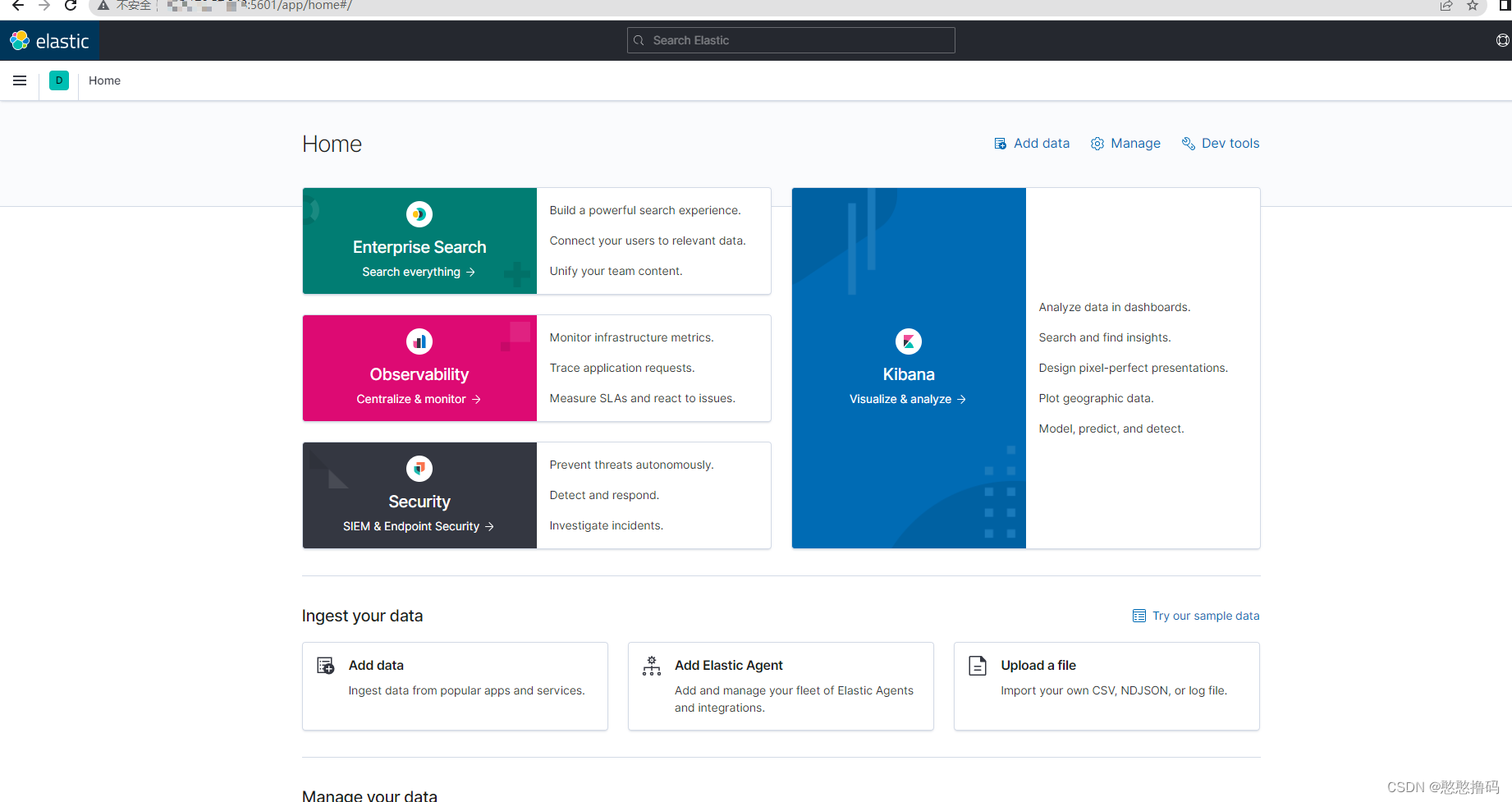
4.����kibana
ͨ��IP��5601�˿ڷ���kibana
5. ����ʹ��DSL�����es���Ͳ�ѯ����
���������������һ�� Dev Tools,������es���Ͳ�ѯ����,������ΪDSL���
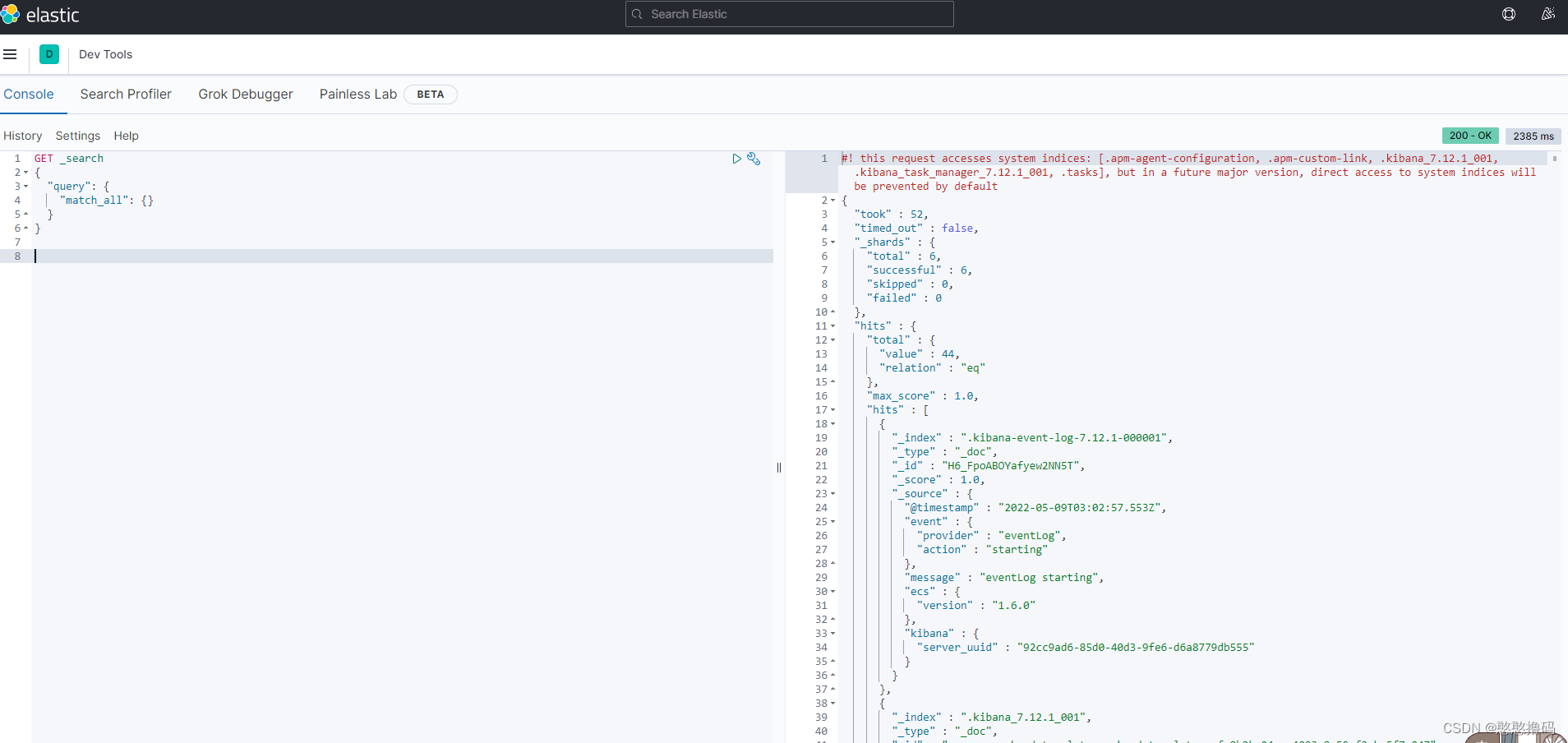
6. �û�����ʱ,����������ݽ��зִ�
����ͨ���ִʵĽ��֪��ʹ��esĬ�ϵķִ�������������ִʲ���Ч

�ġ��ִ���
1. �ִ���������:
(1) ������������ʱ���ĵ����зִ�
(2) �û�����ʱ,����������ݽ��зִ�
2.IK�ִ�������
�������ķִ�һ���ʹ��IK�ִ���,���������ַ�ʽ
(1) �л��������ڲ�������������
docker exec -it es bash
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-
ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
(2)ֱ�ӽ����غõ�ik��ѹ��es��pluginsĿ¼��(�Ƽ�ʹ�����ַ�ʽ)
3.IK�ִ�����ģʽ
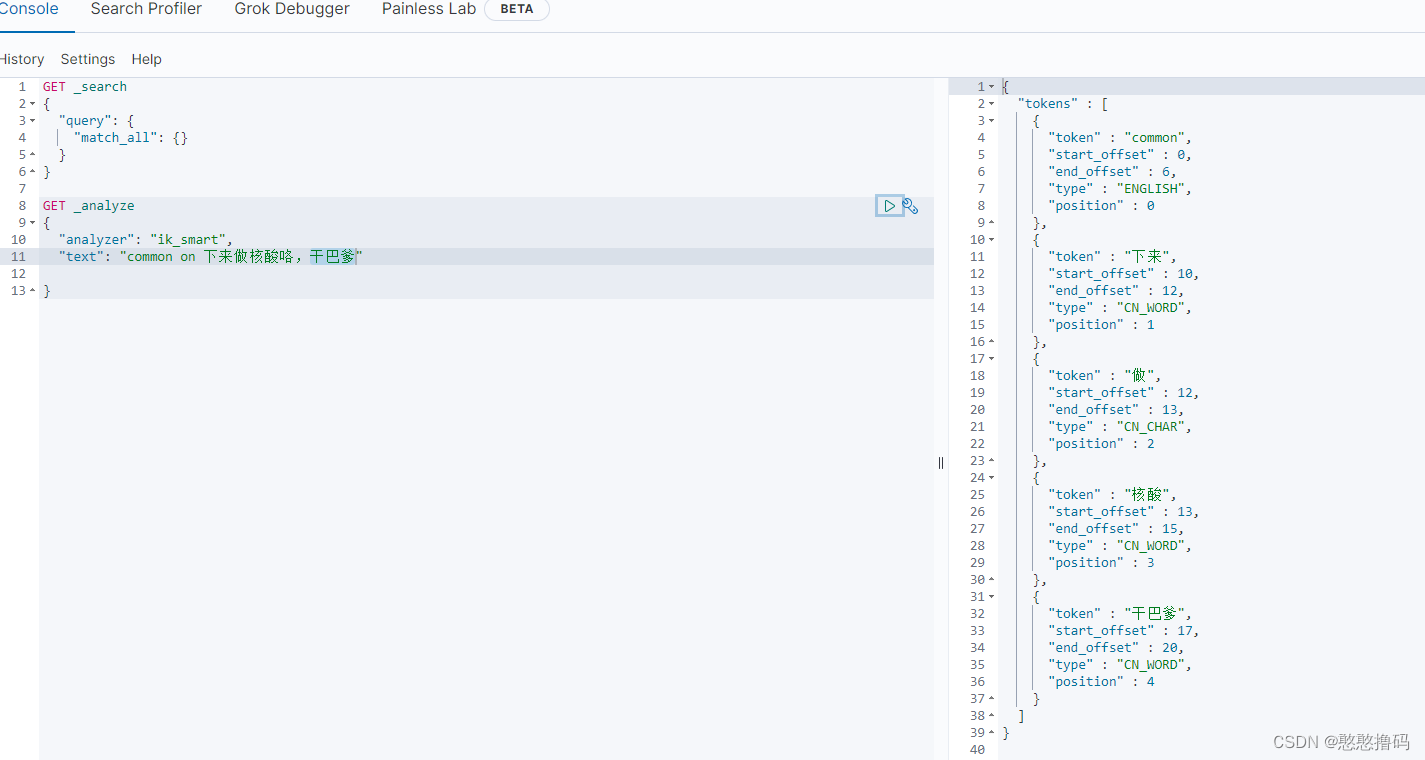
ik_smart:�����з�,������
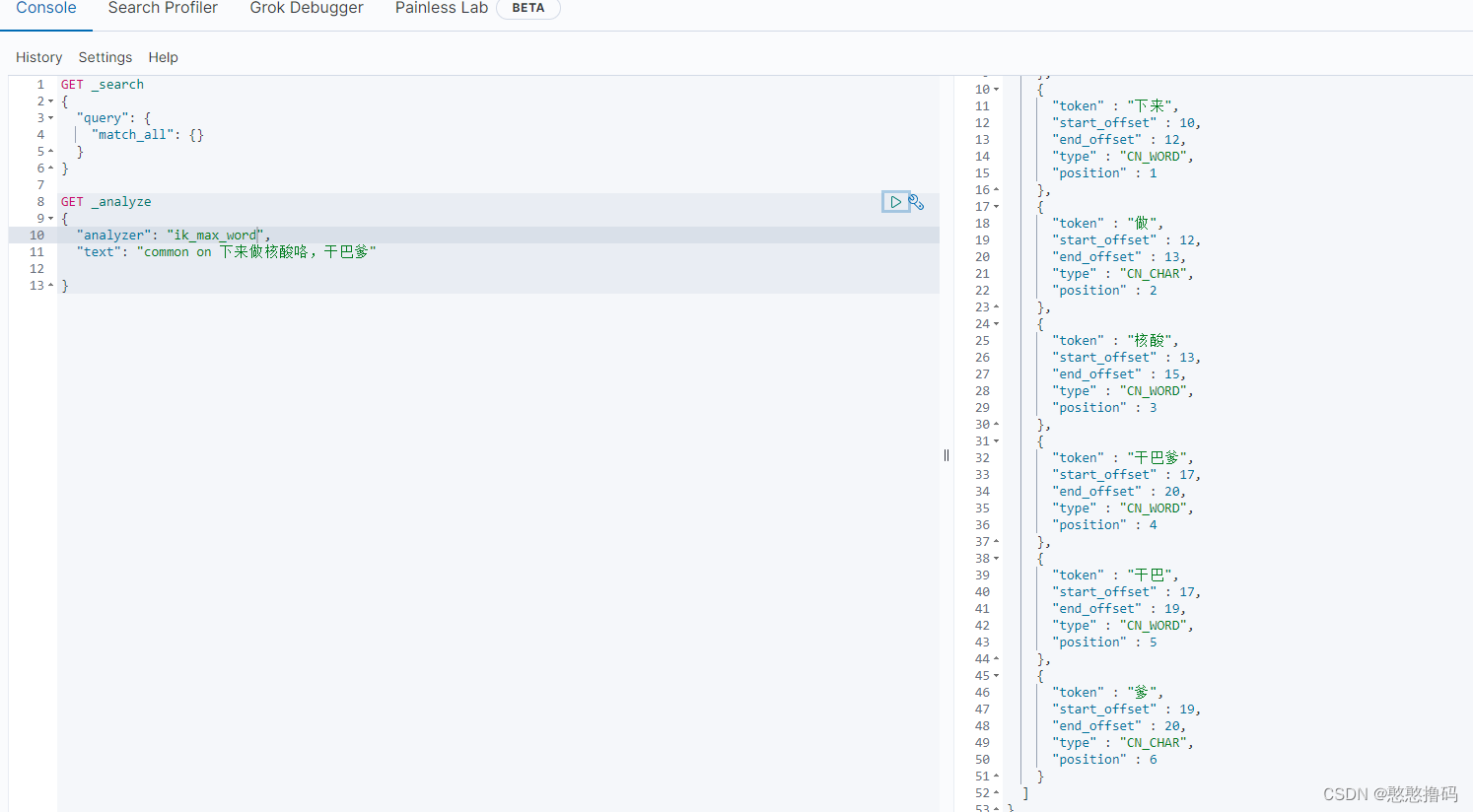
ik_max_word:��ϸ�з�,ϸ����
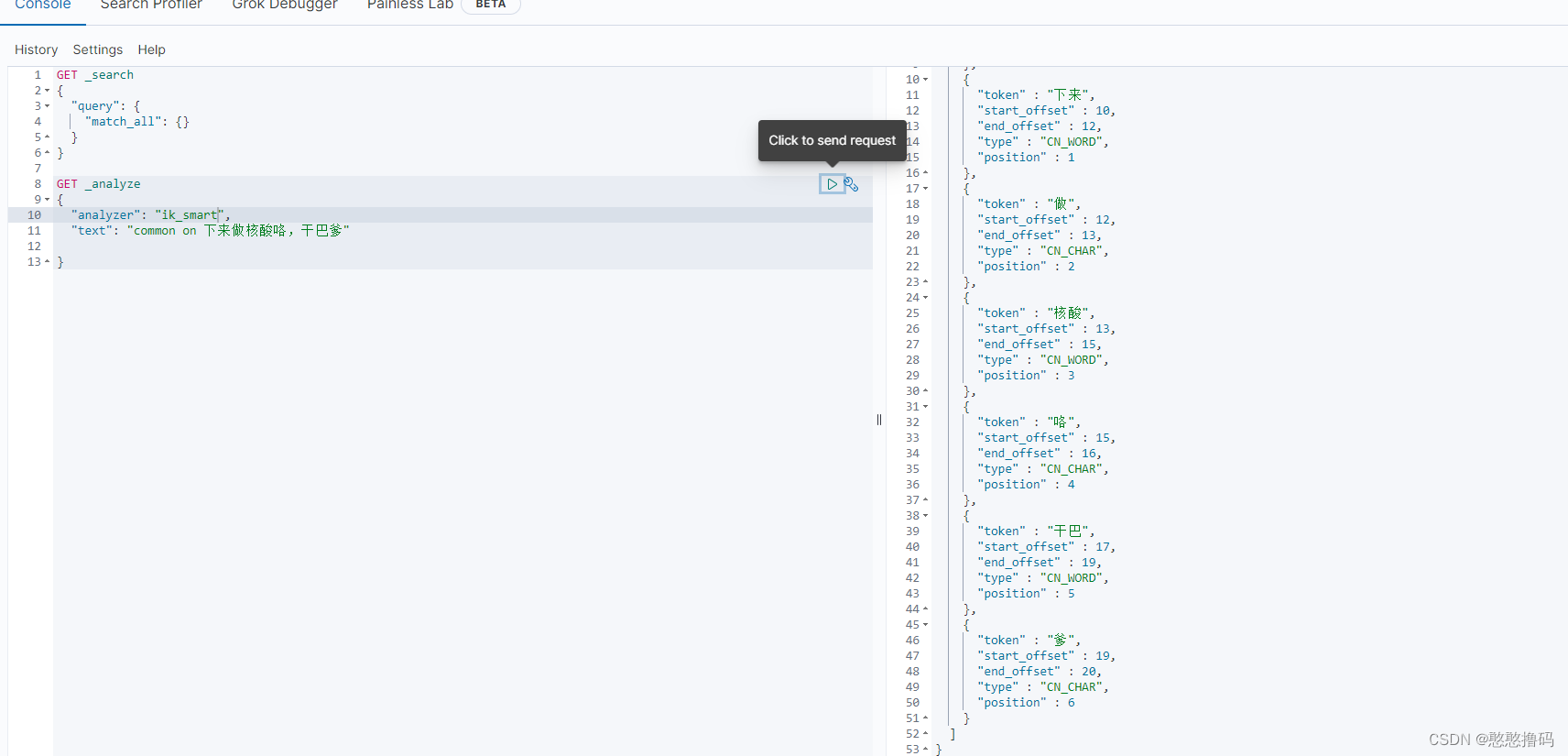
ʹ��IK�ִ���֮��,���ķִ���Ч��,����Щ������������ض��Ĵ�IK�ִ�����ʶ��,���ʱ�����ǿ�����չ�ʿ�,�Լ�����һЩ�������ִʵĴ��
4.������չ�ĵ������ĵ�
��IK�����������ĵ�IKAnalyzer.cfg.xml,�����ĵ�,�ĵ�λ����Ҫ��xml�ļ���ͬһ��Ŀ¼
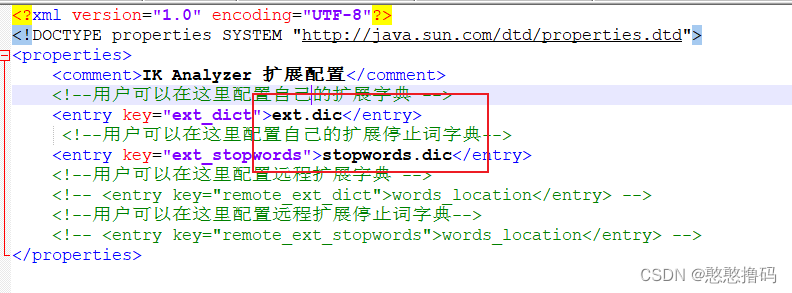
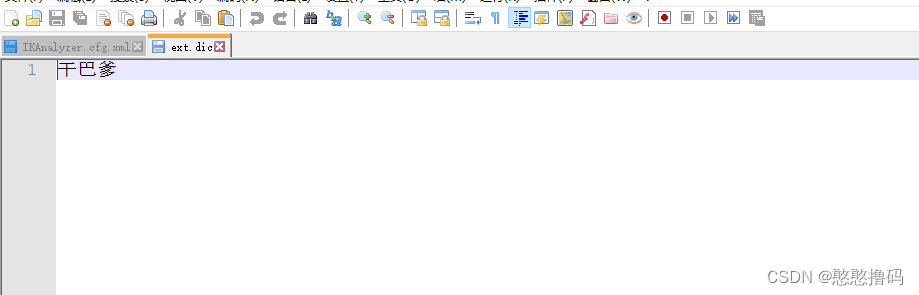
configĿ¼��Ĭ��ֻ��stopwords.dic,û��ext.dic,��Ҫ�Լ�����ext.dic;
����es����,���·�������
�������ص�ַ:https://download.csdn.net/download/booguojieji/85329645

